《论文阅读》传统CoT方法和提出的CoT Prompting的区分
论文:
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
作者对传统CoT方法和本文提出的CoT Prompting的区分。
1. 传统方法的局限性
(1) 基于微调的CoT(Rationale-Augmented Training)
- 实现方式:需人工标注大量〈输入,推理链,输出〉三元组,然后微调模型
# 训练数据示例(需人工编写) {"input": "小明有5个苹果,吃了2个,还剩几个?","rationale": "初始5个 - 吃掉2个 = 剩余3个", # 人工撰写成本高"output": "3" } - 限制:
- 标注成本:撰写高质量推理链比单纯标注答案昂贵10-20倍(论文数据)
- 泛化性差:每个新任务都需要重新微调
(2) 传统Few-Shot Prompting
- 典型结构(Brown et al., 2020):
输入: "3个苹果每个2元,总价多少?" 输出: "6元"输入: "火车2小时行驶240公里,时速多少?" 输出: "120公里/小时"输入: "问题..." # 测试样本 - 缺陷:
- 仅展示输入-输出对,缺乏推理过程示范
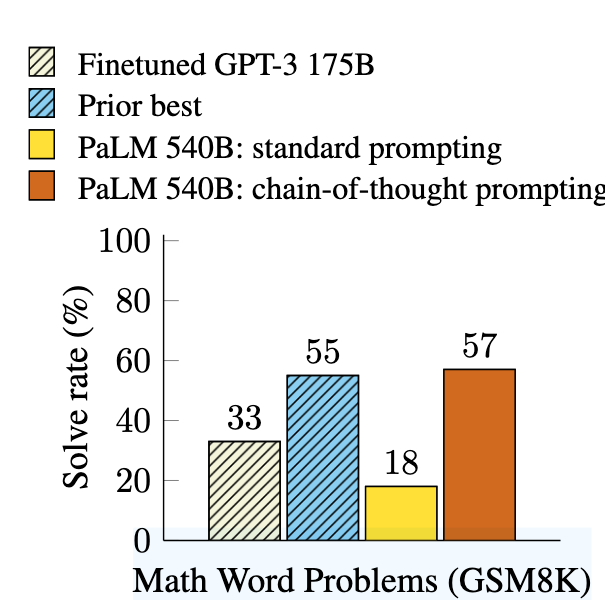
- 在GSM8K数学题测试中,540B参数模型准确率仅17%(对比CoT Prompting的56%)
2. 本文创新:Chain-of-Thought Prompting
核心突破
通过提示工程而非微调,直接激发模型的推理能力:
输入: "小明有5个苹果,吃了2个,还剩几个?"
思考: 初始5个 - 吃掉2个 = 剩余3个
输出: "3"输入: "一个书包原价80元打7折,现价多少?"
思考: 80元 × 0.7 = 56元
输出: "56元"输入: "问题..." # 测试样本
技术差异
| 维度 | 传统微调CoT | 本文CoT Prompting |
|---|---|---|
| 是否需要训练数据 | 需大量标注三元组 | 仅需3-5个示范样例 |
| 模型修改 | 需任务特定微调 | 同一模型参数处理所有任务 |
| 推理链来源 | 依赖标注数据 | 模型自动生成 |
| 计算成本 | 高(每次任务需微调) | 零(仅推理) |
3. 为什么Prompting版CoT更优?
(1) 数据效率
- 传统方法:需5000+标注样本才能微调出可用模型(Cobbe et al., 2021)
- 本文方法:仅需8个示范样例即可达到SOTA(GSM8K上56%准确率)
(2) 涌现能力
-
参数规模效应:当模型 > 100B参数时,CoT Prompting效果突然提升(见论文中的图2,如下)
-
传统Few-Shot:模型增大后性能提升平缓
(3) 任务泛化
- 统一框架:同一组提示模板可处理算术/常识/符号推理
- 传统方法:每类任务需独立微调
4. 案例验证
GSM8K数学题测试:
- 标准Prompting:
输入: "农场有15只鸡和8头牛,共有多少条腿?" 输出: "46" # 错误(未展示计算过程) - CoT Prompting:
输入: "农场有15只鸡和8头牛,共有多少条腿?" 思考: 鸡腿=15×2=30,牛腿=8×4=32,总腿数=30+32=62 输出: "62" # 正确
结果:准确率从17% → 56%(540B参数模型)
5. 本质创新点
作者并非发明CoT概念,而是发现了:
- 无需微调:通过精心设计的提示模板即可激发模型固有推理能力
- 规模效应:超大模型(>100B)在少量示范下能自主生成高质量推理链
- 通用接口:〈输入,思考链,输出〉三元组作为跨任务统一范式
这种方法的革命性在于:将推理能力从模型训练阶段解耦,转变为提示工程问题,使单个预训练模型能零样本处理复杂推理任务。