vLLM 基准测试与性能测试框架:全面解析LLM推理性能评估体系
在大语言模型(LLM)蓬勃发展的当下,模型推理性能的评估已成为系统优化与应用落地的关键环节。vLLM 作为高性能 LLM 推理引擎,其配套的基准测试与性能测试框架为业界提供了一套全面且灵活的评估解决方案。该框架不仅涵盖了从在线服务到离线吞吐量的多维度测试场景,还整合了多样化的数据集管理与精细化的性能指标体系,为科研人员与工程实践提供了强有力的工具支撑。
基准测试架构:多组件协同的评估体系
vLLM的基准测试体系采用了模块化设计,主要包含三大核心组件:基准测试工具、数据集管理系统以及后端支持系统。各模块既独立承担特定功能,又通过标准化接口实现数据交互与流程衔接。这种架构设计体现了软件工程中"关注点分离"的设计原则,使得整个系统既具备了良好的可扩展性,又保持了高度的灵活性。

vLLM 支持多种基准测试场景,包括在线服务基准测试(Online Serving Benchmarks)、离线吞吐量基准测试(Offline Throughput Benchmarks)以及延迟基准测试(Latency Benchmarks)。每种测试场景都针对不同的应用需求和性能关注点进行了专门的优化。
在 vllm github (https://github.com/vllm-project/vllm/tree/main/benchmarks)中的 benchmarks 目录下可以查看到这些源代码。
接下来,挑选一下比较重要的测试工具及方法进行介绍。
核心测试工具矩阵
• 在线服务基准测试(benchmark_serving.py):聚焦于模拟真实负载下的 API 服务性能,支持并发请求模式、多样化流量分布(如基于泊松或伽马分布的请求速率配置)以及全链路延迟测量。该工具通过
asyncio.Semaphore实现并发控制,并基于服务级别目标(SLO)计算有效吞吐量(Goodput),可兼容 vLLM、OpenAI、TGI、TensorRT-LLM 等多种推理引擎。• 离线吞吐量测试(benchmark_throughput.py):在无网络开销的场景下测量批量请求处理的最大吞吐量,适用于硬件评估与容量规划。工具支持 vLLM 的同步/异步推理接口、Hugging Face 模型以及 DeepSpeed-MII 等后端,可输出每秒请求数(requests/second)、每秒token数(tokens/second)等核心指标,并支持 JSON 格式结果输出以便后续分析。
• 延迟基准测试(benchmark_latency.py):通过统计分析单批次处理延迟,为模型基线性能特征分析提供数据支撑,适用于不同硬件配置或优化策略的对比测试。
专业化辅助工具
• 前缀缓存效率测试(benchmark_prefix_caching.py):针对 vLLM 的前缀缓存优化技术,通过对比共享提示前缀场景下的性能差异,量化缓存机制对推理效率的提升效果。
• 请求优先级测试(benchmark_prioritization.py):评估基于优先级的请求调度策略,通过为请求分配随机优先级并测量吞吐量影响,验证调度算法在混合负载场景下的有效性。
数据集管理:多样化场景的测试数据支撑
vLLM 基准测试框架构建了灵活的数据集管理体系,支持从真实场景到自定义需求的多维度测试数据生成与加载,确保评估结果的全面性与针对性。
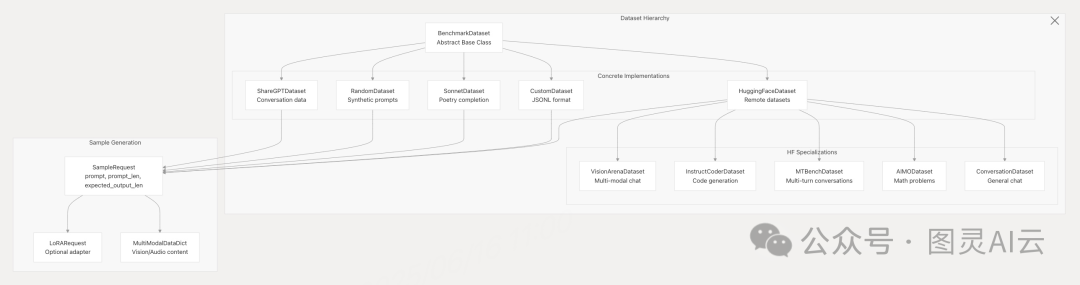
基准测试系统通过 BenchmarkDataset 抽象基类及其实现,支持多种数据集类型。例如:
数据集 | 格式 | 用例 | 多模态 |
ShareGPT | JSON 对话 | 通用聊天评估 | ❌ |
Random | 合成 | 压力测试、控制实验 | ❌ |
Sonnet | 文本行 | 诗歌 / 创意文本 | ❌ |
Custom | JSONL | 用户提供的提示 | ❌ |
VisionArena | HuggingFace | 视觉 - 语言评估 | ✅ |
InstructCoder | HuggingFace | 代码生成 | ❌ |
MTBench | HuggingFace | 多轮对话 | ❌ |
AIMO | HuggingFace | 数学推理 | ❌ |
ASR | HuggingFace | 音频转录 | ✅ |
数据集类型与应用场景
数据集类型 | 数据格式 | 典型应用场景 | 配置示例 |
ShareGPT | JSON 对话数据 | 真实聊天工作负载测试 | --dataset-name sharegpt --dataset-path ShareGPT_V3_unfiltered_cleaned_split.json |
Random | 合成token序列 | 可控输入/输出长度的性能测试 | --dataset-name random --input-len 1024 --output-len 128 |
Sonnet | 文本行数据 | 诗歌创作等创意生成场景测试 | --dataset-name sonnet --prefix-len 50 |
Custom | JSONL 提示数据 | 用户自定义场景测试 | --dataset-name custom --dataset-path user_prompts.jsonl |
HuggingFace | 远程数据集 | 专业化基准测试(如多模态) | --dataset-name hf --dataset-path lmarena-ai/VisionArena-Chat |
数据模型设计
框架定义了统一的 SampleRequest 数据结构,包含提示文本(prompt)、提示长度(prompt_len)、预期输出长度(expected_output_len)等核心字段,同时支持扩展字段如 LoRA 适配器配置(LoRARequest)与多模态数据(MultiModalDataDict),为跨模态模型评估提供了标准化接口。
性能指标体系:精细化量化推理效率
vLLM 基准测试框架构建了覆盖延迟、吞吐量、服务质量的多维度指标体系,通过统计学方法与业务目标结合,实现对模型推理性能的深度剖析。
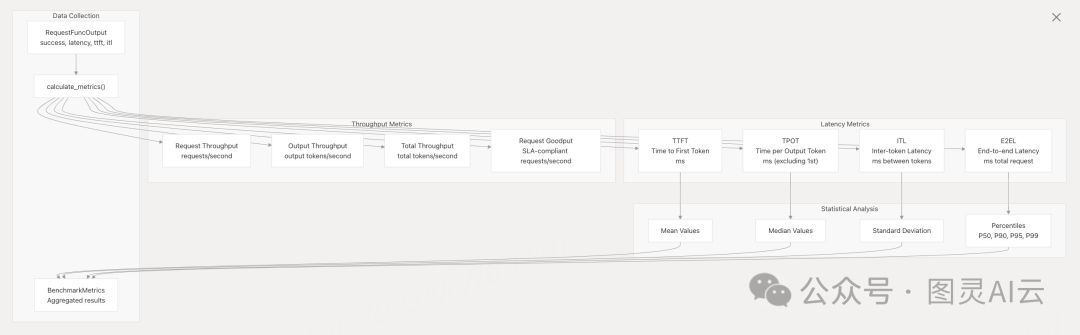
通过 BenchmarkMetrics 数据类,收集了包括吞吐量、延迟、令牌生成时间等在内的多项关键指标。例如:
指标类别 | 指标 | 描述 |
吞吐量 | request_throughput、 | 每秒处理的请求数和令牌数 |
延迟 | mean_ttft_ms、 | 首个令牌生成时间统计 |
令牌生成 | mean_tpot_ms、 | 每个输出令牌的时间(不包括第一个) |
令牌间延迟 | mean_itl_ms、 | 令牌间延迟测量 |
端到端 | mean_e2el_ms、 | 完整请求延迟 |
质量 | request_goodput | 符合 SLA 要求的请求数 |
核心延迟指标
• 首token时间(Time to First Token, TTFT):从请求发起至第一个输出token生成的时间,直接影响用户交互的即时反馈体验。
• 单token生成时间(Time per Output Token, TPOT):排除首token时间后,后续每个token的平均生成时间,反映模型持续推理的效率。
• token间延迟(Inter-token Latency, ITL):相邻token生成的时间间隔,用于分析推理过程的稳定性。
• 端到端延迟(End-to-end Latency, E2EL):从请求发送到完整响应生成的总时间,衡量系统整体处理效率。
吞吐量与服务质量指标
• 请求吞吐量(Request Throughput):每秒处理的请求数,反映系统并发处理能力。
• 输出吞吐量(Output Throughput):每秒生成的输出token数,衡量模型生成效率。
• 总吞吐量(Total Throughput):每秒处理的总token数(提示+输出),用于评估系统整体负载能力。
• 有效吞吐量(Request Goodput):基于 SLO 标准(如 TTFT≤100ms、E2EL≤1000ms)计算的合规请求速率,更贴近实际业务场景下的服务质量要求。
统计分析方法
框架支持均值、中位数、标准差等基础统计量计算,并提供 P50、P90、P95、P99 等百分位值,全面刻画性能指标的分布特征,避免单一平均值对极端情况的掩盖。
多后端支持与请求函数接口
vLLM 基准测试框架通过统一的请求函数接口(ASYNC_REQUEST_FUNCS)实现对多推理后端的兼容,支持包括 vLLM、OpenAI、TGI、TensorRT-LLM、DeepSpeed-MII 等在内的多种引擎,便于科研人员进行跨系统性能对比。
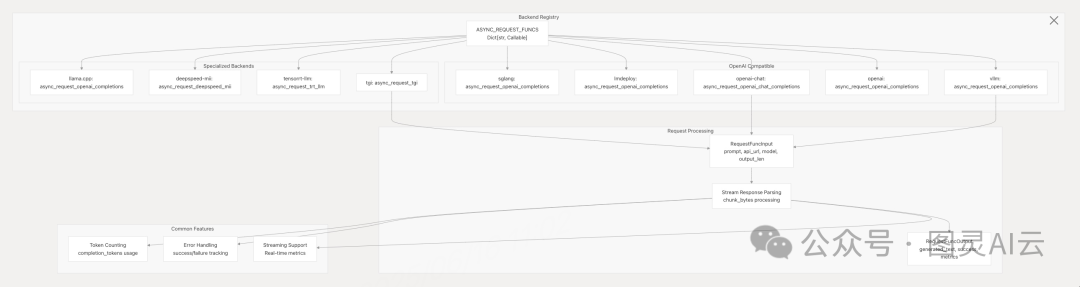
接口标准化设计
• 输入模型(RequestFuncInput):统一封装提示文本、API 地址、模型参数等请求参数,支持流式响应解析与错误处理。
• 输出模型(RequestFuncOutput):标准化返回生成文本、请求状态、延迟指标(TTFT、ITL 等),确保不同后端的指标可比性。
• 流式处理支持:实时收集token级延迟指标,为细粒度性能分析提供数据基础。
# Example from backend_request_func.py
@dataclass
classRequestFuncInput:prompt: strapi_url: strprompt_len: intoutput_len: intmodel: str# ... additional fields@dataclass
classRequestFuncOutput:generated_text: str = ""success: bool = Falselatency: float = 0.0ttft: float = 0.0# Time to first tokenitl: list[float] = field(default_factory=list) # Inter-token latencies# ... additional metrics实战应用:从命令行到场景化测试
典型测试用例
在线服务基准测试(ShareGPT 数据集)
python3 benchmarks/benchmark_serving.py \--backend vllm \--model NousResearch/Hermes-3-Llama-3.1-8B \--endpoint /v1/completions \--dataset-name sharegpt \--dataset-path ShareGPT_V3_unfiltered_cleaned_split.json \--num-prompts 1000 \--request-rate 10.0 \--max-concurrency 50离线吞吐量测试(随机数据集)
python3 benchmarks/benchmark_throughput.py \--model NousResearch/Hermes-3-Llama-3.1-8B \--backend vllm \--dataset-name random \--input-len 1024 \--output-len 128 \--num-prompts 1000多模态模型评估(VisionArena 数据集)
python3 benchmarks/benchmark_serving.py \--backend openai-chat \--model Qwen/Qwen2-VL-7B-Instruct \--endpoint /v1/chat/completions \--dataset-name hf \--dataset-path lmarena-ai/VisionArena-Chat \--num-prompts 100延迟基准测试
python benchmarks/benchmark_latency.py \--model NousResearch/Hermes-3-Llama-3.1-8B \--input-len 512 \--output-len 128 \--batch-size 8 \--num-iters 50总结
vLLM 的基准测试与性能测试框架通过系统化的架构设计、多样化的测试工具、精细化的指标体系,为大语言模型推理性能评估提供了“科研级”的解决方案。该框架不仅满足了学术研究中不同优化策略的对比需求,还为工程落地中的硬件选型、容量规划、服务质量保障提供了数据支撑。随着 LLM 应用场景的不断拓展,此类兼具灵活性与严谨性的基准测试体系,将成为推动模型效率优化与产业落地的重要基础设施。
如需深入了解框架实现细节,可访问 vLLM 官方文档:https://deepwiki.com/vllm-project/vllm/4.2-benchmarking-and-performance-testing,获取完整的代码实现与配置说明。