c语言进阶 自定义类型 (结构体 位段)
自定义类型
- 结构体
- 1. 结构体的声明
- 1.1 结构的基础知识
- 2. 结构的声明
- 2.1 方法 1:先声明类型,再定义变量
- 2.2 方法 2:声明类型的同时定义变量
- 3. 匿名结构体类型
- 3.1基本用法
- 3.2关键特性:类型不兼容
- 4. 结构体的自引用
- 4.1 为什么不能包含同类型变量?
- 4.2 正确用法:包含同类型指针
- 4.3 实际应用:链表
- 5. 结构体变量的初始化
- 5.1基本初始化
- 5.2嵌套结构体的初始化
- 6. 结构体内存对齐(详细计算与多示例)
- 6.1 对齐规则(以VS为例,默认对齐数为8)
- 6.2示例1:struct S1 { char c1; int i; char c2; }
- 步骤1:分析各成员偏移量
- 步骤2:计算总大小
- 用offsetof宏验证
- 6.3 示例2:基础类型成员(char, short, int)
- 步骤1:分析各成员偏移量
- 步骤2:计算总大小
- 6.4 示例 3:含 long 和 double 的结构体
- 步骤1:分析各成员偏移量
- 步骤2:计算总大小
- 用 offsetof 宏验证计算结果
- 7. 嵌套结构体的内存对齐
- 7.1 示例1:嵌套基础结构体
- 步骤1:分析各成员偏移量
- 步骤2:计算总大小
- 7.2 示例 2:多层嵌套结构体
- 步骤 1:计算最内层 struct S4 的总大小
- 步骤 2:计算中间层 struct S5 的总大小
- 步骤 3:计算外层 struct S6 的总大小
- 步骤4:计算总大小
- 8. 内存对齐的原因与优化
- 原因
- 优化:减少空间浪费
- 9. 结构体传参
- 传值:传递结构体拷贝
- 传址:传递结构体地址
- 位段
- 1. 什么是位段
- 2. 位段的内存分配
- 示例1:int类型位段(struct A)
- 示例2:char类型位段(struct S)
- **步骤 1:内存分配过程**
- **步骤 2:赋值后的比特存储(以 VS 为例,从右向左分配比特)**
- 4. 位段的跨平台问题
- 位段在网络协议中的典型应用:IP 头部解析
- 1. 网络协议的痛点:固定长度的比特字段
- 2. IP 头部的位段实现
结构体
1. 结构体的声明
1.1 结构的基础知识
结构体是 C 语言中用于描述复杂对象的自定义类型,它可以将不同类型的数据(如字符、整数、浮点数等)组合成一个整体,以表示一个事物的多个属性。
-
为什么需要结构体?
现实中很多事物无法用单一类型描述(如学生有姓名、年龄、成绩等),结构体可以将这些相关但不同类型的属性 “打包”,便于管理和操作。 -
示例场景:
描述一个学生,需要包含字符串类型的姓名、整数类型的年龄、浮点数类型的成绩,这些数据无法用单一变量或数组存储,因此用结构体整合:
// 用结构体整合学生的多个属性
struct Student {char name[20]; // 姓名(字符串类型)int age; // 年龄(整数类型)float score; // 成绩(浮点数类型)
};
2. 结构的声明
结构体的声明是 “描述类型” 的过程,需明确结构体名称和成员列表。声明后可通过两种方式创建变量:
2.1 方法 1:先声明类型,再定义变量
先描述结构体的 “样子”(成员组成),再根据类型创建具体变量。
// 声明结构体类型(仅描述,不占用内存)
struct Student {char name[20]; // 成员1:姓名int age; // 成员2:年龄float score; // 成员3:成绩
};// 根据类型定义变量(此时分配内存)
struct Student s1; // 定义学生
s1
struct Student s2; // 定义学生s2
- 说明:
truct Student是一个完整的类型名,s1和s2是该类型的变量,各自占用独立的内存空间。
2.2 方法 2:声明类型的同时定义变量
在声明结构体类型时,直接创建变量,适用于临时或仅需少量变量的场景。
// 声明类型的同时定义变量s3、s4
struct Student {char name[20];int age;float score;
} s3, s4; // s3和s4是struct Student类型的变量
- 说明:
s3和s4与方法 1 中的s1、s2类型完全相同,只是定义时机不同。
3. 匿名结构体类型
匿名结构体是省略名称的结构体,只能在声明时定义变量,且成员相同也视为不同类型:
3.1基本用法
// 匿名结构体1:无名称,声明时定义变量x
struct {int a; // 成员1char b; // 成员2
} x;// 匿名结构体2:成员与x的结构体相同,但类型不同
struct {int a;char b;
} y;
3.2关键特性:类型不兼容
即使两个匿名结构体的成员完全一致,编译器也会将它们视为不同的类型,因此不能相互赋值::
// 错误示例:x和y类型不同,无法赋值
x = y; // 错误:编译器提示"类型不兼容"4. 结构体的自引用
结构体自引用指包含同类型的结构体指针(不能包含同类型变量,否则会无限递归),常用于链表等数据结构。
4.1 为什么不能包含同类型变量?
错误示例:包含同类型变量
// 错误:结构体包含自身变量,导致大小无法计算
struct Node {int data;struct Node next; // next内部又包含struct Node,无限嵌套
};
// sizeof(struct Node) 无法计算(大小无穷大)
4.2 正确用法:包含同类型指针
指针的大小是固定的(32 位系统 4 字节,64 位系统 8 字节),因此包含指针不会导致大小问题:
正确示例:
// 正确:包含同类型指针(指针大小固定,不会无限递归)
struct Node {int data; // 节点存储的数据struct Node* next; // 指向同类型下一个节点的指针
};
4.3 实际应用:链表
通过自引用的结构体指针,可以将多个节点串联成链表:
#include <stdio.h>
#include <stdlib.h>int main() {// 创建3个节点struct Node* n1 = (struct Node*)malloc(sizeof(struct Node));struct Node* n2 = (struct Node*)malloc(sizeof(struct Node));struct Node* n3 = (struct Node*)malloc(sizeof(struct Node));// 初始化节点数据并串联n1->data = 10; n1->next = n2; // n1指向n2n2->data = 20; n2->next = n3; // n2指向n3n3->data = 30; n3->next = NULL; // n3指向NULL(链表结束)// 遍历链表struct Node* cur = n1;while (cur != NULL) {printf("%d ", cur->data); // 输出:10 20 30cur = cur->next;}// 释放内存(省略)return 0;
}
5. 结构体变量的初始化
结构体声明不占用内存,定义变量并初始化后才分配内存。初始化需按成员顺序赋值,嵌套结构体用{}单独初始化。
5.1基本初始化
格式:struct 结构体名 变量名 = { 成员1值, 成员2值, ... };
struct Student {char name[20];int age;float score;
};// 初始化Student变量s(按成员顺序赋值)
struct Student s = {"张三", 18, 90.5f};
// 此时s占用内存:name="张三",age=18,score=90.5
5.2嵌套结构体的初始化
若结构体内包含另一个结构体成员,初始化时需在内部用{}单独指定嵌套结构体的成员值:
// 声明嵌套的结构体(生日)
struct Birth {int year;int month;int day;
};// 声明包含嵌套结构体的Person
struct Person {char name[10];struct Birth b; // 嵌套的Birth结构体int id;
};// 初始化Person变量p(嵌套结构体b用{}初始化)
struct Person p = {"李四", // name成员{2001, 3, 15}, // 嵌套的b成员(year=2001, month=3, day=15)1002 // id成员
};6. 结构体内存对齐(详细计算与多示例)
结构体内存对齐是指结构体成员在内存中的存储位置需遵循特定规则,并非简单按顺序排列。以下通过多个示例详细说明计算过程。
6.1 对齐规则(以VS为例,默认对齐数为8)
- 第一个成员必须放在结构体偏移量为0的地址。
- 其他成员的偏移量必须是“对齐数”的整数倍。
- 对齐数 = min(编译器默认对齐数, 成员自身大小)
- 结构体总大小必须是所有成员最大对齐数的整数倍。
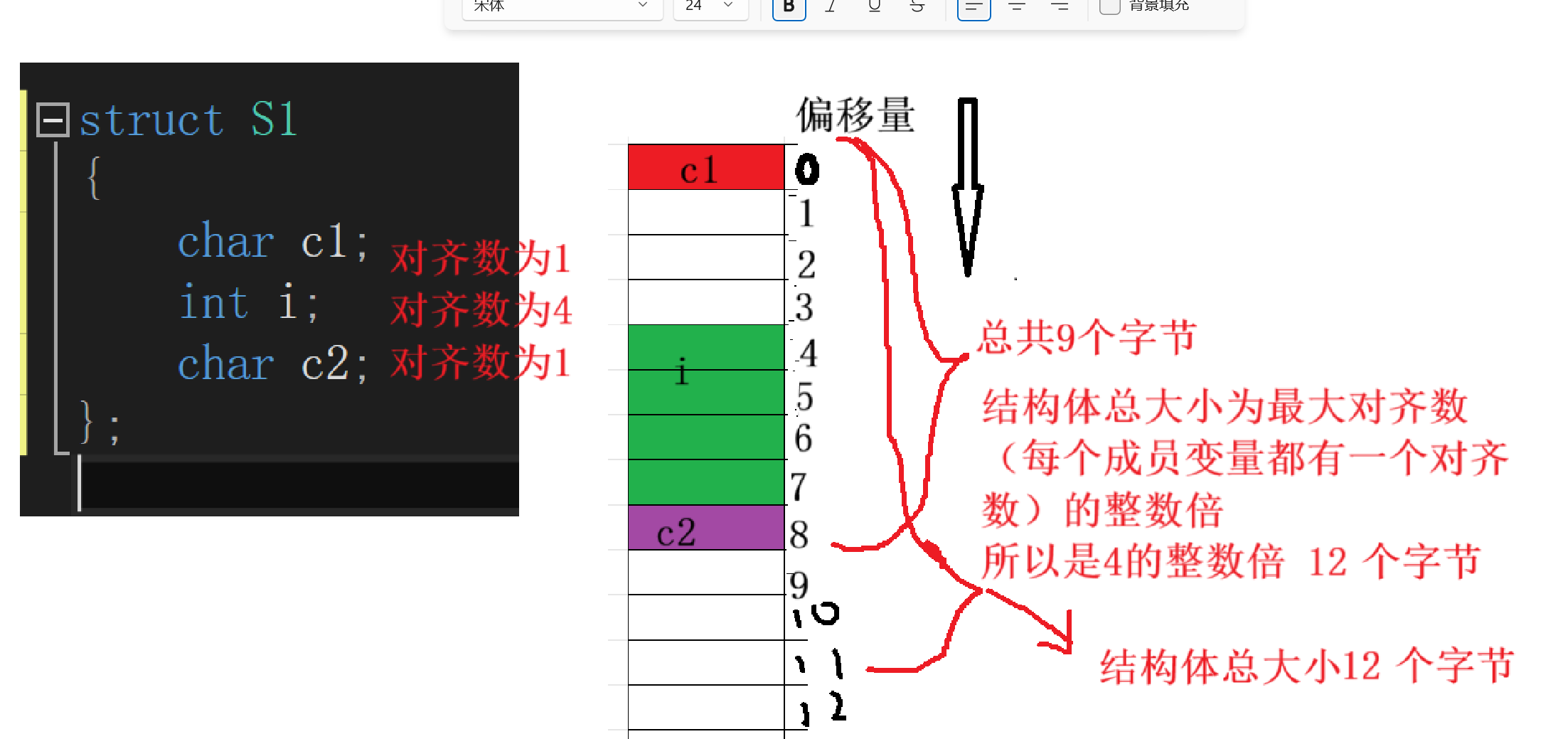
6.2示例1:struct S1 { char c1; int i; char c2; }
struct S1 {
char c1;int i; char c2; }
步骤1:分析各成员偏移量
- c1(char,1字节):
第一个成员,偏移量0(0是1的整数倍),占用地址0。 - i(int,4字节):
对齐数=min(8,4)=4,需对齐到4的整数倍。前一个成员占0,下一个4的整数倍是4,故i偏移量为4,占用4~7。 - c2(char,1字节):
对齐数=min(8,1)=1,需对齐到1的整数倍。前一个成员占7,下一个1的整数倍是8,故c2偏移量为8,占用8。
步骤2:计算总大小
目前占用0~8(9字节),最大对齐数为4。9不是4的倍数,向上取整为12,故sizeof(struct S1)=12。
用offsetof宏验证
offsetof宏(需包含 <stddef.h>)可直接获取成员的偏移量,用于验证计算:
#include <stdio.h>
#include <stddef.h>struct S1 { char c1; int i; char c2; };int main() {printf("c1偏移量:%d\n", offsetof(struct S1, c1)); // 0printf("i偏移量:%d\n", offsetof(struct S1, i)); // 4printf("c2偏移量:%d\n", offsetof(struct S1, c2)); // 8printf("S1总大小:%d\n", sizeof(struct S1)); // 12return 0;
}6.3 示例2:基础类型成员(char, short, int)
结构体定义:
struct S1 {char c; // 1字节short s; // 2字节int i; // 4字节
};
步骤1:分析各成员偏移量
- 成员 c(char,1 字节):
- 第一个成员,偏移量 0(满足规则 1),占用地址 0。
- 成员 s(short,2 字节):
- 对齐数 =
min (8, 2) = 2 - 需对齐到 2 的整数倍地址。前一个成员占用到 0,下一个 2 的整数倍是 2,故 s 的 偏移量为 2,占用地址 2~3(2 字节)。
- 对齐数 =
- 成员 i(int,4 字节):
- 对齐数 =
min (8, 4) = 4 - 需对齐到 4 的整数倍地址。前一个成员占用到 3,下一个 4 的整数倍是 4,故 i 的偏移量为 4,占用地址 4~7(4 字节)。
- 对齐数 =
步骤2:计算总大小
- 总大小计算:
- 已占用地址 0~23(24 字节)。
- 最大对齐数为 8(l 和 d 的对齐数)。
- 24 是 8 的整数倍,故
sizeof(struct S2) = 24。
6.4 示例 3:含 long 和 double 的结构体
结构体定义:
struct S2 {char c; // 1字节long l; // 4字节(32位)或8字节(64位,此处以8字节为例)double d; // 8字节
};
步骤1:分析各成员偏移量
计算步骤(64 位环境,long 为 8 字节):
-
成员 c(char,1 字节):
- 偏移量 0,占用地址 0。
-
成员 l(long,8 字节):
- 对齐数 = min (8, 8) = 8
- 需对齐到 8 的整数倍地址。前一个成员占用到 0,下一个 8 的整数倍是 8,故 l 的偏移量为 8,占用地址 8~15(8 字节)。
-
成员 d(double,8 字节):
- 对齐数 = min (8, 8) = 8
- 需对齐到 8 的整数倍地址。前一个成员占用到 15,下一个 8 的整数倍是 16,故 d 的偏移量为 16,占用地址 16~23(8 字节)。
步骤2:计算总大小
- 已占用地址 0~23(24 字节)。
- 最大对齐数为 8(l 和 d 的对齐数)。
- 24 是 8 的整数倍,故
sizeof(struct S2) = 24。
用 offsetof 宏验证计算结果
#include <stdio.h>
#include <stddef.h>struct S1 { char c; short s; int i; };int main() {printf("c偏移量:%d\n", offsetof(struct S1, c)); // 输出0(正确)printf("s偏移量:%d\n", offsetof(struct S1, s)); // 输出2(正确)printf("i偏移量:%d\n", offsetof(struct S1, i)); // 输出4(正确)printf("S1总大小:%d\n", sizeof(struct S1)); // 输出8(正确)return 0;
}
7. 嵌套结构体的内存对齐
当结构体内包含另一个结构体时,嵌套的结构体视为一个“整体成员”,其对齐规则需额外注意:
- 嵌套结构体的对齐数 = 其内部成员的最大对齐数
- 嵌套结构体的偏移量必须是自身最大对齐数的整数倍
- 整个结构体的总大小 = 所有成员(含嵌套结构体)最大对齐数的整数倍
7.1 示例1:嵌套基础结构体
结构体定义:
// 内部结构体S1(已计算:大小8字节,最大对齐数4)
struct S1 {
char c;
short s;
int i;
};// 包含嵌套结构体的S3
struct S3 {char a; // 1字节struct S1 s; // 嵌套结构体int b; // 4字节
};
步骤1:分析各成员偏移量
- c1(char,1字节):
- 偏移量0,占用0。
- 成员 s(struct S1 类型):
- 嵌套结构体 S1 的最大对齐数为 4(其内部 i 的对齐数)。
- 需对齐到 4 的整数倍地址。前一个成员占用到 0,下一个 4 的整数倍是 4,故 s 的偏移量为 4,占用地址 4~11(8 字节,S1 的大小)。
- 成员 b(int,4 字节):
- 对齐数 = min (8, 4) = 4。
- 需对齐到 4 的整数倍地址。前一个成员占用到 11,下一个 4 的整数倍是 12,故 b 的偏移量为 12,占用地址 12~15(4 字节)。
步骤2:计算总大小
- 已占用地址 0~15(16 字节)。
- 所有成员的最大对齐数为 4(S1 的最大对齐数和 b 的对齐数)。
- 16 是 4 的整数倍,故
sizeof(struct S3) = 16。
7.2 示例 2:多层嵌套结构体
结构体定义:
// 最内层结构体
struct S4 {short s; // 2字节int i; // 4字节char c; // 1字节
};// 中间层结构体(包含S4)
struct S5 {double d; // 8字节struct S4 s; // 嵌套S4
};// 外层结构体(包含S5)
struct S6 {char a; // 1字节struct S5 s; // 嵌套S5
};
步骤 1:计算最内层 struct S4 的总大小
成员分析
- 成员 s(short 类型,2 字节):
- 对齐数 = min (VS 默认 8, 2) = 2
- 第一个成员,偏移量 0,占用地址 0~1(2 字节)。
- 成员 i(int 类型,4 字节):
- 对齐数 = min (8, 4) = 4
- 需对齐到 4 的整数倍地址,前一个成员占 1,下一个 4 的整数倍是 4,故偏移量 4,占用地址 4~7(4 字节)。
- 成员 c(char 类型,1 字节):
- 对齐数 = min (8, 1) = 1
- 需对齐到 1 的整数倍地址,前一个成员占 7,下一个 1 的整数倍是 8,故偏移量 8,占用地址 8(1 字节)。
- 总大小计算
- 已占用地址:0~8(共 9 字节)
- 最大对齐数:4(成员 i 的对齐数)
- 总大小需为 4 的整数倍,9 向上取整为 12
- 结论:
sizeof(struct S4) = 12
步骤 2:计算中间层 struct S5 的总大小
成员分析
- 成员 d(double 类型,8 字节):
- 对齐数 = min (8, 8) = 8
- 第一个成员,偏移量 0,占用地址 0~7(8 字节)。
- 成员 s(struct S4 类型):
- 嵌套结构体 S4 的最大对齐数 = 其内部最大对齐数 4(成员 i 的对齐数)
- 需对齐到 4 的整数倍地址,前一个成员占 7,下一个 4 的整数倍是 8,故偏移量 8,占用地址 8~19(12 字节,S4 的大小)。
- 总大小计算
- 已占用地址:0~19(共 20 字节)
- 最大对齐数:8(成员 d 的对齐数)
- 总大小需为 8 的整数倍,20 向上取整为 24
结论:sizeof(struct S5) = 24
步骤 3:计算外层 struct S6 的总大小
成员分析
- 成员 a(char 类型,1 字节):
- 对齐数 = min (8, 1) = 1
- 第一个成员,偏移量 0,占用地址 0(1 字节)。
- 成员 s(struct S5 类型):
- 嵌套结构体 S5 的最大对齐数 = 其内部最大对齐数 8(成员 d 的对齐数)
- 需对齐到 8 的整数倍地址,前一个成员占 0,下一个 8 的整数倍是 8,故偏移量 8,占用地址 8~31(24 字节,S5 的大小)。
步骤4:计算总大小
总大小计算
- 已占用地址:0~31(共 32 字节)
- 最大对齐数:8(嵌套 S5 的最大对齐数)
- 32 是 8 的整数倍,无需向上取整
结论:sizeof(struct S6) = 32
8. 内存对齐的原因与优化
原因
- 平台兼容性:部分硬件只能访问特定地址(如4的整数倍),未对齐会崩溃。
- 性能优化:CPU访问对齐地址只需1次操作,未对齐可能需要2次。
优化:减少空间浪费
将小成员集中存放,降低对齐间隙:
// 优化前:struct S1 大小12字节(间隙多)
struct S1 { char c1; int i; char c2; };// 优化后:struct S2 大小8字节(更紧凑)
struct S2 { char c1; char c2; int i; }; // 小成员集中,减少对齐浪费9. 结构体传参
结构体传参有传值和传址两种方式,传址更优。
传值:传递结构体拷贝
struct BigStruct { int data[1000]; }; // 4000字节的大结构体// 传值:形参是结构体的拷贝(浪费内存和时间)
void func1(struct BigStruct s) {// 操作的是拷贝,不影响原结构体
}int main() {struct BigStruct bs;func1(bs); // 传递4000字节的拷贝,效率低return 0;
}
传址:传递结构体地址
// 传址:形参是指针(仅4/8字节,效率高)
void func2(struct BigStruct* ps) {ps->data[0] = 100; // 可修改原结构体
}int main() {struct BigStruct bs;func2(&bs); // 传递地址,仅4字节,效率高return 0;
}
位段
1. 什么是位段
位段是一种特殊的结构体,通过指定成员占用的比特位数(bit) 来节省内存,其定义有两个核心规则:
- 成员类型限制:必须是
int、unsigned int、signed int或char(均属于整形家族)。 - 比特数指定:成员名后用
:加数字表示占用的比特数(如int a:3表示a占3个比特)。
示例:
// 位段定义(成员后指定比特数)
struct BitSeg {unsigned int flag:1; // 占1个比特(只能存0或1)char data:4; // 占4个比特(范围0~15或-8~7,取决于符号)
}2. 位段的内存分配
位段按成员类型以4字节(int)或1字节(char)为单位开辟空间,成员仅占用指定的比特数,剩余空间可被后续成员复用(若空间足够)。
示例1:int类型位段(struct A)
结构体定义:
struct A {int _a:2; // 占2比特int _b:5; // 占5比特int _c:10; // 占10比特int _d:30; // 占30比特
};
内存分配步骤(int 类型以 4 字节 = 32 比特为单位开辟):
-
- 第一次开辟 4 字节(32 比特):
_a用 2 比特 → 剩余 32-2=30 比特;
-_b用 5 比特 → 剩余 30-5=25 比特;
-_c用 10 比特 → 剩余 25-10=15 比特;- 剩余 15 比特不足以容纳 _d(需 30 比特),再次开辟 4 字节。
-
2.第二次开辟 4 字节(32 比特):
_d用 30 比特 → 剩余 32-30=2 比特(未使用)。
-
总大小:2 次 ×4 字节 = 8 字节。
验证:
printf("struct A size: %zu\n", sizeof(struct A)); // 输出8
示例2:char类型位段(struct S)
结构体定义:
struct S {char a:3; // 占3比特(char类型以1字节=8比特为单位开辟)char b:4; // 占4比特char c:5; // 占5比特char d:4; // 占4比特
};
步骤 1:内存分配过程
- 第一次开辟 1 字节(8 比特):
- a 用 3 比特 → 剩余 8-3=5 比特;
- b 用 4 比特 → 剩余 5-4=1 比特;
剩余 1 比特不足以容纳 c(需 5 比特),再次开辟 1 字节。
- 第二次开辟 1 字节(8 比特):
- c 用 5 比特 → 剩余 8-5=3 比特;
- 剩余 3 比特不足以容纳 d(需 4 比特),第三次开辟 1 字节。
- 第三次开辟 1 字节(8 比特):
- d 用 4 比特 → 剩余 8-4=4 比特(未使用)。
总大小:3 次 ×1 字节 = 3 字节。
验证:
printf("struct S size: %zu\n", sizeof(struct S)); // 输出3
步骤 2:赋值后的比特存储(以 VS 为例,从右向左分配比特)
struct S s = {0};s.a = 10; // 二进制1010 → 截断为低3比特010(因a只占3比特)
s.b = 12; // 二进制1100 → 完整存入4比特(b占4比特)
s.c = 3; // 二进制11 → 扩展为5比特00011(c占5比特)
s.d = 4; // 二进制100 → 扩展为4比特0100(d占4比特)
各字节的二进制组成:
- 第 1 字节(a 和 b):
剩余 1 比特(高位)补 0 → 0 1100 010(二进制)
(前 1 位 0,中间 4 位 b=12,后 3 位 a=10 截断) - 第 2 字节(c):
剩余 3 比特(高位)补 0 → 000 00011(二进制)
(前 3 位 0,后 5 位 c=3) - 第 3 字节(d):
剩余 4 比特(高位)补 0 → 0000 0100(二进制)
(前 4 位 0,后 4 位 d=4)
4. 位段的跨平台问题
位段的实现依赖编译器和硬件,存在以下不确定因素,导致跨平台兼容性差:
-
int位段的符号性不确定:
- 示例:
int a:3中的a在某些编译器中是有符号数(范围-43),在另一些中是无符号数(范围07),存储负数时结果不同。
- 示例:
-
最大比特数不确定:
- 16位机器中int最大占16比特,32位机器中占32比特。若定义
int a:20,在16位机器中会超出范围,导致未定义行为。
- 16位机器中int最大占16比特,32位机器中占32比特。若定义
-
比特分配方向未定义:
- 示例:
char a:3中的3个比特,可能占字节的低3位(右)或高3位(左),不同编译器处理不同,读取时结果不一致。
- 示例:
-
剩余比特的处理不确定:
- 示例:若1字节剩余2比特,下一个成员需3比特,编译器可能舍弃剩余2比特(新开辟字节)或跨字节存储(复用剩余比特),导致内存占用不同。
结论:注重可移植性的程序应避免使用位段。
位段在网络协议中的典型应用:IP 头部解析
1. 网络协议的痛点:固定长度的比特字段
网络协议(如 IP、TCP)的报头包含大量 “固定比特数的字段”(如 IP 版本占 4 位、TCP 标志位占 6 位)。如果用普通变量存储,会浪费内存(比如 4 位的数据用 4 字节 int 存储)。
位段的价值:通过精确控制成员的比特数,直接映射协议的二进制格式,既节省内存,又简化代码。
2. IP 头部的位段实现
以 IPv4 头部 为例,核心字段的比特数如下:
| 字段 | 比特数 | 含义 |
|---|---|---|
| 版本(version) | 4 | IPv4 是 4,IPv6 是 6 |
| 首部长度(ihl) | 4 | 头部占多少个 32 位字 |
| 服务类型(tos) | 8 | 优先级、延迟等属性 |
| 总长度(total_len) | 16 | 整个 IP 包的字节数 |