补充一种激活函数:GeGLU
GeGLU(Gated Gaussian Linear Unit)是一种激活函数,在神经网络中用于提高模型的表达能力,尤其在深度学习中的自注意力机制和 Transformer 模型中表现出色。GeGLU 是对 ReLU(Rectified Linear Unit) 和 GELU(Gaussian Error Linear Unit) 激活函数的一种改进,它结合了门控机制,并使用高斯分布的特性来对神经网络的非线性变换进行优化。
一、GeGLU 的数学公式
GeGLU 激活函数的形式如下:
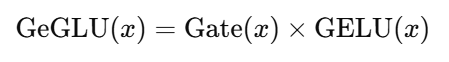
其中:
Gate(x)是一个门控函数,通常使用一个 线性变换 来计算:
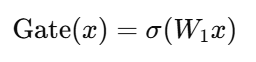
其中,σ\sigmaσ 是 Sigmoid 函数,W1 是权重矩阵,x 是输入。
GELU(x)是 Gaussian Error Linear Unit 函数:
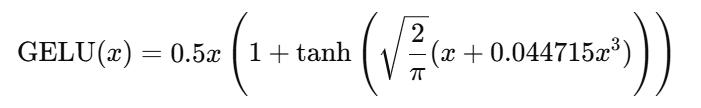
GELU 是一种平滑版本的 ReLU,利用高斯分布进行激活,可以在处理大规模数据时,减少梯度消失或爆炸问题。
GeGLU 的核心是将 GELU 激活 与 门控机制(使用 sigmoid 函数控制激活的强度) 结合,使得网络能够学习到更加复杂的非线性映射。
二、GeGLU 的优点
结合门控机制和高斯分布特性:
GeGLU 在某种程度上结合了 ReLU 和 GELU 的优点。通过门控机制对信息流进行有选择的控制,同时利用高斯分布的平滑性来更好地进行激活。
提高了非线性建模能力:
通过将输入信号与门控和 GELU 激活结合,GeGLU 可以在训练过程中捕捉到更加复杂和丰富的非线性模式,提升网络的表达能力。
更好的梯度流动性:
与传统的 ReLU 激活函数相比,GeGLU 在处理梯度时提供了更平滑的非线性映射,这有助于缓解梯度消失或梯度爆炸问题,尤其是在深层网络中。
对计算效率有益:
由于 GeGLU 结合了线性变换和门控机制,它在某些深度学习模型中表现出了比其他激活函数更高的训练速度和计算效率,尤其是在大规模数据和模型的训练中。
三、GeGLU 的应用场景
GeGLU 的特点使其非常适合于深度神经网络和复杂模型中的一些应用,特别是当需要处理大量输入数据并且关注非线性变换时。
Transformer 模型:
GeGLU 可以应用于 Transformer 模型中的前馈神经网络部分。由于其更好的梯度流动性,它帮助网络更好地学习复杂的表示,提升模型的训练效果和收敛速度。
自然语言处理(NLP)任务:
在 NLP 任务中,GeGLU 可以用于语义表示的生成,帮助 Transformer 模型在任务如机器翻译、文本生成等中表现更好。
图像识别和计算机视觉:
作为一种强化激活函数,GeGLU 也可用于计算机视觉模型中的卷积神经网络(CNN),尤其是在深度卷积网络中,能够有效提高性能。
生成式模型:
在生成式模型(如 GAN、VAE 等)中,GeGLU 能够帮助更有效地控制生成过程,使得生成的图像或文本具有更高的质量。
四、GeGLU 和其他激活函数的对比
| 特性 | GeGLU | ReLU | GELU |
|---|---|---|---|
| 非线性 | 更复杂,结合了门控和高斯分布特性 | 简单的非线性,直接将负值设置为0 | 平滑非线性,使用高斯分布 |
| 计算开销 | 较高(包含门控和高斯分布计算) | 低(仅仅是对负值进行修正) | 中等(包含高斯分布计算) |
| 梯度流动性 | 更好,平滑梯度流动 | 可能有梯度消失或爆炸的风险 | 更平滑,减轻梯度消失问题 |
| 收敛速度 | 较快,适用于深度网络 | 快,但在深层网络中可能出现问题 | 中等,适合较深网络 |
| 优点 | 结合门控机制和高斯分布优势 | 简单且高效,适用于大部分任务 | 更平滑的非线性,改进模型的鲁棒性 |
五、GeGLU 的局限性
计算复杂性较高:
相比 ReLU,GeGLU 引入了门控机制和 GELU 计算,导致其计算复杂性更高,可能在训练和推理时需要更多的计算资源。
对超参数的依赖较大:
GeGLU 在某些情况下可能对网络架构和超参数(如门控函数的权重)非常敏感,因此可能需要更多的调优工作。
未必适用于所有任务:
尽管 GeGLU 在一些任务中表现优异,但对于一些简单的任务或浅层网络,可能会不如 ReLU 或 GELU 效果好。
六、总结
GeGLU(Gated Gaussian Linear Unit)是一种结合门控机制和高斯分布特性的激活函数,在神经网络中表现出了更好的非线性建模能力、梯度流动性和计算效率。它通过将输入信号与 GELU 激活和门控机制相结合,增强了网络的表达能力,特别是在深度学习中的 Transformer 模型和生成式任务中。尽管 GeGLU 具有一些优势,但它的计算开销和对超参数的依赖也需要在实际应用中注意。