深入理解Linux网络--读书笔记(二)
第5章 深入理解本机网络
5.1 相关实际问题
➥ 127.0.0.1本机网络10需要经过网卡吗?
➥ 数据包在内核中是什么走向,和外网发送相比流程上有什么差别?
➥ 访问本机服务时,使用127.0.0.1能比使用本机IP(例如192.168.X.X)更快吗?
5.2 跨机网络通信过程
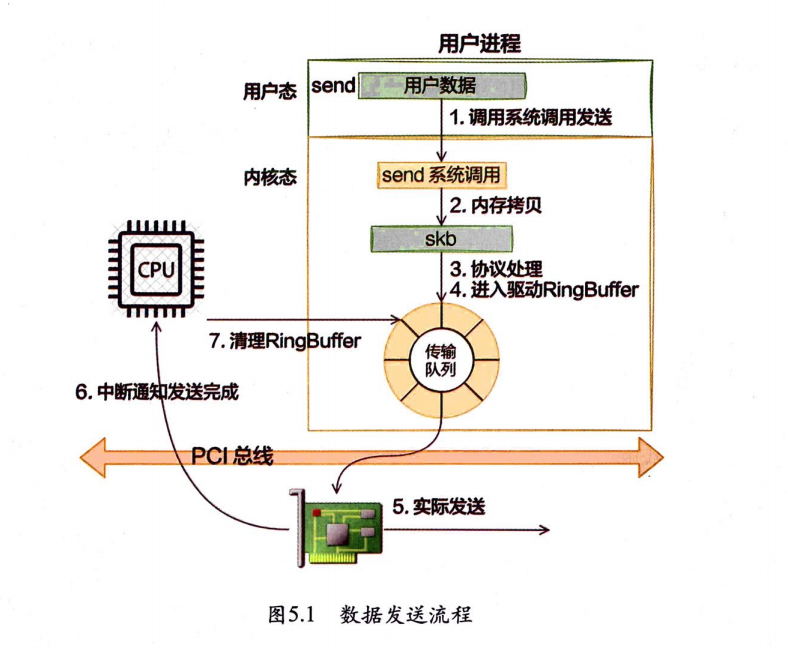
5.2.1 跨机数据发送
从send系统调用开始,直到网卡把数据发送出去。 用户数据被拷贝到内核态,然后经过协议栈处理后进入RingBuffer。随
后网卡驱动真正将数据发送了出去。当发送完成的时候,是通过硬中断来通知CPU,然后清理RingBuffer。
5.2.2 跨机数据接收
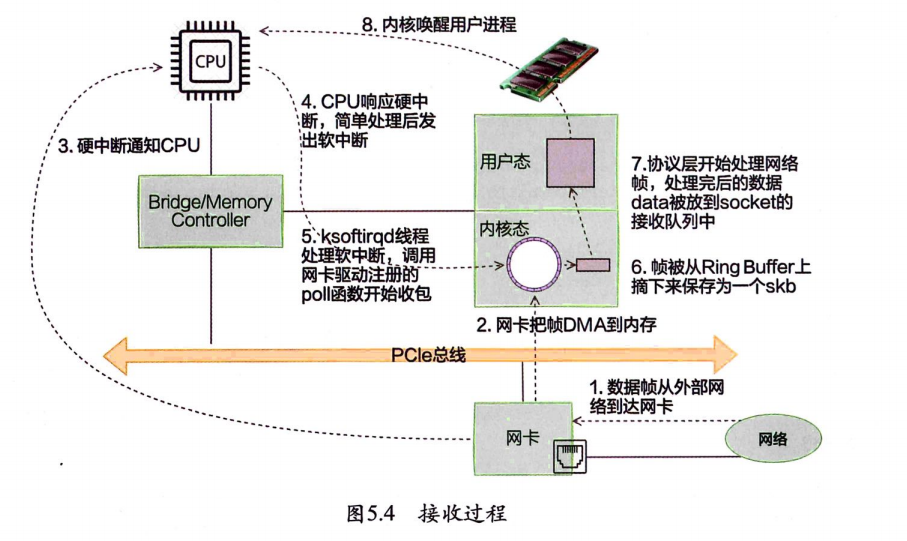
当网卡收到数据以后,向CPU发起一个中断,以通知CPU有数据到达。当CPU收到中断请求后,会去调用网络驱动注册的中断处理函数,触发软中断。ksoftirgd检测到有软中断请求到达,开始轮询收包,收到后交由各级协议栈处理。当协议栈处理完并把数据放到接收队列之后,唤醒用户进程(假设是阻塞方式)。
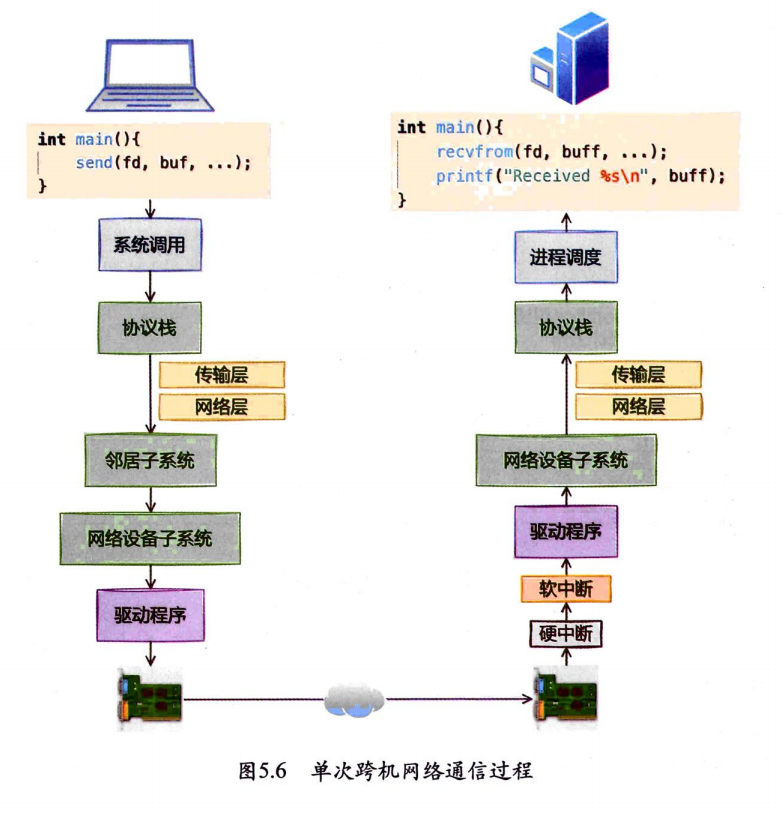
5.2.3 跨机网络通信汇总
5.3 本机发送过程
5.3.1 网络层路由
发送数据进入协议栈到达网络层的时候,网络层入口函数是ip_queue_xmit。在网络层里会进行路由选择,路由选择完毕,再设置一些IP头,进行一些netfilter的过滤,将包交给邻居子系统。
对于本机网络lO来说,特殊之处在于在local路由表中就能找到路由项,对应的设备都将使用loopback网卡,也就是常说的lo设备。
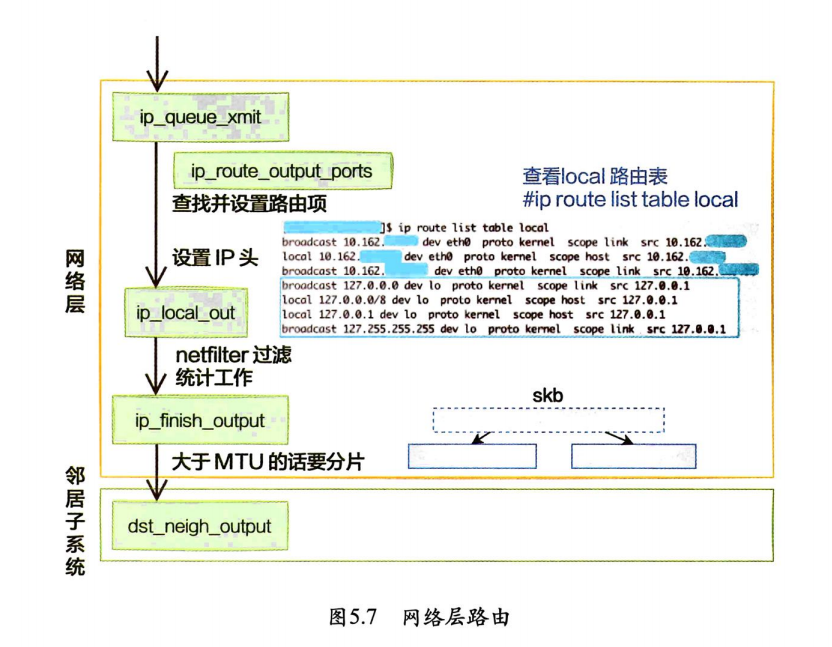
在fib_lookup中将会对local和main两个路由表展开查询,并且先查询local后查询main。在Linux上使用ip命令可以查看到这两个路由表,这里只看local路由表(因为本机网络IO查询到这个表就终止了)。
ip route list table local
#广播地址 127.0.0.0 ,流量通过回环接口 ,路由由内核自动添加,路由作用域为链路层(仅限本地网络),源 IP 地址为 127.0.0.1(回环地址)
broadcast 127.0.0.0 dev lo proto kernel scope link src 127.0.0.1
# 目标地址是整个 127.0.0.0/8网段, scope:路由作用域为主机本地(仅限本机)
local 127.0.0.0/8 dev lo proto kernel scope host src 127.0.0.1
local 127.0.0.1 dev lo proto kernel scope host src 127.0.0.1
broadcast 127.255.255.255 dev lo proto kernel scope link src 127.0.0.1
#目标地址是 172.17.0.0(Docker 默认网络的子网地址)
broadcast 172.17.0.0 dev docker0 proto kernel scope link src 172.17.0.1
local 172.17.0.1 dev docker0 proto kernel scope host src 172.17.0.1
broadcast 172.17.255.255 dev docker0 proto kernel scope link src 172.17.0.1
broadcast 192.168.0.0 dev eth0 proto kernel scope link src 192.168.1.61
local 192.168.1.61 dev eth0 proto kernel scope host src 192.168.1.61
broadcast 192.168.1.255 dev eth0 proto kernel scope link src 192.168.1.61
💡 对于目的是127.0.0.1的路由在local路由表中就能够找到。
对于本机的网络请求,设备将全部使用net->loopback_dev,也就是lo虚拟网卡。接下来的网络层仍然和跨机网络IO一样,最终会经过ip_finish_output,进入邻居子系统的入口函数dstneigh_output。
本机网络IO需要进行IP分片吗?因为和正常的网络层处理过程一样,会经过ip_finish_output函数,在这个函数中,如果skb大于MTU,仍然会进行分片。只不过lo虚拟网卡的MTU比Ethernet要大很多。通过ifconfig命令就可以查到,物理网卡MTU一般为1500,而lo虚拟接口能有65535个。
5.3.2 本机IP路由
本机IP与127.0.0.1都设置为了RIN_LOCAL。性能没有任何差异。
5.3.3 网络设备子系统
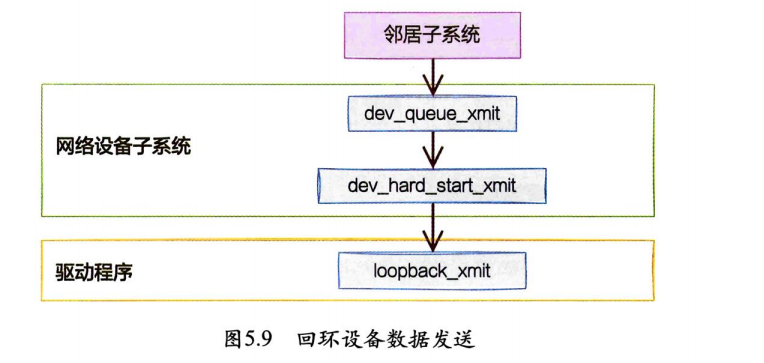
网络设备子系统的入口函数是dev_queue_xmit。对于真的有队列的物理设备,该函数进行了一系列复杂的排队等处理后,才调用dev_hard_startxmit,从这个函数再进入驱动程序来发送。在这个过程中,甚至还有可能触发软中断进行发送。
但是对于启动状态的回环设备(q->enqueue判断为false)来说,就简单多了。没有队列的问题,直接进入dev_hard_startxmit。接着进入回环设备的“驱动”里发送回调函数loopback_xmit,将skb“发送”出去。
5.3.4 “驱动”程序
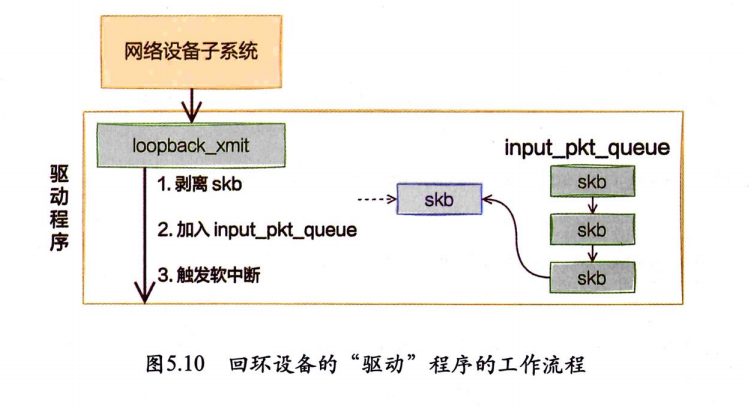
注意,在本机网络IO发送的过程中,传输层下面的skb就不需要释放了,直接给接收方传过去就行,总算是省了一点点开销。不过可惜传输层的skb同样节约不了,还是要频繁地申请和释放。
5.4 本机接收过程
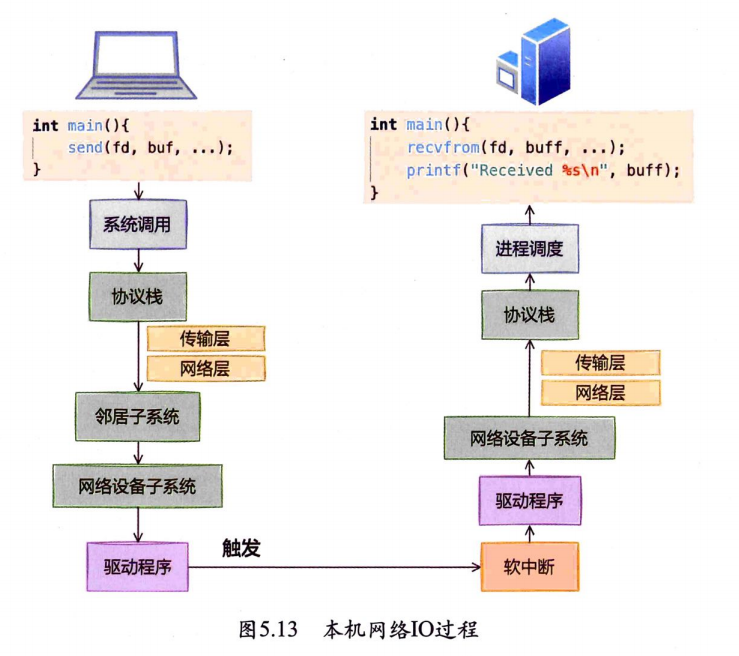
在跨机的网络包的接收过程中,需要经过硬中断,然后才能触发软中断。而在本机的网络IO过程中,由于并不真的过网卡,所以网卡的发送过程、硬中断就都省去了,直接从软中断开始。
5.5 本章总结
➥ 127.0.0.1本机网络10需要经过网卡吗?
不需要
➥ 数据包在内核中是什么走向,和外网发送相比流程上有什么差别?
总的来说,本机网络O和跨机网络口比较起来,确实是节约了驱动上的一些开销。发送数据不需要进RingBuffer的驱动队列,直接把skb传给接收协议栈(经过软中断)。但是在内核其他组件上,可是一点儿都没少,系统调用、协议栈(传输层、网络层等)、设备子系统整个走了一遍。连“驱动”程序都走了(虽然对于回环设备来说只是一个纯软件的虚拟出来的东西)。所以即使是本机网络口,切忌误以为没啥开销就滥用。
➥ 访问本机服务时,使用127.0.0.1能比使用本机IP(例如192.168.X.X)更快吗?
没有差别。
第6章 深度理解TCP连接建立过程
6.1 相关实际问题
➥ 为什么服务端程序都需要先listen一下?
➥ 半连接队列和全连接队列长度如何确定?
➥ “Cannot assign requested address”这个报错你知道是怎么回事吗?该如何解决?
➥ 一个客户端端口可以同时用在两条连接上吗
➥ 服务端半/全连接队列满了会怎么样?
➥ 新连接的socket内核对象是什么时候建立的?
➥ 建立一条TCP连接需要消耗多长时间?
➥ 把服务器部署在北京,给纽约的用户访问可行吗?
➥ 服务器负载很正常,但是CPU被打到底了是怎么回事?
6.2 深人理解listen
6.2.1 listen系统调用
根据用户传入的文件描述符来查找对应的socket内核对象。再接着获取了系统里的net.core.somaxconn内核参数的值,和用户传入的backlog比较后取一个最小值传入下一步。 所以,虽然listen允许我们传入backlog(该值和半连接队列、全连接队列都有关系),但是如果用户传入的值比net.core.somaxconn还大的话是不会起作用的。
接着通过调用sock->ops->listen进入协议栈的listen函数。
6.2.2 协议栈listen
💡如果在线上遇到了全连接队列溢出的问题,想加大该队列长度,那么可能需要同时考虑执行
listen函数时传入的backlog和net.core.somaxconn。
6.2.3 接收队列定义
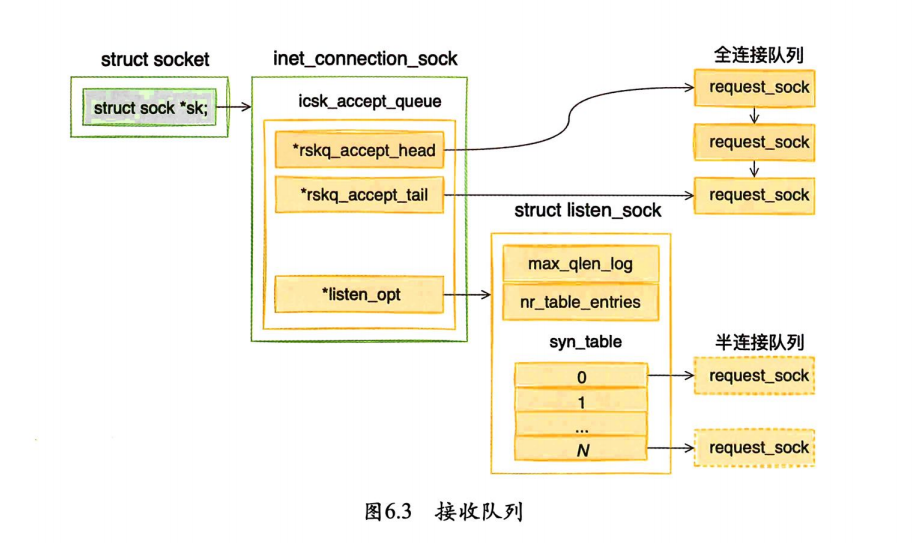
对于全连接队列来说,在它上面不需要进行复杂的查找工作,accept处理的时候只是先进先出地接受就好了。所以全连接队列通过rskq_accept_head和rskq_accept_tail以链表的形式来管理。
和半连接队列相关的数据对象是listen_opt,它是listen_sock类型的。
因为服务端需要在第三次握手时快速地查找出来第一次握手时留存的request_sock对象,所以其实是用了一个哈希表来管理,就是struct request_sock *syn_table[0]。max_qlen_log和nr_table_entries都和半连接队列的长度有关。
6.2.4 接收队列申请和初始化
半连接队列上每个元素分配的是一个指针大小
( sizeof (struct request_sock *) )。这其实是一个哈希表。真正的半连接用的request_sock对象是在握手过程中分配的,计算完哈希值后挂到这个哈希表上。
6.2.5 半连接队列长度计算
半连接队列长度的计算归纳成了一句话:半连接队列的长度是
min(backlog, somaxconn,tcp_max_syn_backlog)+1再上取整到2的N次幂,但最小不能小于16。线上遇到了半连接队列溢出的问题,想加大该队列长度,那么就需要同时考虑
somaxconn、backlog和tcp_max_syn_backlog三个内核参数。
6.2.6 listen过程小结
listen最主要的工作就是申请和初始化接收队列,包括全连接队列和半连接队列。其中全连接队列是一个链表,而半连接队列由于需要快速地查找,所以使用的是一个哈希表(其实半连接队列更准确的叫法应该叫半连接哈希表)。
全/半两个队列是三次握手中很重要的两个数据结构,有了它们服务端才能正常响应来自客户端的三次握手。所以服务端都需要调用listen才行。
- 对于全连接队列来说,其最大长度是
listen时传入的backlog和net.core.somaxconn之间较小的那个值。 - 半连接队列的长度,其最大长度是
min(backlog,somaxconn,tcp_max_syn_backlog)+1再上取整到2的N次幂,但最小不能小于16。如果需要加大半连接队列长度,那么需要一并考虑backlog、somaxconn和tcp_max_syn_backlog这三个参数。
6.3 深人理解connect
6.3.1 connect 调用链展开
刚创建完毕的socket的状态就是SS_UNCONNECTED,在这里将把socket状态设置为TCP_SYN_SENT。
6.3.2 选择可用端口
1️⃣根据要连接的目的IP和端口等信息生成一个随机数。
2️⃣读取管理员配置的可用的端口范围(内核参数:net.ipv4.ip_local_port_range)
该参数的默认值是32768 —— 61000,意味着端口总可用的数量是61000-32768=28232个。如果觉得这个数字不够用,那就修改
net.ipv4.ip_local_port_range内核参数。 如果不希望某些端 那么把它们写到ip_local_reserved_ports这个内核参数中就行了。
3️⃣ 从前面那个随机数开始,把整个可用端口范围遍历一遍。直到找到可用的端口后停止。
整个系统中会维护一个所有使用过的端口的哈希表,它就是hinfo->bhash。接下来的代码就会在这里查找端口。如果在哈希表中没有找到,那么说明这个端口是可用的。至此端口就算是找到了。这个时候通过net_bind_bucket_create申请一个inet_bind_bucket来记录端口已经使用了,并用哈希表的形式都管理了起来。
遍历完所有端口都没找到合适的,就返回-EADDRNOTAVAIL,在用户程序上看到的就是Cannot assign requested address这个错误。应该想到去查一下net.ipv4.ip_local_port_range中设置的可用端口的范围是不是太小了。
6.3.3 端口被使用过怎么办
port在bhash中如果已经存在,就表示有其他的连接使用过该端口了。请注意,如果check_established返回o,该端口仍然可以接着使用。check_established作用就是检测现有的TCP连接中是否四元组和要建立的连接四元素完全一致。如果不完全一致,那么该端口仍然可用!!!
如果匹配,就是四元组完全一致的连接,所以这个端口不可用。也返回-EADDRNOTAVAIL
如果不匹配,哪怕四元组中有一个元素不一样,例如服务端的端口号不一样,那么就返回0,表示该端口仍然可用于建立新连接。
所以一台客户端机最大能建立的连接数并不是65535。只要服务端足够多,单机发出百万条连接没有任何问题。
6.3.4 发起syn请求
tcp_connect一口气做了这么几件事:
- 申请一个
skb,并将其设置为SYN包。 - 添加到发送队列上。
- 调用
tcp_transmit_skb将该包发出。 - 启动一个重传定时器,超时会重发。
该定时器的作用是等到一定时间后收不到服务端的反馈的时候来开启重传。首次超时时间是在TCP_TIMEOUT_INIT宏中定义的,该值在LinuX3.10版本中是1秒,在一些老版本中是3秒。
6.3.5 connect小结
客户端在执行connect函数的时候,把本地socket状态设置成了TCP_SYN_SENT,选了一个可用的端口,接着发出SYN握手请求并启动重传定时器。
选择端口都是从ip_local_port_range范围中的某一个随机位置开始循环的。如果可用端口很充足,则能快一些找到可用端口,那循环很快就能退出。假设实际中ip_local_port_range中的端口快被用光了,这时候内核就大概率要把循环多执行很
多轮才能找到可用端口,这会导致connect系统调用的CPU开销上涨。
如果在connect之前使用了bind,将会使得connect系统调用时的端口选择方式无效。转而使用bind时确定的端口。调用bind时如果传入了端口号,会尝试首先使用该端口号,如果传入了0,也会自动选择一个。但默认情况下一个端口只会被使用一次。所以对于客户端角色的socket,不建议使用bind!
6.4 完整TCP连接建立过程
6.4.1 客户端connect
客户端在执行connect函数的时候,把本地socket状态设置成了TCP_SYN_SENT,选了一个可用的端口,接着发出SYN握手请求并启动重传定时器。
6.4.2 服务端响应SYN
在tcp_v4_do_rcv中判断当前socket是listen状态后,首先会到tcp_v4_hnd_req查看半连接队列。服务端第一次响应SYN的时候,半连接队列里必然空空如也,所以相当于什么也没干就返回了。
在tcp_rcv_state_process里根据不同的socket状态进行不同的处理。
LISTEN状态,服务端响应SYN的主要处理逻辑都在这个tcp_v4_conn_request里。
在这里首先判断半连接队列是否满了,如果满了进入tcp_syn_flood_action去判断是否开启了tcp_syncookies内核参数。如果队列满,且未开启tcp_syncookies,那么该握手包将被直接丢弃!
接着还要判断全连接队列是否满。因为全连接队列满也会导致握手异常,那干脆就在第一次握手的时候也判断了。如果全连接队列满了,且young_ack数量大于1的话,那么同样也是直接丢弃。
young_ack是半连接队列里保持着的一个计数器。记录的是刚有SYN到达,没有被SYN_ACK重传定时器重传过SYN_ACK,同时也没有完成过三次握手的sock数量。
最后把当前握手信息添加到半连接队列,并开启计时器。计时器的作用是,如果某个时间内还收不到客户端的第三次握手,服务端会重传synack包。
总结一下,服务端响应ack的主要工作是判断接收队列是否满了,满的话可能会丢弃该请求,否则发出synack。申请request_sock添加到半连接队列中,同时启动定时器。
6.4.3 客户端响应SYNACK
客户端收到服务端发来的synack包的时候,也会进入tcp_rcv_state_process函数。不过由于自身socket的状态是TCP_SYN_SENT,所以会进入另一个不同的分支。
客户端响应来自服务端的synack时清除了connect时设置的重传定时器,把当前socket状态设置为ESTABLISHED,开启保活计时器后发出第三次握手的ack确认。
6.4.4 服务端响应ACK
服务端响应第三次握手的ack时会同样进入tcp_v4_do_rcv。 不过由于这已经是第三次握手了,半连接队列里会存在第一次握手时留下的半连接信息,所以tcp_v4hnd_req的执行逻辑会不太一样。
inet_csk_search_req负责在半连接队列里进行查找,找到以后返回一个半连接request_sock对象,然后进入tcp_check_req。
➥ 创建子socket
注意,在第三次握手这里又继续判断一次全连接队列是否满了,如果满了修改一下计数器就丢弃了。如果队列不满,那么就申请创建新的sock对象。
➥ 删除半连接队列
把连接请求块从半连接队列中删除。
➥ 添加全连接队列
将握手成功的request_sock对象插到全连接队列链表的尾部。
➥ 设置连接为ESTABLISHED
第三次握手的时候进入tcp_rcv_state_process的路径有点不太一样,是通过子socket进来的。这时的子socket的状态是TCP_SYN_RECV。
6.4.5 服务端accept
reqsk_queue_remove这个操作很简单,就是从全连接队列的链表里获取一个头元素返回就行了。
6.4.6 连接建立过程总结
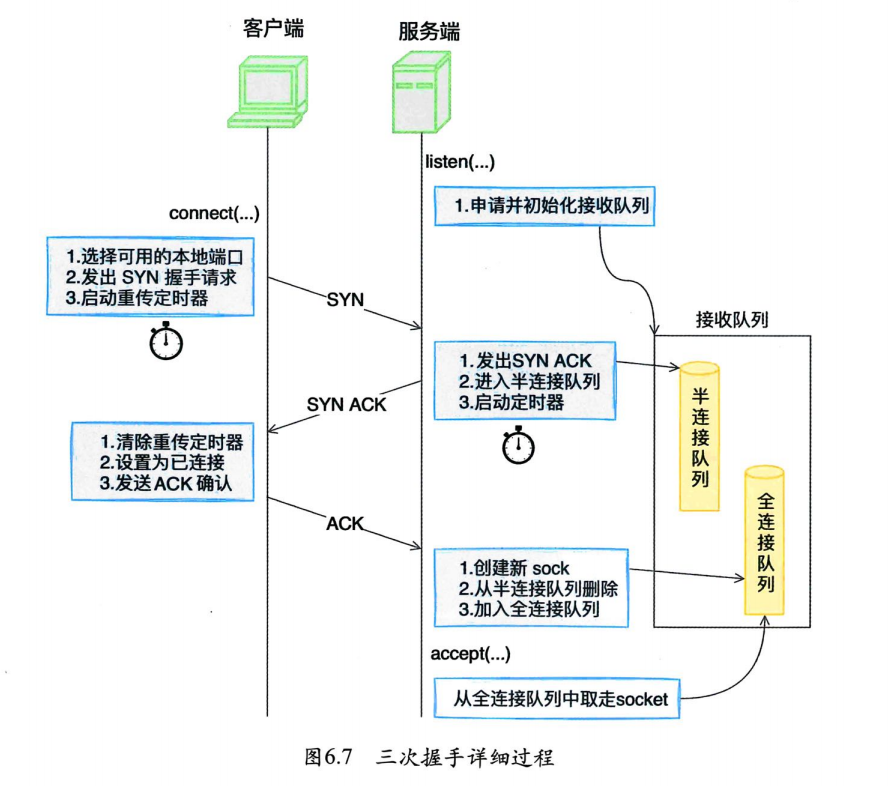
6.5 异常TCP连接建立情况
正常情况下一次TCP连接耗时也就大约是一个RTT多一点儿。但事情不一定总是这么美好,总会有意外发生。在某些情况下,可能会导致连接耗时上涨、CPU处理开销增加、甚至超时失败。
6.5.1 connect系统调用耗时失控
客户端在发起connect系统调用的时候,主要工作就是端口选择。在选择的过程中,有个大循环,从ip_local_port_range的一个随机位置开始把这个范围遍历一遍,找到可用端口则退出循环。如果端口很充足,那么循环只需要执行少数几次就可以退出。但假设端口消耗掉很多已经不充足,或者干脆就没有可用的了,那么这个循环就得执行很多遍。
在每次的循环内部需要等待锁以及在哈希表中执行多次的搜索。注意这里的锁是自旋锁,是一种非阻塞的锁,如果资源被占用,进程并不会被挂起,而是会占用CPU去不断尝试获取锁。
但假设端口范围ip_local_port_range配置的是10000~30000,而且已经用尽了。那么每次当发起连接的时候都需要把循环执行20000遍才退出。这时会涉及大量的哈希查找以及自旋锁等待开销,系统态CPU将会出现大幅度上涨。
strace -cp 31066
6.5.2 第一次握手丢包
如果半连接队列满了,而且ipv4.tcp_syncookies参数设置为0,那么来自客户端的握手包将goto drop,意思就是直接丢弃!
SYN Flood攻击就是通过耗光服务端上的半连接队列来使得正常的用户连接请求无法被响应。不过在现在的Linux内核里只要打开tcp_syncookies,半连接队列满了仍然可以保证正常握手的进行。
假如全连接队列满的情况下,且同时有young_ack,那么内核同样直接丢掉该SYN握手包。
tcp_write_timeout的判断逻辑其实也有点复杂。对于SYN握手包主要的判断依据是net.ipv4.tcp_synretries,但其实并不是简单对比次数,而是转化成了时间进行对比。所以如果在线上看到实际重传次数和对应内核参数不一致也不用太奇怪。
6.5.3 第三次握手丢包
客户端在收到服务器的synack响应的时候,就认为连接建立成功了,然后会将自己的连接状态设置为ESTABLISHED,发出第三次握手请求。但服务端在第三次握手的时候,还有可能有意外发生。
第三次握手时,如果服务器全连接队列满了,来自客户端的ack握手包又被直接丢弃。第三次握手失败并不是客户端重试,而是由服务端来重发synack。
在实践中,客户端往往是以为连接建立成功就会开始发送数据,其实这时候连接还没有真的建立起来。它发出去的数据,包括重试将全部被服务端无视,直到连接真正建立成功后才行
6.5.4 握手异常总结
正因为握手重试对服务端影响很大,所以能深刻理解三次握手中的这些异常情况很有必要。如果出现了丢包的问题,该如何应对。
-
打开
syncookie。可以通过打开tcp_syncookies来防止过多的请求打满半连接队列。 -
加大连接队列长度
全连接队列在修改完后可以通过ss命令中输出的Send-Q来确认最终生效长度。
ss -nlt # Recv-Q告诉我们当前该进程的全连接队列使用情况。如果Recv-Q已经逼 近了Send-Q,那么可能不需要等到丢包也应该准备加大全连接队列了。 -
尽快调用
accept -
尽早拒绝。将Redis、MySQL等服务器的内核参数
tcp_abort_on_overflow设置为1。如果队列满了,直
接发reset指令给客户端。告诉后端进程/线程不要“痴情”地傻等。这时候客户端会收到错误“connection reset by peer”。 -
尽量减少TCP连接的次数:思考是否可以用长连接代替短连接,减少过于频繁的三次握手。
6.6 如何查看是否有连接队列溢出发生
6.6.1 全连接队列溢出判断
全连接队列溢出都会记录到ListenOverflows这个MIB(Management Information Base,管理信息库),对应SNMP统计信息中的ListenDrops这一项。
服务端在响应客户端的SYN握手包的时候,有可能会在tcp_v4_conn_request调用这里发生全连接队列溢出而丢包。
全连接队列满了以后调用NET_INC_STATS_BH增加了LINUX_MIB_LISTENOVERFLOWS和LINUX_MIB_LISTENDROPS这两个MIB。
服务端在响应第三次握手的时候,会再次判断全连接队列是否溢出。如果溢出,一样会增加这两个MIB。
在执行netstat -s 的时候,该工具会读取SNMP统计信息并展现出来。
watch 'netstat -s| grep overflowed'198 times the list enqueue of a socket overflowed6.6.2 半连接队列溢出判断
半连接队列,溢出时更新的是LINUX_MIB_LISTENDROPS这个MIB,对应到SNMP就是ListenDrops这个统计项。
但是问题在于,不是只在半连接队列发生溢出的时候会增加该值。所以根据netstat -s看半连接队列是否溢出是不靠谱的!
对于如何查看半连接队列溢出丢包这个问题,建议是不要纠结怎么看是否丢包了。直接看服务器上的tcp_syncookies是不是1就行。 如果该值是1,那么下面代码中want_cookie就返回真,是根本不会发生半连接溢出丢包的。
第7章 一条TCP连接消耗多大内存
7.1 相关实际问题
➥ 内核是如何管理内存的?
➥ 如何查看内核使用的内存信息?
➥ 服务器上一条ESTABLISH状态的空连接需要消耗多少内存?
➥ 我的机器上出现了3万多个TIME_WAIT,内存开销会不会很大?
7.2 Linux内核如何管理内存
内核针使用了一种叫作SLAB/SLUB的内存管理机制。这种管理机制通过四个步骤把物理内存条管理起来,供内核申请和分配内核对象,
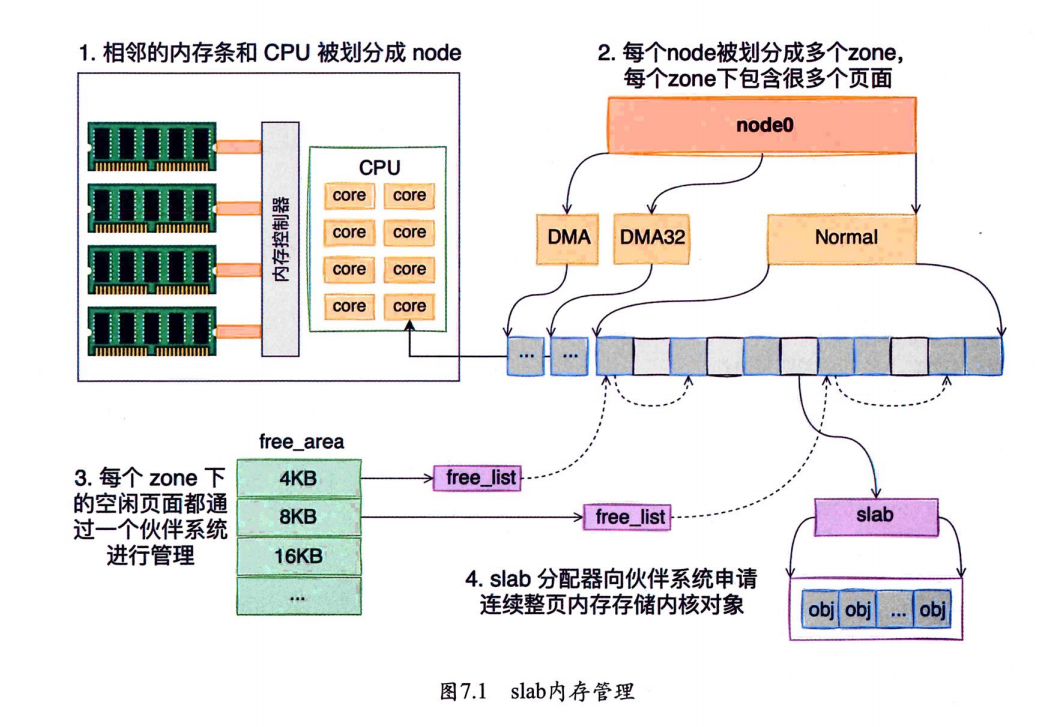
7.2.1 node划分
在现代的服务器上,内存和CPU都是所谓的NUMA架构
CPU往往不止一颗。通过dmidecode命令查看主板上插着的CPU的详细信息。
内存也不只一条。dmidecode同样可以查看到服务器上插着的所有内存条,也可以看到它是和哪个CPU直接连接的。
dmidecode [root@localhost rx-0]# dmidecode
# dmidecode 3.2
Getting SMBIOS data from sysfs.
SMBIOS 2.8 present.
10 structures occupying 534 bytes.
Table at 0x7FBCB000.Handle 0x0100, DMI type 1, 27 bytes
System Information......Handle 0x0300, DMI type 3, 21 bytes
Chassis Information......Handle 0x0400, DMI type 4, 42 bytes
Processor InformationSocket Designation: CPU 0 #处理器插槽标识(这里是第一个 CPU 插槽)Type: Central Processor # 处理器类型(中央处理器)。Family: Other # 处理器家族(Other表示非标准分类,可能是虚拟化环境或特殊硬件)。Manufacturer: Red Hat # 制造商(虚拟化环境中通常显示为 Red Hat或 KVM,而非真实硬件厂商)。ID: D3 06 00 00 FD FB 8B 07 # 处理器唯一标识符(虚拟化环境中为模拟值)。Version: RHEL-7.6.0 PC (Q35 + ICH9, 2009) # 处理器版本(实际是虚拟化平台的描述,如 QEMU/KVM 的模拟环境)Voltage: UnknownExternal Clock: UnknownMax Speed: 2000 MHz # 最大时钟频率(2 GHz)。Current Speed: 2000 MHz # 当前运行频率Status: Populated, Enabled # 处理器状态(已安装且启用)。Upgrade: OtherL1 Cache Handle: Not ProvidedL2 Cache Handle: Not ProvidedL3 Cache Handle: Not ProvidedSerial Number: Not SpecifiedAsset Tag: Not SpecifiedPart Number: Not SpecifiedCore Count: 2 # 物理核心数(2 核)。Core Enabled: 2 # 启用的物理核心数(全部启用)Thread Count: 1 # 线程数(1 线程,可能是虚拟化环境的限制或单线程模拟)。Characteristics: None
# DMI type 16/17 虚拟机通常配置固定大小的内存(如 4 GB),与物理机不同。
Handle 0x1000, DMI type 16, 23 bytes
Physical Memory Array......Handle 0x1100, DMI type 17, 40 bytes
Memory Device......Handle 0x1300, DMI type 19, 31 bytes
Memory Array Mapped Address......Handle 0x1301, DMI type 19, 31 bytes
Memory Array Mapped Address......Handle 0x2000, DMI type 32, 11 bytes
System Boot InformationStatus: No errors detected
# BIOS 信息(DMI type 0):
Handle 0x0000, DMI type 0, 26 bytes
BIOS Information......
Handle 0xFEFF, DMI type 127, 4 bytes
End Of Table每一个CPU以及和它直连的内存条组成了一个**node(节点)**。可以使用numactl命令看到每个node的情况。
numactl --hardware7.2.2 zone划分
每个node又会划分成若干的**zone(区域)**,zone表示内存中的一块范围。
ZONE_DMA:地址段最低的一块内存区域,供IO设备DMA访问。ZONE_DMA32:该zone用于支持32位地址总线的DMA设备,只在64位系统里才有效。ZONE_NORMAL:在X86-64架构下,DMA和DMA32之外的内存全部在NORMAL的zone里管理。
在每个zone下,都包含了许许多多个**Page(页面)**,在Linux下一个页面的大小一般是4KB。可以使用zoneinfo命令查看到机器上zone的划分,也可以看到每个zone下所管理的页面有多少个。
cat /proc/zoneinfoNode 0, zone DMA......Node 0, zone DMA32........
Node 0, zone Normalpages free 172469 # 当前空闲页数量(单位:页,默认 4KB/页,约 670MB 空闲)。min 8766 # 内存回收的 最低水位线low 10957 # 内存回收的 低水位线(低于此值会触发后台 kswapd 回收)。high 13149scanned 0spanned 524288 # 该 zone 的总页数(524288 * 4KB ≈ 2GB)。present 524288 # 实际可用的页数(与 spanned相同,表示无硬件保留区域)。managed 503538 #由伙伴系统(Buddy System)管理的页数(略小于 present,因部分页保留)nr_free_pages 172469 #当前空闲页数(与 pages free一致)。nr_free_pages(172469) 远大于 min/low/high,说明 无内存压力。nr_alloc_batch 2150nr_inactive_anon 31599nr_active_anon 16919nr_inactive_file 201083nr_active_file 41749nr_unevictable 0nr_mlock 0nr_anon_pages 34546nr_mapped 6545nr_file_pages 256904nr_dirty 0nr_writeback 0nr_slab_reclaimable 21019nr_slab_unreclaimable 6912nr_page_table_pages 1711nr_kernel_stack 164nr_unstable 0nr_bounce 0nr_vmscan_write 5730010nr_vmscan_immediate_reclaim 31491 # 较低,表明 未频繁触发紧急回收nr_writeback_temp 0nr_isolated_anon 0nr_isolated_file 0nr_shmem 12399nr_dirtied 1335498205nr_written 1651089494numa_hit 25015273105numa_miss 0numa_foreign 0numa_interleave 15330numa_local 25015273105numa_other 0workingset_refault 298164503workingset_activate 124675779workingset_nodereclaim 324109nr_anon_transparent_hugepages 1nr_free_cma 0protection: (0, 0, 0, 0)pagesetscpu: 0count: 177high: 186batch: 31vm stats threshold: 20cpu: 1count: 133high: 186batch: 31vm stats threshold: 20all_unreclaimable: 0start_pfn: 1048576inactive_ratio: 37.2.3 基于伙伴系统管理空闲页面
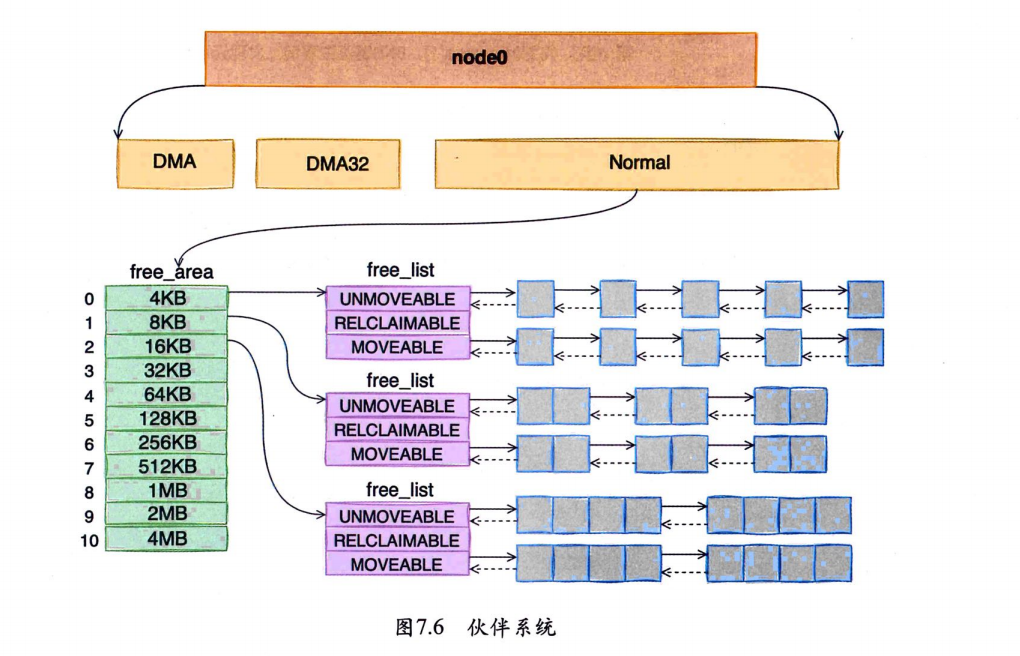
每个zone下面都有如此之多的页面,Linux使用伙伴系统对这些页面进行高效的管理。在内核中,表示zone的数据结构是struct zone。其下面的一个数组free_area管理了绝大部分可用的空闲页面。这个数组就是伙伴系统实现的重要数据结构。
free_area是一个包含11个元素的数组,每一个数组分别代表的是空闲可分配连续4KB、8KB、16KB…4MB内存链表。 通过cat /proc/pagetypeinfo命令可以看到当前系统中伙伴系统各个尺寸的可用连续内存块数量
伙伴系统中的伙伴指的是两个内存块,大小相同,地址连续,同属于一个大块区域。
cat /proc/pagetypeinfoPage block order: 9 # 9表示一个内存块(Page Block)由 2^9 =512个连续物理页(Page)组成,即 512页 × 4KB/页 = 2MB的连续内存块。
Pages per block: 512 #进一步确认块大小为 512 页(2MB),这是内核管理内存碎片化的基本单位。# Migrate Types(迁移类型)
# Unmovable 不可移动的页(如内核数据结构、DMA 内存)。
# Reclaimable 可回收的页(如文件缓存、dentry 缓存)。
# Movable 可移动的页(如匿名内存页、进程堆/栈)。
# Reserve 保留页(通常为 0)。
# CMA 连续内存分配器保留的页(用于大块连续内存请求)。
# Isolate 隔离页(通常为 0)。# 0 - 10 表示 内存块(Page Block)的阶数(Order)范围,用于描述连续物理页的数量
Free pages count per migrate type at order 0 1 2 3 4 5 6 7 8 9 10
Node 0, zone DMA, type Unmovable 1 0 0 0 0 1 1 0 1 0 0
Node 0, zone DMA, type Reclaimable 2 0 1 2 2 0 1 1 1 1 0
Node 0, zone DMA, type Movable 1 0 3 1 0 1 0 1 1 0 2
Node 0, zone DMA, type Reserve 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA, type CMA 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA, type Isolate 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA32, type Unmovable 202 276 170 76 25 0 0 0 0 0 0
Node 0, zone DMA32, type Reclaimable 906 678 51 6 1 1 0 0 0 0 0
Node 0, zone DMA32, type Movable 19086 19659 17705 4073 554 10 0 0 0 0 0
Node 0, zone DMA32, type Reserve 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA32, type CMA 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA32, type Isolate 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone Normal, type Unmovable 97 97 148 14 0 0 0 0 0 0 0
Node 0, zone Normal, type Reclaimable 994 569 52 14 1 0 0 0 0 0 0
Node 0, zone Normal, type Movable 20378 20172 18090 3482 496 2 0 0 0 0 0
Node 0, zone Normal, type Reserve 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone Normal, type CMA 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone Normal, type Isolate 0 0 0 0 0 0 0 0 0 0 0 Number of blocks type Unmovable Reclaimable Movable Reserve CMA Isolate
Node 0, zone DMA 1 2 5 0 0 0
Node 0, zone DMA32 21 32 963 0 0 0
Node 0, zone Normal 34 37 953 0 0 0 为什么需要
Order?内核通过
Order管理内存碎片化:
低阶(Order 0-3):
小块连续内存(如 1页、2页、4页、8页),用于分配小对象(如进程栈、小文件缓存)。
高阶(Order 4-10):
大块连续内存(如 16页、32页、…、1024页),用于分配大对象(如大页、DMA 缓冲区、数据库大内存请求)。
👉一个8KB内存分配过程:
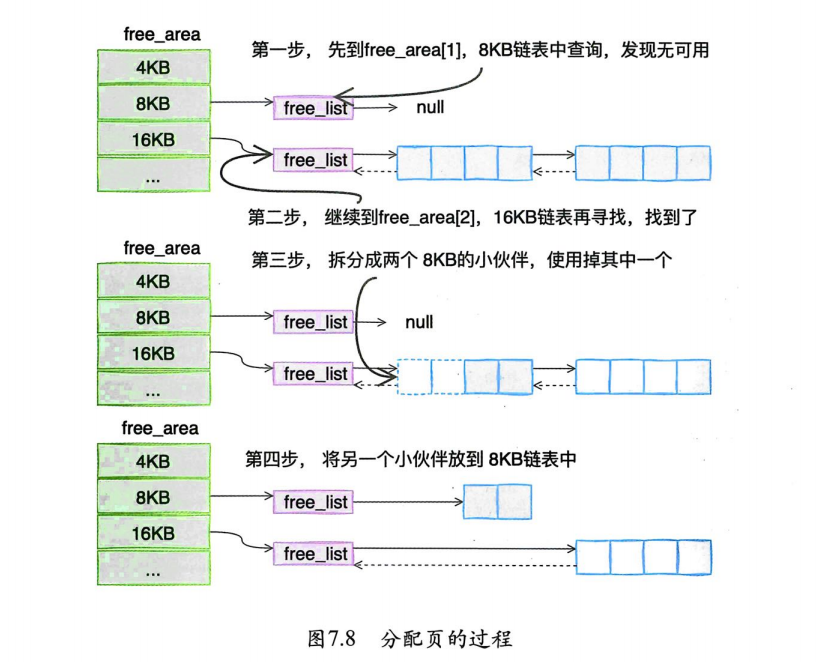
基于伙伴系统的内存分配中,有可能需要将大块内存拆分成两个小伙伴。在释放中,可能会将两个小伙伴合并再次组成更大块的连续内存。
7.2.4 slab分配器
内存分配都是以页面(4KB)为单位的。但有的对象只有几百、甚至几十字节。如果都直接分配一个4KB的页面来存储的话也太铺张了,所以伙伴系统并不能直接使用。
在伙伴系统之上,内核又给自己搞了一个专用的内存分配器,叫slab或slub。 这个分配器最大的特点就是,一个slab内只分配特定大小、甚至是特定的对象,这样当一个对象释放内存后,另一个同类对象可以直接使用这块内存。通过这种办法极大地降低了碎片发生的概率。
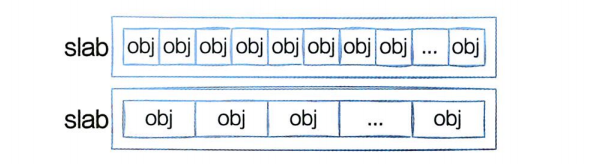
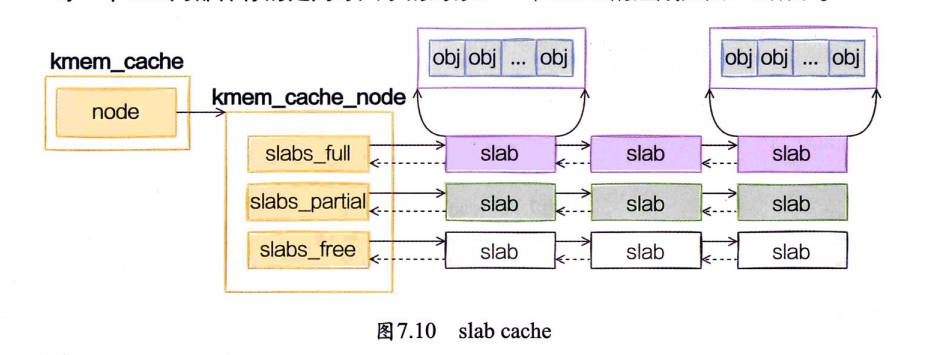
每个cache都有满、半满、空三个链表。每个链表节点都对应一个slab,一个slab由一个或者多个内存页组成。
每一个slab内都保存的是同等大小的对象。
当cache中内存不够的时候,会调用基于伙伴系统的分配器(__alloc_pages函数)请求整页连续内存的分配。
内核中会有很多个kmem_cache存在,它们是在Linux初始化,或者是运行的过程中分配出来的。它们有的是专用的,有的是通用的。
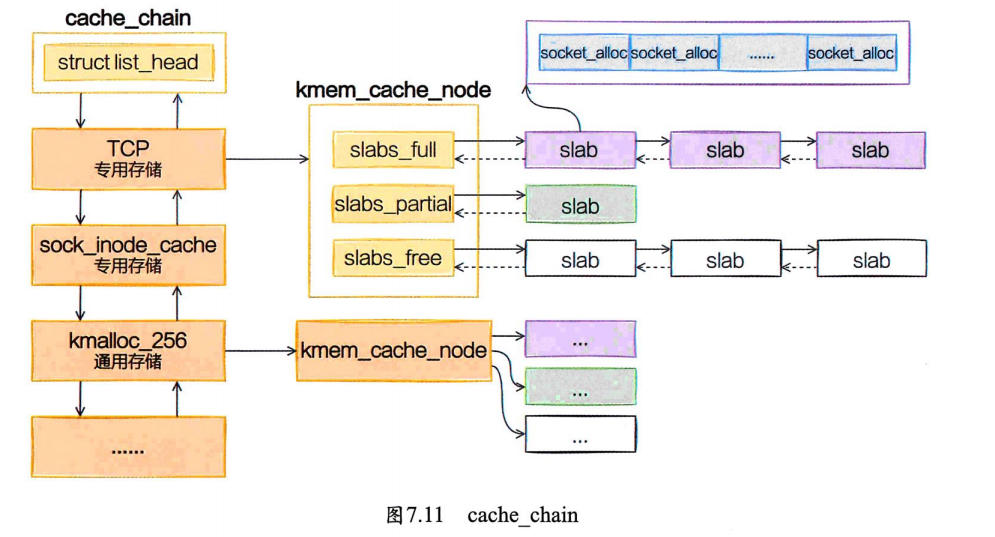
socket_alloc内核对象都存在TCP的专用kmem_cache中。通过查看/proc/slabinfo可以查看所有的kmem_cache。
cat /proc/slabinfo#按照占用内存从大往小进行排列
slabtop无论是/proc/slabinfo,还是slabtop命令的输出,里面都包含了每个cache中slab的如下两个关键信息:
objsize:每个对象的大小。objperslab:一个slab里存放的对象的数量。
/proc/slabinfo还多输出了一个pagesperslab。展示了一个slab占用的页面的数量,每个页面4KB,这样也就能算出每个slab占用的内存大小。
slab管理器组件提供了若干接口函数,方便自己使用。
kmem_cache_create:方便地创建一个基于slab的内核对象管理器。kmem_cache_alloc:快速为某个对象申请内存。kmem_cache_free:将对象占用的内存归还给slab分配器。
7.3 TCP连接相关内核对象
7.3.1 socket函数直接创建
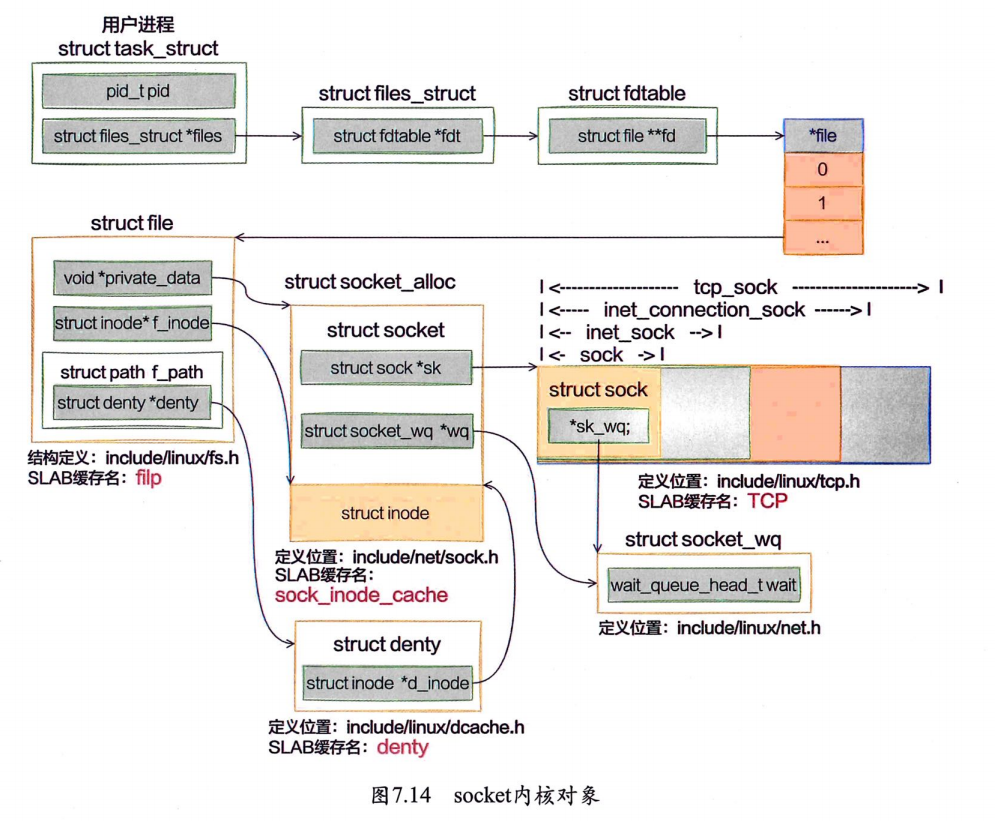
➥ sock_inode_cache申请(struct socket_alloc)
在sock_alloc函数中,申请了一个struct socket_alloc内核对象。socket_alloc内核对象将socket和inode信息关联了起来。
sock_inode_cache是专门用来存储struct socket_alloc的slab缓存
➥ TCP对象申请(struct tcp_sock)
将会到TCP这个slab缓存中申请一个struct sock内核对象出来
➥ dentry申请
➥ flip对象申请(struct file)
7.3.2 服务端socket创建
7.4 实测TCP内核对象开销
7.4.1 实验准备
7.4.2 实验开始
7.4.3 观察ESTABLISH状态开销
7.4.4 观察非ESTABLISH状态开销
7.4.5 收发缓存区简单测试
7.4.6 实验结果小结
7.5 本章总结
➥ 内核是如何管理内存的?
➥ 如何查看内核使用的内存信息?
/proc/slabinfo
➥ 服务器上一条ESTABLISH状态的空连接需要消耗多少内存?
struct socket_alloc,大小约为0.62KB,slab缓存名是sock_inode_cache。stuct tcp_sock,大小约为1.94KB,slab缓存名是tcp。struct dentry,大小约为0.19KB,slab缓存名是dentry。struct file,大小约为0.25KB,slab缓存名是flip。
这组内核对象的大小大约总共是3.3KB左右。粗算6000条ESTABLISH状态的空长连接在内存上的开销也就是6000×3.3KB,大约20MB
➥ 我的机器上出现了3万多个TIME_WAIT,内存开销会不会很大?
其实这种情况只能算是warning,而不是error!从内存的角度来考虑,一条TIME_WAIT状态的连接仅仅是0.4KB左右的内存而已。
想解决这个问题可以考虑使用tcp_max_tw_buckets来限制TIME_WAIT连接总数,或者打开tcp_tw_recycle、tcp_tw_reuse来快速回收端口。如果再彻底一些,也可以干脆直接用长连接代替频繁的短连接。