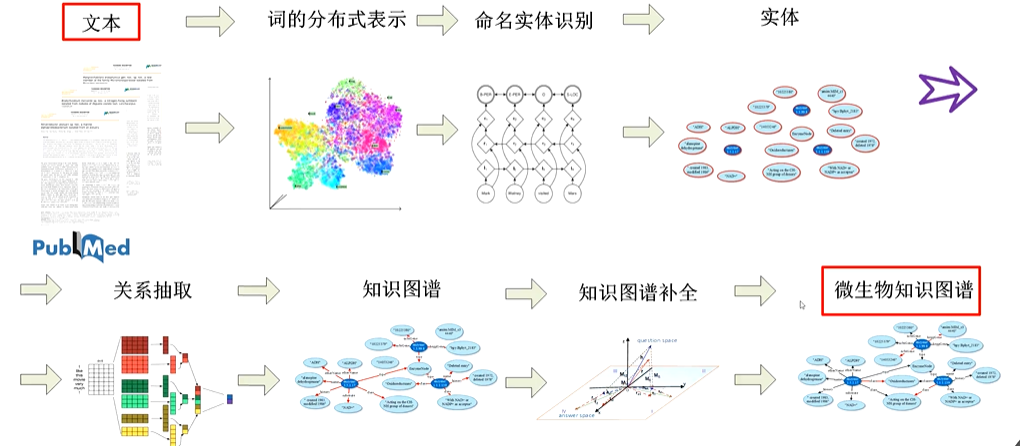
知识图谱【2】
目录
一、知识图谱的由来
1、起源
2、KG的本质
3、常见的KG
4、KG的技术体系
二、知识的表示与建模
1、知识表示的常见方式:
2、基于语义网的知识表示框架
左侧(技术实现视角)
右侧(功能抽象视角)
3、RDF简介
4、基于 Protégé 的知识建模
(1)什么是 Protégé?
三、知识的抽取与挖掘
1、知识抽取来源
(1)抽取来源是Database
(2)抽取来源是infoBox[信息框】
(3)抽取来源是Text
2、任务1-实体识别与抽取(抽取文本中的原子信息元素)
(1)什么是序列标注
(2)序列标注模型(实体识别的实现工具)
2、任务2-关系抽取
(1)基于规则的方法
(2)基于机器学习的监督方法
(3)半监督学习方法
(4)弱监督学习-远程监督学习方法
3、任务3-事件抽取
4、工具推荐
(1)DeepDive
四、知识的存储与查询
1、存储
(1)图数据库
(2)关系型数据库(RDBMS)
(3)三元组存储
2、查询技术
(1)基于结构化查询语言
(2)基于语义检索
五、知识的补全与融合
1、补全方法分类
2、知识融合
3、挑战
六、举例-KGBuilder
一、知识图谱的由来
1、起源
知识图谱的概念在 2012 年由 Google 首次提出,用于改进搜索引擎的理解能力,让搜索从“关键字匹配”进化为“语义理解”。
其实在此之前,人工智能领域已经有类似的工作,例如:
-
语义网(Semantic Web):由 Tim Berners-Lee 提出,通过 RDF(资源描述框架)和 OWL(Web本体语言)来实现数据的语义化和关联。
-
本体(Ontology):在人工智能和哲学中,本体是对概念及其关系的形式化描述。
Google 将这些理念落地到互联网搜索中,诞生了我们今天熟知的知识图谱概念和工程化实践。
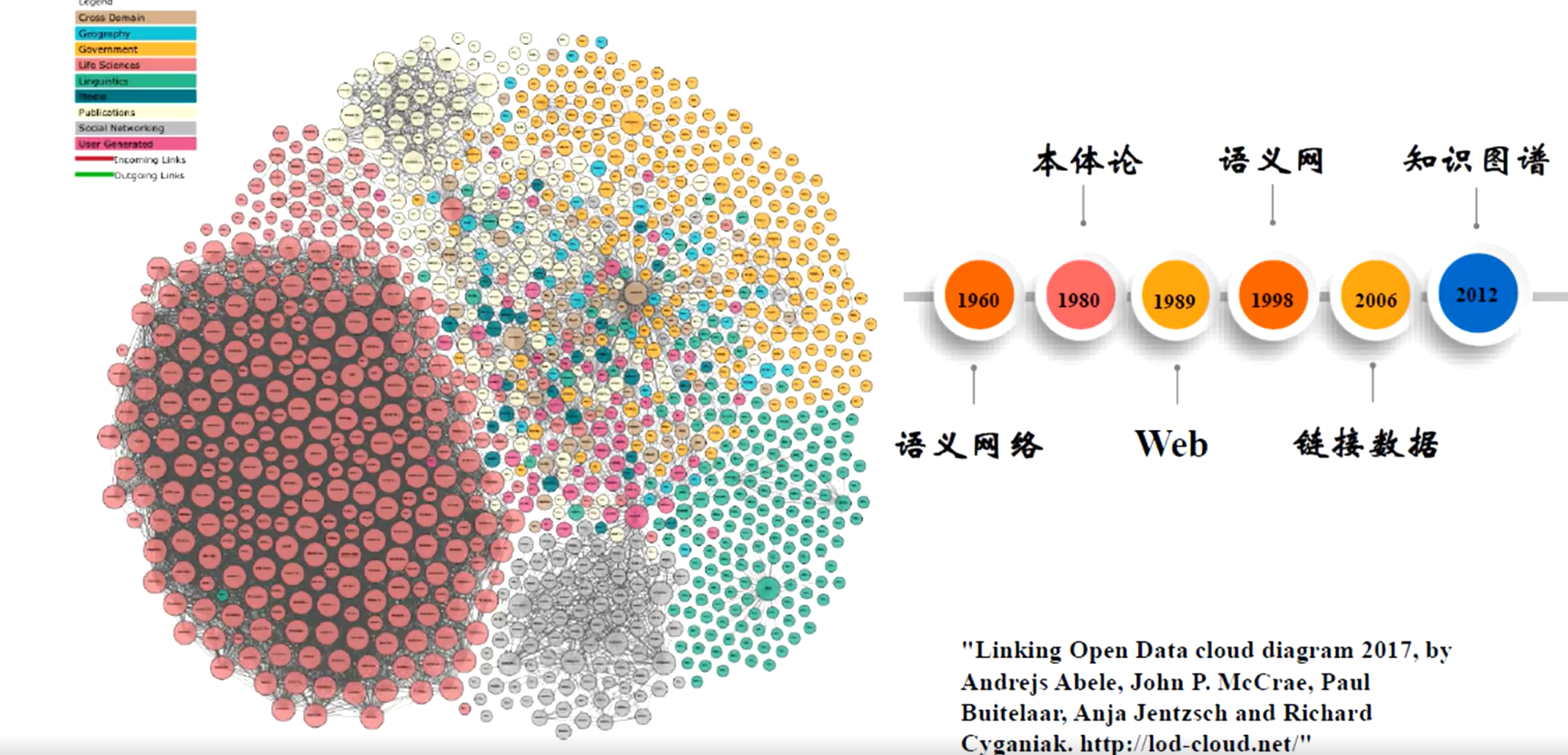
The Linked Open Data Cloud 显示了已以链接数据格式发布的数据集
开放知识图谱
2、KG的本质
Web视角--- 像建立文本之间的超链接一样,建立数据之间的语义链接,并支持语义搜索
NLP视角 ----怎样从文本中抽取语义和结构化数据
KR视角----怎样利用计算机符号来表示和处理知识
AI视 角---怎样利用知识库来辅助理解人的语言
DB视角---用图的方式去存储知识
3、常见的KG

4、KG的技术体系
二、知识的表示与建模
知识图谱的核心在于如何把知识结构化、标准化地表示出来。
1、知识表示的常见方式:
-
三元组 (Triple):
(实体1, 关系, 实体2)
例如(北京, 属于, 中国)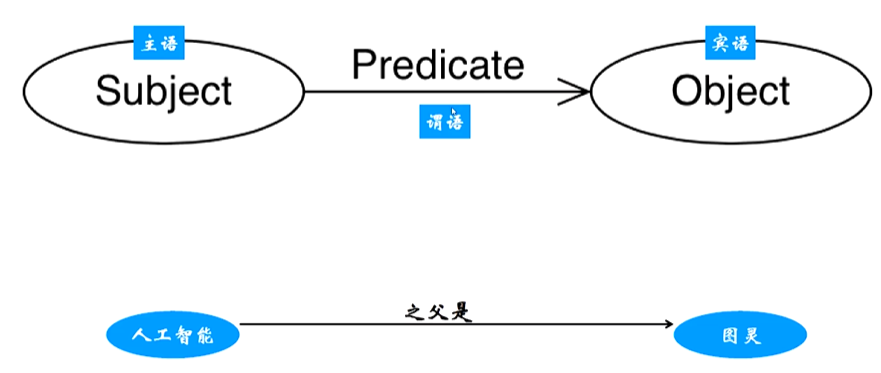
-
属性描述:给实体加上属性,如
(北京, 人口, 2170万) -
本体模型 (Ontology):定义实体类别(类)、属性类型、关系类型等。
2、基于语义网的知识表示框架
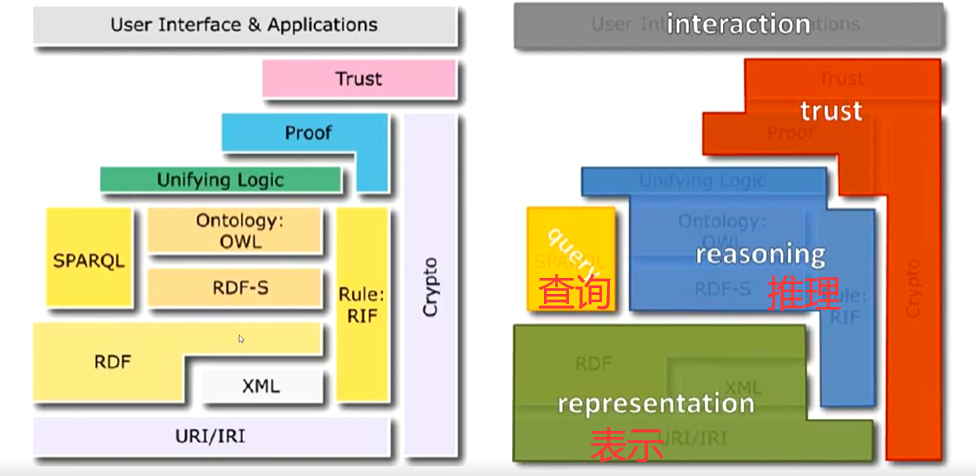
左侧(技术实现视角)
URI/IRI & XML(底层标识与数据格式
RDF & RDF-S(数据语义化):RDF用三元组表达实体及其关系。;RDF-S:RDF Schema,用于定义类和属性。
OWL & RIF(本体与规则):OWL:Web Ontology Language,用于更复杂的本体定义。RIF:Rule Interchange Format,用于规则推理。
SPARQL(查询层):针对 RDF 数据的查询语言。
Unifying Logic & Proof(推理与证明):使用逻辑推理来生成新知识,并给出推理过程的证明。
Trust(信任层):确保数据来源可靠、安全。
右侧(功能抽象视角)
Representation(表示):如何用标准方式表示知识(对应 RDF、OWL)。
Query(查询):如何检索和访问知识(对应 SPARQL)。
Reasoning(推理):如何基于现有知识生成新知识(对应 OWL 推理、RIF 规则)。
Trust(信任):如何保证知识可信、可验证。
3、RDF简介
资源描述框架(Resource Description Framework, RDF),R代表页面,图片、视频等任何具有URI标识符,D标识属性、特征和资源之间的关系,F标识模型、语言和这些描述的语法。在RDF中,知识总是以三元组的形式出现,即每一份知识都可以被分解为:(subject, predicate, object)。

4、基于 Protégé 的知识建模
在构建知识图谱时,除了理解 RDF、OWL 等语义网标准,还需要用实际工具来进行本体(Ontology)建模。
Protégé 是目前最常用、功能最全的开源本体编辑与知识建模工具,由斯坦福大学开发,支持 OWL、RDF(S) 等标准。
(1)什么是 Protégé?
帮助我们定义类、属性、关系,建立本体结构,并生成可机读的 RDF/OWL 文件
三、知识的抽取与挖掘
1、知识抽取来源
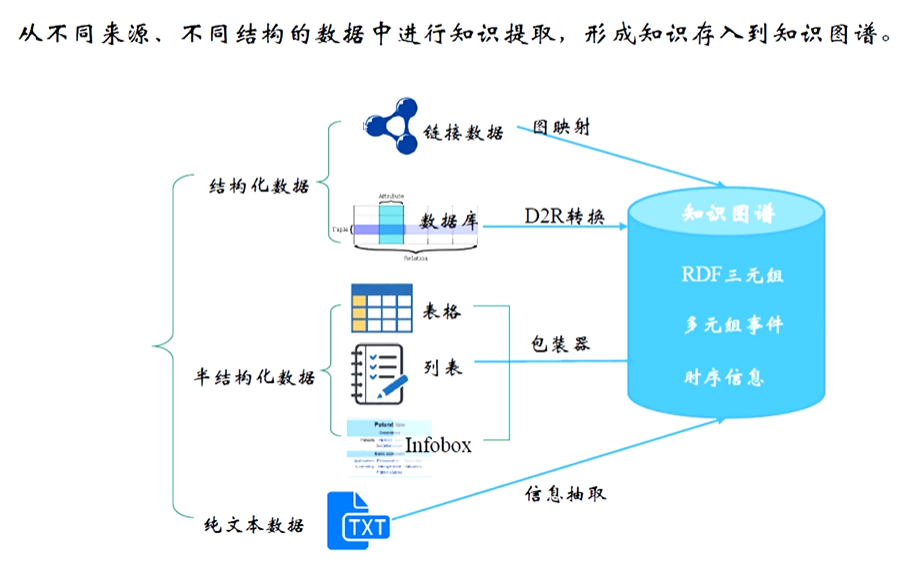
知识抽取是从不同来源的数据中提取出结构化知识(如实体、关系、属性等)的过程,其来源主要包括 Database(数据库)、infoBox(信息框)和 Text(文本)。以下是对这三种来源的详细解析:
(1)抽取来源是Database
数据库是结构化数据的典型存储形式,其本身已具备一定的组织形式(如表格、字段、关系等),知识抽取相对直接。
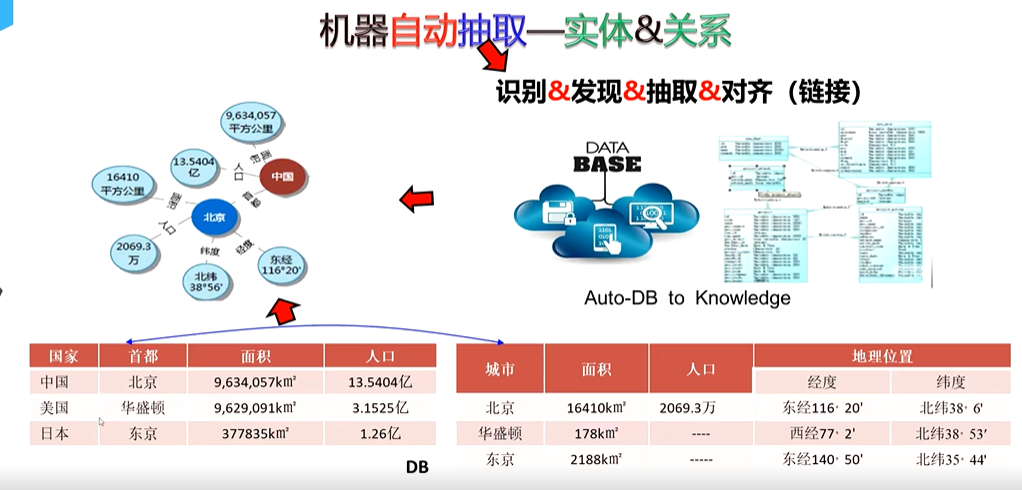
(2)抽取来源是infoBox[信息框】
infoBox 常见于维基百科、百度百科等百科类平台,是对页面主题(如人物、事件、物体)的核心信息进行结构化汇总的模块(通常以 “属性 - 值” 对形式呈现)
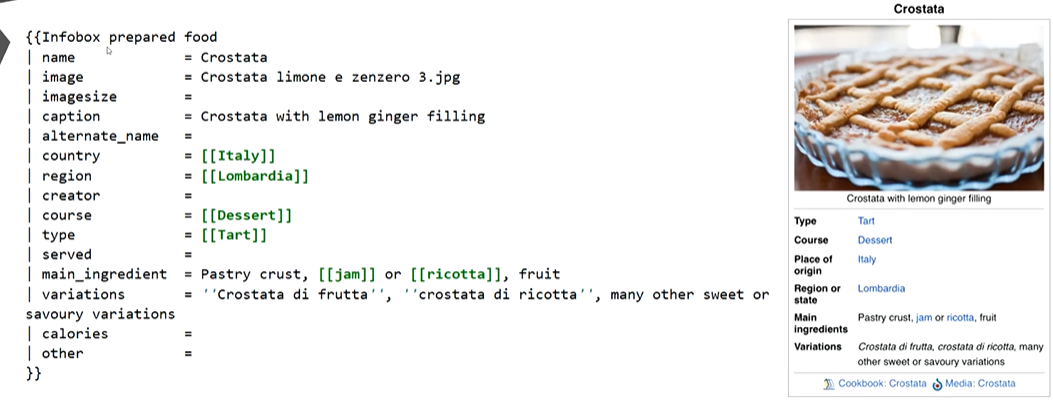
(3)抽取来源是Text
文本是最广泛的知识来源,包括新闻、书籍、论文、社交媒体内容等,形式为非结构化的自然语言。需复杂的自然语言处理技术。
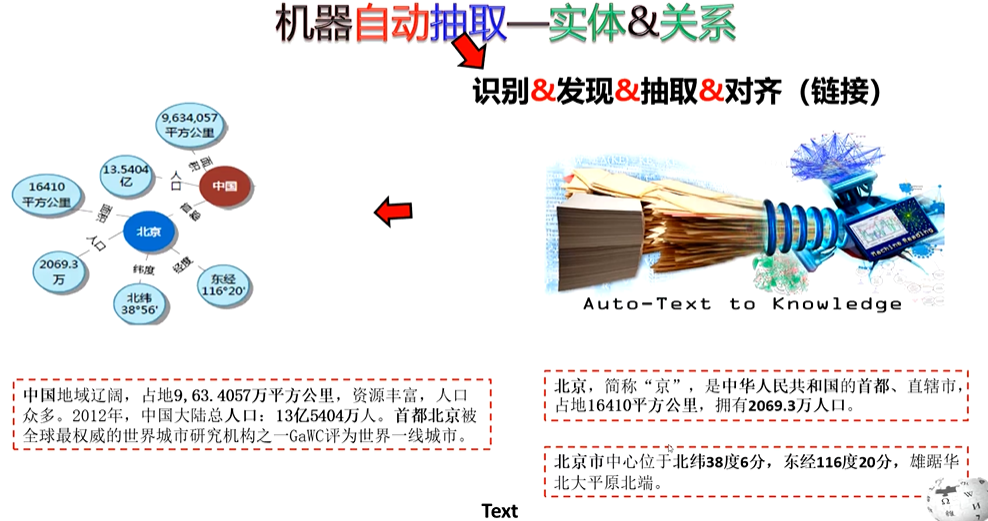
知识抽取相关任务的概述,涵盖命名实体识别、术语抽取、关系抽取三类关键任务
2、任务1-实体识别与抽取(抽取文本中的原子信息元素)
命名实体识别:分检测与分类两步。如检测是从文本(如 “库克非常兴奋” )里找出实体(“库克” );分类则明确实体类别(“库克” 为 “人物” ),聚焦识别文本中具特定意义的实体并归类 。
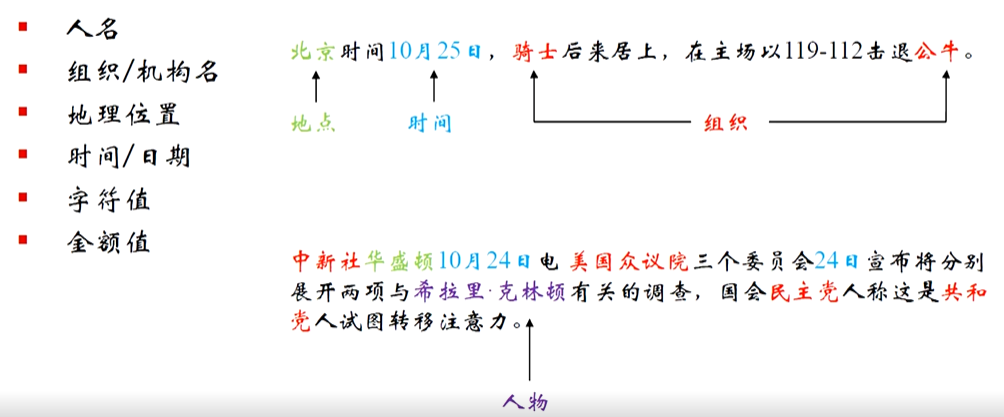
(1)什么是序列标注
实体识别的核心需求是 “定位实体边界” 并 “分类实体类型”。例如,在句子 “李白在长安创作了《静夜思》” 中,需要识别出 “李白”(人名)、“长安”(地名)、“《静夜思》”(作品名)。
由于文本是按顺序排列的词 / 字符序列(如 “李→白→在→长→安→创→作→了→《→静→夜→思→》”),序列标注天然适合这一任务:它为序列中的每个元素分配一个标签,通过标签组合即可确定实体的边界和类型。
最常用的标签体系包括BIO、BIOES等,其中标签由两部分组成:
- 前缀:表示元素在实体中的位置(如 “B” 代表实体开始,“I” 代表实体内部,“O” 代表非实体);
- 后缀:表示实体类型(如 “PER” 代表人名,“LOC” 代表地名,“ORG” 代表组织名)。
(2)序列标注模型(实体识别的实现工具)
-
马尔可夫模型(HMM):
假设标签序列是 “隐藏状态”,文本序列是 “观测状态”,通过 “马尔可夫假设”(当前标签仅依赖前一个标签)和 “观测独立性假设”(当前词仅依赖当前标签)建模。
优点:简单高效;缺点:无法捕捉长距离上下文,假设过于严格。 -
条件随机场(CRF):
直接建模 “标签序列的联合概率”,可利用全局特征(如 “B-ORG” 后更可能接 “I-ORG” 而非 “B-PER”),避免 HMM 的独立性假设。
优点:能处理标签间的依赖关系,效果优于 HMM;缺点:依赖人工特征(如词性、词缀),对复杂语义捕捉不足。 -
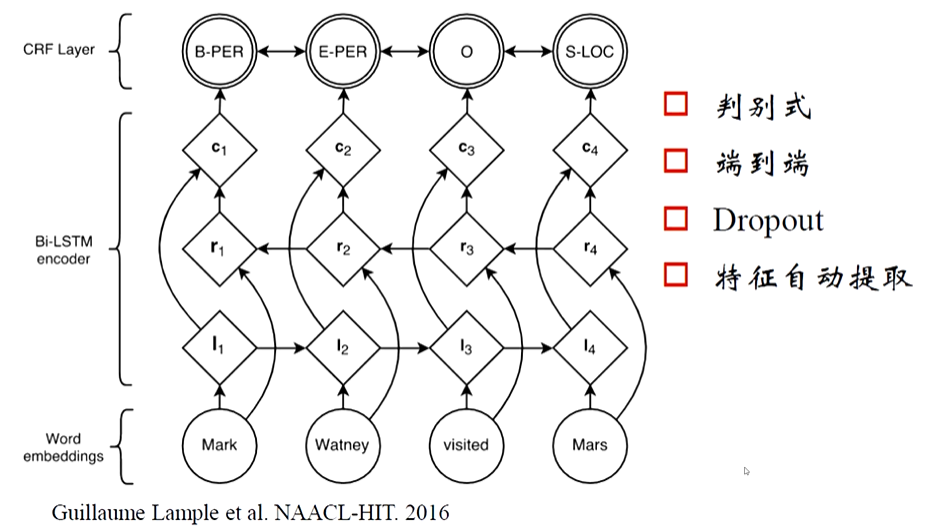
循环神经网络(RNN/LSTM/GRU)+ CRF:
- LSTM/GRU 可捕捉文本的上下文语义(解决 HMM 无法处理长距离依赖的问题);
- 叠加 CRF 层学习标签间的依赖关系(如 “O” 后更可能接 “B-X” 而非 “I-X”)。
优点:端到端学习,无需人工特征;缺点:对超长期依赖的捕捉仍有限。
-
Transformer 模型(如 BERT)+ CRF:
Transformer 通过 “自注意力机制” 可同时捕捉双向长距离上下文,预训练模型(如 BERT)已学习到通用语义知识,微调后在 NER 任务上表现远超传统模型。
优点:语义理解能力强,是当前 SOTA(State-of-the-Art)方法;缺点:计算成本高。
2、任务2-关系抽取
识别实体之间的关系(如“阿司匹林”与“头痛”之间是“治疗”关系)。常用方法包括基于规则的方法、基于机器学习的监督学习方法、半监督学习方法以及远程监督学习方法
(1)基于规则的方法
人工定义一系列语法规则和语义规则,通过匹配这些规则来抽取实体之间的关系。
【EG】在人物关系抽取中,可以定义规则 “[人物 A] 的 [亲属称谓] 是 [人物 B]”,当文本中出现 “张三的父亲是李四” 时,通过匹配该规则,就能抽取到 “张三” 和 “李四” 之间存在父子关系。在金融领域,可以定义 “[公司 A] 收购 [公司 B]” 这样的规则,来抽取企业间的收购关系。
(2)基于机器学习的监督方法
将关系抽取看作一个分类任务,利用标注好的语料(包含实体对及其关系类型)训练分类模型。
【EG】以使用 BERT 模型为例,首先将包含实体对的文本进行预处理,然后输入到预训练的 BERT 模型中获取文本的特征表示,接着在 BERT 模型的输出之上添加一个分类层,通过标注好的实体对关系数据对整个模型进行微调训练。当输入新的文本时,模型就能判断其中实体对的关系。比如输入文本 “苹果公司发布了新款 iPhone 手机”,模型可以判断出 “苹果公司” 和 “新款 iPhone 手机” 之间存在 “生产 / 发布” 关系。
(3)半监督学习方法
结合少量的标注数据和大量的未标注数据进行学习。主要方法包括自训练(self-training)和协同训练(co - training)等。
自训练是先用少量标注数据训练一个初始模型,然后使用该模型对大量未标注数据进行预测,挑选出置信度高的预测结果加入到标注数据集中,再次训练模型,如此迭代;
协同训练是利用数据的不同视图(如文本的句法视图和语义视图),在不同视图上分别训练模型,然后相互提供伪标注数据进行训练。
(4)弱监督学习-远程监督学习方法
利用现有的知识库(如 Freebase、DBpedia 等)自动生成训练数据。
【EG】如果知识库中记录了 “鲁迅” 和 “狂人日记” 之间存在 “创作” 关系,那么在文本中只要出现同时包含 “鲁迅” 和 “狂人日记” 的句子,就自动标注为 “创作” 关系的训练样本,如 “鲁迅写下了经典著作狂人日记”。
3、任务3-事件抽取
从自然语言中抽取出用户感兴趣的事件信息,并以结构化的形式呈现出来,例如事件发生的时间、地点、发生原因、参与者等。


4、工具推荐
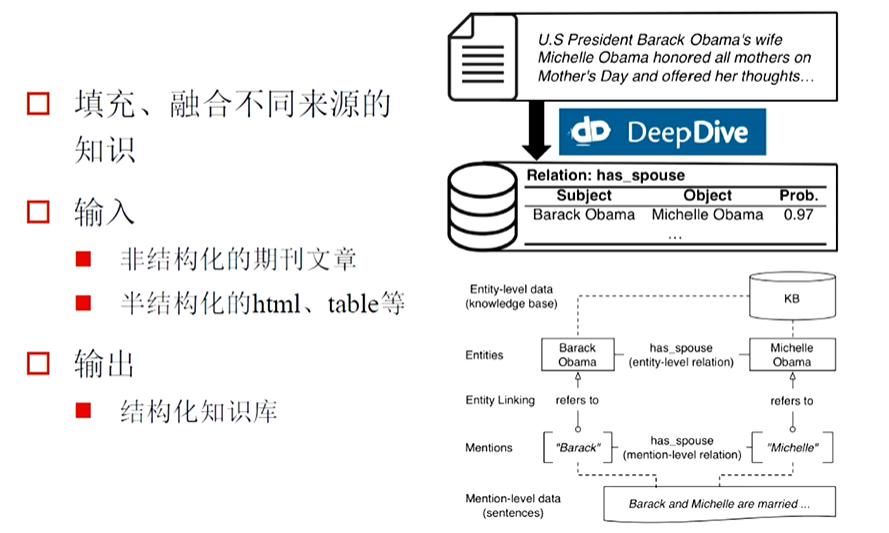
(1)DeepDive
DeepDive 是由斯坦福大学开发的一款用于信息抽取的软件系统,旨在从非结构化或半结构化数据(如文本、表格、网页等)中提取结构化的知识。如:
四、知识的存储与查询
1、存储
(1)图数据库
以 “节点 - 边 - 属性” 的图结构存储知识,节点代表实体,边代表关系,属性可附着于节点或边(如 “人物节点” 的 “年龄” 属性,“好友关系” 的 “认识时间” 属性)。

(2)关系型数据库(RDBMS)
基于二维表结构存储知识,通过外键关联实体与关系(如 “实体表”“关系表” 分别存储实体属性和实体间关联)。
- 实体表:
(用户ID, 姓名, 年龄) - 关系表:
(用户ID1, 关系类型, 用户ID2)(如 “好友”“同事” 关系)
(3)三元组存储
以 “主语(S)- 谓语(P)- 宾语(O)” 三元组形式存储知识(如 “李白 - 朝代 - 唐朝”),专为语义网(Semantic Web)设计,支持 RDF(资源描述框架)和 SPARQL 查询语言。
2、查询技术
知识查询需根据存储方式选择对应的查询语言和技术,核心目标是快速定位实体、关系或事件,并支持复杂关联推理
(1)基于结构化查询语言
SQL:用于关系型数据库,通过SELECT JOIN等语句查询实体属性和简单关系(如 “查询年龄> 30 的用户及其所属部门”)
Cypher:图数据库 Neo4j 的查询语言,以模式匹配为核心,支持多跳关系查询(如 “查询用户 A 的好友的所有同事”):
MATCH (a:User {name: 'A'})-[:FRIEND]->(b)-[:COLLEAGUE]->(c)
RETURN c.nameSPARQL:三元组存储的查询语言,基于 RDF 三元组模式匹配(如 “查询所有属于唐朝的诗人”):
SELECT ?poet WHERE {?poet rdf:type :Poet .?poet :belongsToDynasty :Tang
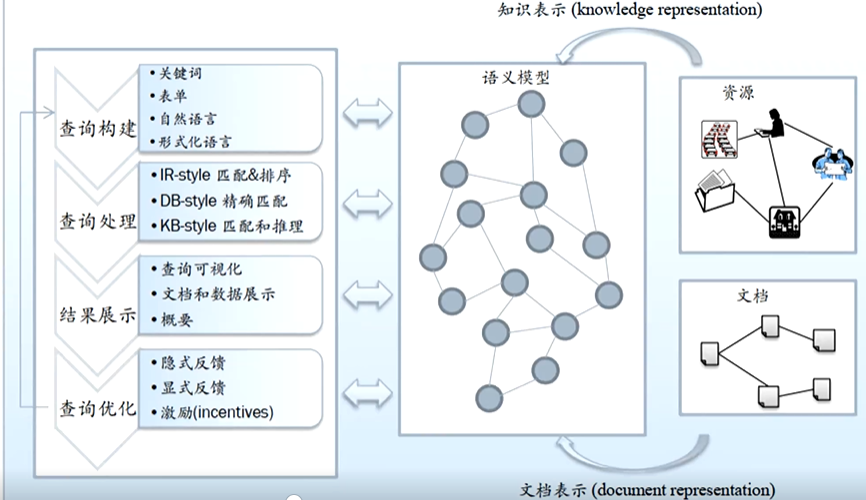
}(2)基于语义检索
语义搜索流程
五、知识的补全与融合
知识的补全与融合是知识图谱构建和维护中的关键环节,旨在解决知识库的不完整性(补全)和多源异构性(融合),提升知识的质量、覆盖率和一致性 。
1、补全方法分类
知识补全(又称知识图谱补全)针对知识库中存在的缺失实体、关系或属性(如 “李白 - 出生地 -?”“?- 发明 - 电灯”),通过推理或预测技术补充这些缺失信息,增强知识的完整性。其核心目标是:基于已有知识,挖掘隐含关联,填补知识图谱中的 “空白”。
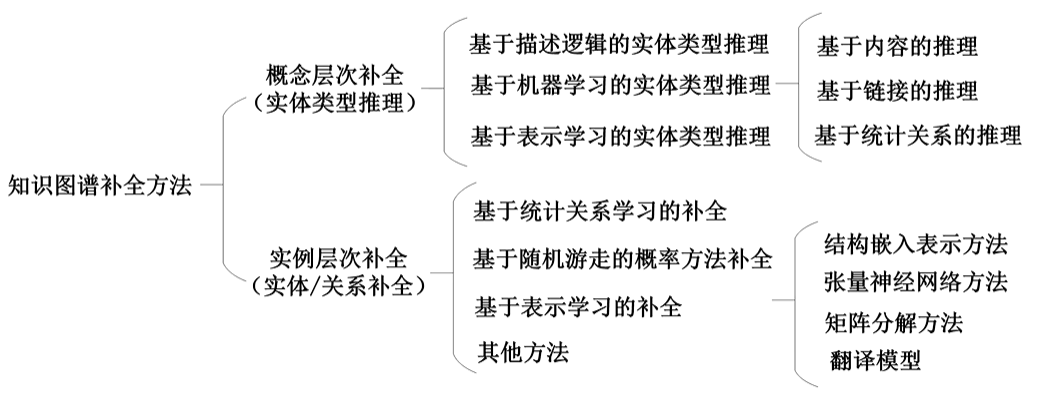
2、知识融合
知识融合(又称知识整合)针对多源异构知识(如不同数据库、文本、表格中的知识),解决其冗余、冲突、异构问题(如 “马云” 在 A 库中是 “阿里巴巴创始人”,在 B 库中是 “阿里巴巴 CEO”;“Apple” 可能指公司或水果),最终形成统一、一致的知识库。其核心目标是:“去重、消歧、对齐”,实现知识的互联互通。
3、挑战

六、举例-KGBuilder