gpu 优化
最近一直在做gpu的优化项目,我用一个简单的例子过一下gpu优化的一些套路和方向。
256QAM GPU优化
256QAM 是5G通信领域的一个重要模块。发送端的时候,8bit 的源数据会映射到星座图上的一个点,正好星座图有2^8=256个点。每个点在星座图上对应一个I/Q 复数坐标。N bit的比特流(b0b1b2b3b4b5b6b7b8b9b10b11b12b13b14b15…..) 映射到N/8的复数序列(c0c1…).
接收端,接收N/8的复数序列(c0c1…),要把它解码到长度N 的uint8_t 的soft bit的序列。Soft bit代表是该bit判断为1或者0的概率。一个复数会被解码到8个soft bit.
因为复数序列每个元素之间是相互独立的,那么gpu并行就成了一个非常好的加速手段。
以下是接收端的256qam从复数到soft bit的转换公式,显而易见的是有很多的分支, anyway, 让我们看看如何一步一步去优化它。

- 线程块在SM内的并行度 (occupancy)
在我测试的GPU 上,Maximum number of threads per multiprocessor: 1536(48 warps)。Maximum number of threads per block: 1024。一般初学者喜欢把num of thread per block 设置成最大1024, 让一个block可以做最多的活。但是,这样设置呢,并不能充分利用SM的计算能力,因为它可以同时支持1536线程。因此,我们可以设定num of thread per block为512, 256, 128这种可以被1536整除的数。比如说,设置为512, 那么3个块可以同时在一个SM里面运行,同一时间可以做1536个元素。当然,并行度受SM硬件资源(寄存器和share memory)影响。

2. 访存合并
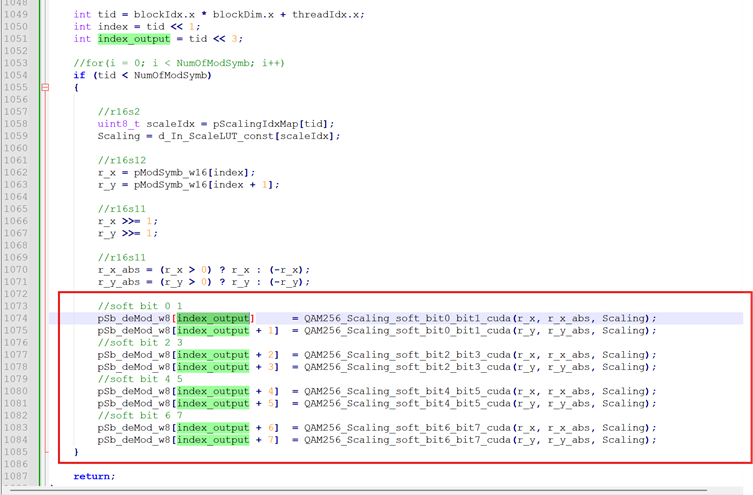
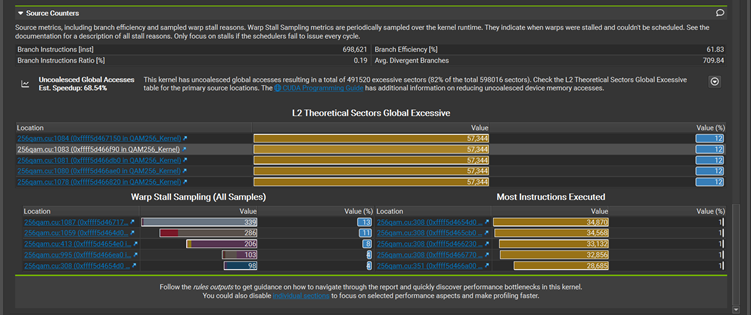
让我们来看一下下面的store操作有没有合并。
Nsight compute:
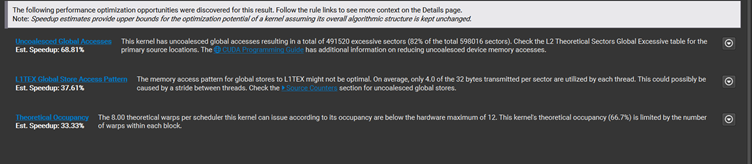
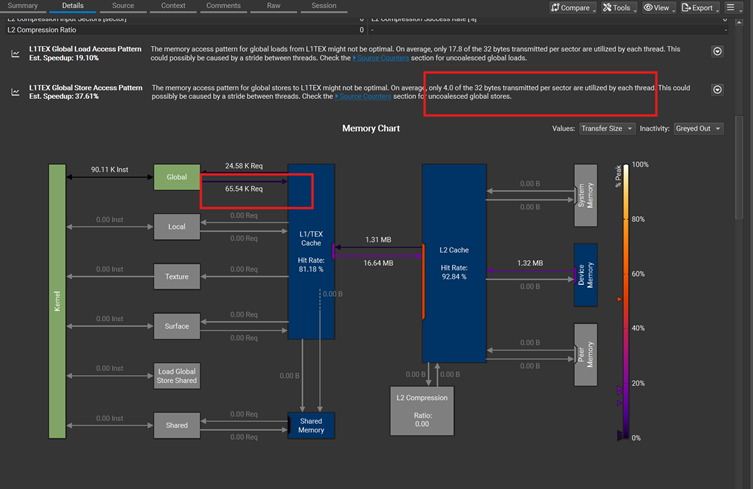
Store的次数是65.54K,合并的效果是每个线程里面4.0 bytes of 32 bytes sector 被合并了。
走进汇编:
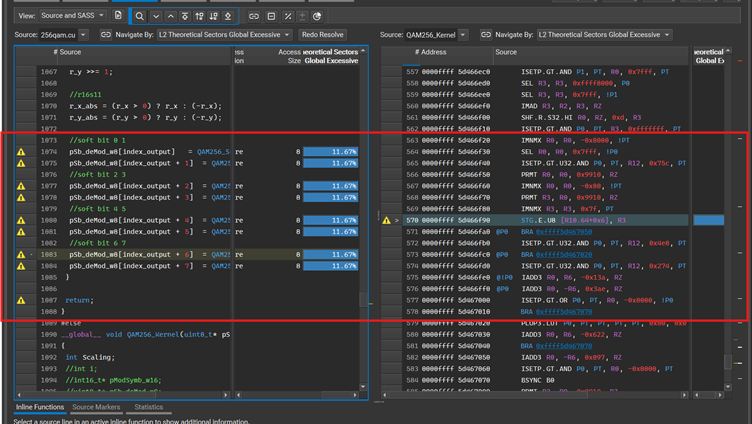
发现就是store 的操作导致访存利用率低。修改到下面的代码,用临时变量去存储每个soft bit的结果

如果用A的方法,依旧是每byte 赋值,store的次数和合并的效果差不多
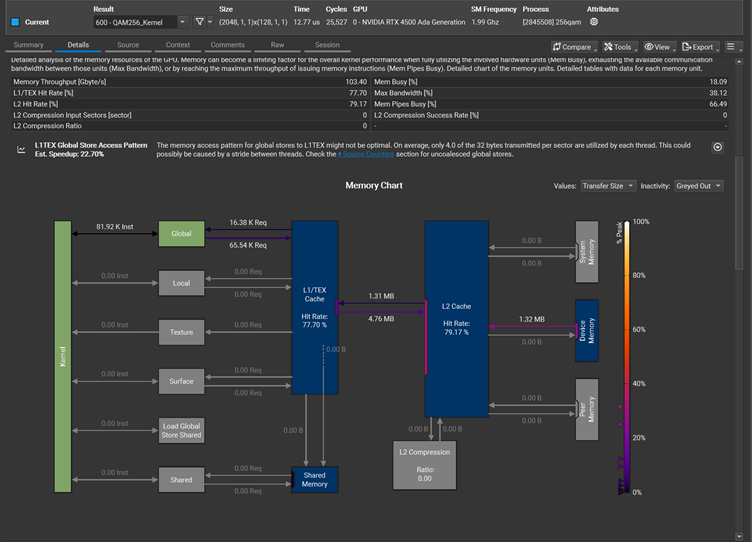
如果用B的方法,把byte 先合并到一个64bit上面,再一次性写64bit. 效果直接立杆见影。Store的次数降到了1/8,从65.54K 到8.19K
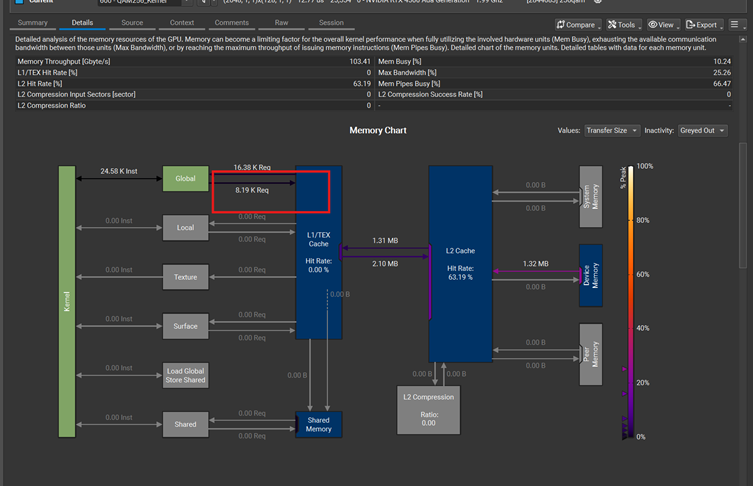
接着我们再看load操作,从global memory load 复数的I/Q数据。
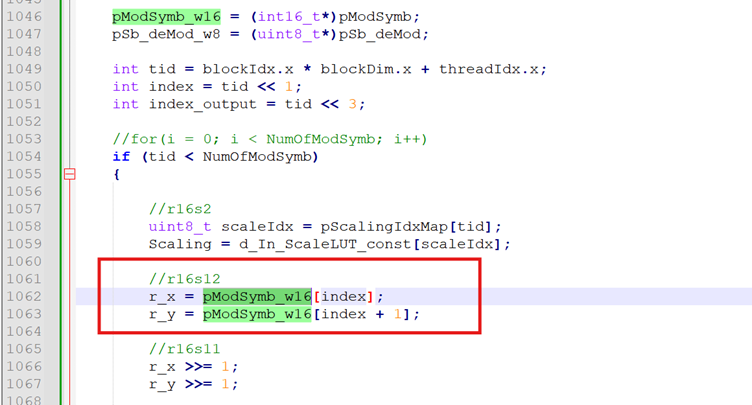
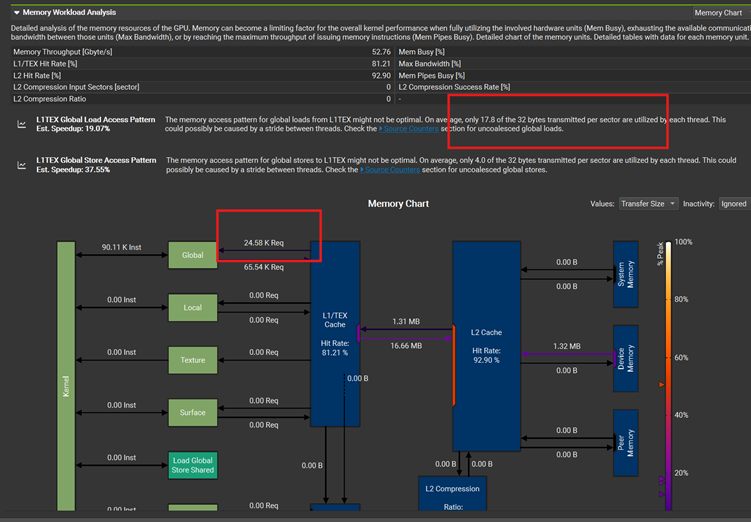
24.58K的load操作,和17.8 bytes of 32 bytes sector 被合并了。修改到下面的代码:
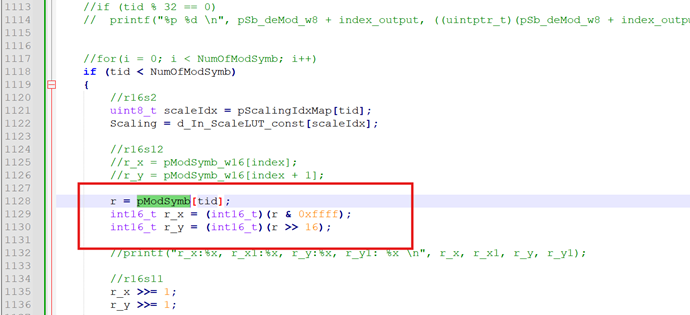
每个线程从3次load操作,变成2次,降了1/3, 从24.58K 降到16.38K
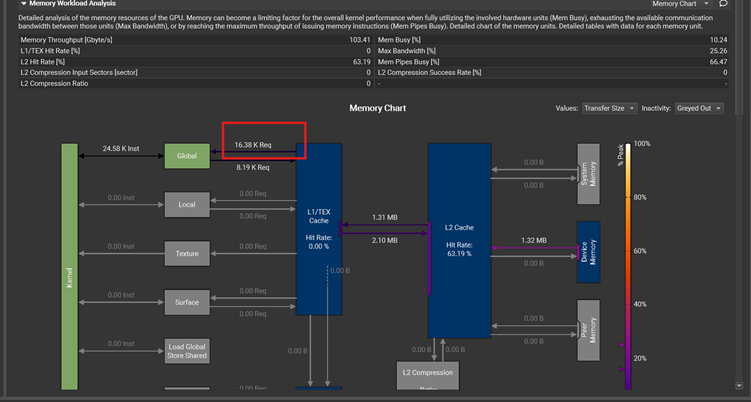
把这些内存访存操作改动之后,发现kernel执行的时间少了40%。
3. 减小分支
初始代码如下,有很多if else

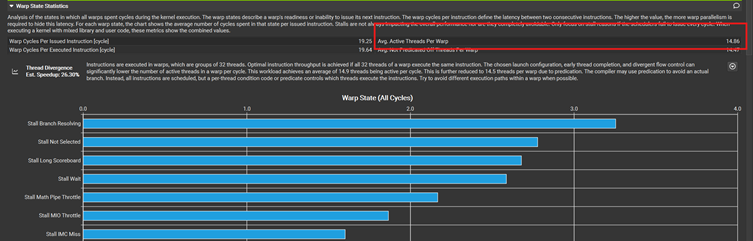
查看Nsight Compute, 每个warp里面只有14.86个线程活跃,其他都等待。
使用LUT, 把每个判断条件里面执行的动作全部统一化, 然后更改到如下的代码,

查看Nsight compute, warp里面的32个线程全部Active。

把这些分支拿掉之后,发现kernel执行的时间仅仅少了5%。可能为了去掉分支,增加了很多运算量吧。还有一种可能是warp里面的线程大部分情况下很幸运的进入到同一分支, 可以添加counter验证,就不再试验了。另外有些资料说,gpu capabilities越来越强,对于divergence的处理越来越好。
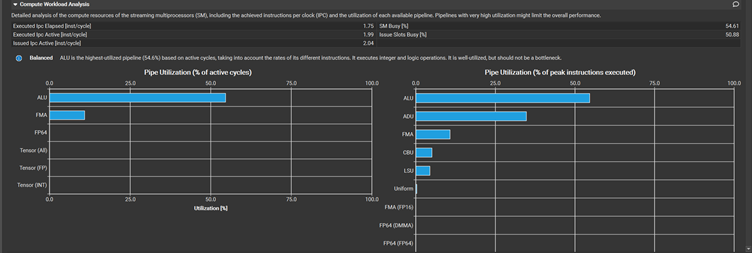
有分支:
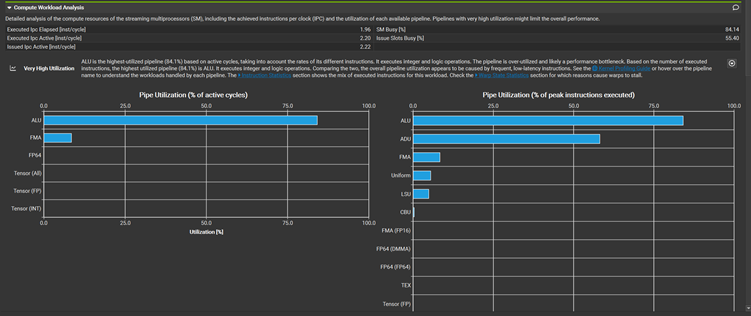
无分支:
4. 如何利用stream 进行pipeline
基本上稍微新一点的gpu都是独立的双向copy (D2H 和H2D)。查看配置Concurrent copy and kernel execution: Yes with 2 copy engine(s)
我们把数据分成4个stream, 看看会不会有并发的操作可以帮助减少时间。
有两种stream的方法:
第一是parallel, 就是相同的操作并行放在一起
Nsight 里面确实看到了Kernel执行和memcpy H2D有重叠。
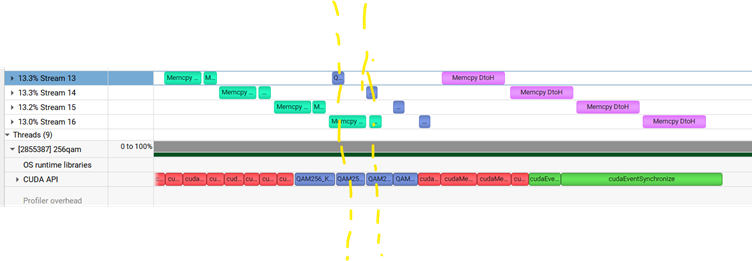
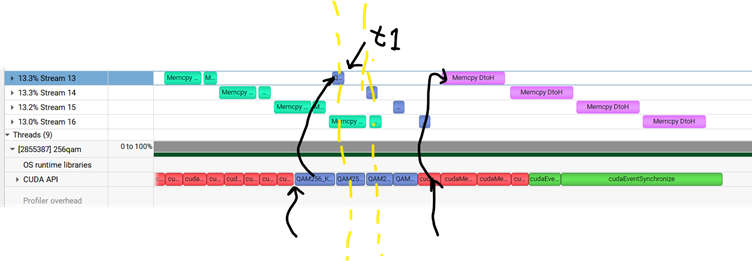
因为这个例子是数据传输占据最大的时间,所以我想要看到H2D和D2H的重叠,但是没看到。为什么呢?因为host launch CUDA API 也需要花时间,而且在这个例子中,launch API 的时间不短,比kernel执行的时间长。考虑第一个stream, 本来launch kernel应该紧跟H2D copy, 但是图中它要等所有的stream 的H2D copy launch后,才launch 256qam kernel。 同样,256qam 做完之后的t1时刻,应该发动D2H的memory copy. 但是stream 0的D2H CUDA API 还没到,这时候要等改API被launch 才会触发D2H.
第二是sequential, 就是一次性把一个stream 里面的API launch完,再去launch其他的stream.
Nsight system看到的结果太完美了,并行叠加效果太明显了。

这两种结果对比如下(一个是9.9%的提升,一个有31.499%的提升):

其实如果把Num of Elements 变得很大的话,这两种是没啥区别的。
时间原因,我其实还想试一下循环展开,看看能不能有更好的效果。