GPT OSS 双模型上线,百度百舸全面支持快速部署
GPT OSS 是 OpenAI 推出的重量级开放模型,专为强推理能力、智能体任务及多样化开发场景设计,标志着大模型在开放性与实用性上的重要突破。
该系列包含两款高性能模型:参数规模为 117B 的 GPT‑OSS‑120B 和 21B 的 GPT‑OSS‑20B。二者皆采用 MoE 架构,并在 MoE 权重上创新性地使用 4‑bit 量化方案 MXFP4,显著降低资源占用,同时实现更高效的推理速度。得益于更少的激活参数,模型在保持强大性能的同时,具备更低的部署成本和更高的响应效率。
目前,百度百舸平台已经同步支持这 2 款模型的快速部署,为企业提供一站式 AI 服务,实现大模型落地「快稳省」的要求。
当前,百度百舸的推理服务支持部署 LLM、MLLM、VLA 等多种模型的高效推理,广泛服务于线教育、AIGC、医疗、具身智能等行业客户,助力客户实现推理业务的大规模、高稳定性运行。
推理服务快速部署流程
登录百度百舸·AI 异构计算平台,在「快速开始」找到 GPT-OSS-20B 模型。
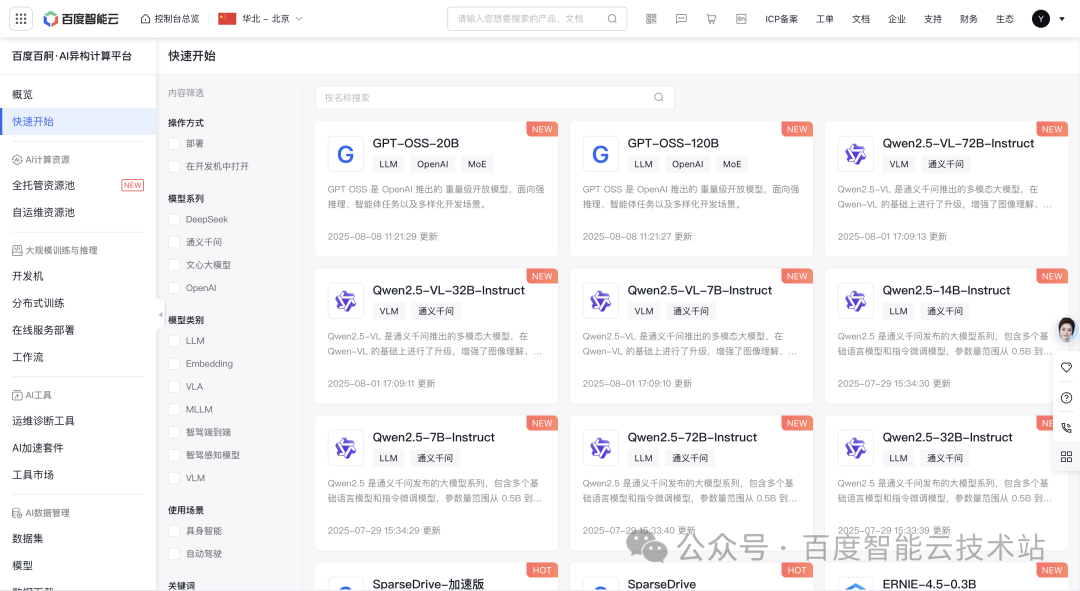
点击模型卡片的「一键部署」启动模型部署流程。
目前 GPT‑OSS 系列模型支持 vLLM 推理加速方式。百度百舸平台已集成 vLLM 推理加速框架,并会根据模型特性(例如,部署 GPT‑OSS‑20B 推荐配置为 1 卡 GPU、12 核 CPU、36GB 内存)智能推荐最优资源配置,用户可按需调整。
点击【确定】即可一键部署到百度百舸平台。
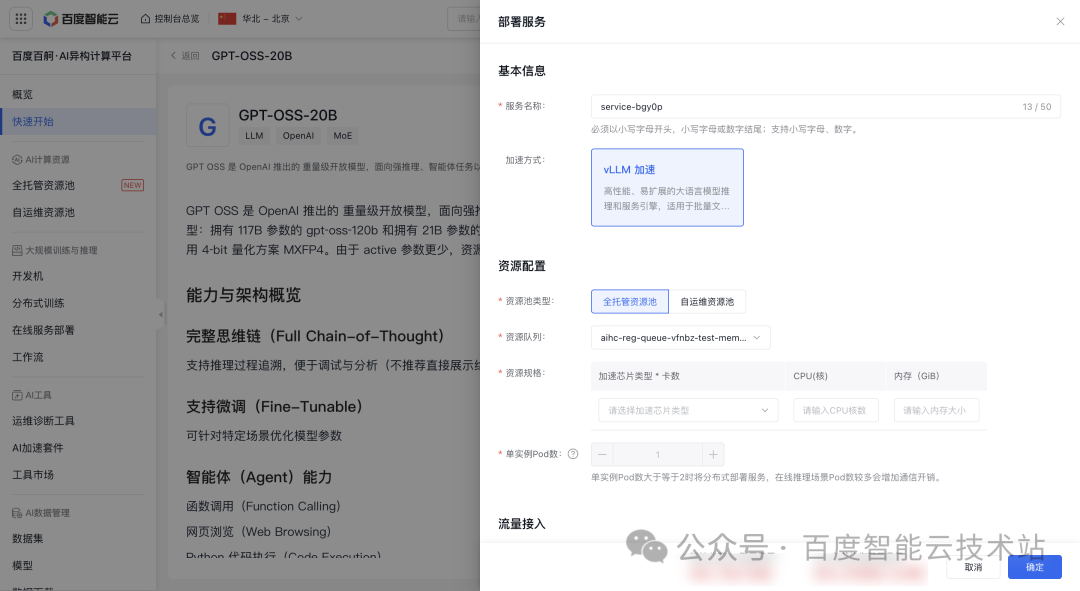
部署服务时,可以使用「云原生网关」接入流量,支持查看 Token 用量监控、消费者鉴权、流量控制等功能,实现业务的高效、安全运营。
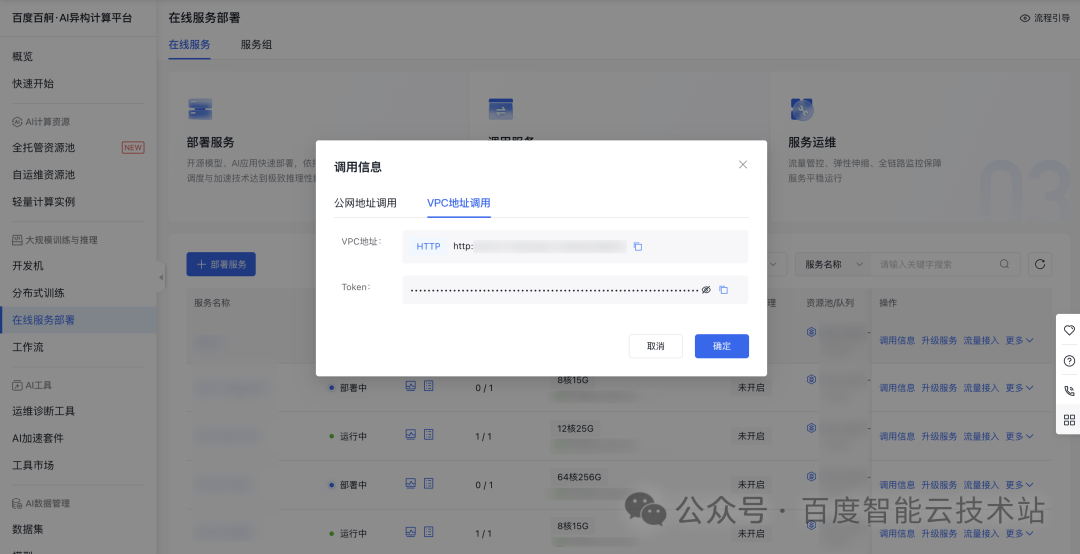
部署成功后,可以通过「在线服务」列表获取服务请求地址和 Token 调用信息,快速接入应用。
百度百舸·AI 异构计算平台,是面向大模型训推一体化的基础设施,提供领先的 AI 工程加速能力,从资源准备、模型开发、模型训练到模型部署,为 AI 工程全周期提供丰富特性和极致易用体验。