草稿未完成!Linux网络系统【文件传输】【I/O 多路复用】
文件传输:从IO瓶颈到零拷贝的性能优化全景解析
磁盘是计算机系统中速度最慢的硬件设备之一,其读写速度比内存慢百倍以上。这种巨大的速度差距,使得磁盘IO成为系统性能的核心瓶颈。为了突破这一限制,业界发展出了DMA、零拷贝、PageCache、异步IO等一系列优化技术。本文将从传统IO的底层逻辑出发,逐层解析这些技术的原理、应用场景及取舍逻辑,带你全面掌握文件传输的性能优化之道。
一、传统IO的困境:CPU被“绑定”的低效传输
在深入优化技术前,我们必须先理解传统IO的痛点。早期计算机中,磁盘与内存的数据传输完全依赖CPU,这种方式不仅效率低下,更浪费了宝贵的CPU资源。
1.1 传统IO过程:CPU的“苦力搬运”模式(结合传统IO过程图)
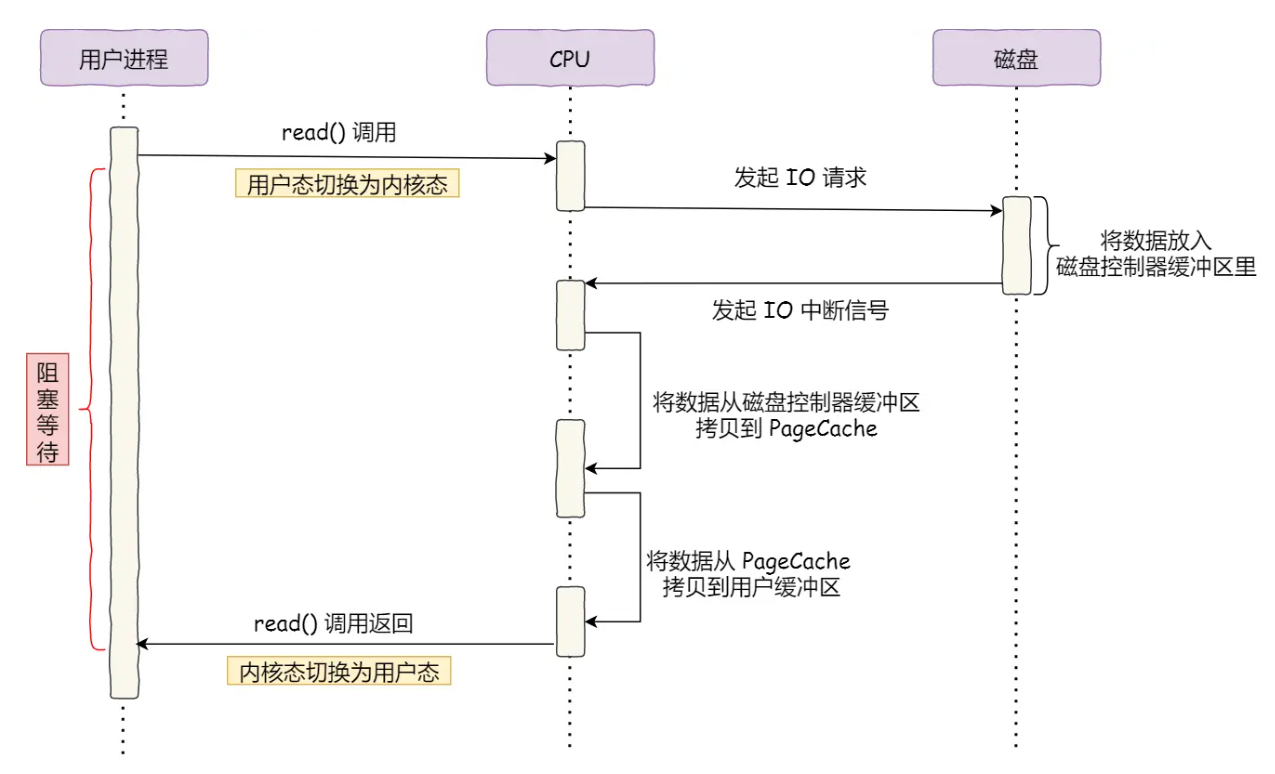
传统IO传输数据时,CPU扮演了“搬运工”和“指挥官”的双重角色,具体流程如下:
- 步骤1:CPU向磁盘控制器发送IO请求,明确读取数据的位置和长度。
- 步骤2:磁盘控制器开始读取数据,将数据暂存到自身缓冲区(磁盘本地缓存)。
- 步骤3:磁盘控制器缓冲区填满后,向CPU发送中断信号,告知“数据已就绪”。
- 步骤4:CPU收到中断后,暂停当前任务,将磁盘控制器缓冲区的数据逐个字节拷贝到CPU寄存器,再从寄存器写入内存。
- 步骤5:整个传输过程中,CPU被完全占用,无法执行其他任务。
这种模式下,即使传输GB级数据,CPU也必须全程参与搬运,导致“CPU资源被浪费在简单机械劳动上”的尴尬局面。在千兆网卡或高并发场景中,这种低效会直接拖垮系统性能。
1.2 传统文件传输的“四次切换+四次拷贝”灾难
以服务端向客户端传输文件为例,传统方式通过read()和write()两个系统调用实现,但背后隐藏着惊人的冗余开销(结合传统文件传输四次拷贝图):
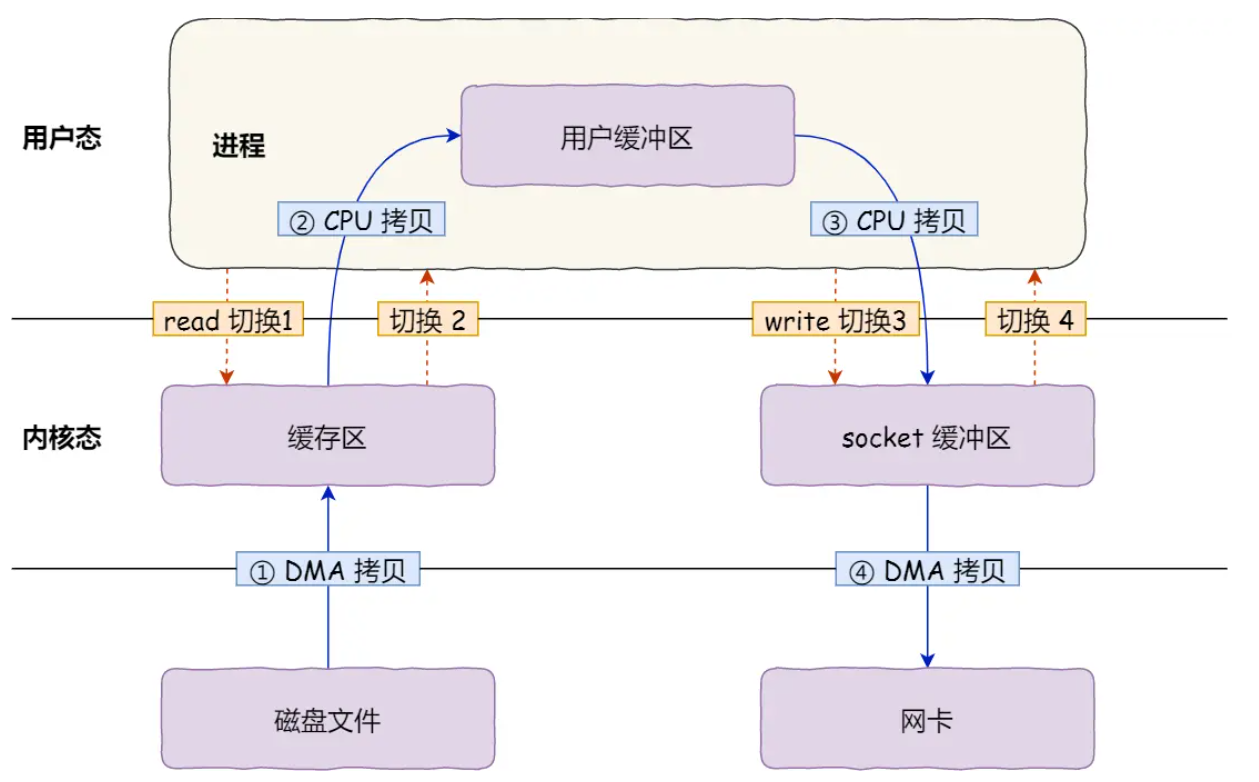
四次上下文切换:
每次系统调用都会引发“用户态→内核态→用户态”的切换,两次系统调用共产生4次切换:
read()调用:用户态→内核态(发起请求)→用户态(等待数据);write()调用:用户态→内核态(传输数据)→用户态(完成传输)。
虽然单次切换仅需几十纳秒到几微秒,但高并发场景下,切换开销会被无限放大。
四次数据拷贝:
数据从磁盘到网卡的传输过程中,经历4次拷贝,其中2次由CPU完成,2次由DMA完成:
- 第一次(DMA):磁盘数据→内核缓冲区(PageCache);
- 第二次(CPU):内核缓冲区→用户缓冲区(用户进程内存);
- 第三次(CPU):用户缓冲区→内核Socket缓冲区;
- 第四次(DMA):内核Socket缓冲区→网卡缓冲区。
核心问题:用户空间无权直接操作硬件(磁盘/网卡),必须通过内核中转,导致数据在用户态与内核态之间“来回搬运”。而多数场景下,用户进程仅需“传输数据”而非“加工数据”,用户缓冲区的存在完全是冗余的。
二、DMA技术:解放CPU的“专职搬运工”
为解决CPU被IO绑定的问题,直接内存访问(DMA)技术应运而生。DMA相当于“硬件级搬运工”,专门负责IO设备与内存的数据传输,CPU仅需发起请求和接收结果。
2.1 DMA的工作流程:CPU从“搬运工”变“指挥官”(结合DMA传输流程图)
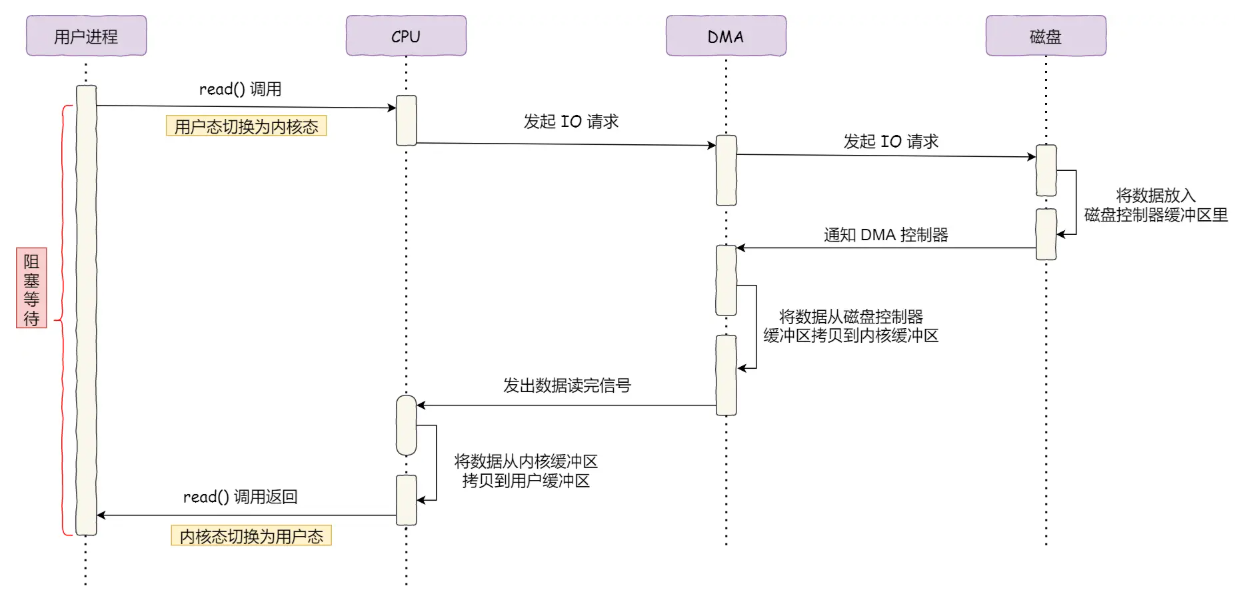
DMA传输涉及用户进程、CPU、DMA控制器、磁盘四个角色,具体流程如下:
- 用户进程发起请求:调用
read()系统调用,请求从磁盘读取数据到用户缓冲区,随后进入阻塞状态等待结果。 - CPU转发任务:操作系统CPU收到请求后,向DMA控制器下达指令(明确数据来源、目标地址、长度),随后继续执行其他任务(不再等待IO完成)。
- DMA与磁盘交互:
- DMA向磁盘控制器发送IO请求,磁盘开始读取数据并暂存到自身缓冲区;
- 当磁盘控制器缓冲区满时,向DMA发送中断信号,告知“数据就绪”。
- DMA搬运数据:DMA收到中断后,将磁盘控制器缓冲区的数据直接拷贝到内核缓冲区(PageCache),此过程无需CPU参与。
- 通知CPU完成:DMA完成数据搬运后,向CPU发送中断信号;CPU收到信号后,将内核缓冲区数据拷贝到用户缓冲区,唤醒阻塞的用户进程。
核心价值:CPU在DMA处理IO期间可执行其他任务,资源利用率大幅提升。但CPU并非完全“脱手”——数据传输的“指令规划”(传输什么、从哪到哪)仍需CPU完成。
三、零拷贝技术:消除冗余拷贝与切换的终极方案
零拷贝技术的核心目标是减少用户态与内核态的上下文切换和数据拷贝,针对传统IO的冗余开销精准优化。主流方案包括mmap+write和sendfile。
3.1 mmap+write:减少一次CPU拷贝
mmap()通过“内存映射”将内核缓冲区直接暴露给用户进程,避免了“内核→用户”的CPU拷贝。
函数调用与参数解析:
// 替代传统read()的mmap调用
void* mmap(void* addr, size_t length, int prot, int flags, int fd, off_t offset);
addr:指定映射地址(通常为NULL,由内核自动分配);length:映射长度(文件需传输的字节数);prot:映射权限(如PROT_READ表示可读);flags:映射类型(如MAP_SHARED表示内核与用户空间共享修改);fd:待映射的文件描述符;offset:文件内的起始映射位置。
返回值为映射到用户空间的内存地址(buf),后续可直接通过buf访问内核缓冲区数据。
传输流程(结合mmap传输流程图):
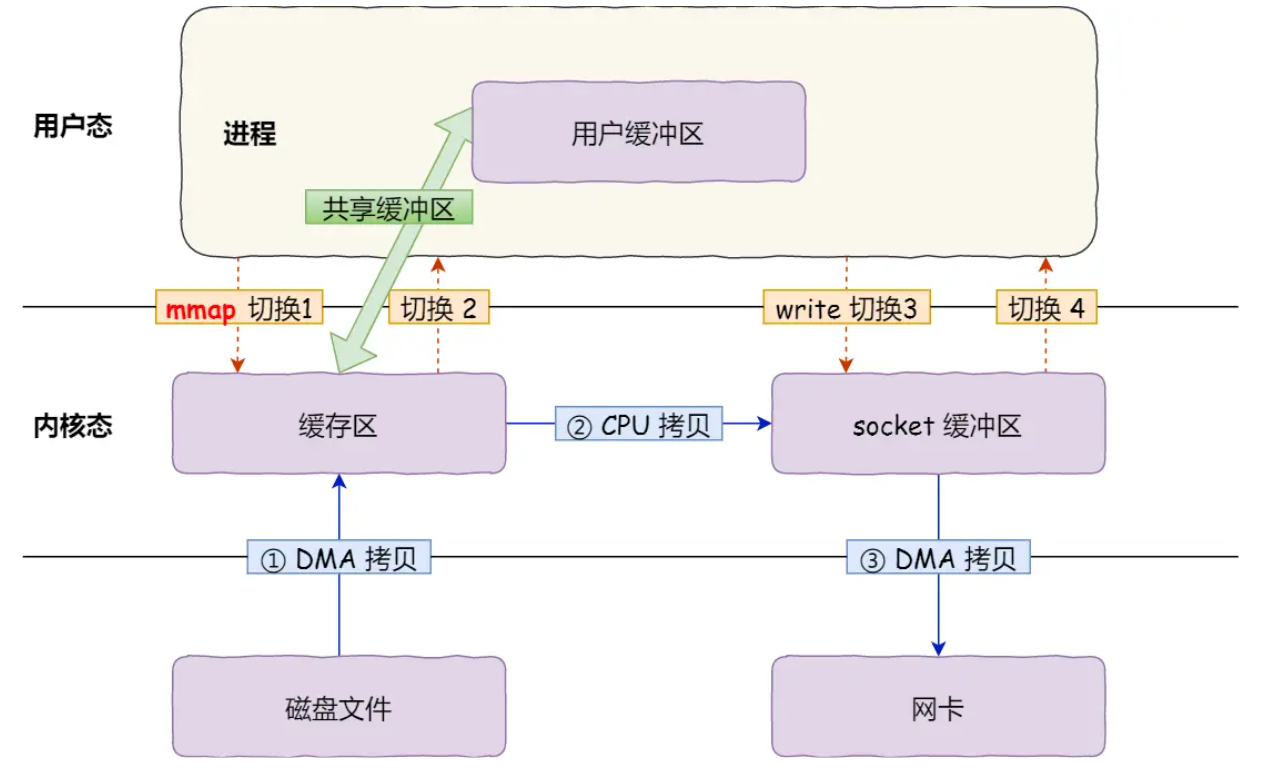
- mmap映射:调用
mmap(file, len)后,DMA将磁盘数据拷贝到内核缓冲区,内核与用户进程通过内存映射共享该缓冲区(无数据拷贝)。 - write传输:调用
write(sockfd, buf, len)时,CPU将共享的内核缓冲区数据拷贝到Socket缓冲区(内核态内操作)。 - DMA到网卡:Socket缓冲区数据通过DMA拷贝到网卡缓冲区,完成传输。
优化效果:
- 拷贝次数:从4次减少到3次(消除“内核→用户”的CPU拷贝);
- 上下文切换:仍为2次系统调用(
mmap+write),共4次切换; - 适用场景:需对数据进行简单加工后传输的场景(用户进程可直接操作共享缓冲区)。
3.2 sendfile:减少系统调用与CPU拷贝
Linux 2.1内核引入sendfile()系统调用,将read()和write()合并为一次调用,进一步减少切换和拷贝。
函数调用与参数解析:
#include <sys/socket.h>
ssize_t sendfile(int out_fd, int in_fd, off_t* offset, size_t count);
out_fd:目标文件描述符(如网卡Socket);in_fd:源文件描述符(如磁盘文件);offset:源文件内的起始传输位置(NULL表示从当前位置开始);count:传输数据长度;- 返回值:实际传输的字节数。
传输流程(结合sendfile传输流程图):
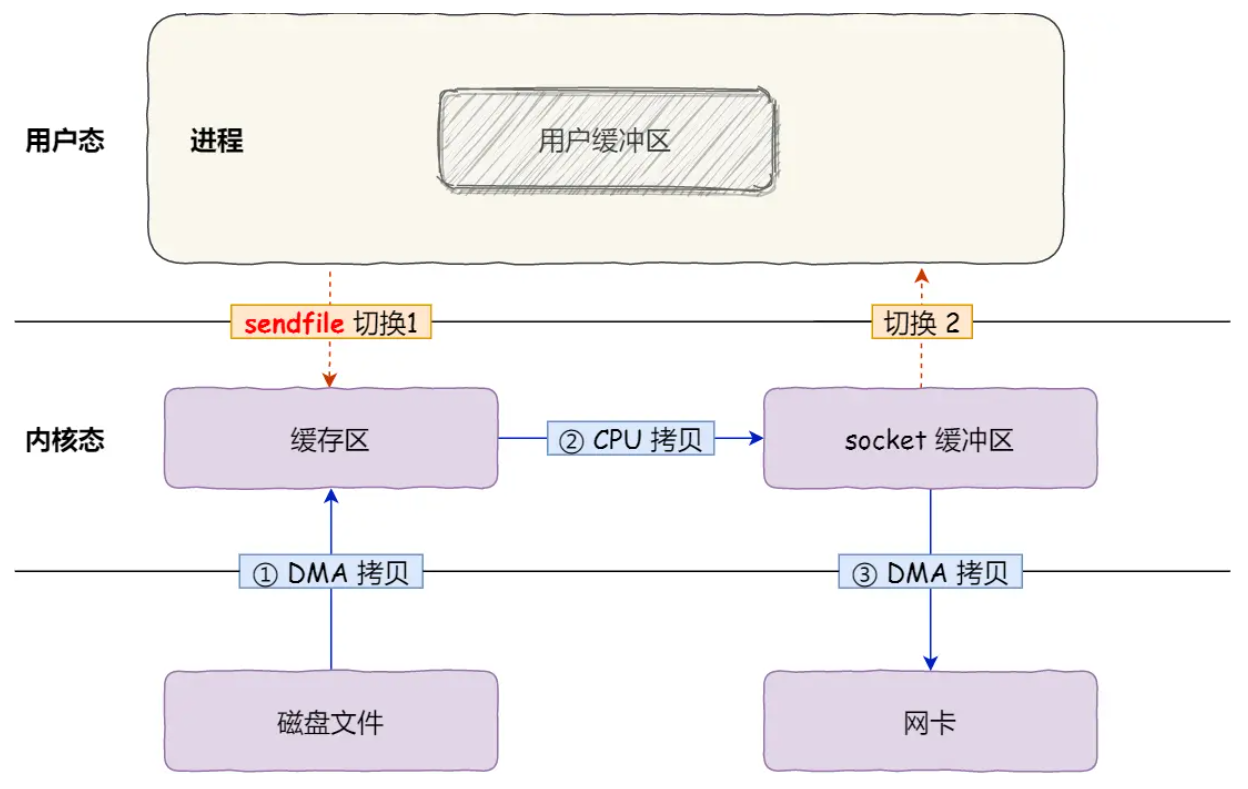
- 一次系统调用:
sendfile()替代read()+write(),上下文切换从4次减少到2次(用户态→内核态→用户态)。 - 内核内数据传输:DMA将磁盘数据拷贝到内核缓冲区后,CPU直接将内核缓冲区数据拷贝到Socket缓冲区(全程内核态操作,无用户态介入)。
进一步优化:SG-DMA技术
若网卡支持分散-聚集DMA(SG-DMA),可彻底消除“内核缓冲区→Socket缓冲区”的CPU拷贝:
- 原理:DMA直接从内核缓冲区读取数据并传输到网卡,无需中间拷贝;Socket缓冲区仅存储“数据地址和长度”的描述符,而非实际数据。
- 检查方法:通过
ethtool -k eth0 | grep scatter-gather查看,输出“scatter-gather: on”表示支持。
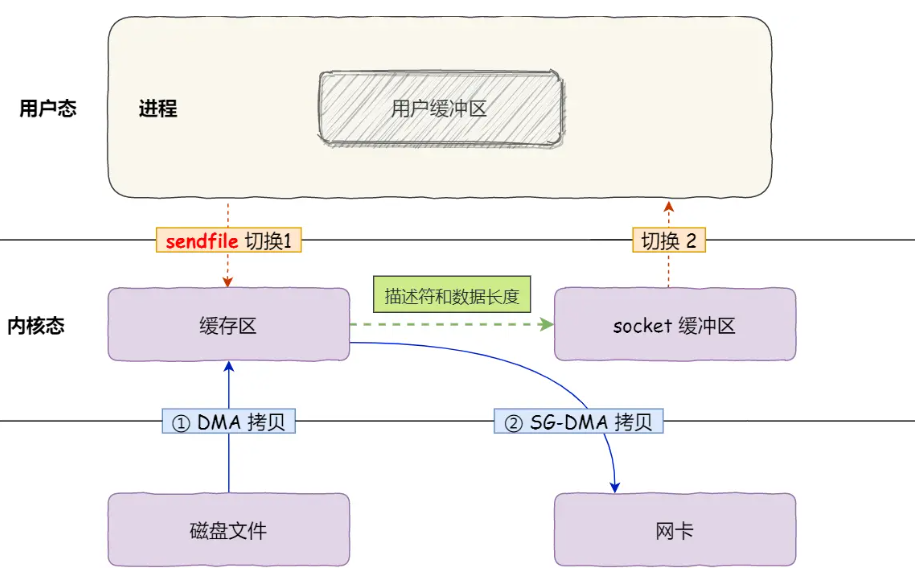
优化效果(SG-DMA加持下):
- 拷贝次数:仅2次(磁盘→内核缓冲区,内核缓冲区→网卡,均由DMA完成);
- 上下文切换:1次系统调用,共2次切换;
- CPU占用:全程无CPU参与数据拷贝,实现“真正的零拷贝”。
3.3 零拷贝的实际应用:Kafka与Nginx
零拷贝技术在高性能系统中应用广泛,典型案例如下:
Kafka:基于transferTo的高吞吐量
Kafka的Java NIO库中transferTo方法底层调用Linuxsendfile(),数据从磁盘直接通过内核传输到网卡,避免用户态介入。实测表明,零拷贝可缩短65%以上的文件传输时间,是Kafka支撑百万级消息吞吐量的核心能力之一。 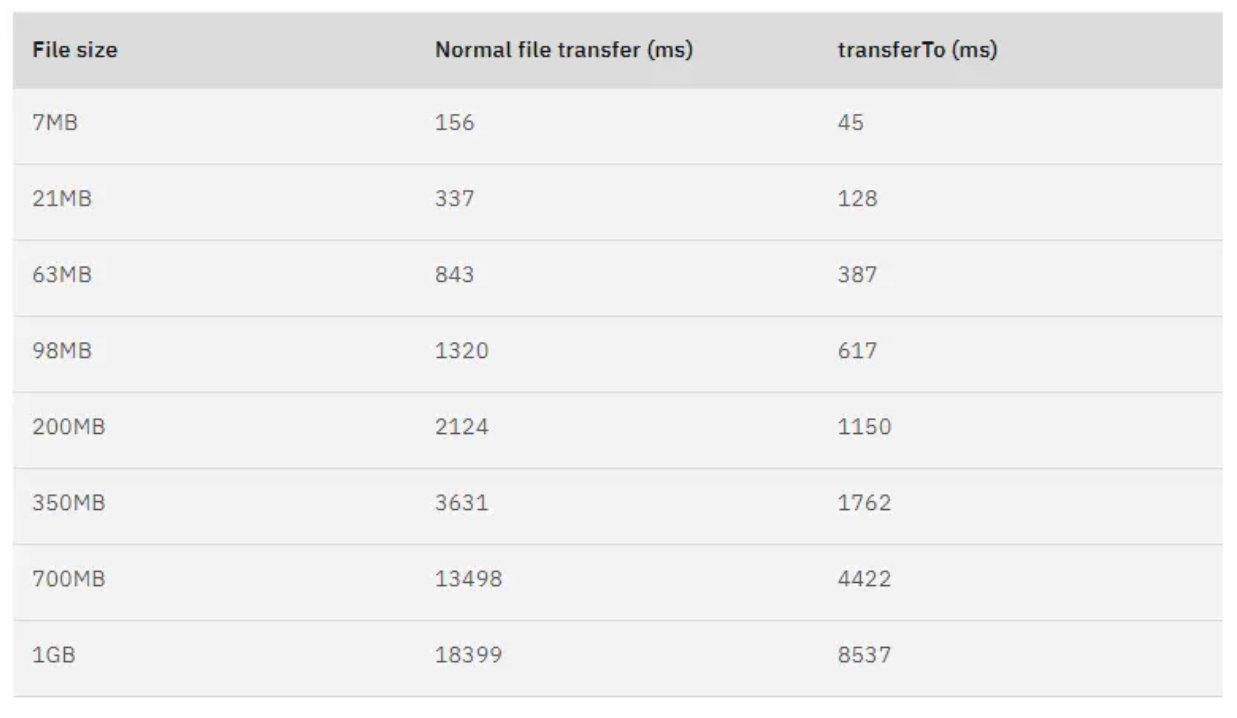
Nginx:通过配置启用零拷贝
Nginx通过sendfile配置项控制是否启用零拷贝:
http {...sendfile on; # 启用零拷贝(默认开启)tcp_nopush on; # 配合sendfile使用,累积数据后一次性发送,减少网络包数量...
}
sendfile on:使用sendfile()传输文件,2次上下文切换+2次DMA拷贝;sendfile off:使用传统read+write,4次切换+4次拷贝(2次CPU)。
四、PageCache:零拷贝的“性能加速器”
零拷贝技术的高效依赖于内核中的PageCache(磁盘高速缓冲区),它通过缓存和预读机制进一步放大性能优势。
4.1 PageCache的核心机制:缓存与预读
PageCache是内核在内存中开辟的缓冲区,用于缓存磁盘数据,核心功能包括:
(1)缓存最近访问的数据:基于局部性原理
程序运行具有局部性特征:
- 时间局部性:刚访问的数据短期内再次被访问的概率高(如循环读取配置文件);
- 空间局部性:访问某数据时,相邻数据被访问的概率高(如顺序读取日志文件)。
PageCache缓存最近访问的数据,当空间不足时,通过“LRU(最近最少使用)”算法淘汰最久未访问的缓存。读取数据时,优先命中PageCache(内存读),未命中再读磁盘,并将数据缓存到PageCache。
(2)预读功能:减少机械磁盘寻道耗时
机械磁盘的磁头寻道(旋转到数据所在扇区)耗时远高于数据读取,PageCache通过预读机制优化:
- 当进程读取032KB数据时,内核自动预读3264KB数据到PageCache;
- 若后续读取32~64KB数据,可直接从PageCache获取,避免再次寻道。
预读大小通常为“2的幂次”(如32KB、64KB),可通过/sys/block/<disk>/queue/read_ahead_kb调整。
4.2 PageCache的局限性:大文件传输的“陷阱”
大文件传输
虽然PageCache能显著提升小文件性能,但对GB级大文件传输可能适得其反:
调用read()读取大文件,进程实际上会阻塞在read()方法的调用上,因为需要 等待磁盘数据的返回:
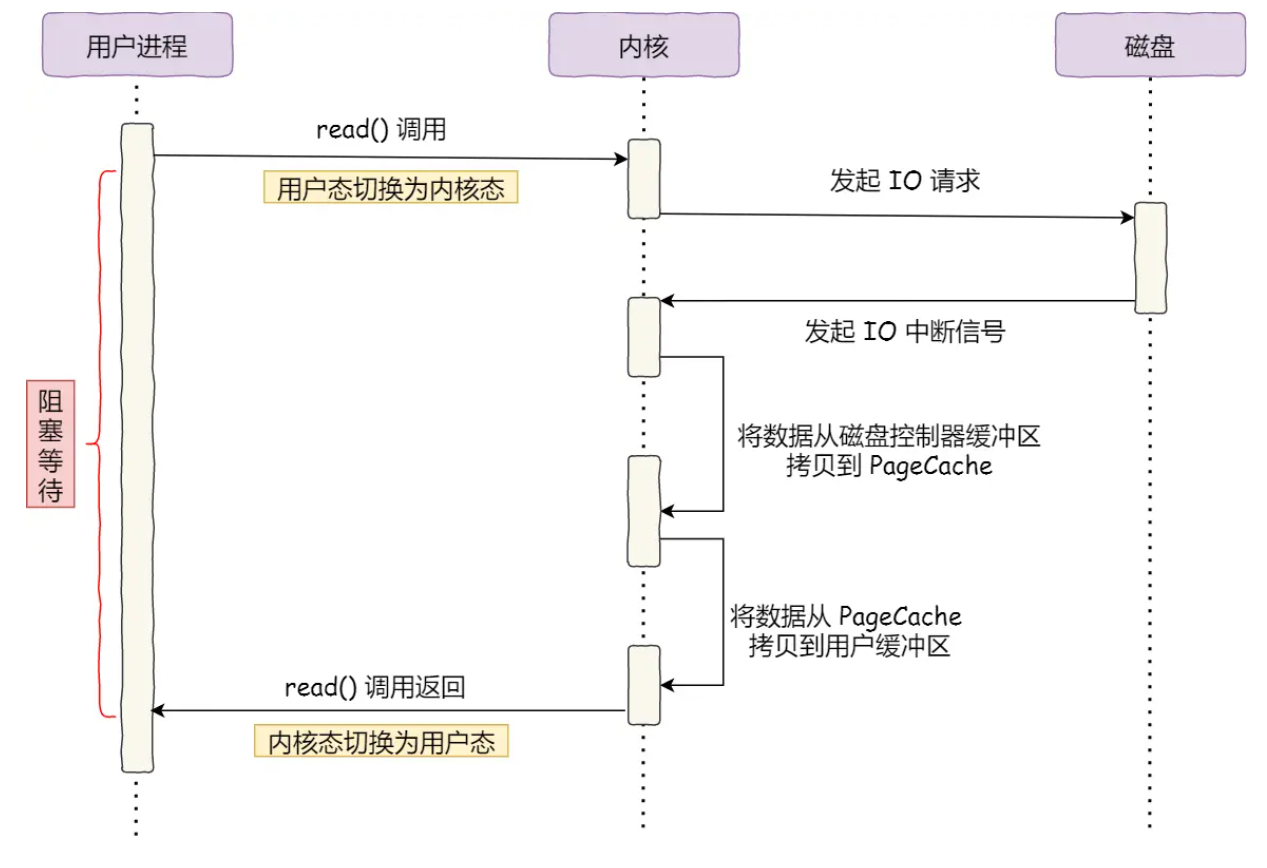
- 当用户进程进行系统调用read() 时,会阻塞着等待read()返回,
- 用户进程发起read()调用时,发生一次上下文切换,从用户态切换至内核态,
- 接着内核对磁盘发起I/O请求
- 磁盘收到请求后,开始寻址,当磁盘数据准备完毕后,会向内核发送I/O中断信号
- 内核收到I/O中断后,就将数据从磁盘控制器缓存区拷贝到PageCache
- 内核再将PageCache的数据拷贝到用户缓冲区,
- 最后read()调用返回,从内核态切换回用户态,用户进程才结束阻塞
这个过程中存在三个问题:
(1)缓存命中率低
大文件数据量庞大,访问后短期内再次被访问的概率极低,PageCache中的大文件数据多为“无效缓存”。
(2)挤占热点小文件缓存
大文件会快速占满PageCache空间,导致频繁访问的“热点小文件”(如配置文件、用户头像)无法缓存,被迫直接读磁盘,整体性能下降。
(3)额外的DMA拷贝开销
大文件数据从磁盘到PageCache的DMA拷贝未带来缓存收益,反而浪费IO资源。
五、大文件传输的优化:异步IO+直接IO
针对大文件传输场景,需绕过PageCache,采用“异步IO+直接IO”组合方案。
5.1 直接IO:绕开PageCache的传输方式
直接IO允许进程直接访问磁盘,无需经过PageCache,适用于:
- 应用层已实现缓存:如MySQL可通过
innodb_flush_method=O_DIRECT开启直接IO,避免PageCache二次缓存; - 大文件传输:减少PageCache占用,保障热点小文件性能。
5.2 异步IO:非阻塞的IO处理方式
传统IO中,进程会阻塞等待IO完成,而异步IO允许进程发起请求后继续执行其他任务,IO完成后通过信号或回调通知。
流程(结合异步IO流程图):
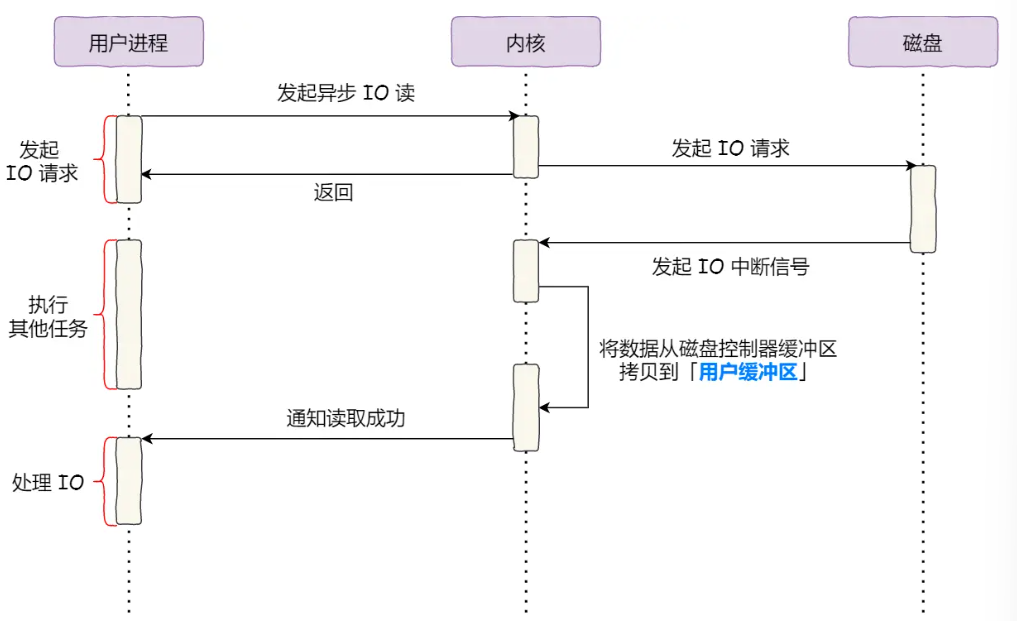
- 进程发起异步IO请求(如
aio_read),指定数据缓冲区、长度和通知方式(信号/回调),无需阻塞,继续执行后续逻辑; - 内核通过DMA将磁盘数据直接拷贝到用户缓冲区(直接IO模式);
- 数据传输完成后,内核通过信号或回调通知进程处理数据。
5.3 组合优势:异步IO+直接IO
- 无阻塞等待:进程无需阻塞在IO操作上,CPU利用率更高;
- 绕开PageCache:避免大文件挤占缓存,保障热点小文件性能;
- 适合大文件:大文件缓存命中率低,直接IO减少无效拷贝。
5.4 直接IO的局限性与补偿
直接IO绕开PageCache,失去了内核的两项关键优化:
- IO合并:内核IO调度算法会累积小IO请求,合并为大请求后发送,减少磁盘寻道;
- 预读:内核自动预读相邻数据到PageCache,提升顺序读性能。
因此,直接IO需在应用层实现类似优化(如手动合并请求、预读数据),适用于大文件等缓存命中率低的场景。
六、文件传输优化策略总结
根据文件大小和场景选择合适的传输方式,是高性能系统设计的核心原则:
| 场景 | 推荐技术 | 核心优势 | 局限性 |
|---|---|---|---|
| 小文件传输 | 零拷贝(sendfile+SG-DMA) | 高缓存命中率,低拷贝/切换开销 | 无法对数据加工(如压缩、加密) |
| 大文件传输 | 异步IO+直接IO | 避免PageCache占用,非阻塞处理 | 无内核缓存/预读优化,实现较复杂 |
| 通用Web服务器 | Nginx动态阈值配置 | 小文件用零拷贝,大文件自动切换异步IO | 需要根据业务调整阈值(如1MB) |
七、面试官可能的考察点与回答建议
考察点1:传统IO的性能瓶颈是什么?如何通过技术手段解决?
问题本质:考察对IO底层开销的理解,以及优化技术的核心思路。
回答思路:
- 传统IO的瓶颈:核心是“四次上下文切换”和“四次数据拷贝”。两次系统调用(
read+write)导致4次切换,数据在用户态与内核态之间来回拷贝,CPU参与两次冗余拷贝,资源浪费严重。 - 解决手段:
- DMA技术:将“磁盘→内核缓冲区”的拷贝交给DMA,解放CPU;
- 零拷贝技术:通过
mmap+write减少一次CPU拷贝,通过sendfile+SG-DMA消除所有CPU拷贝和多余切换; - 核心逻辑:减少用户态与内核态的交互(降低切换),避免数据在用户态与内核态之间的冗余拷贝。
考察点2:零拷贝技术有哪些实现方式?它们的区别是什么?
问题本质:考察对零拷贝具体方案的掌握,以及技术细节的对比。
回答思路:
- 两种主流方案:
mmap+write和sendfile。- mmap+write:
- 原理:通过内存映射将内核缓冲区共享给用户进程,避免“内核→用户”的CPU拷贝;
- 开销:2次系统调用(4次切换),3次拷贝(2次DMA+1次CPU);
- 适用场景:需对数据简单加工(如添加头部信息)的场景。
- sendfile:
- 原理:一次系统调用完成“读磁盘+写网卡”,全程内核态操作;
- 优化:配合SG-DMA可实现2次DMA拷贝(无CPU参与),2次上下文切换;
- 适用场景:纯文件传输(无需加工数据),如静态资源服务器。
- mmap+write:
- 核心区别:
mmap允许用户态访问数据,sendfile全程内核态操作,效率更高但灵活性更低。
考察点3:PageCache的作用是什么?为什么大文件传输不适合依赖PageCache?
问题本质:考察对PageCache机制的理解,以及缓存策略的场景适配能力。
回答思路:
- PageCache的核心作用:
- 缓存最近访问数据:利用程序局部性原理,将频繁访问的数据留在内存,减少磁盘IO;
- 预读优化:机械磁盘顺序读时,自动预读相邻数据到内存,减少磁头寻道次数。
- 大文件传输不适合依赖PageCache的原因:
- 缓存命中率低:大文件单次访问后再次访问的概率低,缓存收益有限;
- 挤占热点缓存:大文件占满PageCache后,频繁访问的“热点小文件”(如配置、日志)被迫读磁盘,整体性能下降;
- 无效拷贝开销:大文件数据从磁盘到PageCache的DMA拷贝未带来缓存收益,反而浪费IO资源。
考察点4:大文件传输为什么选择“异步IO+直接IO”?它们的原理是什么?
问题本质:考察对特殊场景优化策略的理解,以及技术取舍的逻辑。
回答思路:
- 大文件传输的痛点:零拷贝依赖PageCache,但大文件会导致PageCache失效,反而降低系统性能。
- 异步IO+直接IO的优势:
- 直接IO:绕开PageCache,避免大文件挤占缓存,减少无效DMA拷贝;
- 异步IO:进程发起IO后无需阻塞,可继续执行其他任务,提升CPU利用率。
- 原理补充:
- 直接IO:数据从磁盘直接拷贝到用户缓冲区,不经过PageCache;
- 异步IO:内核完成数据传输后通过信号/回调通知进程,避免阻塞等待。
- 适用场景:GB级大文件传输、应用层已实现缓存(如数据库)的场景。
考察点5:如何根据文件大小选择传输方式?实际项目中如何落地?
问题本质:考察技术落地能力,以及对场景适配的综合判断。
回答思路:
- 核心策略:按文件大小动态选择,平衡性能与资源占用:
- 小文件(<1MB):优先零拷贝(
sendfile),利用PageCache的高命中率和低开销; - 大文件(≥1MB):采用异步IO+直接IO,绕开PageCache,避免缓存污染。
- 小文件(<1MB):优先零拷贝(
- 实际落地案例:
- Nginx配置:通过
sendfile on启用零拷贝,结合client_body_buffer_size设置阈值,大文件自动切换为直接IO; - Kafka优化:小消息依赖PageCache和零拷贝,大文件通过配置调整PageCache策略,避免缓存失效。
- Nginx配置:通过
考察点6:零拷贝技术的局限性是什么?哪些场景不适合使用?
问题本质:考察对技术边界的理解,避免盲目套用优化方案。
回答思路:
- 零拷贝的局限性:
- 无法加工数据:数据全程在内核态传输,用户进程无法中途修改(如压缩、加密);
- 依赖PageCache:大文件或随机访问场景下,PageCache命中率低,优化效果打折;
- 硬件依赖:SG-DMA需要网卡支持,老设备可能无法启用最高效模式。
- 不适合的场景:
- 需要对数据加工的场景(如传输前压缩);
- 大文件传输(GB级以上);
- 随机IO密集型场景(如数据库随机读写)。
八、文件传输IO优化技术总结
一、早期IO的核心痛点:CPU被“绑定”的低效传输
早期IO操作中,内存与磁盘的数据传输完全依赖CPU完成:CPU不仅要发起IO请求,还要逐个字节将数据从磁盘控制器缓冲区搬运到内存,期间无法执行其他任务,导致CPU资源严重浪费。这种模式在海量数据传输场景(如千兆网卡、大容量硬盘)中效率极低,成为系统性能瓶颈。
二、DMA技术:解放CPU的“专职搬运工”
为解决CPU被IO绑定的问题,直接内存访问(DMA)技术应运而生:
- 核心逻辑:IO设备(如磁盘、网卡)配备独立的DMA控制器,CPU只需向DMA下达指令(传输数据的来源、目标、长度),后续数据搬运工作由DMA全程负责,CPU可专注于其他任务。
- 优势:CPU从“数据搬运工”转变为“指挥官”,大幅提升资源利用率,为后续IO优化奠定基础。
三、传统文件传输的瓶颈:四次切换与四次拷贝
基于DMA的传统文件传输(如read()+write())仍存在严重冗余:
- 四次上下文切换:
read()和write()两次系统调用,每次调用引发“用户态→内核态→用户态”的切换,共4次切换,高并发场景下开销被放大。 - 四次数据拷贝:数据从磁盘到网卡需经历4次拷贝(2次DMA拷贝:磁盘→内核缓冲区、内核Socket缓冲区→网卡;2次CPU拷贝:内核缓冲区→用户缓冲区、用户缓冲区→内核Socket缓冲区),CPU参与的冗余拷贝浪费资源。
四、零拷贝技术:减少切换与拷贝的终极优化
零拷贝技术通过减少用户态与内核态交互、消除冗余拷贝,显著提升传输性能,主流方案包括两种:
-
mmap+write:
- 用
mmap()替代read(),将内核缓冲区直接映射到用户空间,实现内核与用户空间的内存共享,减少“内核缓冲区→用户缓冲区”的CPU拷贝。 - 仍需2次系统调用(4次切换)和3次拷贝(2次DMA+1次CPU),适用于需简单加工数据的场景。
- 用
-
sendfile:
- 一次系统调用合并“读磁盘+写网卡”操作,减少为2次上下文切换;配合网卡支持的SG-DMA技术,可消除所有CPU拷贝,仅保留2次DMA拷贝(磁盘→内核缓冲区、内核缓冲区→网卡)。
- 全程内核态操作,无用户态介入,是“真正的零拷贝”,适用于纯文件传输场景。
五、零拷贝的基石:PageCache的作用与局限
零拷贝性能依赖于内核的磁盘高速缓存(PageCache):
-
PageCache的优势:
- 缓存最近访问数据:利用程序局部性原理(刚访问的数据短期内再次被访问的概率高),将频繁访问数据留在内存,减少磁盘IO;
- 预读优化:机械磁盘读取时,自动预读相邻数据到内存,减少磁头寻道耗时(顺序读性能优于随机读的核心原因)。
-
PageCache的局限性:
- 对GB级大文件传输效果有限:大文件单次访问后再次访问的概率低,缓存命中率低,且会挤占“热点小文件”(如配置文件、日志)的缓存空间,导致整体性能下降;
- 大文件的数据从磁盘到PageCache的DMA拷贝属于无效开销,未带来缓存收益。
六、大文件传输的优化:异步IO+直接IO
针对大文件传输场景,需绕开PageCache,采用“异步IO+直接IO”组合方案:
-
直接IO:数据从磁盘直接拷贝到用户缓冲区,不经过PageCache,避免大文件挤占缓存;
-
异步IO:进程发起IO请求后无需阻塞等待,可继续执行其他任务,内核完成数据传输后通过信号/回调通知进程,提升CPU利用率。
-
局限性:直接IO绕开PageCache,失去内核的IO合并(累积小请求为大请求,减少磁盘寻道)和预读优化,需在应用层手动补偿(如合并请求、预读数据)。
七、实际应用与场景适配
-
零拷贝的典型应用:
- Kafka:通过Java NIO的
transferTo方法底层调用sendfile,实现数据从磁盘到网卡的零拷贝传输,支撑百万级消息吞吐量; - Nginx:默认启用
sendfile on配置,小文件传输依赖零拷贝,可通过设置文件大小阈值,自动为大文件切换“异步IO+直接IO”。
- Kafka:通过Java NIO的
-
场景适配原则:
- 小文件(<1MB):优先选择零拷贝(
sendfile+SG-DMA),利用PageCache的高命中率提升性能; - 大文件(≥1MB):采用“异步IO+直接IO”,避免PageCache污染;
- 需加工数据的场景(如压缩、加密):选择
mmap+write,允许用户态访问数据。
- 小文件(<1MB):优先选择零拷贝(
八、核心结论
文件传输IO优化的本质是减少无效交互(上下文切换)和冗余拷贝:
- DMA技术解决了CPU参与数据搬运的问题;
- 零拷贝技术通过合并系统调用、消除用户态与内核态拷贝,大幅提升小文件传输效率;
- PageCache的缓存与预读机制进一步放大零拷贝优势,但需警惕大文件对缓存的挤占;
- 大文件传输需结合异步IO与直接IO,平衡性能与资源占用。
速记版本(核心要点)
- 早期痛点:CPU全程参与数据搬运,低效且浪费资源。
- DMA:IO设备的“专职搬运工”,CPU仅发指令,解放资源。
- 传统IO问题:4次上下文切换+4次拷贝(2次CPU+2次DMA),冗余开销大。
- 零拷贝技术:
- mmap+write:减少1次CPU拷贝,仍需4次切换;
- sendfile+SG-DMA:1次调用、2次切换、2次DMA拷贝(无CPU参与)。
- PageCache:缓存+预读提升性能,但大文件易挤占缓存,降低命中率。
- 大文件优化:异步IO(非阻塞)+直接IO(绕开PageCache)。
- 应用:Kafka/Nginx用零拷贝;Nginx可设阈值适配大小文件。