【C++】priority_queue的模拟实现
目录
- 一、`priority_queue` 要点解析
- 二、仿函数
- 2.1 仿函数的简单使用
- 2.2 仿函数的进阶使用
- 三、`priority_queue`的模拟实现
- 3.1 基础框架
- 3.2 adjust_down和adjust_up
- 向下调整算法adjust_down
- 向上调整算法adjust_up
- 3.3 构造`(constructor)`
- 3.3.1 构造函数
- 3.3.2 迭代器区间构造
- 3.4 push
- 3.5 pop
- 3.6 top
- 3.7 `empty`和`size`
- 3.8 整体测试
- 四、算法竞赛中堆的使用方式

个人主页<—请点击
C++专栏<—请点击
一、priority_queue 要点解析
我们上期讲解了stack和queue的模拟实现,priority_queue和它们一样也是一种容器适配器。它提供了优先队列(堆)的功能。以下是库中原型:
注意:优先队列,一种特殊的队列,元素按优先级出队,而不是先进先出。

可以看出库中实现它的底层容器使用了vector,这也没有什么争议,在C语言模拟堆的时候,我们就知道使用数组对二叉堆进行存储是合理的。
其中第三个模板参数Compare是一个函数对象类型(也称为仿函数),它用于定义队列中元素的比较规则,即决定哪个元素的优先级更高。默认值是std::less<T>,这意味着priority_queue默认是一个大根堆,这个和我们预想的似乎不太一样,它是反着的,传less<T>时(默认),是大根堆,传greater<T>时,是小根堆。
使用测试:
void test()
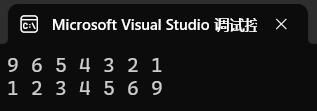
{vector<int> a = { 2,5,3,9,6,4,1 };//默认是大根堆priority_queue<int> p(a.begin(),a.end());while (p.size()){cout << p.top() << " ";p.pop();}cout << endl;//小根堆priority_queue<int,vector<int>,greater<int>> q(a.begin(), a.end());while (q.size()){cout << q.top() << " ";q.pop();}cout << endl;
}
注意:这里priority_queue后面尖括号中需要的是类型,所以传递less<T>、greater<T>即可。
测试结果:
仿函数也是我们本期博客的重点,仿函数是一个类(或结构体),它通过重载operator()使得该类的对象可以像函数一样被调用。
二、仿函数
2.1 仿函数的简单使用
既然仿函数是我们本期博客的重点,所以我们就把它直接拎出来先讲。
仿函数是一个类(或结构体),它通过重载operator()使得该类的对象可以像函数一样被调用。
我们可以先实现一个仿函数来打破它的神秘感,我们都会加法运算,那我们就先实现一个加法运算的仿函数。
class Add
{
public:int operator()(const int& a,const int& b){return a + b;}
};
测试:
void test1()
{Add add;int a = add(2, 3);cout << a;
}
结果:
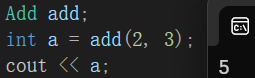
这就是仿函数基本的使用方法,它的调用方式就像调用函数一样。
2.2 仿函数的进阶使用
我们都使用过冒泡排序,这个最基本的排序算法是我们最先熟知的,它的大致实现如下:
void BubbleSort(int* a, int n)
{for (int i = 0;i < n;i++){int flag = 0;for (int j = 0;j < n - i - 1;j++){if (a[j] > a[j+1]){flag = 1;swap(a[j], a[j + 1]);}}if (!flag)break;}
}
现在我们要对冒泡排序进行升级,把它升级为模板函数,再对它使用仿函数。
那现在我们就应该考虑仿函数应该在哪里应用了,它的作用是用于定义队列中元素的比较规则,决定哪个元素的优先级更高,也就是比较逻辑,那在冒泡排序中就是if条件语句。
首先我们就要对冒泡排序的声明部分进行改造:
template<class T, class Com = Less<T>>
void BubbleSort(T* a, int n, Com cmp);
这样我们的仿函数就有了用武之地,其次我们就要调用仿函数,将比较逻辑变为cmp(a,b)。
最终冒泡排序变成了这样:
template<class T, class Com = Less<T>>
void BubbleSort(T* a, int n, Com cmp)
{for (int i = 0;i < n;i++){int flag = 0;for (int j = 0;j < n - i - 1;j++){if (cmp(a[j], a[j + 1])){flag = 1;swap(a[j], a[j + 1]);}}if (!flag)break;}
}
仿函数Less:
template<class T>
class Less
{
public:bool operator()(const T& a, const T& b){return a < b;}
};
仿函数Greater:
template<class T>
class Greater
{
public:bool operator()(const T& a, const T& b){return a > b;}
};
测试:
void test2()
{int a[] = { 8,6,9,7,5,3,4,2,1 };BubbleSort(a, 9, Less<int>());for (auto& e : a)cout << e << " ";cout << endl;BubbleSort(a, 9, Greater<int>());for (auto& e : a)cout << e << " ";cout << endl;
}
注意:这里排序算法的第三个参数需要的是类对象,所以我们可以传递匿名对象过去。
结果:
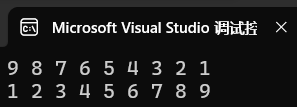
这样实现的比较逻辑刚好和库中的相同,相当于调用less是大根堆,而调用greater是小根堆,当把com(a,b)中的a和b的位置调换一下就相反了。
三、priority_queue的模拟实现
3.1 基础框架
namespace PRI
{template<class T>class less{public:bool operator()(const T& x, const T& y){return x < y;}};template<class T>class greater{public:bool operator()(const T& x, const T& y){return x > y;}};template<class T,class Container = vector<T>,class Compare = less<T>>class priority_queue{public:private:Container _con;};
}
由于我们设计的类名都和库中的名称相同,为了避免命名冲突,所以将它们放入了一个命名空间中。
priority_queue的成员变量就只有一个vector<T>类型的对象,这就足够存储优先队列了。
3.2 adjust_down和adjust_up
为了维护堆,向下调整算法和向上调整算法是不可避免的,它们是维护堆的核心方式,之前的博客对这两种算法进行过讲解,这里就不过多赘述,需要的点击即可【数据结构】堆。
此外我们不希望别人在类外面可以调用它们,所以我们将它们定义为私有。
向下调整算法adjust_down
void adjust_down(int parent)
{Compare cmp;int child = parent * 2 + 1;while (child < _con.size()){if (child + 1 < _con.size() && cmp(_con[child], _con[child + 1]))++child;if (cmp(_con[parent], _con[child])){swap(_con[child], _con[parent]);parent = child;child = parent * 2 + 1;}elsebreak;}
}
注意:这里为了和库中默认是大根堆一样,就要在比较逻辑上花一些心思,不然很有可能就错了。
向上调整算法adjust_up
void adjust_up(int child)
{Compare cmp;int parent = (child - 1) / 2;while (child > 0){if (cmp(_con[parent], _con[child])){swap(_con[child], _con[parent]);child = parent;parent = (child - 1) / 2;}elsebreak;}
}
3.3 构造(constructor)
3.3.1 构造函数
默认生成的构造函数就足够了,因为它会调用自定义类型自己的构造函数,由于我们还要实现迭代器区间构造,所以可以强制让编译器生成默认构造函数。
priority_queue() = default;
3.3.2 迭代器区间构造
我们知道vector实现了迭代器区间构造,所以我们调用它的迭代器区间构造就可以了,但是需要注意的是我们还要将这段区间的数据调整成大根堆或者小根堆。
template<class InputIterator>
priority_queue(InputIterator first, InputIterator last):_con(first,last)
{//向下调整建堆for (int i = ((_con.size() - 1) - 1) / 2;i >= 0;i--){adjust_down(i);}
}
这里采用了向下调整建堆,从最后一个父节点开始调整,逐步向上移动,等到移动到堆顶时,也就调整好了。其中_con.size()-1是末尾的值,它再减一除2就是它的父节点。
3.4 push
void push(const T& val)
{_con.push_back(val);adjust_up(_con.size() - 1);
}
3.5 pop
直接删除堆顶不好删,可以和最后一个元素交换一下,然后调用成员变量的pop_back,再向下调整堆即可。
void pop()
{swap(_con[0], _con[_con.size() - 1]);_con.pop_back();adjust_down(0);
}
3.6 top
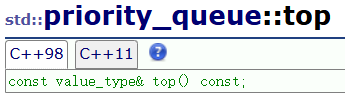
const T& top() const
{return _con[0];
}
3.7 empty和size
bool empty() const
{return _con.empty();
}
size_t size() const
{return _con.size();
}
3.8 整体测试
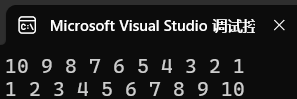
void test3()
{vector<int> a = { 8,6,5,9,2,1,7,3,4,10 };PRI::priority_queue<int, vector<int>, PRI::less<int>> p(a.begin(),a.end());while (p.size()){cout << p.top() << " ";p.pop();}cout << endl;PRI::priority_queue<int, vector<int>, PRI::greater<int>> q(a.begin(), --a.end());q.push(10);while (!q.empty()){cout << q.top() << " ";q.pop();}
}
结果:
四、算法竞赛中堆的使用方式
在算法竞赛中,一旦考到堆,它的结点一般是比较复杂的,这时候我们库中的方法无法很好的完成任务,这时候如果时间充裕的话,我们可以重新写一个仿函数,但是竞赛就是追求速度的,所以这时候仿函数就不是最优解了,其实还有一种解决办法。
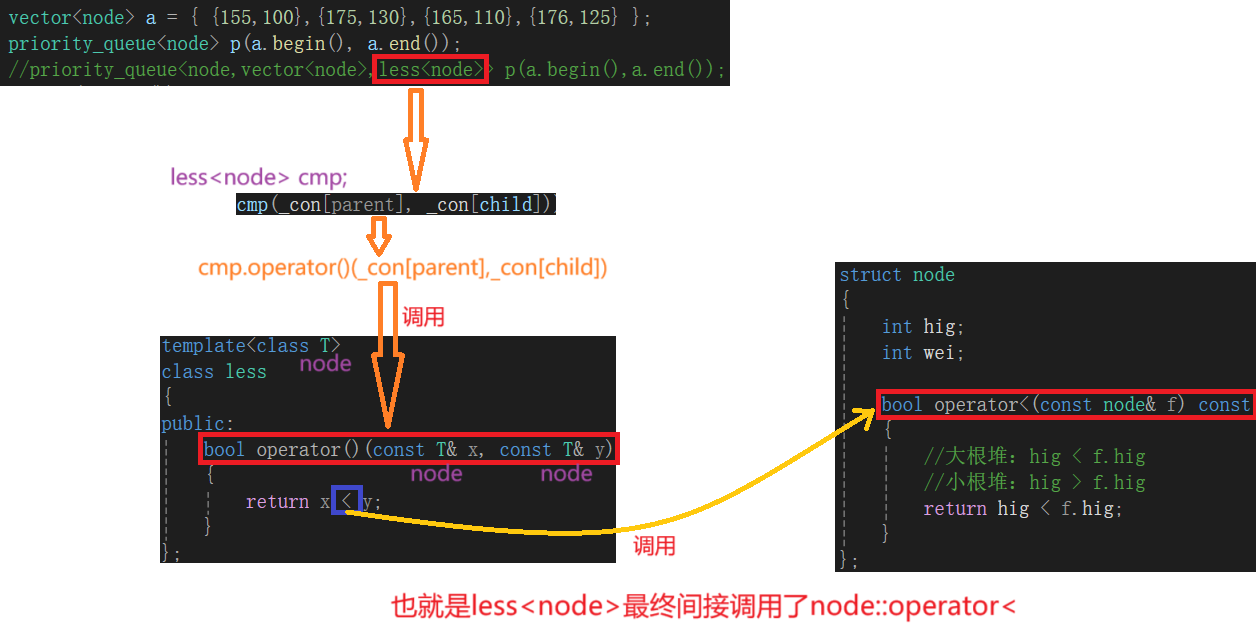
在定义的结点中重载operator<,这样也可以完成对小根堆和大根堆的控制。
原理:priority_queue它默认的仿函数是less,而它是使用<运算符进行比较的,这样较大的元素会排在前面,也就是说priority_queue默认是用<进行比较的,所以只要我们在我们定义的结点内部对operator<进行重载就能控制大、小根堆。
应用
假设我们现在有一个相对复杂的结点,结点中有两个变量身高、体重,我们要针对其中一个变量比如身高进行建堆,这个时候我们就可以重载operator<了。
struct node
{int hig;int wei;bool operator<(const node& f) const{//大根堆:hig < f.hig//小根堆:hig > f.higreturn hig < f.hig;}
};
此时我们的代码执行出来的就是大根堆。
测试:
void test4()
{vector<node> a = { {155,100},{175,130},{165,110},{176,125} };priority_queue<node> p(a.begin(), a.end());while (p.size()){node t = p.top();p.pop();cout << t.hig << " " << t.wei << endl;}
}
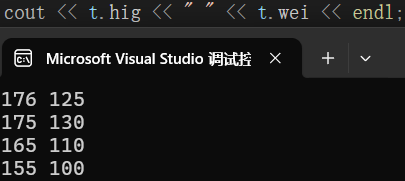
想要变成小根堆将operator<中的<改为>就好了。
原理解释图:
总结:
以上就是本期博客分享的全部内容啦!如果觉得文章还不错的话可以三连支持一下,你的支持就是我前进最大的动力!
技术的探索永无止境! 道阻且长,行则将至!后续我会给大家带来更多优质博客内容,欢迎关注我的CSDN账号,我们一同成长!
(~ ̄▽ ̄)~