【n8n】如何跟着AI学习n8n【05】:Merge节点和子流程调用
📚前言
n8n的系统性学习,对各知识点地毯式学习🔍~
前面课程
定制n8n的AI老师,有AI老师制定学习大纲,参考之前的文档(本系列n8n学习大纲,也在这里):
【n8n】如何跟着AI学习n8n_01:定制AI老师-CSDN博客
第二课开始基础知识学习
【n8n】如何跟着AI学习n8n【02】:基础节点学习-CSDN博客
【n8n】如何跟着AI学习n8n【02.5】:第一部分总练习-CSDN博客
【n8n】如何跟着AI学习n8n【03】:HTTPRequest节点、Webhook节点、SMTP节点、mysql节点-CSDN博客
【n8n】如何跟着AI学习n8n【04】:错误处理与日志监控-CSDN博客
👌好了,下面的课程还是基础知识,苍天大厦,都是一砖一瓦堆砌而成,继续搬砖💪
📚课程内容
🧭 Day 13:Merge 节点
✅Merge节点简介
Merge节点用于将多个输入流的数据合并为单个输出流。它支持多种合并模式,适用于需要整合来自不同来源或分支的数据的场景。
合并模式:
- Append - 简单追加(默认)
- Merge By Index - 按索引合并
- Merge By Key - 按指定键合并
- Multiplex - 创建所有可能组合
🧪 实战项目:
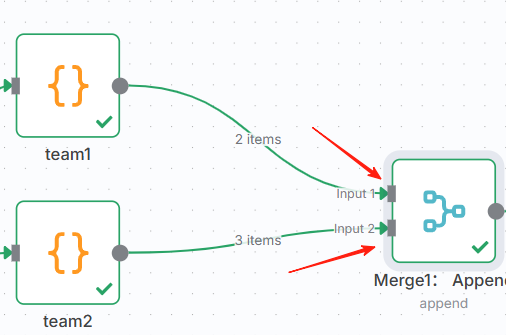
🔧创建流程,如下图
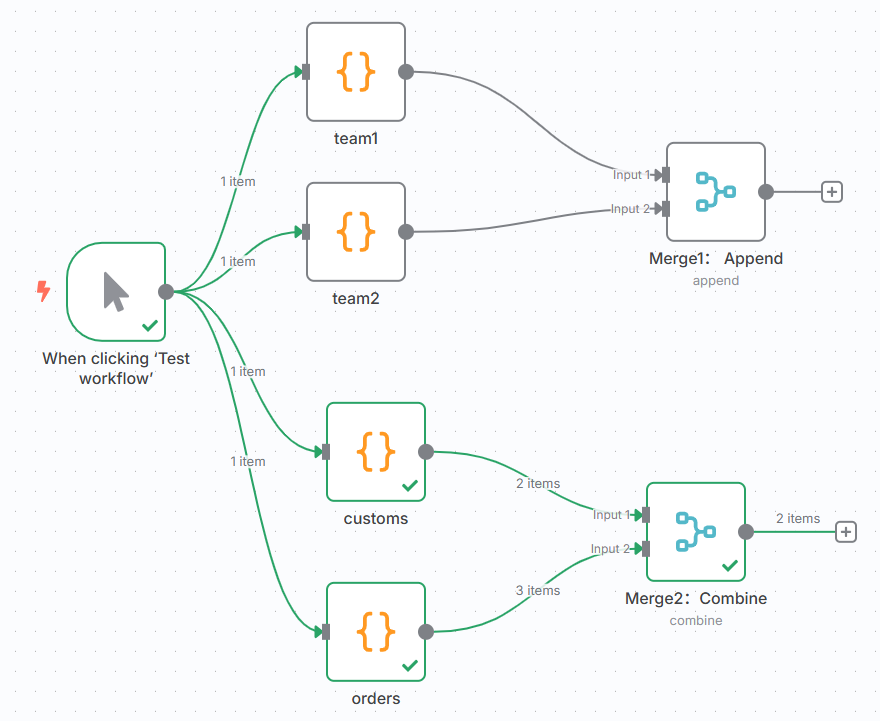
🔧节点Merge1,使用Append模式(简单合并)
team1节点:
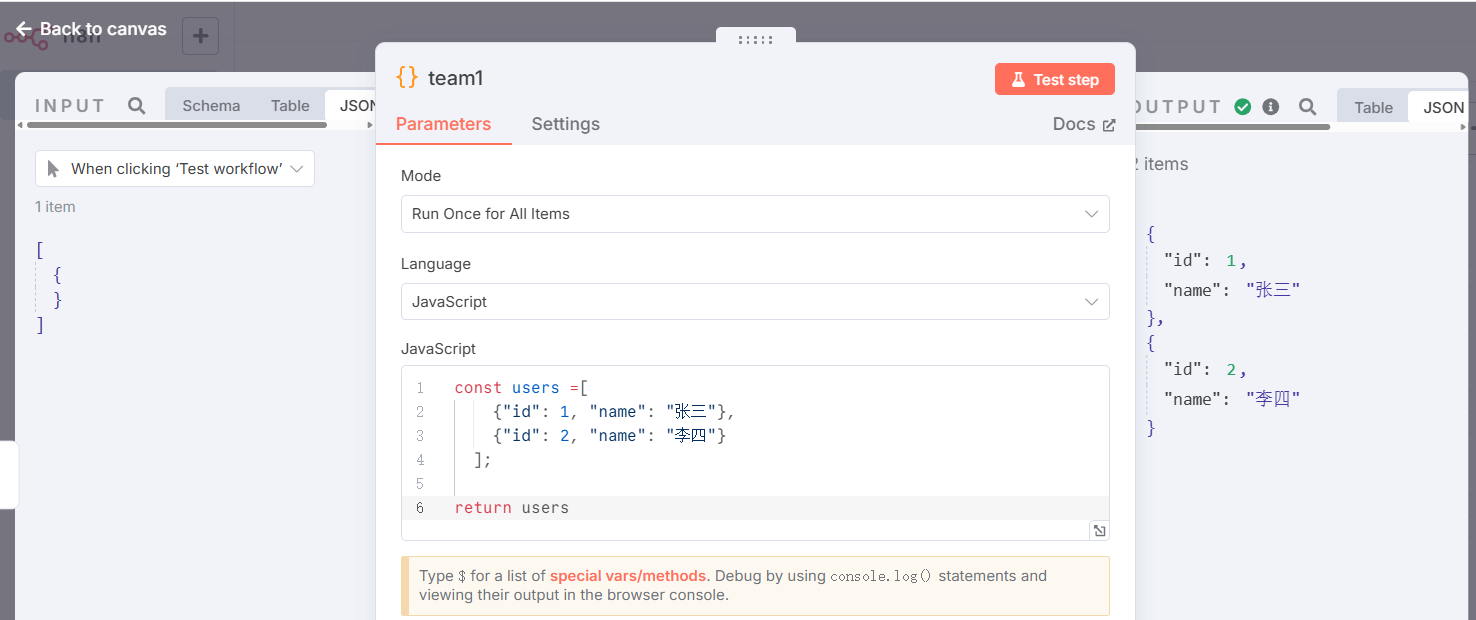
代码:
const users =[{"id": 1, "name": "张三"},{"id": 2, "name": "李四"}];return usersteam2节点:
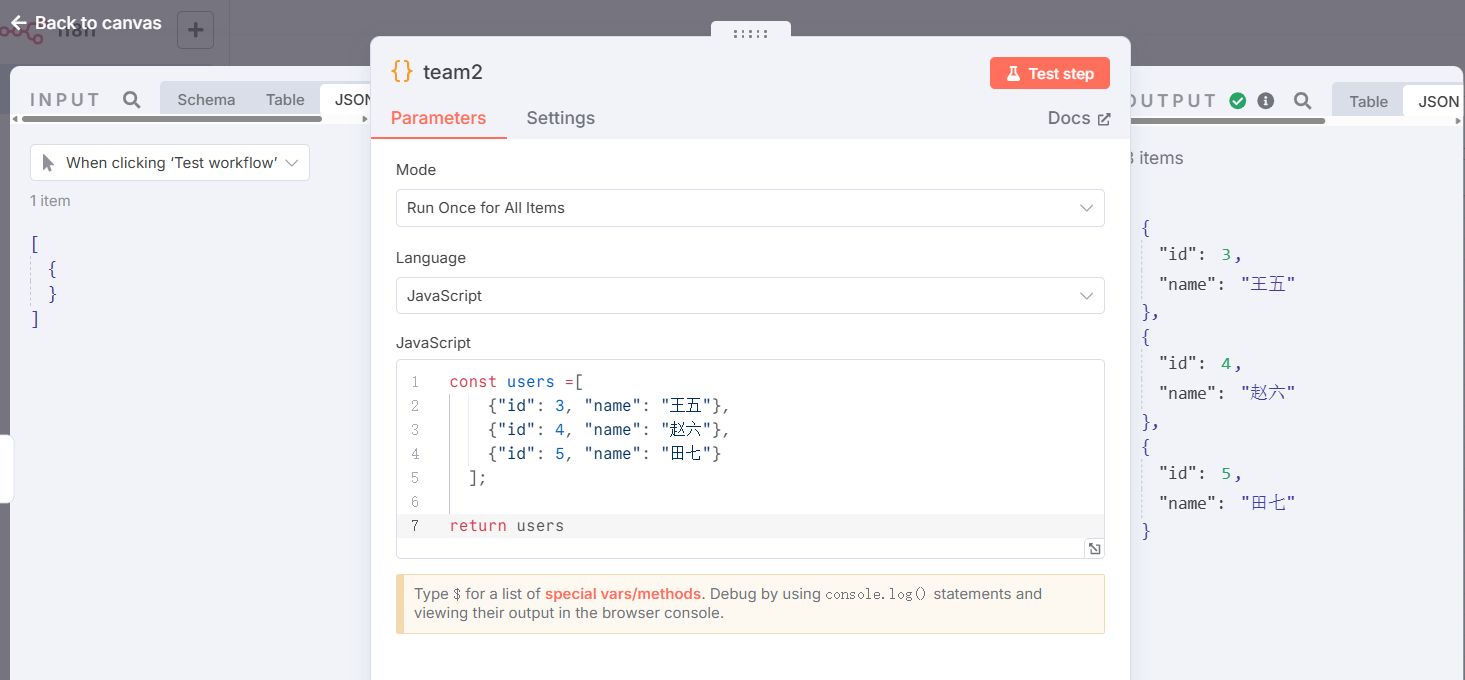
代码:
const users =[{"id": 3, "name": "王五"},{"id": 4, "name": "赵六"},{"id": 5, "name": "田七"}];return usersMerge1节点:
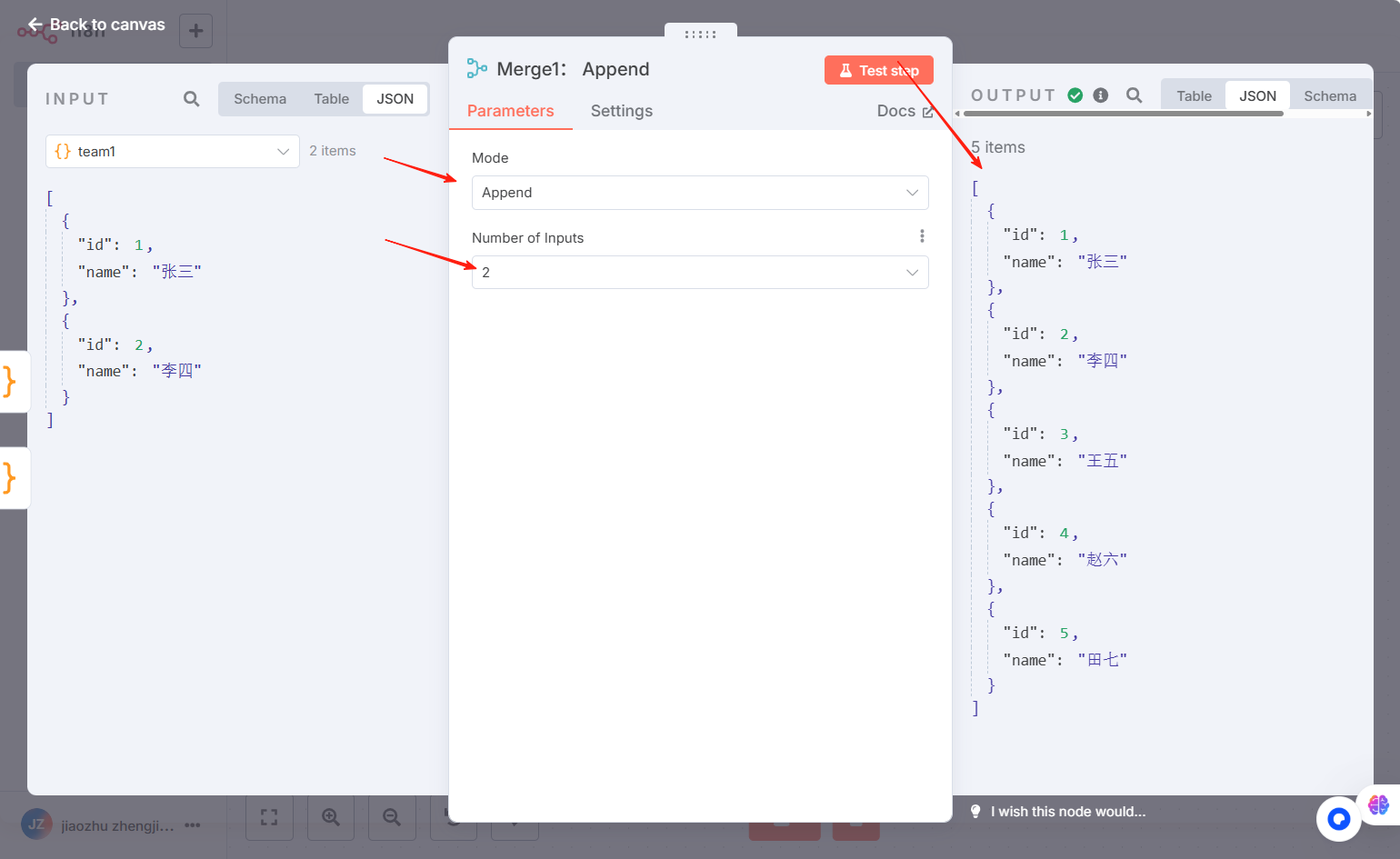
⚠️ 注意,Merge节点设置,输入数量即汇入分支有几个,每个分支要连入不同的输入口,如果连在一个input上面,无法合并数据:
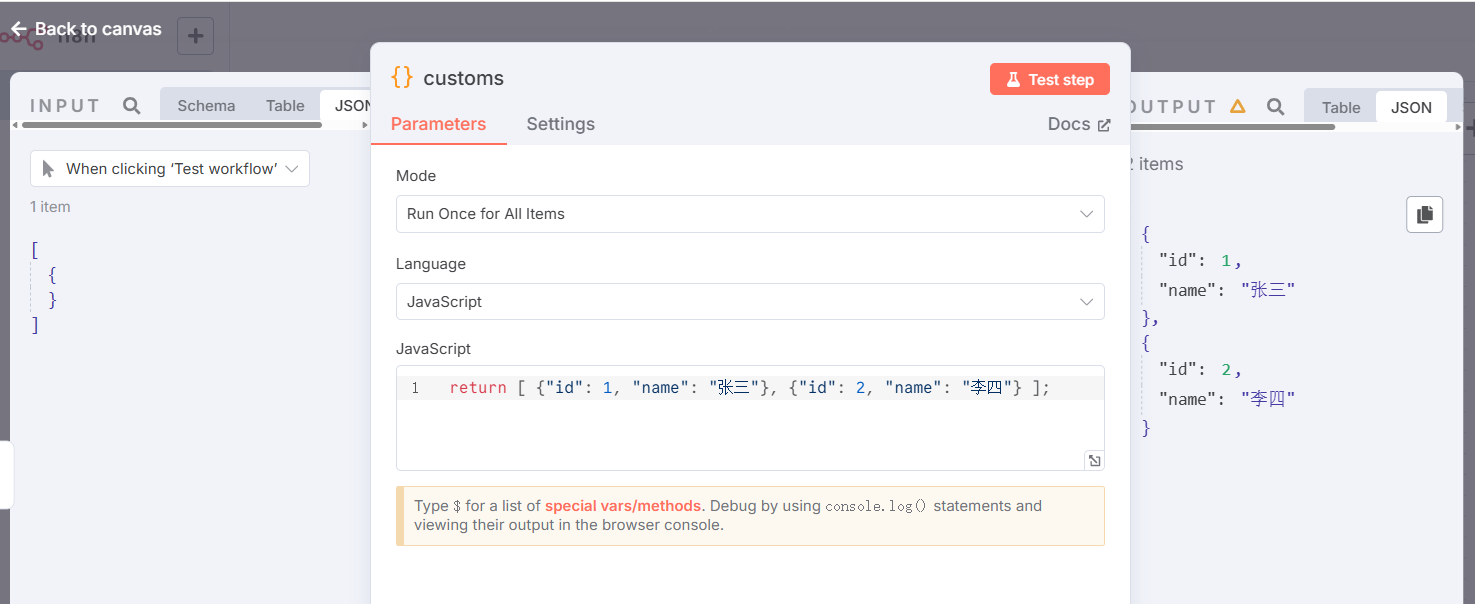
🔧节点Merge2组合方式
customers节点设置,模拟客户列表:
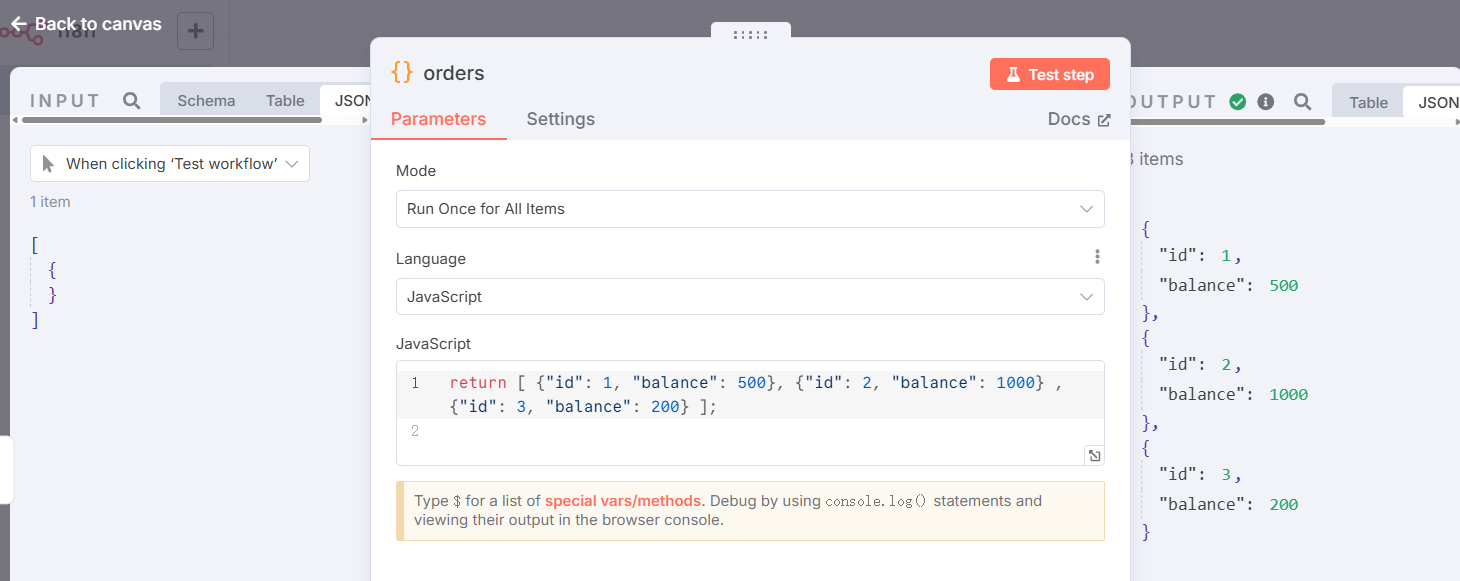
order是节点设置,模拟客户订单数:
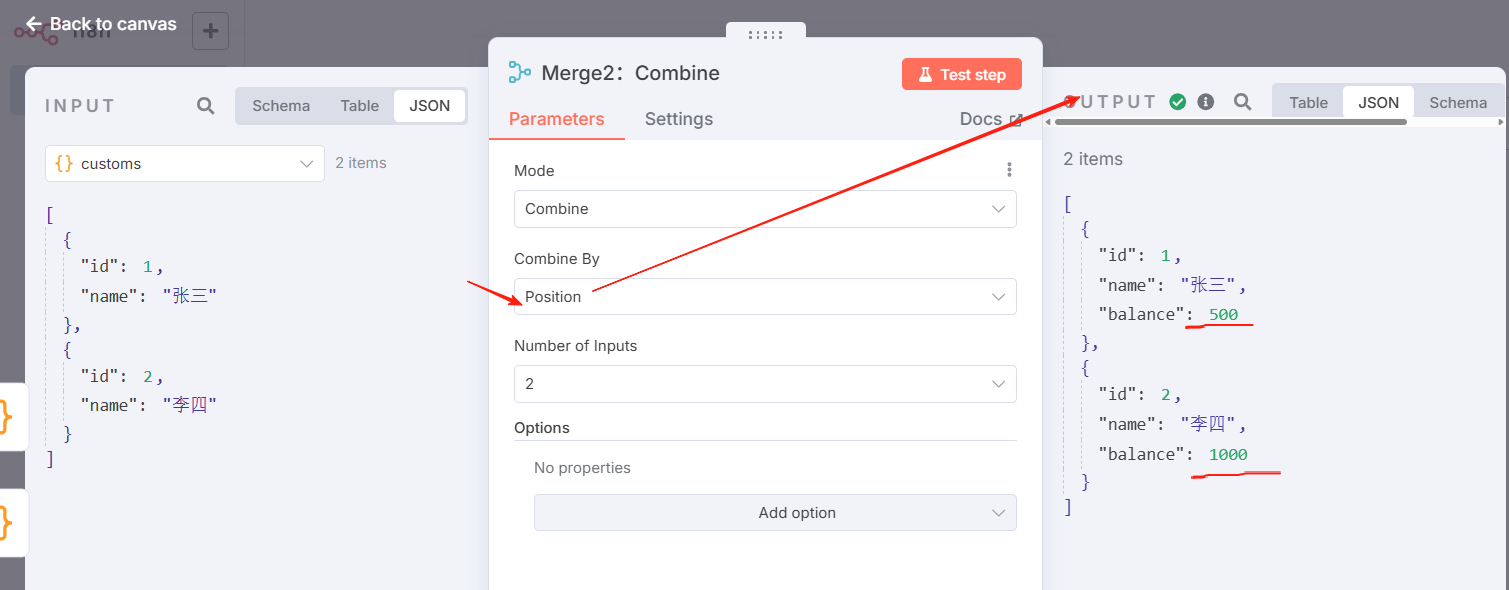
Merge2:按位置组合,效果示意
Merge2:按字段组合-匹配,效果示意
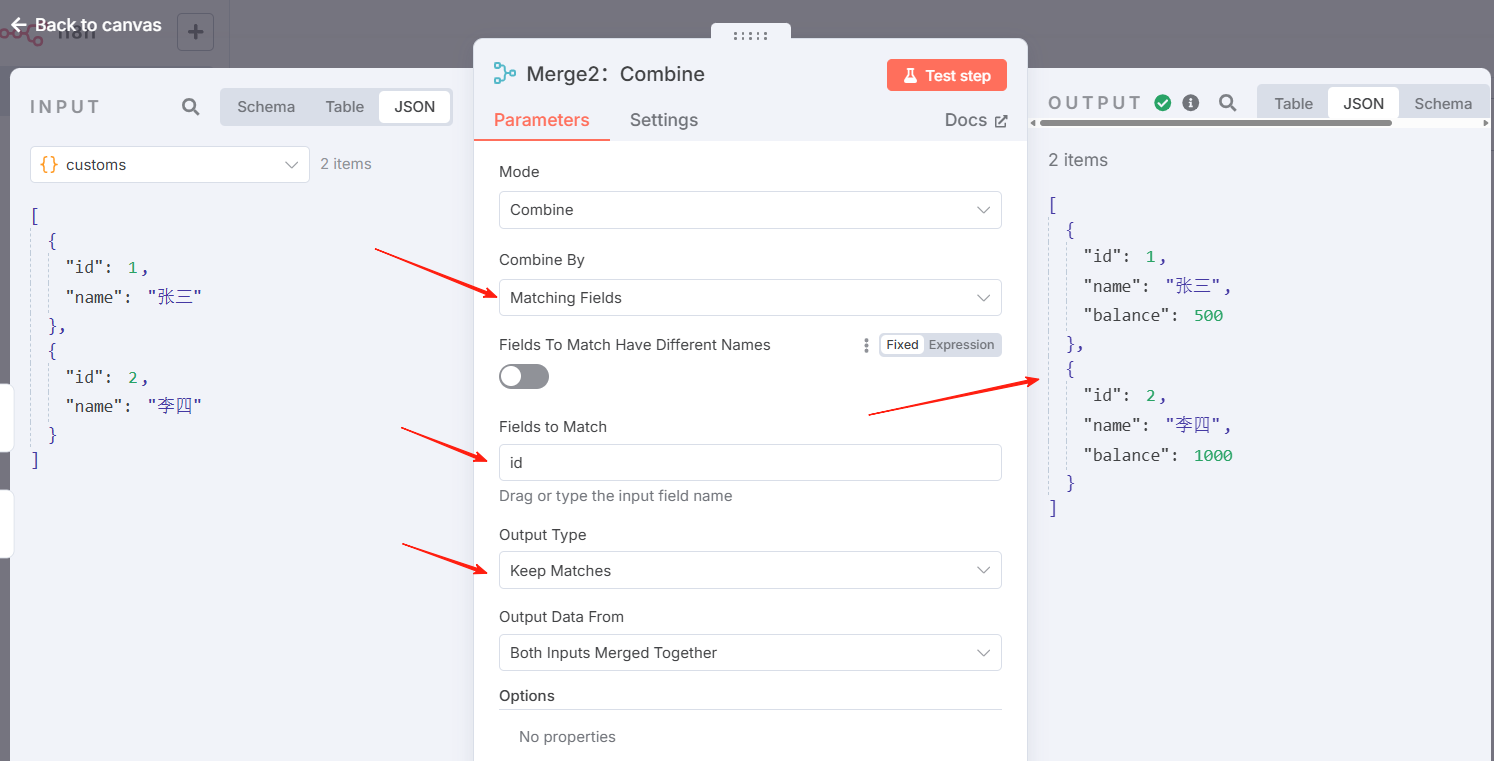
Merge2:按字段组合-未匹配,效果示意
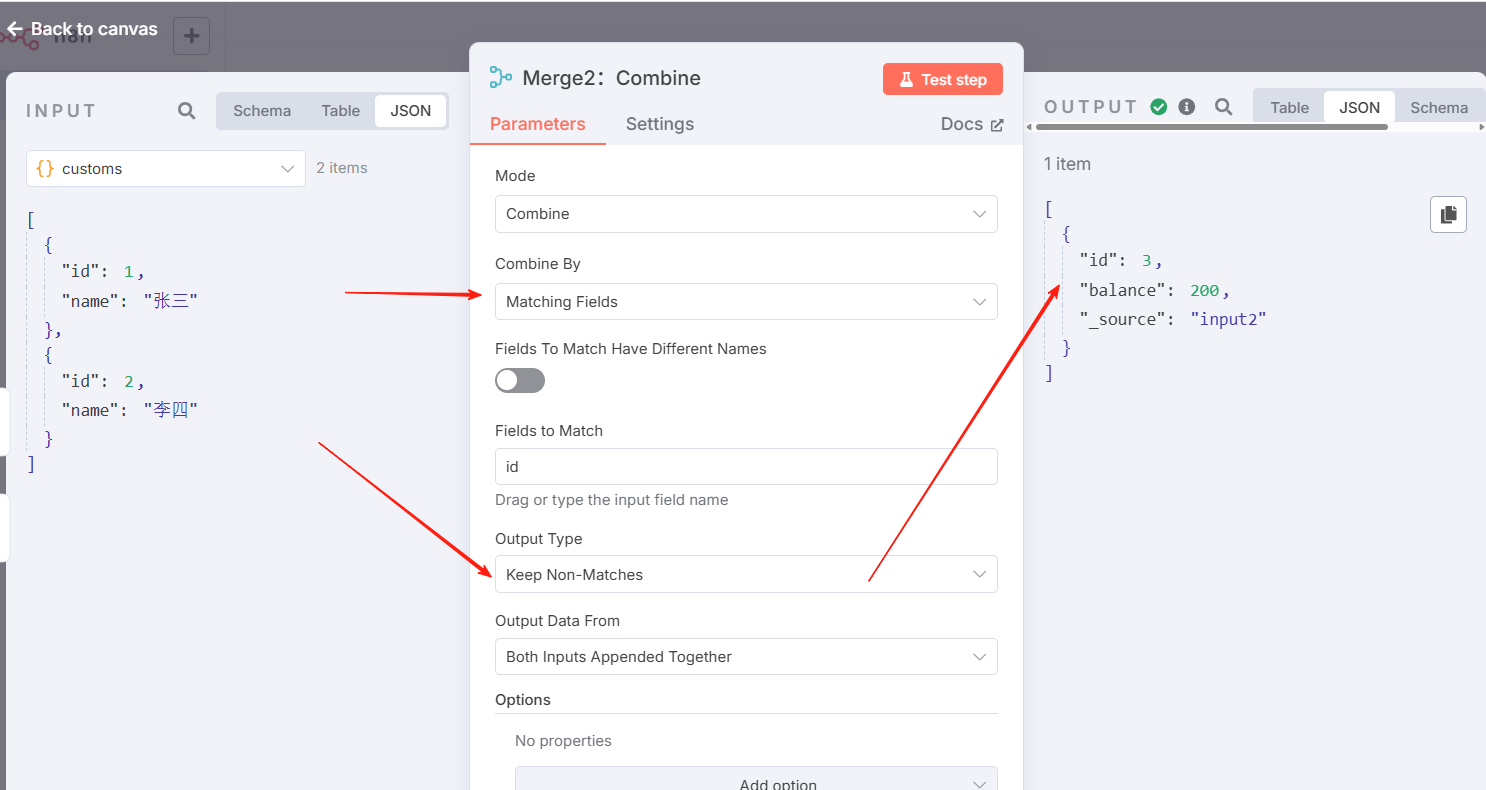
Merge2:按字段组合-输出所有,效果示意
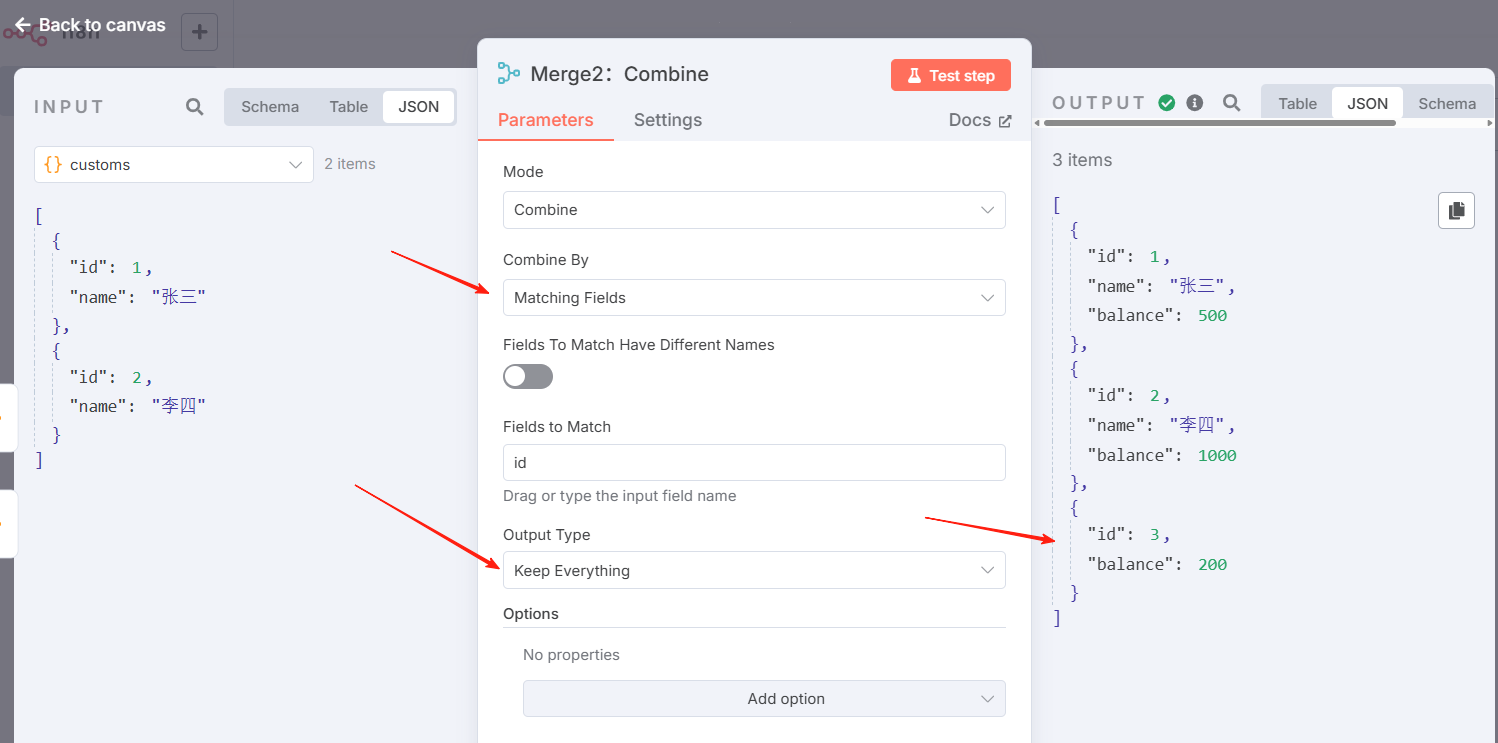
Merge2:按字段组合-以input1为主,效果示意
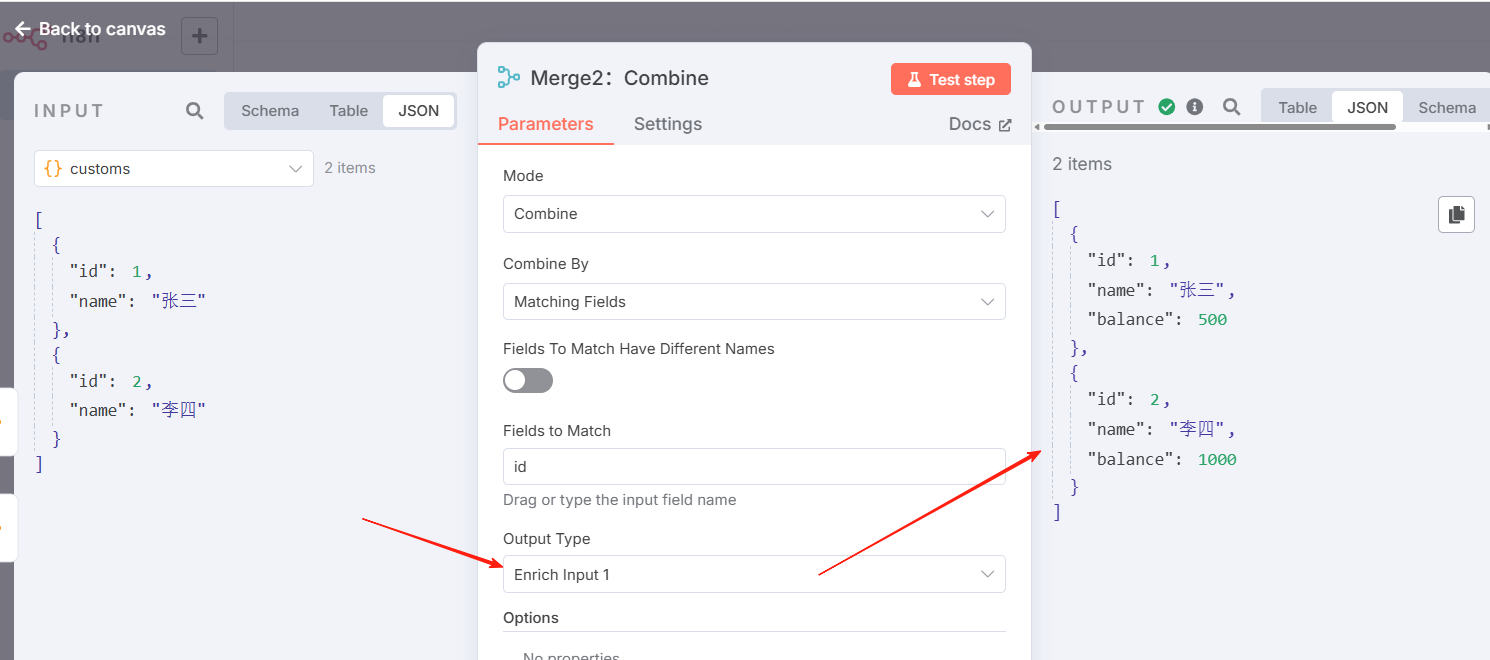
Merge2:按字段组合-以input2为主,效果示意
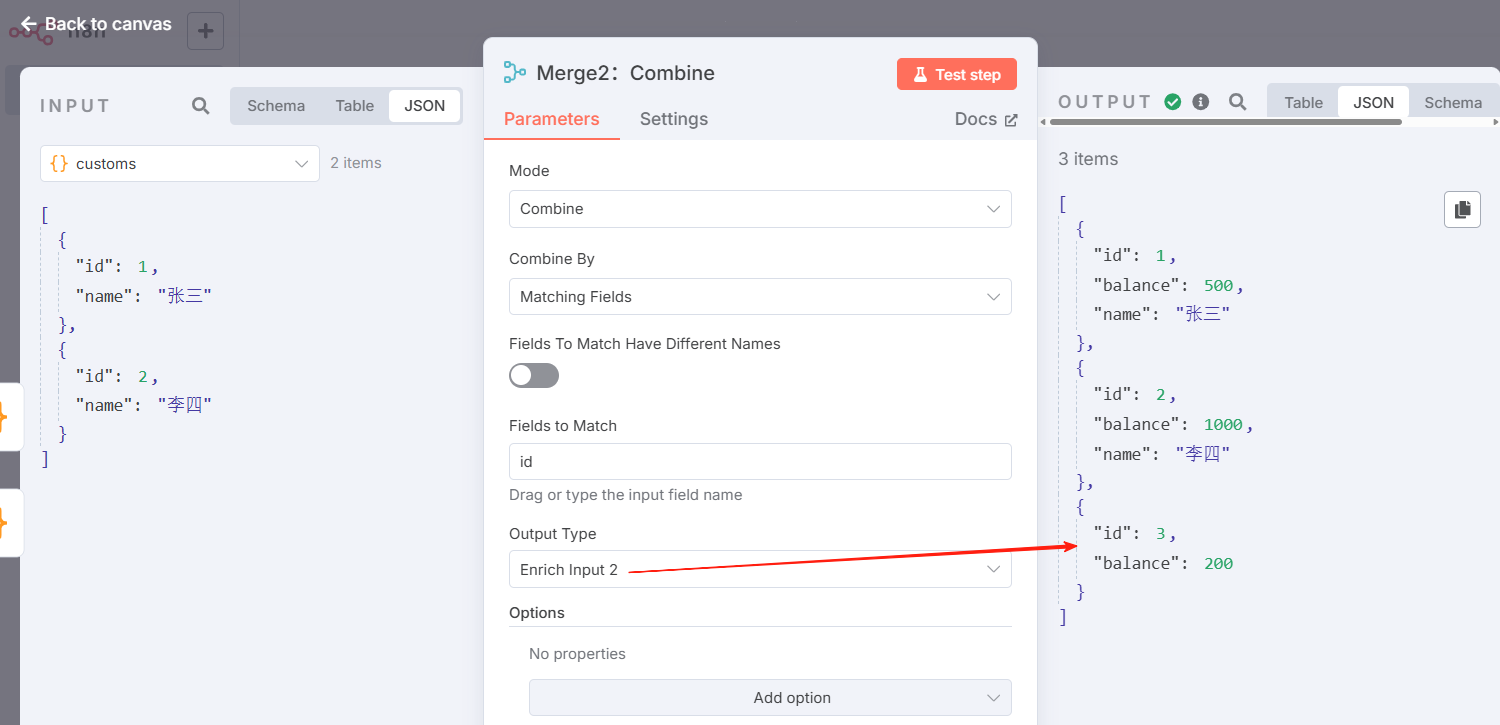
Merge2:组合-所有位置交叉,效果示意 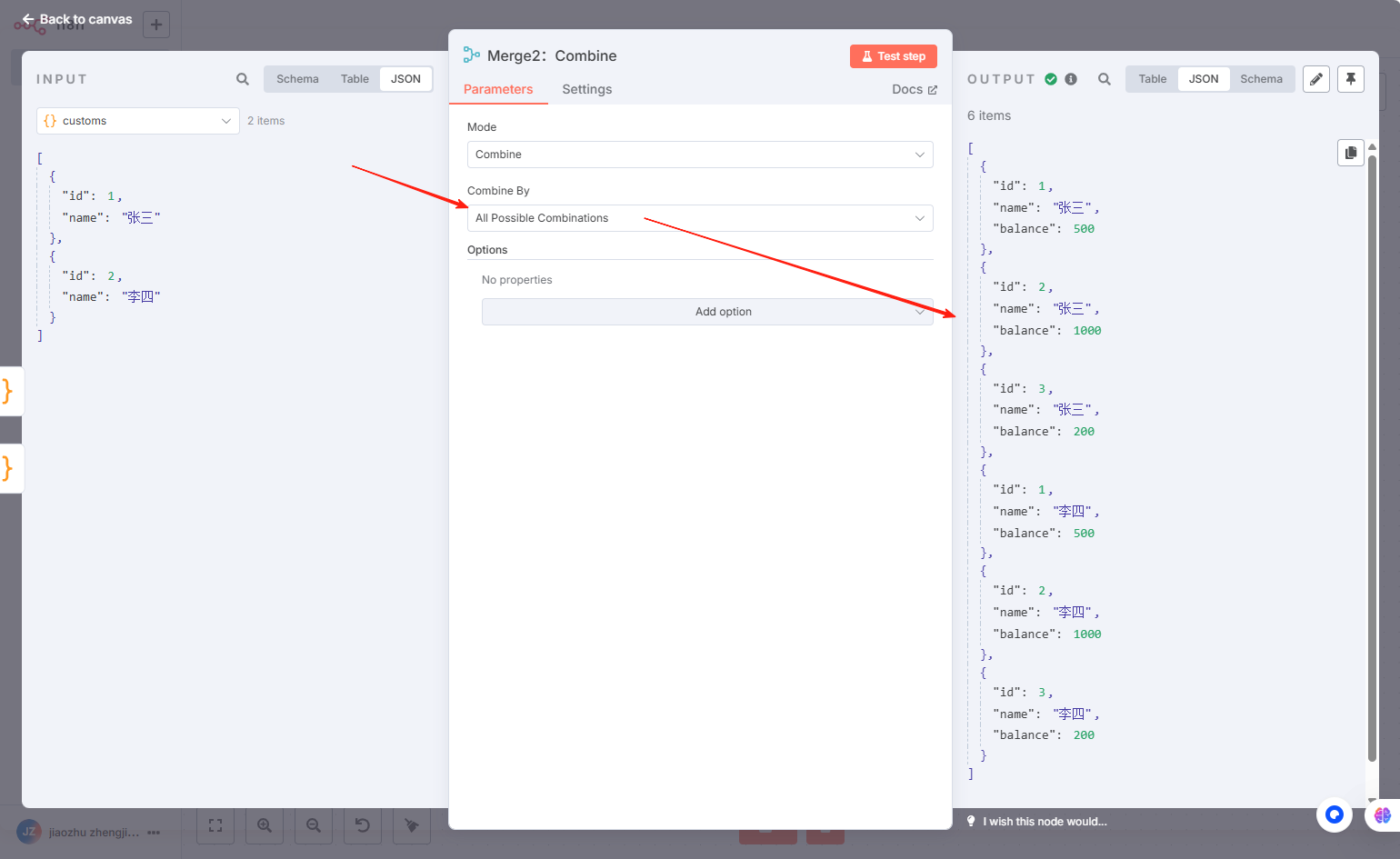
🧭 Day 14:Execute Sub-Workflow(调用子流程)
✅Execute Sub-Workflow节点简介
Execute Sub-Workflow 节点是 n8n 中一个非常强大的节点,它可以让你在一个工作流中调用另一个工作流,从而实现模块化、复用和更清晰的流程管理。
这个节点非常适合以下场景:
- 将复杂流程拆分为多个小流程(模块化)
- 重用通用流程逻辑(如发送通知、处理数据、调用API等)
- 构建可维护和可测试的自动化系统
🧪 实战项目:
实战场景,我们有两个工作流:
- 主流程(Main Workflow):接收用户输入,调用子流程处理数据
- 子流程(Sub Workflow):将用户信息写入 Mysql
🔧创建子流程(Sub Workflow)
- 新建一个工作流,命名为
练习7:subflow - 添加以下节点:
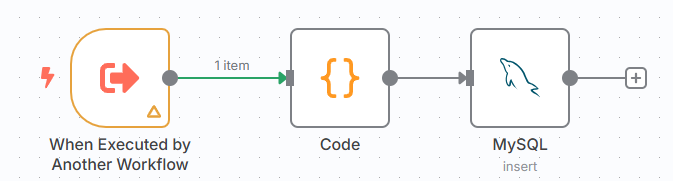
When Executed by Another Workflow(被其他流程调用节点)- code(用于处理数据并格式化)
MySql(用于写入数据)
各节点设置如下:
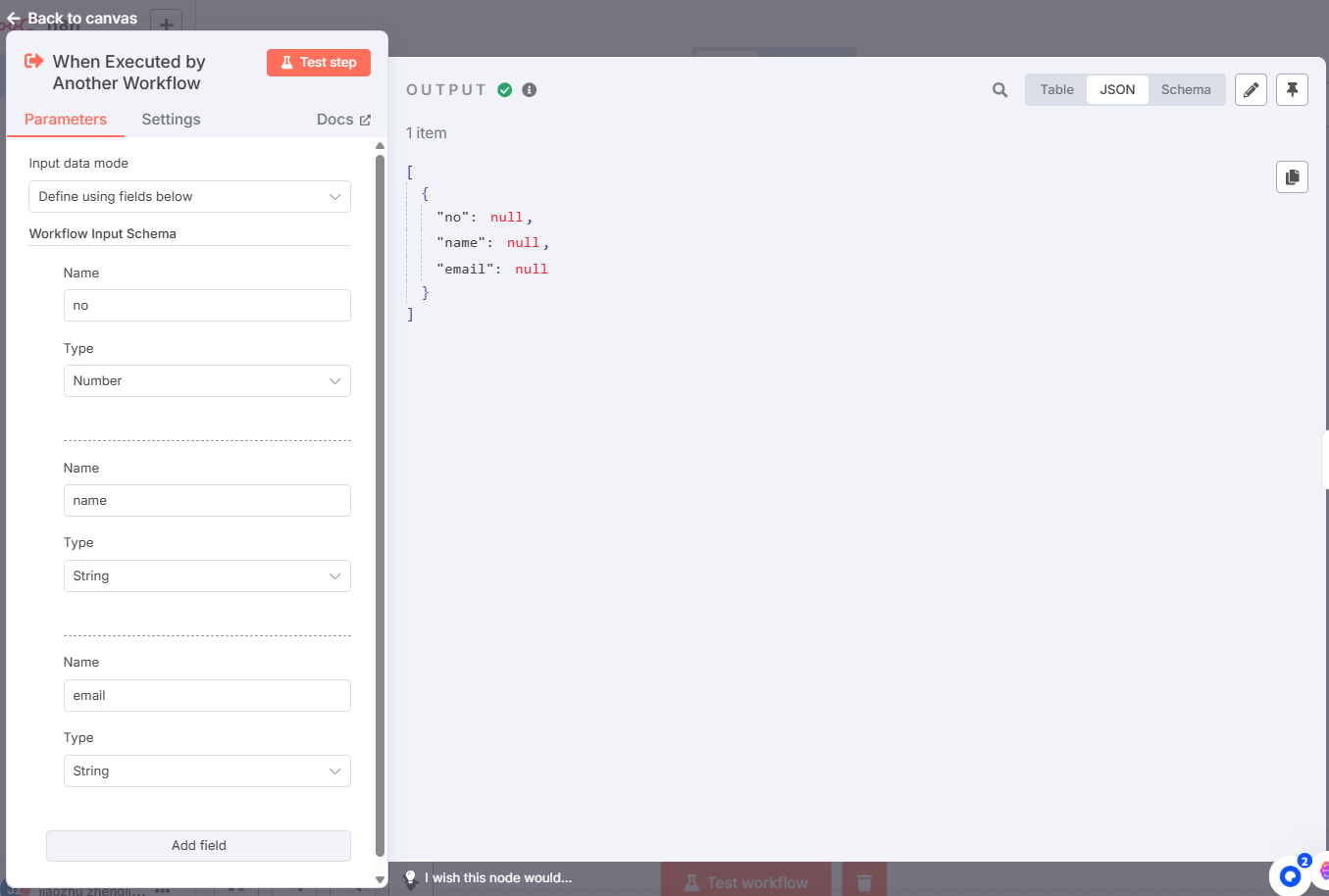
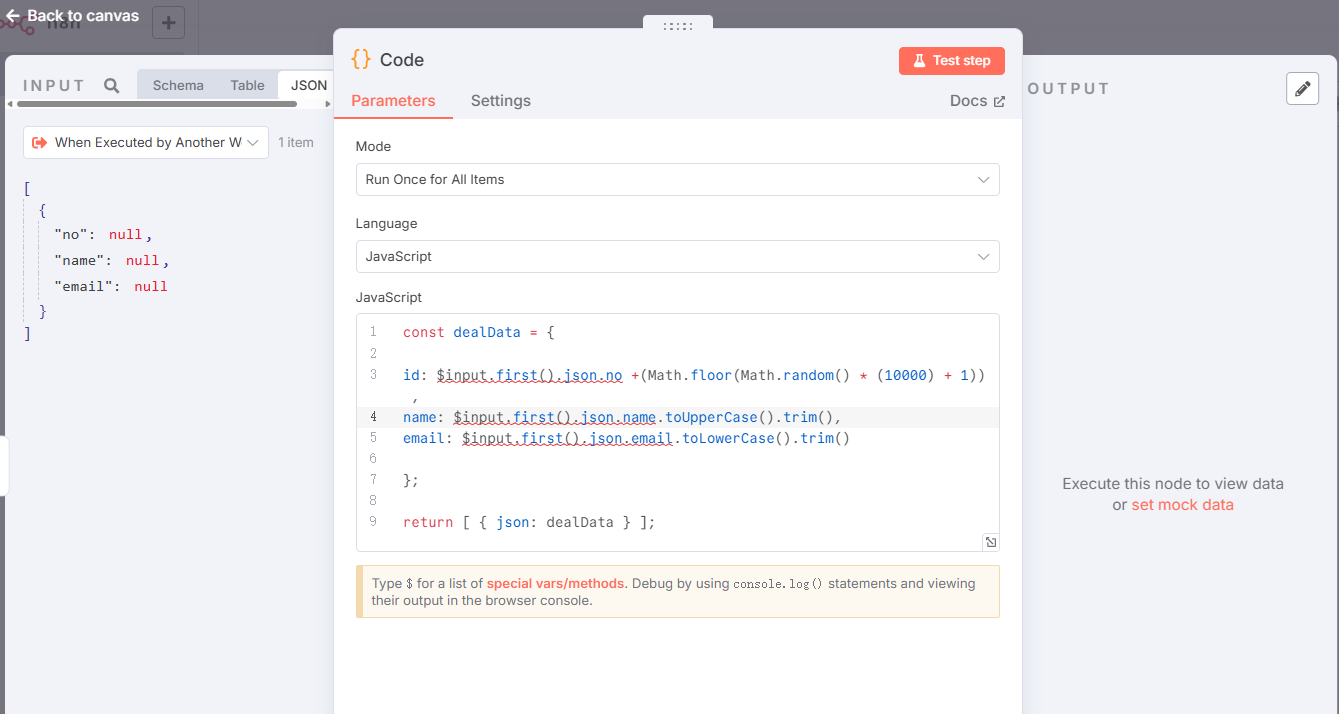 代码:
代码:
const dealData = {id: $input.first().json.no +(Math.floor(Math.random() * (10000) + 1)) ,
name: $input.first().json.name.toUpperCase().trim(),
email: $input.first().json.email.toLowerCase().trim()};return [ { json: dealData } ];⚠️ 提示:因为前一步没有数据,当前配置界面,js有错误提示,不影响保存及运行。
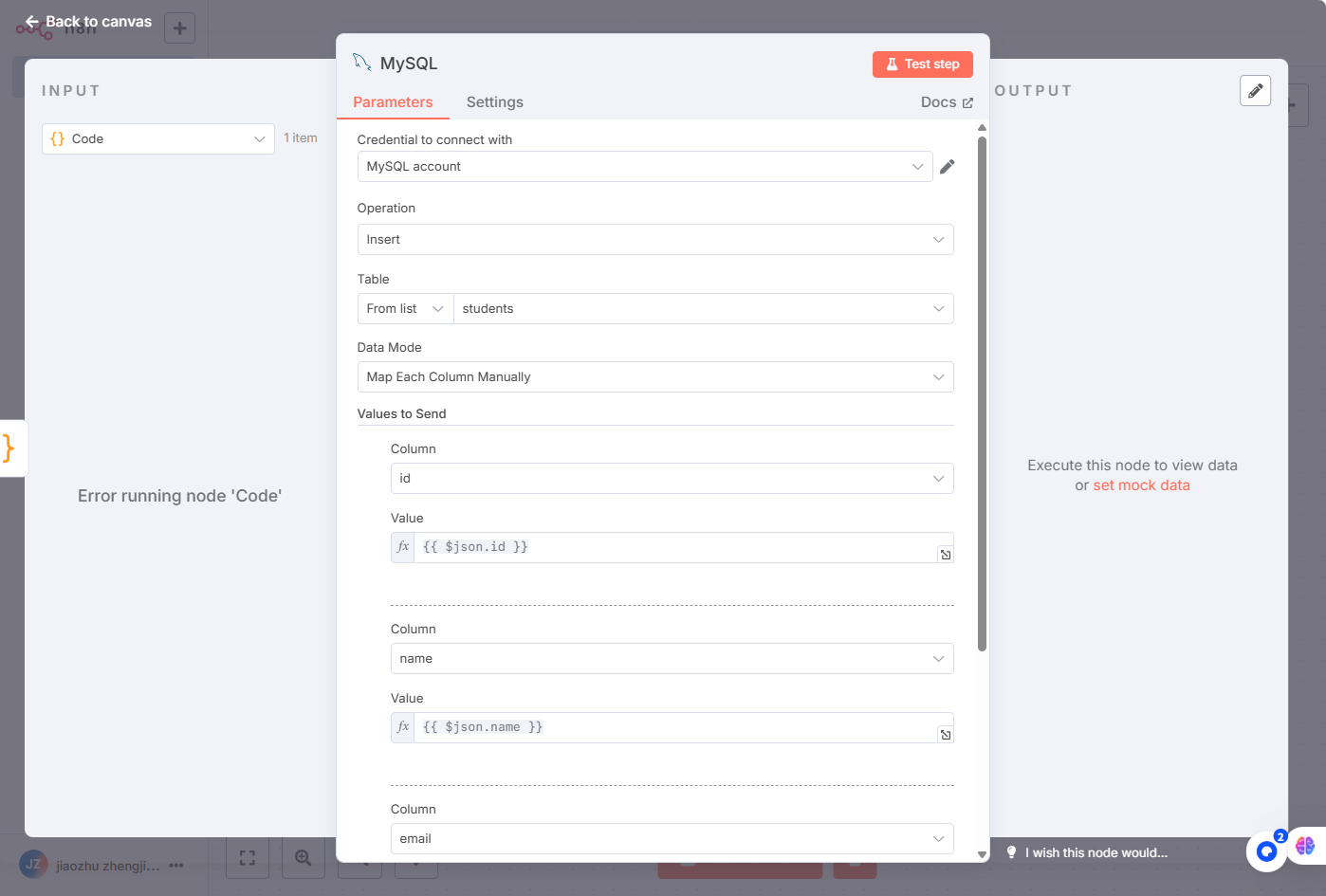
🔧创建主流程(Main Workflow)
- 新建一个工作流,命名为 :
练习7:mainflow - 添加以下节点:
Manual Trigger(手动触发)Set(设置用户数据)Execute Sub-Workflow(调用子流程)
流程图如下: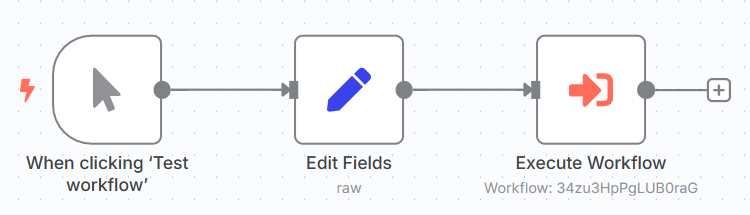
各节点设置如下:
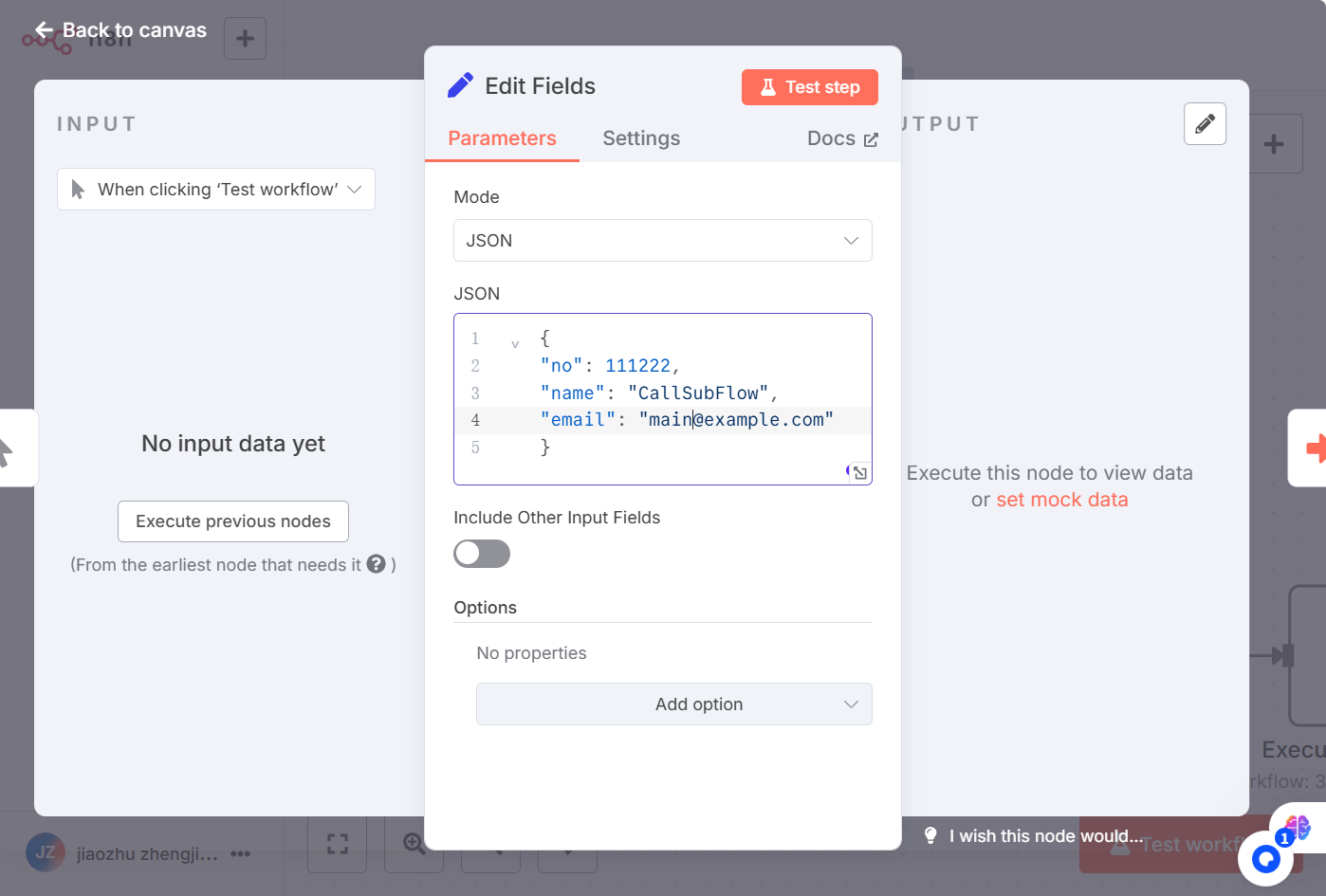
代码:
{
"no": 111222,
"name": "CallSubFlow",
"email": "main@example.com"
}set节点后,增加子流程调用节点:
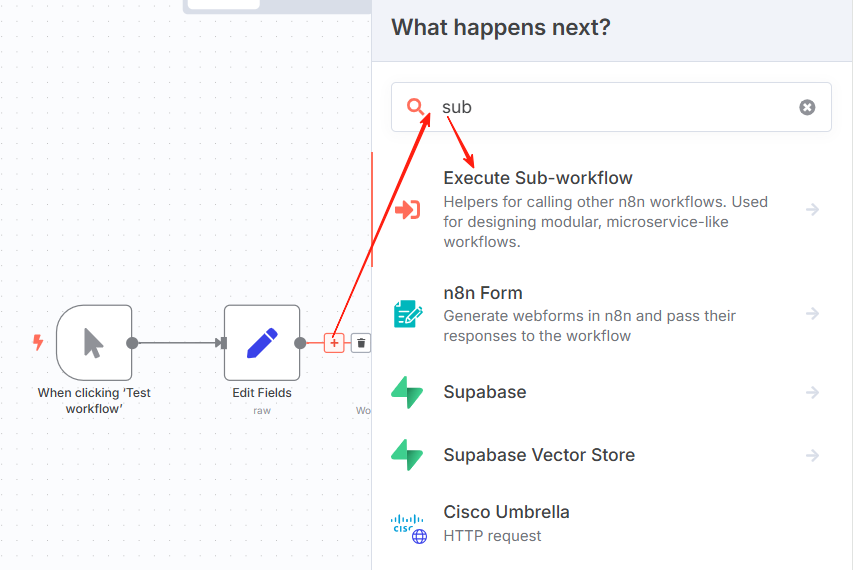
子流程节点,选择调用的流程后,子流程中设置的字段会自动加载进来:
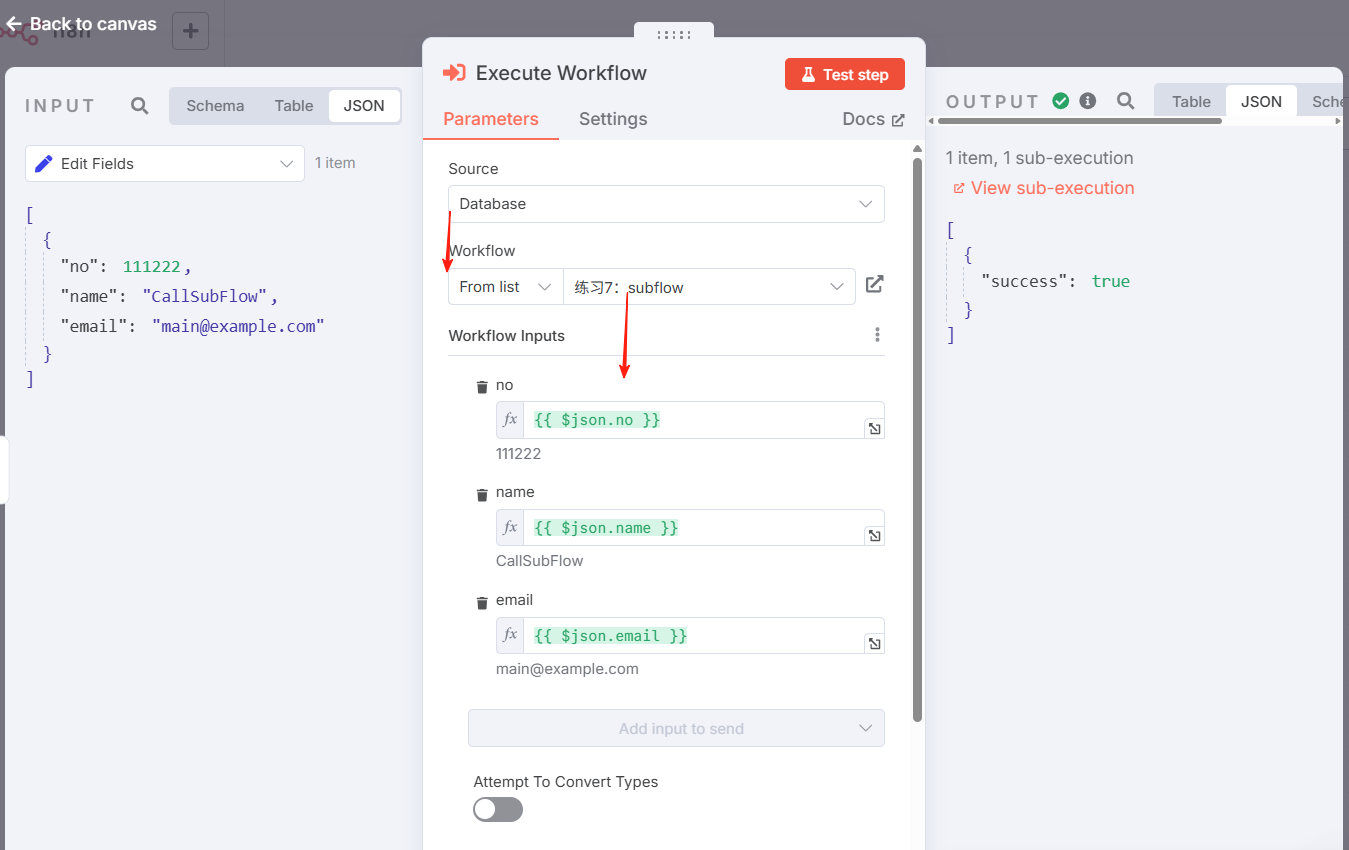
🔧测试
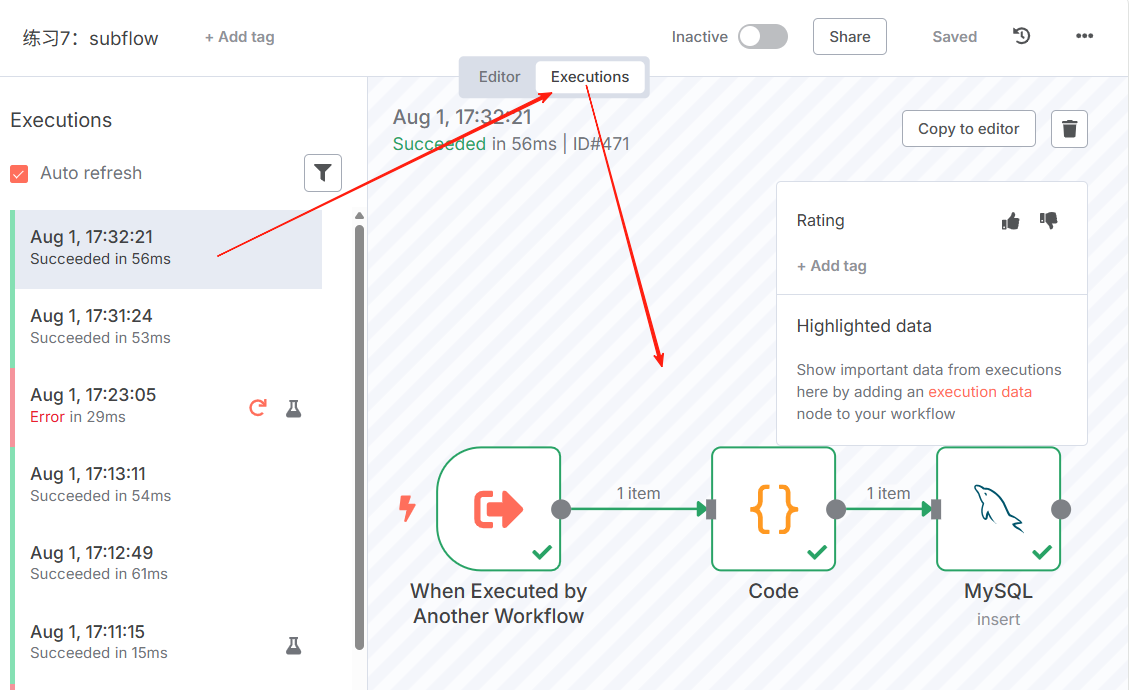
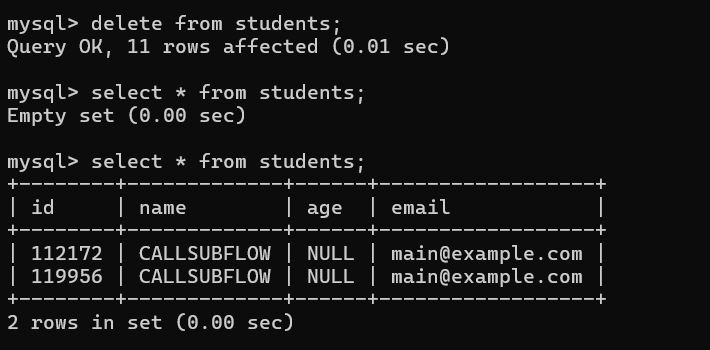
- 运行主流程
- 查看子流程的执行记录,以及数据库里的数据
📚附录(以下内容来自官方文档AI翻译)
1、Merge 节点的应用详解
您可以通过选择 模式 来指定合并节点应如何组合来自不同数据流的数据:
Append(附加 )
保留所有输入的数据。选择输入数, 以逐个输出每个输入的项目。节点等待所有连接输入的执行。
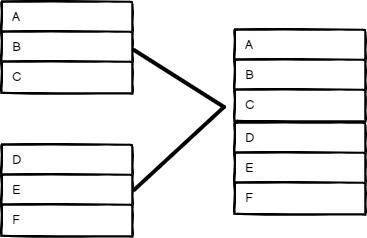
追加模式输入和输出
Combine(组合)
合并来自两个输入的数据。在 “合并方式” 中选择一个选项,以确定要如何合并输入数据。
Matching Fields(匹配字段)
按字段值比较项目。在要匹配的字段中输入要比较的字段。
n8n 的默认行为是保持匹配的项目。您可以使用输出类型设置进行更改:
- 保留匹配: 合并匹配的项目。这就像一个内在的连接。
- 保留不匹配的项目 :合并不匹配的项目。
- 保留所有内容 :将匹配的项目合并在一起,并包含不匹配的项目。这就像一个外部连接。
- 丰富输入 1: 保留输入 1 中的所有数据,并添加输入 2 中的匹配数据。这就像一个左连接。
- 丰富输入 2: 保留输入 2 中的所有数据,并添加输入 1 中的匹配数据。这就像一个右连接。
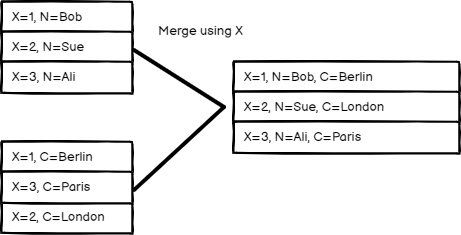
通过匹配字段进行组合模式输入和输出
Position (按位置)
根据商品的顺序组合商品。输入 1 中索引 0 的项与输入 2 中索引 0 的项合并,依此类推。
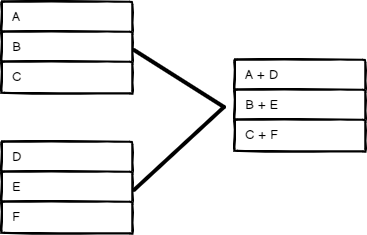
按位置模式输入和输出组合
All Possible Combinations (所有可能的组合)
输出所有可能的项目组合,同时合并具有相同名称的字段。
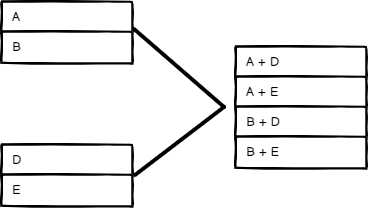
通过所有可能的组合模式输入和输出进行组合
Combine mode options (组合模式选项)
按模式 > 组合合并数据时,您可以设置以下选项 :
- 冲突处理 :选择在数据流冲突或存在子字段时如何合并。
冲突处理
如果索引中的多个项具有同名的字段,则这是冲突。例如,如果输入 1 和输入 2 中的所有项都具有名为
language的字段,则这些字段会发生冲突。默认情况下,n8n 优先考虑输入 2,这意味着如果语言在输入 2 中有一个值,则 n8n 在合并项目时使用该值。您可以通过选择 “选项”>“冲突处理 ”来更改此行为:
- 当字段值发生冲突时 :选择要优先考虑的输入,或选择始终将输入数字添加到字段名称以保留所有字段和值,并将输入数字附加到字段名称后面以显示它来自哪个输入。
- 合并嵌套字段
- 深度合并 :合并项目所有级别的属性,包括嵌套对象。这在处理复杂的嵌套数据结构时非常有用,因为您需要确保合并所有级别的嵌套属性。
- 浅层合并 :仅合并项顶层的属性,而不合并嵌套对象。当您具有平面数据结构或只需要合并顶级属性而不必担心嵌套属性时,这非常有用。
- 模糊比较: 在比较字段时是否允许类型差异(启用),是否允许(禁用,默认)。例如,当您启用此功能时,n8n 将
“3”和3视为相同。 - 禁用点表示法 :这会阻止在字段名称中使用
parent.child访问子字段。 - 多个匹配: 选择 n8n 在比较数据流时如何处理多个匹配项。
- 包括所有匹配项 :如果有多个匹配项,则输出多个项目,每个匹配项一个。
- 仅包括第一个匹配项: 保留每个匹配项的第一个项目并丢弃剩余的多个匹配项。
- 包括任何未配对的项目: 选择按位置合并时是保留还是丢弃未配对的项目。默认行为是省略不匹配的项。
Choose Branch(选择分支 )
选择要保留的输入。此选项始终等待,直到来自两个输入的数据可用。您可以选择输出 :
- 输入 1 数据
- 输入 2 数据
- 单个空项目
节点从所选输入输出数据,而不更改它。
SQL Query (SQL 查询)
编写自定义 SQL 查询来合并数据。
例:
SELECT * FROM input1 LEFT JOIN input2 ON input1.name = input2.id来自先前节点的数据可作为表使用,您可以根据其顺序在 SQL 查询中将它们用作 input1、input2、input3 等。有关受支持的 SQL 语句的完整列表,请参阅 AlaSQL GitHub 页面 。
Supported SQL statements
- SELECT TOP number columns INTO table FROM tableid1 JOIN tableid2 ON oncond WHERE cond GROUP BY v1,v2 HAVING cond ORDER BY a,b, LIMIT number OFFSET number
- INSERT INTO table [ (field1, field2) ] VALUES (value1, value2), (value3, value4), ...
- INSERT INTO table SELECT subquery
- UPDATE table SET field = value1, field = value2 WHERE condition
- DELETE FROM table WHERE condition
- CREATE TABLE [IF NOT EXISTS] table (columns type PRIMARY KEY, constraints)
- ALTER TABLE ADD COLUMN / DROP COLUMN
- DROP TABLE [IF EXISTS] table
- CREATE DATABASE, USE DATABASE, DROP DATABASE
- SHOW DATABASES / SHOW TABLES / SHOW COLUMNS / SHOW CREATE TABLE
- SOURCE 'url-file.sql'
- ASSERT json-object
- Expression (like SELECT expression)
Try all these statements in AlaSQL console
SELECT statement
AlaSQL.js supports following subset of SELECT syntax:
- SELECT column1, column2 AS alias3, FUNCTION(field4+field5) AS alias6, SUM(expression7) AS alias8, , table2.
- TOP number
- FROM table1, table2, (SELECT * FROM table3) alias
- LEFT / RIGHT / INNER / OUTER / ANTI / SEMI / CROSS / NATURAL JOIN table2 ON condition / USING columns
- WHERE condition
- GROUP BY column1, column2, ROLLUP(a,b), CUBE(c,d,e), GROUPING SETS(g,h)
- HAVING condition
- ORDER BY column1, column2 DESC,
- LIMIT number [OFFSET number]
- UNION / UNION ALL select / INTERSECT / EXCEPT
Operators:
- +, -, *, /, %, AND, OR, NOT, BETWEEN, NOT BETWEEN, EXISTS (Subquery), > ALL (subquery/array), > ANY/SOME (subquery / array), [NOT] IN (subquery / array), LIKE
- CAST (expression AS type)
Aggregators:
- SUM(), COUNT(), MIN(), MAX(), FIRST(), LAST(), AVG(), AGGR(), ARRAY(), REDUCE()
GROUP BY Grouping functions:
- ROLLUP(), CUBE(), GROUPING SETS()
Functions:
- ABS(), IIF(), IFNULL(), INSTR(), LOWER(), UPPER(), LCASE(), UCASE(), LEN(), LENGTH()
- GREATEST(), LEAST()
SELECT modifiers (non-standard SQL):
- SELECT VALUE - get single value
- SELECT ROW - get first row as an array
- SELECT COLUMN - get first column as an array
- SELECT MATRIX - get all results as an array of arrays
See a complete list of SQL-99 statements and if they are supported or not
User-defined JavaScript functions
You can use all benefits of SQL and JavaScript togeather by defining user functions. Just add new functions to alasql.fn object:
alasql.fn.double = function(x){return x*2}; alasql.fn.sum10 = function(x,y) { return x+y*10; }db.exec('SELECT a, double(a) AS b, sum10(a,b) FROM test1');User-defined functions are related to current database. You can define different functions in different databases.
2、执行工作流触发器节点(When Executed by Another Workflow)
使用此节点启动工作流以响应另一个工作流。它应该是工作流中的第一个节点。
n8n 允许您从其他工作流调用工作流。如果您想:
- 重用工作流:例如,您可以让多个工作流从不同源提取和处理数据,然后让所有这些工作流调用生成报告的单个工作流。
- 将大型工作流程分解为更小的组件。
用法
此节点运行以响应来自 “执行子工作流 ”或 “调用 n8n 工作流工具 ”节点的调用。
创建子工作流
-
创建新的工作流。
从现有工作流创建子工作流
您可以选择使用 Execute Sub-workflow 节点直接从现有父工作流创建子工作流。在节点中,选择 数据库 和 从列表选项,然后在列表中选择 创建子工作流。
您还可以使用上下文菜单中的子工作流转换直接提取选定的节点。
-
可选 :配置哪些工作流可以调用子工作流:
- 选择 “选项” 菜单>“设置 ”。n8n 打开工作流设置模式。
- 更改此工作流可以调用方式设置。有关配置工作流的更多信息,请参阅工作流设置 。
- 添加 执行子工作流 触发器节点(如果您在触发器节点下搜索,则标题也为 当由另一个工作流执行时 )。
- 设置 输入数据 模式以选择如何定义子工作流的输入数据:
- 使用以下字段定义 :选择此模式可定义调用工作流需要提供的单个输入名称和数据类型。调用工作流中的 Execute Sub-workflow 节点或 Call n8n Workflow Tool 节点将自动拉入此处定义的字段。
- 使用 JSON 示例进行定义 :选择此模式可提供演示预期输入项及其类型的示例 JSON 对象。
- 接受所有数据: 选择此模式可无条件接受所有数据。子工作流不会定义任何必需的输入项。此子工作流必须处理任何输入不一致或缺失值。
- 根据需要添加其他节点以构建子工作流功能。
- 保存子工作流。
子工作流不得包含错误
如果子工作流中存在错误,则父工作流无法触发它。
在构建之前将数据加载到子工作流中
这需要能够从以前的执行中加载数据 ,这在 n8n Cloud 和注册的社区计划中可用。
如果要将数据加载到子工作流中以在构建时使用:
- 创建子工作流并添加执行子工作流触发器 。
- 将节点的输入数据模式设置为接受所有数据, 或者使用字段或 JSON 定义输入项(如果它们已知)。
- 在子工作流设置中,将 保存成功的生产执行 设置为 保存 。
- 跳到设置父工作流,然后运行它。
- 按照步骤加载以前执行的数据 。
- 如有必要,调整输入数据模式以匹配父工作流发送的输入。
现在,您可以在触发器节点中固定示例数据,从而在配置工作流程的其余部分时处理真实数据。
调用子工作流 #
- 打开要调用子工作流的工作流。
- 添加 执行子工作流 节点。
-
在 “执行子工作流” 节点中,设置要调用的子工作流。您可以选择按 ID 调用工作流、从本地文件加载工作流、将工作流 JSON 添加为节点中的参数,或通过 URL 定位工作流。
查找工作流 ID
子工作流的 ID 是其 URL 末尾的字母数字字符串。
-
填写子工作流定义的必填输入项。
- 保存您的工作流程。
当您的工作流执行时,它会将数据发送到子工作流,并运行它。
您可以通过打开 Execute Sub-workflow 节点并选择 View sub-execution 链接来跟踪从父工作流到子工作流的执行流程。同样,子工作流的执行包含一个返回父工作流执行的链接,以便导航到另一个方向。
数据如何在工作流之间传递 #
例如,假设您在工作流 A 中有一个执行子工作流节点。“执行子工作流”节点调用另一个名为 “工作流 B”的工作流:
- “执行子工作流”节点将数据传递到工作流 B 的“执行子工作流触发器”节点(画布中的标题为“当由另一个节点执行时”)。
- 工作流 B 的最后一个节点将数据发送回工作流 A 中的“执行子工作流”节点。
3、执行子工作流(Execute Sub-workflow)
使用“执行子工作流”节点在运行 n8n 的主机上运行不同的工作流。
节点参数
来源
选择节点应从以下位置获取子工作流的信息:
- 数据库: 选择此选项可按 ID 从数据库加载工作流。您还必须输入:
- 从列表: 从帐户可用的工作流列表中选择工作流。
- 工作流 ID:输入工作流的 ID。工作流的 URL 包含
/workflow/之后的 ID。例如,如果工作流的 URL 为https://my-n8n-acct.app.n8n.cloud/workflow/abCDE1f6gHiJKL7,则工作流 ID 为abCDE1f6gHiJKL7。
- 本地文件: 选择此选项可从本地保存的 JSON 文件加载工作流。您还必须输入:
- 工作流路径: 输入您希望节点执行的本地 JSON 工作流文件的路径。
- 参数 :选择此选项可从参数加载工作流。您还必须输入:
- 工作流 JSON:输入您希望节点执行的 JSON 代码。
- URL:选择此选项可从 URL 加载工作流。您还必须输入:
- 工作流 URL:输入要从中加载工作流的 URL。
工作流输入 #
如果使用数据库和 “从列表” 选项选择子工作流,则子工作流的输入项将自动显示,供您填写或映射值。
您可以选择删除请求的输入项,在这种情况下,子工作流会接收 null 作为项的值。您还可以启用尝试转换类型以尝试自动将数据转换为子工作流项请求的类型。
如果子工作流的“工作流输入触发器”节点使用“接受所有数据”输入数据模式,则不会显示输入项。
模式 #
使用此参数可控制节点的执行模式。从以下选项中进行选择:
- 对所有项目运行一次 :将所有输入项目传递到节点的单个执行中。
- 为每个项目运行一次 :依次为每个输入项目执行一次节点。
节点选项 #
此节点包括一个选项:“ 等待子工作流完成”。这使您可以控制主工作流是否应等待子工作流完成,然后再继续下一步(已打开),或者主工作流是否应继续而不等待(已关闭)。
设置和使用子工作流 #
本节演练如何设置父工作流和子工作流。
创建子工作流 #
-
创建新的工作流。
从现有工作流创建子工作流
您可以选择使用 Execute Sub-workflow 节点直接从现有父工作流创建子工作流。在节点中,选择 数据库 和 从列表选项,然后在列表中选择 创建子工作流。
您还可以使用上下文菜单中的子工作流转换直接提取选定的节点。
-
可选 :配置哪些工作流可以调用子工作流:
- 选择 “选项” 菜单>“设置 ”。n8n 打开工作流设置模式。
- 更改此工作流可以调用方式设置。有关配置工作流的更多信息,请参阅工作流设置 。
- 添加 执行子工作流 触发器节点(如果您在触发器节点下搜索,则标题也为 当由另一个工作流执行时 )。
- 设置 输入数据 模式以选择如何定义子工作流的输入数据:
- 使用以下字段定义 :选择此模式可定义调用工作流需要提供的单个输入名称和数据类型。调用工作流中的 Execute Sub-workflow 节点或 Call n8n Workflow Tool 节点将自动拉入此处定义的字段。
- 使用 JSON 示例进行定义 :选择此模式可提供演示预期输入项及其类型的示例 JSON 对象。
- 接受所有数据: 选择此模式可无条件接受所有数据。子工作流不会定义任何必需的输入项。此子工作流必须处理任何输入不一致或缺失值。
- 根据需要添加其他节点以构建子工作流功能。
- 保存子工作流。
子工作流不得包含错误
如果子工作流中存在错误,则父工作流无法触发它。
在构建之前将数据加载到子工作流中
这需要能够从以前的执行中加载数据 ,这在 n8n Cloud 和注册的社区计划中可用。
如果要将数据加载到子工作流中以在构建时使用:
- 创建子工作流并添加执行子工作流触发器 。
- 将节点的输入数据模式设置为接受所有数据, 或者使用字段或 JSON 定义输入项(如果它们已知)。
- 在子工作流设置中,将 保存成功的生产执行 设置为 保存 。
- 跳到设置父工作流,然后运行它。
- 按照步骤加载以前执行的数据 。
- 如有必要,调整输入数据模式以匹配父工作流发送的输入。
现在,您可以在触发器节点中固定示例数据,从而在配置工作流程的其余部分时处理真实数据。
调用子工作流 #
- 打开要调用子工作流的工作流。
- 添加 执行子工作流 节点。
-
在 “执行子工作流” 节点中,设置要调用的子工作流。您可以选择按 ID 调用工作流、从本地文件加载工作流、将工作流 JSON 添加为节点中的参数,或通过 URL 定位工作流。
查找工作流 ID
子工作流的 ID 是其 URL 末尾的字母数字字符串。
-
填写子工作流定义的必填输入项。
- 保存您的工作流程。
当您的工作流执行时,它会将数据发送到子工作流,并运行它。
您可以通过打开 Execute Sub-workflow 节点并选择 View sub-execution 链接来跟踪从父工作流到子工作流的执行流程。同样,子工作流的执行包含一个返回父工作流执行的链接,以便导航到另一个方向。