ETL流程详解:从概念到实战案例一次讲透
ETL流程详解:从概念到实战案例一次讲透
很多企业在上了两三套系统后,都会遇到一个尴尬的事——数据对不上。销售部门从CRM系统里看到的客户信息,和财务部门从ERP系统里调出来的完全不一致;运营要做个月度报表,需要从五六个不同的数据库里手工导数据,拼拼凑凑才能出个像样的分析结果。这种情况下,ETL就成了救命稻草。
作为一个在数据集成领域摸爬滚打了十多年的老兵,我见过太多企业因为数据孤岛问题焦头烂额,也亲手帮助不少公司通过合理的ETL设计,让原本混乱的数据变得井井有条。今天就来聊聊ETL这个话题,从基础概念到实际应用,争取一次性给大家讲透。
ETL到底是什么?为什么企业都在用
ETL是Extract(提取)、Transform(转换)、Load(加载)三个英文单词的缩写,说白了就是把数据从一个地方搬到另一个地方的过程。但这个"搬运"可不是简单的复制粘贴,而是要经过精心的处理。
- Extract(提取):从各种数据源把需要的数据拉出来,可能是Oracle数据库、MySQL、Excel表格,甚至是API接口返回的JSON数据。
- Transform(转换):对提取出来的数据进行清洗、格式统一、逻辑计算等处理。比如把"北京市"和"北京"统一成一个标准格式,或者根据业务规则计算出客户的风险等级。
- Load(加载):把处理好的数据写入目标系统,通常是数据仓库、数据湖或者业务系统的数据库。
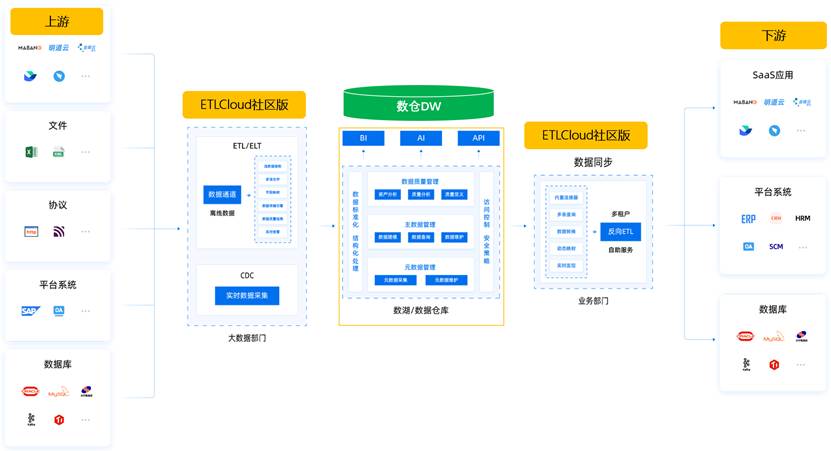
企业为什么要用ETL?核心原因是解决数据孤岛问题。不同的业务系统往往采用不同的技术架构,数据格式和存储方式千差万别。要想让这些系统的数据能够互联互通,为企业决策提供统一的数据视图,ETL就是必不可少的桥梁。
常见的ETL应用场景解析
场景一:ERP与CRM数据打通
很多企业同时使用ERP管理内部资源和CRM管理客户关系,但两套系统的客户信息经常对不上号。比如销售在CRM里录入的客户名称是"阿里巴巴集团",而财务在ERP里记录的是"阿里巴巴(中国)有限公司",导致数据无法关联。
通过ETL流程,可以建立客户主数据管理规则:从CRM提取客户基础信息,与ERP中的客户档案进行匹配,利用模糊匹配算法和业务规则进行数据清洗,最终在数据仓库中形成统一的客户360度视图。
场景二:数据库迁移和同步
企业在技术升级过程中,经常需要进行数据迁移。比如从传统的Oracle数据库迁移到云端的PostgreSQL,或者在本地数据中心和云平台之间建立数据同步机制。
这种场景下,ETL不仅要处理数据格式转换(比如Oracle的DATE类型到PostgreSQL的TIMESTAMP类型),还要考虑增量同步策略。对于实时性要求高的业务,可能需要采用CDC(Change Data Capture)技术实现准实时同步。
场景三:多源数据整合分析
现代企业的数据来源越来越多样化:除了传统的数据库,还有来自社交媒体的API数据、物联网设备的传感器数据、第三方服务的推送数据等。要做综合性的业务分析,必须把这些异构数据源整合起来。
比如一个零售企业要分析门店销售效果,需要整合POS机的交易数据、天气API的气象数据、门店客流监控系统的人流数据等。ETL流程需要处理不同的数据格式(关系型数据、JSON、XML等),并按照时间维度进行对齐。
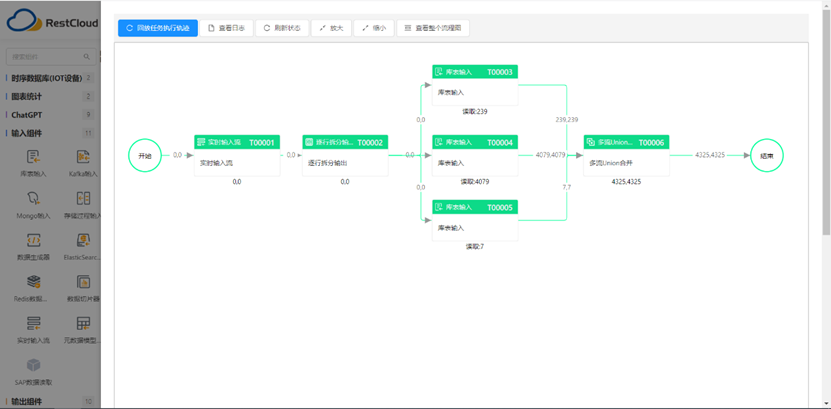
ETL的核心处理逻辑和技术要点
批处理vs实时处理
传统的ETL多采用批处理模式,比如每天凌晨跑一次数据同步任务。这种方式适合对实时性要求不高的场景,处理效率高,资源消耗相对较低。
但随着业务节奏的加快,很多场景需要实时或准实时的数据同步。比如电商平台的库存同步、金融机构的风控数据更新等。这就催生了流式ETL的需求,需要使用Kafka、Flink等流处理技术。
数据质量控制
ETL过程中最容易出问题的环节就是数据质量。常见的问题包括:
- 数据缺失:源系统中某些字段为空
- 数据重复:同一条记录在不同系统中有多个版本
- 数据不一致:同一个业务实体在不同系统中的表示方式不同
- 数据格式错误:日期、数字等格式不符合规范
一个成熟的ETL流程必须包含完善的数据质量检查机制,包括数据验证规则、异常数据处理策略、数据血缘跟踪等。
性能优化策略
大数据量的ETL处理往往面临性能瓶颈。常用的优化策略包括:
- 并行处理:将大任务拆分成多个子任务并行执行
- 增量更新:只处理变化的数据,避免全量重复处理
- 索引优化:在关键字段上建立索引,提高查询效率
- 分区策略:按时间或业务维度对数据进行分区存储
实战案例:某制造企业的数据集成项目
去年我参与了一个制造企业的企业数据治理项目,客户的痛点很典型:生产系统、质量管理系统、供应链系统各自为政,管理层要看一个完整的生产效率报表,需要IT部门花两天时间手工整理数据。
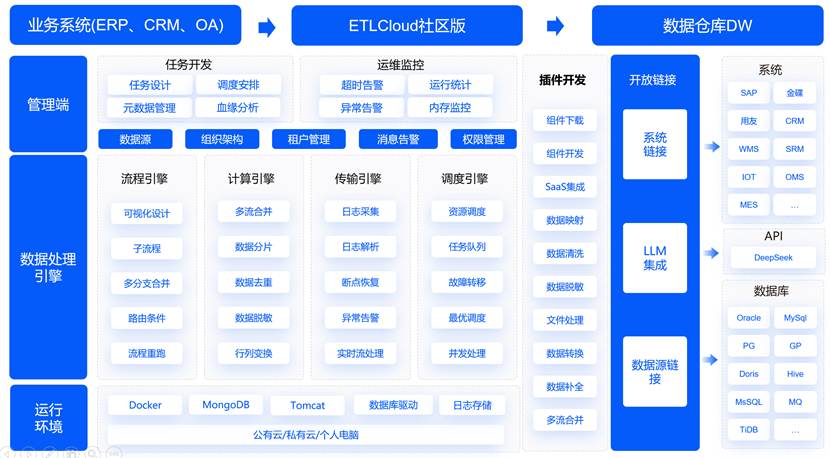
我们设计的ETL解决方案分为三个层次:
数据接入层:通过API集成和数据库直连的方式,从各个业务系统提取数据。生产系统通过数据库连接池每15分钟同步一次,质量管理系统通过REST API实时推送检验结果,供应链系统每小时进行一次批量数据同步。
数据处理层:建立了统一的产品编码体系和供应商主数据,解决了不同系统中同一个产品有多个编号的问题。同时建立了数据质量监控规则,对异常数据进行自动标记和人工审核。
数据服务层:将处理好的数据存储在数据仓库中,并通过数据服务API为各种报表和分析工具提供统一的数据接口。
项目上线后,原来需要两天才能出的报表,现在可以实时生成。更重要的是,建立了可复用的数据集成平台,后续新系统的接入变得非常简单。
选择ETL工具的几点建议
市面上的ETL工具很多,从开源的Talend、Pentaho,到商业化的Informatica、DataStage,再到国内新兴的ETLCloud等。选择时需要考虑几个关键因素:
技术适配性:是否支持企业现有的技术栈,包括数据库类型、消息队列、云平台等。
易用性:可视化设计界面是否友好,是否支持拖拽式配置,学习成本如何。
扩展性:能否应对数据量增长和业务复杂度提升,是否支持分布式处理。
成本控制:包括软件许可成本、实施成本、运维成本等综合考虑。
ETL本质上是企业数字化转型过程中的基础设施建设,选择合适的工具和设计合理的架构,能够为企业的数据驱动决策提供坚实的技术支撑。随着云计算和AI技术的发展,ETL也在向着更智能、更灵活的方向演进,比如自动化的数据映射、智能的数据质量检测等,这些新技术将进一步降低数据集成的门槛,让更多企业能够享受到数据价值释放带来的红利。