论文reading学习记录7 - daily - ViP3D
文章目录
- 前言
- 一、题目和摘要
- 二、引言
- 三、相关工作
- 四、方法
- 五、训练
前言
开冲,清华大学的,带HDmap的端论文,用的Query,和UniAD一样。
一、题目和摘要
ViP3D: End-to-end Visual Trajectory Prediction via 3D Agent Queries
ViP3D:通过三维智能体查询进行端到端视觉轨迹预测
注意,这篇论文要输入HDMap
PS:Query 是 Transformer 框架里的“查询向量”
Agent Query 的核心想法是:
给场景中每一个潜在的交通参与者分配一个可学习的 Query 向量(就像是给每个人一个“跟踪编号”)
这个向量在网络计算时会主动去从传感器特征(比如图像特征)里抓取与自己对应的那个人/车的相关信息。
它和传统的密集 BEV 特征不一样:
传统:先生成一张密密麻麻的地图,再用算法去找人 → 中间有 NMS、关联匹配等不可微步骤。
Agent Query:一开始就假设“我有 N 个对象”,每个对象一个 Query,全程跟踪 → 不需要 NMS 或匹配,过程可微。
感知和预测如果分离,预测作为下游模块,只能从感知模块接收有限的信息。更糟糕的是,感知模块的误差会传播和累积,对预测结果产生不利影响。
在这项工作中,我们提出了ViP3D,这是一种基于查询的视觉轨迹预测管道,它利用原始视频中的丰富信息直接预测场景中代理的未来轨迹。ViP3D采用稀疏代理查询来检测、跟踪和分析,并在整个管道中进行预测,使其成为第一种完全可微的基于视觉的轨迹预测方法。
与使用历史特征图和轨迹不同,来自先前时间戳的有用信息被编码在Agent Queries中,这使得ViP3D成为一种简洁的流式预测方法。此外,在nuScenes数据集上的大量实验结果表明,ViP3D在基于视觉的预测方面比传统管道和之前的端到端模型具有更强的性能。
二、引言
感知和预测是现有自动驾驶软件管道中的两个独立模块,它们之间的接口通常被定义为手工挑选的几何和语义特征,如历史目标轨迹、目标类型、目标大小等。
缺点:导致可用于轨迹预测的有用感知信息的丢失。例如,尾灯和刹车灯指示车辆的意图,行人的头部姿势和身体姿势则表明他们的注意力。
基于激光雷达的轨迹预测的端到端模型缺点:
(1)无法利用来自相机的丰富细粒度视觉信息;
(2)这些模型使用卷积特征图作为帧内和帧间的中间表示,因此受到不可微操作的影响,如对象解码中的非最大抑制和多对象跟踪中的对象关联。
为了解决这些缺点,我们提出了一种新的管道,该管道利用以查询为中心的模型设计来预测未来的轨迹,称为ViP3D(通过3D目标查询进行视觉轨迹预测)。
如何做:ViP3D消耗来自周围摄像机和高清地图的多视图视频,并以端到端和简洁的流式方式进行代理级未来轨迹预测,如图1所示。

ViP3D使用3D目标查询作为流水线的主线,从原始视频帧输入中实现端到端的未来轨迹预测。这种新颖的设计通过有效地利用细粒度的视觉信息(如车辆的转向信号)来提高轨迹预测性能。
具体而言,ViP3D利用3D代理查询作为整个管道的接口,其中每个查询最多可以mapping到环境中的一个目标。
在每个时间步,查询从多视图图像中聚合视觉特征,学习代理的时间动态,对代理之间的关系进行建模,并最终为每个代理生成可能的未来轨迹。随着时间的推移,3D代理查询被保存在一个内存库中,可以对其进行初始化、更新和丢弃,以跟踪环境中的代理。
此外,与以前利用历史代理轨迹和来自多个历史帧的特征图的预测方法不同,ViP3D只使用来自一个先前时间戳的3D代理查询和来自当前时间戳的传感器特征,使其成为一种简洁的流式方法。
三点核心贡献:
- ViP3D是第一种完全可微分的基于视觉的方法,用于预测自动驾驶目标的未来轨迹。而不是使用手工挑选的特征,像是历史轨迹和目标大小,ViP3D利用了原始图像中丰富而精细的视觉特征,这些特征对轨迹预测任务很有用。
- ViP3D以3D Agent Queries为接口,显式地对目标级检测、跟踪和预测进行建模,使其具有可解释性和可调试性。
- 我们实验最jb屌
三、相关工作
目前端到端的痛点:它们都依赖于BEV特征图或热图作为中间表示,这导致从密集特征图到实例级特征时不可避免的不可微操作,例如检测中的非最大抑制(NMS)和跟踪中的关联。
我们牛逼,HDmap,把稀疏目标查询作为表示,大大提高了可微性和可解释性。真的有用吗?
从密集特征图 → 实例级信息,一般会经历两个关键步骤:
检测里的 NMS(非最大抑制)
检测会生成一堆可能的框,然后 NMS 会把重叠度高的框合并掉,只保留一个最可能的。
这个过程是基于“比较大小、硬决策”的,不可导(即在梯度反传时没法平滑计算)。
跟踪里的关联
跟踪要把“这一帧的车”和“下一帧的车”对应起来,这通常用匈牙利算法等匹配方法,也属于硬匹配,不可导。
四、方法
ViP3D利用以查询为中心的模型设计。
被跟踪的Agent Queries可能包含许多有用的视觉信息,包括目标的运动动力学和视觉特征。
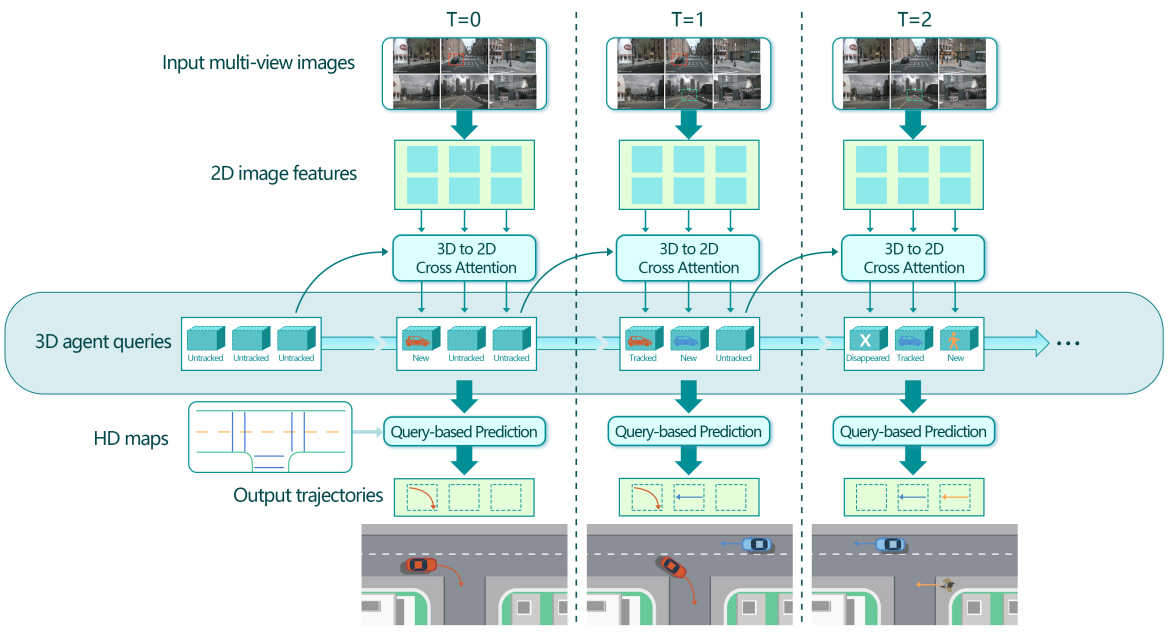
感知:
输入:多视图cam
输出:跟踪agent query集合,这包含许多视觉信息,包括agent的运动特性和视觉特征
预测:
输入:跟踪query和HDmap
输出:agent的未来轨迹。
初始的3D agent query更新和丢弃,在一个query存储库里完成。
模型介绍:这里提取图像用的是ResNet50和FPN,不是ViT系列。然后用相机内参和外参矩阵把3D查询参考点映射到图像的2D坐标上,然后将上面得到的向量作为Q,图像特征L,经过W映射,得到三个QKV矩阵,然后计算跨注意力,最后经过一个带层归一化的两层感知机FFN,更新agent query。
作者设计了两个query来更新和移除agent,一个是匹配query,一个是空query。如果出现一个未匹配query,说明是新出现的agent,如果一个agent消失了,就分配一个未匹配且空的标签,留待后用。对于匹配query,那就说明还在视野里,正在处理。
针对二分匹配,使用了一个query解码器输出每个query的中心坐标,损失函数有类别损失和坐标回归损失,即bbox的L1损失。
Query存储库是一个单进单出的队列,大小为S,仅在每个query和它的历史状态之间进行注意力计算,没有多agent交互,每个query对应一个agent。
以往的轨迹预测模型分为三部分,agent编码器,地图编码器和轨迹解码器。
agent编码器:基于查询的检测和跟踪输出被跟踪的agent查询,这相当于agent编码器的输出。因此,基于查询的预测模块仅由地图编码器和轨迹解码器组成
地图编码器:采用VectorNet。
轨迹解码器:框架级设计,基于回归的方法(Regression-based)、基于目标的方法(Goal-based)、基于热图的方法(Heatmap-based)都能用。
五、训练
模型的loss是联合训练的,包括前面的分类和坐标回归loss。提出了一个新指标,EPA,端到端预测精度。数据集是nuscenes。
这里提到一个trick,就是把agent的最后一个位置作为原始值和方向作为y轴,可以使预测模型集中于未来模态预测,而不是坐标变换。