OpenAI 最新开源模型 gpt-oss (Windows + Ollama/ubuntu)本地部署详细教程
OpenAI 最近发布了其首个开源的开放权重模型gpt-oss,这在AI圈引起了巨大的轰动。对于广大开发者和AI爱好者来说,这意味着我们终于可以在自己的机器上,完全本地化地运行和探索这款强大的模型了。
本教程将一步一步指导你如何在Windows系统上,借助极其便捷的本地大模型运行框架Ollama,轻松部署和使用 gpt-oss 模型。
作者:IvanCodes
日期:2025年8月8日
专栏:开源模型
一、准备工作:系统配置与性能预期
在开始之前,了解运行环境非常重要。本次部署将在我的个人电脑上进行,下面是推荐配置:
- CPU: 现代多核 CPU,如 Intel Core i7 或 AMD Ryzen 7 系列
- 内存 (RAM): 32 GB 或更多
- 显卡 (GPU): 强烈推荐 NVIDIA GeForce RTX 4090 (24 GB 显存)。这是确保大型模型流畅运行与高效微调的理想选择。
- 操作系统: Linux 或 Windows 11
- Python 版本: 推荐 3.12
性能预期:
在这套配置下,运行 gpt-oss-20b 这样中等规模的模型,响应速度会比较慢,生成一段较长文本可能需要几十秒甚至更久。但这完全可用于功能测试、学习和轻度使用。如果你的显卡性能更强 (如RTX 5090, 4090),体验会流畅很多。当然我自己电脑的性能要差点
二、了解 gpt-oss 模型
gpt-oss 是 OpenAI 发布的开放权重语言模型,截止到2025年8月8日,提供了 gpt-oss-120b 和 gpt-oss-20b 两个版本。它旨在支持开发者在各种硬件上进行研究和创新。
官方 GitHub 仓库: https://github.com/openai/gpt-oss
三、安装 Ollama:本地部署的神器
Ollama 是一个开源框架,它极大地简化了在本地运行 Llama, Mistral, Gemma 以及现在 gpt-oss 等大模型的过程。
1. 访问 Ollama 官网并下载
打开浏览器,访问 Ollama 官网。你会看到一个简洁的界面,邀请你与开源模型一起对话和构建。
点击 “Download” 按钮后,页面会自动跳转到下载选择页面。
2. 选择操作系统
Ollama 支持 macOS, Linux 和 Windows。我们选择 Windows。
3. 安装 Ollama
下载完成后,运行安装程序。安装过程非常简单,基本就是一路“下一步”。
安装完成后,Ollama 会在你的系统托盘中以后台服务的形式运行。
四、拉取并运行 gpt-oss 模型
Ollama 的命令行操作与 Docker 非常相似,主要使用 pull 和 run 命令。
1. 打开终端
打开你的Windows PowerShell 或命令提示符 (CMD)。
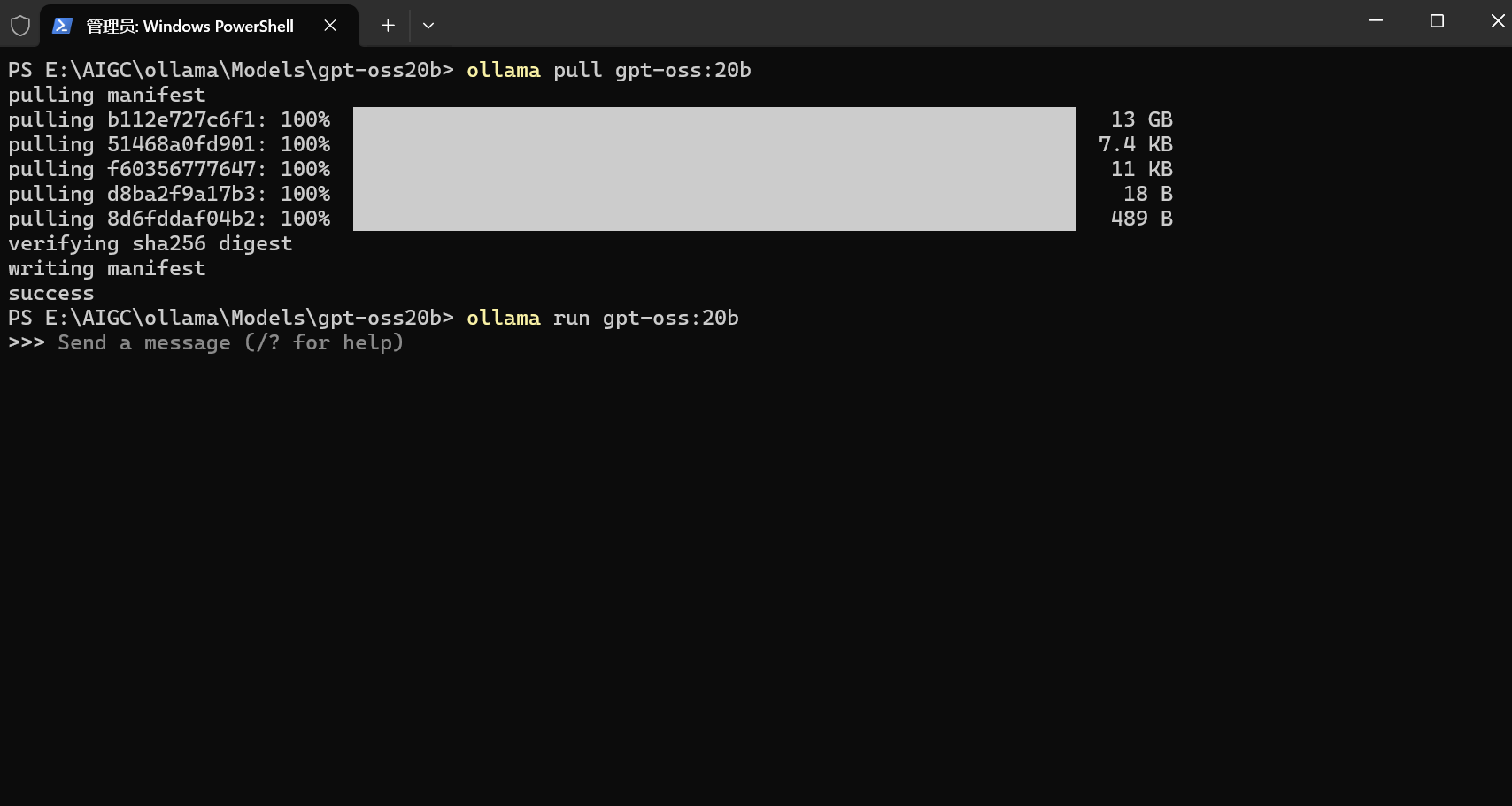
2. 拉取 (Pull) 模型
gpt-oss 有多个版本,我们这里以对硬件要求稍低的 20b 版本为例。执行以下命令:
ollama pull gpt-oss:20b
这个过程会下载模型文件,根据你的网络速度,可能需要一些时间。
3. 运行 (Run) 模型
下载完成后,运行模型进行交互:
ollama run gpt-oss:20b
五、与 gpt-oss 模型交互
1. 基础对话
运行 ollama run 命令后,你就可以直接在终端中输入问题并与模型对话了。我们来问一个经典问题:“你是谁?”
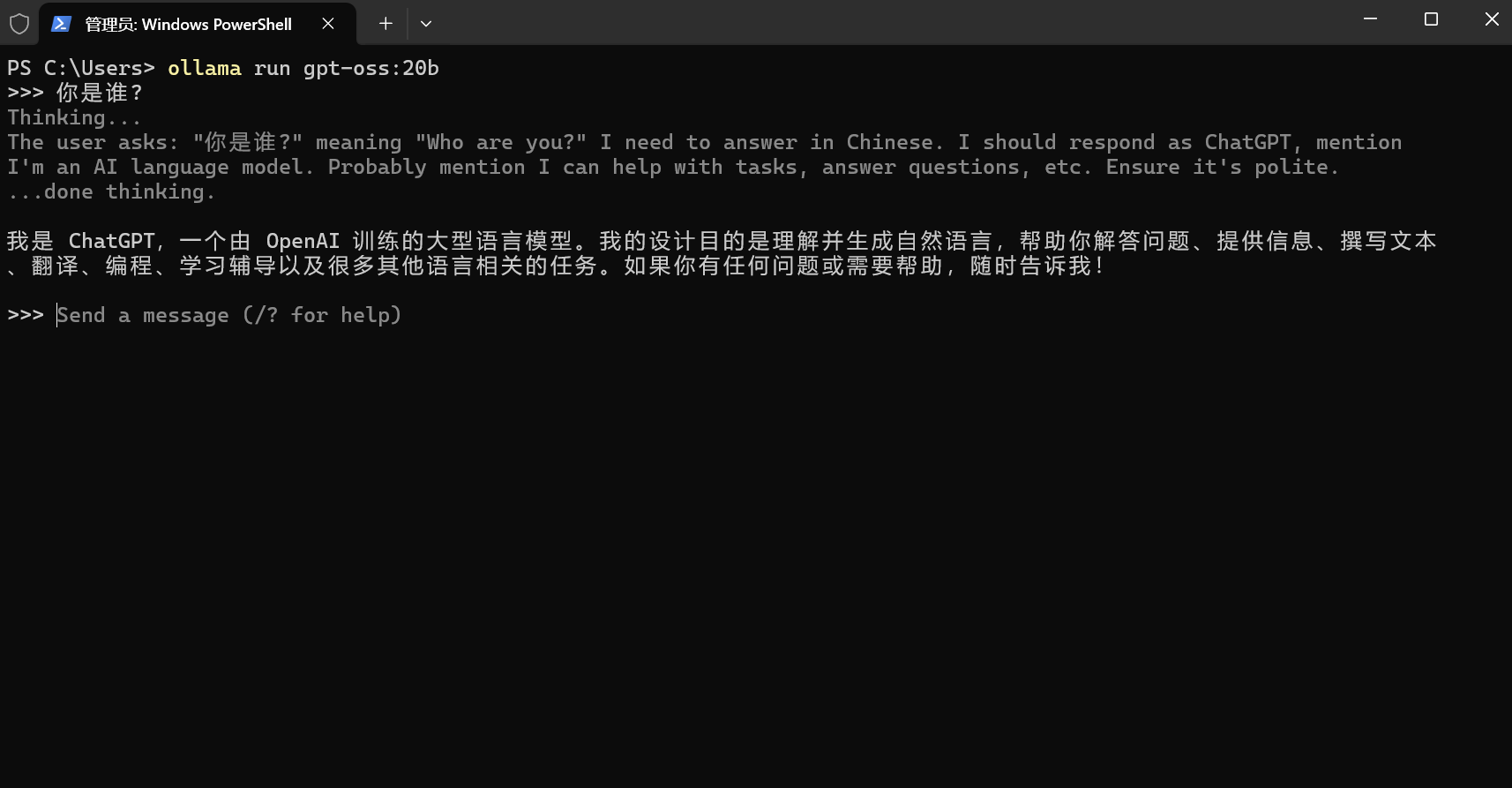
注意:模型的回答中提到了 “ChatGPT”,这可能是因为 gpt-oss 的训练数据或基础架构与ChatGPT有很深的渊源。
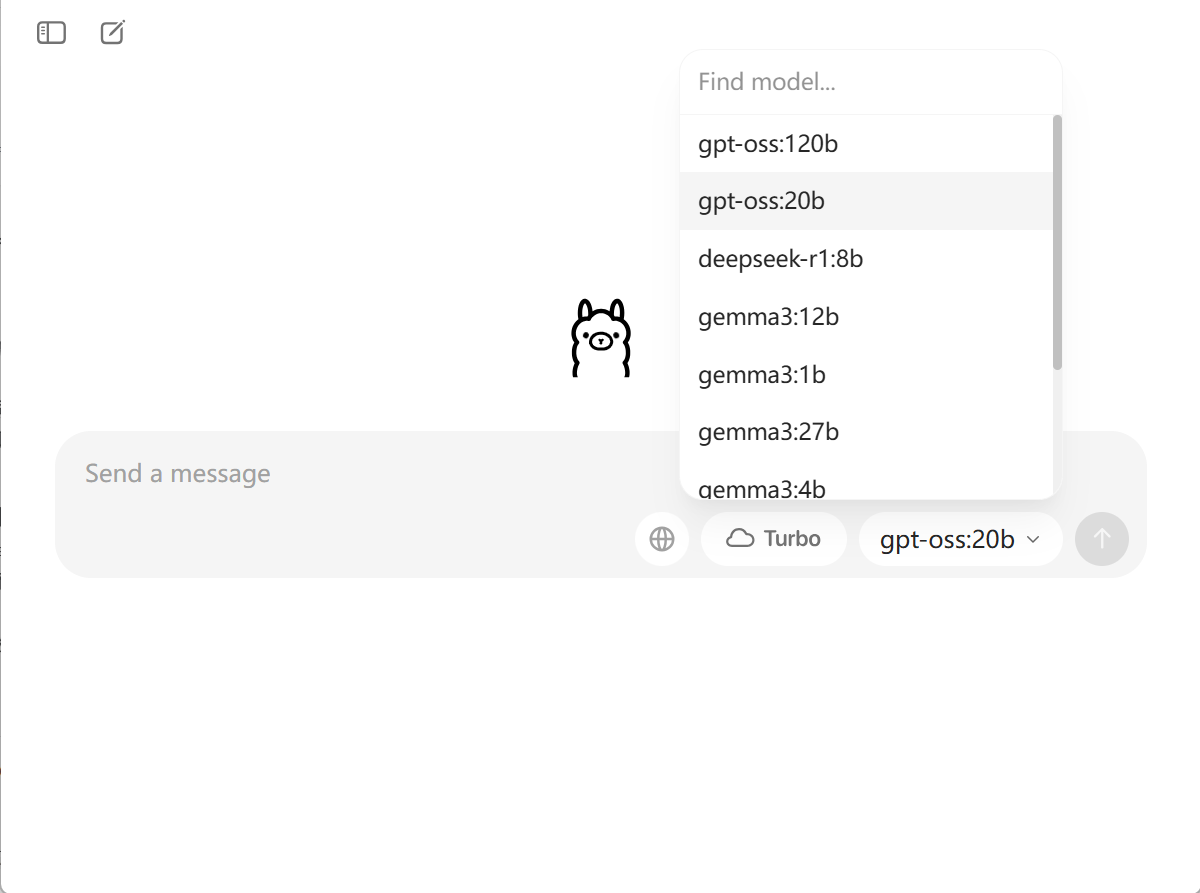
2.使用 Ollama 桌面应用 GUI
除了命令行,Ollama 也提供了一个简洁的桌面应用
- 安装Ollama后,它通常会自动启动。
- 你可以在主界面的下拉菜单中,选择你已经
pull下来的模型 (如gpt-oss:20b),然后直接开始对话。
3.创建你的 Ollama Hub 个人资料
登录 Ollama 官网后,你可以创建并编辑你的个人资料。这是分享你自定义的模型 (Modelfiles) 和参与社区的第一步。
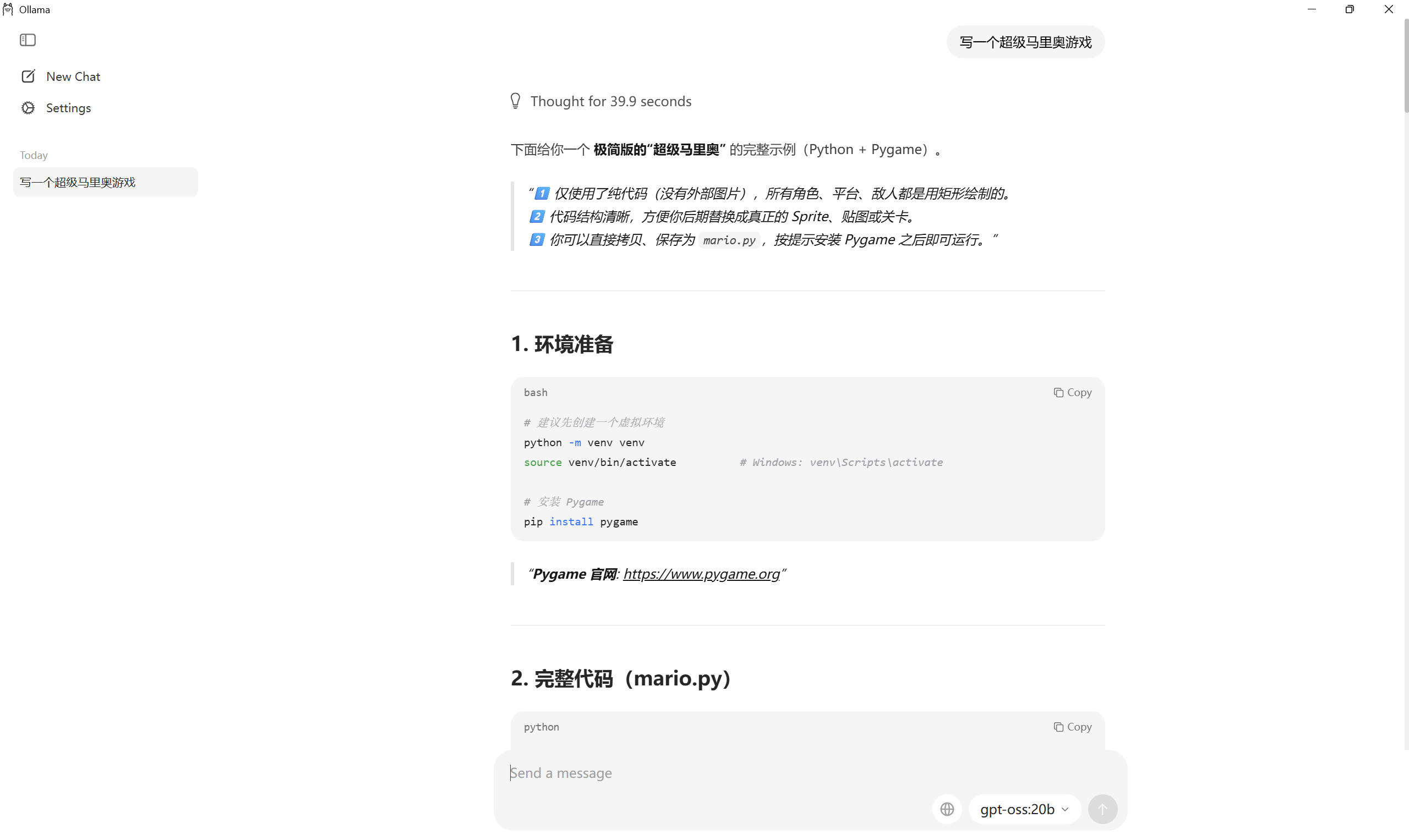
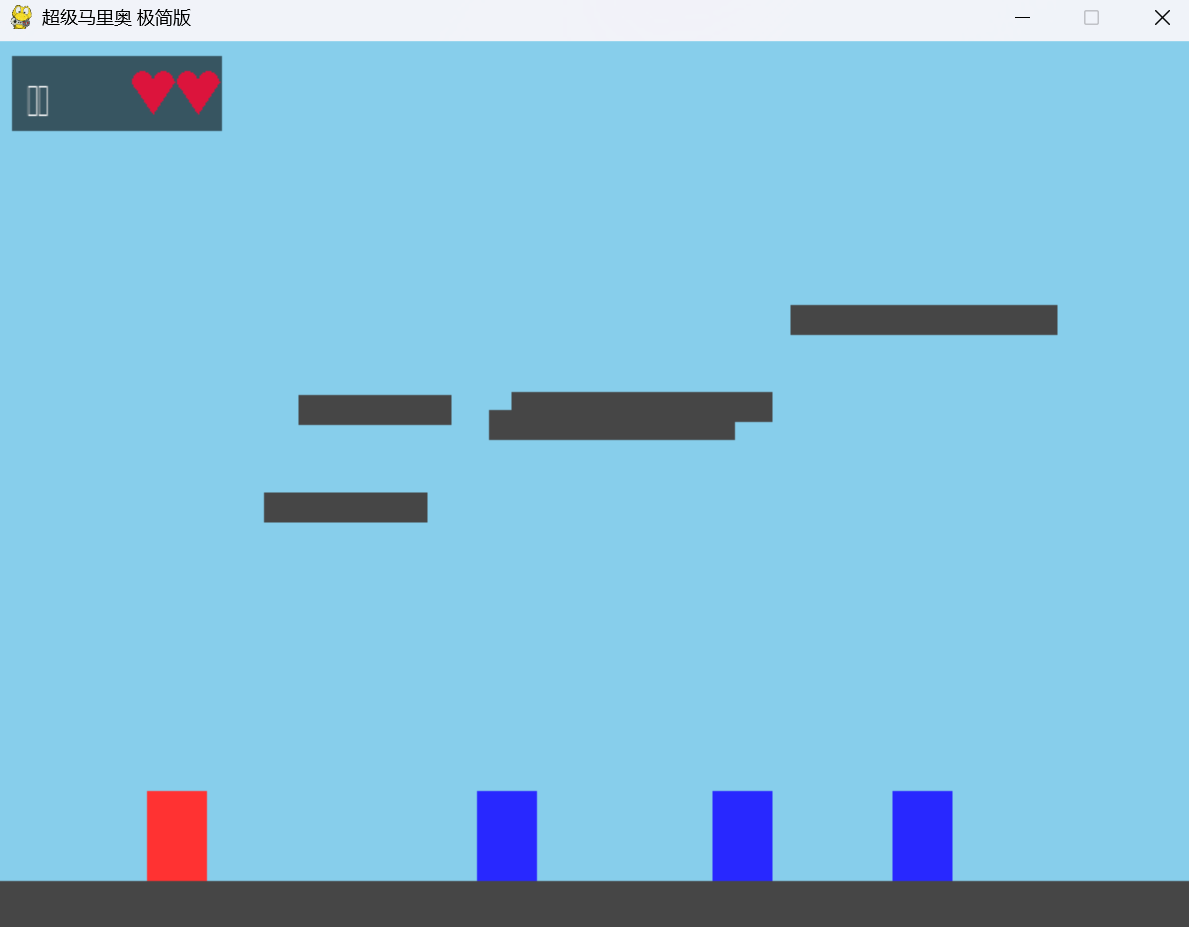
4. 代码生成
gpt-oss 的代码能力还可以。我们可以让它尝试写一个pygame游戏。
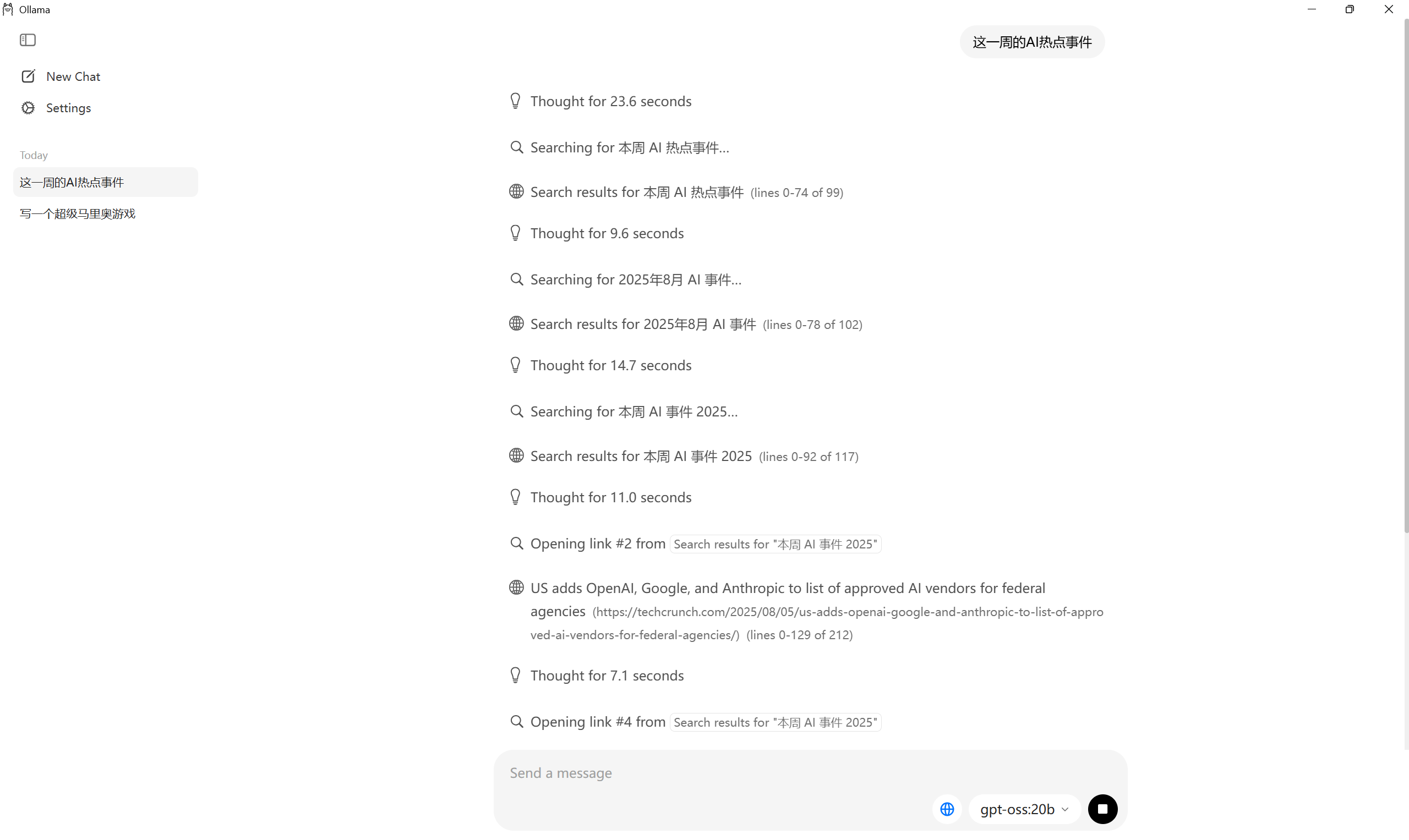
3. 联网搜索功能
一个令人惊喜的功能是,gpt-oss 在 Ollama 中可以联网!但这需要你先在 Ollama Hub 上创建并登录你的账户。
登录后,当你提出一个需要实时信息的问题时,模型会自动触发搜索功能。
六、在 Ubuntu上部署及使用 Web 客户端
对于Linux用户,特别是作为服务器使用时,命令行是基础,但搭建一个功能强大的Web界面能提供更好的体验。
1. 在 Ubuntu 上安装 Ollama
在Ubuntu上安装Ollama极其简单,官方提供了一键安装脚本。打开你的终端,执行以下命令:
curl -fsSL https://ollama.com/install.sh | sh
脚本会自动下载Ollama二进制文件,并将其设置为一个 systemd 后台服务。安装完成后,Ollama服务会自动启动。你可以通过 systemctl status ollama 验证其运行状态。
2. 拉取并运行模型 (命令行)
与Windows完全相同,在Ubuntu终端中执行:
ollama pull gpt-oss:20b
ollama run gpt-oss:20b
3. 搭建Web客户端:Open WebUI
Open WebUI 是一个非常流行的、与Ollama完美兼容的开源Web客户端。
a. 安装 Docker
Open WebUI 最简单的部署方式是使用Docker。如果你的系统尚未安装Docker,请执行:
apt-get update
apt-get install -y docker.io
# 启动并设置开机自启
systemctl start docker
systemctl enable docker
b. 运行 Open WebUI 容器
执行以下命令来下载并运行 Open WebUI 容器:
docker run -d --network=host -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
命令解析:
-d: 后台运行容器。--network=host: 让容器共享主机的网络,这样WebUI可以轻松访问在本机11434端口运行的Ollama服务。-v open-webui:/app/backend/data: 挂载一个数据卷,用于持久化WebUI的用户数据和配置。--name open-webui: 给容器命名。--restart always: 确保Docker服务重启时,该容器也会自动启动。
c. 访问并使用 Open WebUI
- 在你的浏览器中,访问
http://<你的Ubuntu服务器IP>:8080(Open WebUI 默认使用8080端口)。 - 首次访问时,你需要注册一个管理员账户。
- 登录后,你就可以在界面上选择已经拉取到本地的
gpt-oss:20b模型,并开始对话了!
总结
通过本教程,我们成功地在一台普通的Windows电脑上,使用 Ollama 轻松部署了OpenAI的
gpt-oss模型。同时,我们也学习了如何在Ubuntu环境下完成同样的部署,并额外搭建了一个功能强大的Open WebUI客户端。我们体验了它的基础对话、代码生成乃至联网搜索等强大功能。虽然在中端硬件上性能有限,但这无疑为广大AI爱好者和开发者打开了一扇探索前沿大模型的大门。
Q&A 问答环节
1. 问:为什么模型在我电脑上运行这么慢?
答: 模型运行速度主要取决于GPU性能和显存。gpt-oss-20b 是一个有200亿参数的模型,对资源要求较高。在RTX 3050这样的入门级/中端显卡上,推理速度自然会比较慢。Ollama会自动利用你的GPU,但如果显存不足,部分模型层会加载到CPU和内存中,进一步拖慢速度。
2. 问:除了gpt-oss,我还能用Ollama运行哪些模型?
答: 非常多!Ollama支持目前几乎所有主流的开源模型,例如 Google 的 Gemma,Meta 的 Llama 3,Mistral AI 的 Mistral 等。你可以在Ollama官网的 “Models” 页面查看完整的模型库。
3. 问:联网搜索功能是如何实现的?需要额外配置吗?
答: 这是 gpt-oss 模型本身在Ollama框架下集成的功能,可能利用了类似工具调用 (Tool Calling) 或函数调用 (Function Calling) 的机制。当你提出需要外部信息的问题时,模型会自动调用一个内置的搜索工具。除了登录Ollama Hub账户外,通常不需要你进行额外配置。
4. 问:如果我没有NVIDIA显卡,还能运行吗?
答: 可以。Ollama支持纯CPU运行。它会自动检测你是否有兼容的GPU,如果没有,它会完全使用你的CPU和系统内存来运行模型。当然,纯CPU运行的速度会比GPU慢得多。
5. 问:我可以微调或定制 gpt-oss 模型吗?
答: 可以。这正是开放权重模型的魅力所在。你可以使用自己的数据集对模型进行微调 (fine-tuning)。在Ollama中,你还可以通过编写 Modelfile 来定制模型的系统提示词 (System Prompt)、参数等,然后构建一个属于你自己的新模型版本。
6. 问:如何查看我的 Open WebUI 容器的日志 (Ubuntu)?
答: 如果Open WebUI无法启动或出现问题,你可以使用Docker命令查看其日志来排查错误。在终端中执行:
docker logs open-webui
如果你想实时跟踪日志,可以加上 -f 选项:docker logs -f open-webui。