IROS-2025 | OIKG:基于观察-图交互与关键细节引导的视觉语言导航

近日,博维资讯有限公司创新研发部和广东省智能科学与技术研究院脑机元宇宙数字融合联合实验室团队的研究成果“Observation-Graph Interaction and Key-Detail Guidance for Vision and Language Navigation”被机器人领域顶级国际会议IROS 2025(IEEE/RSJ International Conference on Intelligent Robots and Systems)录用,清华大学谢奕凡为文章第一作者,博维资讯有限公司欧彬凯为文章第二作者,广东省智能科学与技术研究院刘耀华为文章通讯作者。
我们经常在科幻电影里看到这样的情景,电影主人公对着家里的机器人说:“去厨房,看看冰箱里还有没有牛奶。” 机器人不仅准确走到了厨房,还在移动过程中避开了椅子,转身打开冰箱,并回答你:“还有半瓶。”现在这不是遥远的科幻,而是具身智能的下一站——视觉语言导航技术。
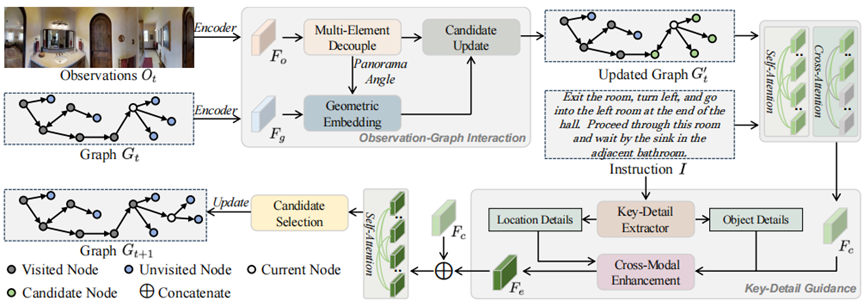
图1 OIKG的总体架构图
相比于传统的机器人导航技术,视觉语言导航要求智能体能够根据自然语言指令在全新且未知的环境中完成自主导航任务,这种具身导航方法不仅为更自然、更高效的人机交互铺平道路,也是实现通用人工智能的有效途径之一。然而,现有的视觉语言导航方法往往难以在导航过程中有效融合视觉观察与指令细节,导致路径规划欠佳且成功率有限。因此,我们提出了一种OIKG(观察图交互与关键细节引导)创新框架,通过两大核心组件解决上述问题:
观察图交互模块(Observation-graph Interaction Module):该模块通过几何嵌入将角度和视觉信息解耦,并加强导航空间中边的表示。具体来说,模块首先将观察特征分解为角度嵌入和视觉嵌入,然后通过三角公式计算相对角度差异,并将其与原始角度信息结合,生成最终的位置嵌入。这些位置嵌入与原始角度信息结合,更新候选节点的特征,从而生成更新后的图。
关键细节引导模块(Key-detail Guidance Module):该模块动态提取指令中的细粒度位置和对象信息,以实现更精确的视觉与语言对齐。模块使用大型语言模型(LLM)对R2R和RxR数据集的文本进行分类,总结出位置细节和对象细节两个词库。然后,模块根据这些词库从指令中提取相应的特征,并将它们融合以生成关键细节特征。通过交叉注意力机制和线性投影层,模块增强了智能体对导航线索和环境细节的理解。
实验部分在R2R和RxR数据集上进行,使用了多种评估指标,包括轨迹长度(TL)、导航误差(NE)、成功率(SR)和路径长度加权成功率(SPL)等。
实验证明,OIKG框架通过观察图交互和关键细节引导,显著提高了智能体在VLN任务中的导航能力。观察图交互模块通过解耦角度和视觉信息,减少了特征表示的干扰,并通过几何嵌入增强了边的表示。关键细节引导模块则通过动态提取指令中的细粒度信息,实现了更精确的视觉与语言对齐。结果表明,OIKG在多个数据集和评估指标上均优于现有方法,证明了其在提高导航精度和成功率方面的有效性。
