加密流量论文复现:《Detecting DNS over HTTPS based data exfiltration》(下)
在上一篇文章当中,我们已经详细阅读了论文原文,并对其中的一些较难理解的地方加以解释。本篇文章,将对论文最终得到的结论进行简单的论证。

数据收集
首先,由于重新搭建和论文描述的实验环境太过复杂,这里为了简化(实际是太懒了),可以寻找网上的相关数据集。可以查阅到,有关DoH隧道研究较为出名,并且能够搜索到的公开数据集是来着“北海道大学”公开的数据集,具体链接如下:https://eprints.lib.hokudai.ac.jp/dspace/handle/2115/88092

其中有两个数据集,我们下载第一个就ok。因为第二个单纯的都是DoH隧道流量,适用于研究不同软件发出的DoH隧道流量的探测。第一个数据集其实也是包含整理了第二个数据集,其中的l1-total-add.csv 有很多行数据,包含了多个特征值字段和最后的实际标签(DoH或NonDoH),这恰好是可以给我使用的。

大家可以重新翻看之前的文章,其中讲到了研究者刚开始是使用了如下图的24个特征值进行训练模型:
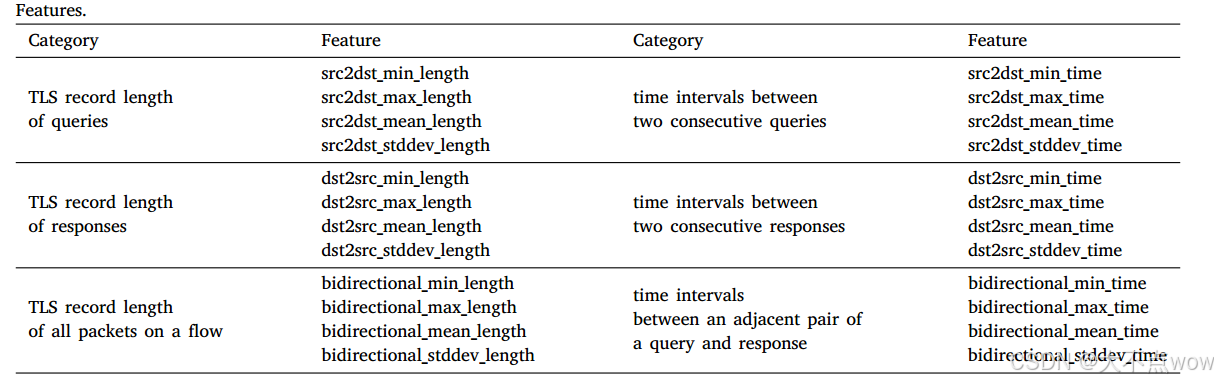
但是,在最后的论证当中发现,由于可能会出现0填充的影响导致有关TLS记录长度的特征无效,所以研究者只用了有关时间的特征进行训练,发现效果依然不错,也是他们最后得到的结论之一。所以,我们可以借此使用l1-total-add.csv 当中的有关时间的特征进行模型训练。虽然,数据集中并没有记录,并且我们也无法根据现有的数据计算出和论文当中一模一样的12个时间特征,但是,我认为数据集当中的16个时间特征仍旧有效,能够保留论文当中12个时间特征的相关特性。
模型训练
论文使用的是sklearn库中的现有模型进行训练,我们也可以同样进行使用。对于研究者使用的增强决策树模型,下面我将会使用GBDT(Gradient Boosting Decision Tree,梯度提升决策树) 进行替代。
废话不多说,代码也不难,下面直接贴代码。
随机森林
- 训练代码
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score, StratifiedKFold
from sklearn.metrics import make_scorer, accuracy_score, precision_score, recall_score, f1_score, roc_auc_score
from sklearn.preprocessing import LabelEncoder
from sklearn.utils import shuffle
from joblib import dump # 用于保存模型
from tqdm import tqdm# 1. 加载数据
print("正在加载数据...")
data = pd.read_csv(r"CIRA-CIC-DoHBrw-2020-and-DoH-Tunnel-Traffic-HKD\l1-total-add.csv")
print(f"数据加载完成,总样本数: {len(data)}")# 2. 清理数据
print("\n正在清理数据...")
data = data.dropna()
print(f"清理后剩余样本数: {len(data)}")# 3. 分离特征和标签
X = data.iloc[:, 18:-1].values
y = data.iloc[:, -1].values # 标签列是字符串( 'DoH'/'NonDoH')# 4. 将字符串标签编码为数值(推荐)
label_encoder = LabelEncoder()
y = label_encoder.fit_transform(y)
print("类别顺序:", label_encoder.classes_)# 5. 打乱数据
print("\n正在打乱数据顺序...")
X, y = shuffle(X, y, random_state=42)# 6. 初始化随机森林模型
print("\n初始化随机森林模型...")
rf_model = RandomForestClassifier(n_estimators=100,max_depth=None,min_samples_split=2,min_samples_leaf=1,random_state=42,verbose=1,n_jobs=-1
)# 7. 定义评估指标
scoring = {'accuracy': make_scorer(accuracy_score),'precision': make_scorer(precision_score, pos_label=0), # 根据实际编码调整'recall': make_scorer(recall_score, pos_label=0),'f1': make_scorer(f1_score, pos_label=0),'roc_auc': make_scorer(roc_auc_score, needs_proba=True)
}# 8. 5折交叉验证
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)# 9. 执行交叉验证(带进度条)
print("\n开始5折交叉验证...")
results = {}
for metric_name in tqdm(scoring, desc="交叉验证进度"):scores = cross_val_score(rf_model, X, y, cv=cv, scoring=scoring[metric_name])results[metric_name] = scores.mean()print(f"{metric_name}: {scores.mean():.4f} (±{scores.std():.4f})")# 10. 输出结果
print("\n平均性能评估:")
for metric, score in results.items():print(f"{metric}: {score:.4f}")# 11. 训练最终模型(在整个数据集上)
print("\n训练最终模型...")
rf_model.fit(X, y)
print("模型训练完成!")# 12. 保存模型
dump(rf_model, 'random_forest_model.joblib')
print("模型已保存为 'random_forest_model.joblib'")
- 验证代码
import numpy as np
import pandas as pd
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, roc_auc_score
from joblib import load
from sklearn.preprocessing import LabelEncoder# 1. 加载数据
print("正在加载数据...")
data = pd.read_csv(r"CIRA-CIC-DoHBrw-2020-and-DoH-Tunnel-Traffic-HKD\l1-total-add.csv")
print(f"数据加载完成,总样本数: {len(data)}")# 2. 清理数据
print("\n正在清理数据...")
data = data.dropna()
print(f"清理后剩余样本数: {len(data)}")# 3. 分离特征和标签
X = data.iloc[:, 18:-1].values
y_true = data.iloc[:, -1].values # 原始标签# 4. 标签编码
label_encoder = LabelEncoder()
y = label_encoder.fit_transform(y_true)
print("类别顺序:", label_encoder.classes_) # 确认0和1分别对应哪个类别# 5. 加载模型
print("\n加载模型...")
model = load('random_forest_model.joblib')
print("模型加载完成!")# 6. 获取预测概率
print("\n进行预测...")
y_proba = model.predict_proba(X)[:, 1] # 正类的概率
y_pred = (y_proba > 0.5).astype(int) # 默认阈值0.5的预测# 7. 识别所有假阳性样本
fp_mask = (y_pred == 1) & (y == 0) # 假阳性条件
fp_indices = np.where(fp_mask)[0] # 假阳性样本的索引print(f"\n发现 {len(fp_indices)} 个假阳性样本:")
print("----------------------------------------")# 8. 打印每个FP样本的详细信息(可选)
# for idx in fp_indices:
# print(f"\n样本索引: {idx}")
# print(f"真实标签: {y_true[idx]} (编码为: {y[idx]})")
# print(f"预测概率: {y_proba[idx]:.6f}")
# print("特征值:")
# print(pd.DataFrame(X[idx].reshape(1, -1),
# columns=data.columns[18:-1]).to_string(index=False))
# print("----------------------------------------")# 9. 假阳性概率分布分析
if len(fp_indices) > 0:print("\n假阳性样本的预测概率统计:")print(pd.Series(y_proba[fp_indices]).describe())
else:print("\n没有发现假阳性样本")# 10. 评估指标
print("\n完整评估指标:")
metrics = {'Accuracy': accuracy_score(y, y_pred),'Precision': precision_score(y, y_pred, pos_label=1),'Recall': recall_score(y, y_pred, pos_label=1),'F1 Score': f1_score(y, y_pred, pos_label=1),'ROC AUC': roc_auc_score(y, y_proba),'False Positives': len(fp_indices),'False Positive Rate': len(fp_indices) / len(y[y == 0])
}
for name, value in metrics.items():print(f"{name}: {value:.6f}" if isinstance(value, float) else f"{name}: {value}")
增强决策树
- 训练代码
import pandas as pd
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.model_selection import cross_val_score, StratifiedKFold
from sklearn.metrics import make_scorer, accuracy_score, precision_score, recall_score, f1_score, roc_auc_score
from sklearn.preprocessing import LabelEncoder
from sklearn.utils import shuffle
from joblib import dump
from tqdm import tqdm# 1. 加载数据
print("正在加载数据...")
data = pd.read_csv(r"CIRA-CIC-DoHBrw-2020-and-DoH-Tunnel-Traffic-HKD\l1-total-add.csv")
print(f"数据加载完成,总样本数: {len(data)}")# 2. 清理数据
print("\n正在清理数据...")
data = data.dropna()
print(f"清理后剩余样本数: {len(data)}")# 3. 分离特征和标签
X = data.iloc[:, 18:-1].values
y = data.iloc[:, -1].values # 标签列是字符串( 'DoH'/'NonDoH')# 4. 将字符串标签编码为数值
label_encoder = LabelEncoder()
y = label_encoder.fit_transform(y)
print("类别顺序:", label_encoder.classes_)# 5. 打乱数据
print("\n正在打乱数据顺序...")
X, y = shuffle(X, y, random_state=42)# 6. 初始化梯度提升树模型(增强决策树)
print("\n初始化梯度提升树模型...")
gb_model = GradientBoostingClassifier(n_estimators=100, # 树的数量(与RF相同)learning_rate=0.1, # 学习率(重要参数)max_depth=3, # 每棵树的最大深度(通常比RF小)min_samples_split=2, # 分裂内部节点所需的最小样本数min_samples_leaf=1, # 叶节点所需的最小样本数max_features='sqrt', # 寻找最佳分割时考虑的特征数random_state=42,verbose=1, # 显示训练进度
)# 7. 定义评估指标
scoring = {'accuracy': make_scorer(accuracy_score),'precision': make_scorer(precision_score, pos_label=0), # 根据实际编码调整'recall': make_scorer(recall_score, pos_label=0),'f1': make_scorer(f1_score, pos_label=0),'roc_auc': make_scorer(roc_auc_score, needs_proba=True)
}# 8. 5折交叉验证
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)# 9. 执行交叉验证(带进度条)
print("\n开始5折交叉验证...")
results = {}
for metric_name in tqdm(scoring, desc="交叉验证进度"):scores = cross_val_score(gb_model, X, y, cv=cv, scoring=scoring[metric_name])results[metric_name] = scores.mean()print(f"{metric_name}: {scores.mean():.4f} (±{scores.std():.4f})")# 10. 输出结果
print("\n平均性能评估:")
for metric, score in results.items():print(f"{metric}: {score:.4f}")# 11. 训练最终模型(在整个数据集上)
print("\n训练最终模型...")
gb_model.fit(X, y)
print("模型训练完成!")# 12. 保存模型
dump(gb_model, 'gradient_boosting_model.joblib')
print("模型已保存为 'gradient_boosting_model.joblib'")
- 验证代码
import numpy as np
import pandas as pd
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, roc_auc_score
from joblib import load
from sklearn.preprocessing import LabelEncoder# 1. 加载数据
print("正在加载数据...")
data = pd.read_csv(r"CIRA-CIC-DoHBrw-2020-and-DoH-Tunnel-Traffic-HKD\l1-total-add.csv")
print(f"数据加载完成,总样本数: {len(data)}")# 2. 清理数据
print("\n正在清理数据...")
data = data.dropna()
print(f"清理后剩余样本数: {len(data)}")# 3. 分离特征和标签
X = data.iloc[:, 18:-1].values
y_true = data.iloc[:, -1].values # 原始标签# 4. 标签编码
label_encoder = LabelEncoder()
y = label_encoder.fit_transform(y_true)
print("类别顺序:", label_encoder.classes_) # 确认0和1分别对应哪个类别# 5. 加载模型
print("\n加载模型...")
model = load('gradient_boosting_model.joblib')
print("模型加载完成!")# 6. 获取预测概率
print("\n进行预测...")
y_proba = model.predict_proba(X)[:, 1] # 正类的概率
y_pred = (y_proba > 0.5).astype(int) # 默认阈值0.5的预测# 7. 识别所有假阳性样本
fp_mask = (y_pred == 1) & (y == 0) # 假阳性条件
fp_indices = np.where(fp_mask)[0] # 假阳性样本的索引print(f"\n发现 {len(fp_indices)} 个假阳性样本:")
print("----------------------------------------")# 8. 打印每个FP样本的详细信息(可选)
# for idx in fp_indices:
# print(f"\n样本索引: {idx}")
# print(f"真实标签: {y_true[idx]} (编码为: {y[idx]})")
# print(f"预测概率: {y_proba[idx]:.6f}")
# print("特征值:")
# print(pd.DataFrame(X[idx].reshape(1, -1),
# columns=data.columns[18:-1]).to_string(index=False))
# print("----------------------------------------")# 9. 假阳性概率分布分析
if len(fp_indices) > 0:print("\n假阳性样本的预测概率统计:")print(pd.Series(y_proba[fp_indices]).describe())
else:print("\n没有发现假阳性样本")# 10. 评估指标
print("\n完整评估指标:")
metrics = {'Accuracy': accuracy_score(y, y_pred),'Precision': precision_score(y, y_pred, pos_label=1),'Recall': recall_score(y, y_pred, pos_label=1),'F1 Score': f1_score(y, y_pred, pos_label=1),'ROC AUC': roc_auc_score(y, y_proba),'False Positives': len(fp_indices),'False Positive Rate': len(fp_indices) / len(y[y == 0])
}
for name, value in metrics.items():print(f"{name}: {value:.6f}" if isinstance(value, float) else f"{name}: {value}")
逻辑回归
- 训练代码
import numpy as np
import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score, StratifiedKFold
from sklearn.metrics import make_scorer, accuracy_score, precision_score, recall_score, f1_score, roc_auc_score
from sklearn.preprocessing import LabelEncoder, StandardScaler
from sklearn.utils import shuffle
from joblib import dump
from tqdm import tqdm# 1. 加载数据
print("正在加载数据...")
data = pd.read_csv(r"CIRA-CIC-DoHBrw-2020-and-DoH-Tunnel-Traffic-HKD\l1-total-add.csv")
print(f"数据加载完成,总样本数: {len(data)}")# 2. 清理数据
print("\n正在清理数据...")
data = data.dropna()
print(f"清理后剩余样本数: {len(data)}")# 3. 分离特征和标签
X = data.iloc[:, 18:-1].values
y = data.iloc[:, -1].values # 标签列是字符串( 'DoH'/'NonDoH')# 4. 将字符串标签编码为数值
label_encoder = LabelEncoder()
y = label_encoder.fit_transform(y)
print("类别顺序:", label_encoder.classes_)# 5. 数据标准化(对LR非常重要)
print("\n正在进行数据标准化...")
scaler = StandardScaler()
X = scaler.fit_transform(X)# 6. 打乱数据
print("\n正在打乱数据顺序...")
X, y = shuffle(X, y, random_state=42)# 7. 初始化逻辑回归模型
print("\n初始化逻辑回归模型...")
lr_model = LogisticRegression(penalty='l2', # 正则化类型(L2正则)C=1.0, # 正则化强度的倒数(越小正则化越强)solver='lbfgs', # 优化算法(适合中小数据集)max_iter=1000, # 最大迭代次数random_state=42,verbose=1, # 显示训练日志n_jobs=-1 # 使用所有CPU核心
)# 8. 定义评估指标
scoring = {'accuracy': make_scorer(accuracy_score),'precision': make_scorer(precision_score, pos_label=0), # 根据实际编码调整'recall': make_scorer(recall_score, pos_label=0),'f1': make_scorer(f1_score, pos_label=0),'roc_auc': make_scorer(roc_auc_score, needs_proba=True)
}# 9. 5折交叉验证
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)# 10. 执行交叉验证(带进度条)
print("\n开始5折交叉验证...")
results = {}
for metric_name in tqdm(scoring, desc="交叉验证进度"):scores = cross_val_score(lr_model, X, y, cv=cv, scoring=scoring[metric_name])results[metric_name] = scores.mean()print(f"{metric_name}: {scores.mean():.4f} (±{scores.std():.4f})")# 11. 输出结果
print("\n平均性能评估:")
for metric, score in results.items():print(f"{metric}: {score:.4f}")# 12. 训练最终模型(在整个数据集上)
print("\n训练最终模型...")
lr_model.fit(X, y)
print("模型训练完成!")# 13. 保存模型和预处理对象
dump(lr_model, 'logistic_regression_model.joblib')
dump(scaler, 'scaler.joblib')
dump(label_encoder, 'label_encoder.joblib')
print("模型和预处理对象已保存")
- 验证代码
import numpy as np
import pandas as pd
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, roc_auc_score
from joblib import load
from sklearn.preprocessing import LabelEncoder# 1. 加载数据
print("正在加载数据...")
data = pd.read_csv(r"CIRA-CIC-DoHBrw-2020-and-DoH-Tunnel-Traffic-HKD\l1-total-add.csv"))
print(f"数据加载完成,总样本数: {len(data)}")# 2. 清理数据
print("\n正在清理数据...")
data = data.dropna()
print(f"清理后剩余样本数: {len(data)}")# 3. 分离特征和标签
X = data.iloc[:, 18:-1].values
y_true = data.iloc[:, -1].values # 原始标签# 4. 加载预处理对象
print("\n加载模型...")
scaler = load('scaler.joblib') # 加载训练时的标准化器
label_encoder = load('label_encoder.joblib') # 加载训练时的标签编码器
model = load('logistic_regression_model.joblib') # 加载模型
print("模型加载完成!")# 5. 应用预处理
X = scaler.transform(X) # 使用训练时的均值和方差标准化
y = label_encoder.transform(y_true) # 使用训练时的编码规则# 6. 获取预测概率
print("\n进行预测...")
y_proba = model.predict_proba(X)[:, 1] # 正类的概率
y_pred = (y_proba > 0.5).astype(int) # 默认阈值0.5的预测# 7. 识别所有假阳性样本
fp_mask = (y_pred == 1) & (y == 0) # 假阳性条件
fp_indices = np.where(fp_mask)[0] # 假阳性样本的索引print(f"\n发现 {len(fp_indices)} 个假阳性样本:")
print("----------------------------------------")# 8. 打印每个FP样本的详细信息(可选)
# for idx in fp_indices:
# print(f"\n样本索引: {idx}")
# print(f"真实标签: {y_true[idx]} (编码为: {y[idx]})")
# print(f"预测概率: {y_proba[idx]:.6f}")
# print("特征值:")
# print(pd.DataFrame(X[idx].reshape(1, -1),
# columns=data.columns[18:-1]).to_string(index=False))
# print("----------------------------------------")# 9. 假阳性概率分布分析
if len(fp_indices) > 0:print("\n假阳性样本的预测概率统计:")print(pd.Series(y_proba[fp_indices]).describe())
else:print("\n没有发现假阳性样本")# 10. 评估指标
print("\n完整评估指标:")
metrics = {'Accuracy': accuracy_score(y, y_pred),'Precision': precision_score(y, y_pred, pos_label=1),'Recall': recall_score(y, y_pred, pos_label=1),'F1 Score': f1_score(y, y_pred, pos_label=1),'ROC AUC': roc_auc_score(y, y_proba),'False Positives': len(fp_indices),'False Positive Rate': len(fp_indices) / len(y[y == 0])
}
for name, value in metrics.items():print(f"{name}: {value:.6f}" if isinstance(value, float) else f"{name}: {value}")结果分析
- 5折交叉验证平均性能
| 指标 | 随机森林 | 增强决策树 | 逻辑回归 |
|---|---|---|---|
| 准确率(accuracy) | 0.9891 | 0.9490 | 0.8701 |
| 精确度(precision) | 0.9895 | 0.9587 | 0.8173 |
| 召回率(recall) | 0.9734 | 0.8651 | 0.7273 |
| f1 | 0.9814 | 0.9095 | 0.7674 |
| roc_auc | 0.9982 | 0.9843 | 0.8978 |
这么一看,发现在模型效果上,随机森林>增强决策树>逻辑回归,这也恰好符合论文得出的结果。
- 模型在整体数据集上的性能
- 随机森林

- 增强决策树

- 逻辑回归

- 随机森林
整体效果上,还是符合论文的结果。但是,论文最后的结论指出,逻辑回归模型虽然效果较差,但是其假阳的阈值比较低,从而能够作为提前发现DoH隧道流量的有效依据。可是,在本次实验当中,发现反而还是增强决策树的假阳样本的阈值普遍较低,其次才是逻辑回归模型,最后是随机森林模型,我估计应该是参数的不同,或者是研究者选择的增强决策树的模型不同导致的(这里我没有进行参数优化,也没有试一试多个增强决策树模型,因为比较懒,哈哈哈)。不管怎么说,模型效果仍然就是随机森林>增强决策树>逻辑回归,并且效果低下的原因也是因为假阳率太高导致,最终随机森林模型训练的f1分数也高达99.9%,这也证实了使用不同的时间特征仍然可以对DoH隧道流量和良性流量能够有较好的区分。
复现实验整体还是比较成功的!!要是大家有更好的复现结果,欢迎随时在评论区与我进行讨论!!
