Redis 数据同步机制
在现代分布式系统中,Redis 凭借其高性能和丰富的数据结构成为核心组件。保障数据可靠性与服务高可用,其数据同步机制尤为关键。本文将深入剖析 Redis 的三种核心同步机制:主从复制、哨兵模式与集群分片,助你构建稳健的 Redis 架构。
一、主从复制(Replication):数据冗余与读写分离基础
核心目标:实现单一主节点(Master)向多个从节点(Slave/Replica)的数据复制。
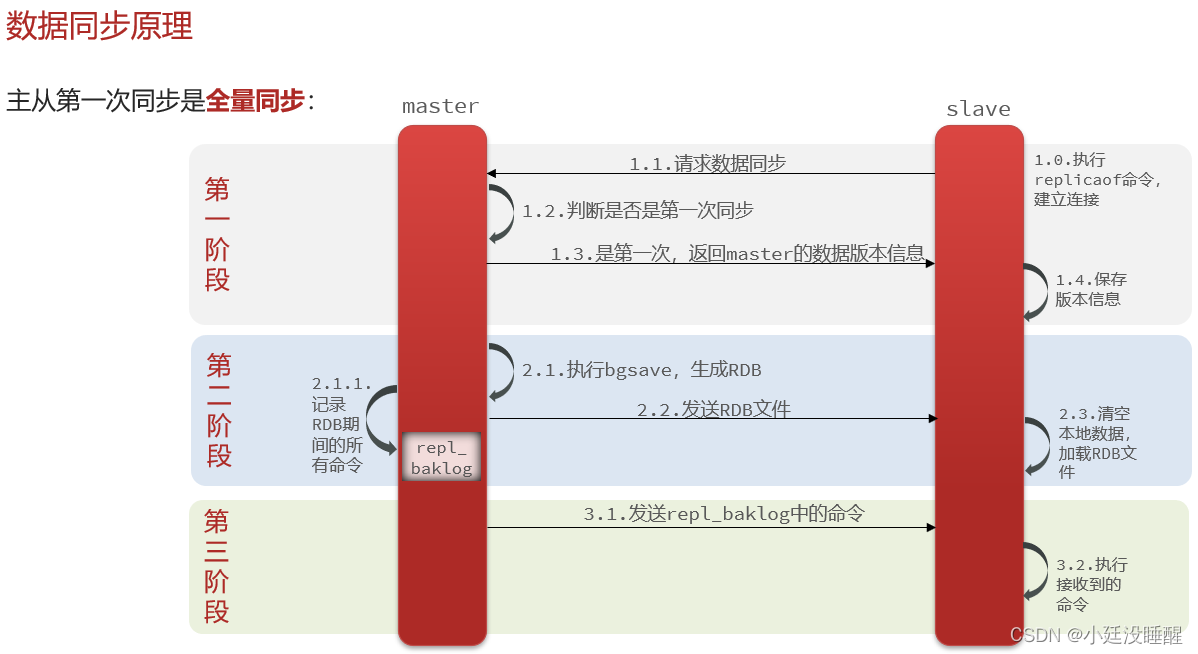
1. 同步流程详解
连接建立:Slave 启动后,通过
replicaof <masterip> <masterport>命令向 Master 发起连接请求。全量同步(SYNC):
Master 收到 SYNC 命令后启动后台
bgsave进程生成 RDB 快照文件。RDB 生成期间的新写命令,Master 将其缓冲在内存 (
replication buffer)。RDB 文件生成完毕,Master 将其传输给 Slave。Slave 清空旧数据,加载 RDB。
Master 将缓冲区的写命令发送给 Slave 执行,实现追赶。
主节点视角日志分析
1:M 03 Aug 2025 01:20:34.560 * Partial resynchronization not accepted: Replication ID mismatch
1:M 03 Aug 2025 01:20:34.560 * Starting BGSAVE for SYNC with target: disk
1:M 03 Aug 2025 01:20:34.564 * Background saving started by pid 19
19:C 03 Aug 2025 01:20:34.630 * DB saved on disk
1:M 03 Aug 2025 01:20:34.709 * Background saving terminated with success
1:M 03 Aug 2025 01:20:34.709 * Synchronization with replica 172.17.0.1:6379 succeeded
拒绝增量同步请求
Partial resynchronization not accepted: 主节点发现副本的复制ID不匹配(3d69e61vs 主节点的c59dc2b)启动全量同步
Starting BGSAVE: 主节点开始创建整个数据库的快照(RDB文件)快照保存
子进程(pid 19)将内存数据写入磁盘RDB文件(DB saved on disk)同步完成
主节点将完整的RDB发送给从节点后报告同步成功
从节点视角日志分析
1:S 03 Aug 2025 01:20:33.448 * MASTER <-> REPLICA sync started
1:S 03 Aug 2025 01:20:33.448 * Master replied to PING
1:S 03 Aug 2025 01:20:33.449 * Trying a partial resynchronization...
1:S 03 Aug 2025 01:20:33.451 * Full resync from master...
1:S 03 Aug 2025 01:20:33.451 * Discarding previously cached master state.
1:S 03 Aug 2025 01:20:33.552 * Receiving RDB from master
1:S 03 Aug 2025 01:20:33.552 * Flushing old data
1:S 03 Aug 2025 01:20:33.552 * Loading DB in memory
1:S 03 Aug 2025 01:20:33.556 * Done loading RDB, keys loaded: 1
1:S 03 Aug 2025 01:20:33.556 * Synchronization finished with success
启动同步连接
从节点主动连接主节点(192.168.88.128:7001)尝试增量同步
Trying partial resynchronization: 发送自己的复制偏移量请求增量数据转为全量同步
Full resync: 收到主节点要求全量同步的指令准备接收数据
Discarding cached state: 清除旧数据准备重建接收加载RDB
接收187字节RDB文件 → 清空旧数据 → 加载新数据(加载了1个key)
增量同步(PSYNC):
基于
Replication ID(标识主从关系) 和Offset(复制偏移量)。Slave 重连或短暂断开后,发送
PSYNC <replid> <offset>。Master 检查 Repl ID 和 Offset:
若 Repl ID 匹配且 Offset 在
repl_backlog_buffer(环形复制积压缓冲区) 范围内,则发送CONTINUE及后续命令。否则触发全量同步。
2. 关键组件
repl_backlog_buffer:固定大小的环形缓冲区 (由repl-backlog-size配置)。Master 将写入命令同时写入此缓冲区和发送给 Slave。是增量同步的关键。Replication ID:标识一个主从数据集。主节点重启或提升从节点时生成新 ID。Offset:Master 和 Slave 各自维护的复制进度计数器(字节为单位)。Master 每发送 N 个字节数据,Offset 增加 N;Slave 每接收并执行 N 个字节,Offset 增加 N。通过对比 Offset 判断同步状态。
3. 配置要点
# Master 配置 (redis.conf)
repl-backlog-size 1mb # 积压缓冲区大小,影响增量同步能力
repl-backlog-ttl 3600 # Master 无 Slave 连接后保留积压的时长(秒)
client-output-buffer-limit replica 256mb 64mb 60 # 限制复制缓冲区大小,防Master OOM# Slave 配置 (redis.conf 或 命令)
replicaof 192.168.1.100 6379
replica-read-only yes # 推荐开启,从节点只读