【数据结构入门】单链表和数组的OJ题(1)
目录
1.移除链表元素
分析:
代码:
2.链表的中间结点
分析:
代码:
3.链表中倒数第k个结点
分析:
代码:
4. 合并两个有序链表
分析:
代码:
5.分割链表
分析:
代码:
1.移除链表元素
在原链表中直接修改
给你一个链表的头节点 head 和一个整数 val ,请你删除链表中所有满足 Node.val == val 的节点,并返回 新的头节点 。
示例 1:
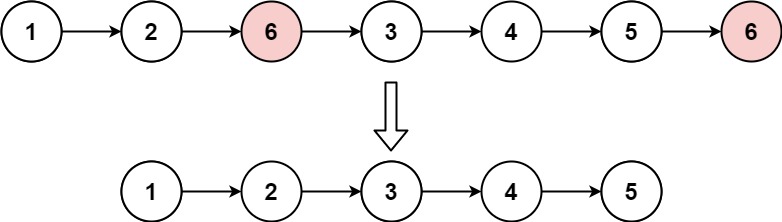
输入:head = [1,2,6,3,4,5,6], val = 6 输出:[1,2,3,4,5]
示例 2:
输入:head = [], val = 1 输出:[]
示例 3:
输入:head = [7,7,7,7], val = 7 输出:[]
分析:
①这里需要两个指针,prev、curr,分别初始化为NULL、head;如果要删除curr所指向的元素,直接使用prev跳过curr即可。
②循环条件是curr不为空,当curr找到val的时候,此时分两种情况
(1)curr就在首元素:此时将head重新赋值为curr的下一个元素,然后释放掉curr,更新curr为head;
(2)curr指向链表非首元素位置,prev此时就不是空,此时需要prev指向curr的下一个元素,释放curr,然后将curr更新为prev;
③当curr没找到val的时候,此时直接先更新prev为curr,在更新curr为curr的next。
代码:
/*** Definition for singly-linked list.* struct ListNode {* int val;* struct ListNode *next;* };*/
struct ListNode* removeElements(struct ListNode* head, int val) {struct ListNode* prev = NULL;struct ListNode* curr = head;if(head == NULL){return head;}while (curr) {if (curr->val == val) {// 如果第一个就是要删除的if(curr == head){head = curr->next;free(curr);curr = head;}else{ // 正常情况prev->next = curr->next;free(curr);curr = prev->next;}}else{prev = curr; // 始终在curr之前curr = curr->next;}}return head;
}2.链表的中间结点
给你单链表的头结点 head ,请你找出并返回链表的中间结点。
如果有两个中间结点,则返回第二个中间结点。
示例 1:

输入:head = [1,2,3,4,5] 输出:[3,4,5] 解释:链表只有一个中间结点,值为 3 。
示例 2:

输入:head = [1,2,3,4,5,6] 输出:[4,5,6] 解释:该链表有两个中间结点,值分别为 3 和 4 ,返回第二个结点。
分析:
使用最简单的方式是:先遍历一边拿到总结点个数,根据总节点个数算出中间节点,最后遍历一遍得到中间节点。
有没有更好的方法呢? 能不能只遍历一次就找到中间节点呢?可以使用快慢指针,快指针一次走两步,慢指针一次走一步,快指针走到尾的时候,慢指针刚好在中间。
细节:如果是奇数,那么快指针走到最后一个节点结束 ,如果是偶数,快指针走到空结束。
停止条件:快指针走到最后一个或者快指针走到空这个循环就结束;
继续条件:快指针走到最后一个并且快指针走到空这个循环就结束。
即:
while(fast && fast->next)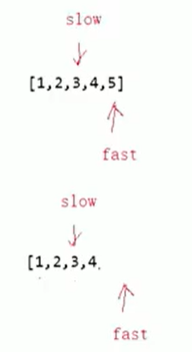
代码:
/*** Definition for singly-linked list.* struct ListNode {* int val;* struct ListNode *next;* };*/struct ListNode* middleNode(struct ListNode* head) {struct ListNode* fast = head;struct ListNode* slow = head;while(fast && fast->next){fast = fast->next->next;slow = slow->next;}return slow;
}3.链表中倒数第k个结点
牛客网传送门
输入一个链表,输出该链表中倒数第k个结点。
示例1
输入
1,{1,2,3,4,5}
输出
{5}
分析:
这里能不能使用双指针,只遍历一次就能完成任务呢?首先让快指针先走k次,然后和慢指针同步走,直到快指针走到空,此时慢指针的位置就是倒数第k个的位置。
原理其实就是让快指针和慢指针保持k个距离,当快指针为空的时候,慢指针就是倒数第k个。
需要注意的事牛客网的测试用例有可能k>链表长度,这就会让链表在走k个元素的时候发生空指针解引用的问题,所以每次k往前走的时候都需要判断k不为空,如果在向前走k步的过程中发现快指针为空了,那么说明此时链表的长度小于k,直接返回空即可。
代码:
/*** struct ListNode {* int val;* struct ListNode *next;* };*//**** @param pListHead ListNode类* @param k int整型* @return ListNode类*/
struct ListNode* FindKthToTail(struct ListNode* pListHead, int k ) {struct ListNode* fast = pListHead;struct ListNode* slow = pListHead;// 先让fast走k步while (k--) {if (fast != NULL) {fast = fast->next;} else {return NULL;}}while (fast) {// 再一起走fast = fast->next;slow = slow->next;}// fast为空的时候slow指向倒数第k个return slow;
}4. 合并两个有序链表
将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
示例 1:
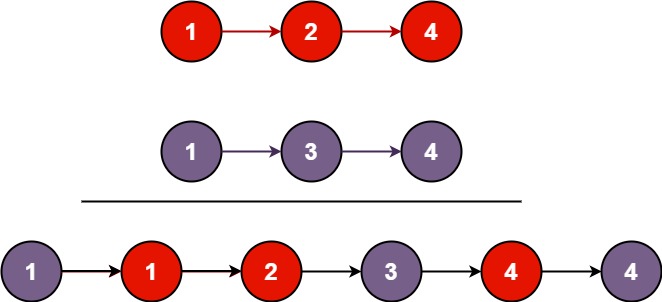
输入:l1 = [1,2,4], l2 = [1,3,4] 输出:[1,1,2,3,4,4]
示例 2:
输入:l1 = [], l2 = [] 输出:[]
示例 3:
输入:l1 = [], l2 = [0] 输出:[0]
提示:
- 两个链表的节点数目范围是
[0, 50] -100 <= Node.val <= 100l1和l2均按 非递减顺序 排列-
分析:
-
首先使用一个全新的链表来作为返回链表,这里定义一个链表头和链表指针,根据l1指针和l2指针所指向的值的大小来判断,新链表中是否要增加新节点。
①判断l1是否为空,为空,返回l2,反之亦如此;
②给新链表的头结点赋初值,这里将l1或者l2指针中较小的元素赋给新链表的头节点、遍历指针,赋值的指针需要向后移动,否则后面的循环就是死循环(自己指向自己);
③循环的条件要保证两个链表均不为空,若有一个链表为空,那么直接将另外一个链表接到新链表后面。
-
④循环体内判断l1还是l2所指向的节点更小,将更小的节点赋给新链表指针指向的位置,此时需要更新新链表指针和更小的节点所在的链表的指针;
-
⑤循环结束之后,判断是哪一个链表为空,将另一个链表接到新链表后面即可
-
⑥返回新链表的头结点。
-
代码:
/*** Definition for singly-linked list.* struct ListNode {* int val;* struct ListNode *next;* };*/
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2) {struct ListNode* curr1 = list1;struct ListNode* curr2 = list2;struct ListNode* head = NULL;struct ListNode* newcurr = head;if (curr1 == NULL) {return curr2;} else if(curr2 == NULL) {return curr1;}// 初始化头if (curr1->val < curr2->val) {head = curr1;newcurr = head;curr1 = curr1->next;} else {head = curr2;newcurr = head;curr2 = curr2->next;}// 停止条件:两个指针有一个为空while (curr1 && curr2) {if (curr1->val < curr2->val) {newcurr->next = curr1;curr1 = curr1->next;} else {newcurr->next = curr2;curr2 = curr2->next;}newcurr = newcurr->next;}if (curr1 == NULL) {newcurr->next = curr2;} else {newcurr->next = curr1;}return head;
}5.分割链表
给你一个链表的头节点 head 和一个特定值 x ,请你对链表进行分隔,使得所有 小于 x 的节点都出现在 大于或等于 x 的节点之前。
你不需要 保留 每个分区中各节点的初始相对位置。
示例 1:
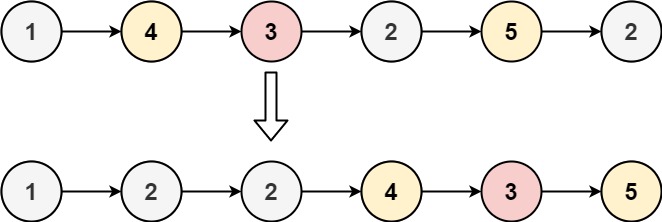
输入:head = [1,4,3,2,5,2], x = 3 输出:[1,2,2,4,3,5]
示例 2:
输入:head = [2,1], x = 2 输出:[1,2]
提示:
- 链表中节点的数目在范围
[0, 200]内 -100 <= Node.val <= 100-200 <= x <= 200
分析:
可以使用两个带头结点的链表来分别保存大于x的节点和小于x的节点,最后合并这两个节点即可。
①首先创建带头节点的两个链表,这里的头结点不存实际的值,只是为了逻辑上更简单不需要判断链表是否为空。
②开始遍历原链表,当找到某节点的val比x更小,需要将其放入lessList中去,同时原链表和lessList链表都需要向后移动指针,greaterList同理。
③由于这是带头结点的链表,这里需要将lp(指向lessList的最后一个指针)指向greaterList的下一个节点(这里跳过头指针),然后释放greaterList(头指针),同理先保存lessList的头结点的next,然后释放头结点,最后得到的是一整串链表;
需要注意的是:由于每次gp指向的都是原链表的内容,如果最后一次指向的内容中next是新链表中的内容,那么就会导致循环链表的产生,所以当循环结束之后需要将gp的next置为空防止出现死循环。
代码:
/*** Definition for singly-linked list.* struct ListNode {* int val;* struct ListNode *next;* };*/
typedef struct ListNode ListNode;
struct ListNode* partition(struct ListNode* head, int x) {// 定义两个带头结点的链表,分别保存比x大/小的节点ListNode* greaterList = (ListNode*)malloc(sizeof(ListNode));ListNode* lessList = (ListNode*)malloc(sizeof(ListNode));ListNode* gp = greaterList;ListNode* lp = lessList;// 遍历原链表while (head) {if (head->val < x) {lp->next = head;lp = lp->next;head = head->next;} else {gp->next = head;gp = gp->next;head = head->next;}}// 关键修正:确保greaterList的尾部正确终止(避免循环引用)gp->next = NULL;// 合并链表lp->next = greaterList->next;free(greaterList);head = lessList->next;free(lessList);return head;
}