k8s日志收集
目录
- 有哪些日志需要收集
- 日志采集工具有哪些
- 1:ELK和EFK
- 2:Filebeat
- 3:新贵Loki
- 使用EFK收集控制台日志
- 1:部署Elasticsearch+Fluentd+Kibana
- 2:Kibana的使用
- 3:创建一个pod,进行日志采集
- 使用Filebeat收集自定义文件日志
- 1:创建Kafka和Logstash
- 3:注入Filebeat Sidecar
- Loki
- 1:创建loki命名空间
- 2:创建loki stack
- 3:查看grafana的密码
有哪些日志需要收集
为了更加方便的处理异常,日志的收集与分析极为重要,在学习日志收集之前,需要知道在集群内有哪些日志需要收集,在这里简单的总结一些比较重要的需要收集的日志:
服务器系统日志
Kubernetes 组件日志
应用程序日志
除了上面列出的日志外,可能还存在其他很多需要采集的日志,比如网关的日志、服务之间调用链的日志等。
日志采集工具有哪些
1:ELK和EFK
在传统的架构中,比较成熟且流行的日志收集平台是 ELK(Elasticsearch+Logstash+Kibana)其中 Logstash 负责采集日志,并输出给 Elasticsearch,之后用 Kibana 进行展示。
我们都知道,几乎所有的服务都可以进行容器化,ELK 技术栈同样可以部署到 Kubernetes 集群中,也可以进行相关的日志收集,但是由于 Logstash 比较消耗系统资源,并且配置稍微有点复杂,因此Kubernetes官方提出了EFK(Elasticsearch+Fluentd+Kibana)的解决方案,相对于ELK中的 Logstash,Fluentd 采用一锅端的形式,可以直接将输出到控制台的日志存储至 Elasticsearch,然后通过 Kibana进行展示。
但是 Fluentd 也有缺陷,比如,它只能收集控制台日志(程序直接输出到控制台的日志),不能收集非控制台的日志,所以很难满足生产环境的需求,因为大部分情况下,没有遵循云原生理念开发的程序,往往会输出很多日志文件,这些容器内的日志无法采集,除非在每个Pod 内添加一个 sidecar,将日志文件的内容进行 tai1 -f转换成控制台日志,但这也是非常麻烦的。
另一个问题是,大部分公司内都有很成熟的 ELK 平台,如果再搭建一个 EFK 平台,属于重复,当然用来存储日志的 Elasticsearch 集群不建议搭建在 Kubernetes 集群中,因为会非常浪费 Kubernetes 集群的资源,所以大部分情况下通过 Fluentd 采集日志输出到外部的 Elasticsearch 集群中。
综上所述,Fluentd 功能有限,Logstash 太重,所以需要一个中和的工具进行日志的收集工作,此时就可以采用一个轻量化的收集工具:Filebeat。
2:Filebeat
在早期的 ELK 架构中,日志收集均以 Logstash 为主,Logstash 负责收集和解析日志,对内存、CPU、I0 资源的消耗比较高,但是 Filebeat 所占系统的 CPU 和内存几乎可以忽略不计。
由于 Filebeat 本身是比较轻量级的日志采集工具,因此 Filebeat 经常被用于以 Sidecar 的形式配置在 Pod 中,用来采集容器内冲虚输出的自定义日志文件。当然,Filebeat 同样可以采用 Daemonset 的形式部署在 Kubernetes 集群中,用于采集系统日志和程序控制台输出的日志。
Fluentd 和 Logstash 可以将采集的日志输出到 Elasticsearch 集群,Filebeat 同样可以将日志直接存储到 Elasticsearch 中,但是为了更好的分析日志或者减轻 Elasticsearch 的压力,一般都是将日志先输出到 Kafka,再由 Logstash 进行简单的处理,最后输出到 Elasticsearch 中。
3:新贵Loki
上述讲的无论是 ELK、EFK 还是 Filebeat,都需要用到Elasticsearch 来存储数据,Elasticsearch本身就像一座大山,维护难度和资源使用都是偏高的。对于很多公司而言,热别是创新公司,可能并不想大费周章的去搭建一个 ELK、EFK或者其他重量级的日志平台,刚开始的人力投入可能是大于收益的,所以就需要一个更轻量级的日志收集平台。
为了解决上述的问题和难点,一个基于 Kubernetes 平台的原生日志收集平台 Loki stack 应运而生,所以一经推出,就受到了用户的青睐。
Loki 是 Grafana Labs 开源的一个支持水平扩展、高可用、多租户的日志聚合系统。
Loki 的架构如图所示
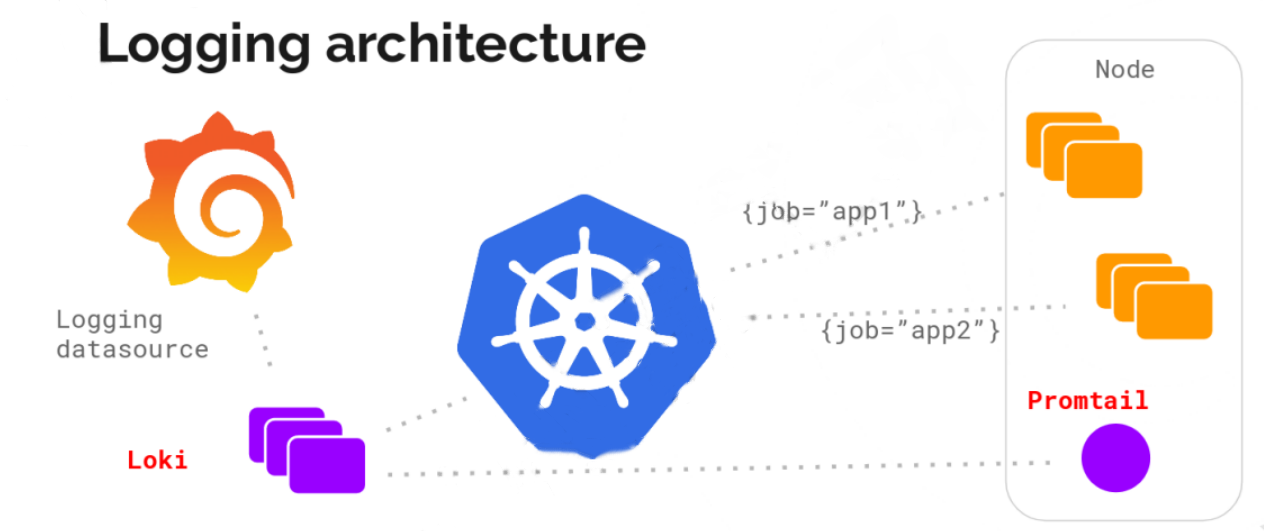
可以看到,Loki 主要包含如下组件:
Loki:主服务器,负责日志的存储和査询,参考了prometheus 服务发现机制,将标签添加到日志流,而不是想其他平台一样进行全文索引。
Promtail:负责收集日志并将其发送给 Loki,主要用于发现采集目标以及添加对应 Label,最终发送给 Loki。
Grafana:用来展示或查询相关日志,可以在页面查询指定标签Pod 的日志。
和其他工具相比,虽然 Loki 不如其他技术栈功能灵活,但是 Loki 不对日志进行全文索引,仅索引相关日志的元数据,所以 Loki 操作起来更简单、更省成本。而且 Loki 是基于 Kubernetes 进行设计的,
可以很方便的部署在 Kubernetes 上,并且对集群的 Pod 进行日志采集,采集时会将 Kubernetes 集群中的一些元数据自动添加到日志中,让技术人员可以根据命名空间、标签字段进行日志的过滤,可以很快的定位到相关日志。
通过上述的了解,我们知道了在 Kubernetes 集群中,日志收集可以选择的技术栈有很多,不只局限于上述提到的。对于平台的选择,没有最好,只有最合适,比如公司内已经有了很成熟的 ELK平台,那么我们可以直接采用 Fluentd 或 Filebeat,然后将 Kubernetes 的日志输出到已存在的 Elasticsearch集群中即可。如果公司并没有成熟的平台支持,又不想耗费很大的精力和成本去建立一个庞大的系统,那么 Loki stack 将会是一个很好的选择。
使用EFK收集控制台日志
首先我们使用 EFK 收集 Kubernetes 集群中的日志,本次实验讲解的是在 Kubernetes 集群中启动-个 Elasticsearch 集群,如果企业已经有了 Elasticsearch 集群,可以直接将日志输出到已有的Elasticsearch 集群中
本案例只用了一个节点去做,也可以增加节点数量
1:部署Elasticsearch+Fluentd+Kibana
创建EFK所用的命名空间

创建Elasticsearch集群(已有平台可以不创建)

备注:
为 es 集群创建服务,以便为 Fluentd 提供数据传入的端口

备注:
9200 端口:用于所有通过 HTTP 协议进行的 API 调用。包括搜索、聚合、监控、以及其他任何使用HTTP 协议的请求。所有的客户端库都会使用该端口与 Elasticsearch 进行交互。
9300 端口:是一个自定义的二进制协议,用于集群中各节点之间的通信。用于诸如集群变更、主节点选举、节点加入/离开、分片分配等事项。
创建es集群


创建Kibana(已有平台可以不创建)

修改Fluentd的部署文件
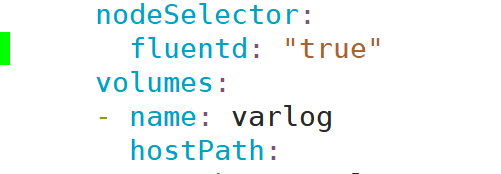
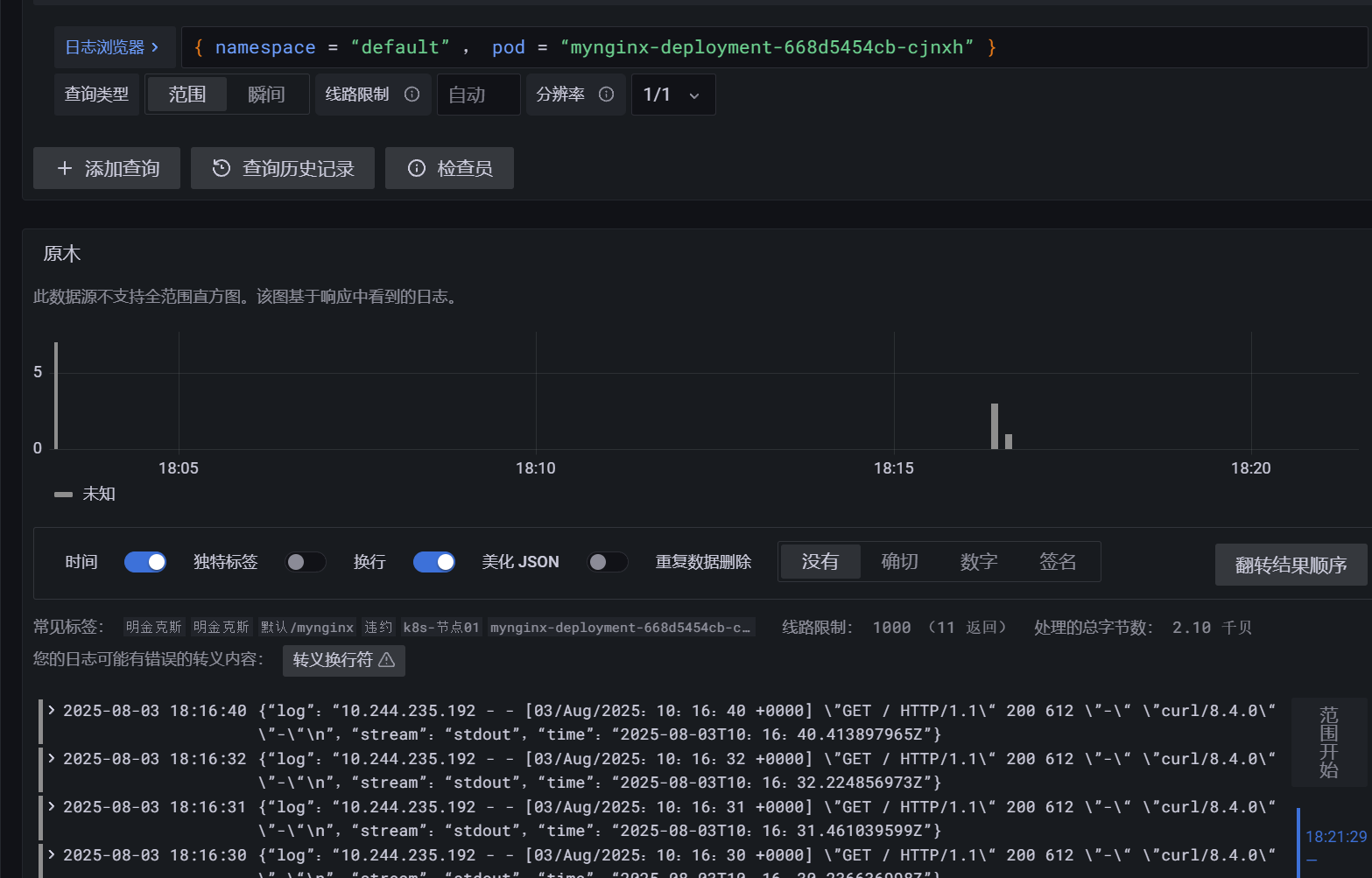
为需要采集日志的服务器设置标签


创建Fluentd

备注:
logstash_format true:指定是否使用常规的 index 命名格式,(logstash-%Y.%m.%d),默认为 false
fluentd 的 configMap 有一个字段需要注意,在 fluentd-es-configmap.yaml 文件的最后有一个output.conf:
host elasticsearch-logging
port 9200
此处的配置将收集到得数据输出到指定的 Elasticsearch 集群中,由于创建 Elasticsearch 集群时会自动创建一个名为 elasticsearch-logging 的 Service,因此默认 Fluentd 会将数据输出到前面创建的 Elasticsearch 集群中。如果企业已经存在一个成熟的 ELK 平台,可以创建一个同名的 Service 指向该集群,然后就能输出到现有的 Elasticsearch 集群中。
2:Kibana的使用
确认创建的pod已经启动

查看kibana的暴露端口

访问kibana
使用任意一个部署了kube-proxy服务的节点ip+端口/kibana即可访问
3:创建一个pod,进行日志采集
编写nginx部署文件

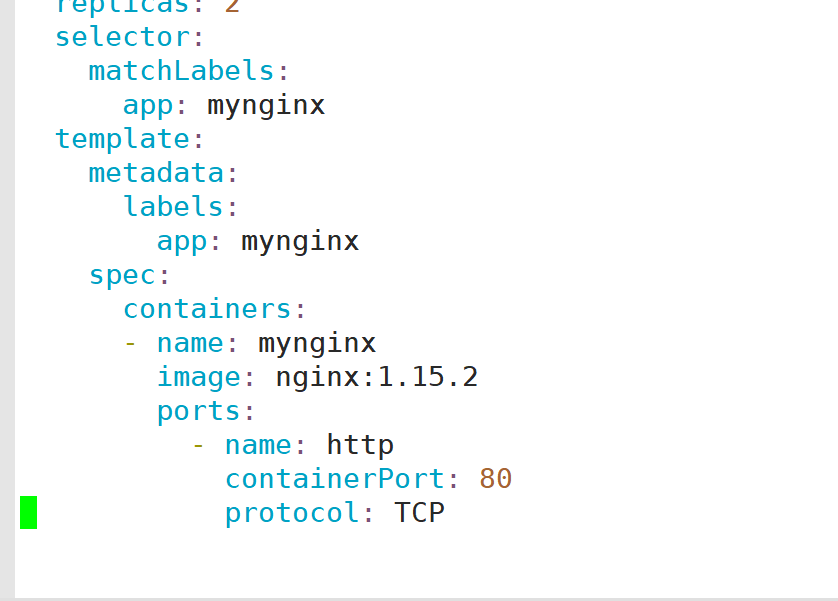
部署该deployment

查看暴露端口

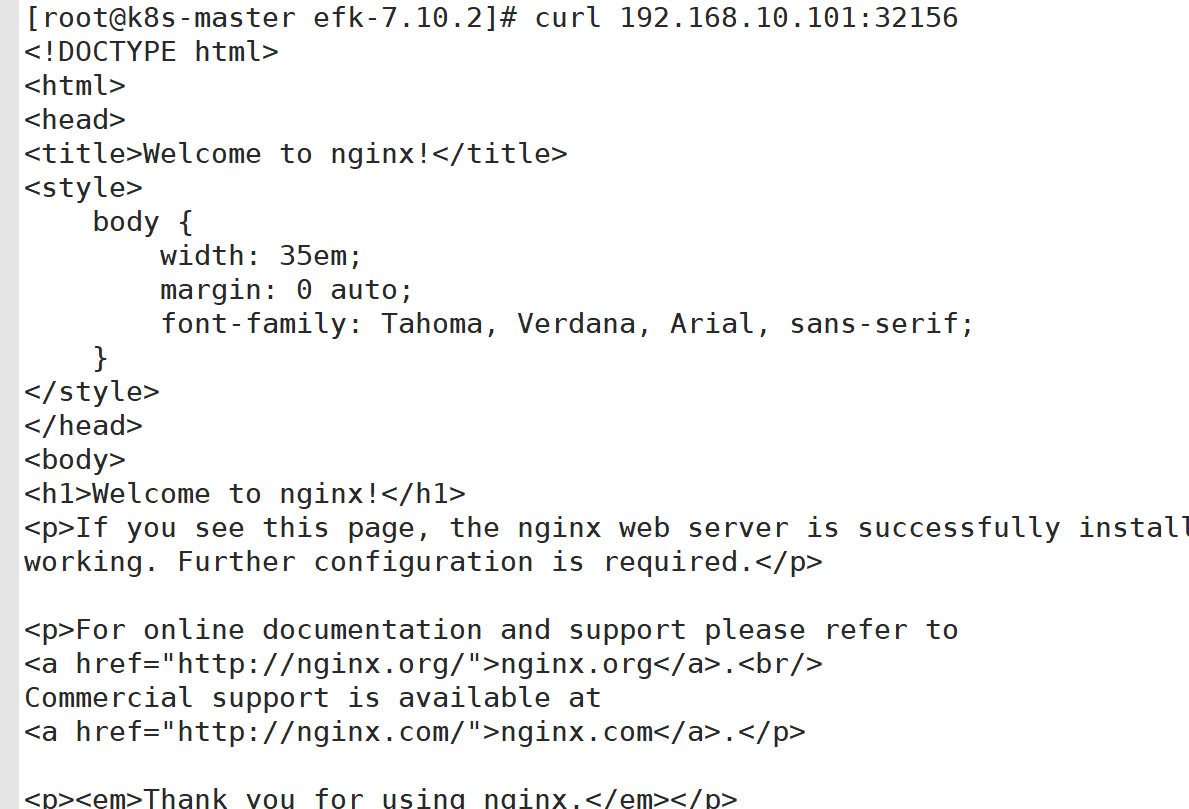
访问测试
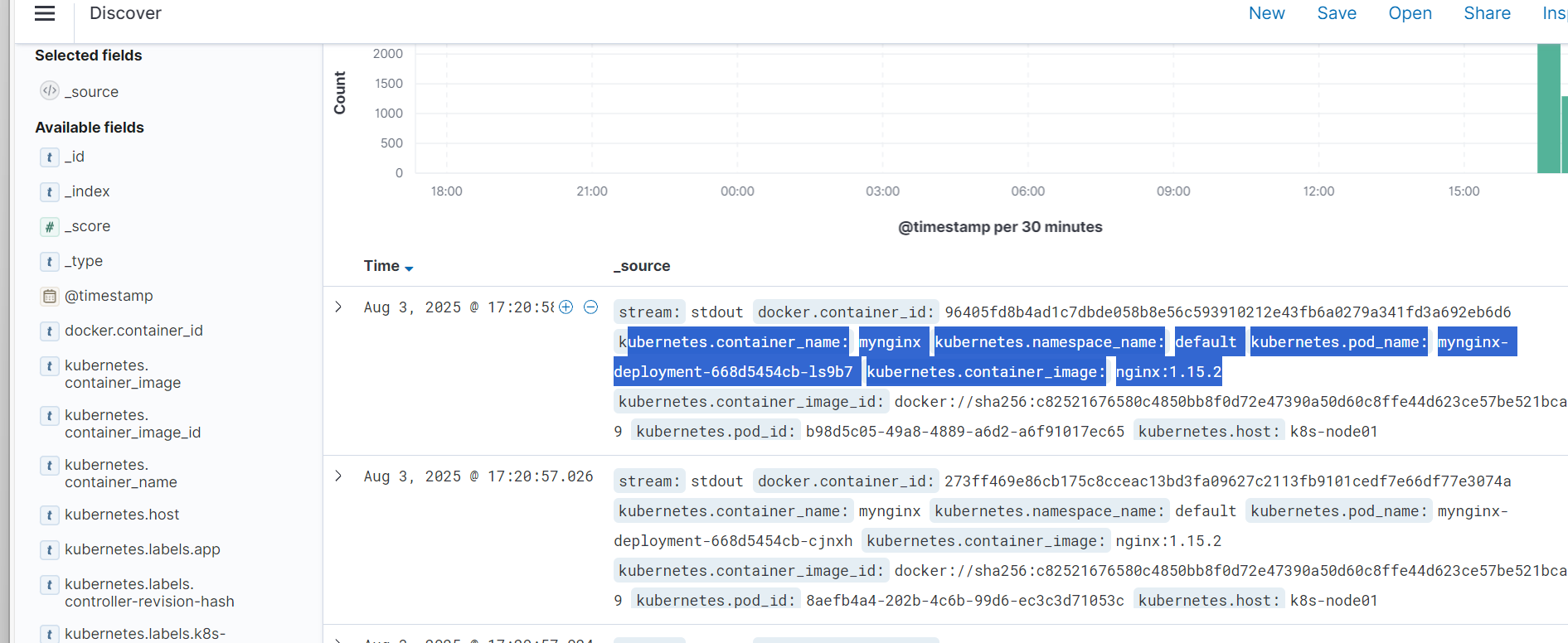
到kibana上查看
使用Filebeat收集自定义文件日志
基于云原生 12 要素开发的程序,一般会将日志直接输出到控制台,并非是指定一个文件存储日志,这一点和传统架构还是有区别的。但是公司内的程序并非都是基于云原生要素开发的,比如一些年代已久的程序,这类程序如果部署至 Kubernetes 集群中,就需要考虑如何将输出至本地文件的日志采集到Elasticsearch。
之前我们了解到 Filebeat 是一个非常轻量级的日志收集工具,可以将其和应用程序部署至一个 Pod中,通过 Volume 进行日志文件的共享,之后 Filebeat 就可以采集里面的数据,并推送到日志平台。为了减轻 Elasticsearch 的压力。本案例将引入 Kafka 消息队列来缓存日志数据,之后通过Logstash 简单处理一下日志,最后再输出到 Elasticsearch 集群。这种架构在生产环境中也是常用的架构,因为日志数量可能比较多,同时也需要对其进行加工。当然 Fluentd 也可以将日志输出到 Kafka。
1:创建Kafka和Logstash
部署zookeeper
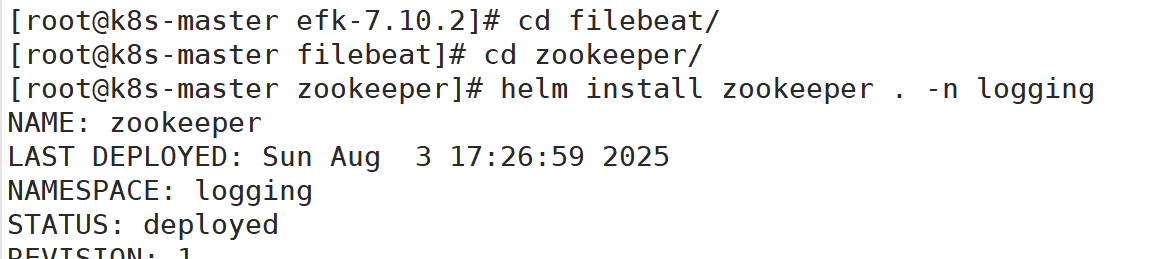
查看zookeeper状态

备注:
-l:指定标签
等一会,部署好显示状态为 Running
部署kafka
查看kafka的状态
创建logstash服务

3:注入Filebeat Sidecar
创建模拟程序

查看pod状态
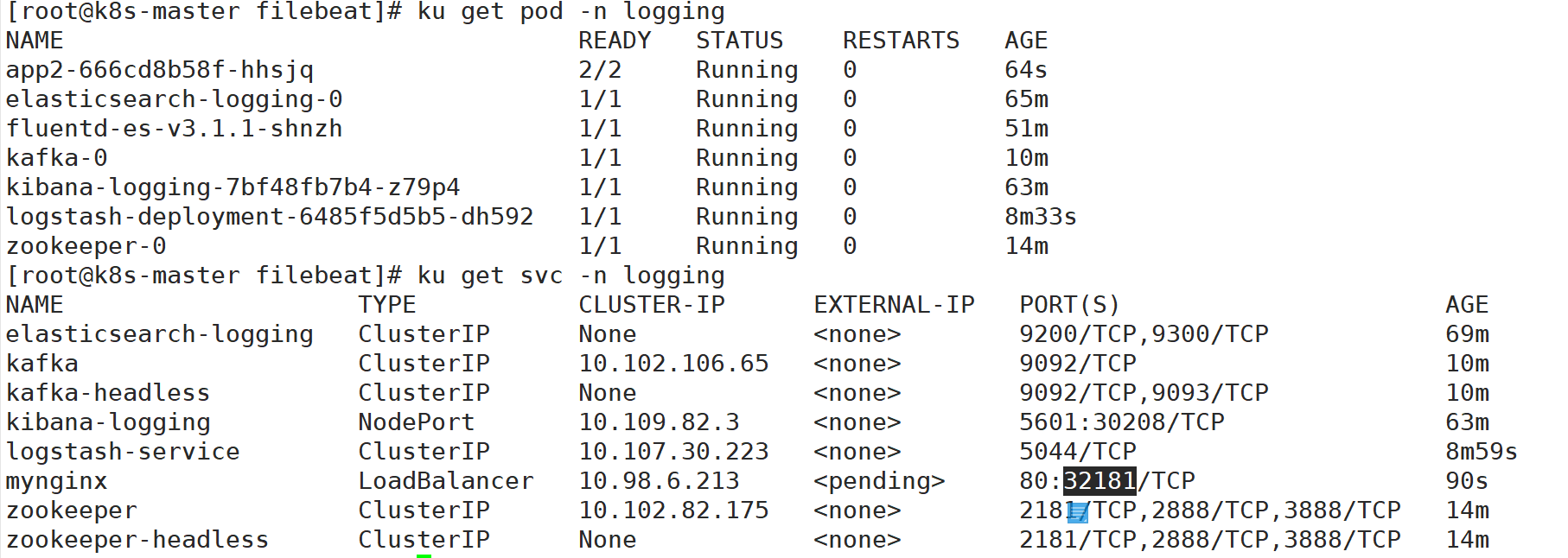
备注:
这里可以访问一下次服务,生成对应的日志。
添加索引查看
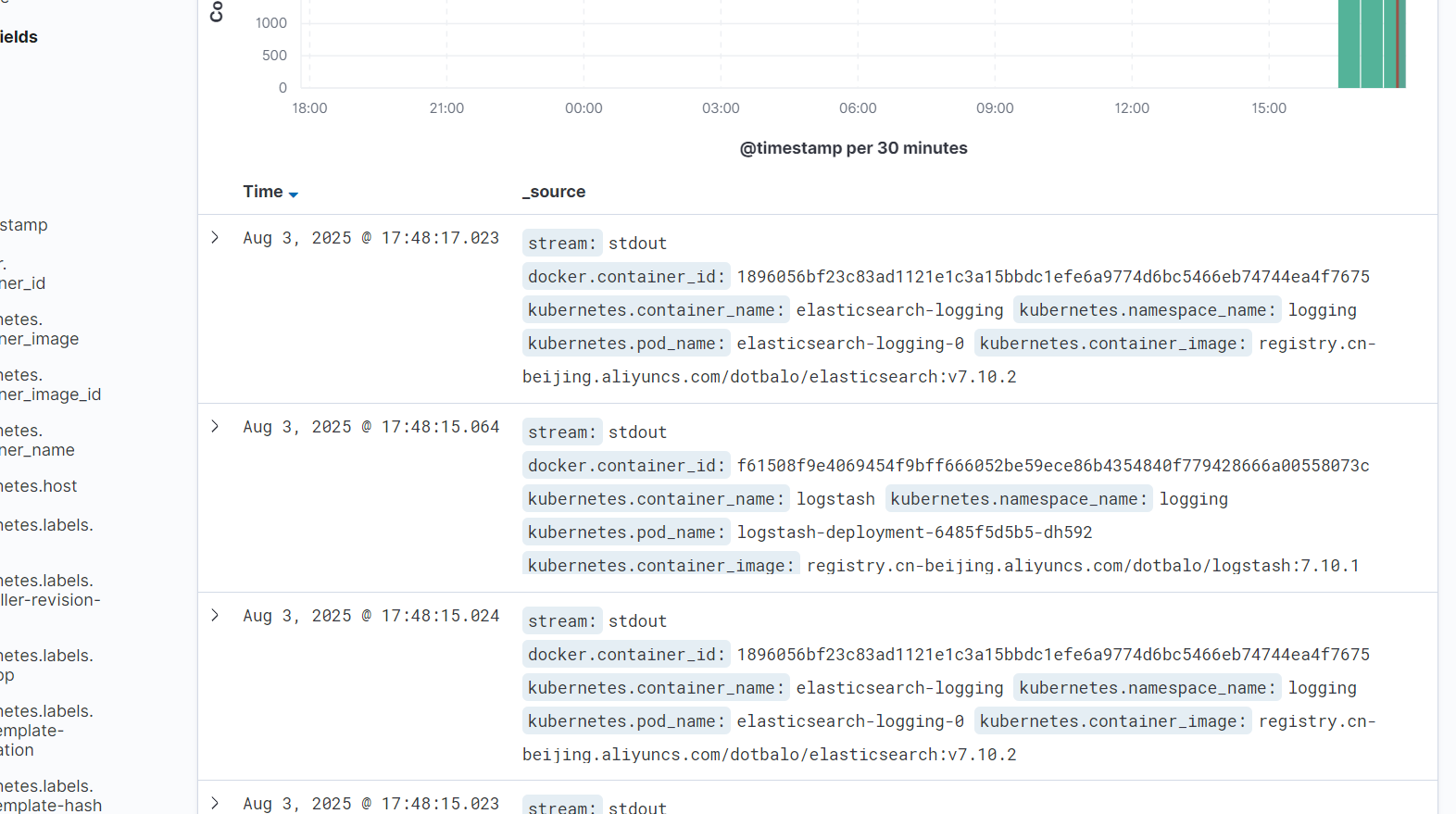
Loki
1:创建loki命名空间

2:创建loki stack

查看状态

查看暴露的端口

3:查看grafana的密码
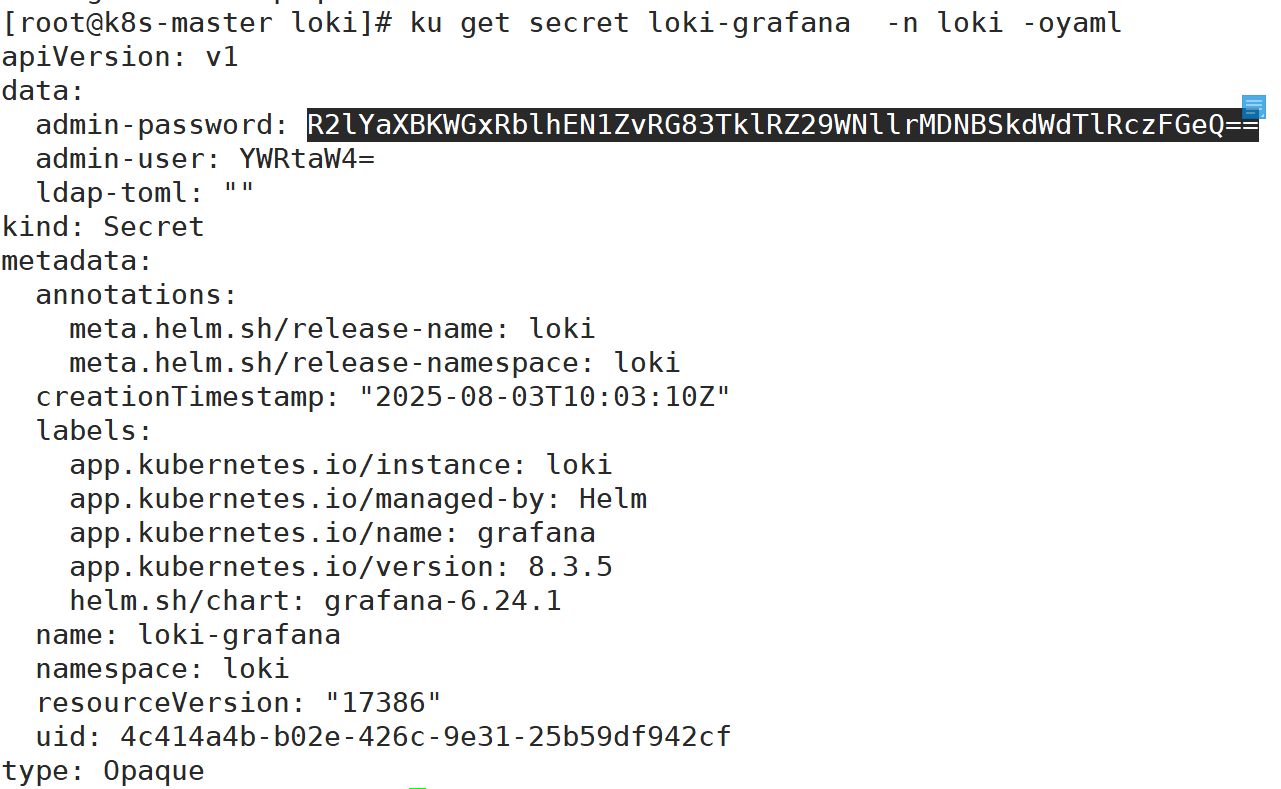

修改密码
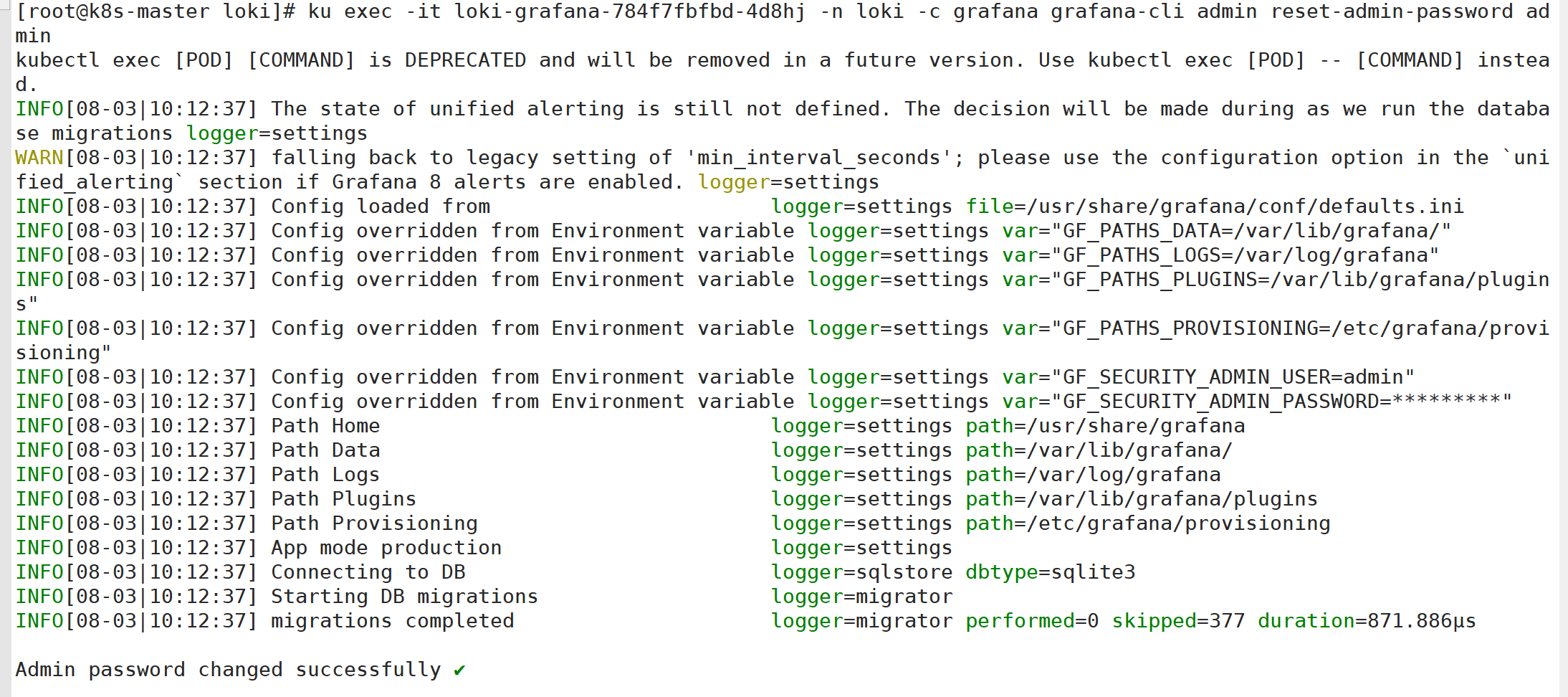
也可以在这里修改密码

客户端访问
还是之前的nginx

在loki中查看pod日志