从零开始:Kaggle 竞赛实战入门指南
一、Kaggle社区概述
Kaggle 是全球最大的数据科学和机器学习社区,由Anthony Goldbloom于2010年创立,2017年被Google收购。平台专注于数据科学竞赛、开源数据集共享、协作编程以及技能学习,吸引了从初学者到专业数据科学家的广泛用户群体。
1、核心功能
竞赛(Competitions)
Kaggle以举办数据科学竞赛闻名,企业和组织通过发布数据集和问题,邀请社区成员提交解决方案。优胜者通常获得奖金或职业机会,竞赛涵盖预测建模、自然语言处理、计算机视觉等领域。
数据集(Datasets)
平台提供超过50,000个开源数据集,涵盖医疗、金融、体育等多个领域。用户可上传、下载数据集,并通过版本控制和讨论功能协作优化数据质量。
代码笔记本(Notebooks)
集成Jupyter Notebook环境,支持Python和R语言。用户可编写、运行代码,并分享给社区。优秀笔记本常被标记为“Expert”或“Grandmaster”,提升个人影响力。
学习资源(Courses)
提供免费的数据科学课程,涵盖Python、机器学习、数据可视化等主题。课程以实践为导向,适合不同水平的学习者。
社区与协作
用户可通过论坛(Discussion)提问或分享见解,形成活跃的技术交流氛围。Kaggle还设有“团队”功能,允许成员组队参与竞赛。
2、用户等级体系
Kaggle通过贡献度划分用户等级,从Novice到Grandmaster。等级依据竞赛排名、笔记本投票、数据集和讨论质量等综合评定,激励用户持续参与。
4、影响力与价值
Kaggle不仅是技能提升平台,也是企业招聘的重要渠道。许多用户通过竞赛成绩和项目展示获得职业机会。此外,平台推动了开源文化,助力解决现实世界的数据问题。
二、注册 Kaggle 账号
https://kagglecn.com
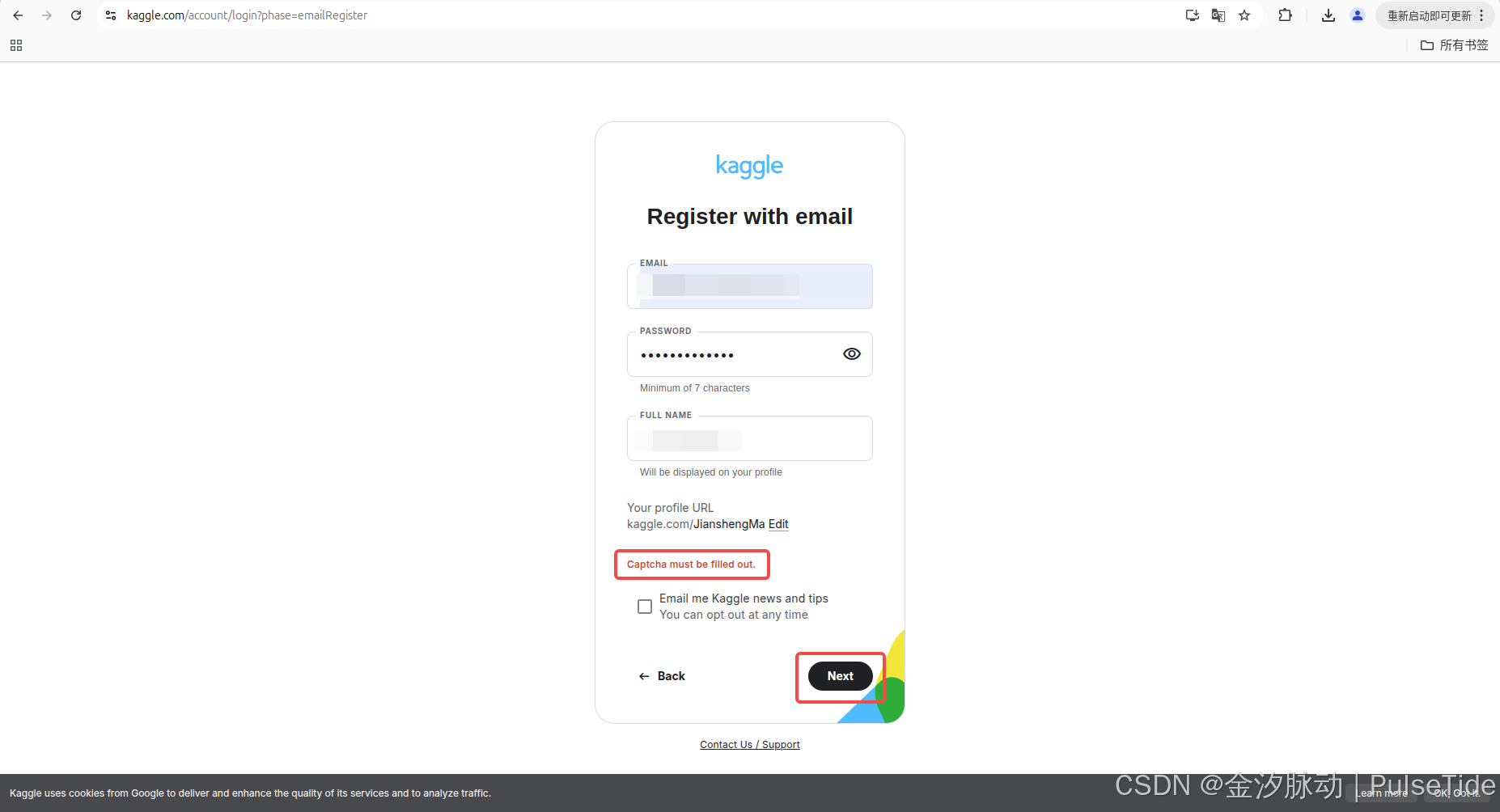
1、注册验证码问题
Captcha must be filled out.
在注册 Kaggle 时,通常会因为网络问题导致提交表单时验证码报错:
2、解决方案
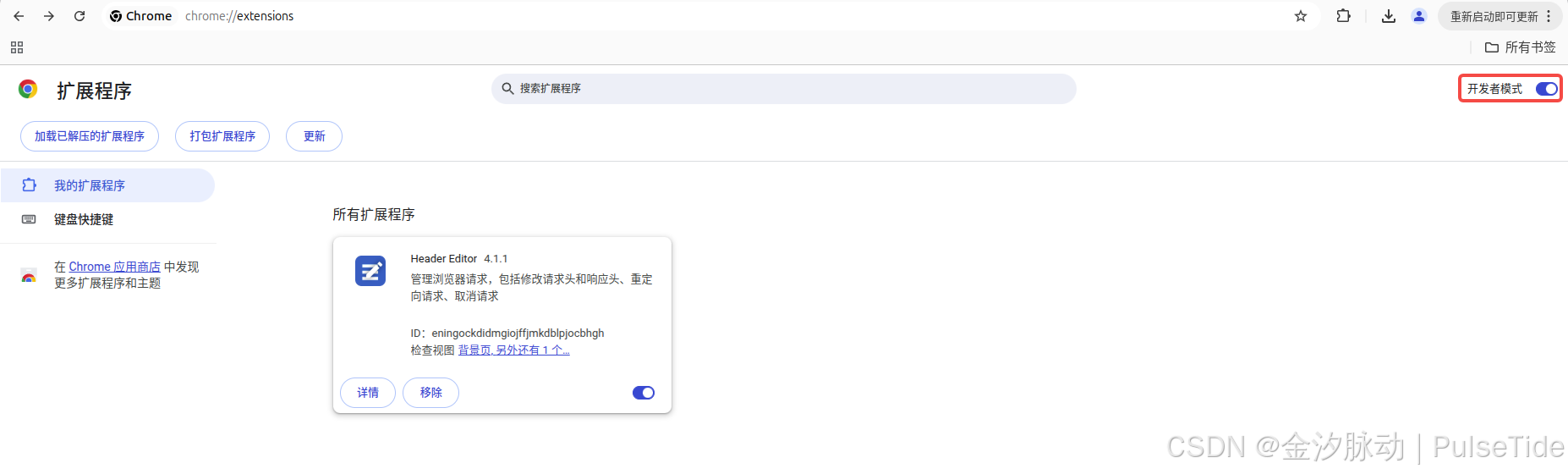
以谷歌浏览器为例,先下载插件 Header Editor 4.1.1.crx,然后打开拓展程序管理页面chrome://extensions/,开启开发者模式,直接把插件拖进来或者点击左上角的加载已解压的扩展程序:
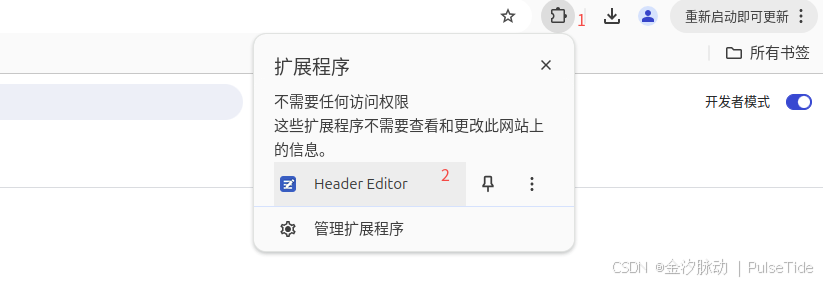
此时启用拓展程序,进行配置:
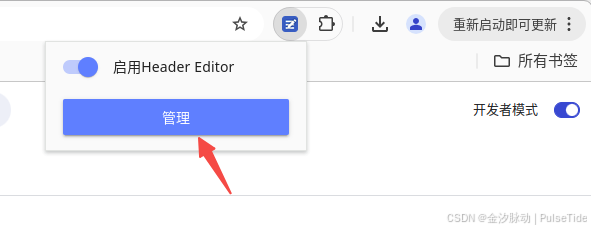
切到导出和导入页签,在下载规则的 URL 栏位输入 https://azurezeng.com/static/HE-GoogleRedirect.json,点击下载按钮,等待导入结果刷新,最后点击保存:
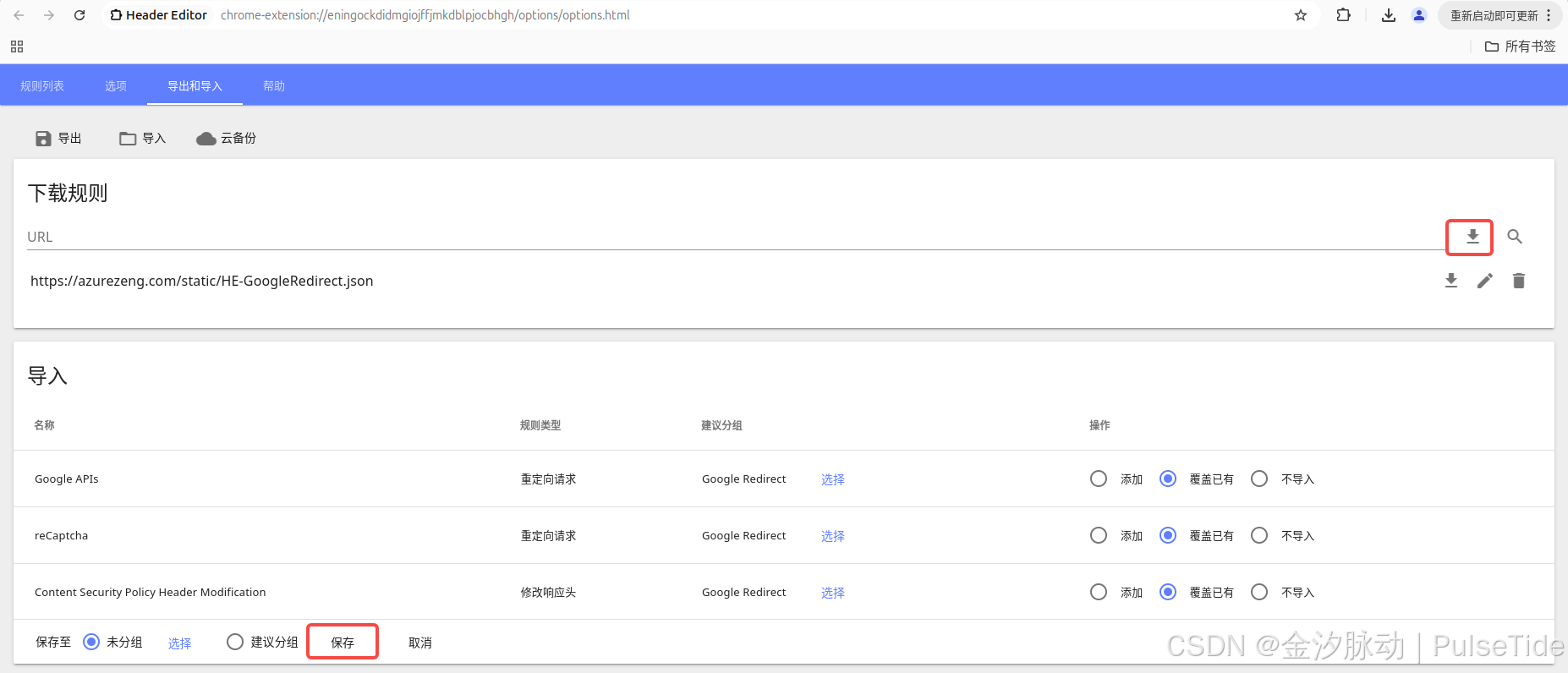
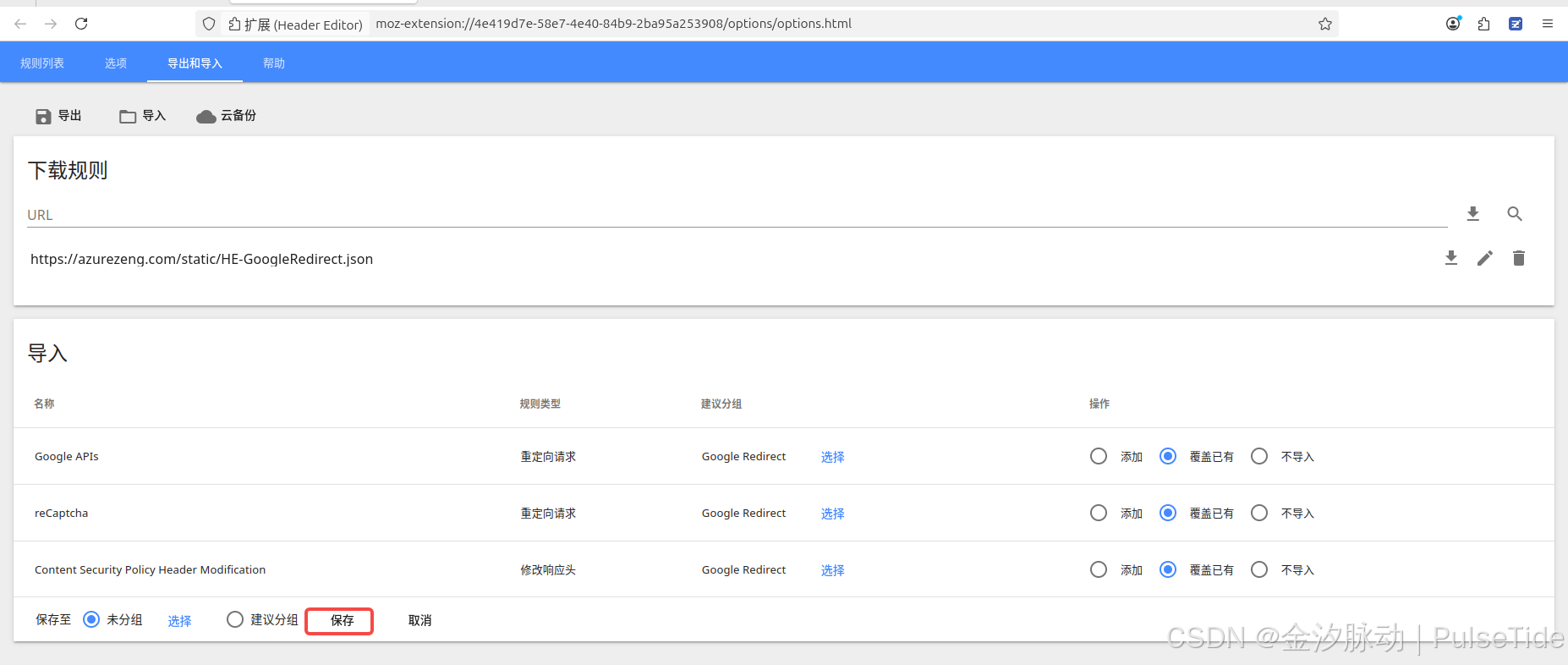
以火狐浏览器为例,同样先下载插件header_editor-4.1.1.xpi,然后打开拓展管理页面about:addons,直接把插件拖进去,同样地启用配置插件:

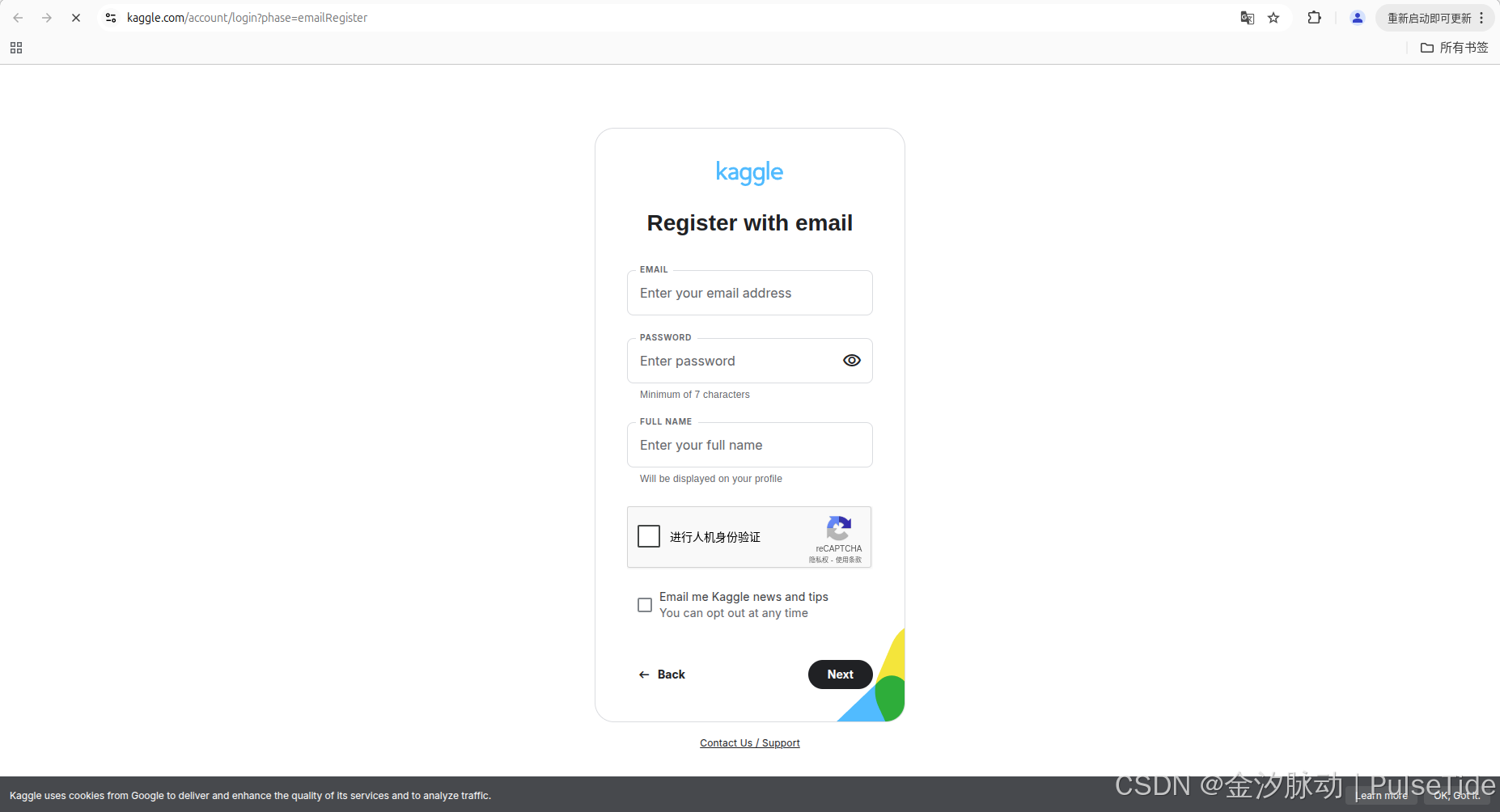
刷新 Kaggle 注册页面,可以看到验证码正常显示了:
注册成功!
三、竞赛指南
Competitions->Getting Started,在竞赛页面开始部分,可以看到有一些较为容易上手的机器学习竞赛项目,我们选择其中的“泰坦尼克号生存者预测”作为开始。
1、赛事任务
使用机器学习创建一个模型来预测哪些乘客在泰坦尼克号沉船灾难中幸存下来。
2、数据集
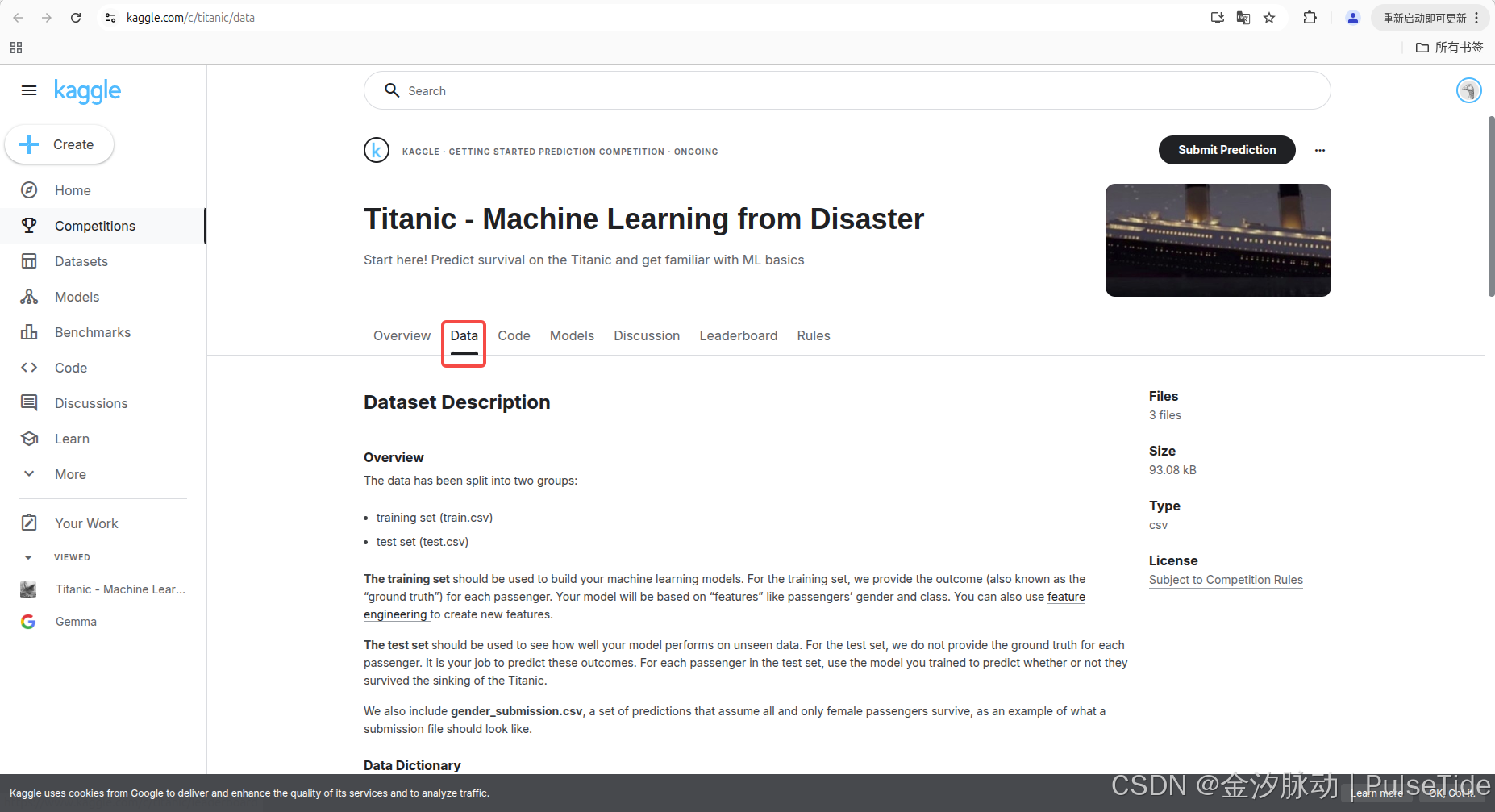
该赛事一共提供了三个数据集:
- 训练集(train.csv)
- 核心用途:用于构建机器学习模型
- 关键特征:包含乘客性别、舱位等级等特征字段
- 特殊属性:提供每个乘客的生存结果
- 扩展功能:支持通过特征工程创建新特征
- 测试集(test.csv)
- 核心用途:评估模型在未知数据上的表现
- 关键差异:不提供乘客生存的真实结果
- 用户任务:需使用训练好的模型预测乘客生存状态
- 应用场景:模拟真实业务中的预测场景
- 示例文件(gender_submission.csv)
- 示范性质:展示标准提交文件的格式规范
- 设计目的: 演示预测结果的文件结构,说明二分类问题的提交格式 。
如果需要本地环境进行实验的话,可以点击 Download All 下载全部数据集:
3、代码教程
Titanic Tutorial 介绍了代码如何实现训练模型并提交第一个预测结果:
可以点进链接直接查看 notebook:
当然也可以复制一份 notebook:
四、上手实战
1、创建一个Notebook
自动创建的 Notebook 会自动生成一段代码,它引导我们如何读取文件输入。
2、导入数据集
我们可以在线导入竞赛数据集:
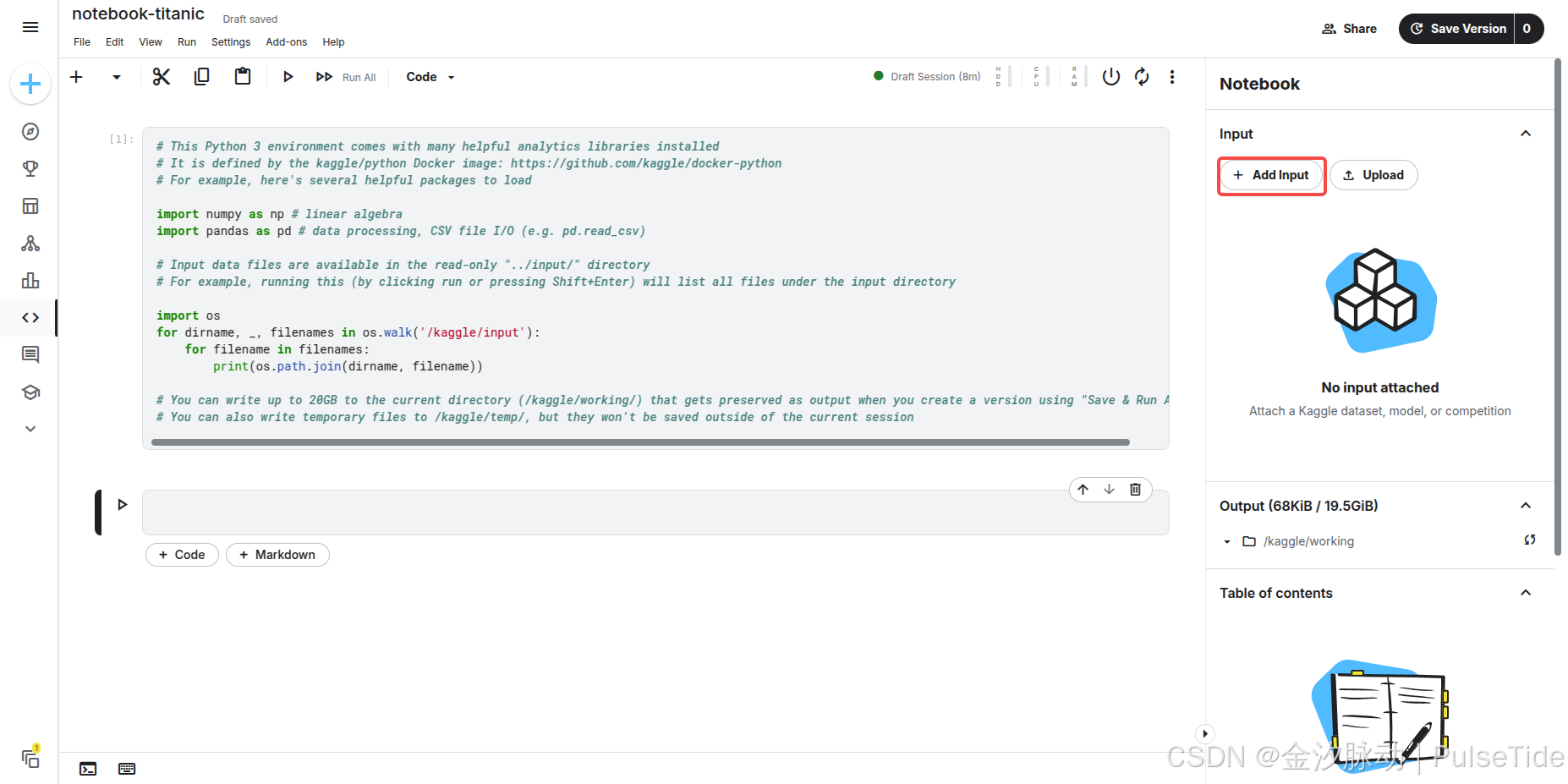
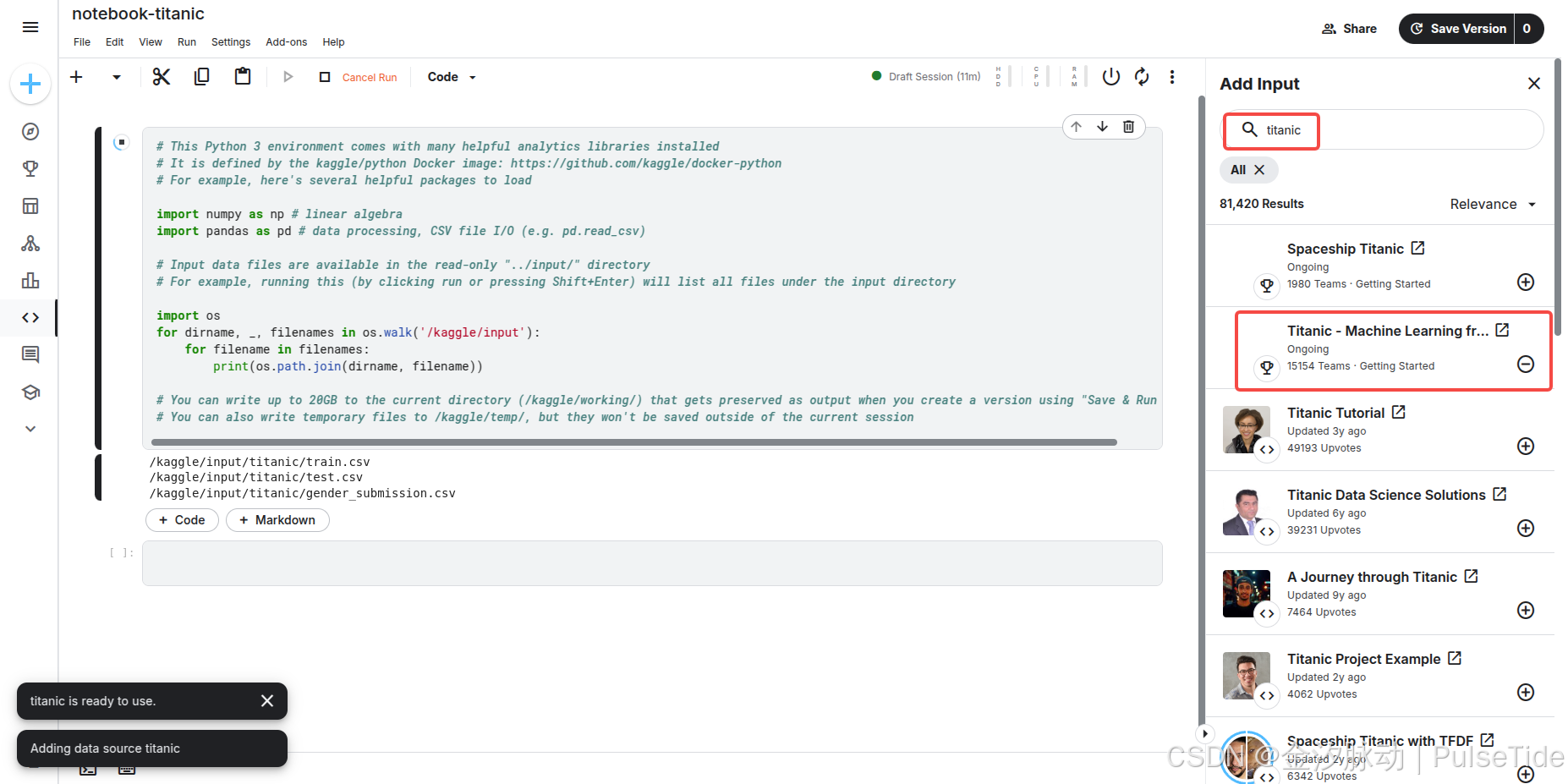
此时按下 [Shift] + [Enter] 执行代码,则对应输出三个文件路径。
除了在线导入数据集,我们也可以上传本地数据集:
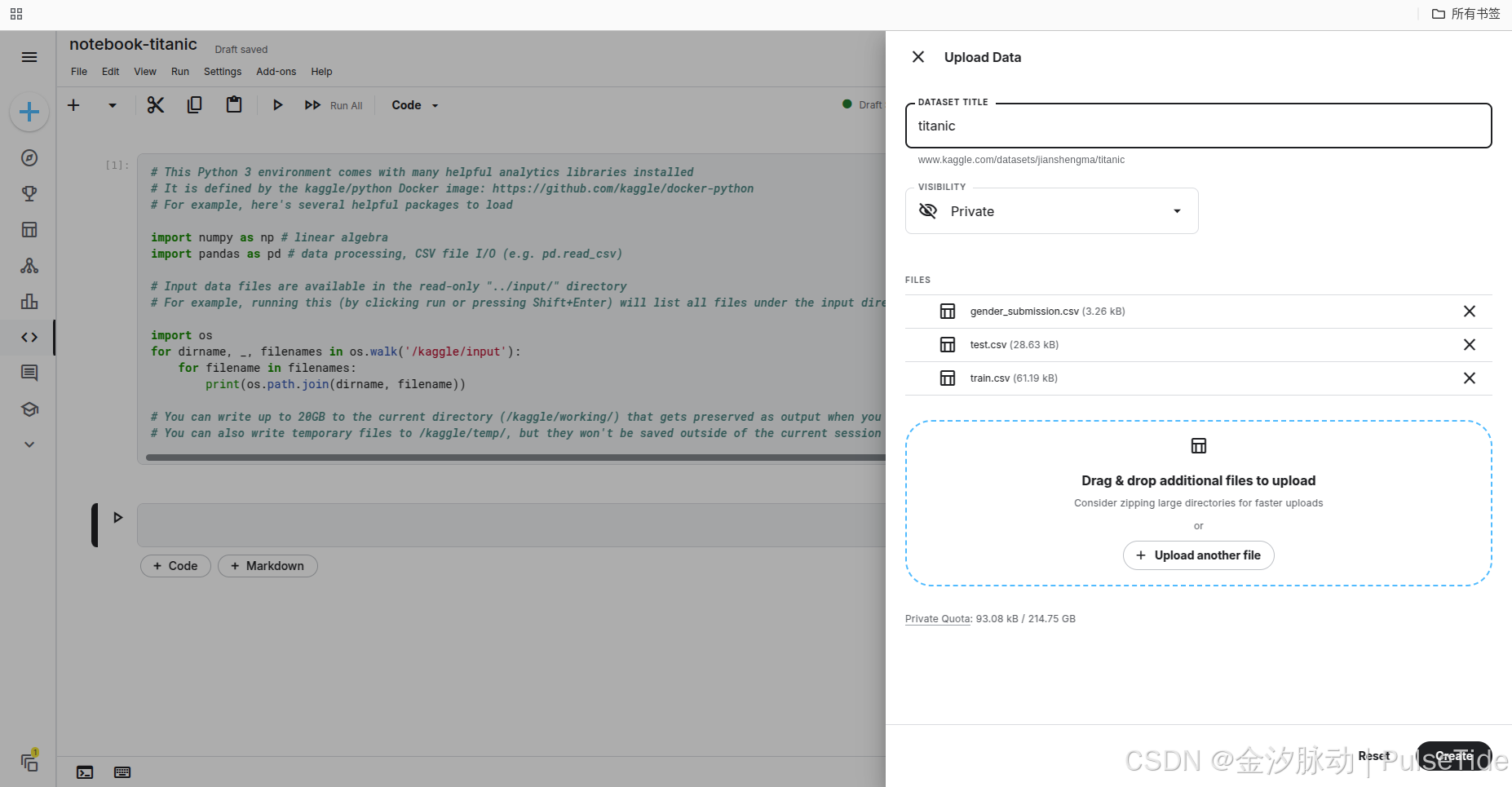
3、加载数据
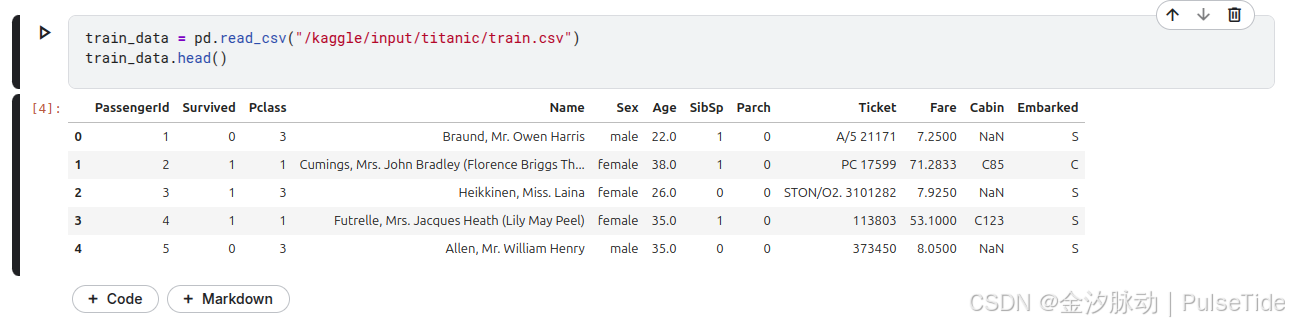
读取训练集数据,并查看前5行数据:
train_data = pd.read_csv("/kaggle/input/titanic/train.csv")
train_data.head()
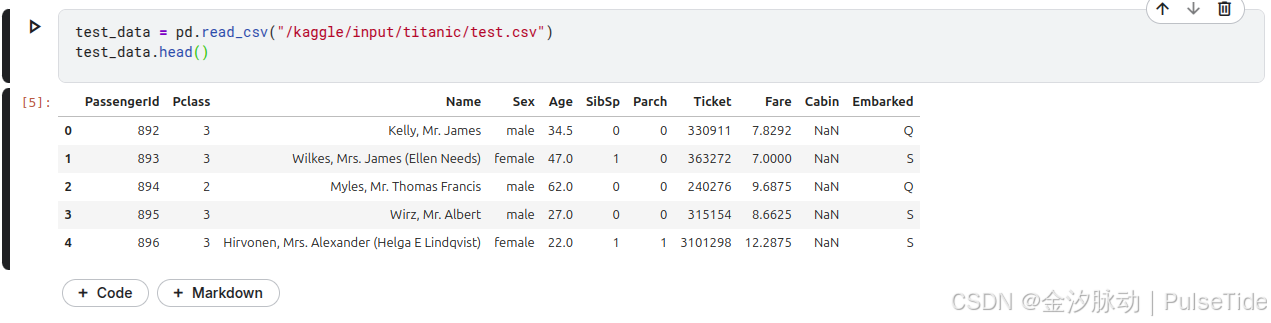
读取测试集数据,并查看前5行数据:
test_data = pd.read_csv("/kaggle/input/titanic/test.csv")
test_data.head()
4、建立模型
Tutorial 中构建了一个名为随机森林的模型,该模型由多棵"决策树"组成,每棵树将独立分析每位乘客的数据,并对其是否幸存进行投票,最终,随机森林模型将通过民主决策确定结果:得票最高的结果即为预测结果。
Tutorial 代码通过分析数据中的四个字段(“Pclass”(舱位等级)、“Sex”(性别)、“SibSp”(同行兄弟姐妹/配偶数)和"Parch"(同行父母/子女数))来寻找规律,它将基于 train.csv 训练集文件中的数据规律构建随机森林模型中的决策树,随后对 test.csv 测试集中的乘客生成预测结果,同时,代码会将预测结果保存至 submission.csv 文件中。
from sklearn.ensemble import RandomForestClassifiery = train_data["Survived"]features = ["Pclass", "Sex", "SibSp", "Parch"]
X = pd.get_dummies(train_data[features])
X_test = pd.get_dummies(test_data[features])model = RandomForestClassifier(n_estimators=100, max_depth=5, random_state=1)
model.fit(X, y)
predictions = model.predict(X_test)output = pd.DataFrame({'PassengerId': test_data.PassengerId, 'Survived': predictions})
output.to_csv('submission.csv', index=False)
print("Your submission was successfully saved!")
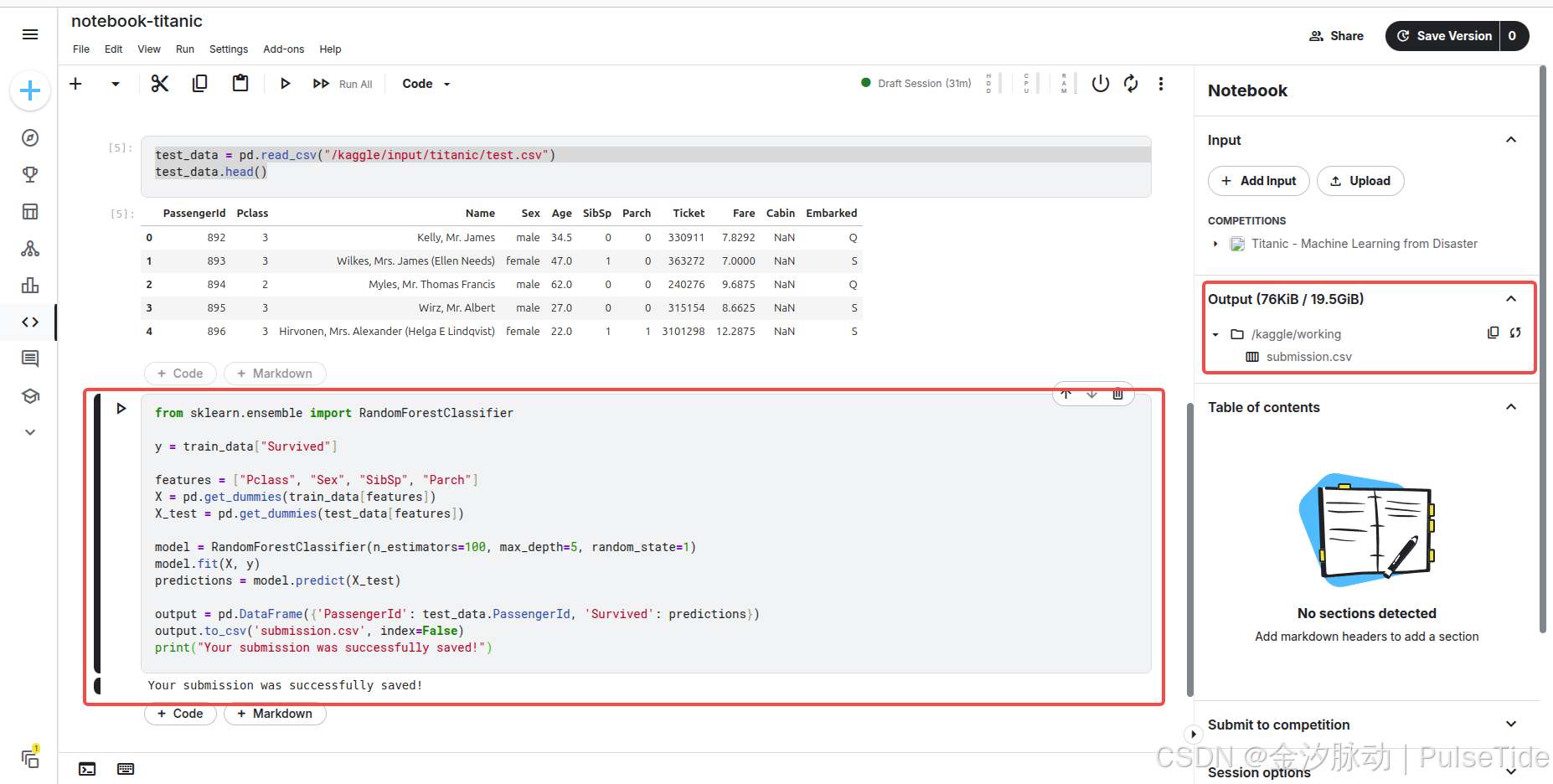
执行代码,在 Output 路径下生成了预测结果文件 submission.csv。
5、提交结果
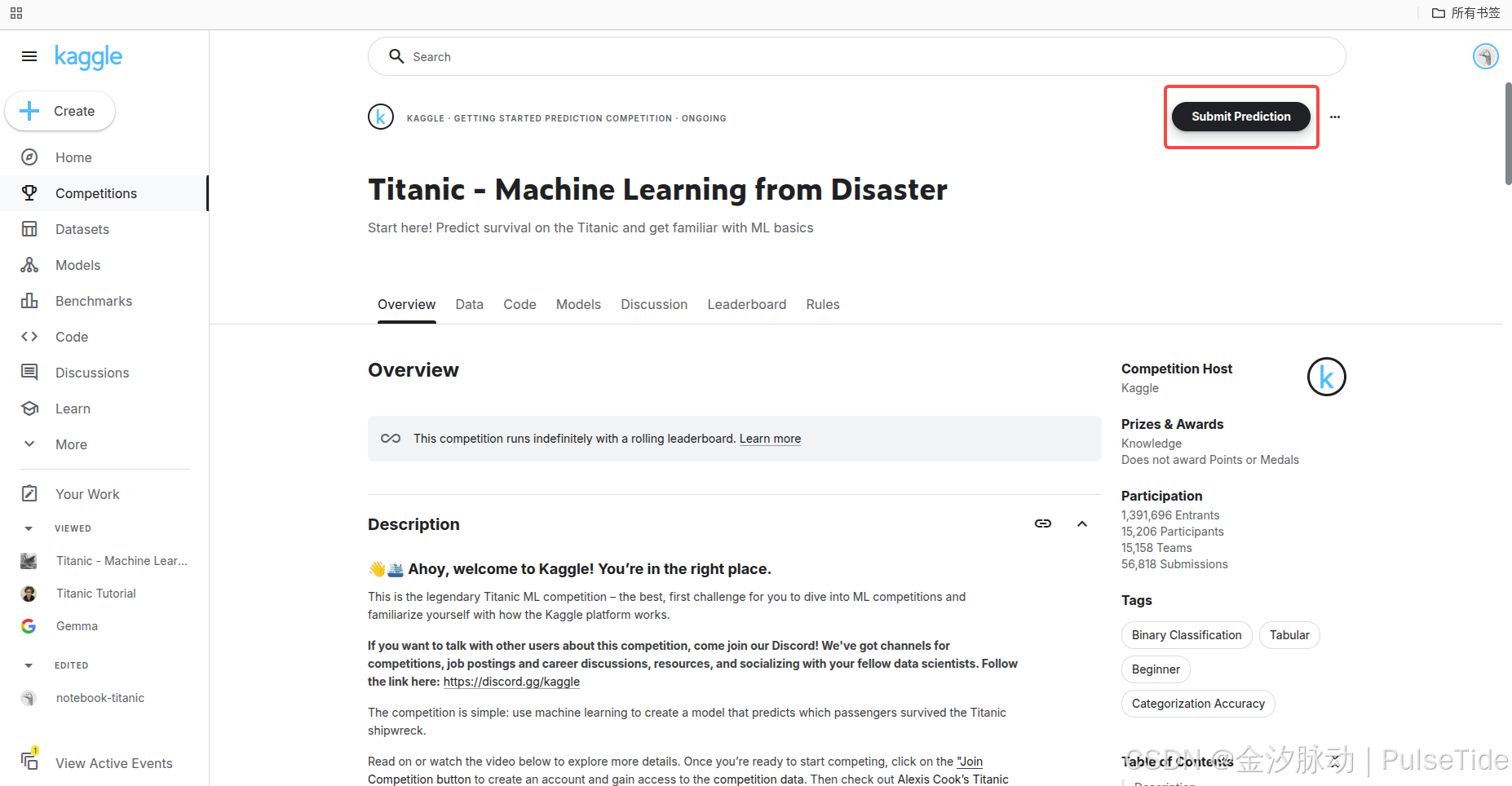
可以提交本地 csv 文件:
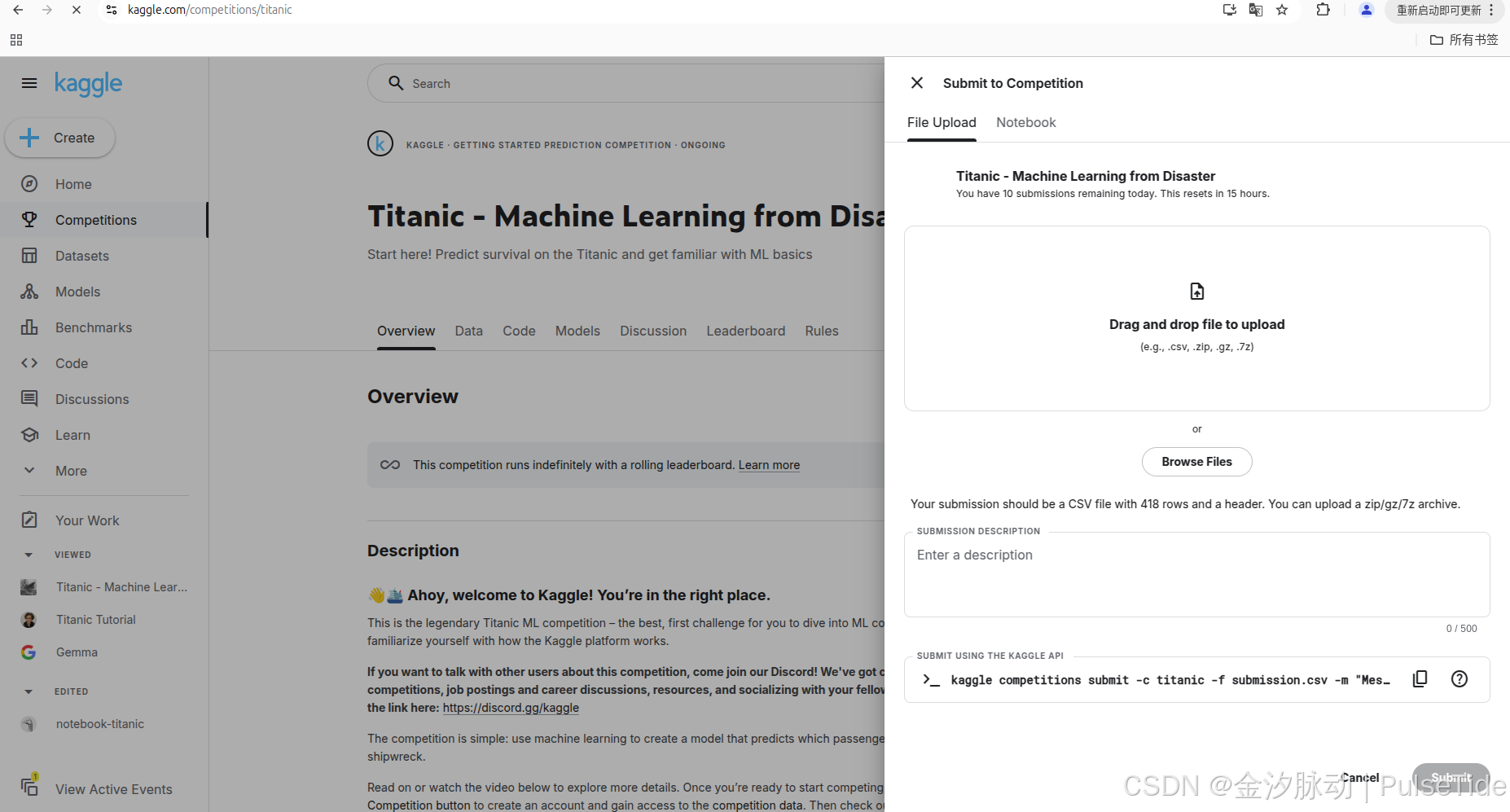
也可以在刚刚的 notebook 中直接提交 :
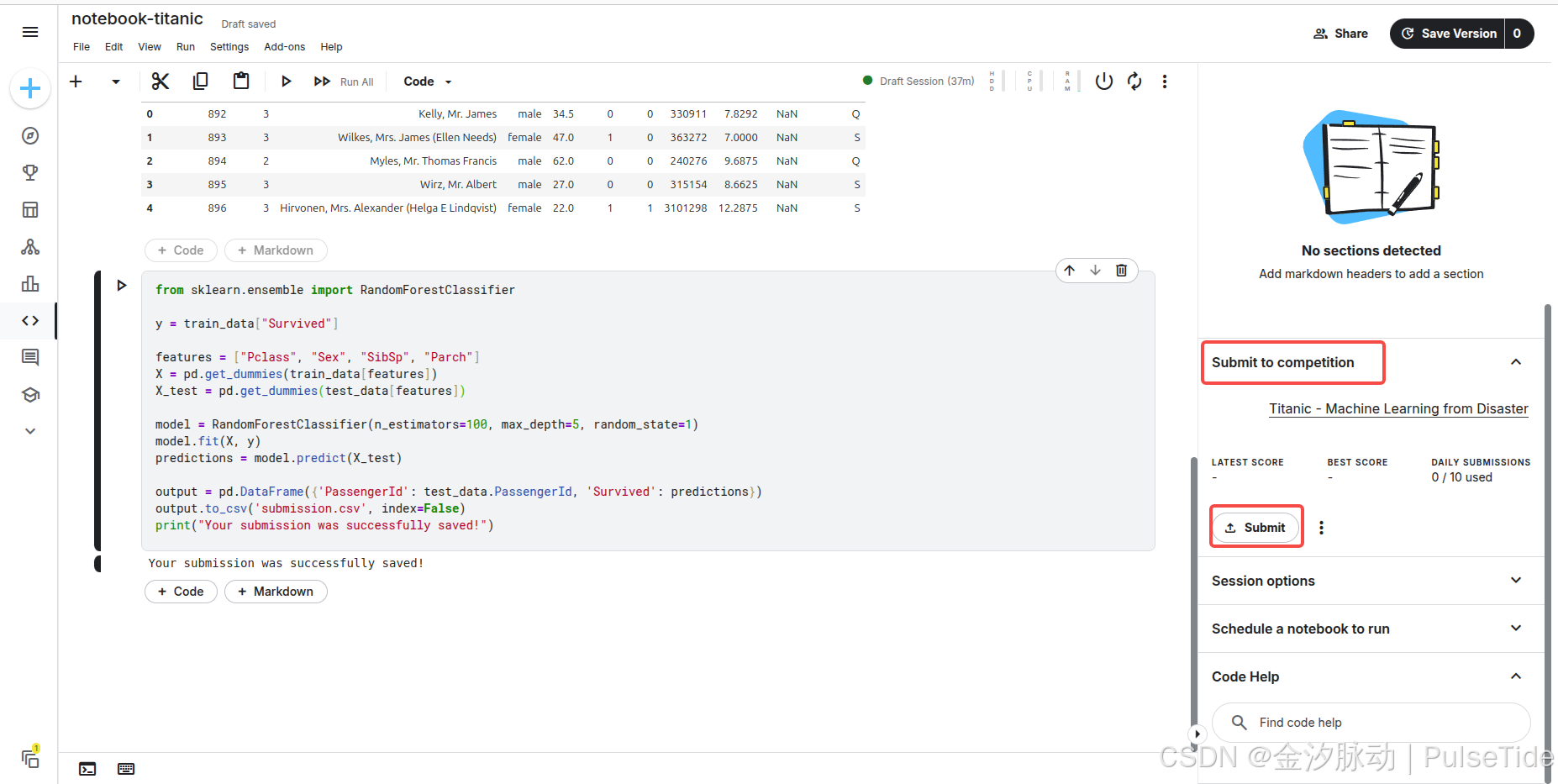
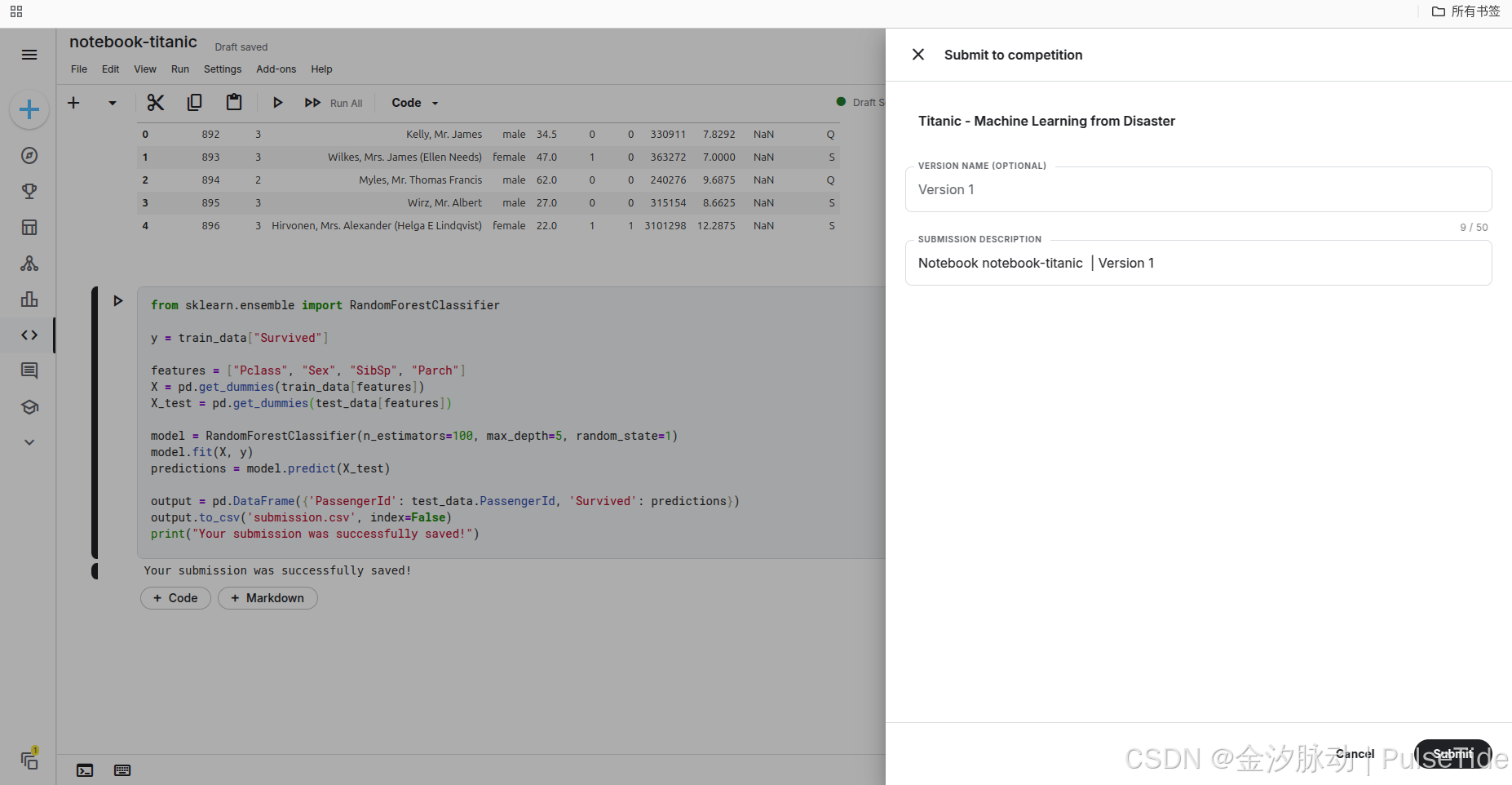
6、排行榜
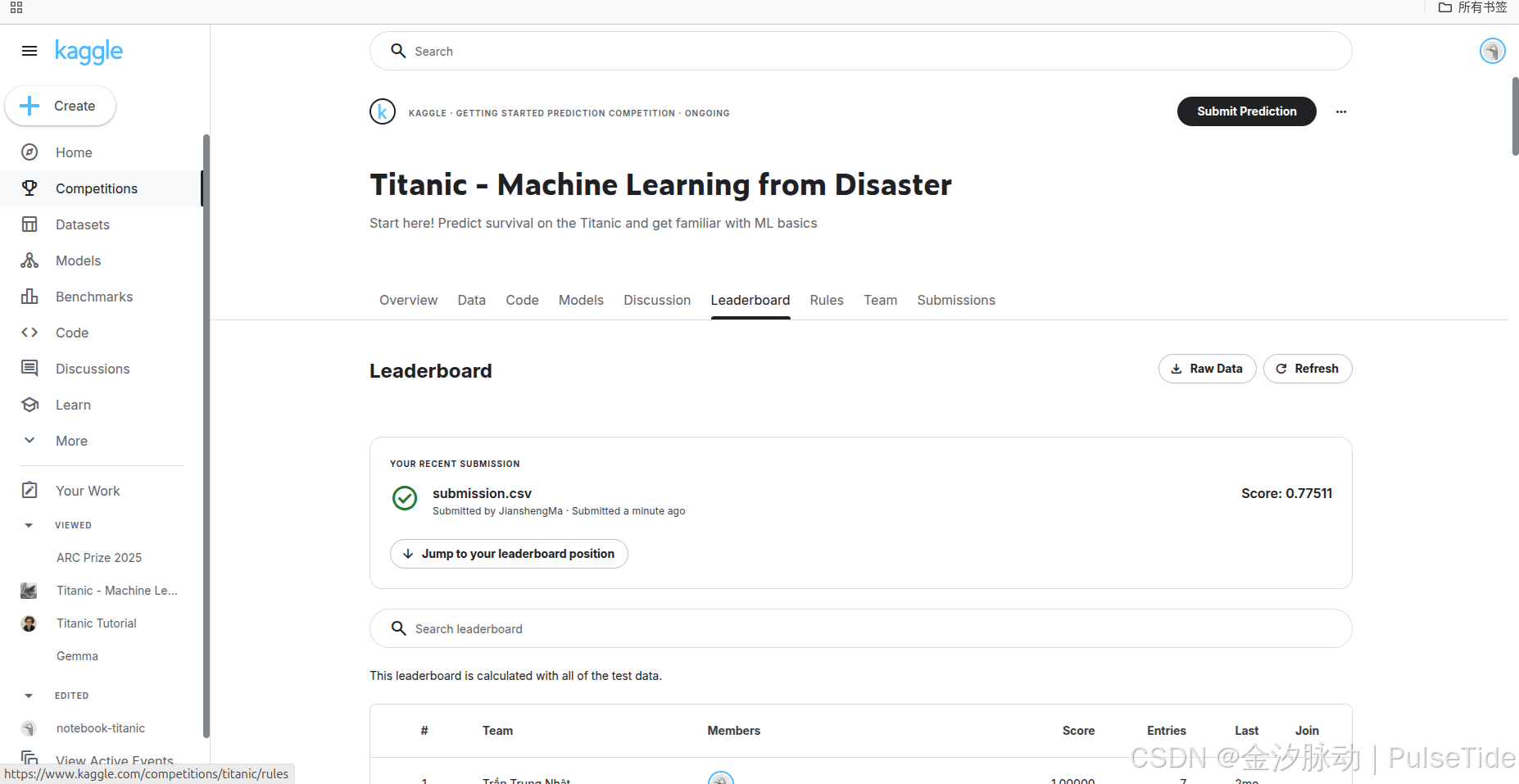
提交结果后,可以在 Leaderboard 页面查看得分与排行:

7、上分打榜
接下来就是使用各种方法不断打磨模型提升预测准确度,注意赛事每天都有提交限制,需要充分利用每一次机会。
8、随机森林算法
核心概念
随机森林是一种基于Bagging集成学习的分类算法,通过组合多棵独立训练的决策树提升模型精度与鲁棒性。其核心思想是:
- 双重随机性:
- 数据随机抽样(Bootstrap):每棵树训练时从原始数据集中有放回抽取样本子集。
- 特征随机选择:每棵树分裂节点时,仅从随机子集(如√n个特征)中选取最优分裂特征。
- 集成预测:最终分类结果由所有决策树投票决定(多数表决)。
工作原理
- 构建多棵决策树:
- 通过自助采样生成
n_estimators个样本子集,每个子集训练一棵决策树。 - 决策树完全生长(不剪枝),依赖随机特征选择降低过拟合风险。
- 通过自助采样生成
- 分类过程:
- 输入样本通过每棵决策树独立预测类别。
- 森林输出得票最高的类别作为最终结果。
主要优势
- 抗过拟合:双重随机性降低模型方差,提升泛化能力。
- 处理复杂数据:
- 支持高维特征,无需手动特征选择。
- 对缺失值、异常值不敏感。
- 辅助分析:可评估特征重要性(基于分裂时的信息增益)。
- 并行化训练:各决策树独立构建,适合分布式计算。
局限性
- 计算开销大:树的数量(
n_estimators)增加会显著延长训练时间。 - 模型解释性差:黑盒性质强,单棵树可解释但整体集成逻辑复杂。
- 空间占用高:需存储多棵树结构,内存消耗较大。
典型应用场景
- 医疗诊断:预测疾病风险(如癌症早期筛查)。
- 金融风控:信用评分、欺诈交易检测。
- 电商推荐:用户行为分类与商品个性化推荐。
- 生物信息学:基因分类与蛋白质功能预测。
关键参数说明:
n_estimators:树的数量(默认100,建议50-200)。max_depth:单棵树最大深度(控制复杂度)。max_features:随机选择特征数(如"sqrt"表示√n)。oob_score=True:启用袋外样本评估模型精度。
总结
随机森林分类器以其高准确性、鲁棒性和易用性成为经典算法,尤其适用于复杂分类任务。尽管计算成本较高且可解释性弱,其在工业界和学术界的广泛应用验证了其有效性。
五、GPU/TPG 额度
GPU的并行架构(数千核心)可加速神经网络的海量矩阵运算,显著缩短训练周期(如ResNet、BERT等大型模型);针对已训练模型(如Transformer),TPU的定制化张量计算单元可实现超高吞吐量响应,成本低于GPU。
Kaggle 提供的 GPU/TPG 额度如下:
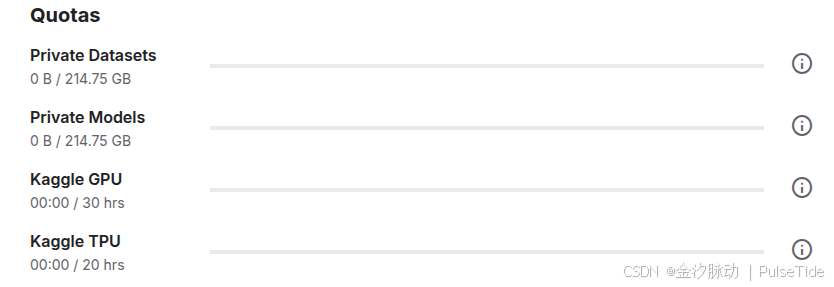
- GPU免费额度:每周30小时
- TPU免费额度:每周20小时
六、不止竞赛
Kaggle 上还有很多竞赛时需要用到的基础知识课程,我们可以从这些课程中快速学会相关技能。