无监督学习聚类方法——K-means 聚类及应用
一、前置知识
质心
质心(Centroid)是聚类算法(尤其是 K-means 聚类)中的一个核心概念,表示一个簇(Cluster)中所有数据点的几何中心(平均位置)。
1️⃣ 质心的定义
数学上,质心是簇内所有点坐标的均值。
对于一个簇 中的
个点
,其质心
定义为:
其中:
:质心(Centroid)
:簇中的数据点数量
:第
个数据点
如果是二维空间:
其中:
:第
个点的 X 坐标
:第
个点的 Y 坐标
2️⃣ 质心在 K-means 中的作用
在 K-means 聚类中:
1、随机初始化 k 个质心(每个质心代表一个簇的中心)。
2、每个点分配到距离最近的质心所在的簇。
3、重新计算每个簇的质心(即簇内所有点的均值)。
4、重复“分配—更新”直到质心不再移动(收敛)。
质心 = 当前簇的代表点,描述该簇的中心位置。
3️⃣质心 vs 中心点(Medoid)
质心(Centroid):是簇内所有点的数学平均值,可能不是真实数据点。
中心点(Medoid):是簇内距离其他点最近的实际数据点(常见于 K-medoids)。
二、 无监督学习与特征发现
监督学习(Supervised Learning):需要有目标变量(y),模型通过训练学习特征与目标之间的映射。
无监督学习(Unsupervised Learning):没有目标变量,算法的目的是学习数据本身的结构和规律,比如聚类、降维。
特征工程中的作用:
无监督算法可以帮助“发现”数据中的隐藏结构(如分组、模式),从而生成新的特征,这些新特征能提高模型的预测能力。
三、聚类的基本概念
定义:将数据点按照相似性分配到不同的簇(Cluster)。
类比:“物以类聚,人以群分”,相似的数据点会被划分到同一簇。
在特征工程中的应用:
客户分群(如营销中不同的市场细分)
地理分区(例如气候相似的地区)
给每个数据点添加“聚类标签”特征,帮助模型处理空间或复杂关系。
四、聚类标签作为新特征
单特征聚类:相当于 “分箱”或“离散化”(Binning)。
多特征聚类:相当于 “多维分箱”(Multi-dimensional binning)。
添加聚类特征的好处:
将复杂的关系切分为多个简单的局部关系(分而治之)。
模型可以分别在这些局部区域中学习,更容易拟合。
五、K-means 聚类原理
1、K-means 是一种基于欧几里得距离(Euclidean Distance)的常用聚类算法。算法流程:
随机初始化 k 个质心(centroids)。
将每个数据点分配到最近的质心簇。
重新计算每个簇的质心位置。
重复步骤 2-3,直到质心不再变化或达到最大迭代次数 max_iter。
参数:
n_clusters (k):簇的数量,由用户指定。
max_iter:最大迭代次数。
n_init:不同的初始随机质心重复运行的次数,选择最佳结果。
注意:
不同初始质心可能导致不同聚类结果,所以需要 n_init 多次运行,选取最优聚类(总距离最小)。
六、示例
本次示例来自kaggle的K-means的练习。
# Setup feedback system
from learntools.core import binder
binder.bind(globals())
from learntools.feature_engineering_new.ex4 import *import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
from sklearn.cluster import KMeans
from sklearn.model_selection import cross_val_score
from xgboost import XGBRegressor# Set Matplotlib defaults
plt.style.use("seaborn-whitegrid")
plt.rc("figure", autolayout=True)
plt.rc("axes",labelweight="bold",labelsize="large",titleweight="bold",titlesize=14,titlepad=10,
)def score_dataset(X, y, model=XGBRegressor()):# Label encoding for categoricalsfor colname in X.select_dtypes(["category", "object"]):X[colname], _ = X[colname].factorize()# Metric for Housing competition is RMSLE (Root Mean Squared Log Error)score = cross_val_score(model, X, y, cv=5, scoring="neg_mean_squared_log_error",)score = -1 * score.mean()score = np.sqrt(score)return score# Prepare data
df = pd.read_csv("../input/fe-course-data/ames.csv")1) 步骤一:特征缩放(Feature Scaling)
X_scaled = (X_scaled - X_scaled.mean(axis=0)) / X_scaled.std(axis=0)
K-means 是基于距离的算法,若不同特征量纲差异大(如面积是千级、楼层是十级),则模型偏向大值特征。因此我们用 标准化(Z-score) 将所有特征缩放至均值为 0、标准差为 1 的标准正态分布。
2)步骤二:聚类标签特征(Cluster Labels)
X = df.copy()
y = X.pop("SalePrice")
# YOUR CODE HERE: Define a list of the features to be used for the clustering
features = ["LotArea","TotalBsmtSF","FirstFlrSF","SecondFlrSF","GrLivArea",
]
# Standardize
X_scaled = X.loc[:, features]
X_scaled = (X_scaled - X_scaled.mean(axis=0)) / X_scaled.std(axis=0)
# YOUR CODE HERE: Fit the KMeans model to X_scaled and create the cluster labels
kmeans = KMeans(n_clusters=10, random_state=0)
X["Cluster"] = kmeans.fit_predict(X_scaled)
# Check your answer
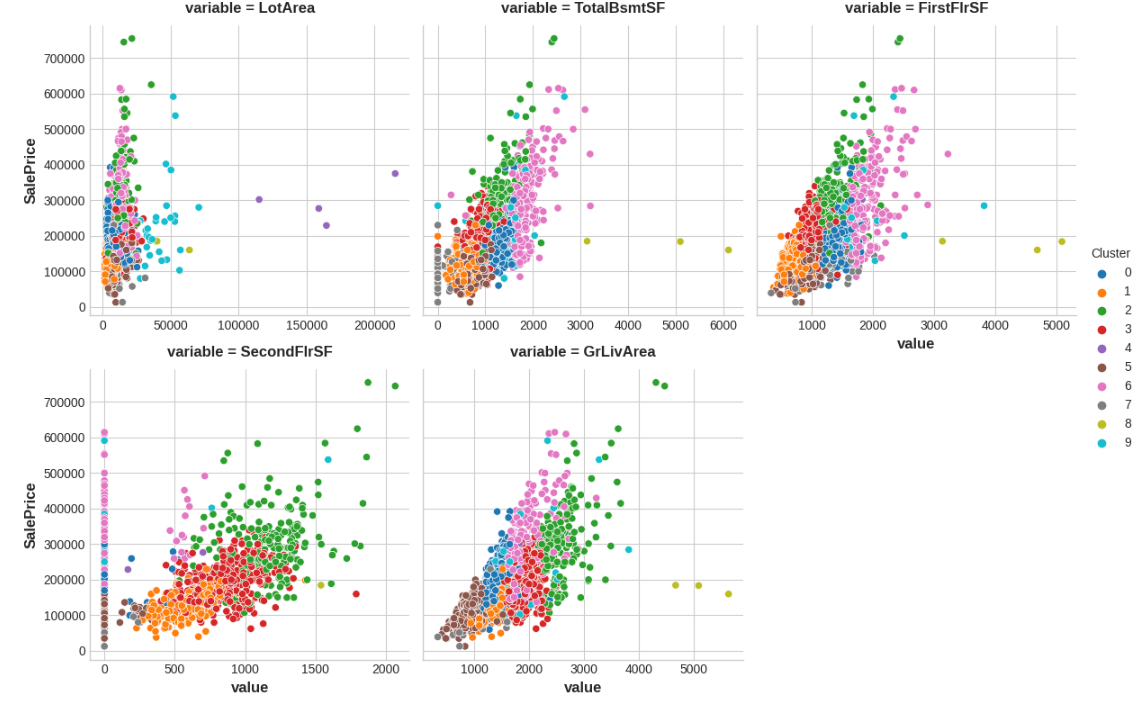
q_2.check()我们对 5 个面积/楼层相关的特征做了 10 个簇的 K-means 聚类,并将每个样本所属簇的标签作为新特征添加到数据集中。
我们将这些聚类标签看作是「房屋结构特征组合」的类别(比如类似面积和楼层组合的房型标签,这些类别与房价可能有明显相关性,因此可以提高模型预测能力。
聚类分析结果:
Xy = X.copy()
Xy["Cluster"] = Xy.Cluster.astype("category")
Xy["SalePrice"] = y
sns.relplot(x="value", y="SalePrice", hue="Cluster", col="variable",height=4, aspect=1, facet_kws={'sharex': False}, col_wrap=3,data=Xy.melt(value_vars=features, id_vars=["SalePrice", "Cluster"],),
);
3)步骤三:聚类距离特征(Cluster Distance Features)
将聚类距离要素添加到数据集中。您可以使用 kmeans 的 fit_transform 方法而不是 fit_predict 来获取这些距离要素。
kmeans = KMeans(n_clusters=10, n_init=10, random_state=0)# YOUR CODE HERE: Create the cluster-distance features using `fit_transform`
X_cd = kmeans.fit_transform(X_scaled)# Label features and join to dataset
X_cd = pd.DataFrame(X_cd, columns=[f"Centroid_{i}" for i in range(X_cd.shape[1])])
X = X.join(X_cd)# Check your answer
q_3.check()与其只用一个离散标签,我们还引入了从每个样本到 所有 10 个簇中心 的欧几里得距离,作为连续特征。
每个房子都可以用它与 10 个典型房型(簇中心)的距离来表示其「房型分布」,这是更丰富的结构信息。
例如:
离 Centroid_0 最近的可能是高楼层 + 小面积
离 Centroid_9 最近的可能是大面积 + 双层住宅
无监督学习(如聚类)可以作为特征工程工具,K-means 聚类标签可作为新特征输入模型。