基于Python 批量导入实体与关系到 Neo4j 数据库的完整实践
引言
在知识图谱构建过程中,将结构化或半结构化数据导入到图数据库是关键步骤之一。本文将详细介绍如何使用 Python 解析自定义格式数据,并通过 Neo4j 官方驱动将实体和关系批量导入到 Neo4j 数据库中,帮助你快速搭建自己的知识图谱。我也在最后附上完整代码,可直接运行。
在知识图谱项目中,我们经常需要处理各种格式的数据并将其转换为图数据库中的实体(Entities)和关系(Relationships)。本项目需要解决:
- 解析自定义分隔符的原始数据,区分实体和关系
- 建立与 Neo4j 数据库的连接
- 将解析后的实体和关系批量写入 Neo4j
- 确保数据导入的准确性和效率
一、环境依赖与说明
- 图数据库:Neo4j - 最流行的开源图数据库,适合存储和查询复杂关系数据
- 编程语言:Python - 强大的数据处理能力和丰富的库支持
- 驱动库:neo4j - Neo4j 官方 Python 驱动,提供高效的数据库交互能力
二代码解读
1. 导入依赖与配置连接信息
首先需要导入必要的库并配置 Neo4j 连接信息:
from neo4j import GraphDatabase# Neo4j 连接配置
uri = "neo4j://181.149.205.11:14802"
user = "neo4j"
password = "your_password"
database = "neo4j"
2. 定义数据分隔符
原始数据使用了自定义分隔符,我们需要先定义这些分隔符以便正确解析数据:
# 自定义分隔符
TUPLE_DELIMITER = "{tuple_delimiter}"
RECORD_DELIMITER = "{record_delimiter}"
COMPLETION_DELIMITER = "{completion_delimiter}"
3. 原始数据准备
这里是我们需要导入的原始数据,包含实体和关系信息:
# 原始数据
raw_data = '''
(entity{tuple_delimiter}费鲁扎巴德{tuple_delimiter}地理{tuple_delimiter}费鲁扎巴德将奥雷利亚人作为人质扣押)
{record_delimiter}
(entity{tuple_delimiter}奥雷利亚{tuple_delimiter}地理{tuple_delimiter}寻求释放人质的国家)
{record_delimiter}
(entity{tuple_delimiter}昆塔拉{tuple_delimiter}地理{tuple_delimiter}协商用资金交换人质的国家)
{record_delimiter}
{record_delimiter}
(entity{tuple_delimiter}蒂鲁齐亚{tuple_delimiter}地理{tuple_delimiter}费鲁扎巴德的首都,奥雷利亚人被关押的地方)
{record_delimiter}
(entity{tuple_delimiter}克罗哈拉{tuple_delimiter}地理{tuple_delimiter}昆塔拉的首都城市)
{record_delimiter}
(entity{tuple_delimiter}卡申{tuple_delimiter}地理{tuple_delimiter}奥雷利亚的首都城市)
{record_delimiter}
(entity{tuple_delimiter}萨缪尔·纳马拉{tuple_delimiter}人物{tuple_delimiter}曾在蒂鲁齐亚的阿尔哈米亚监狱服刑的奥雷利亚人)
{record_delimiter}
(entity{tuple_delimiter}阿尔哈米亚监狱{tuple_delimiter}地理{tuple_delimiter}位于蒂鲁齐亚的监狱)
{record_delimiter}
(entity{tuple_delimiter}杜尔克·巴塔格拉尼{tuple_delimiter}人物{tuple_delimiter}曾被扣为人质的奥雷利亚记者)
{record_delimiter}
(entity{tuple_delimiter}梅吉·塔兹巴{tuple_delimiter}人物{tuple_delimiter}布拉蒂纳斯国民和曾被扣为人质的环保主义者)
{record_delimiter}
(relationship{tuple_delimiter}费鲁扎巴德{tuple_delimiter}奥雷利亚{tuple_delimiter}费鲁扎巴德与奥雷利亚进行了人质交换谈判{tuple_delimiter}0.2)
{record_delimiter}
(relationship{tuple_delimiter}昆塔拉{tuple_delimiter}奥雷利亚{tuple_delimiter}昆塔拉促成了费鲁扎巴德和奥雷利亚之间的人质交换{tuple_delimiter}0.2)
{record_delimiter}
(relationship{tuple_delimiter}昆塔拉{tuple_delimiter}费鲁扎巴德{tuple_delimiter}昆塔拉促成了费鲁扎巴德和奥雷利亚之间的人质交换{tuple_delimiter}0.2)
{record_delimiter}
(relationship{tuple_delimiter}萨缪尔·纳马拉{tuple_delimiter}阿尔哈米亚监狱{tuple_delimiter}萨缪尔·纳马拉是阿尔哈米亚监狱的囚犯{tuple_delimiter}0.8)
{record_delimiter}
(relationship{tuple_delimiter}萨缪尔·纳马拉{tuple_delimiter}梅吉·塔兹巴{tuple_delimiter}萨缪尔·纳马拉和梅吉·塔兹巴在同一次人质释放中被交换{tuple_delimiter}0.2)
{record_delimiter}
(relationship{tuple_delimiter}萨缪尔·纳马拉{tuple_delimiter}杜尔克·巴塔格拉尼{tuple_delimiter}萨缪尔·纳马拉和杜尔克·巴塔格拉尼在同一次人质释放中被交换{tuple_delimiter}0.2)
{record_delimiter}
(relationship{tuple_delimiter}梅吉·塔兹巴{tuple_delimiter}杜尔克·巴塔格拉尼{tuple_delimiter}梅吉·塔兹巴和杜尔克·巴塔格拉尼在同一次人质释放中被交换{tuple_delimiter}0.2)
{record_delimiter}
(relationship{tuple_delimiter}萨缪尔·纳马拉{tuple_delimiter}费鲁扎巴德{tuple_delimiter}萨缪尔·纳马拉是费鲁扎巴德的人质{tuple_delimiter}0.2)
{record_delimiter}
(relationship{tuple_delimiter}梅吉·塔兹巴{tuple_delimiter}费鲁扎巴德{tuple_delimiter}梅吉·塔兹巴是费鲁扎巴德的人质{tuple_delimiter}0.2)
{record_delimiter}
(relationship{tuple_delimiter}杜尔克·巴塔格拉尼{tuple_delimiter}费鲁扎巴德{tuple_delimiter}杜尔克·巴塔格拉尼是费鲁扎巴德的人质{tuple_delimiter}0.2)
{completion_delimiter}
'''.format(tuple_delimiter=TUPLE_DELIMITER,record_delimiter=RECORD_DELIMITER,completion_delimiter=COMPLETION_DELIMITER
)
4. 数据解析函数
接下来实现数据解析函数,将原始数据转换为结构化的实体和关系:
def parse_data(data):entities = []relationships = []# 移除完成符record_data = data.replace(COMPLETION_DELIMITER, '') # 提取每条记录并去除空行records = [r.strip() for r in record_data.strip().split(RECORD_DELIMITER) if r.strip()]for record in records:# 去掉最外层的括号content = record[1:-1].strip() if record.startswith('(') else record.strip()parts = content.split(TUPLE_DELIMITER)if parts[0] == "entity":entities.append({"entity_name": parts[1].strip(),"entity_type": parts[2].strip(),"entity_description": parts[3].strip()})elif parts[0] == "relationship":relationships.append({"source_entity": parts[1].strip(),"target_entity": parts[2].strip(),"relationship_description": parts[3].strip(),"relationship_strength": float(parts[4].strip())})return entities, relationships
解析函数的工作流程:
- 移除数据中的完成符
- 按记录分隔符拆分数据,过滤空记录
- 处理每条记录,去除外层括号
- 按元组分隔符拆分记录内容
- 根据记录类型(实体/关系)将数据存入不同列表
- 返回解析后的实体和关系列表
5. Neo4j 数据写入类
实现一个类来处理与 Neo4j 的交互,包括连接管理和数据写入:
class Neo4jGraphData:def __init__(self, uri, user, password, database="neo4j"):"""初始化数据库连接"""self.driver = GraphDatabase.driver(uri, auth=(user, password))self.database = databasedef close(self):"""关闭数据库连接"""self.driver.close()def _create_entities(self, tx, entities):"""创建实体节点"""for entity in entities:tx.run("""MERGE (e:Entity {name: $name})SET e.type = $type, e.description = $description""",name=entity["entity_name"],type=entity["entity_type"],description=entity["entity_description"])def _create_relationships(self, tx, relationships):"""创建实体之间的关系"""for rel in relationships:tx.run("""MATCH (a:Entity {name: $source})MATCH (b:Entity {name: $target})MERGE (a)-[r:relationships]->(b)SET r.description = $description, r.strength = $strength""",source=rel["source_entity"],target=rel["target_entity"],description=rel["relationship_description"],strength=rel["relationship_strength"])def write_entities_and_relationships(self, entities, relationships):"""写入实体和关系到数据库"""with self.driver.session(database=self.database) as session:session.write_transaction(self._create_entities, entities)session.write_transaction(self._create_relationships, relationships)print("✅ 实体和关系已成功写入 Neo4j")
这个类的核心设计点:
- 使用
MERGE而非CREATE确保不会创建重复节点 - 将实体和关系的创建分开处理,逻辑更清晰
- 使用事务(transaction)确保数据一致性
- 提供明确的连接关闭方法,避免资源泄露
6. 主函数执行流程
最后实现主函数,完成数据解析和导入的完整流程:
if __name__ == "__main__":# 解析数据entities, relationships = parse_data(raw_data)# 打印解析结果(可选)print("Entities:", entities)print("Relationships:", relationships)# 初始化并连接Neo4j数据库writer = Neo4jGraphData(uri, user, password, database)# 写入数据if entities or relationships:writer.write_entities_and_relationships(entities, relationships)else:print("❌ 未解析到任何实体或关系,请检查数据格式。")# 关闭连接writer.close()
三、代码解析与关键技术点
1. 数据解析策略
原始数据采用了类似元组的格式,每条记录用括号包裹,内部使用自定义分隔符分割字段。解析过程中:
- 首先按记录分隔符拆分数据
- 对每条记录进行处理,提取核心内容
- 根据记录类型(entity/relationship)构建不同结构的字典
- 保留实体类型、描述和关系强度等重要属性
2. Neo4j 写入策略
在写入 Neo4j 时,我们采用了以下策略确保数据质量:
- 使用
MERGE语句:避免创建重复节点,当节点已存在时仅更新属性 - 分步骤写入:先写入所有实体,再写入关系,确保关系引用的实体已存在
- 事务处理:将所有实体写入作为一个事务,所有关系写入作为另一个事务,保证数据一致性
- 属性丰富:为节点添加类型和描述属性,为关系添加描述和强度属性
3. 连接管理
通过类的方式封装数据库连接,确保资源正确释放:
- 在
__init__方法中创建连接 - 提供
close方法关闭连接 - 使用
with语句管理会话生命周期
四、运行结果与验证
运行程序后,如果一切正常,会输出:
✅ 实体和关系已成功写入 Neo4j
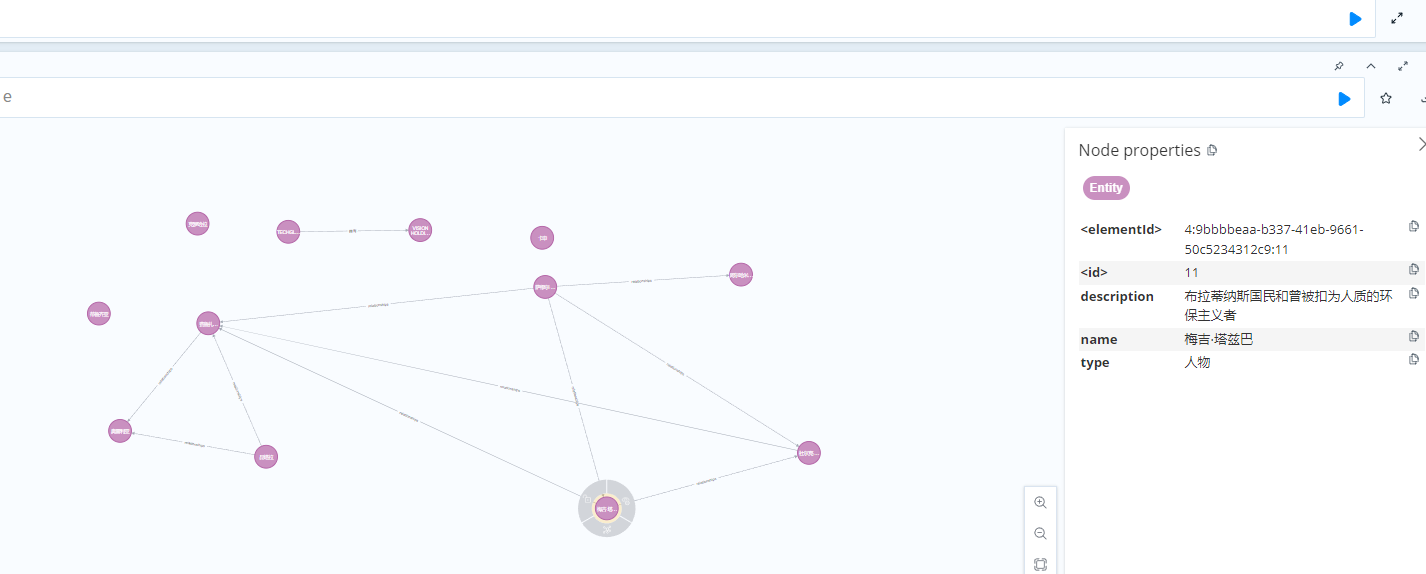
你可以通过 Neo4j Browser 执行查询验证数据是否正确导入:
// 查询所有实体
MATCH (n) RETURN n LIMIT 25// 查询所有关系
MATCH ()-[r]->() RETURN r LIMIT 25// 查询特定实体及其关系
MATCH (n:Entity {name: "费鲁扎巴德"})-[r]->(m) RETURN n, r, m
结果图如下:
五、完整代码
from neo4j import GraphDatabase# Neo4j 连接配置
uri = "neo4j://181.149.205.11:14802"
user = "neo4j"
password = "your_password"
database = "neo4j"# 自定义分隔符
TUPLE_DELIMITER = "{tuple_delimiter}"
RECORD_DELIMITER = "{record_delimiter}"
COMPLETION_DELIMITER = "{completion_delimiter}"# 原始数据(注意:这里保留原始格式)
raw_data = '''(entity{tuple_delimiter}费鲁扎巴德{tuple_delimiter}地理{tuple_delimiter}费鲁扎巴德将奥雷利亚人作为人质扣押)
{record_delimiter}
(entity{tuple_delimiter}奥雷利亚{tuple_delimiter}地理{tuple_delimiter}寻求释放人质的国家)
{record_delimiter}
(entity{tuple_delimiter}昆塔拉{tuple_delimiter}地理{tuple_delimiter}协商用资金交换人质的国家)
{record_delimiter}
{record_delimiter}
(entity{tuple_delimiter}蒂鲁齐亚{tuple_delimiter}地理{tuple_delimiter}费鲁扎巴德的首都,奥雷利亚人被关押的地方)
{record_delimiter}
(entity{tuple_delimiter}克罗哈拉{tuple_delimiter}地理{tuple_delimiter}昆塔拉的首都城市)
{record_delimiter}
(entity{tuple_delimiter}卡申{tuple_delimiter}地理{tuple_delimiter}奥雷利亚的首都城市)
{record_delimiter}
(entity{tuple_delimiter}萨缪尔·纳马拉{tuple_delimiter}人物{tuple_delimiter}曾在蒂鲁齐亚的阿尔哈米亚监狱服刑的奥雷利亚人)
{record_delimiter}
(entity{tuple_delimiter}阿尔哈米亚监狱{tuple_delimiter}地理{tuple_delimiter}位于蒂鲁齐亚的监狱)
{record_delimiter}
(entity{tuple_delimiter}杜尔克·巴塔格拉尼{tuple_delimiter}人物{tuple_delimiter}曾被扣为人质的奥雷利亚记者)
{record_delimiter}
(entity{tuple_delimiter}梅吉·塔兹巴{tuple_delimiter}人物{tuple_delimiter}布拉蒂纳斯国民和曾被扣为人质的环保主义者)
{record_delimiter}
(relationship{tuple_delimiter}费鲁扎巴德{tuple_delimiter}奥雷利亚{tuple_delimiter}费鲁扎巴德与奥雷利亚进行了人质交换谈判{tuple_delimiter}0.2)
{record_delimiter}
(relationship{tuple_delimiter}昆塔拉{tuple_delimiter}奥雷利亚{tuple_delimiter}昆塔拉促成了费鲁扎巴德和奥雷利亚之间的人质交换{tuple_delimiter}0.2)
{record_delimiter}
(relationship{tuple_delimiter}昆塔拉{tuple_delimiter}费鲁扎巴德{tuple_delimiter}昆塔拉促成了费鲁扎巴德和奥雷利亚之间的人质交换{tuple_delimiter}0.2)
{record_delimiter}
(relationship{tuple_delimiter}萨缪尔·纳马拉{tuple_delimiter}阿尔哈米亚监狱{tuple_delimiter}萨缪尔·纳马拉是阿尔哈米亚监狱的囚犯{tuple_delimiter}0.8)
{record_delimiter}
(relationship{tuple_delimiter}萨缪尔·纳马拉{tuple_delimiter}梅吉·塔兹巴{tuple_delimiter}萨缪尔·纳马拉和梅吉·塔兹巴在同一次人质释放中被交换{tuple_delimiter}0.2)
{record_delimiter}
(relationship{tuple_delimiter}萨缪尔·纳马拉{tuple_delimiter}杜尔克·巴塔格拉尼{tuple_delimiter}萨缪尔·纳马拉和杜尔克·巴塔格拉尼在同一次人质释放中被交换{tuple_delimiter}0.2)
{record_delimiter}
(relationship{tuple_delimiter}梅吉·塔兹巴{tuple_delimiter}杜尔克·巴塔格拉尼{tuple_delimiter}梅吉·塔兹巴和杜尔克·巴塔格拉尼在同一次人质释放中被交换{tuple_delimiter}0.2)
{record_delimiter}
(relationship{tuple_delimiter}萨缪尔·纳马拉{tuple_delimiter}费鲁扎巴德{tuple_delimiter}萨缪尔·纳马拉是费鲁扎巴德的人质{tuple_delimiter}0.2)
{record_delimiter}
(relationship{tuple_delimiter}梅吉·塔兹巴{tuple_delimiter}费鲁扎巴德{tuple_delimiter}梅吉·塔兹巴是费鲁扎巴德的人质{tuple_delimiter}0.2)
{record_delimiter}
(relationship{tuple_delimiter}杜尔克·巴塔格拉尼{tuple_delimiter}费鲁扎巴德{tuple_delimiter}杜尔克·巴塔格拉尼是费鲁扎巴德的人质{tuple_delimiter}0.2)
{completion_delimiter}'''.format(tuple_delimiter=TUPLE_DELIMITER,record_delimiter=RECORD_DELIMITER,completion_delimiter=COMPLETION_DELIMITER
)# ✅ 不修改 parse_data(data)
def parse_data(data):entities = []relationships = []record_data = data.replace(COMPLETION_DELIMITER, '') records = [r.strip() for r in record_data.strip().split(RECORD_DELIMITER) if r.strip()] # 先提取每条记录再去除空行for record in records:content = record[1:-1].strip() if record.startswith('(') else record.strip() # 去掉最外层的括号parts = content.split(TUPLE_DELIMITER)if parts[0] == "entity":entities.append({"entity_name": parts[1].strip(),"entity_type": parts[2].strip(),"entity_description": parts[3].strip()})elif parts[0] == "relationship":relationships.append({"source_entity": parts[1].strip(),"target_entity": parts[2].strip(),"relationship_description": parts[3].strip(),"relationship_strength": float(parts[4].strip())})return entities, relationships# ✅ 使用 Class 实现写入 Neo4j
class Neo4jGraphData:def __init__(self, uri, user, password, database="neo4j"):self.driver = GraphDatabase.driver(uri, auth=(user, password))self.database = databasedef close(self):"""关闭数据库连接"""self.driver.close()def _create_entities(self, tx, entities):"""创建实体节点,如果想添加其它属性,通过这个SET e.type = $type, e.description = $description设置"""for entity in entities:tx.run("""MERGE (e:Entity {name: $name})SET e.type = $type, e.description = $description""",name=entity["entity_name"],type=entity["entity_type"],description=entity["entity_description"])def _create_relationships(self, tx, relationships):"""创建实体之间的关系,如果需要添加其它属性,通过SET r.description = $description, r.strength = $strength设置"""for rel in relationships:tx.run("""MATCH (a:Entity {name: $source})MATCH (b:Entity {name: $target})MERGE (a)-[r:relationships]->(b)SET r.description = $description, r.strength = $strength""",source=rel["source_entity"],target=rel["target_entity"],description=rel["relationship_description"],strength=rel["relationship_strength"])def write_entities_and_relationships(self, entities, relationships):"""写入实体和关系"""with self.driver.session(database=self.database) as session:session.write_transaction(self._create_entities, entities)session.write_transaction(self._create_relationships, relationships)print("✅ 实体和关系已成功写入 Neo4j")if __name__ == "__main__":entities, relationships = parse_data(raw_data)print("Entities:", entities)print("Relationships:", relationships)writer = Neo4jGraphData(uri, user, password, database) # 初始化并连接Neo4j数据库if entities or relationships:writer.write_entities_and_relationships(entities, relationships)else:print("❌ 未解析到任何实体或关系,请检查数据格式。")writer.close() #