大队列CT胰腺癌PANDA 模型 医生结合AI后,病灶检测灵敏度提升 8.5%,胰腺癌识别灵敏度提升 20.5%,住院医师性能接近专家水平

胰腺癌(PDAC)因早期难发现、预后极差被称为“癌王”,多数患者确诊时已处于晚期,错失手术机会。近期,《Nature Medicine》发表的一项研究显示,中国团队研发的AI模型PANDA可通过非增强CT精准检测胰腺癌,为大规模筛查提供了新工具。

作者提供了在线网站:panda.medofmind.com 演示模型在几个样本上的效果
一、数据来源:覆盖多场景、多中心,兼顾多样性与可靠性
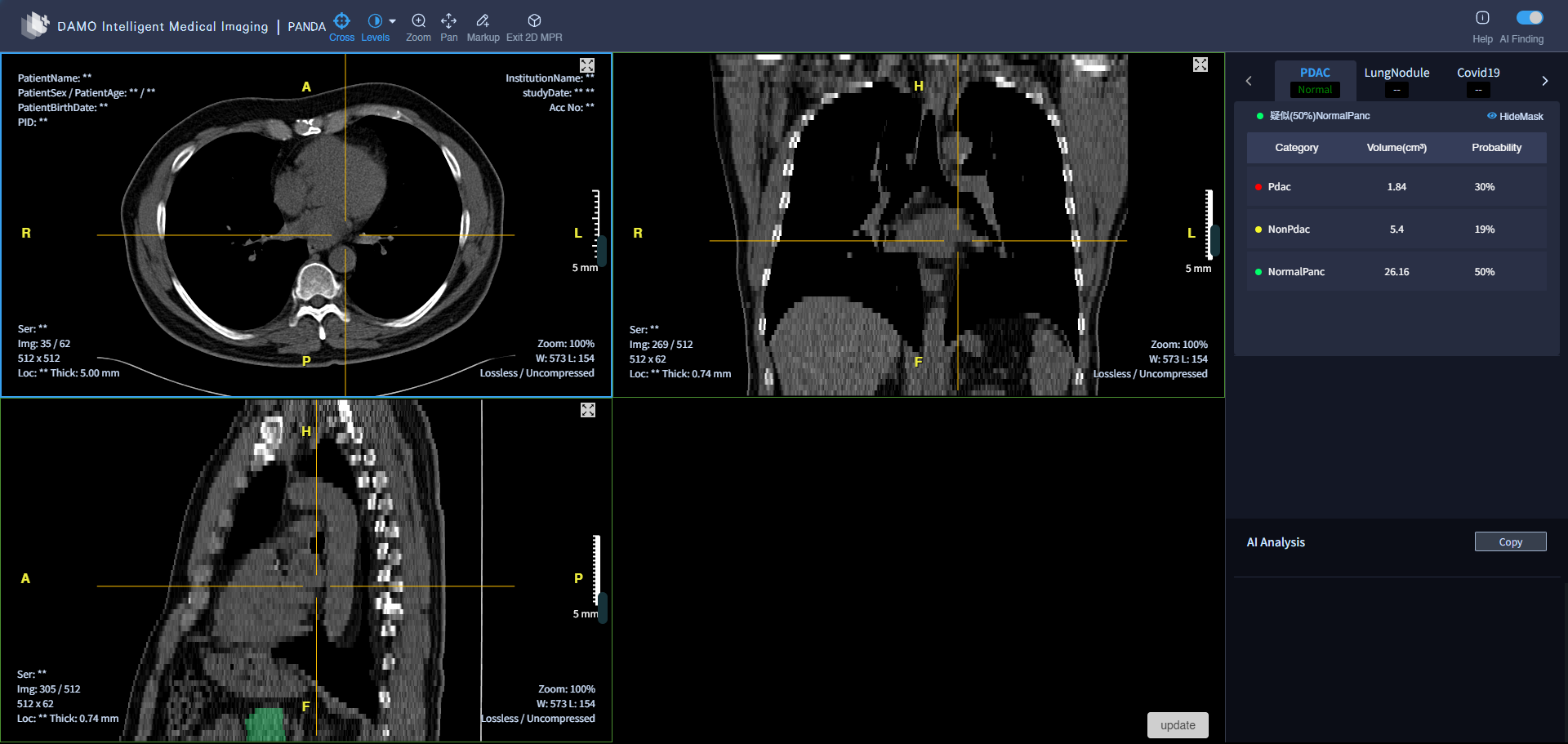
为确保模型的泛化能力,研究团队构建了多维度数据集:
- 训练集:3208名患者(含胰腺癌、良性病变及健康对照),来自上海胰腺疾病研究所(SIPD),均经病理确诊或2年随访验证。
- 多中心验证集:6239名患者,涵盖中国、中国台湾地区及捷克的10个医疗中心,包含不同种族、成像设备及临床场景数据。
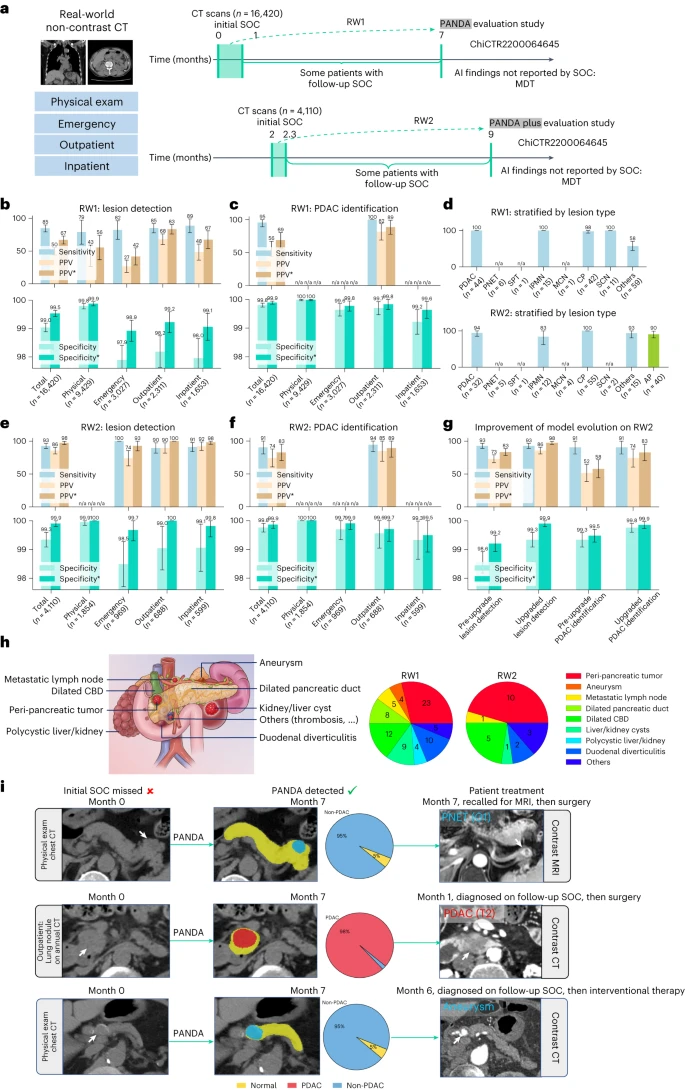
- ChiCTR2200064645数据集:20530名连续患者,来自体检、急诊、门诊、住院4类场景,覆盖常规临床流程中的各类人群。
- 胸部CT数据集:492名患者,验证模型在胸部CT(胰腺部分扫描)中的可行性。
二、数据处理
非增强CT中,胰腺癌与正常组织的灰度差异极小,直接标注病灶几乎不可能。研究团队通过跨模态信息迁移破解这一难题,具体步骤如下:
-
双模态数据对齐
为3208名训练集患者同时采集非增强CT和增强CT(同一检查时段),利用刚性配准算法(基于解剖标志点,如脊柱、血管)将两组图像精准对齐,确保像素级空间对应。 -
专家标注迁移
由5名胰腺影像专家在增强CT上手动标注:1.胰腺整体区域;2.病灶边界(含胰腺癌及7类良性病变);3.病灶类型(病理确诊)。通过配准矩阵,将这些标注“映射”到非增强CT上,生成非增强CT的伪标注(标注精度通过Dice系数验证,≥0.85)。 -
半监督胰腺分割优化
仅靠迁移标注仍不足,团队引入半监督学习:用1000例公开数据集(如TCIA)的胰腺标注初始化模型,再用3208例训练集的伪标注进行微调,最终胰腺分割Dice系数达0.91,为后续病灶检测提供精准“感兴趣区域”。 -
场景适配增强
针对胸部CT可能仅部分扫描胰腺的问题,设计动态裁剪增强:随机裁剪非增强CT的胰腺区域(裁剪比例30%-70%),模拟胸部CT的“不全扫描”场景,迫使模型学习胰管扩张等间接征象。
三、PANDA模型构建
胰腺癌检测的核心难题在于:非增强CT中病灶特征模糊,且需兼顾高灵敏度(不漏诊)与高特异性(少误诊)。PANDA模型的构建围绕这一痛点,通过“数据处理-多阶段建模-临床适配”三层设计
阶段1:胰腺定位(nnU-Net)【从CT种找到胰腺位置】
采用低分辨率nnU-Net (https://github.com/MIC-DKFZ/nnUNet) (3D U-Net 变体),输入为全腹CT(512×512×30层),输出胰腺的三维分割掩码。以标注的胰腺区域为真值,用Dice损失优化(聚焦边缘像素),同时加入“解剖约束”(胰腺与脊柱、十二指肠的相对位置),避免分割偏移。
阶段2:是否有病灶(多任务CNN)
以全分辨率nnU-Net 为 backbone,含双分支:
-
分割分支(seg):输出病灶的像素级掩码(区分胰腺正常组织与病灶);
-
分类分支(cls):对分割分支提取的5级特征图做全局最大池化,拼接后通过全连接层输出“有病灶/无病灶”概率。
-
损失函数:联合优化分割与分类任务
L=Lseg+0.3×Lcls\mathcal{L} = \mathcal{L}_{seg} + 0.3\times\mathcal{L}_{cls}L=Lseg+0.3×Lcls
其中,Lseg\mathcal{L}_{seg}Lseg为Dice损失+交叉熵损失(平衡前景/背景),Lcls\mathcal{L}_{cls}Lcls为二分类交叉熵损失。
-
特异性调优:训练中通过动态阈值调整,在验证集上强制模型特异性达99%(即100例健康人中最多1例假阳性),方法是:当验证集特异性低于99%时,增加分类损失权重,倒逼模型“保守判断”。
阶段3:病灶鉴别诊断(记忆Transformer)
对检测到的病灶,进一步分类为胰腺癌(PDAC)或7类良性病变(如IPMN、慢性胰腺炎等),辅助临床决策。
- 模型结构:双路径记忆Transformer,融合局部细节与全局特征:
- UNet路径:输入胰腺区域裁剪图像(160×256×40层),输出5级特征图(捕捉病灶纹理、边界);
- 记忆路径:初始化200个“记忆tokens”(320通道),通过交叉注意力与UNet特征交互,自动编码不同病灶的典型特征(如胰腺癌的“边界模糊”、IPMN的“胰管扩张”)。
- 注意力机制:每级UNet特征与记忆tokens做交叉注意力(聚焦病灶关键区域),记忆tokens间做自注意力(整合全局特征),最终通过分类头输出8类概率。
- 细分类优化:针对样本不平衡(如胰腺癌占比高,SPT罕见),采用“加权交叉熵损失”(罕见类权重×5),提升小样本类型的识别精度。
四、进一步优化模型:PANDA Plus
现实场景中,CT设备、患者人群差异大,且存在“未见过”的病变(如急性胰腺炎)。团队通过多种增量学习实现模型进化:
-
硬示例挖掘
从16420例真实世界数据(RW1)中筛选出76例假阳性(如peri-胰腺病变)和28例假阴性(如<10mm囊肿),作为“难例集”。 -
增量微调
冻结PANDA主干网络,仅微调分类头和记忆tokens,用“知识蒸馏损失”(约束新模型与原模型输出差异)避免遗忘旧知识,同时学习新病变特征(如急性胰腺炎的“胰腺肿大”)。 -
特异性跃升
PANDA Plus在4110例RW2数据中,特异性从99.0%提升至99.9%(每1000例仅1例假阳性),且新增对急性胰腺炎的检测灵敏度达90.0%。
五、模型结果:精度超专家,覆盖多场景,临床价值显著
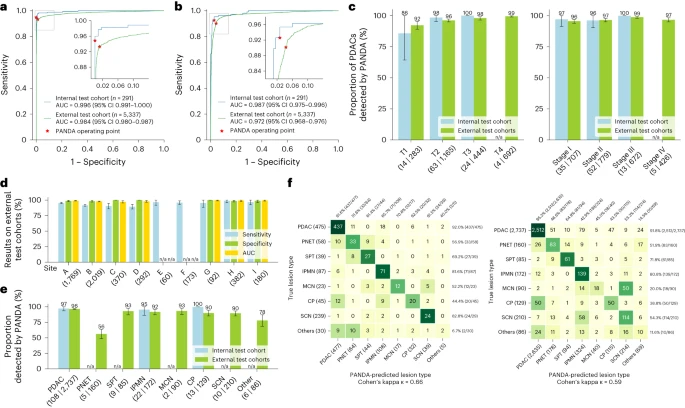
内部与外部验证的核心性能
模型在多中心数据中表现稳定,对早期 / 微小病灶检测能力优异。
与放射科医生的对比及 AI 辅助效果
PANDA 性能超越人工,且能显著提升医生诊断能力。
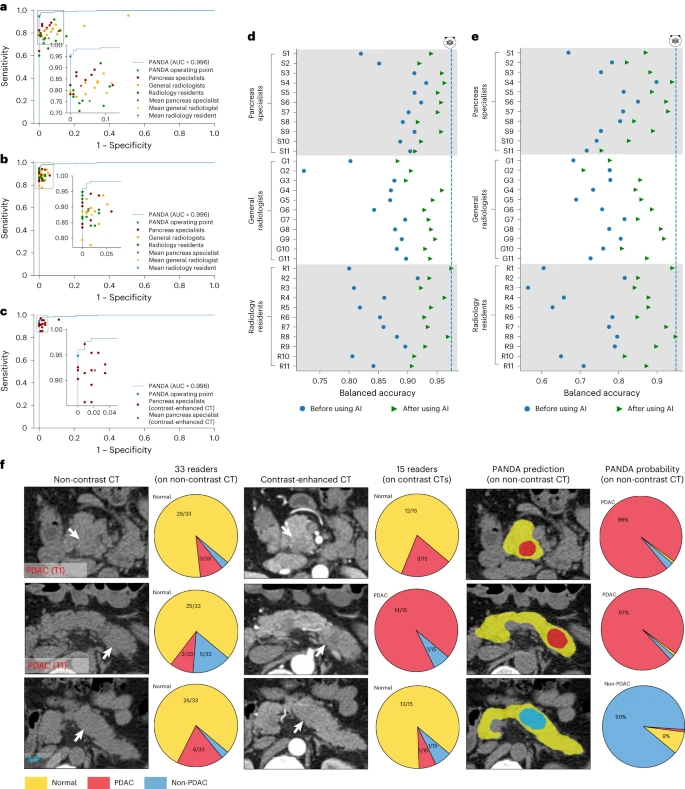
- abc图(AI vs 医生):33 名医生(含专家、普通放射科医生、住院医师)的 ROC 曲线均在 PANDA 下方。PANDA 识别胰腺癌的灵敏度比医生平均高 34.1%,特异性高 6.3%;住院医师单独诊断时灵敏度甚至低至 16.7%-35.2%。
- de中图(AI 辅助前后):医生结合 PANDA 后,病灶检测灵敏度提升 8.5%,胰腺癌识别灵敏度提升 20.5%,住院医师性能接近专家水平。
- f图:展示 AI 检出的早期胰腺癌和自身免疫性胰腺炎,均被医生漏诊,体现 AI 对细微特征的敏感性。
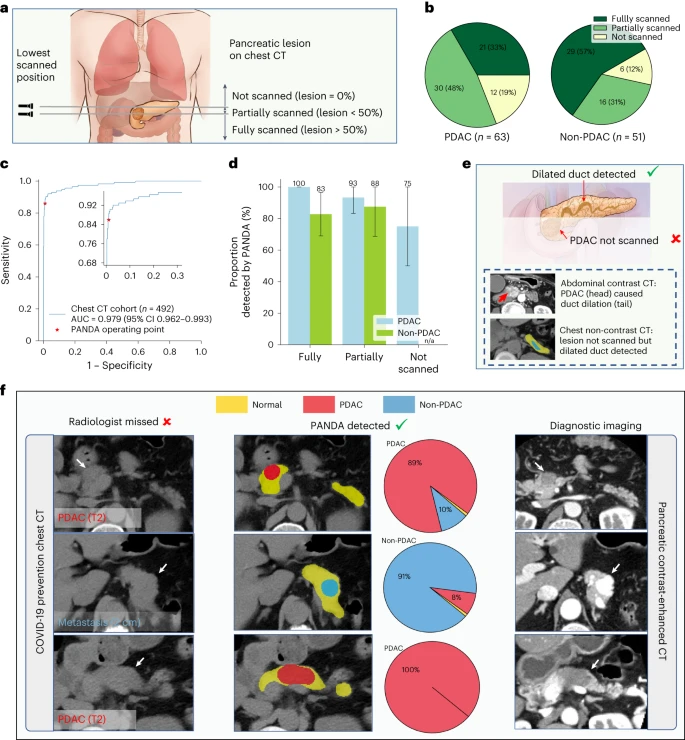
模型可利用胸部 CT(非专门扫描胰腺)实现胰腺癌筛查,拓展应用场景
模型在实际临床流程中安全有效,假阳性极低
- 模型性能:
- 16420 例真实数据(RW1)中,病灶检测特异性 99.0%,优化后的 PANDA Plus 在 4110 例(RW2)中特异性达 99.9%(每 1000 人仅 1 例假阳性);
- 胰腺癌识别阳性预测值(PPV)达 68.9%,意味着 AI 提示的 “可疑病例” 中,近 70% 确为病变,减少不必要的随访。
- 漏诊案例:PANDA 检出 26 例被常规诊断遗漏的病灶(含 1 例胰腺癌、1 例神经内分泌肿瘤),其中 1 例经手术治愈,证明其临床价值