手写DQN (FrozenLake环境)
成功截图

伪代码

实现
框架
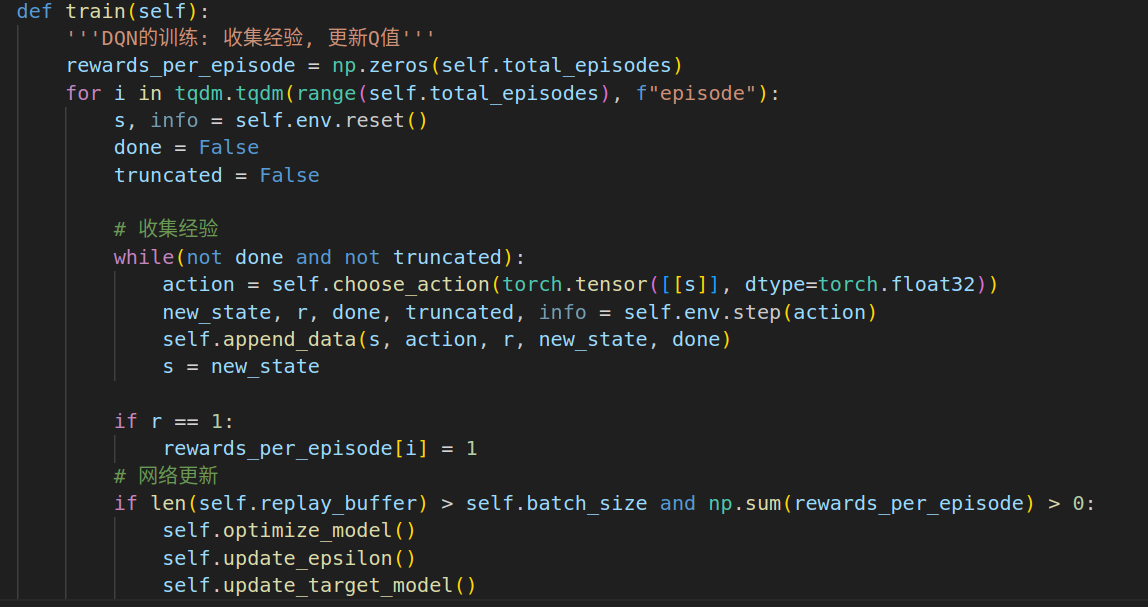
总体思路: 先在一个回合里进行经验收集, 然后进行模型的优化.
模型优化
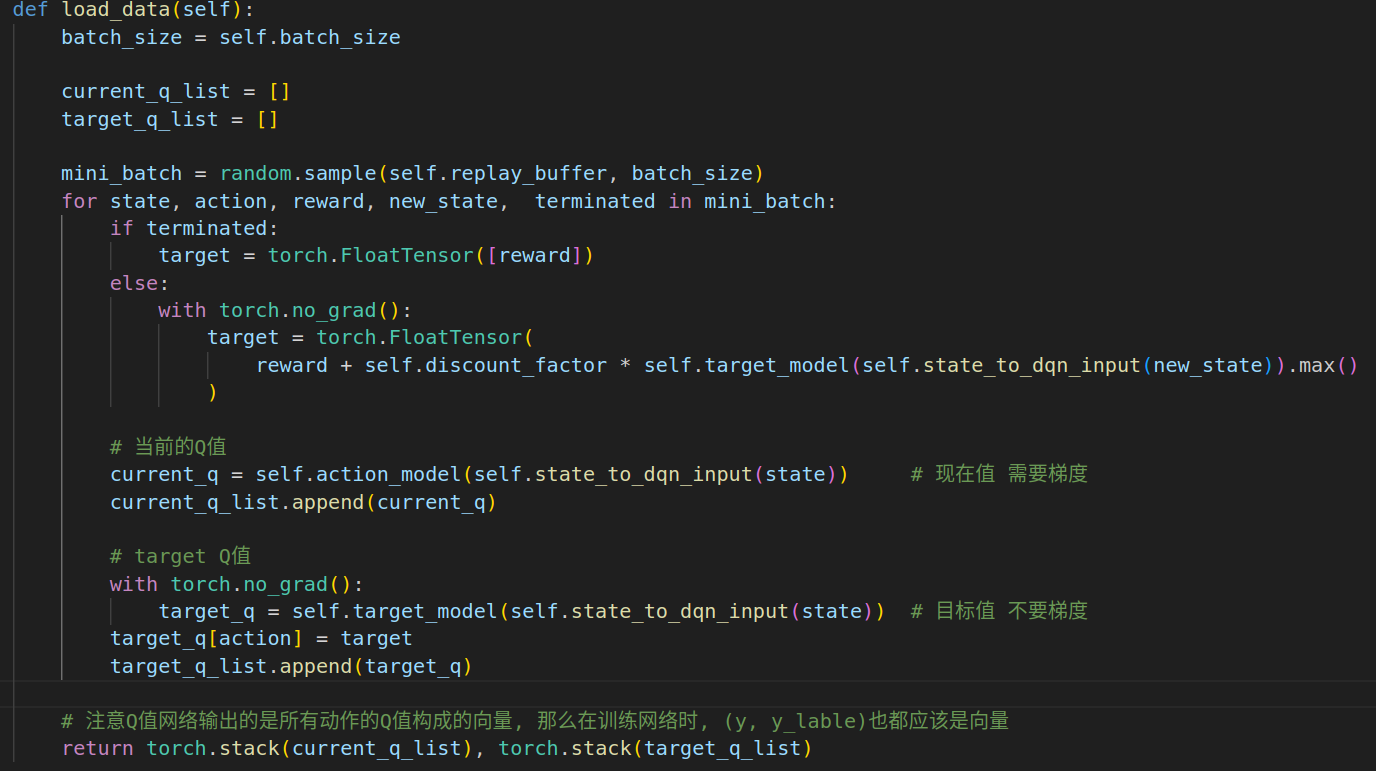
1. 计算一个批次的原始q与目标q
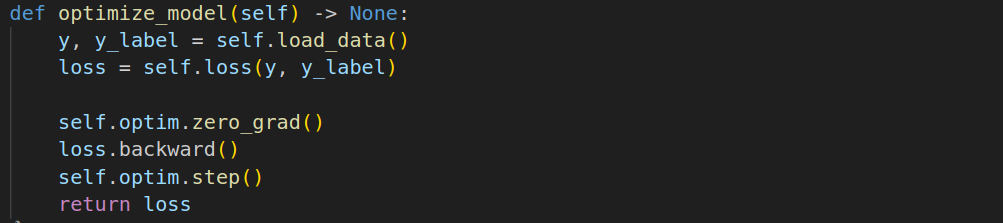
2. 进行反向传播优化
完整代码
import torch
import torch.nn as nn
import numpy as np
import gymnasium as gym
from collections import deque
import random
import copy
import tqdmclass DQN:def __init__(self, env, total_episodes):#############超参数#############self.lr = 0.01 # !!!!!!!!这简单的模型调lr都很有影响 如果lr太小了 + epsilion很快趋于0 探索停止了, 那么就很容易掉进局部最优解了self.batch_size = 32self.initial_epsilion = 1 # epsilion 和 discount_factor 很有影响!!!!!!!!!!!!self.discount_factor = 0.9self.network_sync_rate = 10self.memory_size = 1000self.total_episodes = total_episodes#############DQN的核心要件#############self.replay_buffer = deque(maxlen=self.memory_size)# 训练采经验是action_model 优化的也是action_model, 测试也是用action_model (on-policy实现)self.action_model = nn.Sequential(nn.Linear(env.observation_space.n, env.observation_space.n), nn.ReLU(),nn.Linear(env.observation_space.n, env.action_space.n),)self.target_model = copy.deepcopy(self.action_model)############优化组件#############self.loss = torch.nn.MSELoss()self.optim = torch.optim.Adam(self.action_model.parameters(), lr=self.lr) # 算法运行中间量self.env = envself.epsilon = self.initial_epsilionself.step = 0# epsilon历史记录self.epsilon_history = []def choose_action(self, state: torch.Tensor) -> torch.Tensor:'''基于epsilon-greedy的策略'''self.step += 1if random.random() < self.epsilon:action = env.action_space.sample()else:with torch.no_grad():action = self.action_model(self.state_to_dqn_input(state)).argmax().item() return actiondef train(self):'''DQN的训练: 收集经验, 更新Q值'''rewards_per_episode = np.zeros(self.total_episodes)for i in tqdm.tqdm(range(self.total_episodes), f"episode"):s, info = self.env.reset()done = Falsetruncated = False# 收集经验while(not done and not truncated):action = self.choose_action(torch.tensor([[s]], dtype=torch.float32))new_state, r, done, truncated, info = self.env.step(action)self.append_data(s, action, r, new_state, done)s = new_stateif r == 1:rewards_per_episode[i] = 1# 网络更新if len(self.replay_buffer) > self.batch_size and np.sum(rewards_per_episode) > 0:self.optimize_model() self.update_epsilon() self.update_target_model()def state_to_dqn_input(self, state):'''将标量的状态转为向量'''state = int(state)input_tensor = torch.zeros(16)input_tensor[state] = 1return input_tensordef append_data(self, s, a, r, new_s, done):'''将经验存入replay_buffer中'''self.replay_buffer.append((s, a, r, new_s, done))def optimize_model(self) -> None:y, y_label = self.load_data() loss = self.loss(y, y_label)self.optim.zero_grad()loss.backward()self.optim.step()return lossdef update_epsilon(self) -> None: self.epsilon = max(0, self.epsilon-1/self.total_episodes) def update_target_model(self):if self.step > self.network_sync_rate:self.step = 0self.target_model.load_state_dict(self.action_model.state_dict())def load_data(self):batch_size = self.batch_sizecurrent_q_list = []target_q_list = []mini_batch = random.sample(self.replay_buffer, batch_size)for state, action, reward, new_state, terminated in mini_batch: if terminated:target = torch.FloatTensor([reward])else:with torch.no_grad():target = torch.FloatTensor(reward + self.discount_factor * self.target_model(self.state_to_dqn_input(new_state)).max())# 当前的Q值current_q = self.action_model(self.state_to_dqn_input(state)) # 现在值 需要梯度 current_q_list.append(current_q)# target Q值with torch.no_grad():target_q = self.target_model(self.state_to_dqn_input(state)) # 目标值 不要梯度 target_q[action] = targettarget_q_list.append(target_q)# 注意Q值网络输出的是所有动作的Q值构成的向量, 那么在训练网络时, (y, y_lable)也都应该是向量 return torch.stack(current_q_list), torch.stack(target_q_list)# 训练
env = gym.make("FrozenLake-v1", is_slippery=False)
policy = DQN(env, total_episodes=1000)
policy.train()# 测试
env = gym.make("FrozenLake-v1", render_mode="human", is_slippery=False)
s, info = env.reset()
while True:action = policy.action_model(policy.state_to_dqn_input(s)).argmax().item()s, r, done, truncated, info = env.step(action)if done or truncated:s, info = env.reset()经验
简单的模型调lr很有影响 如果lr太小了 + epsilion很快趋于0 探索停止了, 那么就很容易掉进局部最优解了
epsilion的变化需要心中有数
Q值网络输出的是所有动作的Q值构成的向量, 那么在训练网络时, (y, y_lable)也都应该是向量