【分布式 ID】详解百度 uid-generator(基础篇)
文章目录
- 1. 前言
- 2. 百度 uid-generator
- 2.1 准备工作
- 2.2 DefaultUidGenerator 测试
- 2.2 CachedUidGenerator 测试
- 3. 高效的 CachedUidGenerator
- 3.1 环形数组结构
- 3.2 双 RingBuffer
- 3.3 简单聊下缓存的伪共享和解决方法
- 3.4 缓存行填充
- 3.5 未来时间和 ID 生成与获取
- 3.6 比特位分配
- 3.7 整体性能
- 4. 小结
1. 前言
系列文章:
- 【分布式 ID】生成唯一 ID 的几种方式。
- 【分布式 ID】一文详解美团 Leaf
上面两篇文章就讲述了下生成唯一 ID 的几种方式以及美团的开源项目 Leaf,Leaf 给我们提供了数据库号段和雪花算法的 ID 生成模式,而这篇文章主要就是来看下百度 uid-generator 又使用了哪种方式来生成递增 ID,项目开源地址:baidu/uid-generator。
2. 百度 uid-generator
大家可以把项目拉下来,然后打开项目,有一个 README.zh_cn.md 文件,这个文件就是文档介绍,包括原理和启动示例。
首先来看下基本的示例,uid-generator 给我们提供了两种实现方式,分别是 DefaultUidGenerator 和 CachedUidGenerator,DefaultUidGenerator 是雪花算法的基本实现,CachedUidGenerator 在雪花算法的基础上使用了双 Buffer 提前缓存未来时间的 uid,等到请求到来的时候就可以直接返回结果,性能比较高,这两种方式项目下面都有对应的 test。
2.1 准备工作
由于这两种方式都需要用到 mysql,其实主要是 workerID 要用到,所以我们得先把表创建出来。
DROP TABLE IF EXISTS WORKER_NODE;
CREATE TABLE WORKER_NODE
(
ID BIGINT NOT NULL AUTO_INCREMENT COMMENT 'auto increment id',
HOST_NAME VARCHAR(64) NOT NULL COMMENT 'host name',
PORT VARCHAR(64) NOT NULL COMMENT 'port',
TYPE INT NOT NULL COMMENT 'node type: ACTUAL or CONTAINER',
LAUNCH_DATE DATE NOT NULL COMMENT 'launch date',
MODIFIED TIMESTAMP NOT NULL COMMENT 'modified time',
CREATED TIMESTAMP NOT NULL COMMENT 'created time',
PRIMARY KEY(ID)
)COMMENT='DB WorkerID Assigner for UID Generator',ENGINE = INNODB;
这个表当项目启动的时候就会往里面插入一条记录,相当于项目启动的时候就上报下信息到数据库,信息长这样。

上报的是 ip、当前时间 + port、启动类型(docker 启动还是其他方式启动)、启动日期等,最主要的就是这个自增 ID 了,当项目启动插入一条数据之后返回的 ID 就是 workerID。
接下来由于我们用的 MYSQL 8.0,所以改下 pom 文件,改成使用 MYSQL 8.0 的连接以及使用 1.1.22 的 druid 连接池。

2.2 DefaultUidGenerator 测试
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(locations = { "classpath:uid/default-uid-spring.xml" })
public class DefaultUidGeneratorTest {private static final int SIZE = 100000; // 10wprivate static final boolean VERBOSE = true;private static final int THREADS = Runtime.getRuntime().availableProcessors() << 1;@Resourceprivate UidGenerator uidGenerator;/*** Test for serially generate*/@Testpublic void testSerialGenerate() {// Generate UID seriallySet<Long> uidSet = new HashSet<>(SIZE);for (int i = 0; i < SIZE; i++) {doGenerate(uidSet, i);}// Check UIDs are all uniquecheckUniqueID(uidSet);}/*** Test for parallel generate* * @throws InterruptedException*/@Testpublic void testParallelGenerate() throws InterruptedException {AtomicInteger control = new AtomicInteger(-1);Set<Long> uidSet = new ConcurrentSkipListSet<>();// Initialize threadsList<Thread> threadList = new ArrayList<>(THREADS);for (int i = 0; i < THREADS; i++) {Thread thread = new Thread(() -> workerRun(uidSet, control));thread.setName("UID-generator-" + i);threadList.add(thread);thread.start();}// Wait for worker donefor (Thread thread : threadList) {thread.join();}// Check generate 10w timesAssert.assertEquals(SIZE, control.get());// Check UIDs are all uniquecheckUniqueID(uidSet);}/*** Worker run*/private void workerRun(Set<Long> uidSet, AtomicInteger control) {for (;;) {int myPosition = control.updateAndGet(old -> (old == SIZE ? SIZE : old + 1));if (myPosition == SIZE) {return;}doGenerate(uidSet, myPosition);}}/*** Do generating*/private void doGenerate(Set<Long> uidSet, int index) {long uid = uidGenerator.getUID();String parsedInfo = uidGenerator.parseUID(uid);uidSet.add(uid);// Check UID is positive, and can be parsedAssert.assertTrue(uid > 0L);Assert.assertTrue(StringUtils.isNotBlank(parsedInfo));if (VERBOSE) {System.out.println(Thread.currentThread().getName() + " No." + index + " >>> " + parsedInfo);}}/*** Check UIDs are all unique*/private void checkUniqueID(Set<Long> uidSet) {System.out.println(uidSet.size());Assert.assertEquals(SIZE, uidSet.size());}}
上面是 DefaultUidGeneratorTest 下面的测试类,首先引入了 classpath:uid/default-uid-spring.xml 这个配置文件,因为 DefaultUidGenerator 虽然是用了雪花 id 的实现方式,但是雪花算法的几个字段:时间戳、workerID、序列号的位数是可以配置的,因此这个配置文件里面主要就是设置了 DefaultUidGenerator 的这几个属性值。
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-3.1.xsd"><!-- UID generator --><bean id="disposableWorkerIdAssigner" class="com.baidu.fsg.uid.worker.DisposableWorkerIdAssigner"/><bean id="defaultUidGenerator" class="com.baidu.fsg.uid.impl.DefaultUidGenerator" lazy-init="false"><property name="workerIdAssigner" ref="disposableWorkerIdAssigner"/><!-- Specified bits & epoch as your demand. No specified the default value will be used --><property name="timeBits" value="29"/><property name="workerBits" value="21"/><property name="seqBits" value="13"/><property name="epochStr" value="2016-09-20"/></bean><!-- Import mybatis config --><import resource="classpath:/uid/mybatis-spring.xml"/></beans>
然后我们启动第一个 test,也就是 testSerialGenerate,使用单线程生成 ID,同时判断这些 ID 有没有重复,一共是生成 100000 个 ID,输出结果如下:
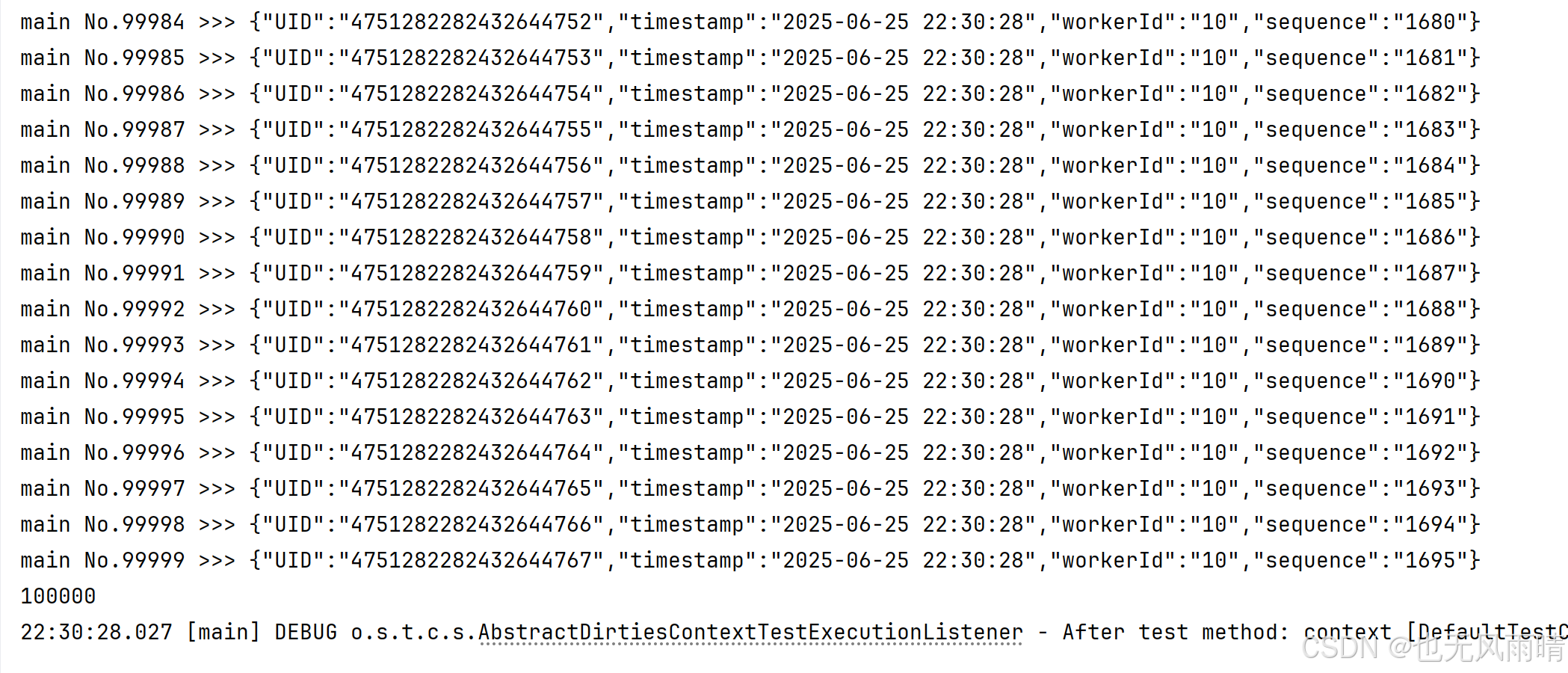
可以看到这些 ID 生成确实是递增生成,且启动的 workerId 为 10,为什么是 10 呢?因为前面我自己测了几次,这次启动插入生成的 ID 就是 10。

既然单线程没有问题,那么多线程有没有问题呢?我们来跑下 testParallelGenerate 这个测试方法。这个测试方法启动和 CPU 核数 * 2 的线程去跑 workerRun 方法,workerRun 方法中就会去生成 ID,然后这些线程一共生成 10w 个 ID,最后看下有没有重复的。
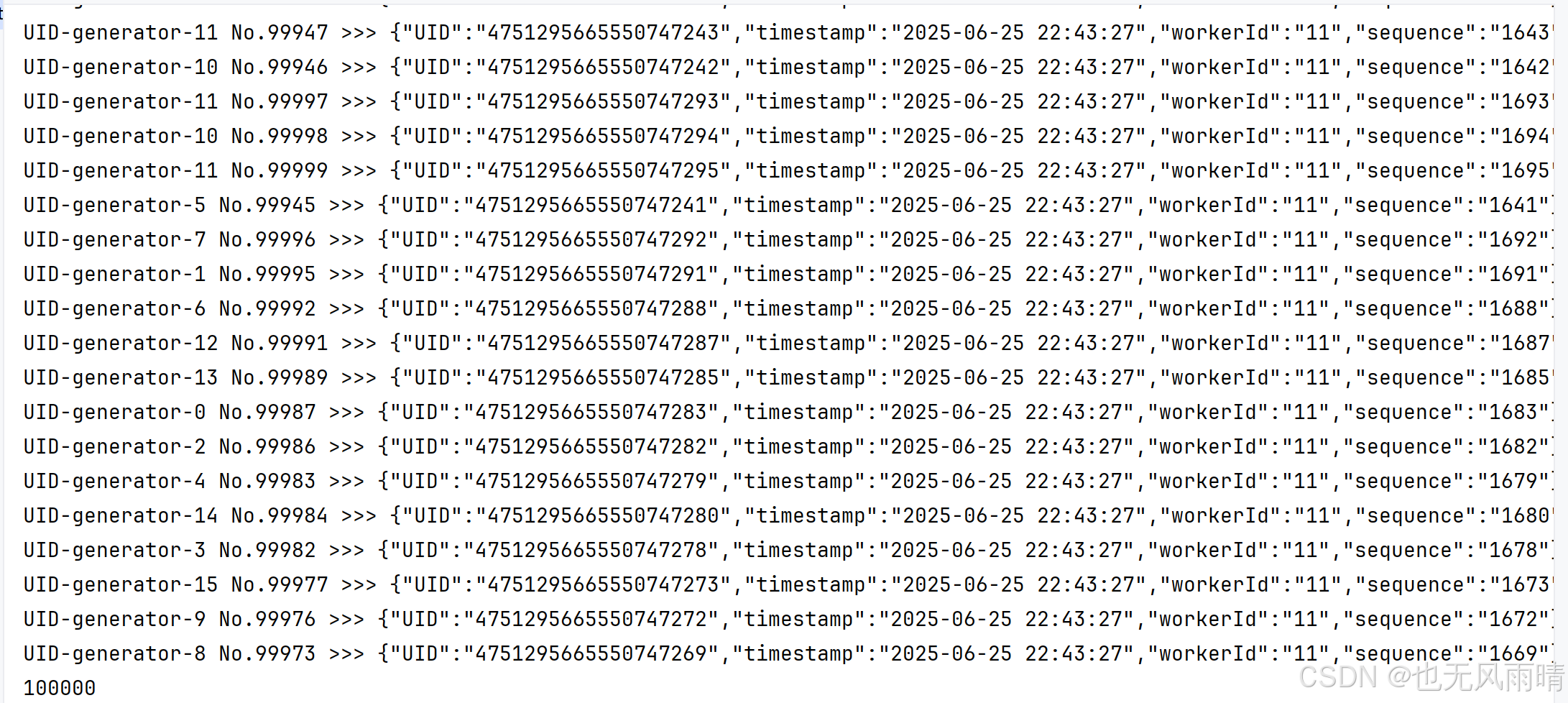
可以看到这些线程生成的 ID 都没有重复的,因为线程生成速度不同,所以输出没有按顺序输出,但是大家知道最终是生成了 10w 个 ID 就行,因为 ID 从 0 开始,99999 结束。
2.2 CachedUidGenerator 测试
CachedUidGenerator 是 uid-generator 的双 Buffer 实现类,如果对性能有要求可以用这个实现类,首先还是一样,先来看下 cache-uid-spring.xml 这个配置类,专门用于配置 CachedUidGenerator 里面的属性的。
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-3.1.xsd"><!-- UID generator --><bean id="disposableWorkerIdAssigner" class="com.baidu.fsg.uid.worker.DisposableWorkerIdAssigner" /><bean id="cachedUidGenerator" class="com.baidu.fsg.uid.impl.CachedUidGenerator"><property name="workerIdAssigner" ref="disposableWorkerIdAssigner" /><!-- 以下为可选配置, 如未指定将采用默认值 --><!-- RingBuffer size扩容参数, 可提高UID生成的吞吐量. --><!-- 默认:3, 原bufferSize=8192, 扩容后bufferSize= 8192 << 3 = 65536 -->
<!-- <property name="boostPower" value="3"></property> --><!-- 指定何时向RingBuffer中填充UID, 取值为百分比(0, 100), 默认为50 --><!-- 举例: bufferSize=1024, paddingFactor=50 -> threshold=1024 * 50 / 100 = 512. --><!-- 当环上可用UID数量 < 512时, 将自动对RingBuffer进行填充补全 --><!--<property name="paddingFactor" value="50"></property>--><!-- 另外一种RingBuffer填充时机, 在Schedule线程中, 周期性检查填充 --><!-- 默认:不配置此项, 即不实用Schedule线程. 如需使用, 请指定Schedule线程时间间隔, 单位:秒 --><!--<property name="scheduleInterval" value="60"></property>--><!-- 拒绝策略: 当环已满, 无法继续填充时 --><!-- 默认无需指定, 将丢弃Put操作, 仅日志记录. 如有特殊需求, 请实现RejectedPutBufferHandler接口(支持Lambda表达式) --><!--<property name="rejectedPutBufferHandler" ref="XxxxYourPutRejectPolicy"></property>--><!-- 拒绝策略: 当环已空, 无法继续获取时 --><!-- 默认无需指定, 将记录日志, 并抛出UidGenerateException异常. 如有特殊需求, 请实现RejectedTakeBufferHandler接口(支持Lambda表达式) --><!--<property name="rejectedTakeBufferHandler" ref="XxxxYourTakeRejectPolicy"></property>--><property name="timeBits" value="41"/><property name="workerBits" value="10"/><property name="seqBits" value="12"/><property name="epochStr" value="2016-09-20"/></bean><!-- Import mybatis config --><import resource="classpath:/uid/mybatis-spring.xml" /></beans>
首先就是官方项目拉下来的时候是没有下面 timeBits 这几个属性的,也就是说如果你不设置就用的是默认值。
/** Bits allocate */
protected int timeBits = 28;
protected int workerBits = 22;
protected int seqBits = 13;/** Customer epoch, unit as second. For example 2016-05-20 (ms: 1463673600000)*/
protected String epochStr = "2016-05-20";
那首先就是 timeBits 设置为了 28 位,我们可以来算下这 28 位时间戳能用多少年,首先大家明确一点就是这两个 UidGenerator 的实现,不管是 DefaultUidGenerator 还是 CachedUidGenerator,都是用的秒,也就是时间戳是用秒来计算的。
public class Main {public static void main(String[] args) {System.out.println((1 << 28) * 1.0 / (365 * 1.0 * 24 * 60 * 60));// 8.512032470826991}
}
可以看到算出来就是 8.5 年,由于起始时间是 2016-05-20,到现在已经 9 年了,所以如果你用的默认值,生成的 ID 就会是负数,因为时间占了 29 位,这样拼出来的 ID 最高位就是 1 了,也就是负数,所以我们这里在 xml 文件里面修改下这几个变量所占的位数,时间设置的大一点。然后我们直接用项目下面的测试类来测试。
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(locations = { "classpath:uid/cached-uid-spring.xml" })
public class CachedUidGeneratorTest {private static final int SIZE = 7000000; // 700wprivate static final boolean VERBOSE = false;private static final int THREADS = Runtime.getRuntime().availableProcessors() << 1;@Resourceprivate UidGenerator uidGenerator;@Testpublic void testSerialGenerateV2() {// Generate UIDlong uid = uidGenerator.getUID();// Parse UID into [Timestamp, WorkerId, Sequence]// {"UID":"180363646902239241","parsed":{ "timestamp":"2017-01-19 12:15:46", "workerId":"4", "sequence":"9" }}System.out.println(uidGenerator.parseUID(uid));}/*** Test for serially generate* * @throws IOException*/@Testpublic void testSerialGenerate() throws IOException {// Generate UID seriallySet<Long> uidSet = new HashSet<>(SIZE);for (int i = 0; i < SIZE; i++) {doGenerate(uidSet, i);}// Check UIDs are all uniquecheckUniqueID(uidSet);}/*** Test for parallel generate* * @throws InterruptedException* @throws IOException*/@Testpublic void testParallelGenerate() throws InterruptedException, IOException {AtomicInteger control = new AtomicInteger(-1);Set<Long> uidSet = new ConcurrentSkipListSet<>();// Initialize threadsList<Thread> threadList = new ArrayList<>(THREADS);for (int i = 0; i < THREADS; i++) {Thread thread = new Thread(() -> workerRun(uidSet, control));thread.setName("UID-generator-" + i);threadList.add(thread);thread.start();}// Wait for worker donefor (Thread thread : threadList) {thread.join();}// Check generate 700w timesAssert.assertEquals(SIZE, control.get());// Check UIDs are all uniquecheckUniqueID(uidSet);}/*** Woker run*/private void workerRun(Set<Long> uidSet, AtomicInteger control) {for (;;) {int myPosition = control.updateAndGet(old -> (old == SIZE ? SIZE : old + 1));if (myPosition == SIZE) {return;}doGenerate(uidSet, myPosition);}}/*** Do generating*/private void doGenerate(Set<Long> uidSet, int index) {long uid = uidGenerator.getUID();String parsedInfo = uidGenerator.parseUID(uid);boolean existed = !uidSet.add(uid);if (existed) {System.out.println("Found duplicate UID " + uid);}// Check UID is positive, and can be parsedAssert.assertTrue(uid > 0L);Assert.assertTrue(StringUtils.isNotBlank(parsedInfo));if (VERBOSE) {System.out.println(Thread.currentThread().getName() + " No." + index + " >>> " + parsedInfo);}}/*** Check UIDs are all unique*/private void checkUniqueID(Set<Long> uidSet) throws IOException {System.out.println(uidSet.size());Assert.assertEquals(SIZE, uidSet.size());}}
然后来看下 testSerialGenerateV2 类,这个是我自己添加的一个测试类,测试获取单个 ID,看看获取处理的会不会是负数,结果肯定是没有问题的,然后再来看下 testSerialGenerate,这个就是单线程获取 ID,然后校验这些 ID 是否有重复。
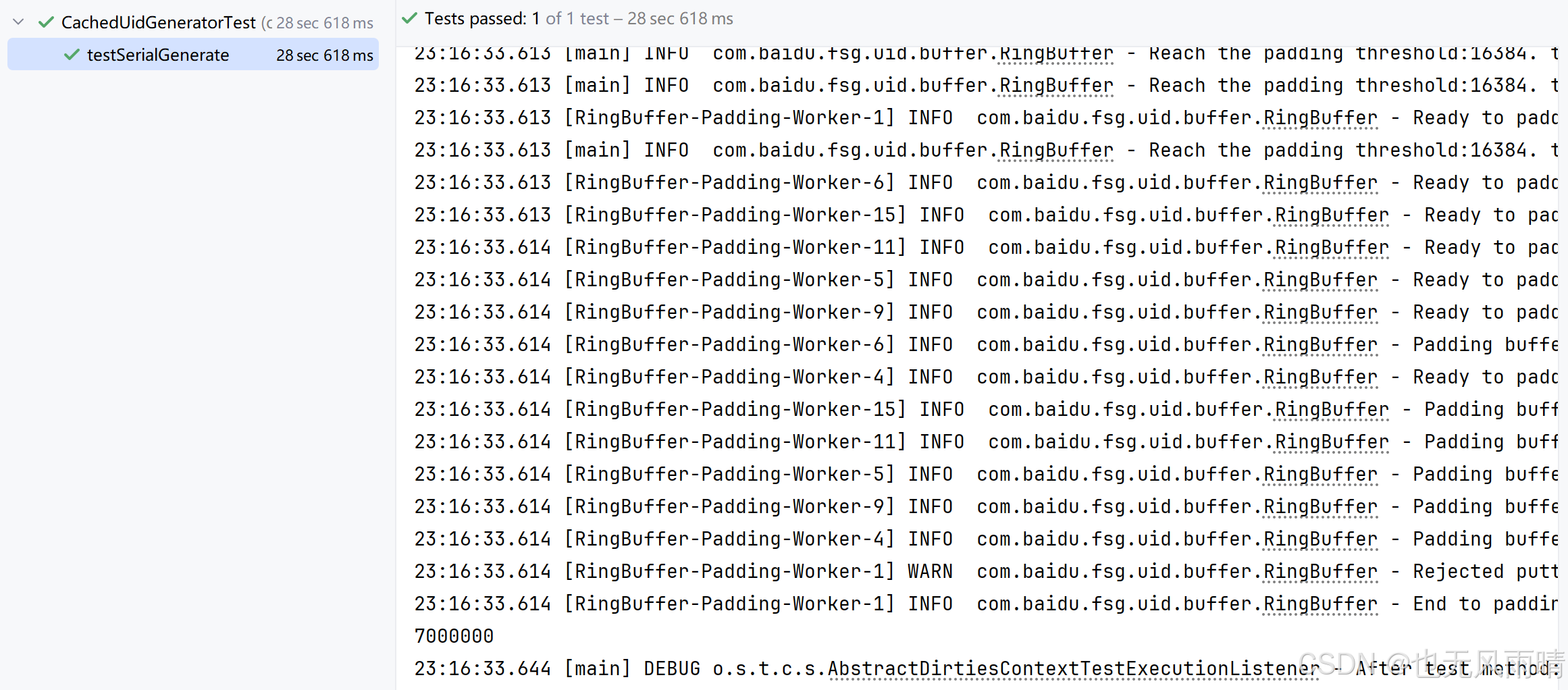
可以看到最终生成的 700w ID 都没有问题,并且没有重复,而且看右边的输出可以看到由于 ID 获取的量太大,Padding 线程池一直在不断补充 ID,而补充 ID 同一时间内只能有一个线程在执行,所以右边会不断打印 Padding buffer is still running,而且可以看到 cursor 和 tail 这两个环形数组的指针不会重置为 0 开始,而是一直递增。
上面单线程获取 ID 的没问题,那么多线程有没有问题呢?来测试下 testParallelGenerate 这个 test 方法。
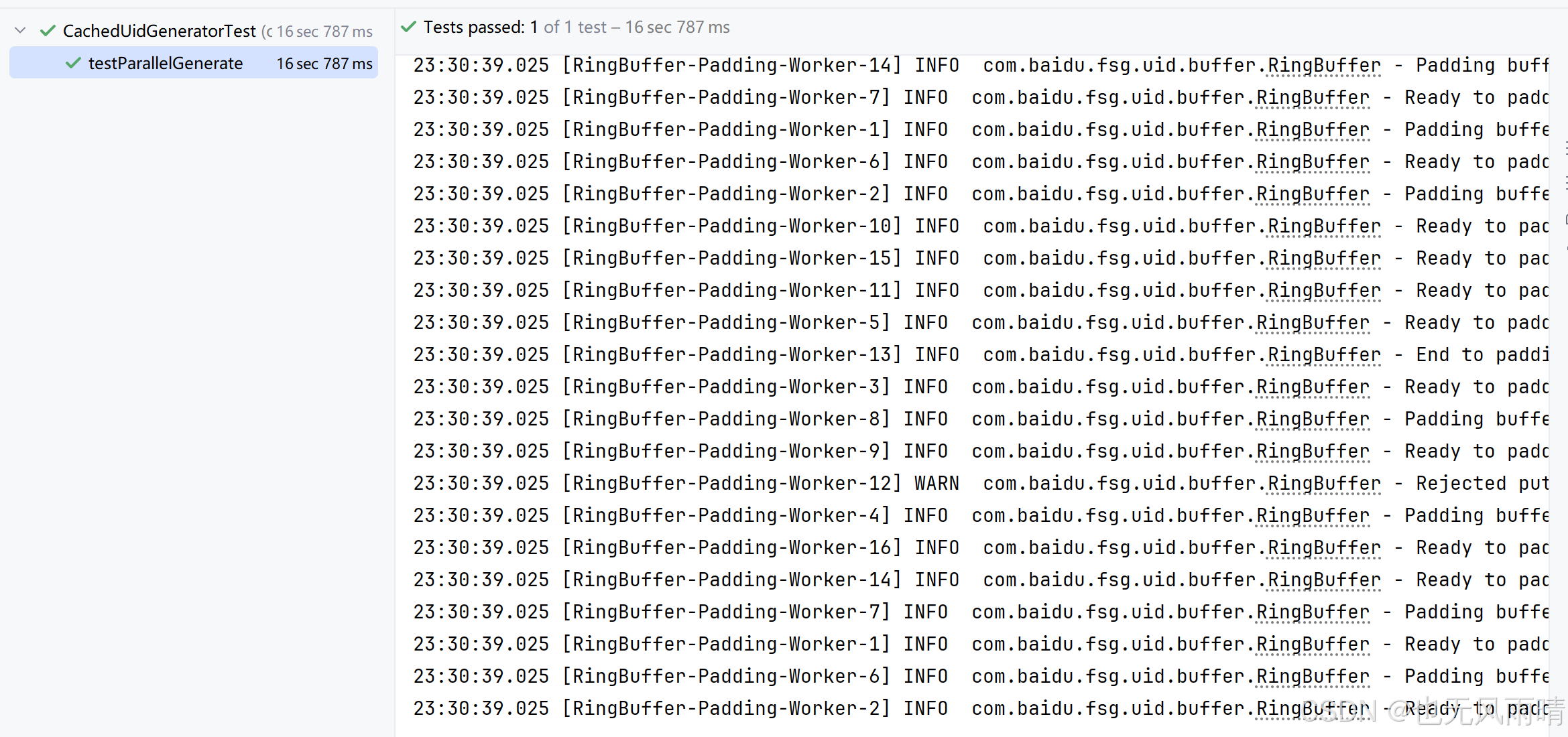
可以看到最终输出也没有问题,也就是说确实是生成了 700w 个 ID,且这些 ID 没有重复,从右边也可以看出来,多线程在获取 ID 的时候 Padding 线程池也在不断往 Buffer 里面添加 ID,最终也能够确保线程安全,不获取到同一个 ID。
3. 高效的 CachedUidGenerator
3.1 环形数组结构
来看下 CachedUidGenerator 的缓存结构,CachedUidGenerator 使用了双 RingBuffer 环形数组来存储 ID。
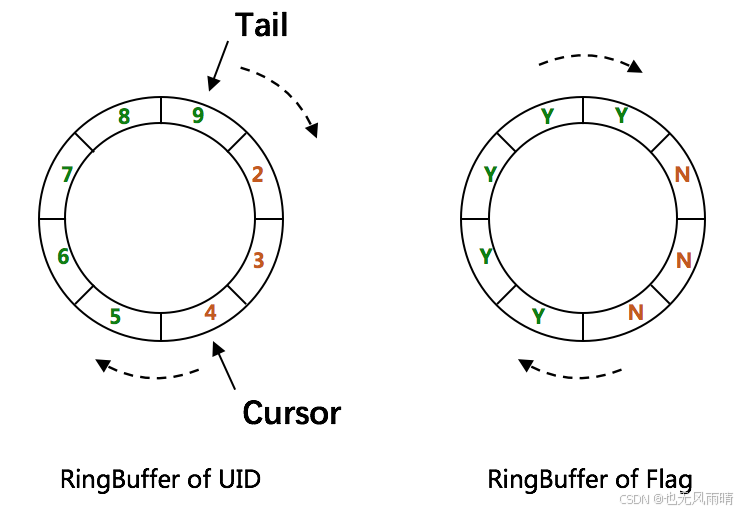
其中用了两个指针 Tail 和 Cursor 来指向环形队列上面的读写 slot,用于添加和获取 ID。
- Tail 指针:tail 指针表示 Producer 生产的最大序号,初始值是 -1,当生产者往 Buffer 里面添加 ID 的时候,添加的是 Tail + 1 的位置,也就是说序号从下标 0 开始添加。
- Cursor 指针:cursor 指针表示 消费者的最大序号,初始值是 -1,当消费者需要消费 Buffer 里面的 ID 时,也是从 Cursor + 1 的位置开始消费,就是下标 0 开始。
由于一开始需要先生产 ID 放到 Buffer 中,因此 Tail 肯定在最前面,后续 Cursor 获取 ID 就会慢慢追上 Tail,但是有一个规定,Tail 放 ID 的时候不能追上 Cursor。
- 当
Cursor == Tail的时候,从放 ID 的角度就是现在 Buffer 已经满了,没有多余的 slot 放 ID 了,这时候需要等待消费者消费,于是调用拒绝策略 rejectedPutHandler 拒绝。 - 从获取 ID 的角度就是 Cursor 追上 Tail 了,由于下一次要获取的 ID 是
Cursor + 1,但是 Cursor + 1 还没有 ID,获取不到,因此这时候调用拒绝策略 rejectedTakeHandler 告诉调用方没有 ID 可以获取了。
获取的 ID 也是通过雪花算法生成,在上面 2.2 我们也演示了如何通过配置文件配置雪花算法的各个属性,所以性能方面肯定是够用的。
3.2 双 RingBuffer
观察上面 3.1 小节的图,大家会发现右边还有一个 Buffer,这个 Buffer 就是用于判断左边的 UID Buffer 上某一个 slot 是否可写或者可读,左边我们这里叫做 UID-Buffer,右边叫做 Flag-Buffer, CachedUidGenerator 提供了两种状态来标记 UID-Buffer 的下标状态,Flag-Buffer 就是下面这两个值。
CAN_PUT_FLAG表示UID-Buffer这个下标的 ID 已经被获取了, 现在生产者可以往里面 Padding 继续放 ID。CAN_TAKE_FLAG表示UID-Buffer这个下标的 ID 已经准备好了, 现在消费者获取这个 ID。
对于 Flag-Buffer,由于使用的是数组来存储,因此考虑到缓存伪共享的问题,对 Flag-Buffer 和 Tail、Cursor 指针使用 CacheLine 补齐方式,也就是下面的图。
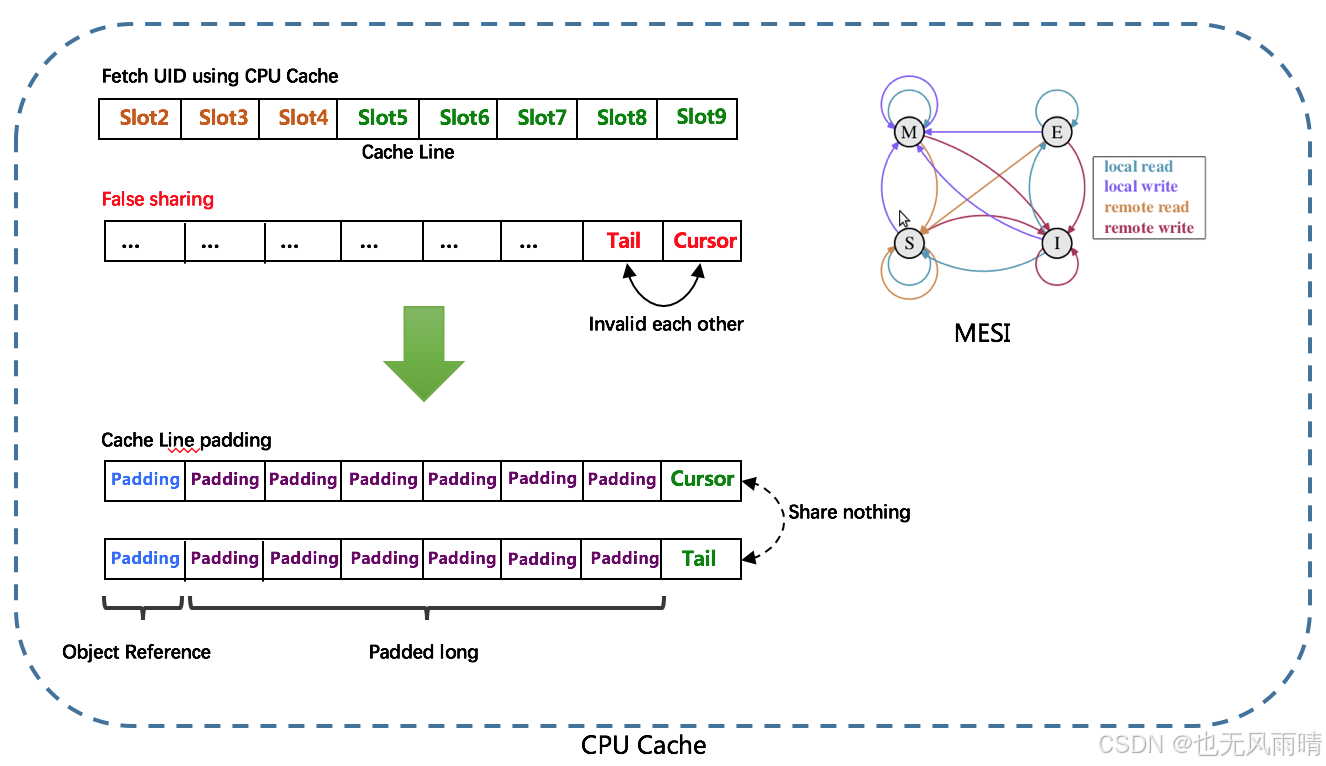
要理解为什么要用这种方式解决伪共享的问题,就要看下什么是伪共享。
3.3 简单聊下缓存的伪共享和解决方法
大家如果有兴趣可以去看下这篇文章(很早之前就收藏的了),这里面写的确实好,也可以去看下缓存一致性是怎么实现的,CPU 之间是如何确保缓存一致的:缓存一致性MESI与内存屏障。
那下面就简单介绍下什么是缓存伪共享。
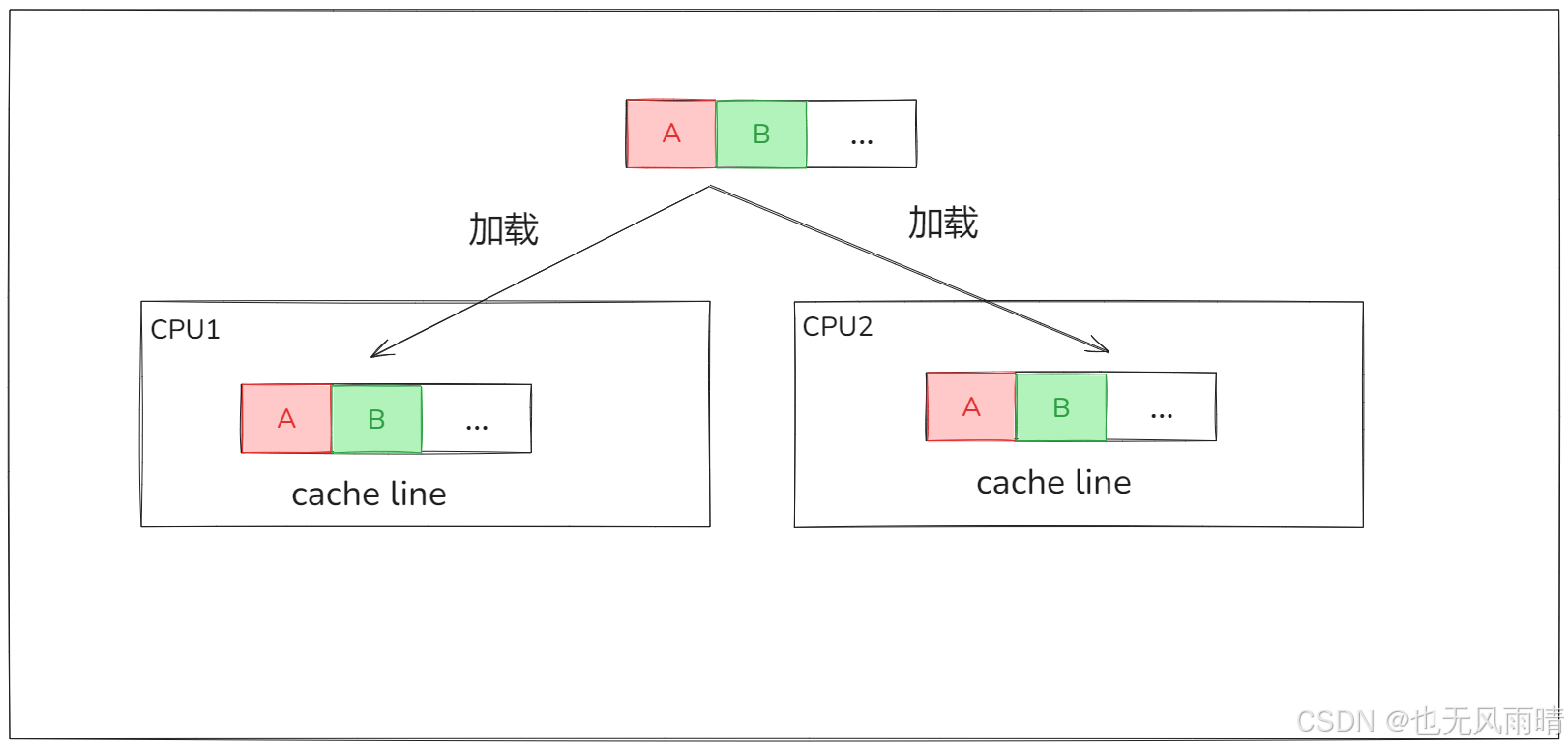
CPU 在 64 位架构下缓存行一次性会读取 64 个字节,而 A、B 我们假设就是一个 long 类型的数字,那么刚好一个缓存行有足够的空间放下这两个数,因此此时 CPU1 和 CPU2 的缓存里面都缓存了内存中的 A 和 B。
那首先在修改前我们来认识下 MESI,当然我们这里就简单看下这几个含义,MESI 协议主要就是用来处理多个 CPU 之间的缓存一致性问题,比如 CPU1 如果修改了 a 这个变量,那么其他 CPU 缓存里面的 a 要如何变化。
- M 就是
Modified,意思就是当 CPU 修改了自己缓存行里面的某个值之后,这个值就是属于 Modified 状态,在这个值被修改后,其他 CPU 就不能在持有这个值,或者持有的这个值变成了Invalid状态。 - E 就是
Exclusive,意思就是处于这个状态的值被某个 CPU 独占,但是这个值有可能是最新的,还没有被修改过,这种状态下可以随时更改为共享状态,被其他 CPU 共享。 - S 就是
Shared,意思是这个值同时出现在一个或者多个 CPU 中,而且这些 CPU 里面的值都是相同的,在修改这个值之前需要经过缓存一致性协议变更状态。 - I 就是
Invalid,意思是这个值由于在其他 CPU 被修改了,那么当前 CPU 里面的就会被打上Invalid状态。
好了,我们就简单看下这几种状态,多的就不说了,大家可以看上面的文章,这时候的 A 和 B 都是 shared 状态,然后假设 CPU1 要修改 A,那么 CPU1 会在修改之前将 CPU2 对应缓存行变成 Invalid 状态(CPU 以缓存行为交互的最小单位)。
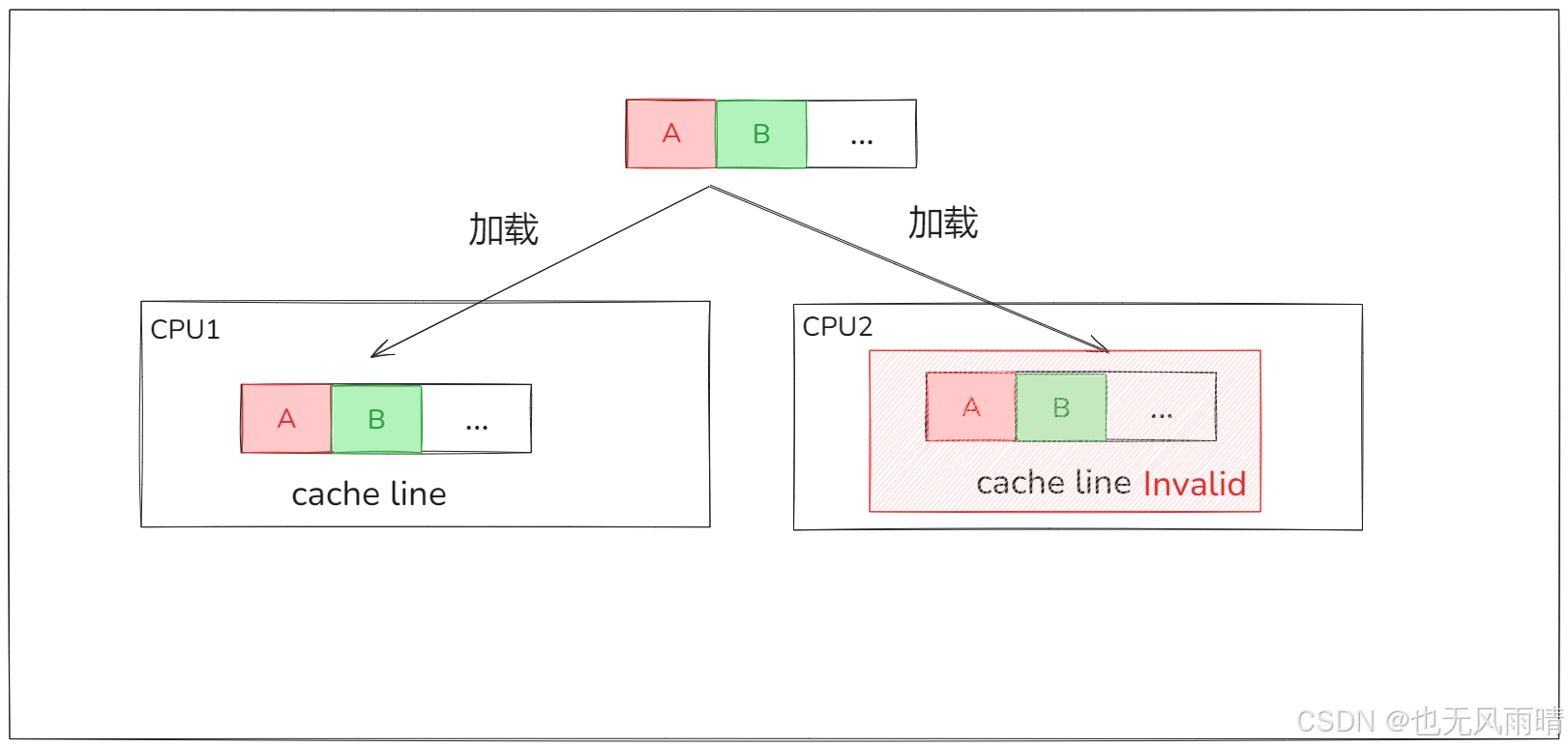
这时候假设 CPU2 想要操作 B,会发现 B 所在的缓存行已经是 Invalid 了,这种情况下需要通过缓存一致去重新获取 B,重新设置到缓存行里面,我们发现 CPU1 只是修改 A 却导致 CPU2 的缓存失效了,原因就是 A 和 B 都被读到了一个缓存行里面,由于缓存行是 64 字节,所以如果是数组,两个值被读到一个缓存行还是常见的。
那么如何解决这个问题呢? 核心方法就是:将这两个值放到不同缓存行,也就是缓存行填充。
3.4 缓存行填充
缓存行填充就是通过填充属性的方式让我们需要操作的属性独占一个缓存行,比如上面 A 和 B 被读到了同一个缓存行中,那么我们就可以把 A 封装到一个对象中,然后在 A 后面填充上 6 个 long 类型的数据。
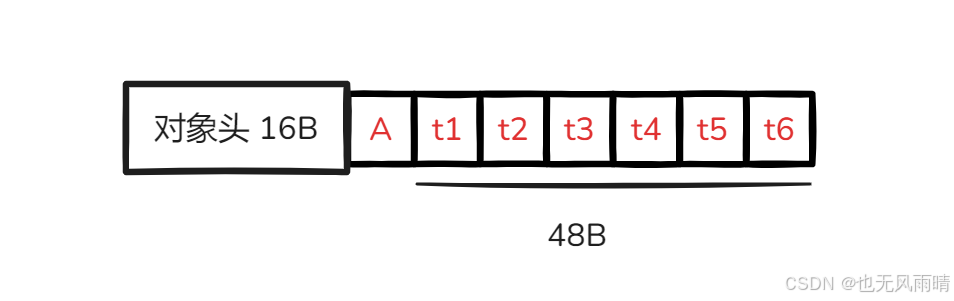
可以看到比如我们在一个对象中 A 的后面填充了 6 个 long 类型的数据,这种情况下加上对象头里面的 16B(Mark Word + Klass Word),一共就能占用到 72 字节,这种情况下我们可以把 B、C 的结构也画出来。

你会发现经过填充之后 A、B、C 不可能在一个 64 位的缓存行中同时存在,因为 t1 ~ t6 占用了 48 字节,加上对象头就 64 字节了,所以 A、C 又或者 B、A 不可能在同一个缓存行出现,那么为什么不用填充 5 个 long 呢,反正 5 个 long 加起来也就 40 个字节,加上对象头 56,也不可能容纳 A、C 或者 B、A 在同一个缓存行。
但是在 32 位系统下,Mark Word 占 4 字节,而 Klass Word 也是 4 字节,因此,上面的图就变成了,因此就算是对象头只占用 8 字节,也可以确保 A、B、C 不在同一个缓存行。

比如现在 A 是一个 long 类型的数据,那我们就将这个数据封装到一个对象中,然后在对象里面填充够 64 个字节,uid-generator 的 PaddedAtomicLong 就是这么干的,下面我们可以自己定义一个类来看下结构。
public class MyLong{public long A;public volatile long p1, p2, p3, p4, p5, p6 = 7L;
}
上面我们定义了一个 MyLong,主要的属性就是 A,其他都是填充,接下来我们引入 jol-core 这个 maven 包,这个包可以输出对象头的字节占用情况。
<dependency><groupId>org.openjdk.jol</groupId><artifactId>jol-core</artifactId><version>0.8</version>
</dependency>
然后我们定义一个 main 方法去测试这个对象的内存占用情况。
public class Main {public static void main(String[] args){MyLong myLong = new MyLong();System.out.println(ClassLayout.parseInstance(myLong).toPrintable());}
}
结果输出如下:
com.bugfix.objecttest.MyLong object internals:OFFSET SIZE TYPE DESCRIPTION VALUE0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)8 4 (object header) 43 c1 00 f8 (01000011 11000001 00000000 11111000) (-134168253)12 4 (alignment/padding gap) 16 8 long MyLong.A 024 8 long MyLong.p1 032 8 long MyLong.p2 040 8 long MyLong.p3 048 8 long MyLong.p4 056 8 long MyLong.p5 064 8 long MyLong.p6 7
Instance size: 72 bytes
Space losses: 4 bytes internal + 0 bytes external = 4 bytes total
可以看到上面对象头一共占了 12 个字节,然后加上 padding 填充的 4 字节,整体对象头来到了 16 字节,A 占用 8 字节,其他填充字段占了 48 字节,总共就 72 字节。
那在 Java8 中除了上面手动填充字段,我们还可以通过 @sun.misc.Contended 修饰类,然后这个类会自动补充缓存行,不过默认情况下 @Contended 注解的填充效果是不生效的,需要通过设置 JVM 参数 -XX:-RestrictContended 来开启。设置了这个参数之后启动来看下输出结果。
com.bugfix.objecttest.MyLong object internals:OFFSET SIZE TYPE DESCRIPTION VALUE0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)8 4 (object header) 43 c1 00 f8 (01000011 11000001 00000000 11111000) (-134168253)12 132 (alignment/padding gap) 144 8 long MyLong.A 0152 128 (loss due to the next object alignment)
Instance size: 280 bytes
Space losses: 132 bytes internal + 128 bytes external = 260 bytes total
可以看到,请求头占了 12 字节,然后填充了 128 字节,接下来就是 A 属性,最后再填充 128 字节,所以 @Contended 就是注释的字段前后会填充 128 个字节避免读到同一缓存行中。
CachedUidGenerator 就是手动填充的缓存行,主要类就是 PaddedAtomicLong,下面来看下里面的结构。
/*** Represents a padded {@link AtomicLong} to prevent the FalseSharing problem<p>* * The CPU cache line commonly be 64 bytes, here is a sample of cache line after padding:<br>* 64 bytes = 8 bytes (object reference) + 6 * 8 bytes (padded long) + 8 bytes (a long value)* * @author yutianbao*/
public class PaddedAtomicLong extends AtomicLong {private static final long serialVersionUID = -3415778863941386253L;/** Padded 6 long (48 bytes) */public volatile long p1, p2, p3, p4, p5, p6 = 7L;/*** Constructors from {@link AtomicLong}*/public PaddedAtomicLong() {super();}public PaddedAtomicLong(long initialValue) {super(initialValue);}/*** To prevent GC optimizations for cleaning unused padded references*/public long sumPaddingToPreventOptimization() {return p1 + p2 + p3 + p4 + p5 + p6;}}
可以看到,就是填充了 48 个字节的缓存,然后我们可以用 jol-core 来测一下这个类的对象占用情况。
public class Main {public static void main(String[] args){PaddedAtomicLong paddedAtomicLong = new PaddedAtomicLong();System.out.println(ClassLayout.parseInstance(paddedAtomicLong).toPrintable());}
}
输出结果如下:
com.bugfix.objecttest.PaddedAtomicLong object internals:OFFSET SIZE TYPE DESCRIPTION VALUE0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)8 4 (object header) 43 c1 00 f8 (01000011 11000001 00000000 11111000) (-134168253)12 4 (alignment/padding gap) 16 8 long AtomicLong.value 024 8 long PaddedAtomicLong.p1 032 8 long PaddedAtomicLong.p2 040 8 long PaddedAtomicLong.p3 048 8 long PaddedAtomicLong.p4 056 8 long PaddedAtomicLong.p5 064 8 long PaddedAtomicLong.p6 7
Instance size: 72 bytes
Space losses: 4 bytes internal + 0 bytes external = 4 bytes total
可以看到整个对象占用了 72 字节,跟我们上面定义的 MyLong 是一样的结构。CachedUidGenerator 中的 tail、cursor 和 Flag-Buffer 用的就是 PaddedAtomicLong,可以看到都是需要频繁操作的字段,尤其是 tail 和 cursor 指针,基本上就是处于不断变更的,因此避免读到同一缓存行能够大大提高性能。
3.5 未来时间和 ID 生成与获取
uid-generator 在启动阶段就会去填充 UID-Buffer 缓存,官方说是使用未来时间来解决 sequence 天然存在的并发限制,这里的并发限制意思是当 timestamp 和 workerID 固定的时候,对于 uid-generator 每秒能生成的 UID 个数就是 sequence 序列号的位数,也就是 2.2 小节的 DefaultUidGenerator,那我们知道假设 sequence 设置得小一点,比如 10 位,意味者每秒能提供的 UID 个数是 1024,这个对于高并发的业务肯定是不够用的。
因此未来时间就是提前生成下 n 秒的 ID 放到 UID-Buffer 中,这样业务过来就能直接获取到足够的 UID,默认的 buffer 大小是 8192 << 3,也就是 65536,也就是说程序启动就会提前生成这么多的 UID 放到 Buffer 中方便业务获取。
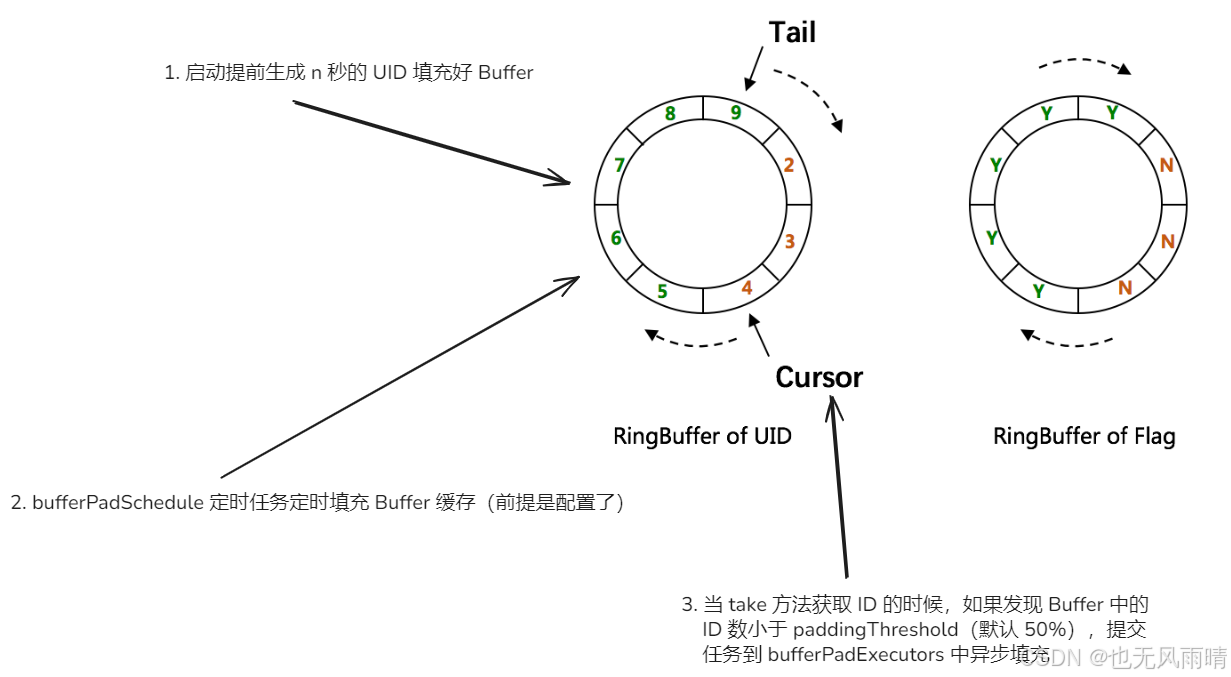
可以看到填充 UID-Buffer 的时机有下面三个:
- 启动提前生成 n 秒的 UID 填充好 Buffer
- bufferPadSchedule 定时任务定时填充 Buffer 缓存(前提是配置了)
- 当 take 方法获取 ID 的时候,如果发现 Buffer 中的 ID 数小于 paddingThreshold(默认 50%),提交任务到 bufferPadExecutors 中异步填充
那么获取 ID 和设置 ID 会不会有并发问题呢,这里就留到下一篇文章讲源码的时候再说,总之经过前面 2.2 的测试大家也可以看到就算是并发获取了 700w UID 也没有出错,而且获取到的 UID 也都是唯一的。
3.6 比特位分配
前面第 2 小节可以看到,uid-generator 每启动一次都会占用一个 workerID,因此如何分配 workerBits、timeBits、seqBits,官方也给出了如下建议。
- 如果是对于并发数要求不高、期望长期使用的应用,可
增加timeBits 位数,减少seqBits 位数。例如节点采取用完即弃的 WorkerIdAssigner 策略,重启频率为12次/天, 那么配置成{"workerBits":23,"timeBits":31,"seqBits":9}时,可支持28个节点以整体并发量14400 UID/s的速度持续运行68年。 - 如果是节点重启比较频繁,但是又期望长期使用的应用,可以增加
workerBits和timeBits,同时减少seqBits,还是一样节点采取用完即弃的 WorkerIdAssigner 策略,重启频率是24 * 12次/天,那么配置成{"workerBits":27,"timeBits":30,"seqBits":6}可以支持37个节点以整体并发量2400 UID/s的速度持续运行34年。
那么这个值是怎么算出来的呢?首先运行时间可以用 timeBits 计算,以第一个建议为例子,31 位的 timeBits 可以存储 1 << 31 这么多秒,然后一年有 365 * 24 * 60 * 60 秒,最终使用 (1L << 31) / (365 * 24 * 60 * 60) 算出来就是 68,而如果每天启动 12 次,那么分配的 23 位 ID 也一共可以使用 (1L << 23) / (28 * 12 * 365) = 68 年,而 14400 是用 (1 << 9) * 28 = 14336,大概算出来,而下面第二个建议的 34 年和并发量 2400 大家也可以用上面的方法算下,当然上面的方法不一定对,如果有不同看法也可以交流下。
3.7 整体性能
我们这里还是给出官方的测试结果,首先测试机器是 MacBook Pro(2.7GHz Intel Core i5, 8G DDR3),然后启动单实例测试吞吐量。
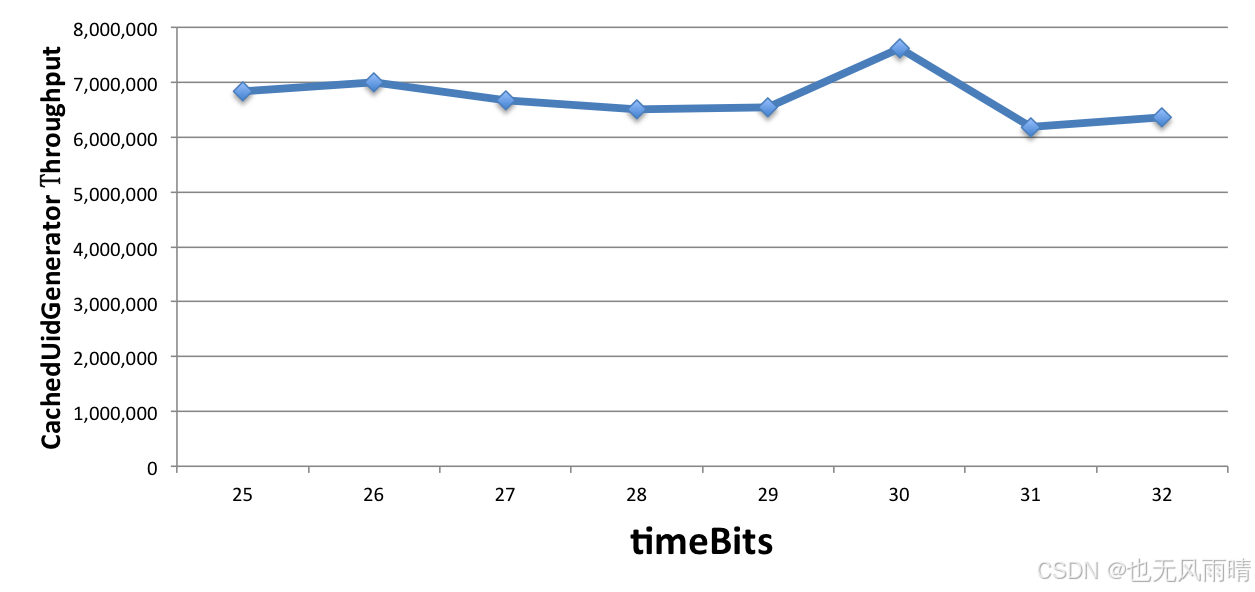
首先就是先固定了 workerBits 为任意一个值,分别统计 timeBits 从 25 至 32,总时长分别对应 1 年和 136 年) 的吞吐量,如下表所示:
| timeBits | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 |
|---|---|---|---|---|---|---|---|---|
| throughput | 6,831,465 | 7,007,279 | 6,679,625 | 6,499,205 | 6,534,971 | 7,617,440 | 6,186,930 | 6,364,997 |
然后再次固定 timeBits 为任意一个值,固定 timeBits 是为了测试一台机器在重启次数变化的情况下通过 seq 分配的 ID 的吞吐量,表格如下:
| workerBits | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 |
|---|---|---|---|---|---|---|---|---|---|---|
| throughput | 6,186,930 | 6,642,727 | 6,581,661 | 6,462,726 | 6,774,609 | 6,414,906 | 6,806,266 | 6,223,617 | 6,438,055 | 6,435,549 |
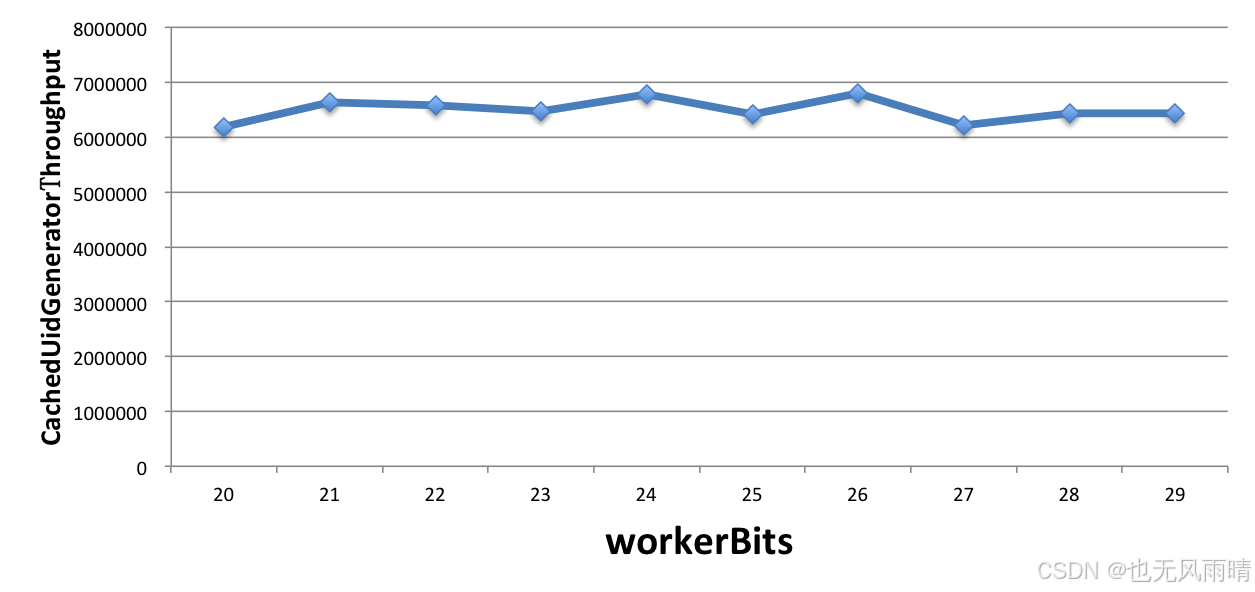
最后, 固定住 workerBits 和 timeBits 位数,分别统计不同数目核数机器的吞吐量,表格如下:
| workerBits | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
| throughput | 6,462,726 | 6,542,259 | 6,077,717 | 6,377,958 | 7,002,410 | 6,599,113 | 7,360,934 | 6,490,969 |
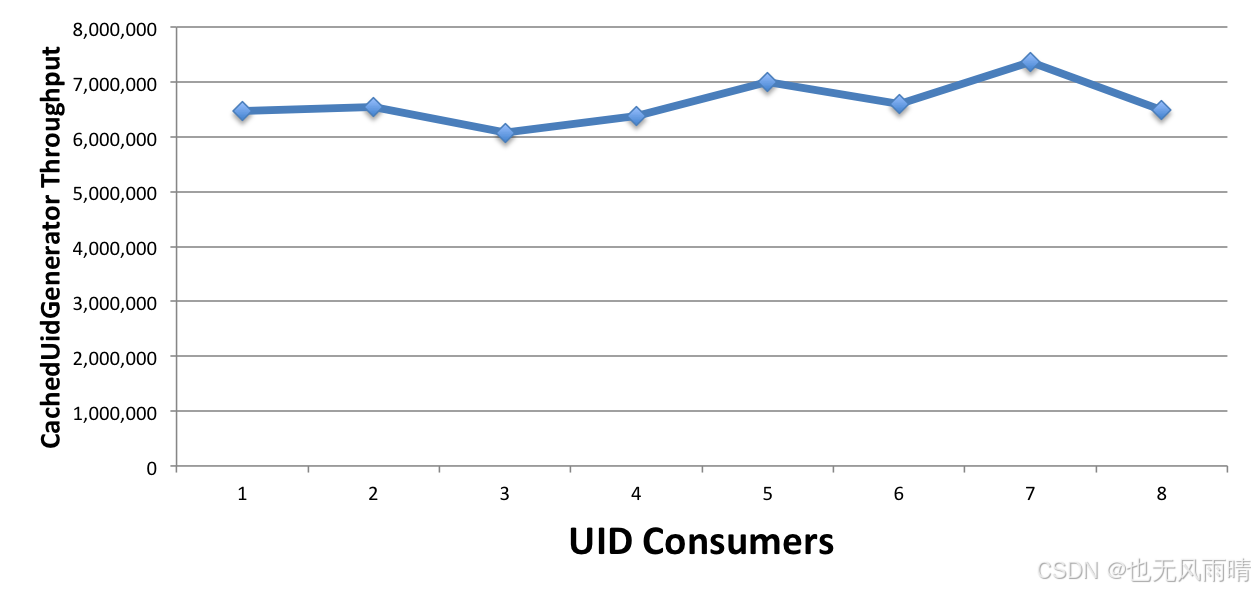
可以看到,按照官方给出来的测试结果,最终测试的吞吐量总在 600w,可以看到吞吐量确实是非常高了,而且使用的年数也能符合我们的要求。
4. 小结
好了,这篇文章我们讲解了 uid-generator 的基础设定以及双 Buffer 结构,下一篇文章再来看下 uid-generator 的源码,主要是篇幅已经够长了,现在已经 2w 字,源码就留到下一篇文章再来看。
如有错误,欢迎指出!!!