pyskl-Windows系统使用自己的数据集训练(一)
1. 基于公开数据集
1.1 所使用数据集
数据集下载:weizmann
数据集情况:一个包含 90 个低分辨率(180 x 144,去隔行扫描 50 fps)视频序列的数据库,这些视频序列显示了 9 个不同的人,每个人执行 10 个自然动作,例如跑步、行走、跳跃、 Jumping-jack (或简称 jack )、双腿向前跳跃(或跳跃)、双腿原地跳跃(或 pjump)、驰骋侧向(或侧面)、挥手双手(或 wave2)、waveone-hand (或 wave1 ) 或弯曲。
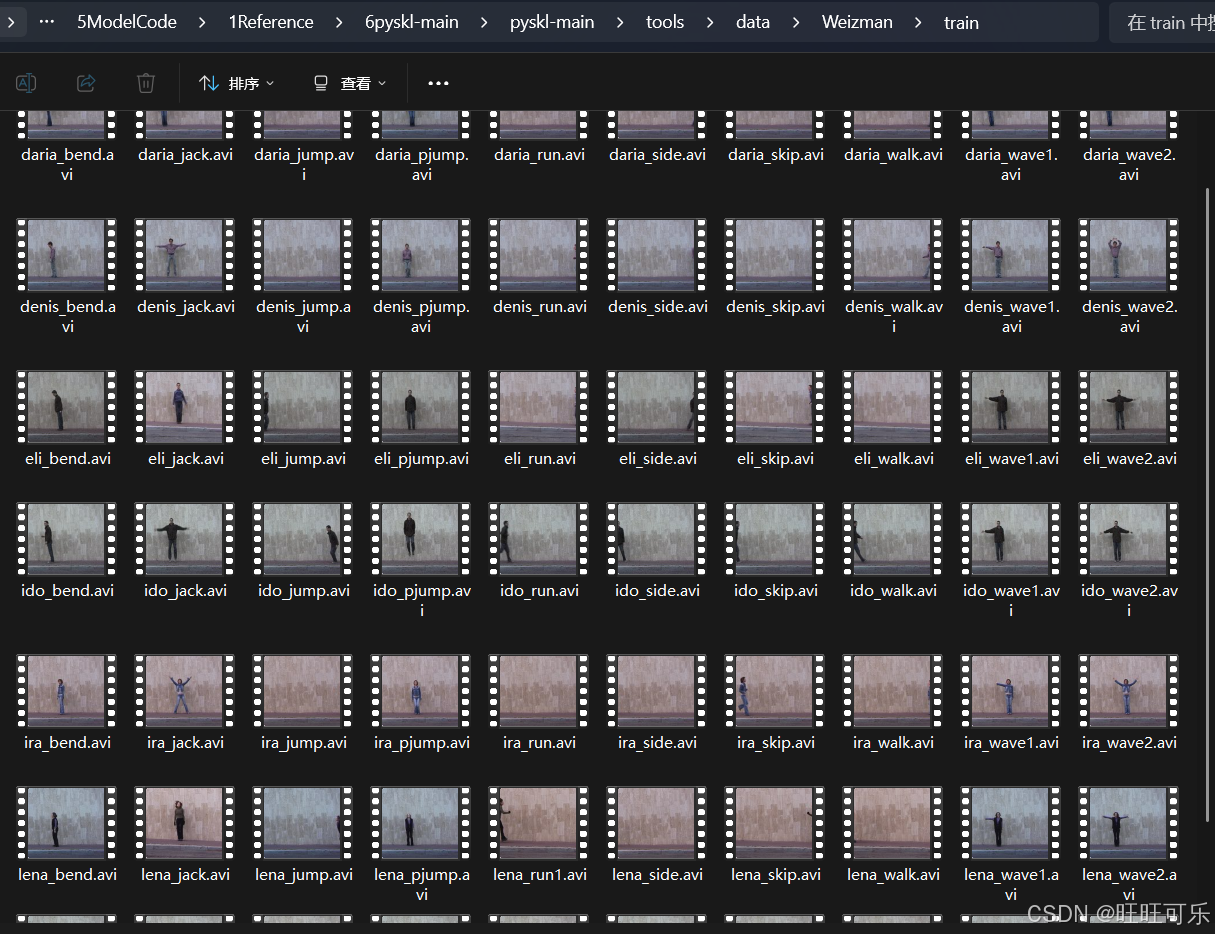
所以数据总量是10各类别,每个类别里面有9个视频,下载位置如图所示:

1.2. 数据集分类
1.2.1数据集放置位置
在pyskl-main/tools/data/下面新建一个文件,如weizmann。再在weizmann文件中创建"train"和 “test”文件夹用于分别存放训练集和测试集数据。
1.2.2 数据集划分
以下是几种常见比例:
(1)小规模数据集:对于传统机器学习阶段(数据集在万这个数量级),一般分配比例为训练集和测试集的比例为7:3或是8:2。为了进一步降低信息泄露同时更准确地反映模型的效能,更为常见的划分比例是训练集、验证集、测试集的比例为6:2:2。
(2)中等规模数据集:对于深度学习目标检测任务,常见的比例是训练集占80%,验证集和测试集各占10%。这种划分方式有助于模型更好地学习任务的特征和模式,同时确保模型在未见过的数据上的性能。
(3)大规模数据集:在大数据时代,对于百万级的数据集,常见的比例可以达到98:1:1,甚至可以达到99.5:0.3:0.2等。只要验证集和测试集的数量足够即可,例如有100万条数据,那么留1万验证集,1万测试集即可。
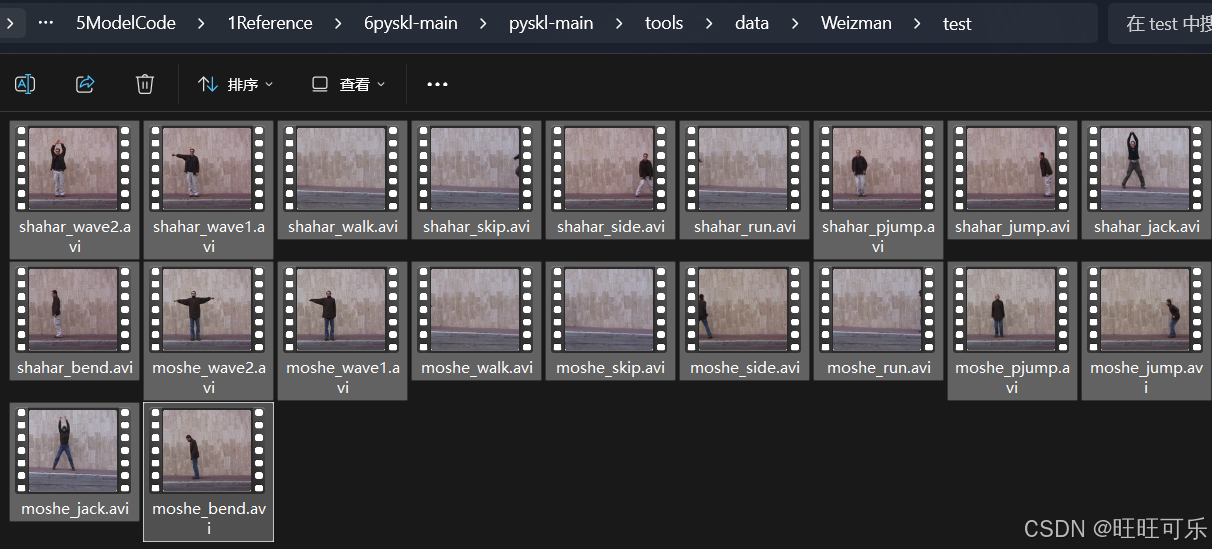
因为每个类大多数是9个视频(有的有10个),拿出7个到train文件夹,剩余的放到test文件夹,所以此处近似使用train:test=7:2的划分。
最后是train:70个,test20个:
1.2.3 视频命名
数据集源文件命名格式是:被拍摄者名字_动作.avi,比如daria_bend.avi,即被拍摄者daria,动作是bend,后面的.avi是视频的一种编码格式。为了方便处理,我们用序号替换动作名称:
| 序号 | 动作 | 动作解释 |
| 0 | bend | 弯腰 |
| 1 | jack | 开合跳 |
| 2 | jump | 跳 |
| 3 | pjump | 原地跳转 |
| 4 | run | 跑 |
| 5 | side | 侧边跳 |
| 6 | skip | 跳 |
| 7 | walk | 走 |
| 8 | wave1 | 单手挥手 |
| 9 | wave2 | 双手挥手 |
train和test分别如图所示:

并且在tools/data/label_map路径下新建一个weizmann.txt文件,文件内容就是数字编号何对应标签的对应关系,从小到大即可,一一对应。
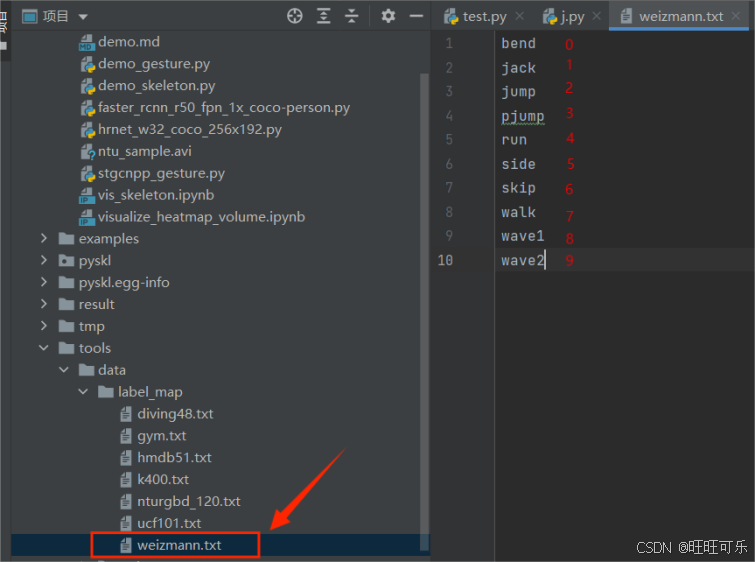
注意这个.txt文件名要和demo/demo_skeleton.py中--label-map参数默认的文件名一直,或者运行的时候自己制定也可以。
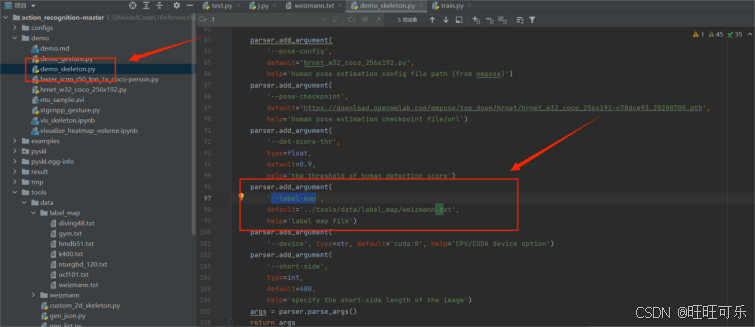
1.3 数据集相关准备文件
1.3.1 .json文件
包括train.json和test.json文件,内容如下:
1.3.2 .list文件
生成tools/data/custom_2d_skeleton.py需要的list文件。内容如下:
上述3个文件生成脚本如下,命名为tdatapre.py,直接存放在工程目录下。生成的train.json,test.json文件在在./tools/data/weizmann文件夹下(与文件生成脚本同路径)
import os
import decord
import json
from mmcv import load, dumpfrom pyskl.smp import mwlinesdef writeJson(path_train, jsonpath):outpot_list = []trainfile_list = os.listdir(path_train)for train_name in trainfile_list:traindit = {}sp = train_name.split('_')traindit['vid_name'] = train_name.replace('.avi', '')traindit['label'] = int(sp[1].replace('.avi', ''))traindit['start_frame'] = 0video_path = os.path.join(path_train, train_name)vid = decord.VideoReader(video_path)traindit['end_frame'] = len(vid)outpot_list.append(traindit.copy())with open(jsonpath, 'w') as outfile:json.dump(outpot_list, outfile)def writeList(dirpath, name):path_train = os.path.join(dirpath, 'train')path_test = os.path.join(dirpath, 'test')trainfile_list = os.listdir(path_train)testfile_list = os.listdir(path_test)train = []for train_name in trainfile_list:traindit = {}sp = train_name.split('_')traindit['vid_name'] = train_nametraindit['label'] = sp[1].replace('.avi', '')train.append(traindit)test = []for test_name in testfile_list:testdit = {}sp = test_name.split('_')testdit['vid_name'] = test_nametestdit['label'] = sp[1].replace('.avi', '')test.append(testdit)# tmpl1 = os.path.join(path_train, '{}')tmpl1 = os.path.join(path_train, '{}').replace(os.sep, '/') # 使用正斜杠或双反斜杠来避免路径问题lines1 = [(tmpl1 + ' {}').format(x['vid_name'], x['label']) for x in train]tmpl2 = os.path.join(path_test, '{}')lines2 = [(tmpl2 + ' {}').format(x['vid_name'], x['label']) for x in test]lines = lines1 + lines2mwlines(lines, os.path.join(dirpath, name))def traintest(dirpath, pklname, newpklname):os.chdir(dirpath)train = load('train.json')test = load('test.json')annotations = load(pklname)split = dict()split['xsub_train'] = [x['vid_name'] for x in train]split['xsub_val'] = [x['vid_name'] for x in test]dump(dict(split=split, annotations=annotations), newpklname)if __name__ == '__main__':dirpath = './tools/data/Weizmann'pklname = 'train.pkl'# 这里的命名结构:自建数据集名称_训练模型_公开数据集名称_公开数据集类别_模型名称.pklnewpklname = 'weizmann_stgn++_ntu120_xsub_hrnet.pkl'"""1、.json文件生成,取消对应注释即可"""#writeJson('./tools/data/weizmann/train', './tools/data/weizmann/train.json')#writeJson('./tools/data/weizmann/test', './tools/data/weizmann/test.json')"""2、.list文件生成,取消对应注释即可"""#writeList('./tools/data/weizmann', 'weizmann.list')"""3、调用custom_2d_skeleton.py,生成训练模型要用的pkl文件,取消对应注释即可"""# python tools/data/custom_2d_skeleton.py --video-list tools/data/weizmann/weizmann.list --out tools/data/weizmann/train.pkl"""4、最终要用的.pkl文件(weizmann_stgn++_ntu120_xsub_hrnet.pkl),取消对应注释即可"""traintest(dirpath, pklname, newpklname)1.3.3 .pkl文件
先修改:tools/data/custom_2d_skeleton.py脚本如下:
# Copyright (c) OpenMMLab. All rights reserved.
import argparse
import os
import os.path as osp
# import pdb
import pyskl
from mmdet.apis import inference_detector, init_detector
from mmpose.apis import inference_top_down_pose_model, init_pose_model
import decord
import mmcv
import numpy as np
# import torch.distributed as dist
from tqdm import tqdm
import mmdet
# import mmpose
# from pyskl.smp import mrlines
import cv2from pyskl.smp import mrlinesdef extract_frame(video_path):vid = decord.VideoReader(video_path)return [x.asnumpy() for x in vid]def detection_inference(model, frames):model = model.cuda()results = []for frame in frames:result = inference_detector(model, frame)results.append(result)return resultsdef pose_inference(model, frames, det_results):model = model.cuda()assert len(frames) == len(det_results)total_frames = len(frames)num_person = max([len(x) for x in det_results])kp = np.zeros((num_person, total_frames, 17, 3), dtype=np.float32)for i, (f, d) in enumerate(zip(frames, det_results)):# Align input formatd = [dict(bbox=x) for x in list(d)]pose = inference_top_down_pose_model(model, f, d, format='xyxy')[0]for j, item in enumerate(pose):kp[j, i] = item['keypoints']return kppyskl_root = osp.dirname(pyskl.__path__[0])
default_det_config = f'{pyskl_root}/demo/faster_rcnn_r50_fpn_1x_coco-person.py'
default_det_ckpt = ('https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco-person/''faster_rcnn_r50_fpn_1x_coco-person_20201216_175929-d022e227.pth')
default_pose_config = f'{pyskl_root}/demo/hrnet_w32_coco_256x192.py'
default_pose_ckpt = ('https://download.openmmlab.com/mmpose/top_down/hrnet/''hrnet_w32_coco_256x192-c78dce93_20200708.pth')def parse_args():parser = argparse.ArgumentParser(description='Generate 2D pose annotations for a custom video dataset')# * Both mmdet and mmpose should be installed from source# parser.add_argument('--mmdet-root', type=str, default=default_mmdet_root)# parser.add_argument('--mmpose-root', type=str, default=default_mmpose_root)# parser.add_argument('--det-config', type=str, default='../refe/faster_rcnn_r50_caffe_fpn_mstrain_1x_coco-person.py')# parser.add_argument('--det-ckpt', type=str,# default='../refe/faster_rcnn_r50_fpn_1x_coco-person_20201216_175929-d022e227.pth')parser.add_argument('--det-config',# default='../refe/faster_rcnn_r50_fpn_2x_coco.py',default=default_det_config,help='human detection config file path (from mmdet)')parser.add_argument('--det-ckpt',default=default_det_ckpt,help='human detection checkpoint file/url')parser.add_argument('--pose-config', type=str, default=default_pose_config)parser.add_argument('--pose-ckpt', type=str, default=default_pose_ckpt)# * Only det boxes with score larger than det_score_thr will be keptparser.add_argument('--det-score-thr', type=float, default=0.7)# * Only det boxes with large enough sizes will be kept,parser.add_argument('--det-area-thr', type=float, default=1300)# * Accepted formats for each line in video_list are:# * 1. "xxx.mp4" ('label' is missing, the dataset can be used for inference, but not training)# * 2. "xxx.mp4 label" ('label' is an integer (category index),# * the result can be used for both training & testing)# * All lines should take the same format.parser.add_argument('--video-list', type=str, help='the list of source videos')# * out should ends with '.pkl'parser.add_argument('--out', type=str, help='output pickle name')parser.add_argument('--tmpdir', type=str, default='tmp')parser.add_argument('--local_rank', type=int, default=1)# pdb.set_trace()# if 'RANK' not in os.environ:# os.environ['RANK'] = str(args.local_rank)# os.environ['WORLD_SIZE'] = str(1)# os.environ['MASTER_ADDR'] = 'localhost'# os.environ['MASTER_PORT'] = '12345'args = parser.parse_args()return argsdef main():args = parse_args()assert args.out.endswith('.pkl')lines = mrlines(args.video_list)lines = [x.split() for x in lines]assert len(lines[0]) in [1, 2]if len(lines[0]) == 1:annos = [dict(frame_dir=osp.basename(x[0]).split('.')[0], filename=x[0]) for x in lines]else:annos = [dict(frame_dir=osp.basename(x[0]).split('.')[0], filename=x[0], label=int(x[1])) for x in lines]rank = 0 # 添加该world_size = 1 # 添加# init_dist('pytorch', backend='nccl')# rank, world_size = get_dist_info()## if rank == 0:# os.makedirs(args.tmpdir, exist_ok=True)# dist.barrier()my_part = annos# my_part = annos[rank::world_size]print("from det_model")det_model = init_detector(args.det_config, args.det_ckpt, 'cuda')assert det_model.CLASSES[0] == 'person', 'A detector trained on COCO is required'print("from pose_model")pose_model = init_pose_model(args.pose_config, args.pose_ckpt, 'cuda')n = 0for anno in tqdm(my_part):frames = extract_frame(anno['filename'])print("anno['filename", anno['filename'])det_results = detection_inference(det_model, frames)# * Get detection results for humandet_results = [x[0] for x in det_results]for i, res in enumerate(det_results):# * filter boxes with small scoresres = res[res[:, 4] >= args.det_score_thr]# * filter boxes with small areasbox_areas = (res[:, 3] - res[:, 1]) * (res[:, 2] - res[:, 0])assert np.all(box_areas >= 0)res = res[box_areas >= args.det_area_thr]det_results[i] = respose_results = pose_inference(pose_model, frames, det_results)shape = frames[0].shape[:2]anno['img_shape'] = anno['original_shape'] = shapeanno['total_frames'] = len(frames)anno['num_person_raw'] = pose_results.shape[0]anno['keypoint'] = pose_results[..., :2].astype(np.float16)anno['keypoint_score'] = pose_results[..., 2].astype(np.float16)anno.pop('filename')mmcv.dump(my_part, osp.join(args.tmpdir, f'part_{rank}.pkl'))# dist.barrier()if rank == 0:parts = [mmcv.load(osp.join(args.tmpdir, f'part_{i}.pkl')) for i in range(world_size)]rem = len(annos) % world_sizeif rem:for i in range(rem, world_size):parts[i].append(None)ordered_results = []for res in zip(*parts):ordered_results.extend(list(res))ordered_results = ordered_results[:len(annos)]mmcv.dump(ordered_results, args.out)if __name__ == '__main__':# default_mmdet_root = osp.dirname(mmcv.__path__[0])# default_mmpose_root = osp.dirname(mmcv.__path__[0])main()再运行如下指令,可以提取到所有视频数据集的骨骼数据,合并到生成train.pkl文件里:
python ./tools/data/custom_2d_skeleton.py --video-list ./tools/data/weizmann/weizmann.list --out ./tools/data/weizmann/train.pkl
中途报错路径不对,查看生成的.list文件果然路径都是有问题的。于是修改了.list文件程序(上面给出的是更新过的)
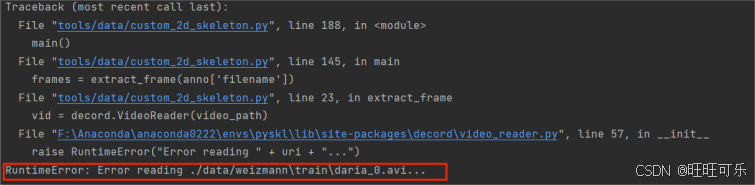
检查list文件无误。重新运行指令:
具体生成过程如下所示:这个全部完成需要很久,约半小时左右。


再根据上面生成的train.pkl、train.json、test.json文件,生成最后训练要用的pkl文件。
from mmcv import load, dump
def traintest(dirpath, pklname, newpklname):os.chdir(dirpath)train = load('train.json') test = load('test.json')annotations = load(pklname)split = dict()split['xsub_train'] = [x['vid_name'] for x in train] #指定训练集里样本名字split['xsub_val'] = [x['vid_name'] for x in test] #指定测试集里样本名字dump(dict(split=split, annotations=annotations), newpklname) #最后用于训练的pkl文件名if __name__ == '__main__':dirpath = './data/Weizmann'pklname = 'train.pkl'newpklname = 'wei_xsub_stgn++_ch.pkl'traintest(dirpath, pklname, newpklname)
上述得到的文件目录如下:
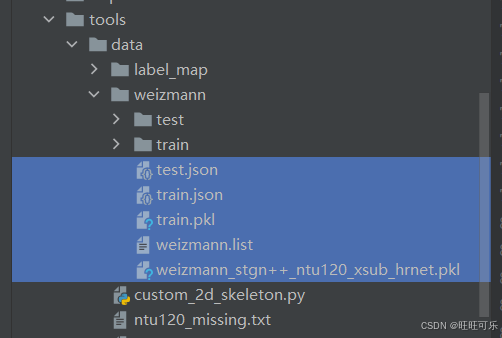
1.4 训练模型
1.4.1 选择要训练的模型
在configs目录下面有所包含的模型配置文件,根据所要训练的模型修改对应的配置文件:
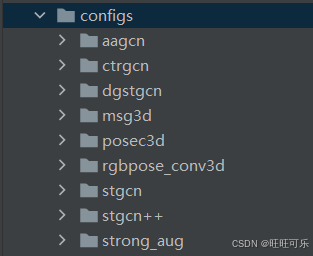
这里先以训练stgcn++为例。使用了configs/stgcn++/stgcn++_ntu120_xsub_hrnet/j.py配置文件。
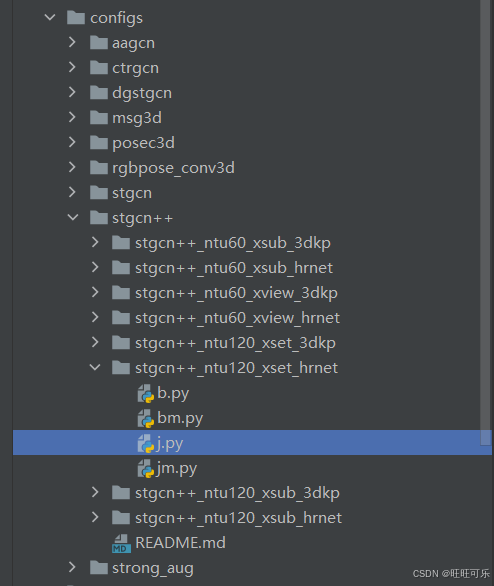
1.4.2 修改模型配置文件
打开对应模型配置文件,主要修改了★位置,还有的超参数也可以修改,暂时不修改。在evaluation部分新增2个参数可以看到准确率最好的权重是哪一个,对应生成的best_top1_acc_epoch_*.pth(*对应训练轮数)。具体如下:
model = dict(type='RecognizerGCN',backbone=dict(type='STGCN',gcn_adaptive='init',gcn_with_res=True,tcn_type='mstcn',graph_cfg=dict(layout='coco', mode='spatial')),cls_head=dict(type='GCNHead',num_classes=10, # ★根据自己数据集的类别修改in_channels=256))dataset_type = 'PoseDataset'
# ann_file = 'C:/Users/Administrator/Desktop/pyspace/pyskl-main/data/Weizmann/Wei_xsub_stgn++.pkl'
# ★ann_file要跟自己之前生成的第5个文件一致
ann_file = 'tools/data/weizmann/weizmann_stgn++_ntu120_xsub_hrnet.pkl'# ★训练、验证、测试中的num_person也可以修改,根据数据集情况(暂时修改为1,因为数据集中只有1个人,原来是2)
train_pipeline = [dict(type='PreNormalize2D'),dict(type='GenSkeFeat', dataset='coco', feats=['j']),dict(type='UniformSample', clip_len=100),dict(type='PoseDecode'),# ★dict(type='FormatGCNInput', num_person=2),dict(type='FormatGCNInput', num_person=1),dict(type='Collect', keys=['keypoint', 'label'], meta_keys=[]),dict(type='ToTensor', keys=['keypoint'])
]
val_pipeline = [dict(type='PreNormalize2D'),dict(type='GenSkeFeat', dataset='coco', feats=['j']),dict(type='UniformSample', clip_len=100, num_clips=1),dict(type='PoseDecode'),# ★dict(type='FormatGCNInput', num_person=2),dict(type='FormatGCNInput', num_person=1),dict(type='Collect', keys=['keypoint', 'label'], meta_keys=[]),dict(type='ToTensor', keys=['keypoint'])
]
test_pipeline = [dict(type='PreNormalize2D'),dict(type='GenSkeFeat', dataset='coco', feats=['j']),dict(type='UniformSample', clip_len=100, num_clips=10),dict(type='PoseDecode'),# ★dict(type='FormatGCNInput', num_person=2),dict(type='FormatGCNInput', num_person=1),dict(type='Collect', keys=['keypoint', 'label'], meta_keys=[]),dict(type='ToTensor', keys=['keypoint'])
]# ★这里的split='xsub_train'、split='xsub_val'可以按照自己写入的时候的key键进行修改,但是要保证weizmann_stgn++_ntu120_xsub_hrnet.pkl
data = dict(videos_per_gpu=16,workers_per_gpu=2,test_dataloader=dict(videos_per_gpu=1),train=dict(type='RepeatDataset',times=5,dataset=dict(type=dataset_type, ann_file=ann_file, pipeline=train_pipeline, split='xsub_train')),val=dict(type=dataset_type, ann_file=ann_file, pipeline=val_pipeline, split='xsub_val'),test=dict(type=dataset_type, ann_file=ann_file, pipeline=test_pipeline, split='xsub_val'))# optimizer
optimizer = dict(type='SGD', lr=0.1, momentum=0.9, weight_decay=0.0005, nesterov=True)
optimizer_config = dict(grad_clip=None)
# learning policy
lr_config = dict(policy='CosineAnnealing', min_lr=0, by_epoch=False)
# ★可以修改训练的轮数total_epochs
total_epochs = 16
# ★新增2个参数便于看到最佳权重
checkpoint_config = dict(interval=1)
evaluation = dict(interval=1,metrics=['top_k_accuracy'],save_best='top1_acc', # ★新增这个参数rule='greater' # ★准确率越大越好)
log_config = dict(interval=100, hooks=[dict(type='TextLoggerHook')])# runtime settings
log_level = 'INFO'
# ★work_dir为保存训练结果文件的地方,可以自己修改
# work_dir = 'C://Users//Administrator//Desktop//pyspace//pyskl-main//result'
# work_dir = './work_dirs/stgcn++/stgcn++_ntu120_xsub_hrnet/j'
work_dir = './work_dirs/stgcn++/stgcn++_ntu120_xsub_hrnet/j'对于windows系统,还需要修改train.py。
1.4.3 开始训练
在train.py文件中,添加全局变量:
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
os.environ['RANK'] = '0' # rank当前进程
os.environ['WORLD_SIZE'] = '1' # WORLD_SIZE进程总数
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '5678'
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
同时为了方便,config参数可以给定默认为自己的配置文件,与前面对应:
parser.add_argument('--config',
default='../configs/stgcn++/stgcn++_ntu120_xsub_hrnet/j.py',
help='train config file path')
具体程序如下:
# Copyright (c) OpenMMLab. All rights reserved.
# flake8: noqa: E722
import argparse
import mmcv
import os
import os.path as osp
import time
import torch
import torch.distributed as dist
from mmcv import Config
from mmcv import digit_version as dv
from mmcv.runner import get_dist_info, init_dist, set_random_seed
from mmcv.utils import get_git_hashfrom pyskl import __version__
from pyskl.apis import init_random_seed, train_model
from pyskl.datasets import build_dataset
from pyskl.models import build_model
from pyskl.utils import collect_env, get_root_logger, mc_off, mc_on, test_portos.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
os.environ['RANK'] = '0' # rank当前进程
os.environ['WORLD_SIZE'] = '1' # WORLD_SIZE进程总数
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '5678'
os.environ["CUDA_VISIBLE_DEVICES"] = "0"def parse_args():parser = argparse.ArgumentParser(description='Train a recognizer')parser.add_argument('--config',default='configs/stgcn++/stgcn++_ntu120_xsub_hrnet/j.py',help='train config file path')parser.add_argument('--validate',action='store_true',help='whether to evaluate the checkpoint during training')parser.add_argument('--test-last',action='store_true',help='whether to test the checkpoint after training')parser.add_argument('--test-best',action='store_true',help='whether to test the best checkpoint (if applicable) after training')parser.add_argument('--seed', type=int, default=None, help='random seed')parser.add_argument('--deterministic',action='store_true',help='whether to set deterministic options for CUDNN backend.')parser.add_argument('--launcher',choices=['pytorch', 'slurm'],default='pytorch',help='job launcher')parser.add_argument('--compile',action='store_true',help='whether to compile the model before training / testing (only available in pytorch 2.0)')parser.add_argument('--local_rank', type=int, default=-1)parser.add_argument('--local-rank', type=int, default=-1)args = parser.parse_args()if 'LOCAL_RANK' not in os.environ:os.environ['LOCAL_RANK'] = str(args.local_rank)return argsdef main():args = parse_args()cfg = Config.fromfile(args.config)# set cudnn_benchmarkif cfg.get('cudnn_benchmark', False):torch.backends.cudnn.benchmark = True# work_dir is determined in this priority:# config file > default (base filename)if cfg.get('work_dir', None) is None:# use config filename as default work_dir if cfg.work_dir is Nonecfg.work_dir = osp.join('./work_dirs', osp.splitext(osp.basename(args.config))[0])if not hasattr(cfg, 'dist_params'):cfg.dist_params = dict(backend='gloo')init_dist(args.launcher, **cfg.dist_params)rank, world_size = get_dist_info()cfg.gpu_ids = range(world_size)auto_resume = cfg.get('auto_resume', True)if auto_resume and cfg.get('resume_from', None) is None:resume_pth = osp.join(cfg.work_dir, 'latest.pth')if osp.exists(resume_pth):cfg.resume_from = resume_pth# create work_dirmmcv.mkdir_or_exist(osp.abspath(cfg.work_dir))# dump configcfg.dump(osp.join(cfg.work_dir, osp.basename(args.config)))# init logger before other stepstimestamp = time.strftime('%Y%m%d_%H%M%S', time.localtime())log_file = osp.join(cfg.work_dir, f'{timestamp}.log')logger = get_root_logger(log_file=log_file, log_level=cfg.get('log_level', 'INFO'))# init the meta dict to record some important information such as# environment info and seed, which will be loggedmeta = dict()# log env infoenv_info_dict = collect_env()env_info = '\n'.join([f'{k}: {v}' for k, v in env_info_dict.items()])dash_line = '-' * 60 + '\n'logger.info('Environment info:\n' + dash_line + env_info + '\n' +dash_line)meta['env_info'] = env_info# log some basic infologger.info(f'Config: {cfg.pretty_text}')# set random seedsseed = init_random_seed(args.seed)logger.info(f'Set random seed to {seed}, deterministic: {args.deterministic}')set_random_seed(seed, deterministic=args.deterministic)cfg.seed = seedmeta['seed'] = seedmeta['config_name'] = osp.basename(args.config)meta['work_dir'] = osp.basename(cfg.work_dir.rstrip('/\\'))model = build_model(cfg.model)if dv(torch.__version__) >= dv('2.0.0') and args.compile:model = torch.compile(model)datasets = [build_dataset(cfg.data.train)]cfg.workflow = cfg.get('workflow', [('train', 1)])assert len(cfg.workflow) == 1if cfg.checkpoint_config is not None:# save pyskl version, config file content and class names in# checkpoints as meta datacfg.checkpoint_config.meta = dict(pyskl_version=__version__ + get_git_hash(digits=7),config=cfg.pretty_text)test_option = dict(test_last=args.test_last, test_best=args.test_best)default_mc_cfg = ('localhost', 22077)memcached = cfg.get('memcached', False)if rank == 0 and memcached:# mc_list is a list of pickle files you want to cache in memory.# Basically, each pickle file is a dictionary.mc_cfg = cfg.get('mc_cfg', default_mc_cfg)assert isinstance(mc_cfg, tuple) and mc_cfg[0] == 'localhost'if not test_port(mc_cfg[0], mc_cfg[1]):mc_on(port=mc_cfg[1], launcher=args.launcher)retry = 3while not test_port(mc_cfg[0], mc_cfg[1]) and retry > 0:time.sleep(5)retry -= 1assert retry >= 0, 'Failed to launch memcached. 'dist.barrier()print("*********************"*100)print("cfg:", cfg)train_model(model, datasets, cfg, validate=args.validate, test=test_option, timestamp=timestamp, meta=meta)dist.barrier()if rank == 0 and memcached:mc_off()if __name__ == '__main__':main()运行如下指令开始训练:
python tools/train.py --validate --test-last --test-best
但是最开始遇到了以下两个问题:
1、mmdetection 报错 TypeError: FormatCode() got an unexpected keyword argument ‘verify‘
可能是yapf版本过高,尝试以下解决方法:
pip uninstall yapf
pip install yapf==0.40.1参考:mmdetection 报错 TypeError: FormatCode() got an unexpected keyword argument ‘verify‘-CSDN博客
2、报错“error:microsoft visual c++ 14.0 or greater is required”问题
解决:使用Visual Studio Installer安装使用C++的桌面开发,默认右侧应该是这些勾选。
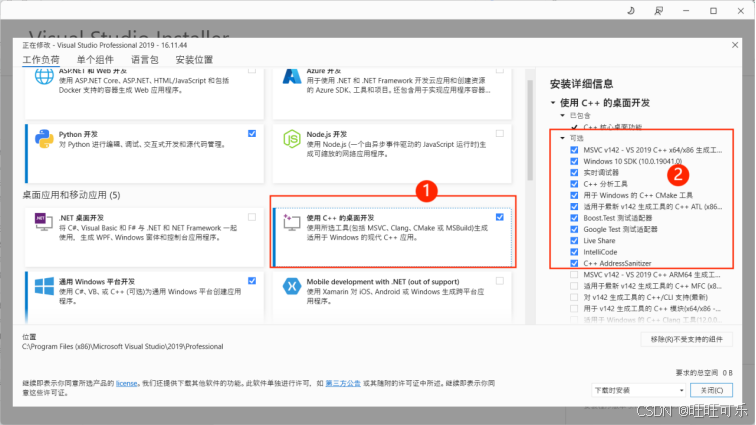
参考:解决pip安装报错“error:microsoft visual c++ 14.0 or greater is required”问题_microsoft visual c++ 14.0的安装-CSDN博客
运行如下指令开始训练。
python tools/train.py --validate --test-last --test-best成功训练(运行的时候前面有很多代码警告,不用管等到这个epochs出现就可以了)。
同时在配置文件指定的输出目录下可以看到训练生成的权重文件,训练结束也会显示路径。这里面有个最好的pth文件(best_top1_acc_epoch_13.pth):

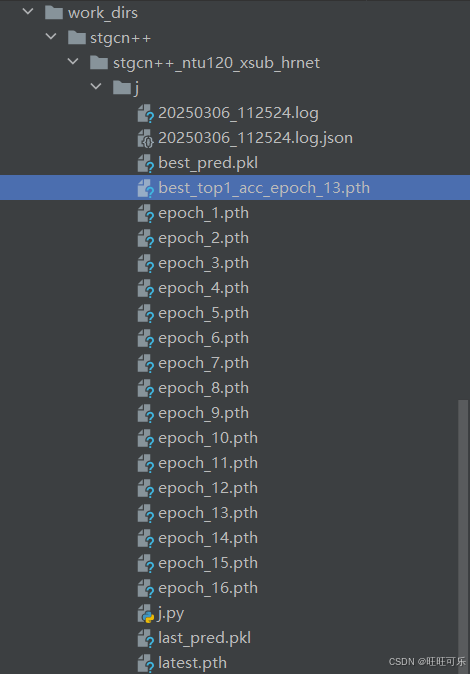
输出结果中还可以看到:top1_acc 0.9000;top5_acc 1.0000。表示模型在测试集上对样本的首选预测类别正确率高达90%。模型具有极强的精准分类能力,在绝大多数情况下能直接给出正确答案。模型预测的前5个候选类别100%覆盖正确标签。即使模型的首选预测错误,正确结果也必定在其预测的Top-5范围内,表明模型对类别特征的泛化能力极强。
1.5 结果测试
1.5.1 demo测试
利用1.4.3得到的效果最好的权重文件best_top1_acc_epoch_13.pth进行测试。demo_skeleton。py需要的参数查看脚本就可以得到,其他我都设置了对应的默认,这里只指定最佳权重文件。
python demo/demo_skeleton.py --checkpoint work_dirs/stgcn++/stgcn++_ntu120_xsub_hrnet/j/best_top1_acc_epoch_13.pth
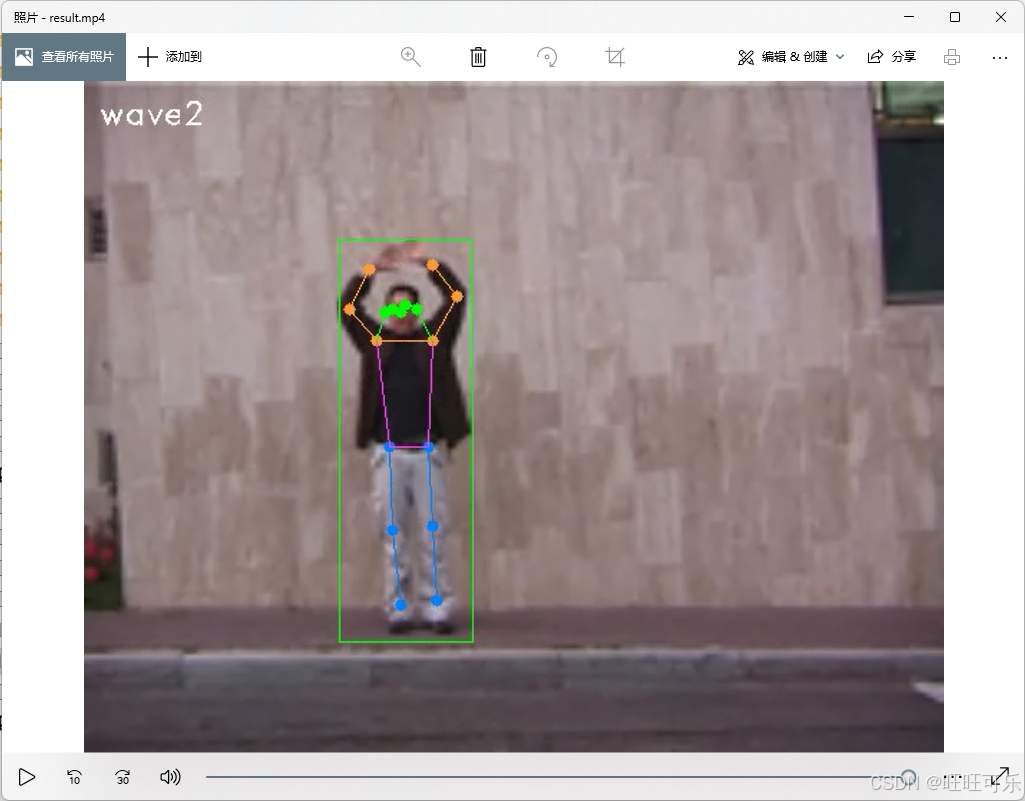
测试视频为shahar_9.avi,理论标签是wave2,检测结果如下:
但是我在运行demo_skeleton.py时写入视频编码出了问题,fps参数没有正常传递时Nonetype,具体在如下,最后锁定问题就出在视频结果编码写入vid.write_videofile(args.out_filename, fps=fps, remove_temp=True)这里,没有正确传入fps参数:
# 修改前vid = mpy.ImageSequenceClip([x[:, :, ::-1] for x in vis_frames], fps=24)vid.write_videofile(args.out_filename, remove_temp=True)# 修改后
def frame_extract():...original_fps = vid.get(cv2.CAP_PROP_FPS)# 如果获取失败(返回0),使用默认值24fps = original_fps if original_fps > 0 else 24...return frame_paths, frames, fpsif __name__ == '__main__':args = parse_args()frame_paths, original_frames, fps = frame_extraction(args.video,args.short_side) ...print(f"fps={fps}) # 看了fps式有值的不是NoneTypevid = mpy.ImageSequenceClip([x[:, :, ::-1] for x in vis_frames], fps=fps)vid.write_videofile(args.out_filename, fps=fps, remove_temp=True)报错内容如下,根据报错xiu'xixiuxi
Traceback (most recent call last):File "demo/demo_skeleton.py", line 319, in <module>vid.write_videofile(args.out_filename, fps=fps, remove_temp=True)File "F:\Anaconda\anaconda0222\envs\pyskl\lib\site-packages\decorator.py", line 232, in funreturn caller(func, *(extras + args), **kw)File "F:\Anaconda\anaconda0222\envs\pyskl\lib\site-packages\moviepy\decorators.py", line 54, in requires_durationreturn f(clip, *a, **k)File "F:\Anaconda\anaconda0222\envs\pyskl\lib\site-packages\decorator.py", line 232, in funreturn caller(func, *(extras + args), **kw)File "F:\Anaconda\anaconda0222\envs\pyskl\lib\site-packages\moviepy\decorators.py", line 135, in use_clip_fps_by_defaultreturn f(clip, *new_a, **new_kw)File "F:\Anaconda\anaconda0222\envs\pyskl\lib\site-packages\decorator.py", line 232, in funreturn caller(func, *(extras + args), **kw)File "F:\Anaconda\anaconda0222\envs\pyskl\lib\site-packages\moviepy\decorators.py", line 22, in convert_masks_to_RGBreturn f(clip, *a, **k)File "F:\Anaconda\anaconda0222\envs\pyskl\lib\site-packages\moviepy\video\VideoClip.py", line 300, in write_videofileffmpeg_write_video(self, filename, fps, codec,File "F:\Anaconda\anaconda0222\envs\pyskl\lib\site-packages\moviepy\video\io\ffmpeg_writer.py", line 213, in ffmpeg_write_videowith FFMPEG_VideoWriter(filename, clip.size, fps, codec = codec,File "F:\Anaconda\anaconda0222\envs\pyskl\lib\site-packages\moviepy\video\io\ffmpeg_writer.py", line 88, in __init__'-r', '%.02f' % fps,
TypeError: must be real number, not NoneType
修改方式1:不要原来的编码方式,把原来的moviepy的ffmpeg_write_video替换成立opencv的编码方式,注释掉原来编码的两行改成下面的即可:
#vid = mpy.ImageSequenceClip([x[:, :, ::-1] for x in vis_frames], fps=fps)#vid.write_videofile(args.out_filename, fps=fps, remove_temp=True)"""*********************************************"""print(f"fps={fps}")fwidth = vis_frames[0].shape[1] # 视频的宽度fheight = vis_frames[0].shape[0] # 视频的高度print(f"fps={fps}")print(f"frame_w={fwidth},frame_h={fheight}")# *************************************************# 定义输出视频的基本信息fourcc = cv2.VideoWriter_fourcc(*'mp4v') # 定义编码器out_filename = args.out_filename # 输出文件名print(f"out_filename{out_filename}")# 创建VideoWriter对象video_writer = cv2.VideoWriter(out_filename, fourcc, fps, (fwidth, fheight))print(f"outputvideo{out_filename}")# 循环遍历每一帧,将它们写入视频文件for frame in vis_frames:video_writer.write(frame)# 释放VideoWriter对象video_writer.release()"""*********************************************"""方式2:排查问题。暂时先不排查。
到此根据公开数据集的训练就结束了。
demo_skeleton.py中得到的vis_frames,其实就是经过了Performing Human Detection for each frame,Performing Human Pose Estimation for each frame,之后打上标签action_label: wave2,然后再把标签写入每一帧得到的结果帧序列,最后编码成视频就是result.mp4.
下面时demo_skeleton.py的完整程序:
# Copyright (c) OpenMMLab. All rights reserved.
import argparse
import cv2
import mmcv
import numpy as np
import os
import os.path as osp
import shutil
import torch
import warnings
from scipy.optimize import linear_sum_assignmentfrom pyskl.apis import inference_recognizer, init_recognizertry:from mmdet.apis import inference_detector, init_detector
except (ImportError, ModuleNotFoundError):def inference_detector(*args, **kwargs):passdef init_detector(*args, **kwargs):passwarnings.warn('Failed to import `inference_detector` and `init_detector` from `mmdet.apis`. ''Make sure you can successfully import these if you want to use related features. ')try:from mmpose.apis import inference_top_down_pose_model, init_pose_model, vis_pose_result
except (ImportError, ModuleNotFoundError):def init_pose_model(*args, **kwargs):passdef inference_top_down_pose_model(*args, **kwargs):passdef vis_pose_result(*args, **kwargs):passwarnings.warn('Failed to import `init_pose_model`, `inference_top_down_pose_model`, `vis_pose_result` from ''`mmpose.apis`. Make sure you can successfully import these if you want to use related features. ')try:import moviepy.editor as mpy
except ImportError:raise ImportError('Please install moviepy to enable output file')FONTFACE = cv2.FONT_HERSHEY_DUPLEX
FONTSCALE = 0.75
FONTCOLOR = (255, 255, 255) # BGR, white
THICKNESS = 1
LINETYPE = 1def parse_args():parser = argparse.ArgumentParser(description='stgcn++ demo')parser.add_argument('--video', default='tools/data/weizmann/test/shahar_9.avi', help='video file/url')parser.add_argument('--out_filename', default='result.mp4', help='output filename')parser.add_argument('--config',default='configs/stgcn++/stgcn++_ntu120_xsub_hrnet/j.py',help='skeleton action recognition config file path')parser.add_argument('--checkpoint',default='../result/best_top1_acc_epoch_63.pth',help='skeleton action recognition checkpoint file/url')parser.add_argument('--det-config',default='demo/faster_rcnn_r50_fpn_1x_coco-person.py',help='human detection config file path (from mmdet)')parser.add_argument('--det-checkpoint',default=('https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco-person/''faster_rcnn_r50_fpn_1x_coco-person_20201216_175929-d022e227.pth'),help='human detection checkpoint file/url')parser.add_argument('--pose-config',default='demo/hrnet_w32_coco_256x192.py',help='human pose estimation config file path (from mmpose)')parser.add_argument('--pose-checkpoint',default='https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w32_coco_256x192-c78dce93_20200708.pth',help='human pose estimation checkpoint file/url')parser.add_argument('--det-score-thr',type=float,default=0.9,help='the threshold of human detection score')parser.add_argument('--label-map',default='tools/data/label_map/weizmann.txt',help='label map file')parser.add_argument('--device', type=str, default='cuda:0', help='CPU/CUDA device option')parser.add_argument('--short-side',type=int,default=480,help='specify the short-side length of the image')args = parser.parse_args()return argsdef frame_extraction(video_path, short_side):"""Extract frames given video_path.Args:video_path (str): The video_path."""# Load the video, extract frames into ./tmp/video_nametarget_dir = osp.join('./tmp', osp.basename(osp.splitext(video_path)[0]))os.makedirs(target_dir, exist_ok=True)# Should be able to handle videos up to several hoursframe_tmpl = osp.join(target_dir, 'img_{:06d}.jpg')vid = cv2.VideoCapture(video_path)original_fps = vid.get(cv2.CAP_PROP_FPS)# 如果获取失败(返回0),使用默认值24fps = original_fps if original_fps > 0 else 24frames = []frame_paths = []flag, frame = vid.read()cnt = 0new_h, new_w = None, Nonewhile flag:if new_h is None:h, w, _ = frame.shapenew_w, new_h = mmcv.rescale_size((w, h), (short_side, np.Inf))frame = mmcv.imresize(frame, (new_w, new_h))frames.append(frame)frame_path = frame_tmpl.format(cnt + 1)frame_paths.append(frame_path)cv2.imwrite(frame_path, frame)cnt += 1flag, frame = vid.read()return frame_paths, frames, fpsdef detection_inference(args, frame_paths):"""Detect human boxes given frame paths.Args:args (argparse.Namespace): The arguments.frame_paths (list[str]): The paths of frames to do detection inference.Returns:list[np.ndarray]: The human detection results."""model = init_detector(args.det_config, args.det_checkpoint, args.device)assert model is not None, ('Failed to build the detection model. Check if you have installed mmcv-full properly. ''You should first install mmcv-full successfully, then install mmdet, mmpose. ')assert model.CLASSES[0] == 'person', 'We require you to use a detector trained on COCO'results = []print('Performing Human Detection for each frame')prog_bar = mmcv.ProgressBar(len(frame_paths))for frame_path in frame_paths:result = inference_detector(model, frame_path)# We only keep human detections with score larger than det_score_thrresult = result[0][result[0][:, 4] >= args.det_score_thr]results.append(result)prog_bar.update()return resultsdef pose_inference(args, frame_paths, det_results):model = init_pose_model(args.pose_config, args.pose_checkpoint,args.device)ret = []print('Performing Human Pose Estimation for each frame')prog_bar = mmcv.ProgressBar(len(frame_paths))for f, d in zip(frame_paths, det_results):# Align input formatd = [dict(bbox=x) for x in list(d)]pose = inference_top_down_pose_model(model, f, d, format='xyxy')[0]ret.append(pose)prog_bar.update()return retdef dist_ske(ske1, ske2):dist = np.linalg.norm(ske1[:, :2] - ske2[:, :2], axis=1) * 2diff = np.abs(ske1[:, 2] - ske2[:, 2])return np.sum(np.maximum(dist, diff))def pose_tracking(pose_results, max_tracks=2, thre=30):tracks, num_tracks = [], 0num_joints = Nonefor idx, poses in enumerate(pose_results):if len(poses) == 0:continueif num_joints is None:num_joints = poses[0].shape[0]track_proposals = [t for t in tracks if t['data'][-1][0] > idx - thre]n, m = len(track_proposals), len(poses)scores = np.zeros((n, m))for i in range(n):for j in range(m):scores[i][j] = dist_ske(track_proposals[i]['data'][-1][1], poses[j])row, col = linear_sum_assignment(scores)for r, c in zip(row, col):track_proposals[r]['data'].append((idx, poses[c]))if m > n:for j in range(m):if j not in col:num_tracks += 1new_track = dict(data=[])new_track['track_id'] = num_tracksnew_track['data'] = [(idx, poses[j])]tracks.append(new_track)if num_joints is None:return None, Nonetracks.sort(key=lambda x: -len(x['data']))result = np.zeros((max_tracks, len(pose_results), num_joints, 3), dtype=np.float16)for i, track in enumerate(tracks[:max_tracks]):for item in track['data']:idx, pose = itemresult[i, idx] = posereturn result[..., :2], result[..., 2]if __name__ == '__main__':args = parse_args()frame_paths, original_frames, fps = frame_extraction(args.video,args.short_side)num_frame = len(frame_paths)h, w, _ = original_frames[0].shapeconfig = mmcv.Config.fromfile(args.config)config.data.test.pipeline = [x for x in config.data.test.pipeline if x['type'] != 'DecompressPose']# Are we using GCN for Infernece?# 配置文件详细输出# print('config:', config)GCN_flag = 'GCN' in config.model.type # GCN是不是在字符串里GCN_nperson = Noneif GCN_flag:format_op = [op for op in config.data.test.pipeline if op['type'] == 'FormatGCNInput'][0]# We will set the default value of GCN_nperson to 2, which is# the default arg of FormatGCNInputGCN_nperson = format_op.get('num_person', 2)model = init_recognizer(config, args.checkpoint, args.device)# Load label_maplabel_map = [x.strip() for x in open(args.label_map).readlines()]# Get Human detection resultsdet_results = detection_inference(args, frame_paths)torch.cuda.empty_cache()pose_results = pose_inference(args, frame_paths, det_results)torch.cuda.empty_cache()fake_anno = dict(frame_dir='',label=-1,img_shape=(h, w),original_shape=(h, w),start_index=0,modality='Pose',total_frames=num_frame)if GCN_flag:# We will keep at most `GCN_nperson` persons per frame.tracking_inputs = [[pose['keypoints'] for pose in poses] for poses in pose_results]keypoint, keypoint_score = pose_tracking(tracking_inputs, max_tracks=GCN_nperson)fake_anno['keypoint'] = keypointfake_anno['keypoint_score'] = keypoint_scoreelse:num_person = max([len(x) for x in pose_results])# Current PoseC3D models are trained on COCO-keypoints (17 keypoints)num_keypoint = 17keypoint = np.zeros((num_person, num_frame, num_keypoint, 2),dtype=np.float16)keypoint_score = np.zeros((num_person, num_frame, num_keypoint),dtype=np.float16)for i, poses in enumerate(pose_results):for j, pose in enumerate(poses):pose = pose['keypoints']keypoint[j, i] = pose[:, :2]keypoint_score[j, i] = pose[:, 2]fake_anno['keypoint'] = keypointfake_anno['keypoint_score'] = keypoint_scoreif fake_anno['keypoint'] is None:action_label = ''else:results = inference_recognizer(model, fake_anno)action_label = label_map[results[0][0]]print("\naction_label:", action_label)pose_model = init_pose_model(args.pose_config, args.pose_checkpoint,args.device)vis_frames = [vis_pose_result(pose_model, frame_paths[i], pose_results[i])for i in range(num_frame)]for frame in vis_frames:cv2.putText(frame, action_label, (10, 30), FONTFACE, FONTSCALE,FONTCOLOR, THICKNESS, LINETYPE)#vid = mpy.ImageSequenceClip([x[:, :, ::-1] for x in vis_frames], fps=fps)#vid.write_videofile(args.out_filename, fps=fps, remove_temp=True)"""*********************************************"""print(f"fps={fps}")fwidth = vis_frames[0].shape[1] # 视频的宽度fheight = vis_frames[0].shape[0] # 视频的高度print(f"fps={fps}")print(f"frame_w={fwidth},frame_h={fheight}")# *************************************************# 定义输出视频的基本信息fourcc = cv2.VideoWriter_fourcc(*'mp4v') # 定义编码器out_filename = args.out_filename # 输出文件名print(f"out_filename{out_filename}")# 创建VideoWriter对象video_writer = cv2.VideoWriter(out_filename, fourcc, fps, (fwidth, fheight))print(f"outputvideo{out_filename}")# 循环遍历每一帧,将它们写入视频文件for frame in vis_frames:video_writer.write(frame)# 释放VideoWriter对象video_writer.release()"""*********************************************"""tmp_frame_dir = osp.dirname(frame_paths[0])shutil.rmtree(tmp_frame_dir)# python demo/demo_skeleton.py --checkpoint work_dirs/stgcn++/stgcn++_ntu120_xsub_hrnet/j/best_top1_acc_epoch_13.pth按照指令运行的输出日志如下:
(pyskl) E:\5ModelCode\1Reference\6pyskl-main\win_pyskl\action_recognition-master>python demo/demo_skeleton.py --checkpoint work_dirs/stgcn++/stgcn++_ntu120_xsub_hrnet/j/best_top1_acc_e
poch_13.pth
load checkpoint from local path: work_dirs/stgcn++/stgcn++_ntu120_xsub_hrnet/j/best_top1_acc_epoch_13.pth
load checkpoint from http path: https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco-person/faster_rcnn_r50_fpn_1x_coco-person_20201216_175929-d022e2
27.pth
Performing Human Detection for each frame
[>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 59/59, 2.9 task/s, elapsed: 20s, ETA: 0sload checkpoint from http path: https://download.openmmlab.com/mmpose/top_down/hrnet/hr
net_w32_coco_256x192-c78dce93_20200708.pth
Performing Human Pose Estimation for each frame
[>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 59/59, 7.5 task/s, elapsed: 8s, ETA: 0s
action_label: wave2
load checkpoint from http path: https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w32_coco_256x192-c78dce93_20200708.pth
fps=25.0
fps=25.0
frame_w=600,frame_h=480
out_filenameresult.mp4
outputvideoresult.mp4
1.5.2 过程分析
该部分主要是根据demo_skeleton.py运行时的输出日志,分析得到动作标签中详细的过程及用到的模型,再深入到每一步模型的训练。
1、视频处理
使用OpenCV将视频解码为帧,并调整分辨率(短边缩放,默认是480,长边对应改变保持图像比例不变,比如输入w:h=180:144=1.25,resize之后就是new_w:new:h=600:480=1.25),具体在参数解析位置:
parser.add_argument( '--short-side', type=int, default=480, help='specify the short-side length of the image')
2、人体检测(Faster R-CNN模型)
-
模型:
faster_rcnn_r50_fpn_1x_coco-person(来自MMDetection) -
作用:检测每帧中的人体边界框,过滤得分低于0.9的检测结果。
-
权重文件加载:load checkpoint from http path: .../faster_rcnn_r50_fpn_1x_coco-person_20201216_175929-d022e227.pth
-
Performing Human Detection for each frame
3、姿态估计(HRNet模型)
-
模型:
hrnet_w32_coco_256x192(来自MMPose) -
作用:对检测到的人体进行17关键点估计。
-
权重文件加载:load checkpoint from http path: .../hrnet_w32_coco_256x192-c78dce93_20200708.pth
-
Performing Human Pose Estimation for each frame
4、姿态跟踪(算法处理)
-
方法:通过匈牙利算法(
linear_sum_assignment)跨帧跟踪同一个人,生成连续骨骼数据。 -
作用:确保不同帧中同一人的动作连贯性,为动作识别提供时序数据。
5、动作识别(ST-GCN++模型)
-
模型:
stgcn++_ntu120_xsub_hrnet(用户训练) -
作用:基于骨骼关键点的时空特征识别动作类型。
-
权重文件加载:load checkpoint from local path: .../best_top1_acc_epoch_13.pth
-
动作标签确定:action_label: wave2
6、结果渲染与输出
- 将动作标签
wave2叠加到姿态估计结果上,生成输出视频result.mp4。