从JPEG到SER:小波+CNN如何横扫CVPR/ICASSP?
分享一个大模型时代很有潜力的研究方向:小波变换+CNN。随着深度学习的发展,小波变换与CNN的结合受到了越来越多的关注。小波变换能够有效地提取信号的多尺度特征,而CNN则擅长处理图像等复杂数据。两者的结合不仅在图像压缩、语音情感识别等领域取得了显著成果,还为解决特征提取和模型优化等问题提供了新的思路。未来,这一方向有望在更多领域实现突破,为学术研究和实际应用带来更多可能性。
下面小图给大家拆解一些相关领域的杰出研究,满满干货,点赞收藏不迷路~
SigWavNet: Learning Multiresolution Signal Wavelet Network for Speech Emotion Recognition
方法:文章首先利用FDWT的特性,包括级联算法、共轭二次滤波器和系数去噪,构建了一个可学习的小波基和去噪模型。接着,通过1D dilated CNN和空间注意力层捕捉情感特征的空间特性,再利用Bi-GRU和时间注意力层捕捉情感特征的时间特性。最后,通过通道加权和全局平均池化层整合多频带特征,并通过Log Softmax层输出情感概率。
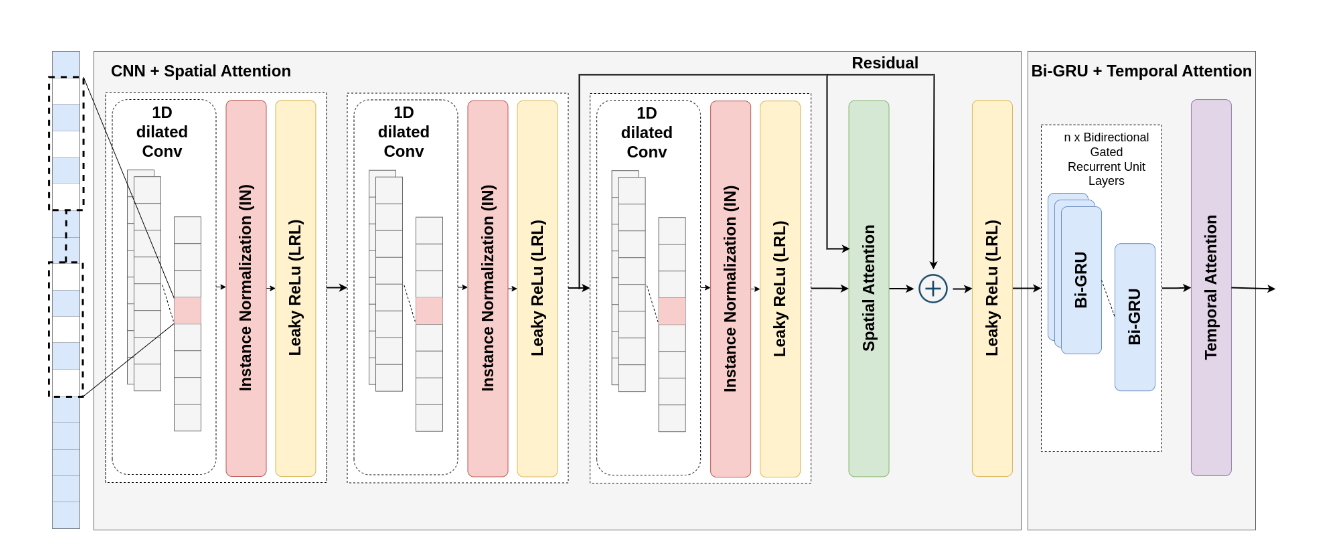
创新点:
提出了一种端到端的深度学习框架,直接从原始语音波形信号中提取有意义的表示,无需预处理或后处理。
引入了快速离散小波变换(FDWT)的可学习模型,通过深度学习技术优化小波系数的阈值操作。
结合一维扩张卷积神经网络、空间注意力层以及双向门控循环单元(Bi-GRU)和时间注意力层,有效捕捉情感特征的时空特性。
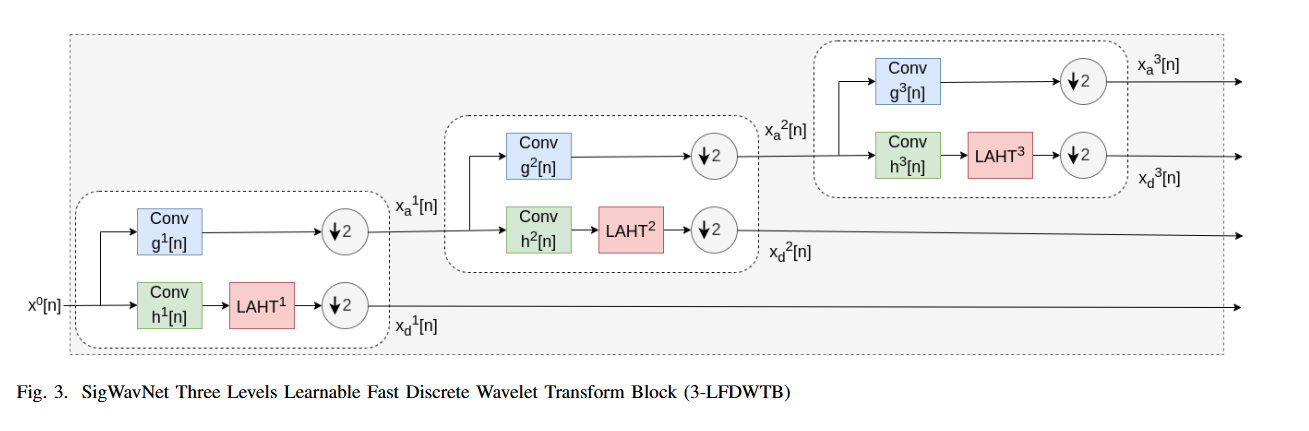
总结:这篇文章提出了一种新颖的多分辨率信号小波网络(SigWavNet),用于语音情感识别(SER),旨在解决现有方法在系统复杂性、特征独特性以及噪声干扰等方面存在的挑战。
3DM-WeConvene: Learned Image Compression with 3D Multi-Level Wavelet-Domain Convolution and Entropy Model
方法:文章首先利用3DM-WeConv层对输入图像进行特征提取,并在这些子带上应用不同大小的卷积核以捕捉不同频率的特征。接着,通过逆3D DWT将特征转换回空间域。在熵编码部分,3DWeChARM模块对3D DWT后的数据进行切片式编码,优先编码低频切片,并将其作为高频切片编码的先验,从而提高编码效率。最后,通过两步训练策略,先平衡不同频率子带的速率,再进行微调,以优化整个系统的性能。
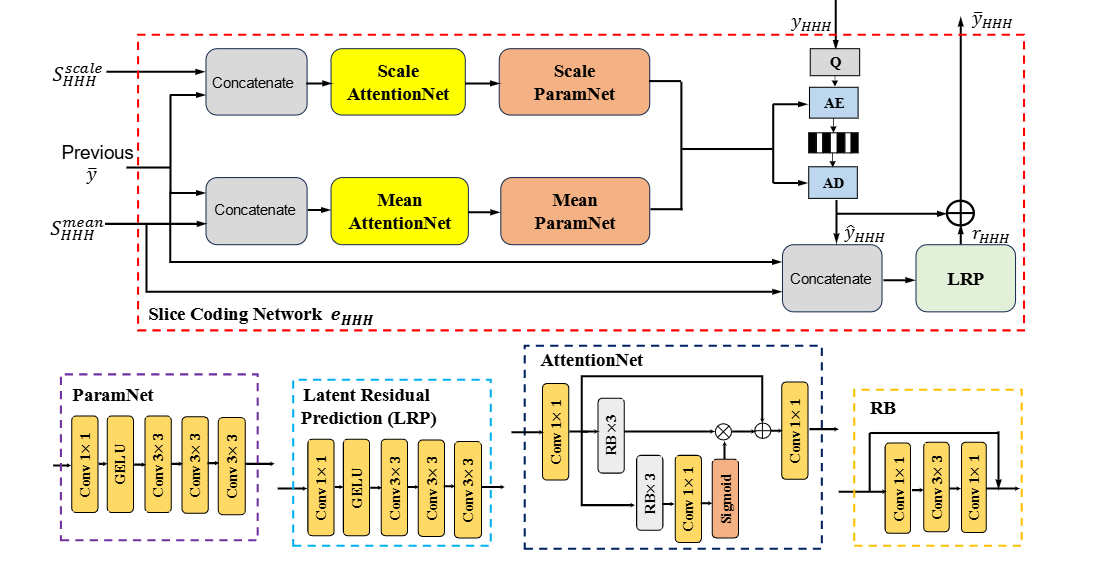
创新点:
提出了一种3D多级小波域卷积(3DM-WeConv)层,通过3D DWT将数据转换到小波域,对不同频率子带应用不同大小的卷积核,再通过逆3D DWT转换回空间域,有效增强了频率选择性。
引入了3D小波域通道自回归熵模型(3DWeChARM),在3D DWT域中进行切片式熵编码,先编码低频切片作为高频切片的先验,进一步提高了编码效率。
采用两步训练策略,先平衡低频和高频子带的速率,再通过权重调整进行微调,优化了系统性能。
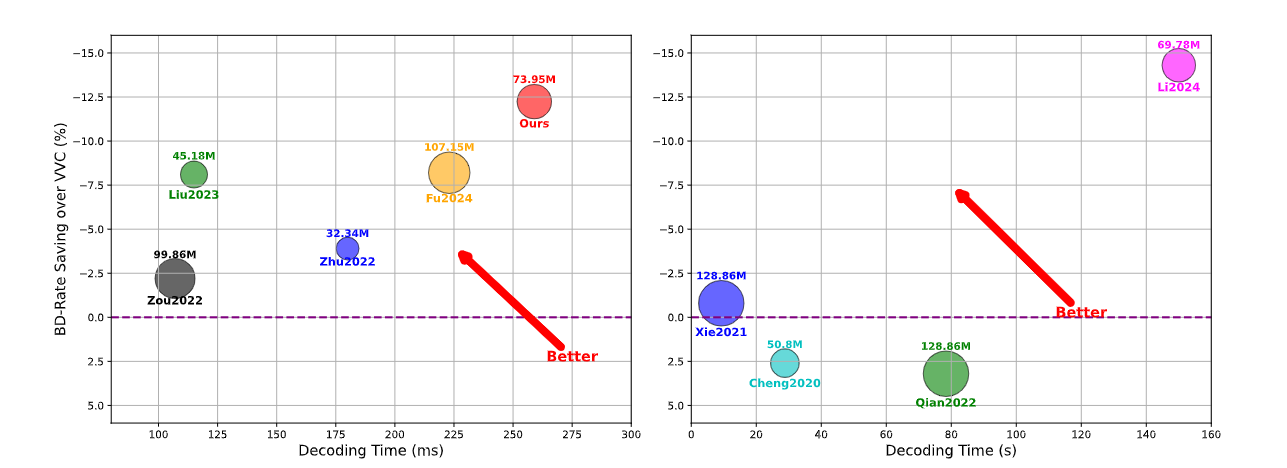
总结:这篇文章提出了一种基于3D多级小波域卷积和熵模型(3DM-WeConvene)的深度学习图像压缩框架,旨在通过整合3D多级离散小波变换(DWT)来减少空间和通道相关性,提升频率选择性和率失真(R-D)性能。
纠结选题?导师放养?投稿被拒?对论文有任何问题的同学,欢迎来gongzhonghao【图灵学术计算机论文辅导】,每天两个免费咨询服务~
WeConvene: Learned Image Compression with Wavelet-Domain Convolution and Entropy Model
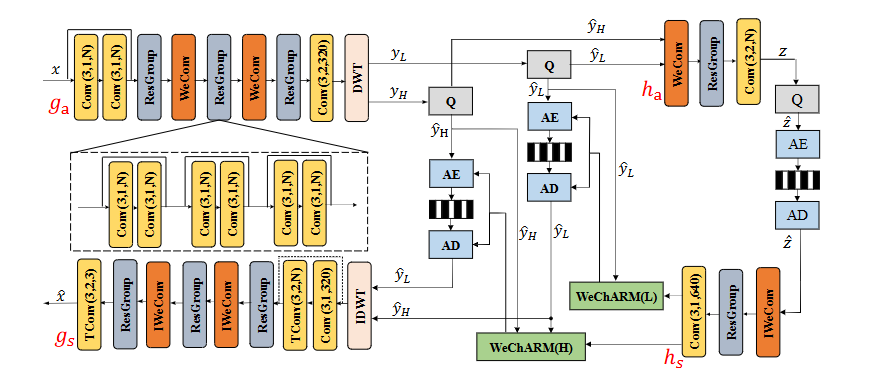
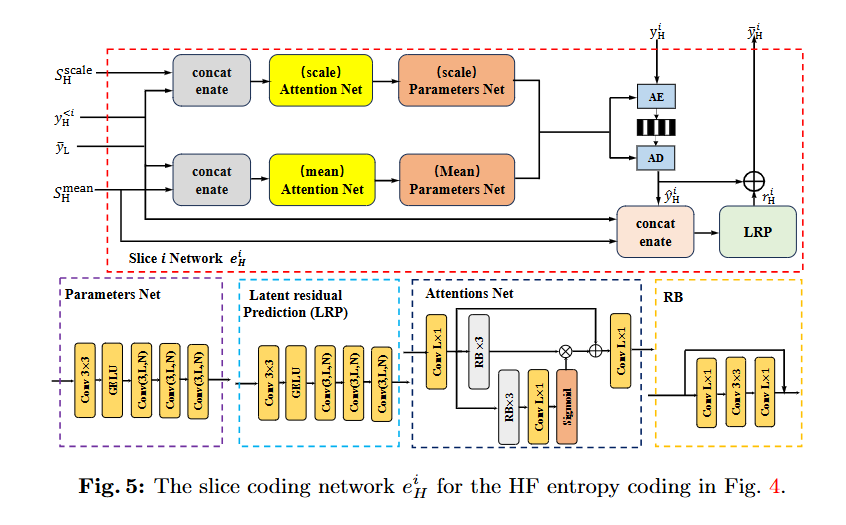
方法:文章首先在核心编码器网络中应用DWT将输入图像的潜在表示转换到小波域,然后通过WeConv模块进行卷积操作,接着对小波系数进行量化和熵编码。在熵编码部分,WeChARM模块将编码过程分为两步,先编码低频子带,再编码高频子带,并利用通道自回归熵编码进一步提高编码效率。最后,通过逆DWT将数据转换回空间域以重建图像。
创新点:
提出了一种小波域卷积(WeConv)模块,通过在DWT和逆DWT之间嵌入卷积操作,使信号在小波域中变得更加稀疏,从而提高压缩效率。
引入了小波域通道自回归熵模型(WeChARM),在编码过程中先对低频DWT系数进行编码,再利用这些低频信息作为先验来编码高频系数。
该框架基于卷积神经网络(CNN),相较于基于Transformer的方案,更容易训练且对GPU资源要求更低,实现了复杂度与性能之间的良好平衡。
总结:这篇文章提出了一种基于小波域卷积和熵模型的深度学习图像压缩框架(WeConvene),旨在通过引入离散小波变换(DWT)来减少空间和频率域的相关性,从而提升图像压缩的率失真(R-D)性能。