系统架构设计师-【2025年上半年案例题】-真题分享
第一题(必选题)
某科技公司开发了一个面向开发者的在线大模型训练平台系统,该平台主要面向具备一定编程基础的用户,支持基于 Python 的模型编写、训练和部署流程。系统旨在简化模型开发流程,用户无需了解底层计算硬件配置,平台将自动解析代码并智能匹配训练资源进行运行。
问题1
根据上述系统描述,依次写出每条需求对应的系统质量属性。(12 分)
1.用户提交模型训练任务时,系统应在 1 分钟内分配资源并开始任务运行(1);
2.数据库发生故障时,能够在 20 分钟内切换至备用数据库,保证平台继续运行(2);
3.服务器发生故障时,能够自动切换至备用服务器,保障系统业务连续(3);
4.系统出现故障时,平台能够继续正常运行并通知管理员,同时应提供相关的操作日志、系统日志、访问日志和调试日志等信息(4);
5.用户界面需自动适配不同设备的分辨率和屏幕比例(5);
6.提供常用快捷键操作,提升平台易用性(6);
7.系统支持切换界面语言,方便不同语言背景用户使用(7);
8.支持远程用户进行测试和操作,但需限定为注册用户(8);
9.系统应支持来自不同终端设备(如浏览器、命令行工具、移动设备等)和操作系统(如 Windows、Linux、macOS)的注册用户同时远程访问与操作平台,系统需能正确解析并响应各类客户端的指令,保证功能一致性与协同操作能力(9);
10.当系统功能需要调整时,应在 3 天内完成功能修改和部署上线(10);
11.系统需具备良好的故障恢复能力,在发生系统级故障时,15 分钟内需完成修复(11);
12.系统需具备良好的异常容错机制,部分模块出错不应影响平台整体运行(12)。
答案
(1)性能(2)可靠性(3)可靠性(4)可靠性(5)易用性(6)易用性(7)易用性(8)可测试性(9)互操作性(10)可修改性(11)可靠性(12)可靠性
问题2
根据题干描述,将下图空白处补充完整,并说明该平台为什么适合用解释器风格?(13 分)
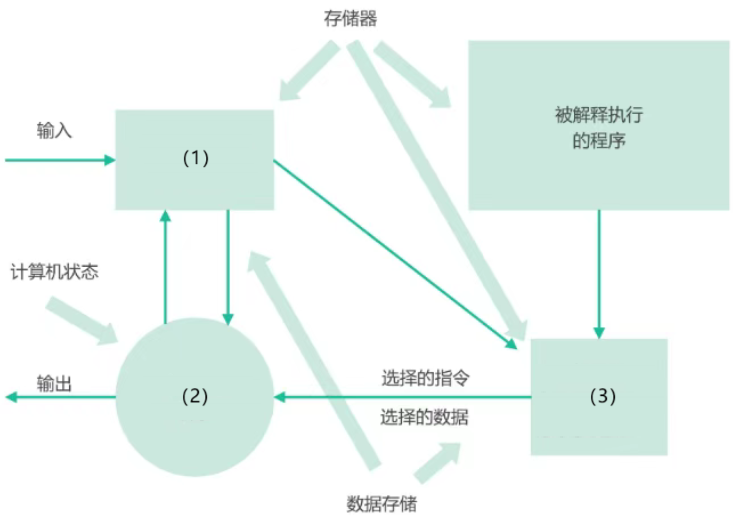
答案
(1)程序执行的当前状态(2)解释器引擎(3)解释器引擎的内部状态
第二题(选做题)
某研究团队基于医疗领域的大量文本与结构化数据,构建了一个面向医疗知识图谱的问答系统。该系统面向医学科研人员与临床医生,支持实体识别、关系抽取、知识检索与答案生成等功能。由于系统设计较为复杂,包含数据预处理、自然语言处理、知识图谱构建、后端服务、前端服务、机器学习与深度学习等多个模块,系统采用“自底向上”的方式构建总体系结构。该系统主要包括:爬取医疗相关数据并建立知识图谱、提供实体识别和关系抽取服务、实现多种类型问答接口(如实体知识问答、药物关系问答、医学关系查询等),并通过后端模块进行统一处理,生成答案。
问题1
根据题干描述的内容,将下列选项填入图中合适位置(9 分)
(a)知识检索(b)模板翻译(c)数据清洗(d)命名实体识别(e)知识表示(f)模板匹配(g)问题分类(h)知识抽取 (i)数据收集

答案
(1)g(2)d(3)b(4)f(5)a(6)h(7)i(8)e(9)c
问题2
在构建医药知识图谱系统中,选择哪类数据库更适合存储知识图谱数据?请明确说明数据库类型及推荐技术实现,并结合医药数据特性说明理由。(7分)
答案
推荐使用图数据库(Graph Database),如 Neo4j、Amazon Neptune 等,来存储医药知识图谱数据。因为医药领域的知识结构普遍基于三元组,图数据库能以节点和边的形式自然建模实体及其复杂关系,尤其适合表示药物相互作用、疾病关联等语义网络。图数据库还支持高效的关系遍历、多跳查询和图算法分析,如最短路径、社区发现等,有助于深入挖掘潜在医学关联。此外,Neo4j 提供的 Cypher 查询语言便于灵活表达医学图谱中的复杂语义关系。
问题3
下图是 Scrapy 框架的核心结构图,其中挖空了三个关键组件,请根据图示结构,在图中标记的位置填入相应的模块名称,并请简要解释什么是“异步IO”。(9 分)
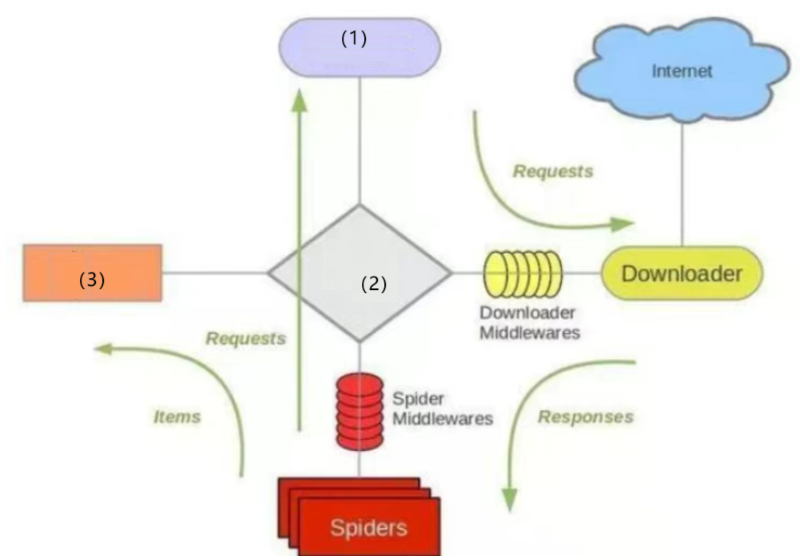
答案
(1) Scheduler(调度器)(2) Scrapy Engine(引擎)(3)Item Pipeline(项目管道)
在异步IO模式下,程序向操作系统发起I/O请求(如读文件、收网络数据)后,不会阻塞等待结果返回,而是立即返回并继续执行其他逻辑。当I/O操作完成后,操作系统会通过回调函数、事件通知或信号等方式通知程序,程序再去处理结果。
第三题(选做题)
某互联网企业开发并部署了一套高并发电商系统,系统中的商品信息、用户购物车、热销榜单等高频数据均存储在 Redis 中以提高访问效率。随着业务规模扩大,单实例 Redis 出现了性能瓶颈和单点故障风险。为提升系统的可用性、扩展性和数据容灾能力,技术团队决定采用 Redis 的主从复制架构,将写操作集中在主节点(Master),将读操作分散到多个从节点(Slave)中。同时,系统还需支持主从自动同步机制,确保在主库故障后可以快速切换至从库,保障业务连续性。
问题1
请根据 Redis 的主从架构原理和下图的同步流程,在图示中填入正确的关键步骤和指令。(10 分)
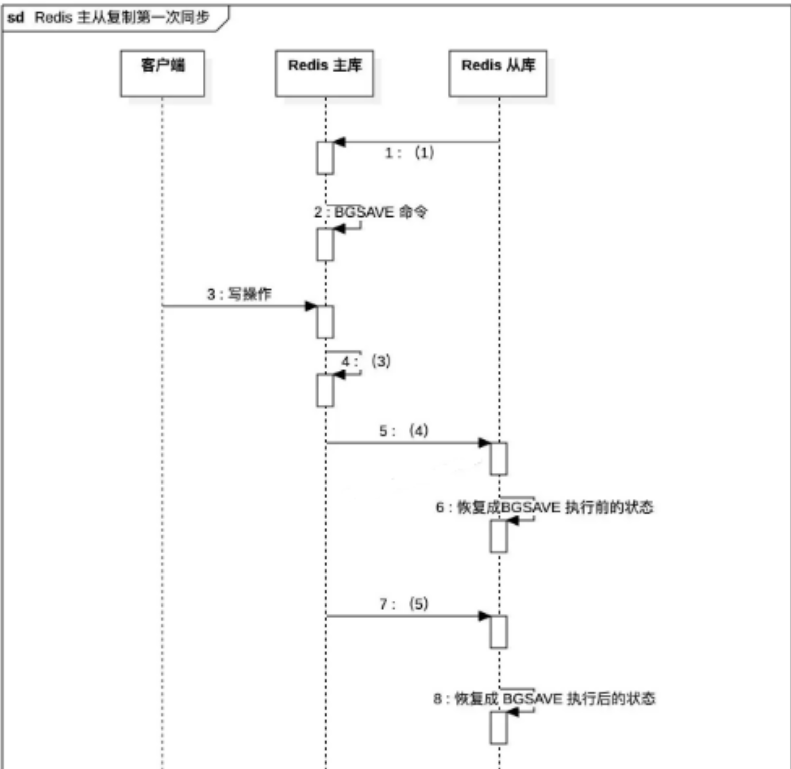
答案

问题2
增量复制的流程图填空,主从库第一次同步完成之后,后面是如何同步的?(6分)
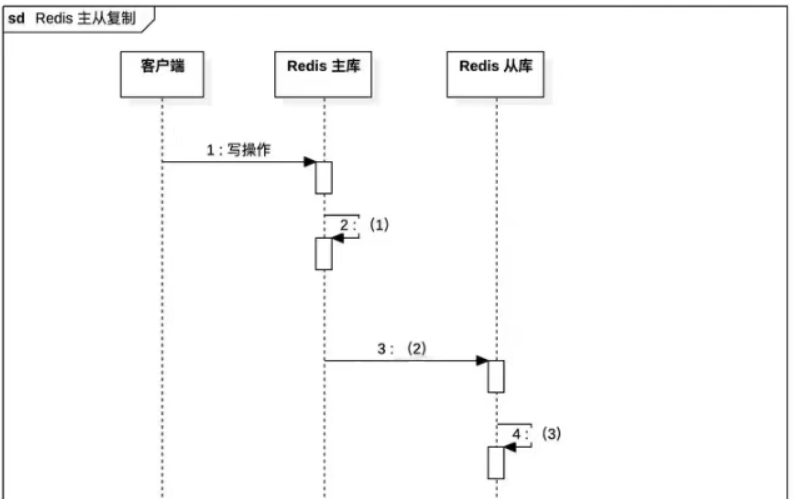
答案

问题3
Redis 的两种持久化技术数据持久化在系统非常重要,系统发生故障的时候需要进行数据恢复,请列举出数据持久化的两种方式,并论述其优缺点(9 分)
答案
Redis 的两种主要持久化方式是 RDB(快照持久化) 和 AOF(追加文件持久化)。RDB 方式会在指定时间间隔生成内存数据的快照并保存为二进制文件,优点是性能高、恢复速度快、适合备份;缺点是如果 Redis 崩溃,可能会丢失最后一次快照后的数据。AOF 会将每次写命令追加记录到日志文件中,优点是数据恢复更完整、丢失最少;缺点是文件体积大、写入频繁时性能开销较高。实际应用中可根据需求开启混合持久化,兼顾性能与数据安全。选择持久化方式需权衡数据安全性与系统性能。
第四题(选做题)
题干略,主要提了端侧 AI和云测 AI 算力。
问题1
云端 A1和端侧 Al的定义以及端侧 A1相比云端 Al的优势是什么?(6 分)
答案
云端 AI 是将人工智能模型部署在云服务器上,由云端负责数据处理和推理计算;而端侧 AI 则是将模型部署在本地设备上,如手机、摄像头、边缘计算设备等,在本地直接进行推理和处理。与云端 AI 相比,端侧 AI 的优势在于低延迟、响应快,能实现实时处理;同时数据无需上传云端,有效保护用户隐私和数据安全;此外,端侧 AI 不依赖网络连接,即使在离线环境下也能正常运行,适用于自动驾驶、智能安防等对时效性和稳定性要求高的场景。随着硬件性能提升,端侧 AI 正逐渐成为重要的发展方向。
问题2
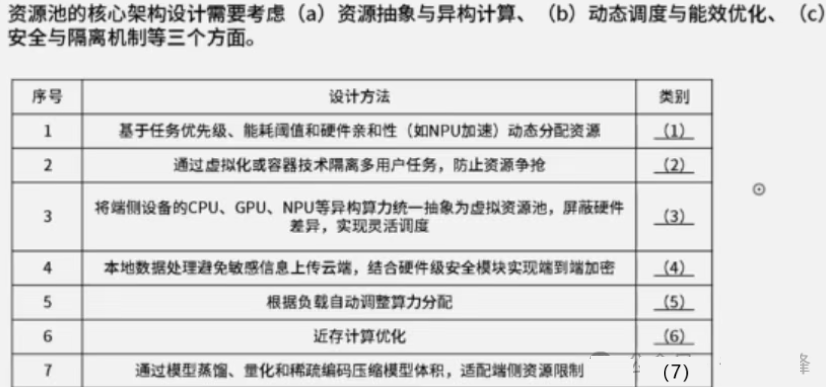
根据给出的选项补充对应的空。(7 分)
答案
- 1 (b) 动态调度与能效优化(根据任务和能耗动态调整资源分配)
- 2 (c ) 安全与隔离机制(虚拟化用于用户任务隔离,防止资源冲突)
- 3 (a) 资源抽象与异构计算(统一抽象异构资源,提升调度灵活性)
- 4 (c ) 安全与隔离机制(强化本地隐私保护与数据加密)
- 5 (b) 动态调度与能效优化(根据实时负载变化动态分配计算资源)
- 6 (b) 动态调度与能效优化(减少数据搬移,提高能效与响应速度)
- 7 (a) 资源抽象与异构计算(模型轻量化以适应端侧设备资源差异)
问题3
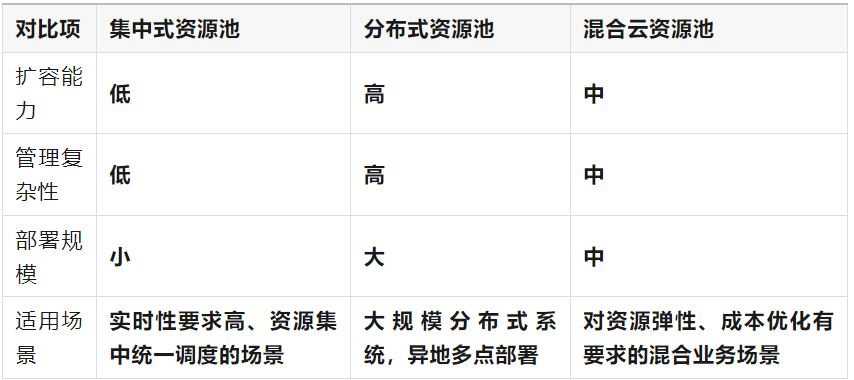
(1)请根据下表填写资源池的扩容能力、管理复杂性、部署规模(高中低),以及各类资源池的适用场景。(12 分)
(2)李工基于目前的场景,认为集中式资源池具有实时性高、统一调度等优点,并且当前系统规模有限,因此决定采用集中式资源池方案。
但王工指出李工的方案存在三个缺陷,请阐述原因。
答案
(1)
(2)
- 扩展性差:集中式架构在面对用户规模增长时,扩容能力有限,无法灵活应对大规模部署需求。
- 单点故障风险高:资源集中,若核心节点故障,可能导致整个平台服务不可用。
- 地理限制明显:用户或设备分布广泛时,集中式架构可能导致访问延迟高、体验差,不适合多地接入场景。
第五题(选做题)
题干略,主要提及了农产品溯源使用区块链相关的内容。
问题1
区块链的六个层次分别是什么,并简单介绍(12 分)
答案
- 数据层
负责底层数据结构与存储,包括区块、链结构、时间戳、Merkle 树等,确保数据一致性与不可篡改。 - 网络层
实现节点间的数据传播、发现和通信,采用 P2P 网络结构,确保区块链系统的去中心化特性。 - 共识层
决定多个节点如何就同一账本状态达成共识,常见机制有 PoW、PoS、PBFT 等,是保障区块链一致性与安全性的核心。激励层
通过发行代币等机制,激励节点参与维护网络的运行与共识过程,常用于公有链中。 - 合约层
实现智能合约的定义与执行,用代码自动执行合约逻辑,实现可信的业务逻辑处理。 - 应用层
提供面向用户的具体应用,如数字货币、供应链金融、身份认证等,是区块链价值体现的直接载体。
问题2
有三种人员:信息填写人员、核对人员、审核人员,请用 400字以内文字说明三种不同人员的操作流程(9 分)
答案
信息填写人员首先登录区块链系统,录入产品的基础信息,如批次、产地、检测报告等内容,并上传原始凭证(如盖章的检测文件)至 IPFS 分布式存储。随后调用智能合约生成初始哈希值,将关键信息上链,系统自动生成带时间戳的区块链存证编号,完成数据初次登记。
核对人员接收系统推送的待核验数据包,重点对比上链哈希值与原始凭证内容是否一致,并可进行实地抽查或远程视频核验,确保数据真实性。在数据验证无误后,使用多重签名钱包进行加密签名操作,触发智能合约将数据推入审核流程。
审核人员调取整个数据包的链上操作日志,检查是否存在异常或修改记录,并通过超过三分之二节点共识机制确认数据有效性。最终,审核人员激活时间锁功能,将该批次数据设为只读状态,并颁发可验证的数字凭证(VC),同步至农业监管区块链,实现数据全流程可溯源与不可篡改。
问题3
介绍下什么是智能合约,并说明智能合约包含哪三方面(4分)
答案
智能合约是一种运行在区块链上的自动化合约程序,它根据事先设定的规则自动执行合约内容,无需人工干预,具备去中心化、不可篡改和可追溯等特点。智能合约通常包含三方面内容:合约主体,即参与合约执行的各方;合约条款,是预先设定的业务逻辑和规则;合约触发机制,指合约在满足特定条件下自动执行的方式。它广泛应用于数字金融、供应链、溯源等领域,提升效率与透明度。