Uipath Studio中爬取网页信息
步骤分析
1:登录百度搜索网站
2:在搜索框里输入关键词
3:点击“百度一下”
4:点击“资讯”
5:创建一个Excel文档
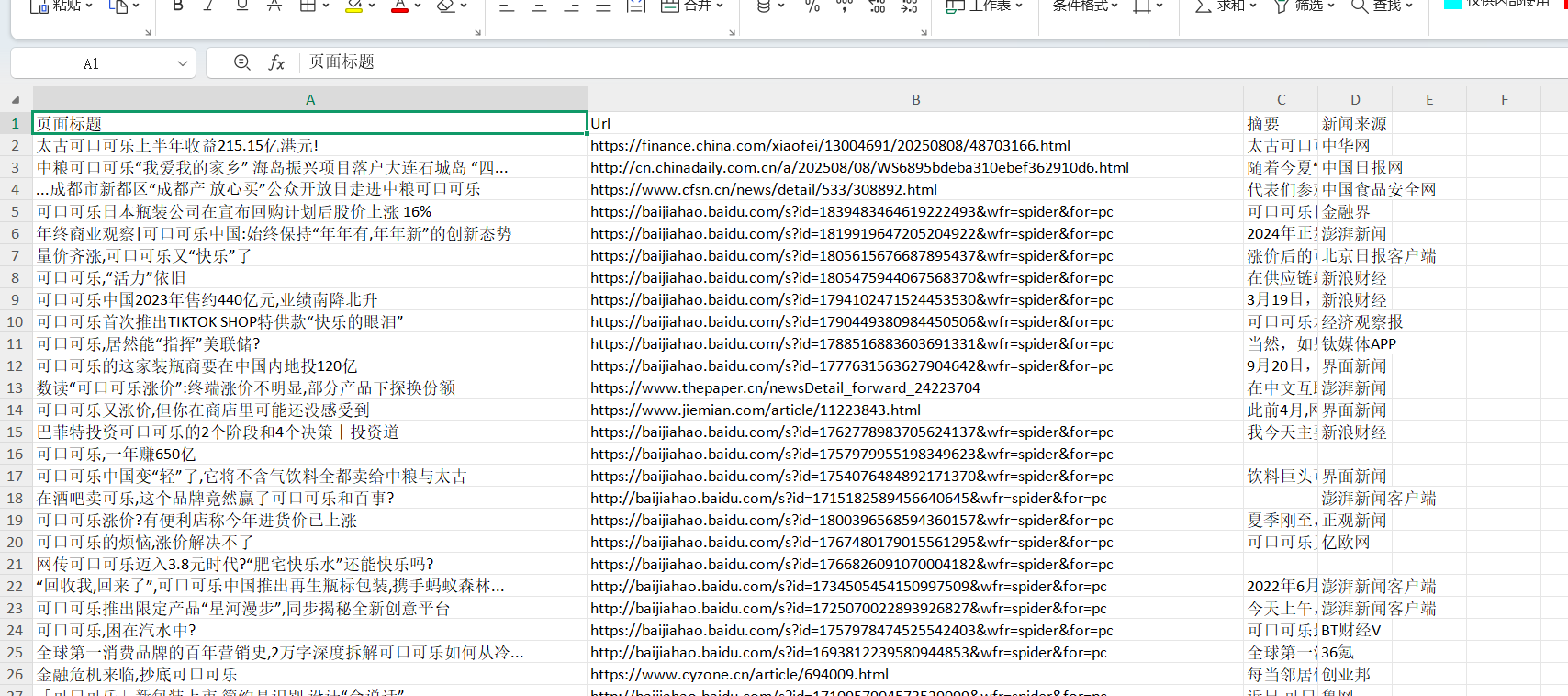
6:读取标题,URL,摘要和新闻来源,并保存到Excel文档
7:重复上一步,读取和保存前*条资讯
8:保存Excel文档
一:准备阶段(新建流程,选择熟悉的语言,打开主工作流)
二:具体操作步骤
1:点击+号

2:双击选择使用应用程序/浏览器(提前打开百度网址)
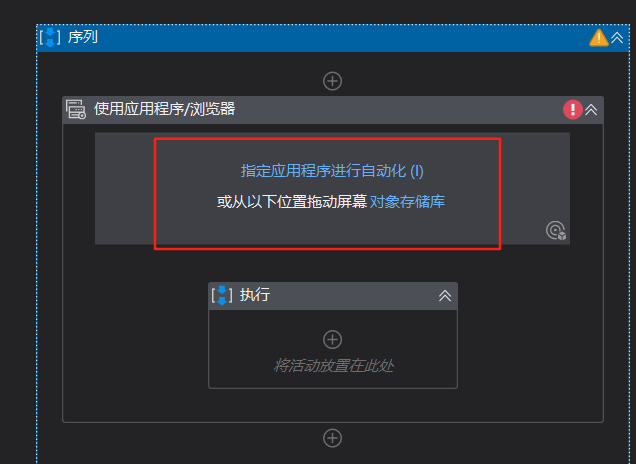
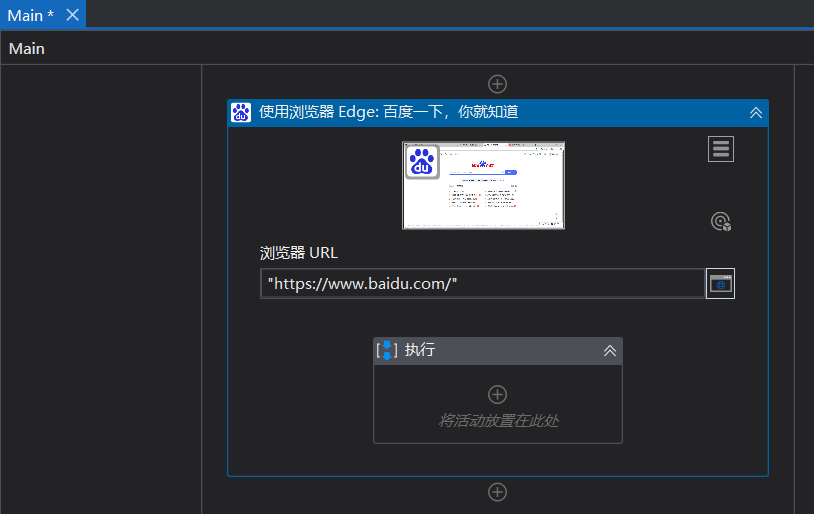
3:点击执行,双击选择输入信息
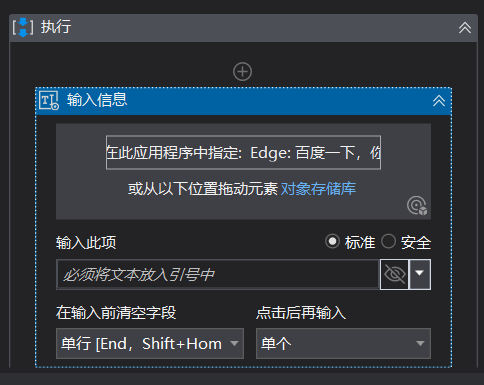
定位到百度的输入框,需要一个锚点(可选择图中蓝色框区域),然后输入你想找的内容(如“可口可乐”)这时,可在网页上模拟一下输入可口可乐后的操作步骤
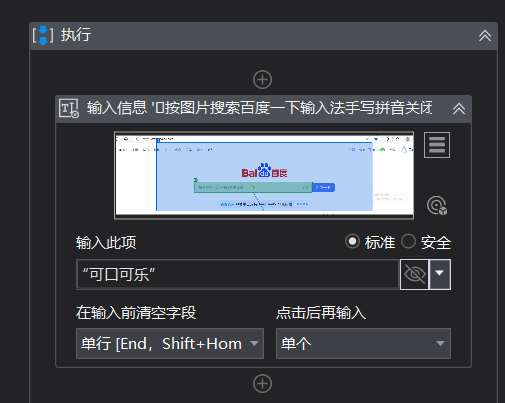
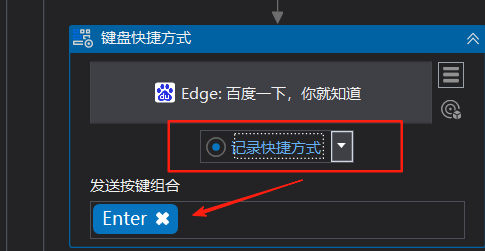
4:需要一个回车或者百度一下进入搜索页,这我们就模拟回车;点击+号,输入键盘,选择键盘快捷方式,然后点击记录快捷方式,键盘上按下回车键,就记录好了
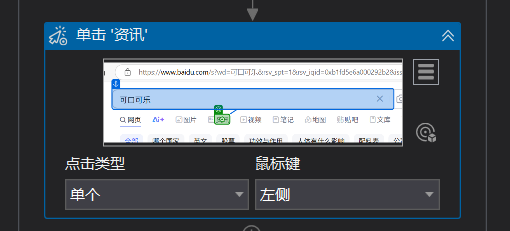
5:下一步,选择单击;选择资讯以及锚点的区域(锚点就是其他可参照的区域,防止网页更新)
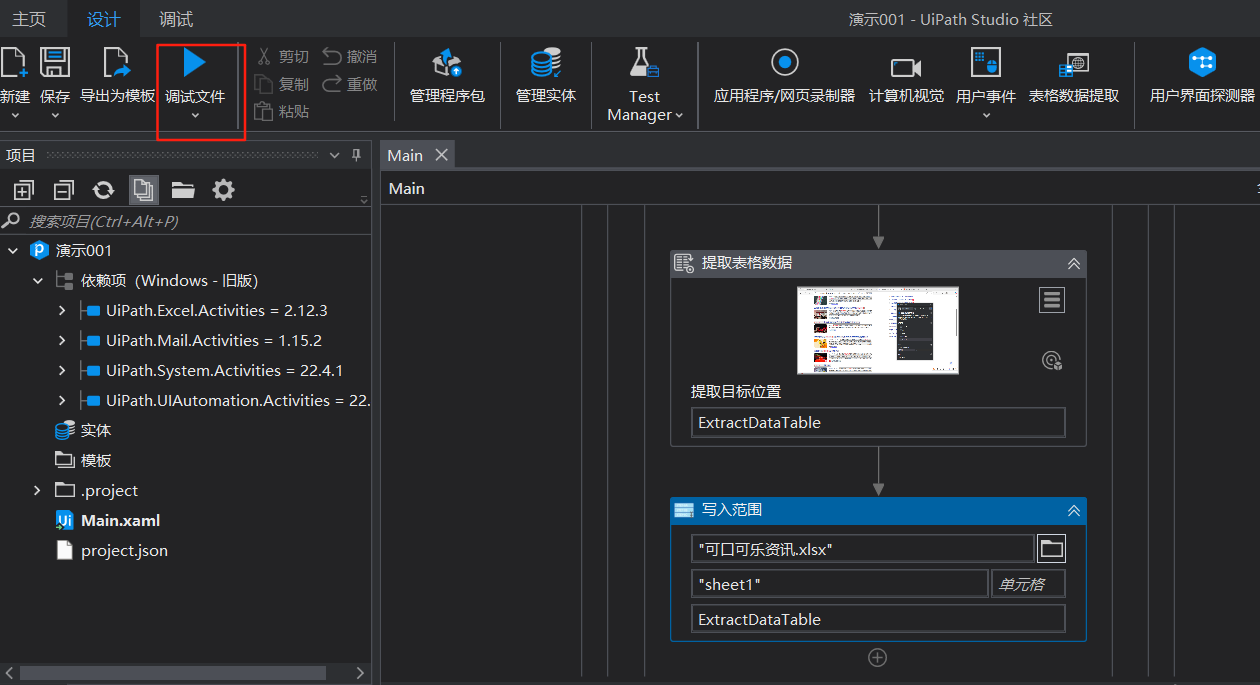
6:选择表格数据提取(同时百度网页上要在资讯的页面如图2),然后使用该工具
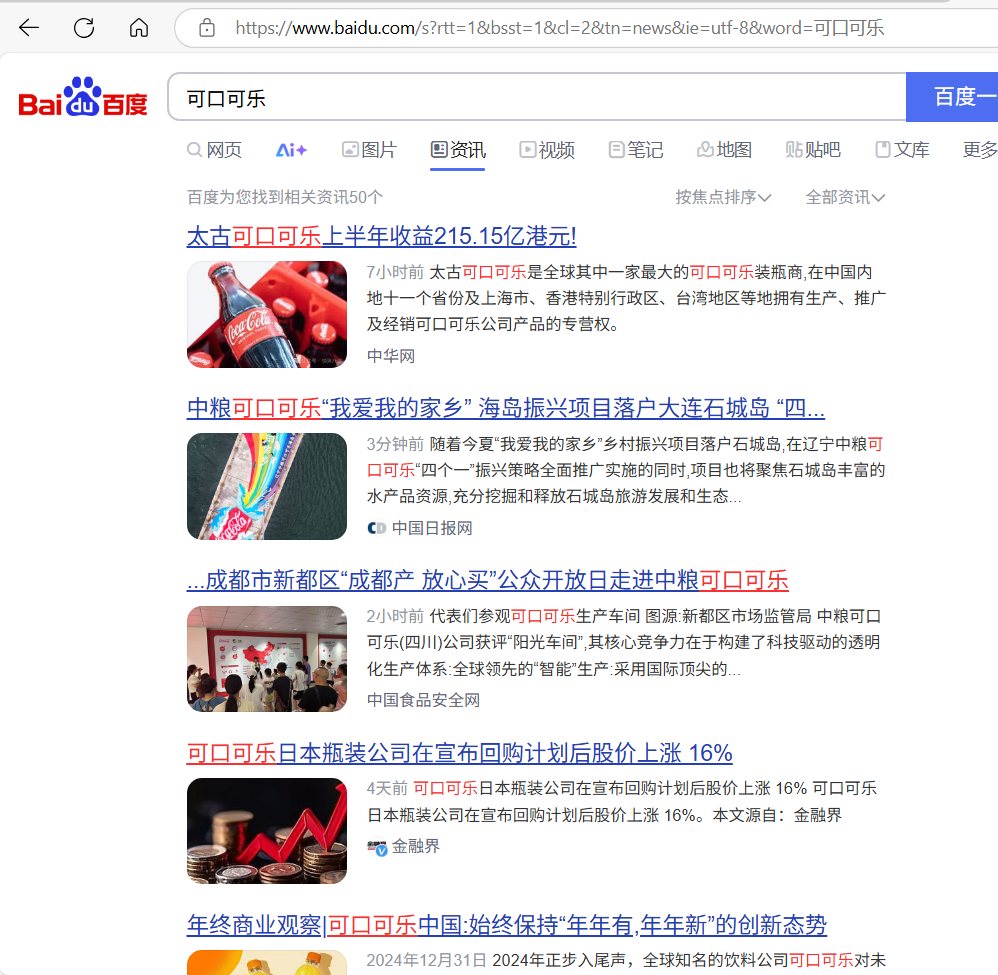
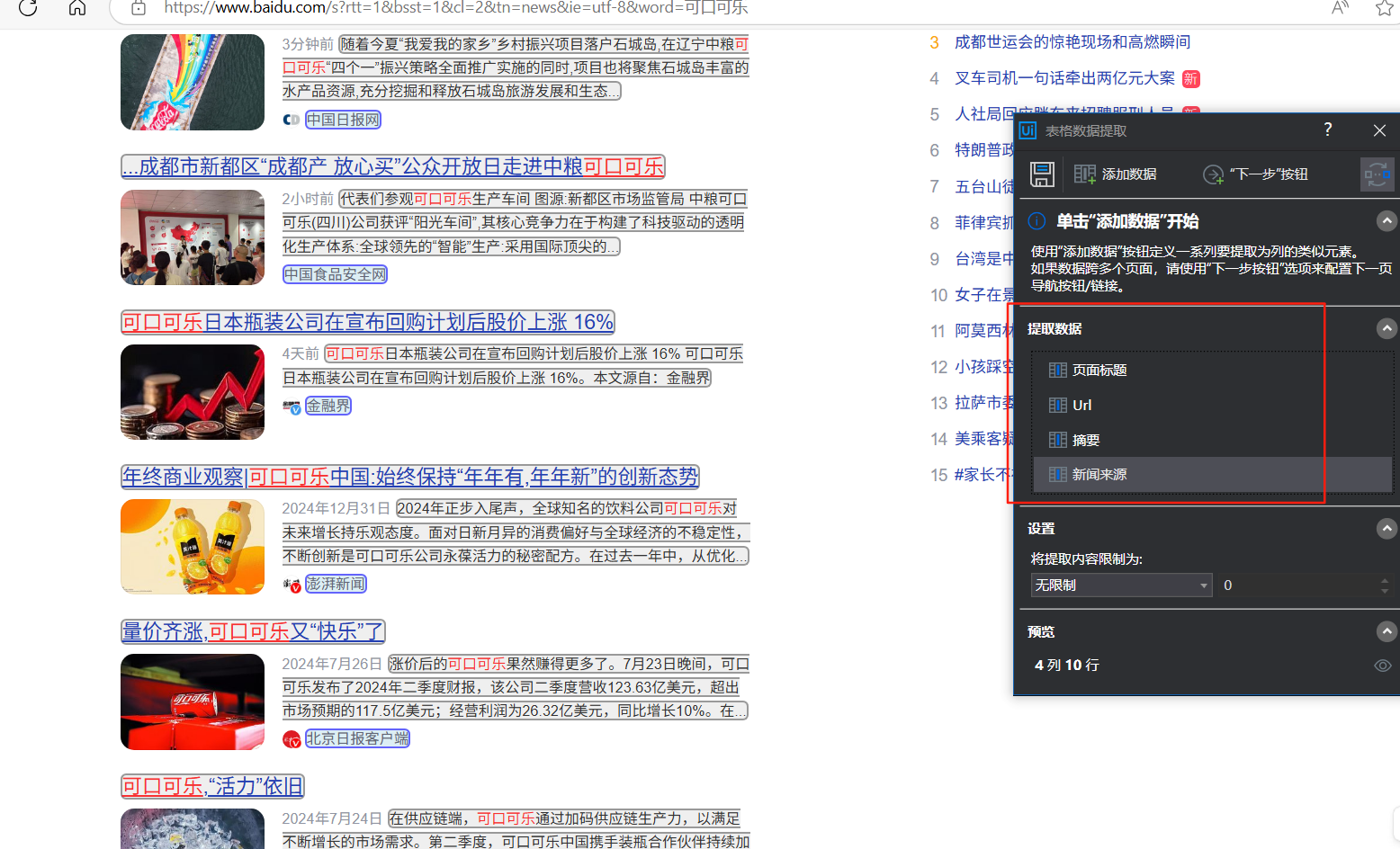
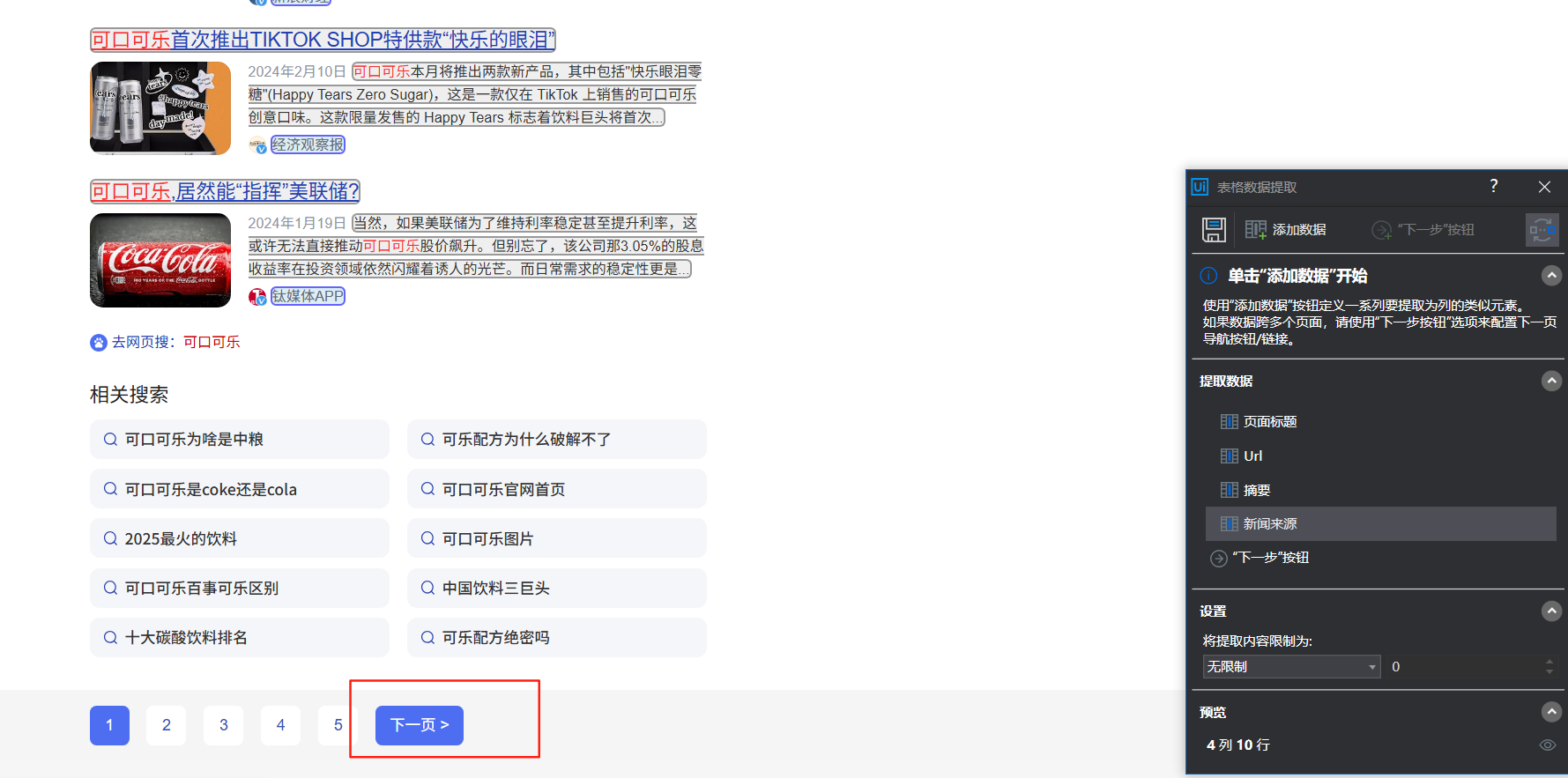
添加自己想要选择的数据,然后重命名(我选取的左边页面的标题、URL、摘要、新闻来源;这是当前页,然后我们需要多少页,点击下一步的按钮,选择自己需要的页数,点击保存;注意看数据选择的范围,有时位置不一样就没选到,多点几次自己要的数据即可)
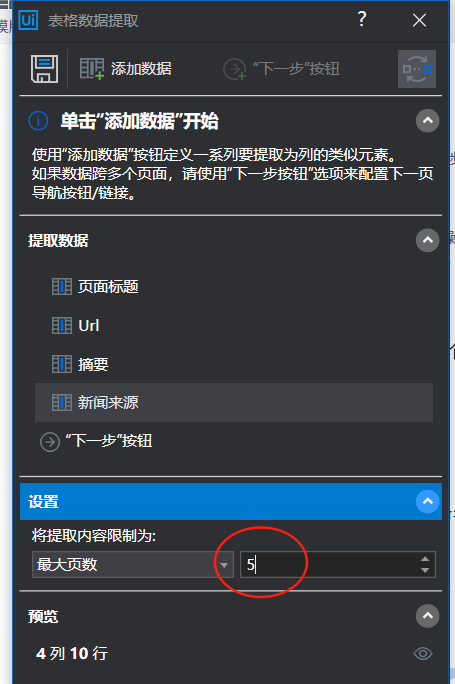
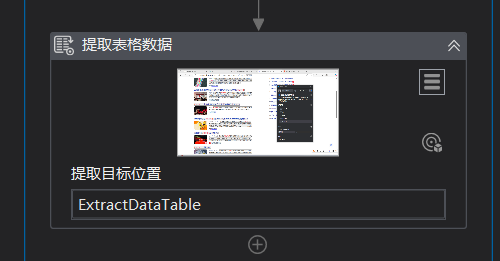
7:最后一步,双击写入范围,最后一个引用变量ExtractDataTable,然后加上标头
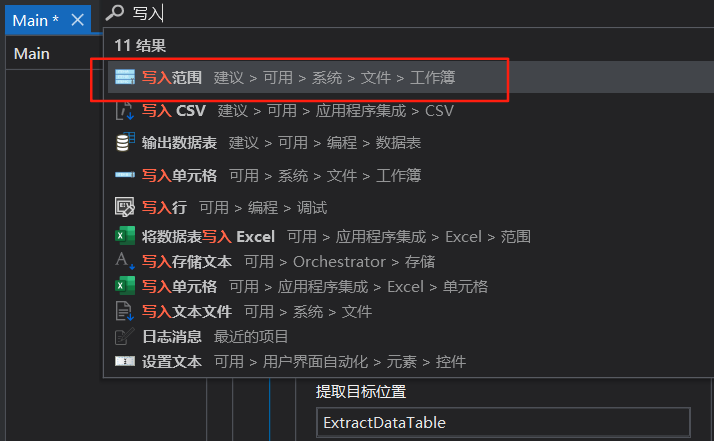
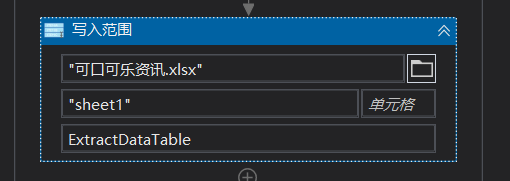
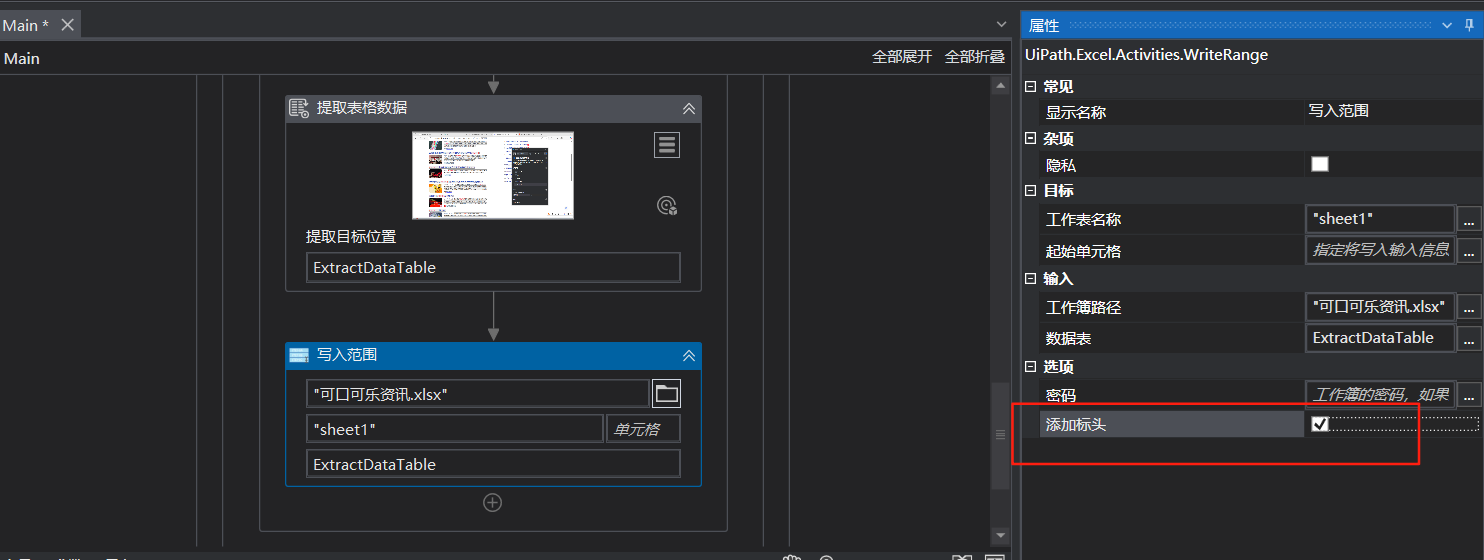
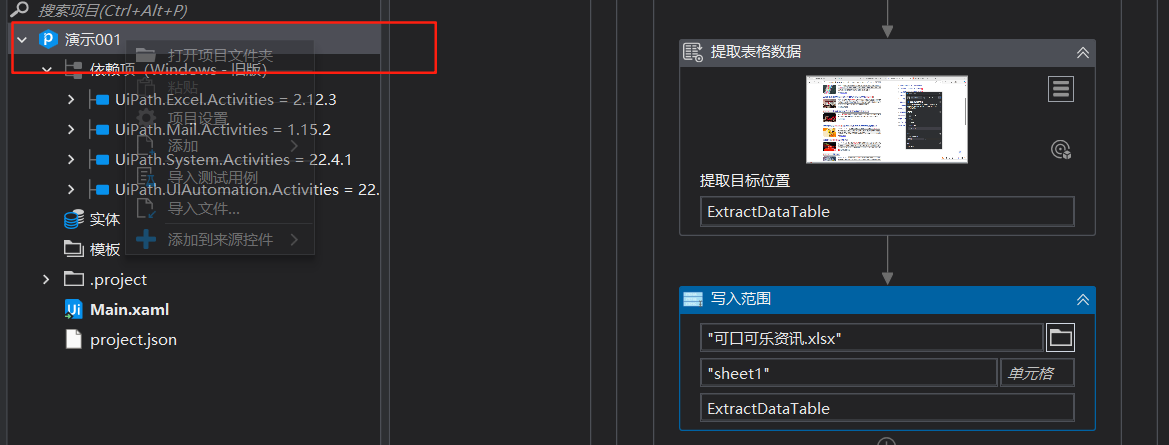
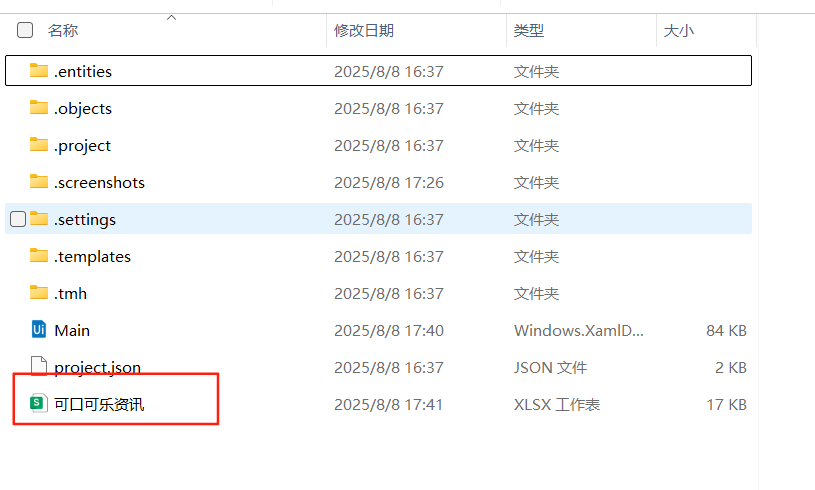
8:调试文件,跑完后然后在演示001右击打开项目文件夹