读取数据集及数据集划分
文章目录
- 读取数据集及数据集划分
- 一、scikit-learn工具介绍
- 1 scikit-learn安装
- 2 Scikit-learn包含的内容
- 二、数据集读取与划分详解
- 1、特征与标签(Feature & Target)
- 2、数据集的获取方式
- 1. 使用 `sklearn` **内置**数据集 `load`
- 🏷️ **使用** `load_iris(return_X_y=True)` **加载特征和标签**
- ✅ `return_X_y=True` 的作用:
- 📦 返回值说明:
- ✅ 对比 `return_X_y=False` 的默认行为:
- 2.现实世界数据集(需联网下载一次)`fetch`
- 3. 使用 Pandas 读取本地数据集
- 三、为什么要划分数据集?
- 四、如何进行数据划分?
- 示例:鸢尾花数据集划分
- 🤔 思考:数据标签不平衡会怎样?
- ✅ 为了解决这个问题,我们可以使用:
- 🔍 参数 `stratify=y` 的作用:
- 🔁 预告:分层K折交叉验证
- 🧠 小结
读取数据集及数据集划分
一、scikit-learn工具介绍

- Python语言机器学习工具
- Scikit-learn包括许多智能的机器学习算法的实现
- Scikit-learn文档完善,容易上手,丰富的API接口函数
- Scikit-learn官网:https://scikit-learn.org/stable/#
- Scikit-learn中文文档:https://scikitlearn.com.cn/
- scikit-learn中文社区
1 scikit-learn安装
参考以下安装教程:https://www.sklearncn.cn/62/
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple scikit-learn
2 Scikit-learn包含的内容
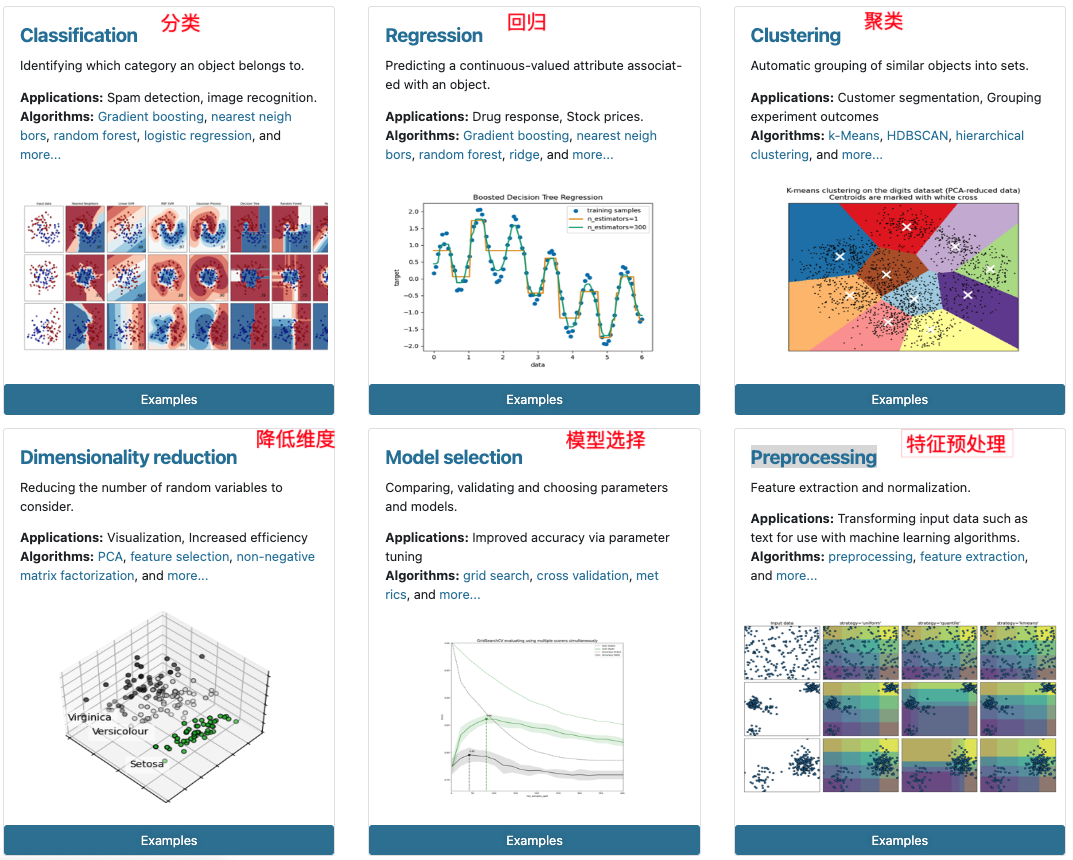
二、数据集读取与划分详解

1、特征与标签(Feature & Target)
在机器学习中,我们训练模型的目标是让它能够从数据中学习规律,并在遇到新数据时做出正确的预测。
- 特征(Feature):是数据的输入,是描述样本属性的变量,例如身高、体重、温度等。
- 标签(Target):是模型要预测的目标值,也叫做响应变量或输出变量。
举例:
| 身高(cm) | 体重(kg) | 是否肥胖 |
|---|---|---|
| 170 | 70 | 否 |
| 160 | 80 | 是 |
在这个例子中:
- “身高” 和 “体重” 是特征(X)
- “是否肥胖” 是标签(y)
2、数据集的获取方式
我们可以通过多种方式获取数据:
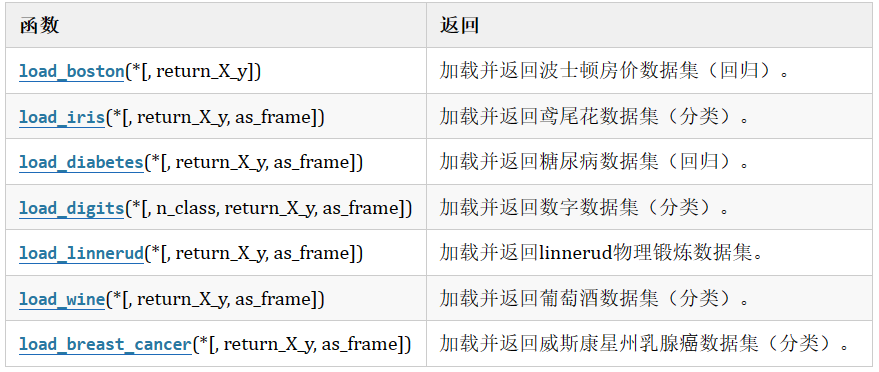
1. 使用 sklearn 内置数据集 load
from sklearn.datasets import load_iris
iris = load_iris()
🏷️ 使用 load_iris(return_X_y=True) 加载特征和标签
在使用 sklearn.datasets 提供的内置数据集(如鸢尾花 iris 数据集)时,我们经常只关心两个核心内容:
- 特征(Feature, X):用来描述样本的属性,如花瓣长度、宽度等;
- 标签(Target, y):样本所属的类别,如鸢尾花的种类。
为了快速获取这两个内容,load_iris() 提供了一个参数:
✅ return_X_y=True 的作用:
from sklearn.datasets import load_irisX, y = load_iris(return_X_y=True)
| 参数 | 类型 | 说明 |
|---|---|---|
return_X_y | bool型 | 如果设置为 True,直接返回 (X, y) |
📦 返回值说明:
X:一个二维数组(ndarray),形状为(样本数量, 特征数量),表示所有样本的特征矩阵;y:一个一维数组,表示每个样本对应的分类标签。
👉 它们组成一个 元组(tuple),我们通过 解构赋值 方式将其拆分为变量 X 和 y,这样可以直接用于后续的数据预处理或模型训练。
✅ 对比 return_X_y=False 的默认行为:
data = load_iris()
print(data.keys())
如果不设置 return_X_y=True,返回的是一个 Bunch 对象(类似字典),需要手动访问:
X = data.data
y = data.target
访问内容:
iris.data # 特征数据
iris.feature_names # 特征名称
iris.target # 目标标签
iris.target_names # 标签说明
iris.DESCR # 数据集描述
2.现实世界数据集(需联网下载一次)fetch
例如:20类新闻文本、加利福尼亚房价数据等
from sklearn.datasets import fetch_20newsgroups
news = fetch_20newsgroups(data_home='./src',subset='all')
说明:
-
None 这是默认值,下载的文件路径为 “C:/Users/ADMIN/scikit_learn_data/20news-bydate_py3.pkz”
自定义路径 例如 “./src”, 下载的文件路径为“./20news-bydate_py3.pkz” -
subset可选'train'、'test'、'all' -
返回的是一个 Bunch 对象,属性包括
data,target,target_names,filenames等
3. 使用 Pandas 读取本地数据集
import pandas as pd
df = pd.read_csv("路径/文件名.csv")
X = df.iloc[:, :-1] # 假设最后一列是标签
y = df.iloc[:, -1] # 标签列
三、为什么要划分数据集?
我们训练模型的目的是让它泛化到未见过的数据,所以不能只在一份数据上训练和测试。

数据集通常会被划分为:
- 训练集(Training Set):用来训练模型。
- 测试集(Test Set):用来测试模型的泛化能力。
- (有时还有验证集用于调参)
这样做的好处:
- 防止模型过拟合训练数据。
- 更真实地评估模型性能。
四、如何进行数据划分?
使用 train_test_split 函数:
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42
)
参数说明:
test_size:测试集占比,一般为 0.2(即20%)random_state:设置随机种子,保证结果可重复
示例:鸢尾花数据集划分
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_splitiris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=22
)
print(X_train.shape, X_test.shape)
🤔 思考:数据标签不平衡会怎样?
在实际分类问题中,标签可能分布不均(比如类别0有 90%,类别1 只有 10%)。如果我们随机划分数据集,可能会出现:
- 训练集或测试集中完全没有某些类别,导致模型无法识别这类样本;
- 模型在训练时只学会预测“多数类”,造成评估失真。
✅ 为了解决这个问题,我们可以使用:
train_test_split(X, y, test_size=0.2, stratify=y, random_state=42)
🔍 参数 stratify=y 的作用:
保证划分后的训练集和测试集中各类别的比例与原始数据集保持一致。
| 参数 | 作用说明 |
|---|---|
stratify=y | 按照标签y的比例进行分层采样,保持类别分布稳定 |
🔁 预告:分层K折交叉验证
即使加入了 stratify,我们还是依赖“单次划分”。为了更稳健地评估模型性能,我们还会学习分层K折交叉验证(Stratified K-Fold CV),它在每一折都保持类别分布一致,让评估结果更加可靠。
🧠 小结
- 特征是模型的输入,标签是我们要预测的目标
- 数据划分是构建模型的第一步,要考虑到数据的分布是否均衡
- 使用
stratify参数可以避免标签不平衡带来的划分偏差 - 为提高评估稳健性,后续我们将引入 分层K折交叉验证