AI入门学习--如何对RAG测试
RAG(Retrieval-Augmented Generation)测试是确保检索增强生成系统可靠性的关键环节。作为测试工程师,你需要聚焦检索准确性、生成质量和端到端一致性三大维度
一、RAG系统核心架构与测试靶点
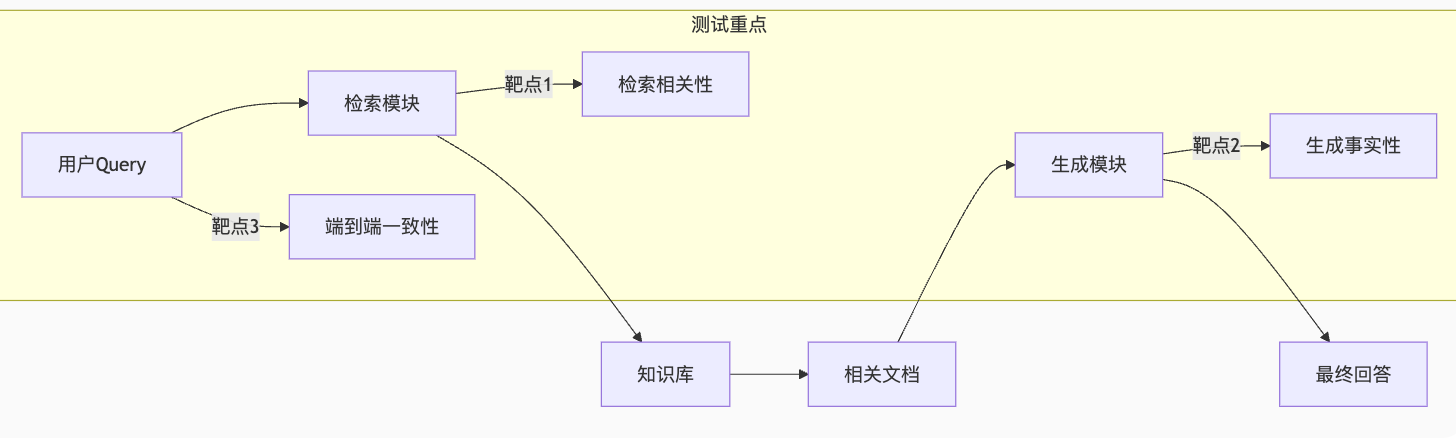
二、测试的核心目标
- 检索器是否能从知识库中精准找到与问题相关的文档(“找得对”);
- 生成器是否基于检索到的知识生成准确、无幻觉(无虚假信息)的回答(“答得好”);
- 系统在边界场景(如知识库无相关信息、问题模糊等)下的鲁棒性;
- 特定领域(如医疗、法律)的专业性和合规性。
三、准备测试数据
测试问题集
- 覆盖不同类型:事实性问题(如 “XX 产品的发布时间?”)、推理类问题(如 “根据文档,XX 政策的影响是什么?”)、模糊问题(如 “介绍一下 XX”)、对抗性问题(如故意混淆概念的问题)。
- 覆盖不同难度:简单匹配(问题与文档关键词高度一致)、语义关联(问题与文档语义相关但用词不同)、多文档关联(需结合多个文档信息)。
黄金文档(Ground Truth Documents)
- 为每个测试问题标注知识库中真正相关的文档(1 个或多个),作为检索器的 “标准答案”。
黄金答案(Ground Truth Answers)
- 基于黄金文档人工撰写理想回答,作为生成器的参考标准(需明确:哪些信息必须包含、哪些需避免)。
四、分模块测试
1. 检索器(Retriever)测试
核心评估 “是否能找到正确的文档”,常用指标和方法:
召回率(Recall):检索结果中包含的黄金文档占所有黄金文档的比例(越高越好,确保不遗漏关键信息)。
- 例:某问题的黄金文档有 3 篇,检索器返回的前 5 篇中包含 2 篇,则召回率 = 2/3。
精确率(Precision):检索结果中黄金文档的占比(越高越好,确保减少无关信息)。
- 例:检索器返回 5 篇文档,其中 3 篇是黄金文档,则精确率 = 3/5。
排序质量:相关文档是否排在检索结果的靠前位置(重要,因为生成器通常优先使用前 N 篇文档)。
- 常用指标:NDCG(归一化折损累积增益)、MAP(平均精确率均值)。
测试方法:
- 批量输入测试问题,获取检索器返回的 Top N 文档(如 Top 3/5/10);
- 对比返回文档与黄金文档,计算上述指标;
- 重点关注 “漏检”(黄金文档未被检索到)和 “误检”(无关文档被高分返回)的案例。
2. 生成器(Generator)测试
核心评估 “是否基于检索到的文档生成高质量回答”,需结合自动指标和人工评估:
自动指标(快速量化,辅助筛选问题):
- 相关性:ROUGE(与黄金答案的重叠度,适合评估事实性内容)、BLEU(机器翻译常用,适合短句匹配)。
- 准确性:Faithfulness(生成内容与检索文档的一致性,可通过模型判断 “生成的每句话是否能从检索文档中找到依据”)。
- 无幻觉:Hallucination Rate(生成内容中未在检索文档或黄金文档中出现的信息占比)。
人工评估(核心,尤其对复杂问题):
- 准确性:是否完全基于检索文档,无虚假信息;
- 完整性:是否覆盖黄金答案的核心要点;
- 流畅性:语言是否自然、逻辑是否清晰;
- 相关性:是否紧扣问题,不偏离主题。
3. 端到端测试(整体流程)
模拟真实用户使用场景,直接输入问题,评估最终输出结果:
核心指标:
- 回答准确率:生成内容与黄金答案的匹配度(人工为主);
- 用户满意度:通过模拟用户打分(如 1-5 分,评估 “是否解决问题”);
- 鲁棒性:
- 知识库无相关信息时,是否能明确告知 “无法回答”(而非编造答案);
- 输入错别字、歧义问题时,是否能正确理解并处理。
测试方法:
- 随机抽取测试问题集中的样本,运行完整 RAG 流程;
- 对比输出结果与黄金答案,记录 “检索错误导致生成错误”“检索正确但生成错误” 等不同失败类型;
- 分析高频错误场景(如特定领域术语、长文档检索、多步推理问题)。
4.特殊场景测试
- 领域适配性:若 RAG 针对特定领域(如金融、医疗),需测试专业术语的处理能力(是否准确检索专业文档、生成专业回答)。
- 时效性:若知识库包含时间敏感信息(如政策、新闻),测试对 “新信息” 的检索和生成效果(如 “2023 年后的 XX 政策” 是否优先返回最新文档)。
- 多模态:若知识库包含图片、表格等非文本信息,测试检索器对多模态内容的理解(如 “根据表格,XX 数据是多少?”)。
五、测试工具与流程
工具:
- 检索测试:Elasticsearch 自带的评估工具、Haystack 的 Eval 模块;
- 生成测试:Hugging Face Evaluate 库(含 ROUGE、BLEU 等)、LangChain 的评估链(Evaluator Chains);
- 端到端:自定义脚本结合人工标注平台(如 Label Studio)。
流程:
- 先做模块测试(检索器→生成器),定位单模块问题;
- 再做端到端测试,验证整体效果;
- 针对高频错误优化(如调整检索器的嵌入模型、优化生成器的提示词),重复测试迭代。