深度学习之pytorch安装与tensor(张量)
一、Pytorch安装
PyTorch 是由 Facebook AI Research 开发的一个开源深度学习框架,因其灵活的设计和简洁的 Python 接口而受到广泛欢迎。它最大的特点是采用动态图机制,允许用户像写普通 Python 代码一样动态构建神经网络结构,便于调试与实验。此外,PyTorch 拥有类似 NumPy 的张量(Tensor)计算功能,并且支持 GPU 加速和自动求导(autograd),适用于各种深度学习任务。通过 torch.nn 模块,用户可以方便地构建和训练神经网络模型。得益于其强大的生态系统(如 torchvision、torchaudio 等)以及活跃的社区支持,PyTorch 在计算机视觉、自然语言处理、强化学习等领域中得到了广泛应用,是目前学术研究和工业项目中主流的深度学习框架之一。
首先打开GEFOORCE进行显卡驱动更新

接着在安装pytorch之前首先要查看自己电脑的CUDA版本号,win+r打开cmd,输入nvidia-smi查看GPU驱动程序版本
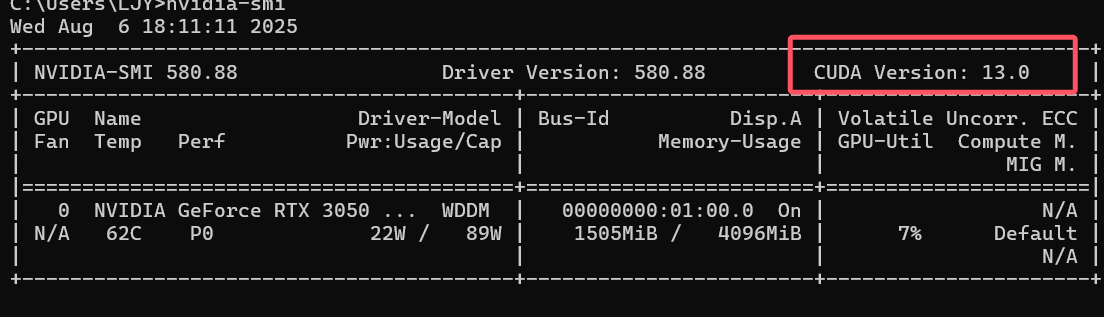
前往pytorch官网:https://pytorch.org/get-started/previous-versions/ 根据官方提供的安装指令安装比自己电脑CUDA版本号低的pytorch即可。

我这里选择的是安装这个上图这个版本。(由于安装包较大,建议在网络环境好的情况下进行安装,或使用VPN进行安装)
二、Pytorch核心—tensor
Tensor 是 PyTorch 的核心基础,几乎可以说是 PyTorch 的“灵魂”。
1.概念
在 PyTorch 中,Tensor(张量)是构建和操作神经网络的最基本数据结构,类似于 NumPy 的多维数组,但具有更强大的功能。Tensor 支持在 CPU 和 GPU 之间自由切换,能大幅提升深度学习任务的计算效率。此外,PyTorch 的自动求导机制(Autograd)正是围绕 Tensor 构建的,使其可以记录和追踪所有操作,从而在训练过程中实现反向传播和梯度更新。Tensor 不仅用于表示输入输出数据,还用于存储模型参数和中间计算结果,因此,熟练掌握 Tensor 的创建、变换、索引、广播及与 NumPy 的互操作,是学习和使用 PyTorch 的核心。简而言之,理解和掌握 Tensor 的使用,是深入学习 PyTorch 的第一步。
- 标量 :0 维张量,如
a = torch.tensor(5) - 向量 : 1 维张量,如
b = torch.tensor([2, 3, 4]) - 矩阵 : 2 维张量,如
c = torch.tensor([[1, 2], [3, 4]])
2.tensor的创建
在pytorch中,tensor以“类”的形式封装起来,一些对tensor的运算、处理的方法都被封装在类中,详细请参考官方文档:https://pytorch.org/docs/stable/torch.html#tensors
接下来介绍几种创建tensor的基本方法。
torch.tensor()
torch.tensor() 是 PyTorch 中最常用、最通用的张量创建方法之一,它可以将 Python 中的列表、元组、NumPy 数组等数据结构直接转换为张量。
import torch
import numpy as npdef test1():t1 = torch.tensor([1, 2, 3])print(t1)t2 = torch.tensor([[1, 2, 5], [3, 6, 9]])print(t2.shape)t3 = torch.tensor(np.random.randint(0, 10, (3, 4)))print(t3)if __name__ == '__main__':test1()
# tensor([1, 2, 3])
# torch.Size([2, 3])
# tensor([[6, 5, 7, 1],
# [9, 8, 4, 6],
# [9, 4, 3, 5]], dtype=torch.int32)
torch.Tensor()
注意这里的Tensor是大写,该API根据形状创建张量,其也可用来创建指定数据的张量。
import torch
import numpy as npdef test2():t1 = torch.Tensor([1, 2, 3])print(t1)t2 = torch.Tensor(3, 4)print(t2)if __name__ == '__main__':test2()# tensor([1., 2., 3.])
# tensor([[-7.1016e-18, 1.9002e-42, 0.0000e+00, 0.0000e+00],
# [ 0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00],
# [ 0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00]])
torch.tensor() 与 torch.Tensor()的区别:
| 比较项 | torch.tensor() | torch.Tensor() |
|---|---|---|
| 推荐程度 | ✅ 推荐使用 | ❌ 不推荐(旧式风格) |
| 用途 | 从已有数据创建一个张量副本 | 构造一个张量,行为取决于参数类型(可能是空张量) |
| 是否初始化数据 | 是(复制输入数据) | 不一定,传形状参数时不会初始化内容,类似 torch.empty() |
| 参数支持 | 支持 dtype、device、requires_grad、copy 等 | 不支持这么多参数,功能有限 |
| 常见用途 | 用于明确创建张量,如从 list、numpy 等创建 | 早期 PyTorch 用法,有潜在初始化错误风险 |
| 示例(安全) | torch.tensor([1, 2, 3]) | torch.Tensor([1, 2, 3]) |
| 示例(危险) | - | torch.Tensor(2, 3) → 得到未初始化的随机值 |
创建随机张量:
常见的创建随机张量的方法:
| 函数 | 作用说明 | 示例 | 输出说明 |
|---|---|---|---|
torch.rand(size) | 从 [0, 1) 的均匀分布中采样 | torch.rand(3) | [0, 1) 区间内的随机数 |
torch.randn(size) | 从标准正态分布 N(0, 1) 中采样 | torch.randn(3) | 均值为 0,标准差为 1 的正态分布数 |
torch.randint(low, high, size) | 在 [low, high) 区间内生成整数随机数 | torch.randint(0, 10, (3,)) | 包括 0,不包括 10 的整数 |
torch.randperm(n) | 生成 0 到 n-1 的随机排列 | torch.randperm(5) | 例如:tensor([3,1,4,0,2]) |
torch.empty(size).uniform_(a, b) | 在 [a, b) 区间内生成均匀分布 | torch.empty(3).uniform_(0, 5) | 更细粒度控制区间 |
torch.empty(size).normal_(mean, std) | 从 N(mean, std) 分布采样 | torch.empty(3).normal_(0, 1) | 控制均值与标准差的正态分布采样 |
在pytorch中可以使用使用torch.manual_seed()设置随机时间种子,通过设置随机数种子,可以做到模型训练和实验结果在不同的运行中进行复现。
示例:
import torch
import numpy as npdef test3():# 设置随机时间种子torch.manual_seed(486)# 创建随机张量t1 = torch.rand(2, 3)t2 = torch.randn(2, 3)t3 = torch.randint(0, 10, (2, 3))print(t1)print(t2)print(t3)if __name__ == '__main__':test3()# tensor([[0.0247, 0.9529, 0.6178],
# [0.8909, 0.8222, 0.7215]])
# tensor([[ 0.4583, -1.0574, 1.2331],
# [-1.3427, -1.5409, -0.4013]])
# tensor([[1, 5, 9],
# [5, 4, 7]])
注意:在不使用时间种子的情况下,每次打印的结果都不一样。
3.tensor常见操作
常见属性
| 属性/方法 | 说明 | 示例 | 返回值类型 |
|---|---|---|---|
tensor.size() | 返回张量的尺寸(各维度大小) | x.size() | torch.Size 对象 |
tensor.shape | 等同于 tensor.size(),更常用于访问属性 | x.shape | torch.Size 对象 |
tensor.ndim | 返回张量的维度数 | x.ndim | int |
tensor.numel() | 返回张量中所有元素的总数 | x.numel() | int |
tensor.dtype | 数据类型 | x.dtype | torch.dtype |
tensor.device | 当前张量所在的设备(CPU/GPU) | x.device | torch.device |
tensor.requires_grad | 是否需要梯度计算 | x.requires_grad | bool |
tensor.is_cuda | 是否存储在 CUDA(GPU)上 | x.is_cuda | bool |
tensor.T | 转置(仅限 2D 张量) | x.T | Tensor |
示例:
import torch
import numpy as npdef test4():t1 = torch.tensor([[1, 3, 5], [2, 6, 9]])print(t1.shape, t1.size(), t1.dtype, t1.device)if __name__ == '__main__':test4()# torch.Size([2, 3]) torch.Size([2, 3]) torch.int64 cpu
注意:这里t1.shape 和 t1.size()返回的都是torch.size,也就是张量的形状。
tensor转numpy
调用numpy()方法,这种方法属于浅拷贝,此时转换前和转换后的变量内存是共享的。
示例:
import torch
import numpy as npdef test5():t1 = torch.tensor([1, 2, 3])new_t1 = t1.numpy()new_t1[0] = 100print(t1)if __name__ == '__main__':test5()# tensor([100, 2, 3])
调用numpy().copy()方法,这种方法属于深拷贝,能够避免内存共享。
示例:
import torch
import numpy as npdef test6():t1 = torch.tensor([1, 2, 3])new_t1 = t1.numpy().copy()new_t1[0] = 100print(t1)if __name__ == '__main__':test6()# tensor([1, 2, 3])
numpy转tensor
调用from_numpy()方法转tensor,这种方法也属于浅拷贝。
import torch
import numpy as npdef test7():data = np.array([1, 2, 3])t = torch.from_numpy(data)t[0] = 100print(data)if __name__ == '__main__':test7()# [100 2 3]
也可直接使用torch.tensor()将numpy数组转为tensor,这种方法为深拷贝,这里我就不再演示,这个方法也是创建tensor的方法。
获取单个元素值
我们可以使用item()方法来获取只有单个元素的tensor值。
import torch
import numpy as npdef test8():t = torch.tensor([[666]])data = t.item()print(data)if __name__ == '__main__':test8()
# 666
注意:这里说的是单个元素,也就是说无论维度是多少,**只要是单个元素的张量都能够获取到它的值,如果不是单个元素则会报错。**并且仅适用于CPU张量,如果张量在GPU上,需先移动到CPU。
设备切换
上面我们提到将张量移动到CPU,一般情况下在使用**torch.tensor()**创建张量时默认的设备为CPU,我们可以在创建张量时直接创建在GPU上:
# 直接在GPU上创建张量
data = torch.tensor([1, 2, 3], device='cuda')
print(data.device)
也可以使用to()方法进行切换
import torch
import numpy as npdef test9():t = torch.tensor([1, 2, 3])print(t.device)device = "cuda" if torch.cuda.is_available() else "cpu"t = t.to(device)print(t.device)if __name__ == '__main__':test9()
# cpu
# cuda:0
阿达玛积
阿达玛积是指两个形状相同的矩阵或张量对应位置的元素相乘。它与矩阵乘法不同,矩阵乘法是线性代数中的标准乘法,而阿达玛积是逐元素操作。假设有两个形状相同的矩阵 A和 B,它们的阿达玛积 C=A∘B定义为:
Cij=Aij×Bij
C_{ij}=A_{ij}×B_{ij}
Cij=Aij×Bij
其中:
- Cij 是结果矩阵 C的第 i行第 j列的元素。
- Aij和 Bij分别是矩阵 A和 B的第 i行第 j 列的元素。
总结一句话就是两个矩阵的对应位置元素相乘
在pytorch中用mul()函数或*来实现:
import torch
import numpy as npdef test10():t1 = torch.tensor([1, 2, 3])t2 = torch.tensor([2, 3, 4])t_a = t1 * t2t_b = t1.mul(t2)print(t_a)print(t_b)if __name__ == '__main__':test10()# tensor([ 2, 6, 12])
# tensor([ 2, 6, 12])tensor相乘
矩阵乘法是线性代数中的一种基本运算,用于将两个矩阵相乘,生成一个新的矩阵。
假设有两个矩阵:
- 矩阵 A的形状为 m×n(m行 n列)。
- 矩阵 B的形状为 n×p(n行 p列)。
矩阵 A和 B的乘积 C=A×B是一个形状为 m×p的矩阵,其中 C的每个元素 Cij,计算 A的第 i行与 B的第 j列的点积。计算公式为:
Cij=∑k=1nAik×Bkj
C_{ij}=∑_{k=1}^nA_{ik}×B_{kj}
Cij=k=1∑nAik×Bkj
矩阵乘法运算要求如果第一个矩阵的shape是 (N, M),那么第二个矩阵 shape必须是 (M, P),最后两个矩阵点积运算的shape为 (N, P)。
pytorch中可以使用@或者matmul完整矩阵乘法运算:
import torchdef test11():data1 = torch.tensor([[1, 2, 3],[4, 5, 6]])data2 = torch.tensor([[3, 2],[2, 3],[5, 3]])print(data1 @ data2)print(data1.matmul(data2))if __name__ == '__main__':test11()# tensor([[22, 17],
# [52, 41]])
# tensor([[22, 17],
# [52, 41]])
形状改变
在pytorch中可以使用reshape()和 view两种方法对张量的形状进行变换。
内存连续性:张量的内存布局决定了其元素在内存中的存储顺序。对于多维张量,内存布局通常按照最后一个维度优先的顺序存储,即先存列,后存行。例如,对于一个二维张量 A,其形状为 (m, n),其内存布局是先存储第 0 行的所有列元素,然后是第 1 行的所有列元素,依此类推。
如果张量的内存布局与形状完全匹配,并且没有被某些操作(如转置、索引等)打乱,那么这个张量就是连续的。PyTorch 的大多数操作都是基于 C 顺序的,我们在进行变形或转置操作时,很容易造成内存的不连续性。
reshape和view变换张量形状的区别:
| 特性 / 方法 | reshape() | view() |
|---|---|---|
| 返回值类型 | 新的张量,可能是原张量的拷贝或视图 | 总是返回一个视图(view) |
| 是否共享内存 | 可能共享,也可能不共享内存 | 一定共享内存(和原张量共用数据) |
| 是否可用于非连续张量 | ✅ 可以自动处理非连续张量 | ❌ 只适用于连续内存张量 |
| 性能 | 通常略慢于 view()(因为可能涉及复制) | 更快(仅改变视图而不复制) |
| 失败风险 | 较低,自动处理多种情况 | 如果张量不连续,会抛出错误 |
| 适用场景推荐 | 更通用,推荐在不确定张量是否连续时使用 | 需要高性能并确认张量是连续时使 |
升维和降维:
降维: torch.squeeze()
torch.squeeze(input, dim=None)
- input:输入的张量。
- dim (可选): 指定要移除的维度。如果指定了 dim,则只移除该维度(前提是该维度大小为 1);如果不指定,则移除所有大小为 1 的维度。若指定维度的大小不为1,虽然降维不会成功,但不会报错。
升维:torch。unsqueeze()
torch.unsqueeze(input, dim)
-
input:输入的张量
-
dim: 指定要增加维度的位置(从 0 开始索引)。
以上内容是博主学习深度学习的一些总结笔记,若文章中出现错误请及时指正博主,感谢浏览☆噜~☆