Redis中间件(三):Redis存储原理与数据模型
文章目录
- 一、redis实现kv数据组织方式
- 0. redis的kv存储结构
- 存储结构
- 存储转换
- 1. 单线程指什么, redis是不是单线程?
- 2. 命令处理为什么是单线程,不采用多线程?
- 3. 单线程为什么这么快?
- 内存数据库(读/写速度极快)
- Reactor网络模型(使用IO多路复用高效)
- 数据结构高效(按需切换保持效率与空间平衡)
- 数据组织方式高效 (按需扩容+Rehash避免一次性耗时)
- *4 做了那些优化?
- 分治 (rehash分摊 + 定时器空闲处理)
- 耗时阻塞操作,在其他线程处理
- 对象类型采用不同的数据结构实现
- 5. redis IO多线程工作原理
- 跳表skiplist
- 柔性数组 list[ ];
- reactor_io多线程网络模型
- Q:为什么redis中字符串选择64字节为分界线?
一、redis实现kv数据组织方式
redis 中KV组织是通过字典,通过 hashtable 来实现;
hashtable 就是通 hash运算的方式来决定字符串放到数组的哪一个槽位,数组大小根据数据量来进行调整,所以就会涉及到扩容和缩容。
- 字符串经过 hash 函数运算得到 64 位整数;
- 64位整数 % 表长size 得到余数,即是字符串在数组中的槽位;
将数组存入对应的槽位中。
0. redis的kv存储结构
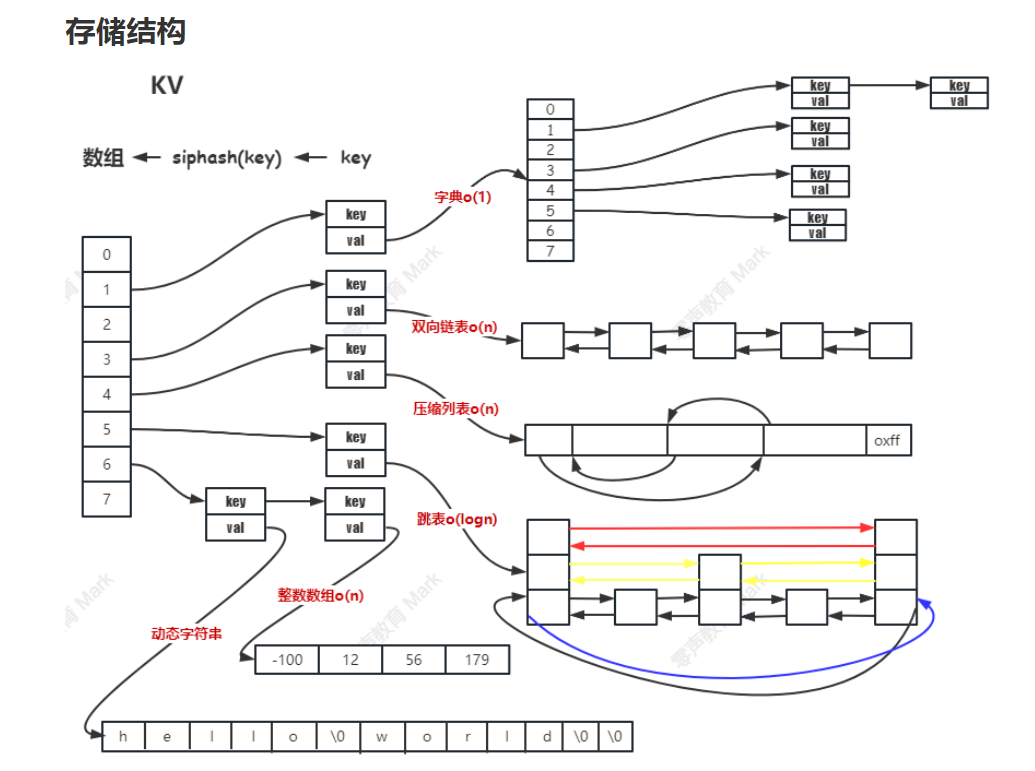
存储结构
- key-value键值对 通过hash的方式存储到数组中。
- value主要的数据结构有string,list,hash,set,zset; value的数据不是单一类型,可以嵌入kv键值对。
存储转换
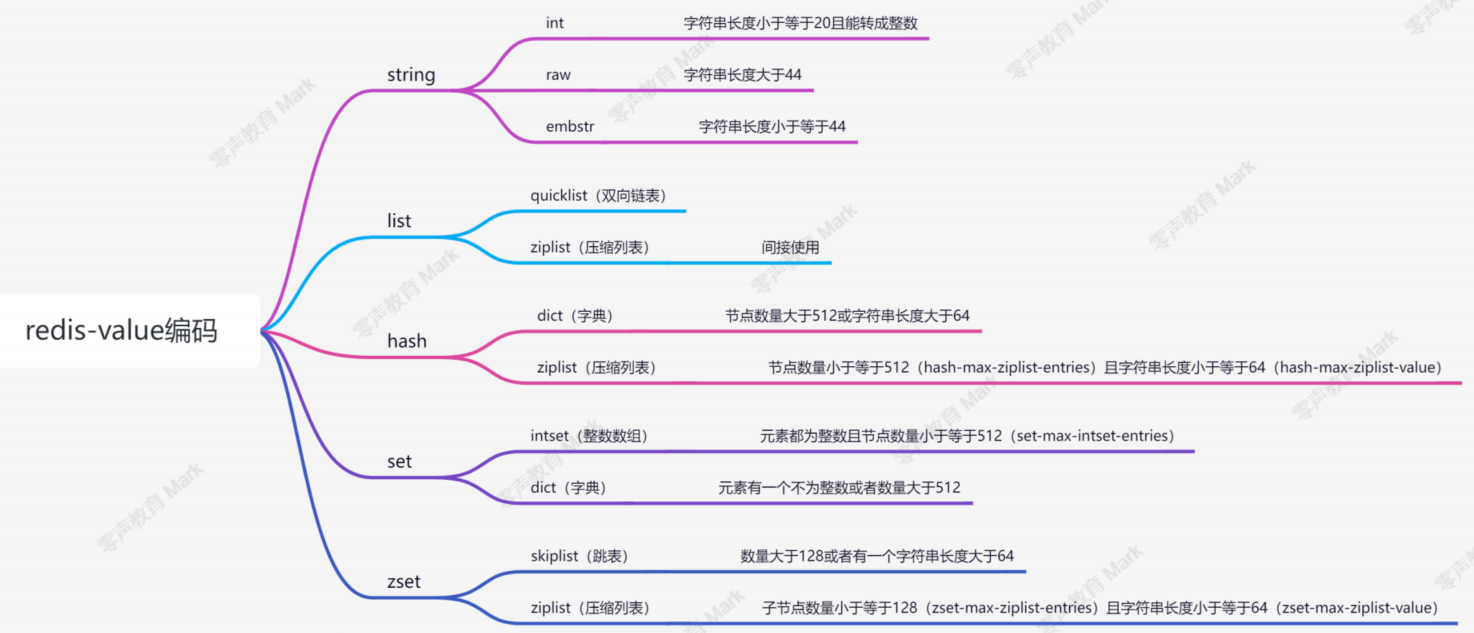
redis 在进行编码存储的时候,同一类型不同的数据量会导致编码的方式不同。
数据量少的时候,以存储效率高 为主
数据量多的时候,以运行查询快 为主
源码调试步骤
【1】makefile编译make clear
bear make (编译前先安装bear)
//推荐插件clongd: ctrl + 鼠标左键实现接口跳转【2】编译调试
查看src/Makefile 确认是有 -g -ggdb, 表示带调试信息【3】配置两个文件
tasks.json 帮助编译代码指令
launch.json 怎么启动redis-server【4】启动调试
vscode 菜单 运行->启动调试
1. 单线程指什么, redis是不是单线程?
单线程:指命令处理在一个线程.
redis不是单线程:本质上是一个单线程执行命令、多线程做杂活的高性能数据库.
2. 命令处理为什么是单线程,不采用多线程?
前提:单线程不能有 (例如cpu运算、阻塞io)耗时操作, 而影响redis相应性能.
1. 避免加锁复杂度
+多线程会引入并发冲突,需要加锁控制:
+加锁粒度难把控,锁得多了性能下降,锁得少了数据错乱,容易出现死锁、竞态等问题。代码复杂度和维护成本上升;
2. 避免线程切换开销
+多线程会发生频繁的 CPU 上下文切换;
+线程切换需要保存/恢复寄存器等上下文信息,如果 Redis 每条命令都切换线程,反而会拉低整体性能;
3. 数据结构无需加锁
+单线程访问所有核心数据结构(如字典、跳表等),天然线程安全
操作原子性强,不会出现“半更新”的问题;
+命令顺序可控,执行逻辑简单可靠
不采用多线程原因:
1.加锁复杂,redis对象类型由多个数据结构实现
2.频繁的的cpu上下文切换,抵消多线程的优势
3. 单线程为什么这么快?
内存数据库(读/写速度极快)
所有数据存储在内存中,读取/写入速度极快(O(1)、O(logN))
Reactor网络模型(使用IO多路复用高效)
详情在⇒ 5. redis IO多线程工作原理
数据结构高效(按需切换保持效率与空间平衡)
按需切换合适的数据结构,在执行效率与空间占用间保持平衡。
- 数据结构切换规则

数据组织方式高效 (按需扩容+Rehash避免一次性耗时)
*插件Bookmarks查看书签项目 : xie fan / redis · GitLab
0.负载因子 = used/size
- used是数组存储元素个数, size是数组长度
- redis负载因子是1,如果大于1扩容(翻倍),小于0.1缩容(正好缩到比used大的最小2的n次方的大小)
1.扩容 (解决冲突问题)
2.缩容(if 负载因子 < 0.1)
3.渐进式rehash (解决扩缩容引发问题,一步一步数据迁移)
- 把扩容过程分摊到增删改查中携带一次rehash操作/在定时器中,在redis空闲时,每次rehash 1ms。
- 处理渐进式rehash不会发生扩容和缩容,为了应对散列表中存储了大量元素,一次性hash耗时;以数组槽位为单位rehash
4.scan 将redis中散列表所有key枚举出来 (解决指令 "key"的耗时)
- 采用高位进位加法遍历,rehash后的槽位在遍历顺序上是相邻的
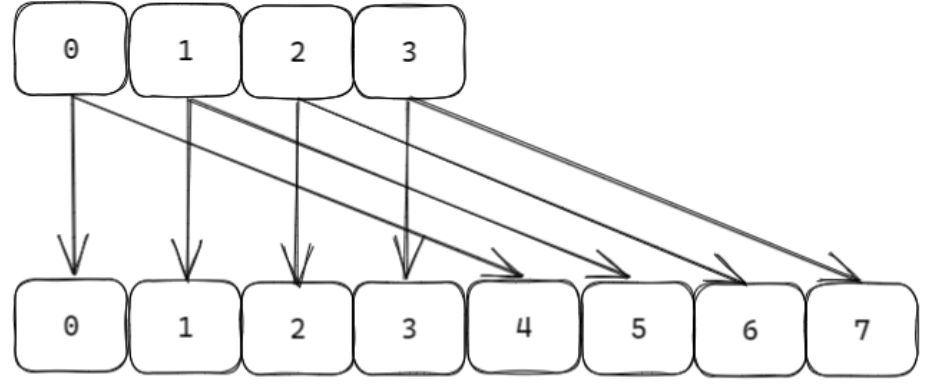
扩容的时候,会发生rehash,扩容后每个元素可能会有两个位置出现
缩容也会发生rehash,位置的调整与扩容相反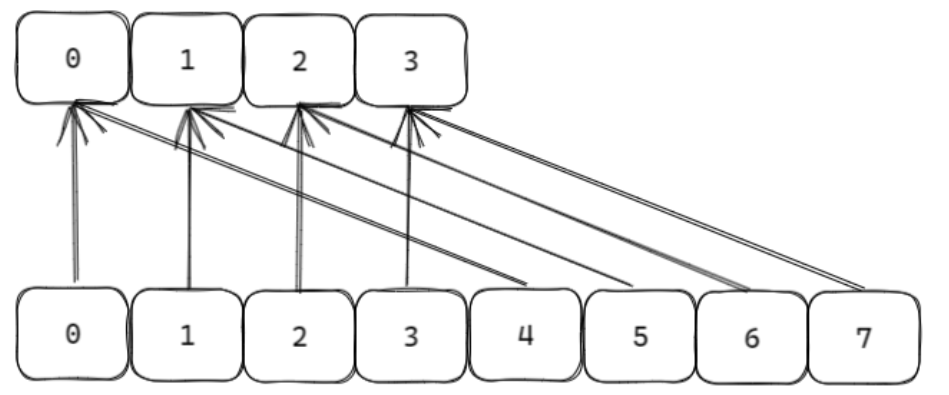
-
渐进式rehash:当 hashtable 中的元素过多的时候,不能一次性 rehash 到 ht[1] ,这样会长期占用 redis,其他命令得不到响应,所以需要使用渐进式 rehash;
rehash步骤:将ht[0]中的元素重新经过 hash 函数生成64位整数,再对ht[1]长度进行取余,从而映射到ht[1] 渐进式 rehash 规则:1. 分治的思想,将rehash分到之后的每步增删改查的操作当中;2. 在定时器中,闲时最大执行一毫秒rehash ,每次步长100个数组槽位 处于渐进式 rehash 阶段时,是否会发生扩容缩容?不会!
*4 做了那些优化?
分治 (rehash分摊 + 定时器空闲处理)
- 把rehash分摊到每一个操作步骤中:Redis的哈希表扩容不再一次性迁移数据,每次增删改查都“顺带”迁移一小部分数据,避免了一次性 rehash 导致服务卡顿。
- 定时器 + 空闲时间处理:比如 redis空闲时,定时器设置以100为步长最多rehash 1ms,利用 Redis 空闲时间来释放大key。
耗时阻塞操作,在其他线程处理
| 操作 | 线程方式 |
|---|---|
| Lazy Free | 创建后台线程异步删除大 Key |
| AOF Rewrite | 在子进程中异步执行 |
| RDB Save | 在子进程中快照,不阻塞主线程 |
| Redis 6.0 I/O 多线程 | 网络I/O在多线程中完成,提高并发性能 |
对象类型采用不同的数据结构实现
redis会根据数据的类型 + 内容大小 + 特性 来动态的选择最优的编码方式,即省内存又加快速度。

5. redis IO多线程工作原理
跳表skiplist
通过增加层级,每次从最高层级跳跃式快速找到节点;
理想情况O(log2(n)), 但现实中crud操作后都需重新构造理想的跳表;
现实优化:理想跳表 --> 概率型跳表 --> 实践型跳表
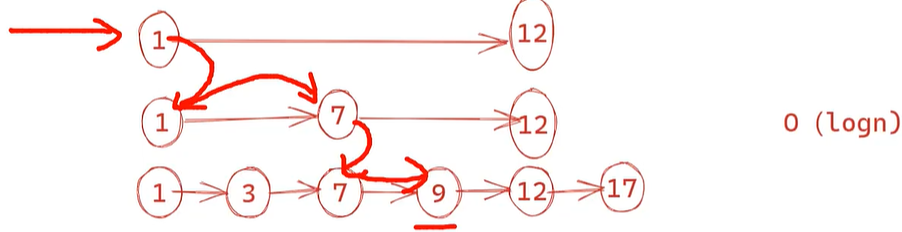
1.每个节点出现在哪些层是 随机的(通常用概率 p=0.25)
2.每一层都是一个有序链表
3.高层节点稀疏,底层节点密集
4.增删改需要重新构建理想跳表结构
5.查找,插入,删除时间复杂度都是O(logn)
6.Redis中使用跳表实现了有序集合(Sorted Set,zset)的排序部分zset中同时使用 哈希表 + 跳表哈希表负责快速查找成员是否存在跳表负责按 score 排序并实现范围查询
跳表特性
1.多层级有序链表, 最底层包含所有元素
2.可以二分查找的数据结构, 增删改查都是O(log2n)
3.范围查询非常方便,通过O(log2n)快速找到边界,然后在最底层遭到范围内所有元素
柔性数组 list[ ];
1.柔性数组的大小是在运行时动态决定的; 它不占结构体静态大小,而是结构体分配内存时追加在后面的一段连续空间。
2. sizeof返回结构体大小不包含柔性数组的大小;一次malloc一次free
一种结构体末尾的数组字段,用于实现可变长度数组
struct MyStruct {int id;char name[20];//柔性数组成员,必须是结构体的最后一个字段int data[];
};
reactor_io多线程网络模型
redis主线程管理调度 + 执行命令,IO 线程专职网络通信 ==> 让系统性能和单线程一致性两者兼得.
-
reactor网络模型
多条客户端连接,开启io多线程 1.没开启io多线程:串行操作 2.开启io多线程: 先读数据和解析协议并行computer串行加密数据和发送数据 并行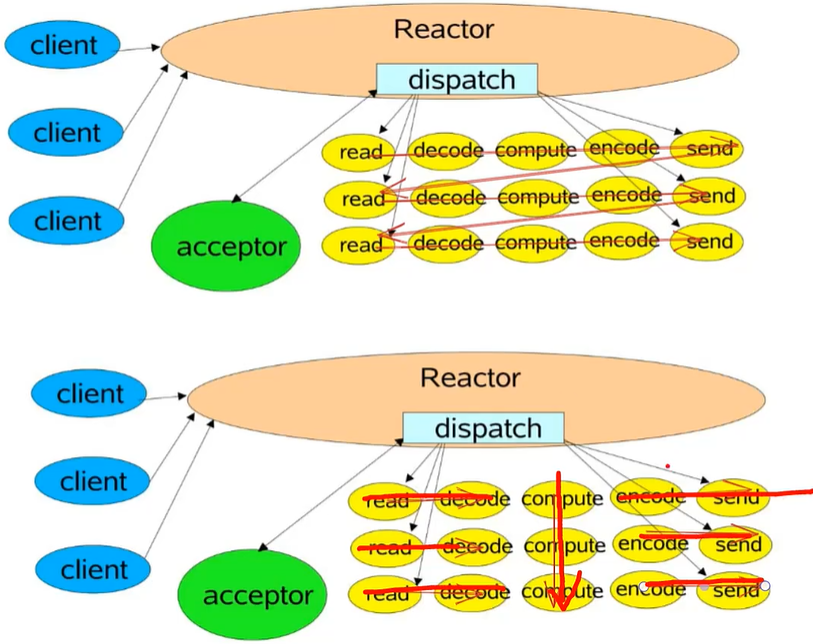
-
线程模型
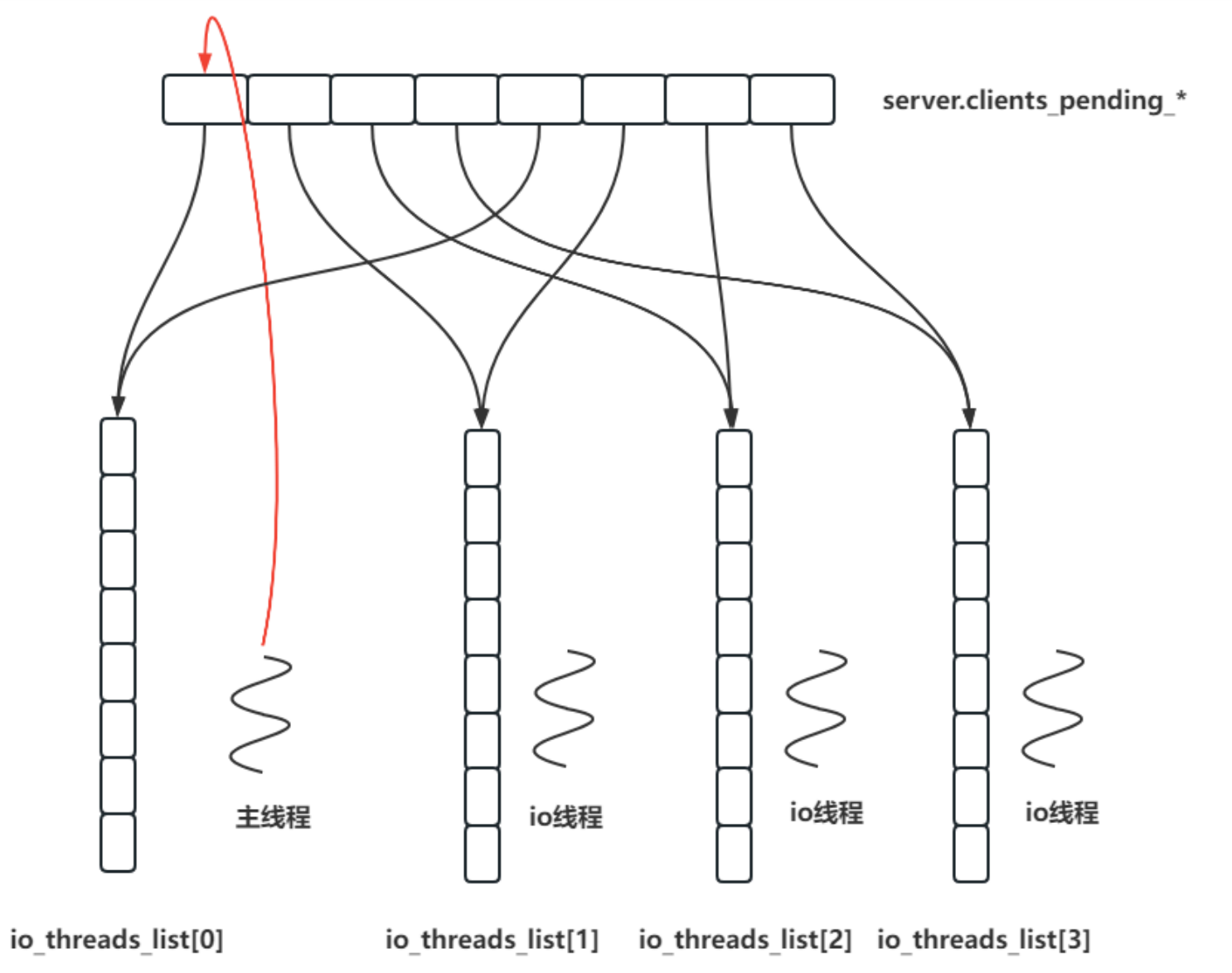
-
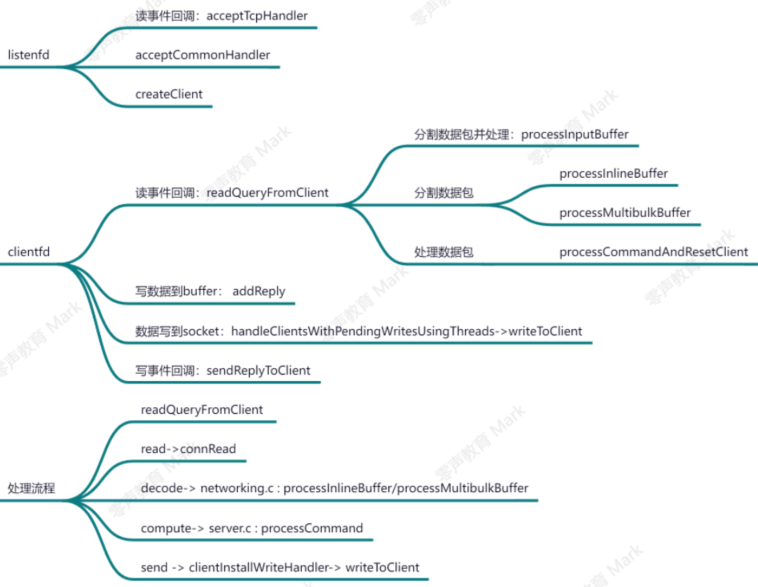
处理流程
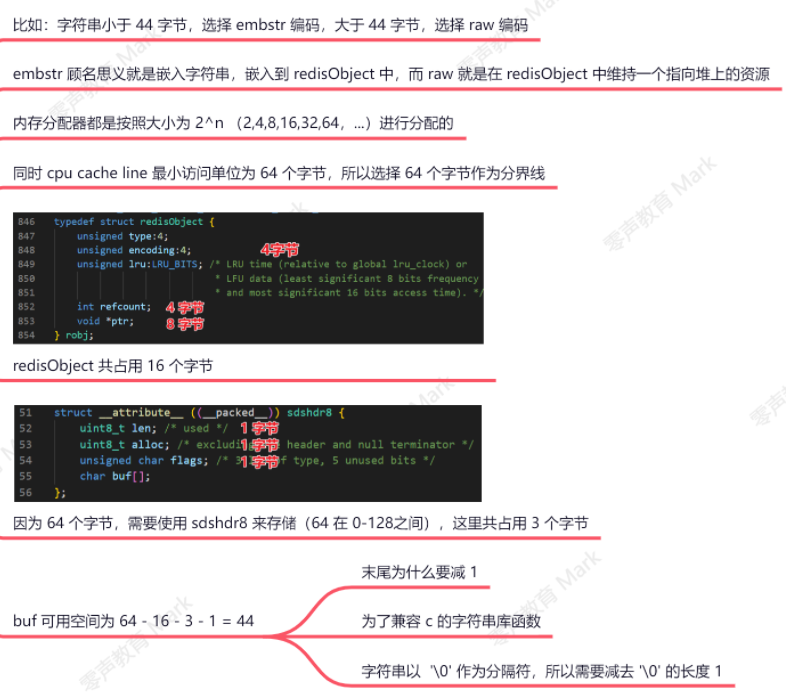
Q:为什么redis中字符串选择64字节为分界线?
*内存分配优化*: 小于64字节的字符串能映射到更小的内存块,避免浪费
*CPU缓存优化*: 64字节正好是cache line大小,提高访问效率
*SDS优化策略*: Redis会针对短字符串启用更激进的性能优化策略
*内存碎片控制*: 避免频繁内存分配、释放引起的碎片化
存储原理角度思考
优秀笔记:
1. 存储原理与数据模型
2. Redis 存储原理与数据模型(三)
参考学习:https://github.com/0voice