深度学习中的模型知识蒸馏
知识蒸馏(knowledge distillation)最初由Hinton等人于2015年提出。知识蒸馏是机器学习中的一种模型优化和压缩技术,用于在不显著降低准确率的情况下降低模型的复杂度和规模,旨在将大型预训练模型(即"teacher model")的学习成果迁移到规模较小的"student model"。它在深度学习中被用作模型压缩和知识迁移的一种形式,尤其适用于大规模深度神经网络。知识蒸馏是一种深度学习过程,将知识从一个复杂且训练有素的模型(称为"teacher)"迁移到一个更简单、更轻量级的模型(称为"student")。知识蒸馏的目标是训练一个更紧凑的模型来模拟更大、更复杂的模型,即训练学生网络,使其预测结果与教师网络的预测结果相匹配。
知识蒸馏不依赖于任何特定的神经网络架构,甚至不要求教师网络和学生网络具有相同的架构:它可以应用于任何深度学习模型。
基本上,知识蒸馏系统由三个关键部分组成:知识、蒸馏算法和师生架构(teacher-student architecture),如下图所示:
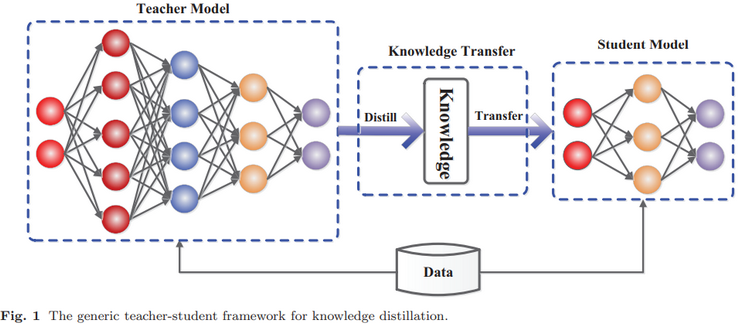
1. 知识:包括基于响应的知识、基于特征的知识和基于关系的知识,如下图所示展示了教师模型中不同知识类别的直观示例
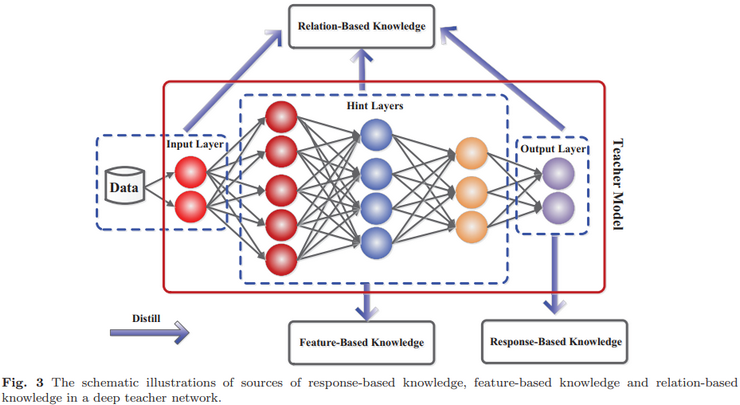
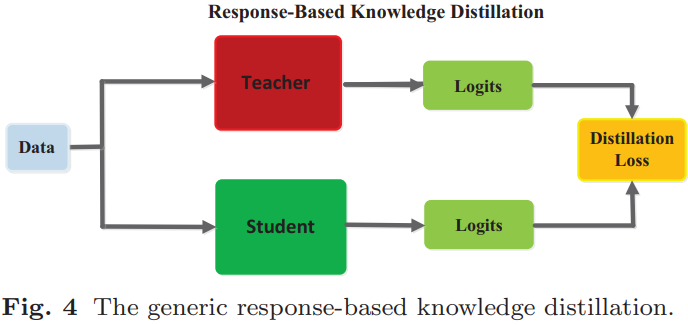
(1).response-based knowledge:基于响应的知识通常指教师模型最后输出层的神经响应。主要思想是直接模仿教师模型的最终预测。基于响应的知识蒸馏简单而有效,用于模型压缩,并已广泛用于不同任务和应用。然而,基于响应的知识通常依赖于最后一层的输出(如soft targets,软目标),因此无法解决教师模型的中级监督(intermediate-level supervision)问题,而这对于使用深度神经网络进行表征学习(representation learning)至关重要。由于软逻辑(soft logits)实际上是类概率分布,因此基于响应的知识蒸馏也仅限于监督学习。如下图所示显示了典型的基于响应的知识蒸馏模型:
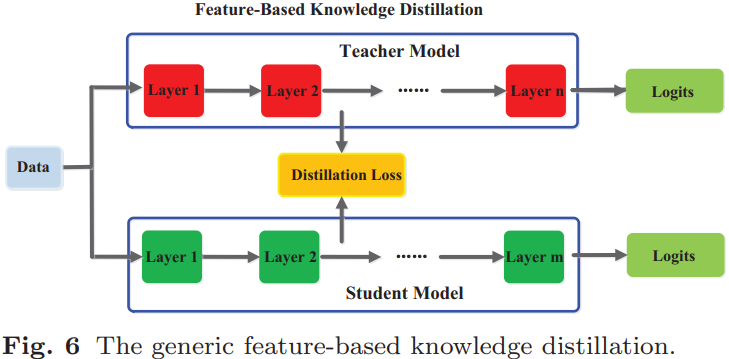
(2).feature-based knowledge:深度神经网络擅长学习多层次的特征表示(multiple levels of feature representation),并不断提升其抽象程度。这被称为表征学习。因此,最后一层的输出和中间层的输出(即特征图)都可以用作知识来监督学生模型的训练。具体来说,来自中间层的基于特征的知识是基于响应的知识的良好扩展,特别是对于更薄(thinner)更深网络的训练。如下图所示显示了通用的基于特征的知识蒸馏模型:
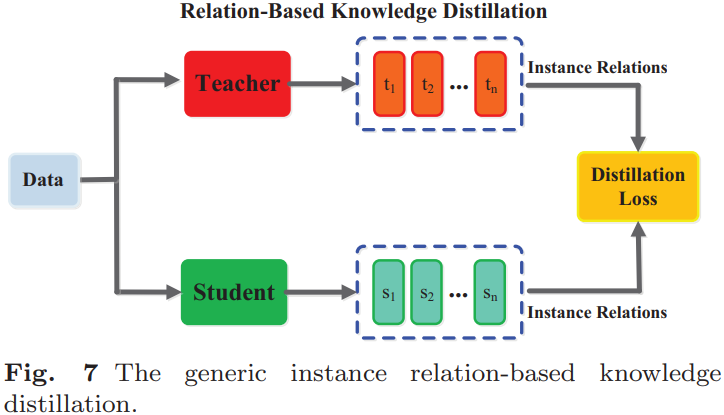
(3).relation-based knowledge:探索不同层或数据样本之间的关系。如下图所示显示了典型的基于实例关系的知识蒸馏模型:
2. 蒸馏算法:
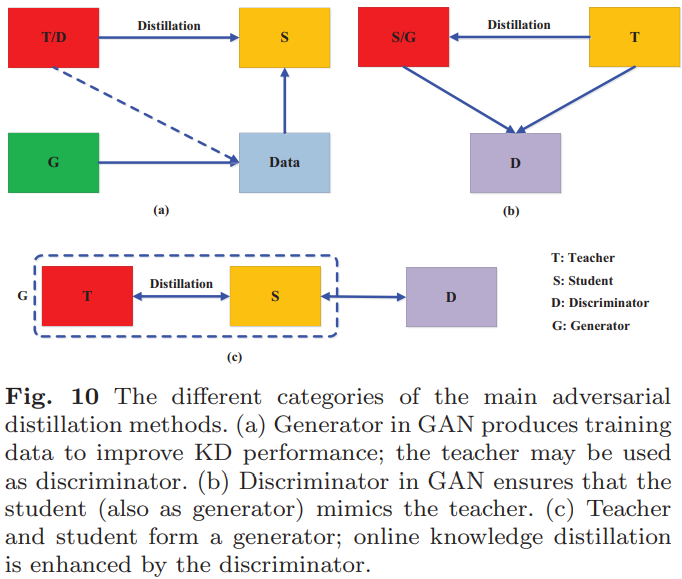
(1).对抗蒸馏:如下图所示:
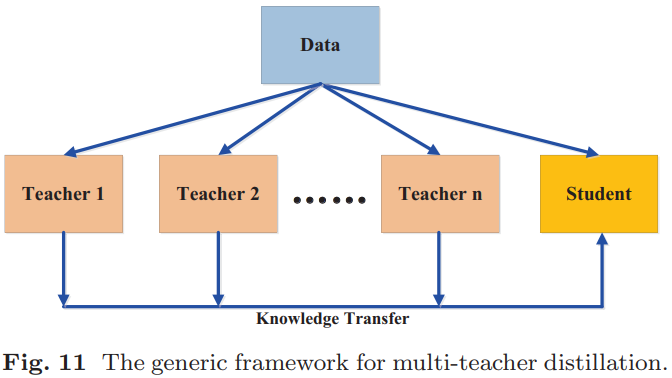
(2).多教师蒸馏:多个教师网络可以在训练学生网络期间单独和整体用于蒸馏。如下图所示:
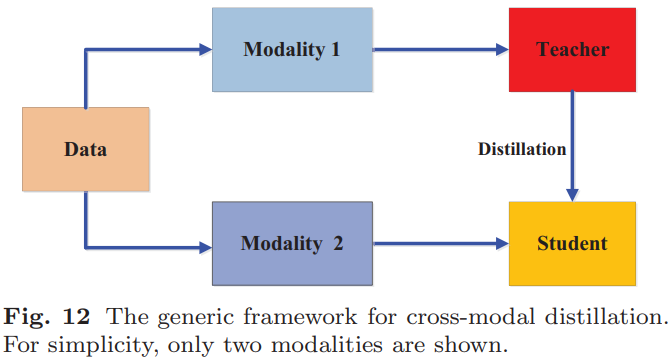
(3).跨模态蒸馏:如下图所示:
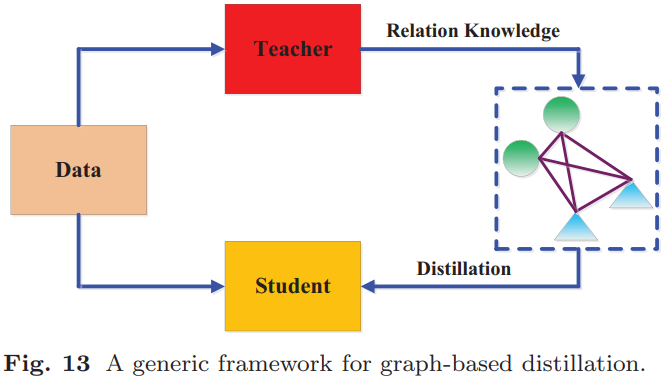
(4).基于图的蒸馏:使用图作为教师知识的载体或使用图来控制教师知识的消息传递。如下图所示:
(5).基于注意力的蒸馏:一些注意力机制用于知识蒸馏中以改善学生网络的性能。
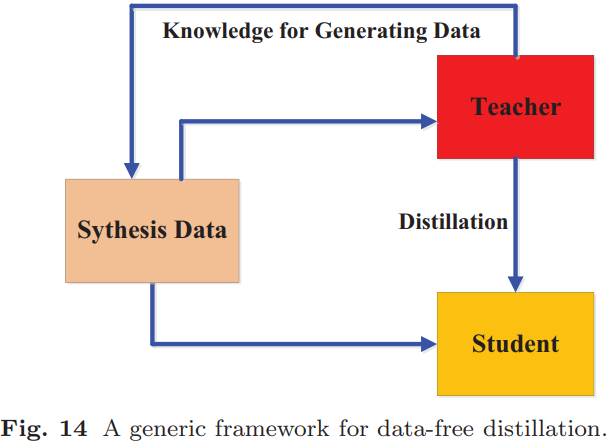
(6).无数据(data-free)蒸馏:克服由于隐私、合法性、安全性和保密性问题导致的数据不可用问题。数据是新生成或合成生成的。如下图所示:
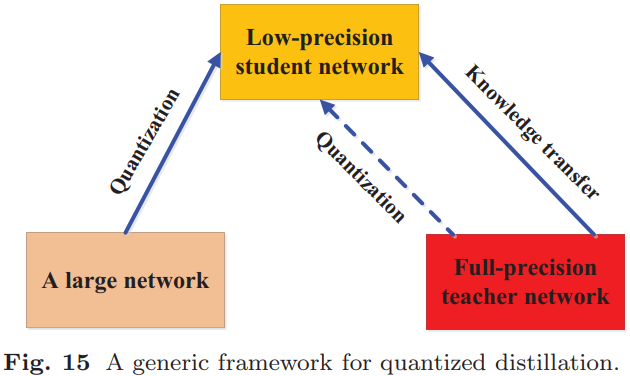
(7).量化蒸馏:如下图所示:
(8).终生(lifelong)蒸馏
(9).基于NAS(neural architecture search)的蒸馏
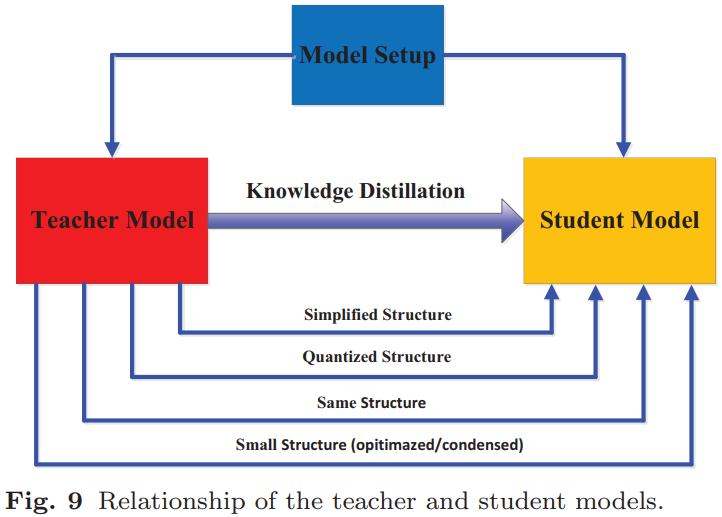
3. 师生架构:在知识蒸馏中,师生架构是形成知识迁移(knowledge transfer)的通用载体。教师模型和学生模型结构之间的关系如下图所示:
蒸馏方案(训练方案):根据教师模型是否与学生模型同时更新,知识蒸馏的学习方案可以直接分为三个主要类别:离线蒸馏、在线蒸馏和自蒸馏,如下图所示:
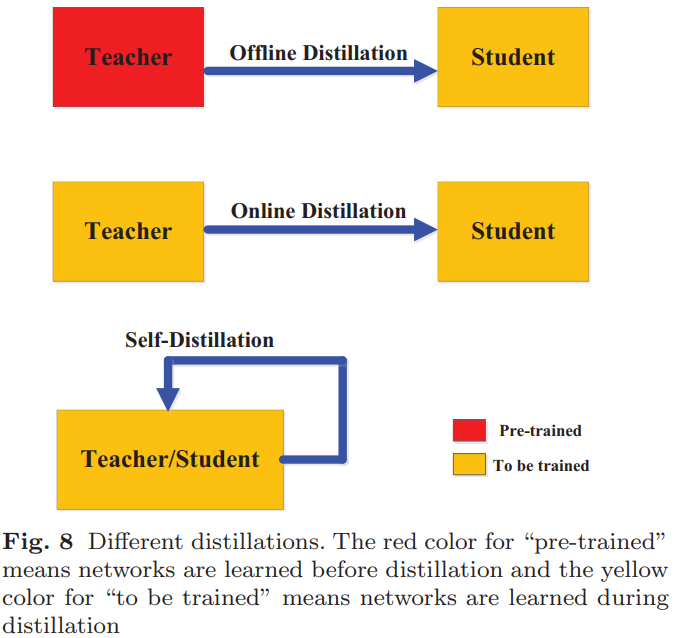
(1).离线蒸馏:整个训练过程有两个阶段:1).在蒸馏之前,首先在一组训练样本上对大型教师模型进行训练;2).教师模型用于以logits或中间特征的形式提取知识,然后在蒸馏过程中用于指导学生模型的训练。离线蒸馏中的第一阶段通常不作为知识蒸馏的一部分讨论,即假设教师模型是预定义的。离线蒸馏是许多大语言模型知识蒸馏方法的典型特征,在这些方法中,教师网络通常是一个更大的专有模型,其模型权重无法更改。
(2).在线蒸馏:教师模型和学生模型同时更新,整个知识蒸馏框架是端到端可训练的。在线蒸馏是一种具有高效并行计算的单阶段端到端训练方案。
(3).自蒸馏:在自蒸馏中,教师和学生模型使用相同的网络。这可以被视为在线蒸馏的特殊情况。
离线蒸馏意味着知识渊博的教师向学生传授知识;在线蒸馏意味着教师和学生一起相互学习;自蒸馏意味着学生自己学习知识。
蒸馏损失(distillation loss):知识蒸馏中的一种特殊类型的损失函数,负责将教师网络的"软知识"传递给学生网络。
知识蒸馏技术已成功应用于自然语言处理(NLP)、语音识别、视觉识别和推荐系统等多个领域。近年来,知识蒸馏的研究对大型语言模型(LLM)尤为重要。对于LLM而言,知识蒸馏已成为一种有效的手段,可以将领先的专有模型的高级功能迁移到更小、更易于访问的开源模型中。
注:以上主要内容及图来自于:https://arxiv.org/pdf/2006.05525
GitHub:https://github.com/fengbingchun/NN_Test