《算法导论》第 8 章—线性时间排序
目录
编辑
编辑
8.1 排序算法的下界
8.1.1 比较排序的模型
8.1.2 决策树模型
8.1.3 下界证明
编辑
8.2 计数排序
8.2.1 基本思想
8.2.2完整 C++ 代码
编辑
8.2.3综合案例:学生成绩排序与排名
编辑
8.2.4复杂度分析
编辑
8.3 基数排序
8.3.1 基本思想
8.3.2完整 C++ 代码(LSD 方法)
编辑
8.3.3 综合案例:电话号码排序
编辑
8.3.4复杂度分析
8.4 桶排序
8.4.1 基本思想
8.4.2 完整 C++ 代码
编辑
8.4.3 综合案例:员工工资排序
编辑
8.4.4复杂度分析
思考题
编辑
本章注记
总结
大家好!今天我们来深入探讨《算法导论》第 8 章的内容 ——线性时间排序。与我们之前学过的比较排序(如快速排序、归并排序)不同,本章介绍的排序算法不基于比较操作,因此能够突破 Ω(n log n) 的时间复杂度下界,在特定条件下达到 O (n) 的线性时间。

本文将按照原书结构,详细讲解排序算法的下界、计数排序、基数排序和桶排序,并提供完整可运行的 C++ 代码和应用案例,帮助大家更好地理解和实践这些算法。

8.1 排序算法的下界
在学习线性时间排序之前,我们首先需要理解:为什么基于比较的排序算法无法突破 O (n log n) 的时间复杂度?
8.1.1 比较排序的模型
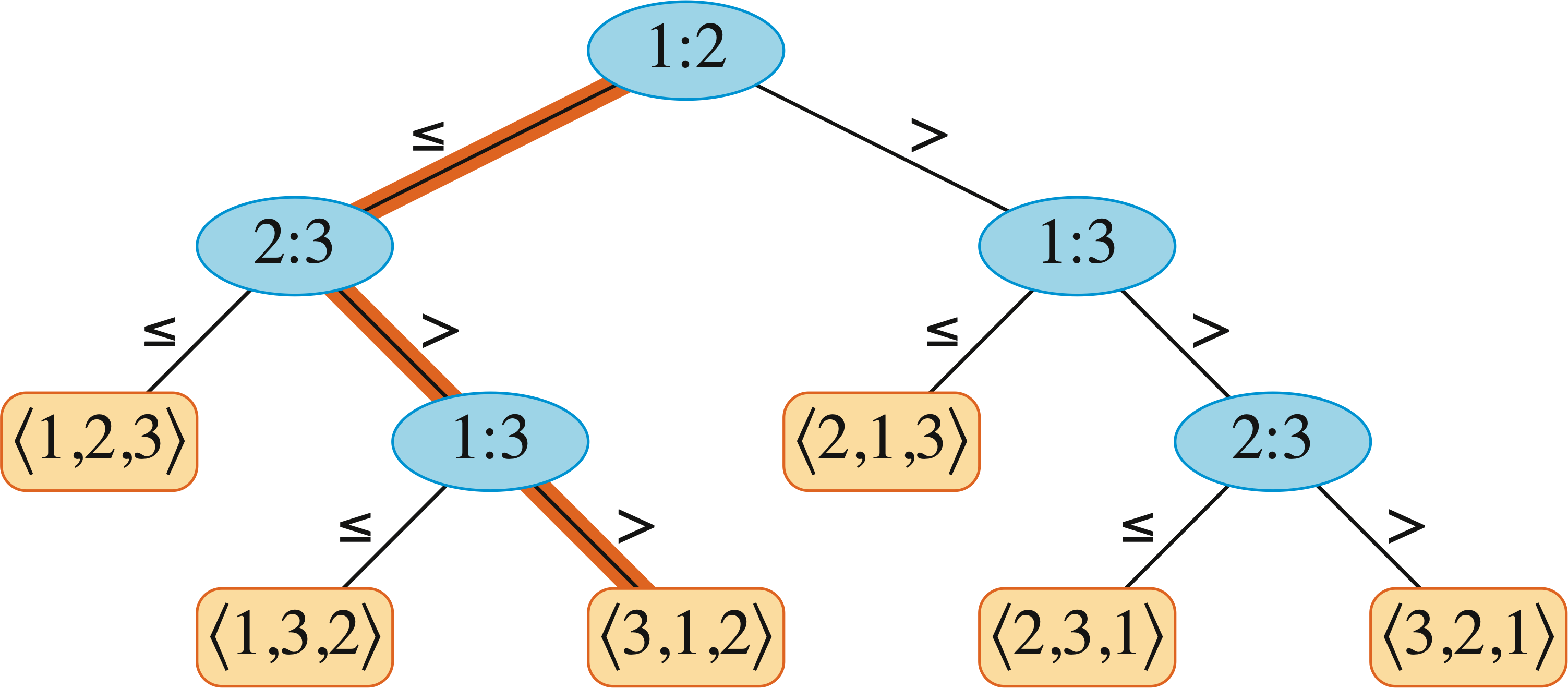
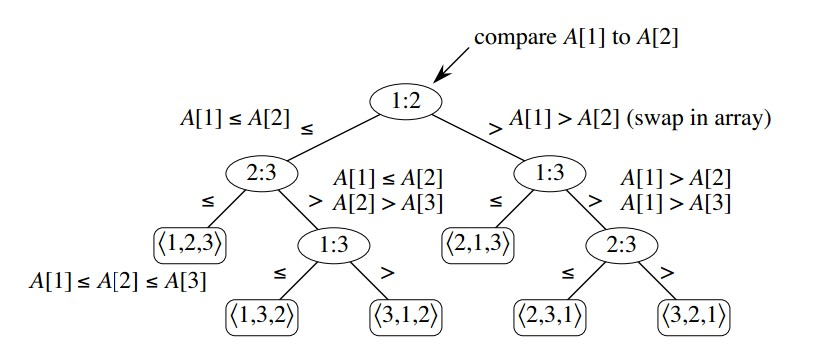
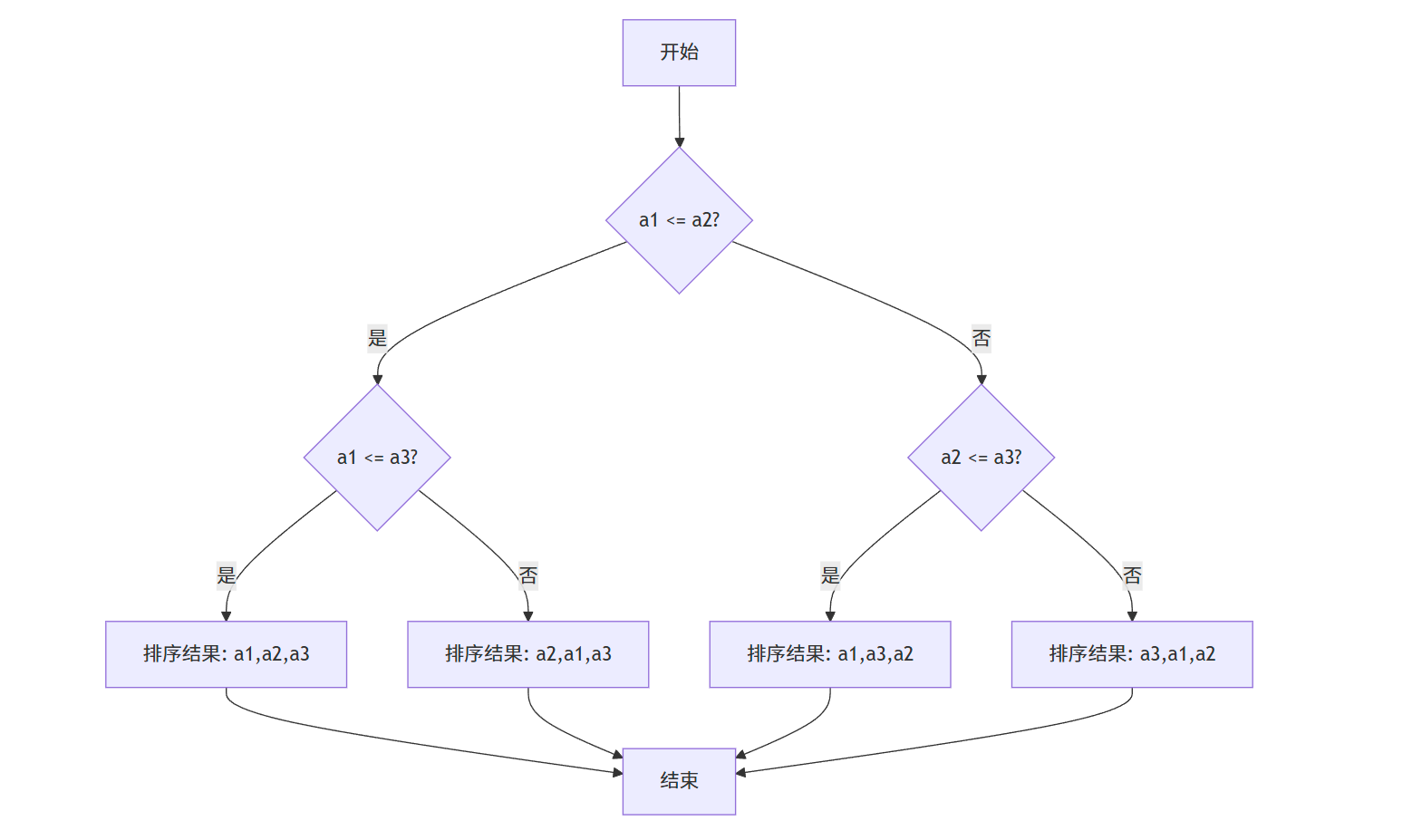
比较排序是指仅通过比较元素间的大小来决定它们的相对顺序的排序算法(如冒泡、插入、快排、归并等)。这类算法可以抽象为一棵决策树。
8.1.2 决策树模型
决策树是一棵二叉树,每个内部节点表示一次比较(如 a ≤ b?),叶节点表示一个排序结果。排序算法的执行过程就是从根节点到叶节点的一条路径。
8.1.3 下界证明
- 对于 n 个元素,有 n! 种可能的排列(叶节点数 ≥ n!)。
- 高度为 h 的二叉树最多有 2^h 个叶节点。
- 因此:2^h ≥ n! → h ≥ log2 (n!)
- 根据斯特林公式:n! ≈ n^n e^(-n)√(2πn),可得 log2 (n!) = Ω(n log n)
- 故任何比较排序算法的最坏情况时间复杂度为 Ω(n log n)。
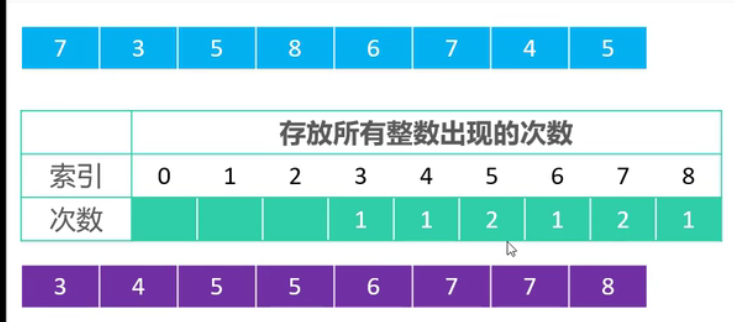
8.2 计数排序
计数排序是一种不基于比较的排序算法,适用于元素范围较小的整数排序(如 0 到 k 的整数)。
8.2.1 基本思想
- 统计每个元素出现的次数;
- 计算每个元素在输出数组中的起始位置;
- 将元素放入输出数组的对应位置。
8.2.2完整 C++ 代码
#include <iostream>
#include <vector>
#include <algorithm>using namespace std;// 计数排序函数
vector<int> countingSort(const vector<int>& A) {if (A.empty()) return {};// 找出数组中的最小值和最大值int min_val = *min_element(A.begin(), A.end());int max_val = *max_element(A.begin(), A.end());int range = max_val - min_val + 1;// 初始化计数数组和输出数组vector<int> count(range, 0);vector<int> output(A.size());// 统计每个元素出现的次数for (int num : A) {count[num - min_val]++;}// 计算前缀和,确定每个元素的结束位置for (int i = 1; i < range; i++) {count[i] += count[i - 1];}// 反向遍历原数组,保证稳定性for (int i = A.size() - 1; i >= 0; i--) {int num = A[i];int idx = count[num - min_val] - 1;output[idx] = num;count[num - min_val]--;}return output;
}int main() {vector<int> A = {4, 2, 2, 8, 3, 3, 1};cout << "Original array: ";for (int num : A) {cout << num << " ";}cout << endl;vector<int> sorted_A = countingSort(A);cout << "Sorted array: ";for (int num : sorted_A) {cout << num << " ";}cout << endl;return 0;
}
8.2.3综合案例:学生成绩排序与排名
假设有 100 名学生,成绩在 0-100 之间,用计数排序快速排序并计算排名。
#include <iostream>
#include <vector>
#include <algorithm>
#include <random>using namespace std;// 学生结构体(添加默认构造函数)
struct Student {int id;int score;// 默认构造函数(无参)Student() : id(0), score(0) {}// 带参数的构造函数Student(int i, int s) : id(i), score(s) {}
};// 基于成绩的计数排序(稳定排序,保持同分数学生的原始顺序)
vector<Student> countSortStudents(const vector<Student>& students) {if (students.empty()) return {};// 成绩范围固定为0-100int min_score = 0;int max_score = 100;int range = max_score - min_score + 1;vector<int> count(range, 0);vector<Student> output(students.size()); // 此处需要默认构造函数// 统计每个分数的人数for (const auto& s : students) {count[s.score - min_score]++;}// 计算前缀和(得到每个分数的最后位置)for (int i = 1; i < range; i++) {count[i] += count[i - 1];}// 反向遍历,保持稳定性for (int i = students.size() - 1; i >= 0; i--) {const auto& s = students[i];int idx = count[s.score - min_score] - 1;output[idx] = s; // 调用拷贝构造函数count[s.score - min_score]--;}return output;
}// 计算排名(同分同排名)
vector<int> calculateRanks(const vector<Student>& sorted_students) {vector<int> ranks(sorted_students.size());if (sorted_students.empty()) return ranks;ranks[0] = 1;for (int i = 1; i < sorted_students.size(); i++) {if (sorted_students[i].score == sorted_students[i - 1].score) {ranks[i] = ranks[i - 1]; // 同分同排名} else {ranks[i] = i + 1; // 排名为位置+1}}return ranks;
}int main() {// 生成100名学生,成绩随机0-100vector<Student> students;random_device rd;mt19937 gen(rd());uniform_int_distribution<> dis(0, 100);for (int i = 0; i < 100; i++) {students.emplace_back(i + 1, dis(gen)); // id从1开始}// 排序vector<Student> sorted_students = countSortStudents(students);// 计算排名vector<int> ranks = calculateRanks(sorted_students);// 输出前10名和后10名cout << "前10名学生(ID 分数 排名):" << endl;for (int i = 0; i < 10; i++) {cout << sorted_students[i].id << "\t" << sorted_students[i].score << "\t" << ranks[i] << endl;}cout << "\n后10名学生(ID 分数 排名):" << endl;for (int i = 90; i < 100; i++) {cout << sorted_students[i].id << "\t" << sorted_students[i].score << "\t" << ranks[i] << endl;}return 0;
}
8.2.4复杂度分析
| 时间复杂度 | 空间复杂度 | 稳定性 | 适用场景 |
|---|---|---|---|
| O(n + k) | O(n + k) | 稳定 | 元素范围 k 较小的整数排序 |
- n 是元素个数,k 是元素的范围(max - min + 1)。
- 当 k = O (n) 时,时间复杂度为 O (n)。
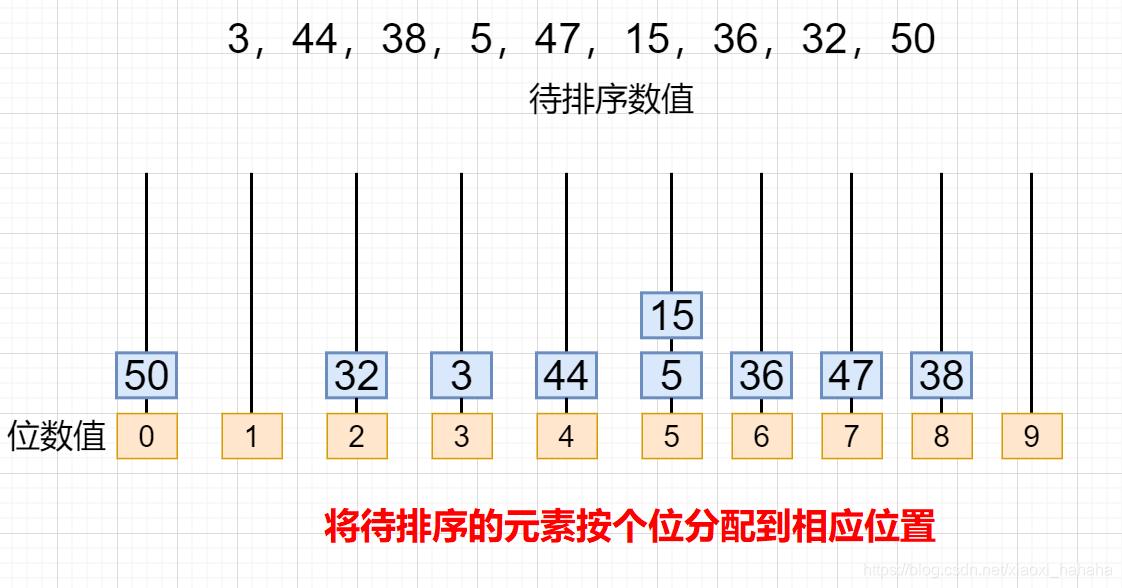
8.3 基数排序
基数排序通过按位排序来实现整体排序,适用于整数或可以表示为固定位数的字符串等。
8.3.1 基本思想
- 从最低有效位(LSD) 到最高有效位(MSD) 依次排序;
- 每一位的排序使用稳定排序算法(如计数排序);
- 经过所有位的排序后,数组整体有序。
8.3.2完整 C++ 代码(LSD 方法)
#include <iostream>
#include <vector>
#include <algorithm>using namespace std;// 获取x的第d位数字(从右数,d=1表示个位)
int getDigit(int x, int d) {for (int i = 1; i < d; i++) {x /= 10;}return x % 10;
}// 对数组按第d位进行稳定排序(使用计数排序)
void countingSortByDigit(vector<int>& A, int d) {int n = A.size();vector<int> output(n);vector<int> count(10, 0); // 0-9共10个数字// 统计第d位数字的出现次数for (int i = 0; i < n; i++) {int digit = getDigit(A[i], d);count[digit]++;}// 计算前缀和for (int i = 1; i < 10; i++) {count[i] += count[i - 1];}// 反向遍历,保持稳定性for (int i = n - 1; i >= 0; i--) {int digit = getDigit(A[i], d);int idx = count[digit] - 1;output[idx] = A[i];count[digit]--;}// 将结果复制回原数组A = output;
}// 基数排序(LSD方法)
void radixSort(vector<int>& A) {if (A.empty()) return;// 找到最大元素,确定最大位数int max_val = *max_element(A.begin(), A.end());int max_digits = 0;while (max_val > 0) {max_digits++;max_val /= 10;}// 从最低位到最高位依次排序for (int d = 1; d <= max_digits; d++) {countingSortByDigit(A, d);}
}// 测试函数
int main() {vector<int> A = {170, 45, 75, 90, 802, 24, 2, 66};cout << "原始数组: ";for (int num : A) {cout << num << " ";}cout << endl;radixSort(A);cout << "排序后数组: ";for (int num : A) {cout << num << " ";}cout << endl;return 0;
}
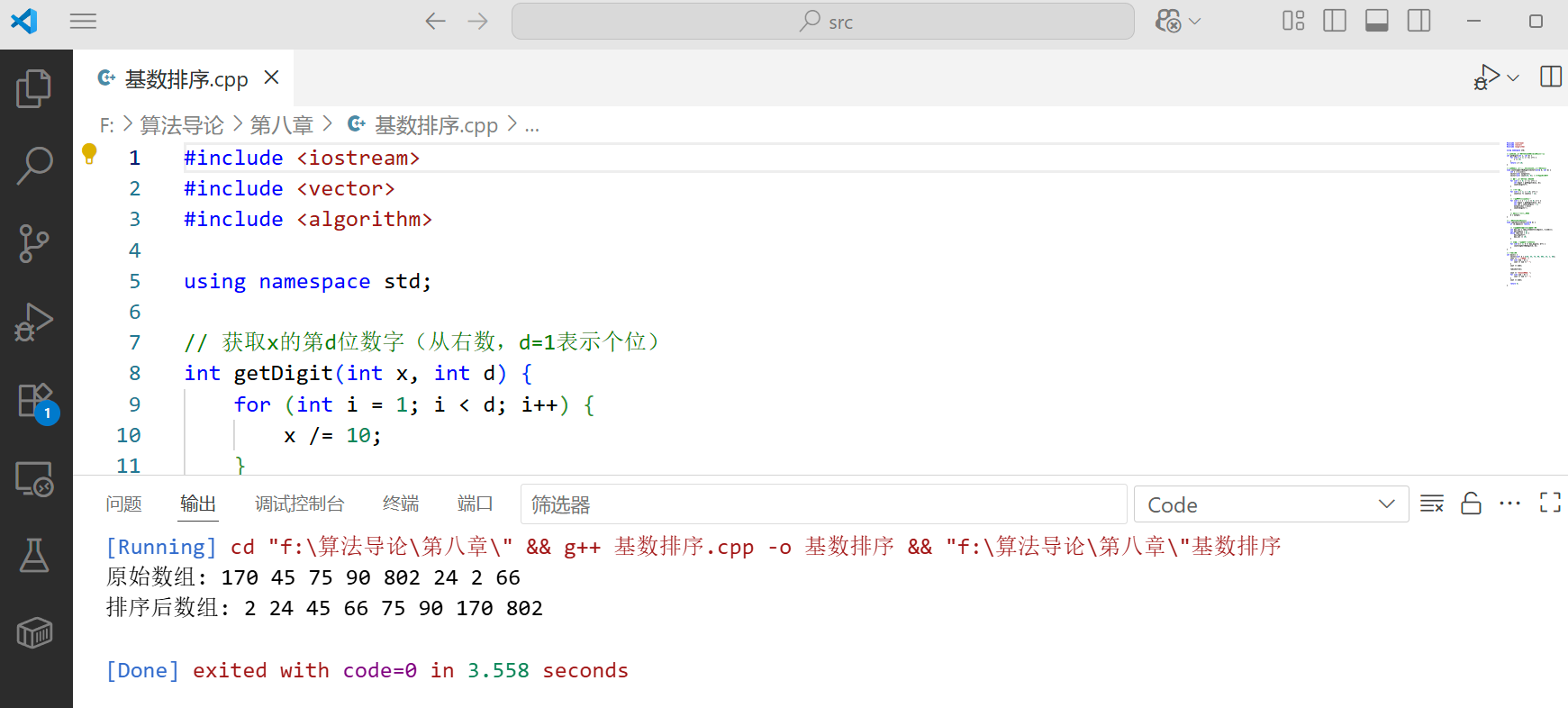
8.3.3 综合案例:电话号码排序
电话号码通常是固定长度的数字串,非常适合用基数排序。
#include <iostream>
#include <vector>
#include <string>using namespace std;// 假设电话号码是11位数字字符串(如中国手机号)
// 获取第d位数字(d=1表示最后一位,d=11表示第一位)
char getPhoneDigit(const string& phone, int d) {// 手机号格式:1xx xxxx xxxx,共11位,索引0-10int index = 11 - d; // d=1对应索引10(最后一位),d=11对应索引0(第一位)return phone[index];
}// 按第d位对电话号码进行稳定排序
void countingSortPhone(vector<string>& phones, int d) {int n = phones.size();vector<string> output(n);vector<int> count(10, 0); // 0-9// 统计第d位数字的出现次数for (const string& p : phones) {char c = getPhoneDigit(p, d);int digit = c - '0';count[digit]++;}// 计算前缀和for (int i = 1; i < 10; i++) {count[i] += count[i - 1];}// 反向遍历,保持稳定性for (int i = n - 1; i >= 0; i--) {const string& p = phones[i];char c = getPhoneDigit(p, d);int digit = c - '0';int idx = count[digit] - 1;output[idx] = p;count[digit]--;}phones = output;
}// 对11位电话号码进行基数排序
void radixSortPhones(vector<string>& phones) {if (phones.empty()) return;// 电话号码固定11位,从第1位(最后一位)到第11位(第一位)排序for (int d = 1; d <= 11; d++) {countingSortPhone(phones, d);}
}int main() {vector<string> phones = {"13812345678","13987654321","13511112222","13633334444","13755556666","13099998888","13177776666"};cout << "原始电话号码: " << endl;for (const string& p : phones) {cout << p << endl;}radixSortPhones(phones);cout << "\n排序后电话号码: " << endl;for (const string& p : phones) {cout << p << endl;}return 0;
}
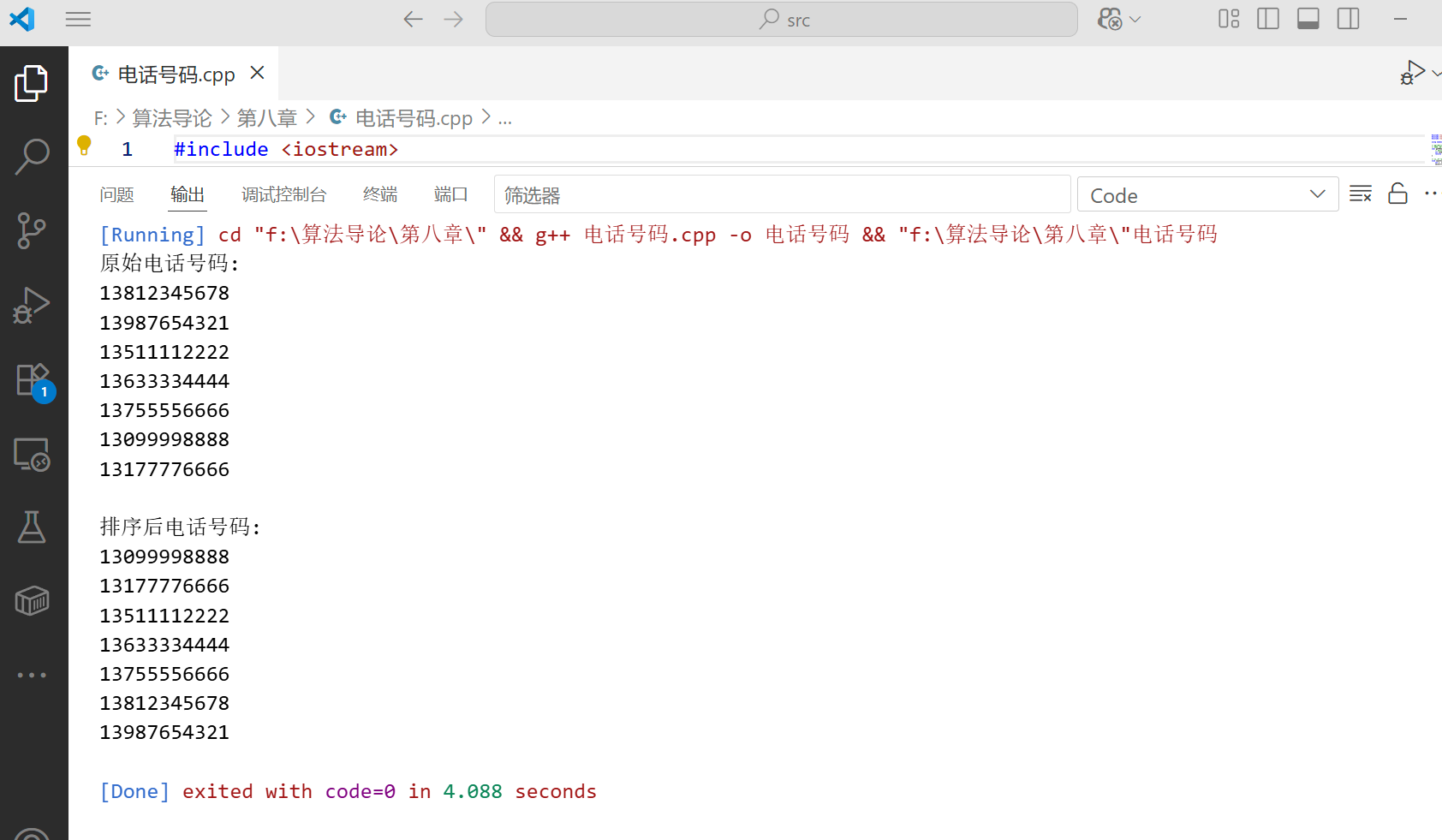
8.3.4复杂度分析
| 时间复杂度 | 空间复杂度 | 稳定性 | 适用场景 |
|---|---|---|---|
| O(d*(n + r)) | O(n + r) | 稳定 | 位数固定的整数、字符串等 |
- d 是最大元素的位数,r 是基数(如十进制 r=10)。
- 当 d 为常数且 r = O (n) 时,时间复杂度为 O (n)。
8.4 桶排序
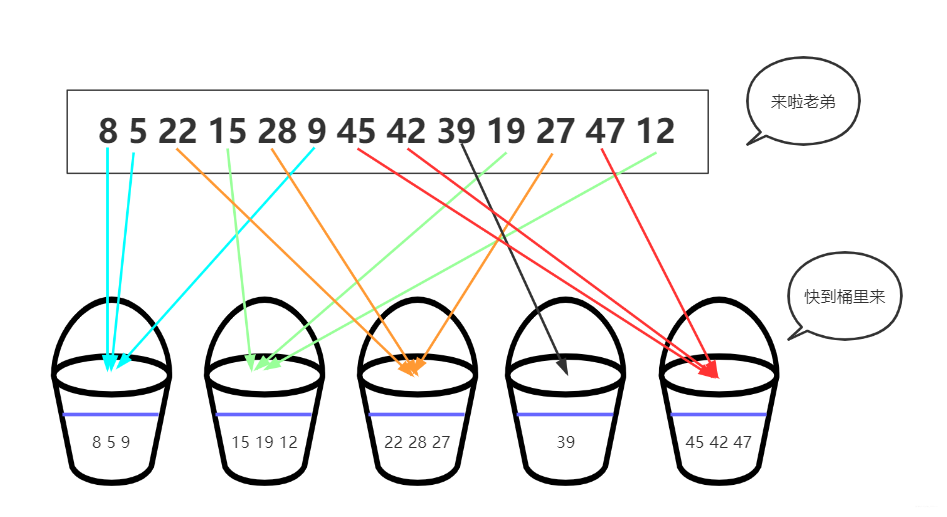
桶排序假设输入数据服从均匀分布,通过将数据分到不同的桶中,再对每个桶单独排序。
8.4.1 基本思想
- 创建若干个空桶;
- 将输入数据根据映射函数分配到对应的桶中;
- 对每个非空桶进行排序(可使用其他排序算法);
- 按顺序合并所有桶中的数据。
8.4.2 完整 C++ 代码
#include <iostream>
#include <vector>
#include <algorithm>
#include <random>using namespace std;// 桶排序(假设输入是[0,1)区间的均匀分布浮点数)
void bucketSort(vector<float>& A) {int n = A.size();if (n == 0) return;// 步骤1: 创建n个空桶vector<vector<float>> buckets(n);// 步骤2: 将元素分配到桶中for (float num : A) {int bucket_idx = n * num; // 映射函数:[0,1) → [0,n-1]buckets[bucket_idx].push_back(num);}// 步骤3: 对每个桶进行排序(使用标准库的sort)for (auto& bucket : buckets) {sort(bucket.begin(), bucket.end());}// 步骤4: 合并所有桶int idx = 0;for (const auto& bucket : buckets) {for (float num : bucket) {A[idx++] = num;}}
}// 测试函数
int main() {// 生成10个[0,1)区间的随机浮点数vector<float> A(10);random_device rd;mt19937 gen(rd());uniform_real_distribution<> dis(0.0, 1.0);for (int i = 0; i < 10; i++) {A[i] = dis(gen);}cout << "原始数组: ";for (float num : A) {cout << num << " ";}cout << endl;bucketSort(A);cout << "排序后数组: ";for (float num : A) {cout << num << " ";}cout << endl;return 0;
}
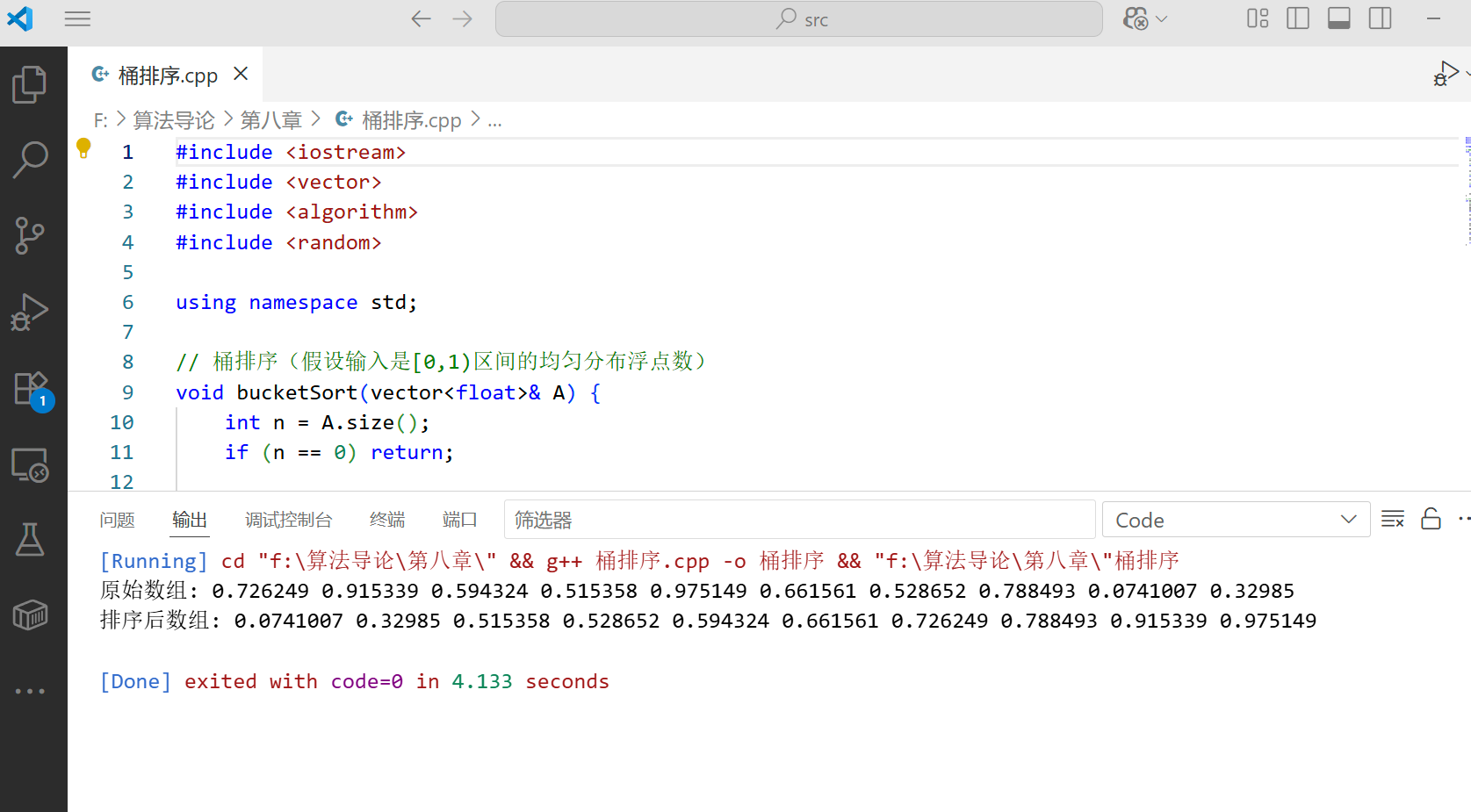
8.4.3 综合案例:员工工资排序
假设某公司员工工资在 3000-10000 元之间,且服从均匀分布,用桶排序快速排序。
#include <iostream>
#include <vector>
#include <algorithm>
#include <random>using namespace std;struct Employee {string name;int salary;Employee(string n, int s) : name(n), salary(s) {}
};// 桶排序员工工资(工资范围3000-10000)
void bucketSortEmployees(vector<Employee>& employees) {int n = employees.size();if (n == 0) return;// 确定桶的数量和范围(每1000元一个桶)int min_salary = 3000;int max_salary = 10000;int bucket_count = (max_salary - min_salary) / 1000 + 1; // 8个桶vector<vector<Employee>> buckets(bucket_count);// 分配员工到对应桶for (const Employee& emp : employees) {int bucket_idx = (emp.salary - min_salary) / 1000;buckets[bucket_idx].push_back(emp);}// 对每个桶按工资排序for (auto& bucket : buckets) {sort(bucket.begin(), bucket.end(), [](const Employee& a, const Employee& b) {return a.salary < b.salary;});}// 合并桶employees.clear();for (const auto& bucket : buckets) {for (const Employee& emp : bucket) {employees.push_back(emp);}}
}int main() {// 生成15名员工,工资3000-10000随机vector<Employee> employees;random_device rd;mt19937 gen(rd());uniform_int_distribution<> dis(3000, 10000);for (int i = 0; i < 15; i++) {string name = "员工" + to_string(i + 1);employees.emplace_back(name, dis(gen));}cout << "原始员工列表(姓名 工资):" << endl;for (const auto& emp : employees) {cout << emp.name << "\t" << emp.salary << endl;}bucketSortEmployees(employees);cout << "\n按工资排序后:" << endl;for (const auto& emp : employees) {cout << emp.name << "\t" << emp.salary << endl;}return 0;
}
8.4.4复杂度分析
| 时间复杂度(平均) | 时间复杂度(最坏) | 空间复杂度 | 稳定性 | 适用场景 |
|---|---|---|---|---|
| O(n) | O(n^2) | O(n + m) | 稳定 | 均匀分布的数据 |
- n 是元素个数,m 是桶的数量。
- 当输入均匀分布时,每个桶的大小为 O (n/m),总时间为 O (n + m*(n/m log (n/m))) = O (n + n log (n/m)),当 m = O (n) 时为 O (n)。
思考题
- 比较计数排序、基数排序和桶排序的适用场景,分别举例说明。
- 如何修改计数排序来处理负整数?
- 基数排序中,如果使用非稳定的子排序算法,会出现什么问题?
- 桶排序的性能很大程度依赖于数据分布,如何设计映射函数来优化桶排序的性能?
- 尝试将本章的排序算法应用到对象排序中(如自定义结构体),需要注意什么?

本章注记
- 线性时间排序算法都不是基于比较的排序,因此能突破 Ω(n log n) 的下界。
- 它们的性能依赖于输入数据的特性(如范围、分布、位数等),因此在实际应用中需要根据数据特点选择合适的算法。
- 计数排序适合范围较小的整数,基数排序适合位数固定的数据,桶排序适合均匀分布的数据。
- 在工程实践中,这些算法常用于大规模数据的预处理或作为更复杂排序算法的子过程。
总结
本章介绍的三种线性时间排序算法为我们提供了突破 O (n log n) 下界的思路,它们各有优缺点和适用场景:
- 计数排序:简单高效,适合范围较小的整数。
- 基数排序:通过按位排序处理长数据,依赖稳定的子排序。
- 桶排序:利用数据分布特性,性能依赖于桶的设计和数据均匀性。
希望通过本文的讲解和代码示例,大家能更好地理解和应用这些算法。动手实践是掌握算法的关键,建议大家尝试修改代码,测试不同的输入场景,加深理解!

如果有任何疑问或建议,欢迎在评论区留言交流!