Kakfa集群部署及主题创建
前言
上篇文章中Kafka的基本使用-CSDN博客主要介绍了Kafka在Windows环境下的安装和基本使用。这篇文章主要介绍Kafka在集群环境中部署相关概念。
生产环境都是采用linux系统搭建服务器集群,但是重点是在于学习kafka的基础概念和核心组件,所以这里搭建一个简单易用的windows集群方便大家的学习和练习。
Kafka集群
Kafka集群部署
1. 在磁盘根目录创建文件夹cluster,将下载的kafka_2.13-3.8.0安装包解压在cluster目录下。
2. 将kafka_2.13-3.8.0重命名为kafka-node-1,并复制3份,命名为kafka-node-2,kafka-node-3。
3. 再复制一份,重命名为kafka-zookeeper。

修改配置文件
1. 修改config/zookeeper.properties文件
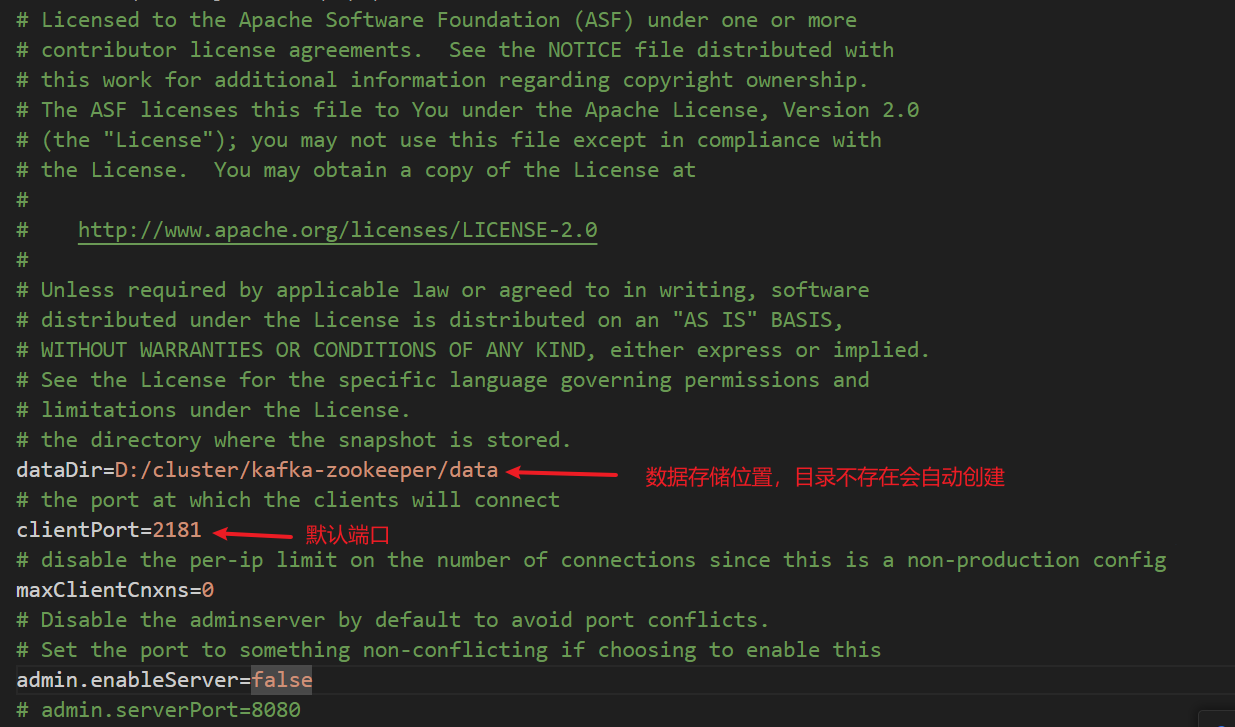
2. 分别修改kafka-node-1、kafka-node-2、kafka-node-3中config/server.properties配置文件。
分别修改三个Kafka的borker.id为1,2,3。以及三个Kafka节点的端口9091、9092、9093。并修改三个Kafka中数据文件路径和Zookeeper软件连接地址。例如:
broker.id=1
listeners=PLAINTEXT://:9091
log.dirs=E:/cluster/kafka-node-1/data
zookeeper.connect=localhost:2181/kafka
封装启动脚本
因为Kafka启动前,必须先启动ZooKeeper,并且Kafka集群中有多个节点需要启动,所以启动过程比较繁琐,这里我们将启动的指令进行封装。
在kafka-zookeeper文件夹下创建zk.cmd批处理文件
在zk.cmd中添加如下命令:
call bin/windows/zookeeper-server-start.bat config/zookeeper.properties
在kafka-node-1,kafka-node-2,kafka-node-3文件夹下分别创建kfk.cmd批处理文件
在kfk.cmd中添加如下命令:
call bin/windows/kafka-server-start.bat config/server.properties
在cluster文件夹下创建cluster.cmd批处理文件,用于启动kafka集群
在cluster.cmd文件中添加内容
cd kafka-zookeeper
start zk.cmd
ping 127.0.0.1 -n 10 >nul
cd ../kafka-node-1
start kfk.cmd
cd ../kafka-node-2
start kfk.cmd
cd ../kafka-node-3
start kfk.cmd
在cluster文件夹下创建cluster-clear.cmd批处理文件,用于清理和重置kafka数据
在cluster-clear.cmd中添加如下命令:
cd kafka-zookeeper
rd /s /q data
cd ../kafka-node-1
rd /s /q data
cd ../kafka-node-2
rd /s /q data
cd ../kafka-node-3
rd /s /q data
双击执行cluster.cmd文件,启动Kafka集群
集群启动命令后,会打开多个黑窗口,每一个窗口都是一个kafka服务,请不要关闭,一旦关闭,对应的kafka服务就停止了。如果启动过程报错,主要是因为zookeeper和kafka的同步问题,请先执行cluster-clear.cmd文件,再执行cluster.cmd文件即可。
Kafka集群启动
相关概念
Broker
Kafka进程一般称为KafkaBroker或KafkaServer。因为Kafka是分布式消息系统,所以在实际生成环境中,是需要多个服务的进程形成集群提供消息服务的。所以每一个服务节点都是Broker, 集群中,为了区分不同服务节点,每一个Broker都有一个全局唯一ID。这个ID同样可以在配置文件中配置。
Controller
因为Kafka是分布式传输系统,所以有多个Broker服务节点,架构是采用分布式系统常见的主从模式,就需要从多个Broker中找到一个用户管理整个Kafka集群的Master(主)节点。这个主节点就称为Controller。主要作用是在Zookeeper的帮助下更好的控制整个Kafka集群。如果在运行状态中,Controller节点出现故障,那么Kafka会使用Zookeeper进行选举新的Controller,让Kakfa集群实现高可用。
Controller功能
1. 监听/Brokers/ids节点的相关变化,这个节点存储的主要是当前集群中的Broker。也就是监听当前集群中Broker节点的变化,主要是监听当前集群中Broker节点数量的增加或者减少的变化,还有Broker对应的数据变化
2. 监听/brokers/topics节点的变化,这个节点存储的主要是当前集群中的Topic。监听topic的新增和修改,还有监听/admin/delete_topics节点下删除topic的变化
3. 监听 /admin/reassign_partitions节点相关的变化,监听 /isr_change_notification节点相关的变化,监听 /preferred_replica_election节点相关的变化。
4. 数据服务
5. 启动分区状态机和副本状态机
Controller选举
第一次启动Kafka集群时,会同时启动多个Broker,每个Broker都会连接到Zookpeeper,并尝试创建一个/Controller节点。
因为Zookpeeper中同一个节点不允许重复创建,所以当有多个Broker时,最终只有一个Broker能创建成功,创建成功的这个Broker就会成为Kafka的集群控制器节点。用来管理整个Kafka集群
没有选举成功的Slava节点就会创建一个监听器,用于监听/controller节点的变化
当controller节点出现故障或者挂掉了,那么此时对应的Zookpeeper连接就会中断,Zookpeeper中的/controller节点就会自动删除掉,而其他的Slave节点因为添加了监听器,当监听到/controller节点被删除后,就会马上向Zookpeeper发出创建/controller节点的请求,一旦创建成功,那么该Broker就会成为新的Controller了。
集群中主题的创建
相关概念
主题(topic)
数据传输方式为发布,订阅模式,也就是说由消息的生产者发布消息,消费者订阅消息后获取数据。为了对消费者订阅的消息进行区分,所以对消息在逻辑上进行了分类,这个分类我们称之为主题:Topic。消息的生产者必须将消息数据发送到某一个主题,而消费者必须从某一个主题中获取消息,并且消费者可以同时消费一个或多个主题的数据。Kafka集群中可以存放多个主题的消息数据。
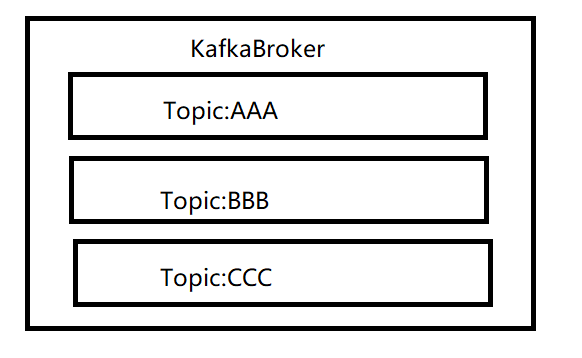
分区(partition)
消息传输采用发布、订阅模式,所以消息生产者必须将数据发送到一个主题,假如发送给这个主题的数据非常多,那么主题所在broker节点的负载和吞吐量就会受到极大的考验,甚至有可能因为热点问题引起broker节点故障,导致服务不可用。一个好的方案就是将一个主题从物理上分成几块,然后将不同的数据块均匀地分配到不同的broker节点上,这样就可以缓解单节点的负载问题。
topic主题的每个分区都会用一个编号进行标记,一般是从0开始的连续整数数字。Partition分区是物理上的概念,也就意味着会以数据文件的方式真实存在。每个topic包含一个或多个partition,每个partition都是一个有序的队列。partition中每条消息都会分配一个有序的ID,称之为偏移量:Offset
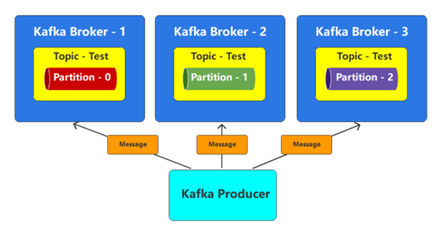
副本(replication)
也就是说,如果一个topic划分了多个分区partition,那么这些分区就会均匀地分布在不同的broker节点上,一旦某一个broker节点出现了问题,那么在这个节点上的分区就会出现问题,那么Topic的数据就不完整了。所以一般情况下,为了防止出现数据丢失的情况,我们会给分区数据设定多个备份,这里的备份,我们称之为:副本Replication。
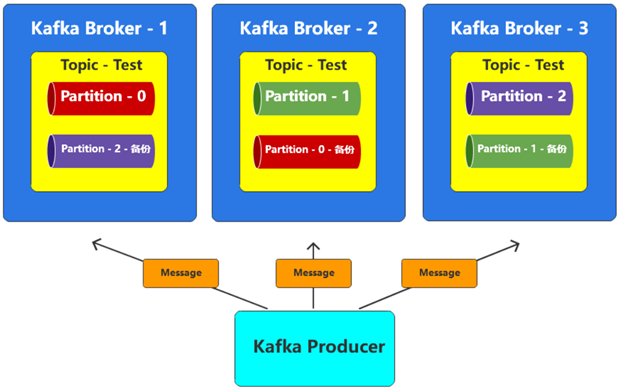
副本类型
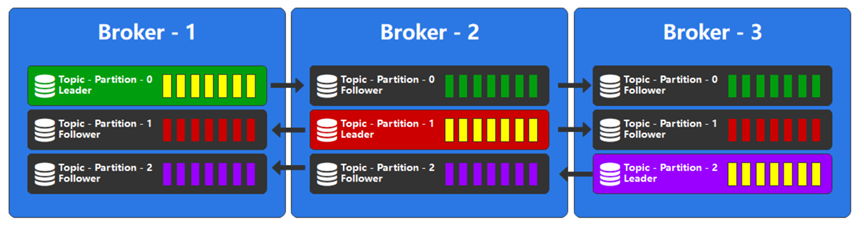
假设我们有一份文件,一般情况下,我们对副本的理解应该是有一个正式的完整文件,然后这个文件的备份,我们称之为副本。但是在Kafka中,不是这样的,所有的文件都称之为副本,只不过会选择其中的一个文件作为主文件,称之为:Leader(主导)副本,其他的文件作为备份文件,称之为:Follower(追随)副本。在Kafka中,这里的文件就是分区,每一个分区都可以存在1个或多个副本,只有Leader副本才能进行数据的读写,Follower副本只做备份使用。
日志
Kafka最开始的应用场景就是日志场景或MQ场景,更多的扮演着一个日志传输和存储系统,这是Kafka立家之本。所以Kafka接收到的消息数据最终都是存储在log日志文件中的,底层存储数据的文件的扩展名就是log。
主题创建后,会创建对应的分区数据Log日志。并打开文件连接通道,随时准备写入数据。
分区和副本
副本就是对每个分区都进行备份,比如1个分区,2个副本,那就此时这1个分区就会有两个备份分布在不同的borker节点上。比如2个分区,2个副本,那么这个2个分区将各自有2个副本分布在不同的borker节点上。比如3个分区,3个副本,那么这个3个分区将各自有3个副本分布在不同的borker节点上。副本有Leader副本和Follower副本,其中leader副本负责读写,follower副本只作为备份使用。
创建主题
创建主题Topic的方式有很多种:命令行,工具,客户端API,自动创建。在server.properties文件中配置参数auto.create.topics.enable=true时,如果访问的主题不存在,那么Kafka就会自动创建主题。
我们采用javaAPI的方式创建主题
public class AdminTopicTest {public static void main(String[] args) {Map<String,Object> map = new HashMap<>();map.put(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");// 管理员对象Admin admin = Admin.create(map);
// 构建主题时需要传递三个参数:主题名称,分区数,副本数String topicName = "topic1";int partitionCount = 1;short replicationCount = 1;NewTopic topic1 = new NewTopic(topicName, partitionCount, replicationCount);String topicName2 = "topic2";int partitionCount1 = 2;short replicationCount1 = 2;NewTopic topic2 = new NewTopic(topicName2, partitionCount1, replicationCount1);// 创建主题CreateTopicsResult result = admin.createTopics(Arrays.asList(topic1, topic2));
// 自定义副本分配策略Map<Integer, List<Integer>> configs = new HashMap<>();configs.put(0, Arrays.asList(1,2)); // 分区0的副本分配策略 1号服务器为Leader分区,2号服务器为Follower分区configs.put(1, Arrays.asList(2,3));configs.put(2, Arrays.asList(1,3));NewTopic test = new NewTopic("test",configs);admin.createTopics(Arrays.asList(test));// 关闭资源admin.close();}
}创建主题原理:集群中创建主题的操作是由controller节点完成的,我们连接的不一定是controller节点,所有当我们向我们连接的broker发送创建主题的请求时,首先连接的该broker会获取到controller节点的位置,然后返回给Admin管理员对象,然后再向controller节点发送创建主题的请求,然后controller节点创建主题成功后,其他broker在监听/brokers/topics时会发现创建的主题,就会将创建的主题同步到各个broker上。
下篇文章将主要介绍Kakfa在集群环境中数据的生产和发送相关操作。