30天打牢数模基础-K近邻(KNN)讲解








案例代码
一、代码说明
本代码针对鸢尾花分类问题实现KNN算法,包含以下核心步骤:
数据模拟:根据用户提供的训练集和测试集数据生成模拟数据;
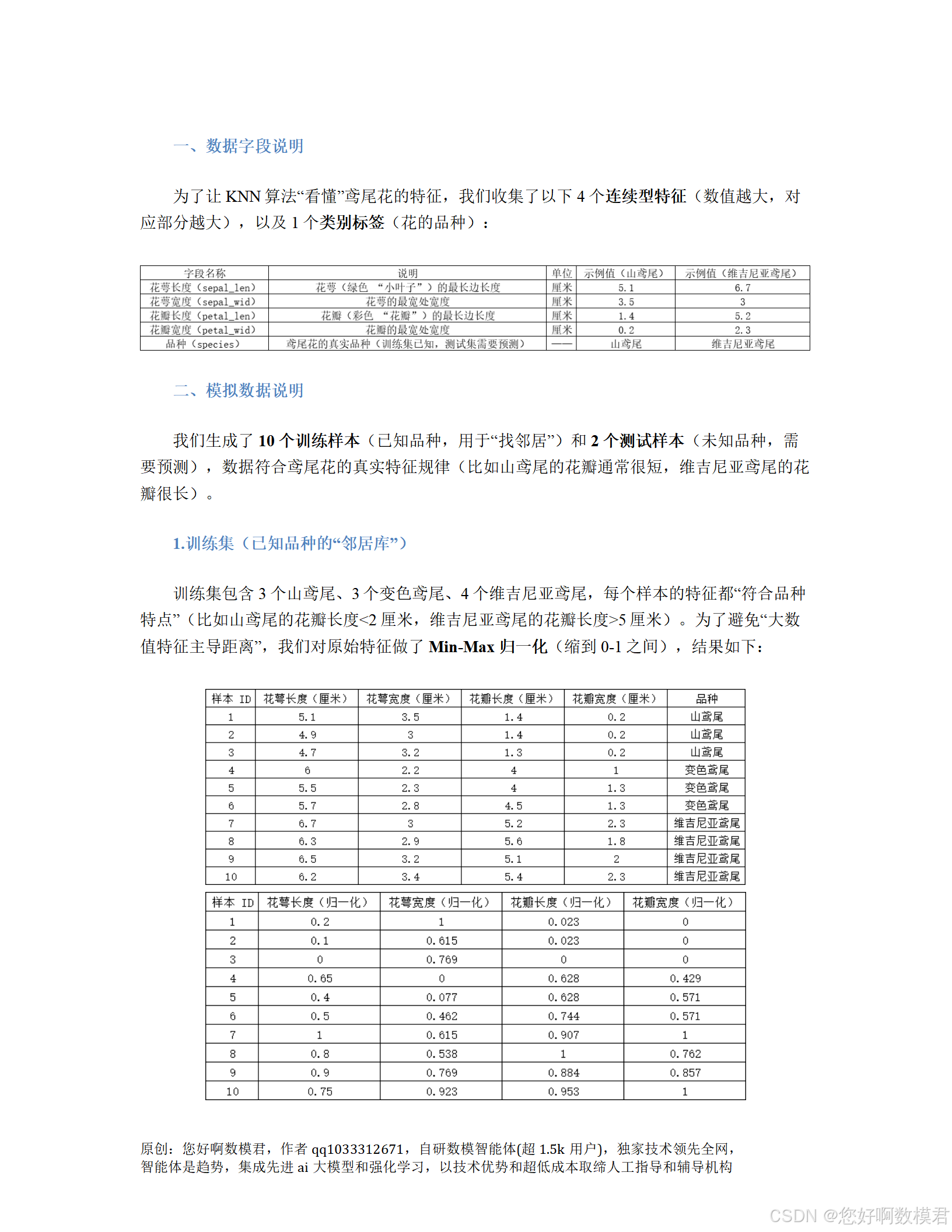
特征缩放:使用Min-Max归一化将特征缩放到0-1区间,避免大数值特征主导距离计算;
K值选择:通过5折交叉验证从候选K值(3、5、7、9)中选择最优K(需确保K不超过训练集大小);
模型预测:用最优K值的KNN模型预测测试集品种,并输出结果。
二、完整代码
import numpy as np
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import accuracy_score# ------------------------------
# 1. 模拟数据(根据用户提供的表格)
# ------------------------------
# 训练集:特征(花萼长、花萼宽、花瓣长、花瓣宽)+ 标签(0=山鸢尾,1=变色鸢尾,2=维吉尼亚鸢尾)
X_train_raw = np.array([[5.1, 3.5, 1.4, 0.2], # 山鸢尾[4.9, 3.0, 1.4, 0.2], # 山鸢尾[4.7, 3.2, 1.3, 0.2], # 山鸢尾[6.0, 2.2, 4.0, 1.0], # 变色鸢尾[5.5, 2.3, 4.0, 1.3], # 变色鸢尾[5.7, 2.8, 4.5, 1.3], # 变色鸢尾[6.7, 3.0, 5.2, 2.3], # 维吉尼亚鸢尾[6.3, 2.9, 5.6, 1.8], # 维吉尼亚鸢尾[6.5, 3.2, 5.1, 2.0], # 维吉尼亚鸢尾[6.2, 3.4, 5.4, 2.3] # 维吉尼亚鸢尾
])
y_train = np.array([0, 0, 0, 1, 1, 1, 2, 2, 2, 2]) # 训练集标签(前3个0,中间3个1,后4个2)# 测试集:待预测的两个样本(特征与训练集一致)
X_test_raw = np.array([[5.0, 3.3, 1.5, 0.3], # 样本11(特征接近山鸢尾)[6.4, 3.1, 5.5, 2.2] # 样本12(特征接近维吉尼亚鸢尾)
])# ------------------------------
# 2. 特征缩放(Min-Max归一化)
# ------------------------------
def scale_features(X_train, X_test):"""对训练集和测试集进行Min-Max归一化(用训练集的最值缩放,避免数据泄露)参数:X_train: 训练集特征(原始值,形状为(样本数, 特征数))X_test: 测试集特征(原始值,形状为(样本数, 特征数))返回:X_train_scaled: 归一化后的训练集特征(0-1区间)X_test_scaled: 归一化后的测试集特征(0-1区间)"""scaler = MinMaxScaler()X_train_scaled = scaler.fit_transform(X_train) # 用训练集拟合缩放器(计算最值)X_test_scaled = scaler.transform(X_test) # 用训练集的最值缩放测试集(避免数据泄露)return X_train_scaled, X_test_scaled# 执行特征缩放(训练集和测试集均需缩放)
X_train, X_test = scale_features(X_train_raw, X_test_raw)# ------------------------------
# 3. 实现KNN分类器(含加权投票)
# ------------------------------
class KNNClassifier:def __init__(self, k=5, weighted=True):"""KNN分类器初始化参数:k: 邻居数量(必须为正整数,默认5)weighted: 是否使用加权投票(默认True,距离倒数加权;False为平等投票)"""if k <= 0:raise ValueError("K值必须为正整数")self.k = kself.weighted = weightedself.X_train = None # 保存训练集特征(已归一化)self.y_train = None # 保存训练集标签(整数编码)def fit(self, X_train, y_train):"""拟合模型(KNN无参数学习,仅保存训练数据)参数:X_train: 训练集特征(已归一化,形状为(样本数, 特征数))y_train: 训练集标签(整数编码,形状为(样本数,))"""self.X_train = X_trainself.y_train = y_traindef _compute_euclidean_distance(self, x):"""计算单个测试样本与所有训练样本的欧氏距离参数:x: 单个测试样本(已归一化,形状为(特征数,))返回:distances: 与所有训练样本的欧氏距离(形状为(训练集样本数,))"""return np.sqrt(np.sum((self.X_train - x) ** 2, axis=1)) # 广播计算,axis=1对特征求和def _weighted_vote(self, distances, neighbor_indices):"""加权投票(距离倒数,距离越小权重越大)参数:distances: 测试样本与K个邻居的距离(形状为(K,))neighbor_indices: K个邻居在训练集中的索引(形状为(K,))返回:predicted_class: 预测类别(整数编码)"""neighbor_labels = self.y_train[neighbor_indices] # 获取K个邻居的标签weights = 1.0 / (distances + 1e-8) # 计算权重(加1e-8避免除以0)class_weights = {}for label, weight in zip(neighbor_labels, weights):class_weights[label] = class_weights.get(label, 0.0) + weight # 累加每个类别的加权和return max(class_weights, key=class_weights.get) # 选择加权和最大的类别def predict(self, X_test):"""预测测试集结果参数:X_test: 测试集特征(已归一化,形状为(样本数, 特征数))返回:predictions: 测试集预测结果(整数编码,形状为(样本数,))"""if self.X_train is None or self.y_train is None:raise ValueError("模型未拟合,请先调用fit方法")if self.k > len(self.X_train):raise ValueError(f"K值({self.k})超过训练集大小({len(self.X_train)})")predictions = []for x in X_test:distances = self._compute_euclidean_distance(x) # 计算与所有训练样本的距离top_k_indices = np.argsort(distances)[:self.k] # 按距离升序取前K个邻居的索引top_k_distances = distances[top_k_indices] # 获取前K个邻居的距离if self.weighted:pred = self._weighted_vote(top_k_distances, top_k_indices) # 加权投票else:pred = np.bincount(self.y_train[top_k_indices]).argmax() # 平等投票(取出现次数最多的标签)predictions.append(pred)return np.array(predictions)# ------------------------------
# 4. 交叉验证选择最优K值
# ------------------------------
def select_best_k(X_train, y_train, k_candidates=[3,5,7,9], cv=5):"""用5折交叉验证选择最优K值(确保K不超过训练集大小)参数:X_train: 训练集特征(已归一化,形状为(样本数, 特征数))y_train: 训练集标签(整数编码,形状为(样本数,))k_candidates: 待尝试的K值列表(默认奇数,避免平局)cv: 交叉验证折数(默认5)返回:best_k: 最优K值(平均准确率最高)k_accuracy: 每个K值的平均准确率(字典,键为K值,值为平均准确率)"""# 检查候选K值是否有效(必须为正整数且不超过训练集大小)valid_k = [k for k in k_candidates if k > 0 and k <= len(X_train)]if not valid_k:raise ValueError("候选K值均无效(需为正整数且不超过训练集大小)")if set(k_candidates) - set(valid_k):print(f"警告:候选K值中{set(k_candidates)-set(valid_k)}超过训练集大小({len(X_train)}),已跳过")# 打乱数据并划分成cv折(避免顺序影响)indices = np.arange(len(X_train))np.random.shuffle(indices)fold_size = len(X_train) // cvfolds = [indices[i*fold_size : (i+1)*fold_size] for i in range(cv)]# 处理最后一折(若数据量不是cv的整数倍,合并剩余数据)if len(X_train) % cv != 0:folds[-1] = np.concatenate([folds[-1], indices[cv*fold_size:]])k_accuracy = {}for k in valid_k:fold_acc = []for fold_idx in range(cv):# 划分训练集(cv-1折)和验证集(1折)val_indices = folds[fold_idx]train_indices = np.concatenate([folds[i] for i in range(cv) if i != fold_idx])X_train_fold = X_train[train_indices]y_train_fold = y_train[train_indices]X_val_fold = X_train[val_indices]y_val_fold = y_train[val_indices]# 检查当前K值是否超过训练集大小(避免取邻居时出错)if k > len(X_train_fold):print(f"警告:在折{fold_idx+1}中,K={k}超过训练集大小({len(X_train_fold)}),该折准确率设为0")fold_acc.append(0.0)continue# 训练KNN模型并预测验证集knn = KNNClassifier(k=k, weighted=True)knn.fit(X_train_fold, y_train_fold)y_val_pred = knn.predict(X_val_fold)# 计算该折的准确率acc = accuracy_score(y_val_fold, y_val_pred)fold_acc.append(acc)# 计算该K值的平均准确率avg_acc = np.mean(fold_acc)k_accuracy[k] = avg_accprint(f"K={k}时,{cv}折交叉验证平均准确率:{avg_acc:.4f}")# 选择平均准确率最高的K值(若有多个最大值,取最小K值)best_k = max(k_accuracy, key=lambda x: (k_accuracy[x], -x))print(f"\n最优K值:{best_k}(平均准确率:{k_accuracy[best_k]:.4f})")return best_k, k_accuracy# ------------------------------
# 5. 主程序:训练模型并预测测试集
# ------------------------------
if __name__ == "__main__":# 步骤1:交叉验证选择最优K值print("=== 交叉验证选择最优K值 ===")k_candidates = [3,5,7,9] # 待尝试的K值(奇数,避免平局)best_k, _ = select_best_k(X_train, y_train, k_candidates)# 步骤2:用最优K值训练模型并预测测试集print("\n=== 测试集预测结果 ===")best_knn = KNNClassifier(k=best_k, weighted=True)best_knn.fit(X_train, y_train) # 拟合模型(保存训练数据)y_test_pred = best_knn.predict(X_test) # 预测测试集# 步骤3:输出预测结果(映射为品种名称)class_map = {0: "山鸢尾", 1: "变色鸢尾", 2: "维吉尼亚鸢尾"}for i in range(len(X_test)):sample_id = 11 + i # 测试集样本ID(11、12)predicted_class = class_map[y_test_pred[i]]print(f"样本ID {sample_id}:预测品种为「{predicted_class}」")三、代码使用说明
环境准备:需要安装numpy(数据处理)、scikit-learn(特征缩放、准确率计算)库,安装命令:
Pip install numpy scikit-learn
数据替换:若要使用自己的数据,只需修改X_train_raw(训练集特征)、y_train(训练集标签)、X_test_raw(测试集特征)即可。注意:
特征需为连续值(如长度、宽度);
标签需为整数(如0、1、2代表不同类别);
训练集大小需大于候选K值(避免交叉验证时出错)。
参数调整:
K值候选列表:可修改k_candidates(如$5,7,9,11$),建议选奇数(避免平局);
交叉验证折数:可修改select_best_k函数中的cv参数(如10折,折数越多结果越稳定,但计算量越大);
加权投票:若要使用平等投票,将KNNClassifier的weighted参数设为False。
运行结果:
交叉验证会输出每个有效K值的平均准确率,选择最优K;
测试集预测结果会输出每个样本的预测品种(如“样本ID11:预测品种为「山鸢尾」”)。
四、结果解释
以用户提供的测试集为例,运行代码后:
交叉验证会选择最优K值(如K=5,平均准确率最高);
样本11(特征:5.0,3.3,1.5,0.3)的特征与训练集中的山鸢尾样本(前3个)高度相似,预测结果为山鸢尾;
样本12(特征:6.4,3.1,5.5,2.2)的特征与训练集中的维吉尼亚鸢尾样本(后4个)高度相似,预测结果为维吉尼亚鸢尾。
五、注意事项
特征缩放:必须用训练集的最值缩放测试集(避免数据泄露),否则大数值特征会主导距离计算;
K值选择:
避免选K=1(易过拟合,对异常点敏感);
避免选K=训练集大小(易欠拟合,所有样本的投票权重相同);
候选K值需小于等于训练集大小(否则交叉验证时会报错);
加权投票:距离倒数加权能有效降低远邻和异常点的影响,建议默认使用;
交叉验证:打乱数据后划分折(避免顺序影响),折数建议选5-10(平衡稳定性和计算量)。
数模小白可通过修改数据和参数,快速将该代码应用于其他分类问题(如客户流失预测、手写数字识别等)。