暑期算法训练.4
目录
15.力扣 904.水果成篮
15.1 题目解析:
15.2 算法思路:
15.2.1 暴力解法:
15.2.1 滑动窗口
15.3代码演示:
15.4 总结反思:
16 力扣 438.找出字符串中所有字母的异位词
16.1 题目解析:
16.2算法思路:
16.3 代码实现:
编辑
16.4 总结反思:
17 力扣 30.串联所有单词的子串
17.1 题目解析:
17.2 算法思路:
17.3 代码演示:
编辑
17.4 总结反思:
18. 力扣 76。最小覆盖子串
18.1 题目解析:
18.2 算法思路:
18.2.1 暴力枚举+哈希表
编辑18.2.2 优化解法:
18.3 代码演示:
18.4 总结反思:
19 力扣 704.二分查找
19.1 题目解析:
19.2 算法思路:
19.3 代码演示:
编辑
19.4 总结反思:
15.力扣 904.水果成篮
15.1 题目解析:

要是单单的看这道题目,确实挺难理解的。不过大家仔细的阅读一下,基本可以理解意思,我把题目给翻译了一下:大体的意思可以翻译为找出一个最长的子数组的长度,子数组中不超过两种类型的水果。 最后返回收集到的最大的水果的数目。
15.2 算法思路:
15.2.1 暴力解法:
解法一就是暴力解法,就是找出子数组,找出其中最长的即可,其中要用到哈希表来存储水果出现的种类。(若表中水果超过了2种,则直接不用往里面放了)。
15.2.1 滑动窗口
最主要的还是第二种解法。不过在直到用到滑动窗口做之前,还需要直到为什么要用到滑动窗口?
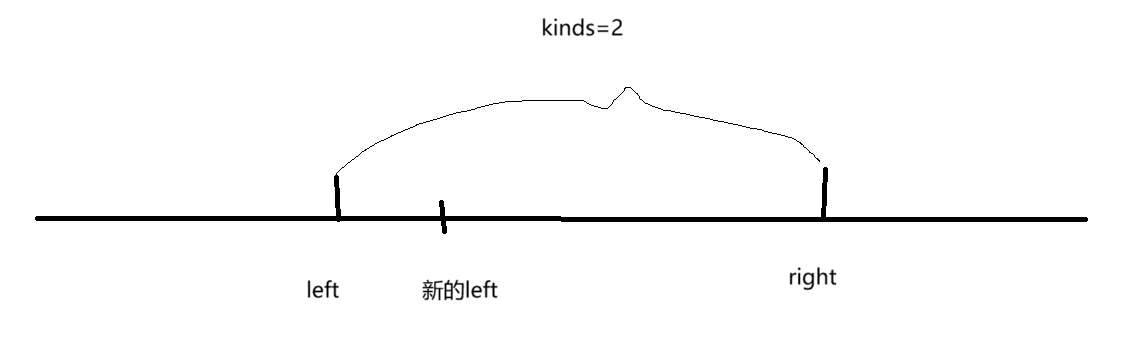
那么大家看着这个图,我来给大家分析一下。图中left与right之间是kinds=2,但是如果说left往右挪动一个数字,挪到了新的left的位置,那么请问,kinds的大小会怎么变呢?
1.kinds不变,因为若left与right中间恰好有一种水果有两个,这不正好抵消了吗?那么此时right也不变。
2.kinds变小,此时说明,恰好把那种水果给挪走了。那么此时right右移(增加水果的种类)。
所以说,right从图中的位置开始移动left也一直向右边移动。所以,他们俩是同向的。既然是同向的,那么也就是会用到滑动窗口。并且这个题也涉及到了子数组。
所以:
1.left,right都是从0开始的。
2.进窗口:这个就是hash[fruits[right]]++.
3.那么判断出窗口的标准就是hash的大小大于2.出窗口,出了窗口之后,hash[fruits[left]]--。减完后,还得加一步判断,如果说你的这个hash[fruits[left]]==0,那么这种水果的数量为0,则要把这种水果从哈希表中给踢出去(种类减一)。之后left才加加。(顺序别搞错了)。因为你left先加加的话,会导致这个位置的水果数量还没判断呢。
15.3代码演示:
1.带容器:若用hash表的话,你得定义两个int,即hash<int,int>,第一个int表示哪种水果,第二个int表示这种水果有几个。并且踢出水果要用hash.erase();
//使用哈希表(容器)
int totalFruit(vector<int>& fruits) {unordered_map<int, int> hash; //统计窗⼝内出现了多少种⽔果int n = fruits.size();int ret = 0;int left = 0;int right = 0;int kind = 0;for (; right < n; right++){if (hash[fruits[right]] == 0) kind++;//若这种水果的数量为0,则要加入这种水果hash[fruits[right]]++;//增加这种水果的数量while (hash.size() > 2)//出窗口{hash[fruits[left]]--;if (hash[fruits[left]] == 0)hash.erase(fruits[left]);//将这种水果删除left++;}ret = max(ret, right - left + 1);}return ret;
}
int main()
{vector<int> fruits = { 3,3,3,1,2,1,1,2,3,3,4 };cout << totalFruit(fruits) << endl;return 0;
}但是呢,带容器的嘛,肯定时间复杂度不够好。所以下面还有一个利用数组来模拟哈希表的写法:
2.用数组代替哈希,得判断一下,若数组中这种水果数量为0,则数组中还没有这种水果,就要++kinds,踢出元素的时候,也是这种水果的数量减到0的时候,才踢出去。
//使用数组模拟哈希表
int totalFruit(vector<int>& fruits) {int hash[100000] = { 0 };//定义哈希数组存放水果int n = fruits.size();int ret = 0;int left = 0;int right = 0;int kind = 0;for (; right < n; right++){if (hash[fruits[right]] == 0) kind++;//若这种水果的数量为0,则要加入这种水果hash[fruits[right]]++;//增加这种水果的数量while (kind > 2)//出窗口{hash[fruits[left]]--;if (hash[fruits[left]] == 0) kind--;//将这种水果删除left++;}ret = max(ret, right - left + 1);}return ret;
}
int main()
{vector<int> fruits = { 3,3,3,1,2,1,1,2,3,3,4 };cout << totalFruit(fruits) << endl;return 0;
}15.4 总结反思:
总结下来还是滑动窗口的那些做题方法。
16 力扣 438.找出字符串中所有字母的异位词
16.1 题目解析:

大家仔细阅读题目,就可知异位词是什么。例如:abc,那么abc,acb,bac,bca,cab,cba。均为abc的异位词。

16.2算法思路:
这个的算法思路比较复杂,细节也比较多。



以上就是本题算法的所有细节与思路了,还是挺多的。关键是不好想。
16.3 代码实现:
//找出字符串中所有字母的异位词
vector<int> findAnagrams(string s, string p) {vector<int> ret;int hash1[26] = { 0 };//这个数组存储p中的字符的个数for (auto& e : p) hash1[e - 'a']++;int hash2[26] = { 0 };//这个数组存储s中的字符个数for (int left = 0, right = 0, count = 0; right < s.size(); right++){char in = s[right];//定义一个进来的变量hash2[in - 'a']++;if (hash2[in - 'a'] <= hash1[in - 'a']) count++;//count的作用是起到一个统计有效字符的作用if (right - left + 1 > p.size())//此时出窗口的判断条件{char out = s[left];if (hash2[out - 'a'] <= hash1[out - 'a']) count--;hash2[out - 'a']--;//这个是在判断count后才减的,因为你要是先减完了,那怎么能判断这个位置的字符的个数呢?left++;}if (count == p.size()) ret.push_back(left);}return ret;
}
int main()
{vector<int> outcome;string s("cbaebabacd");string p("abc");outcome = findAnagrams(s, p);for (auto& e : outcome){cout << e << "";}cout << endl;return 0;
}
16.4 总结反思:
本题还是挺有挑战性的。即使你的思路想出来了,但是如果说你的代码能力不够强,也还是写不出这样的代码的。
17 力扣 30.串联所有单词的子串
17.1 题目解析:
 大家一看到这是个困难题目,好家伙一下子,全蔫了。没事,不要紧。这道题,你仔细的阅读一下,是不是跟上一题寻找异位词差不多,只不过这里的字符变成了字符串。所以本题的解答思路就是,将这些字符串看成字符进行解答。但是细节上呢,可能有些不同。接下来在算法思路里面讲解:
大家一看到这是个困难题目,好家伙一下子,全蔫了。没事,不要紧。这道题,你仔细的阅读一下,是不是跟上一题寻找异位词差不多,只不过这里的字符变成了字符串。所以本题的解答思路就是,将这些字符串看成字符进行解答。但是细节上呢,可能有些不同。接下来在算法思路里面讲解:
17.2 算法思路:

本道题目与上一道题目的算法思路几乎一模一样,就是一些细节不一样而已。
17.3 代码演示:
//串联所有单词的子串
vector<int> findSubstring(string s, vector<string>& words) {vector<int> ret;unordered_map<string, int> hash1;//记录一下words只出现的单词的频率for (auto& e : words) hash1[e]++;int len = words[0].size();for (int i = 0; i < len; i++){unordered_map<string, int> hash2;for (int left = i, right = i, count = 0; right + len <= s.size(); right += len)//注意这个地方是right+len<=s.size(),否则到了最后就会越界。后面是加len{string in = s.substr(right, len);hash2[in]++;if (hash2[in] <= hash1[in]) count++;while (right - left + 1 > len * (words.size()))//这个地方只需要看right-left+1比words中的长度长即可证明该出窗口了{string out = s.substr(left, len);//这个只是一个下标if (hash2[out] <= hash1[out]) count--;//是有效字符hash2[out]--;left += len;}if (count == words.size()) ret.push_back(left);}}return ret;
}
int main()
{string s("barfoothefoobarman");vector<string> words = { "foo","bar" };vector<int> outcome = findSubstring(s, words);for (auto& e : outcome){cout << e << "";}cout << endl;return 0;
}注意是加len。
17.4 总结反思:
还是得先真正的搞懂一道题目之后,才可以对类似的题目得心应手。
18. 力扣 76。最小覆盖子串
18.1 题目解析:
 题目很短,也很好理解,关键就是在于怎么去找出很好的方法去解开这道题。
题目很短,也很好理解,关键就是在于怎么去找出很好的方法去解开这道题。
18.2 算法思路:
18.2.1 暴力枚举+哈希表
 18.2.2 优化解法:
18.2.2 优化解法:

 以上便是这道题的全部思路以及细节 ,其实还是挺复杂的。
以上便是这道题的全部思路以及细节 ,其实还是挺复杂的。
另外还有一些需要注意:
1.能用数组的就用数组,因为数组非常的快(比容器要快)
2.一般,当只有字符的时候,可以用数组,因为字符容易找到下标,就是存储的位置,且你要是hash[26],那得减去'a',。因为只有26个位置。但要是128的话,就没必要减了,因为ascii码表也才127个值
3.字符串只能使用容器(哈希表),因为用数组,无法找到可以存储的位置。且容器还得有string,int。即unordered_map<string,int>才可以。
18.3 代码演示:
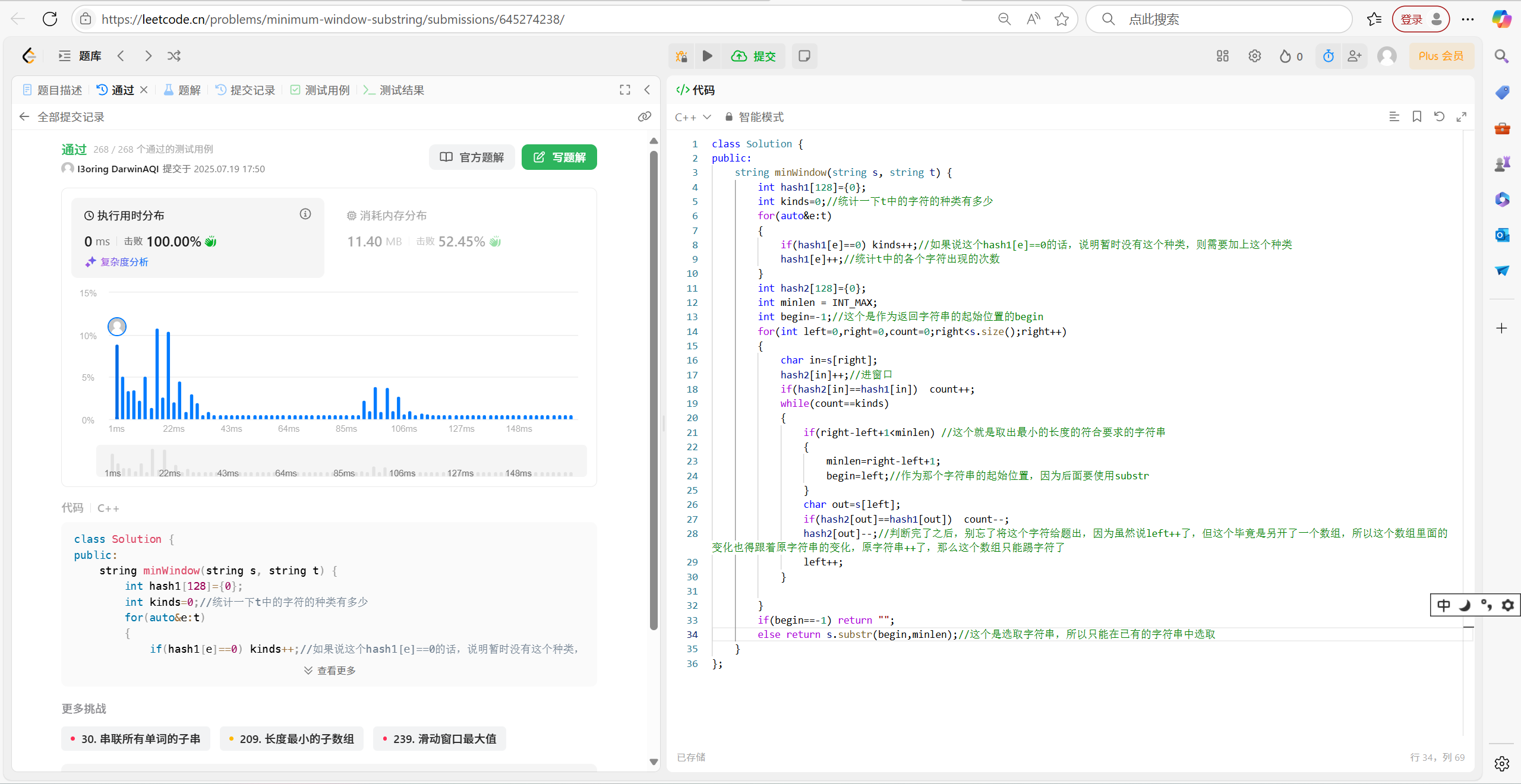
//最小覆盖子串
string minWindow(string s, string t) {int hash1[128] = { 0 };int kinds = 0;//统计一下t中的字符的种类有多少for (auto& e : t){if (hash1[e] == 0) kinds++;//如果说这个hash1[e]==0的话,说明暂时没有这个种类,则需要加上这个种类hash1[e]++;//统计t中的各个字符出现的次数}int hash2[128] = { 0 };int minlen = INT_MAX;int begin = -1;//这个是作为返回字符串的起始位置的beginfor (int left = 0, right = 0, count = 0; right < s.size(); right++){char in = s[right];hash2[in]++;//进窗口if (hash2[in] == hash1[in]) count++;while (count == kinds){if (right - left + 1 < minlen) //这个就是取出最小的长度的符合要求的字符串{minlen = right - left + 1;begin = left;//作为那个字符串的起始位置,因为后面要使用substr}char out = s[left];if (hash2[out] == hash1[out]) count--;hash2[out]--;//判断完了之后,别忘了将这个字符给题出,因为虽然说left++了,但这个毕竟是另开了一个数组,所以这个数组里面的变化也得跟着原字符串的变化,原字符串++了,那么这个数组只能踢字符了left++;}}if (begin == -1) return "";else return s.substr(begin, minlen);//这个是选取字符串,所以只能在已有的字符串中选取
}
int main()
{string s("ADOBECODEBANC");string t("ABC");string outcome = minWindow(s, t);cout << outcome << endl;return 0;
}18.4 总结反思:
处理好一些细节,就可以把一道题做的很好。
19 力扣 704.二分查找
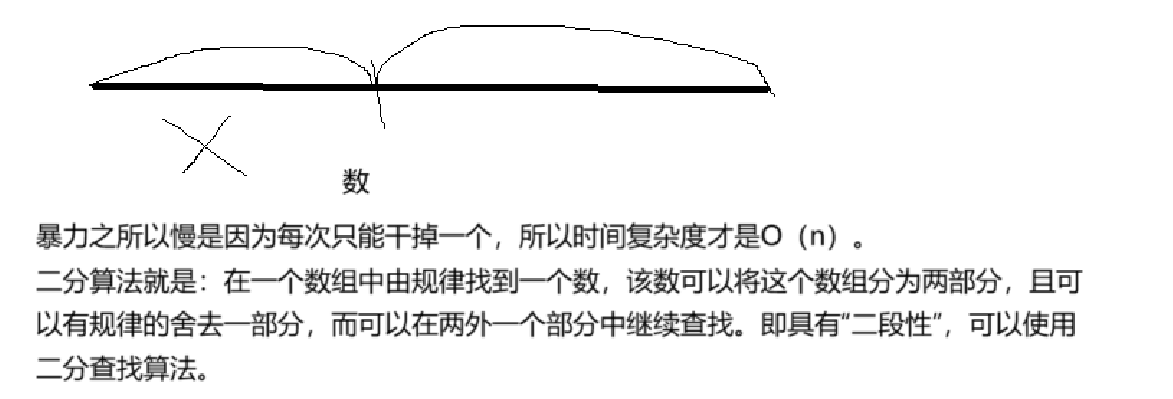
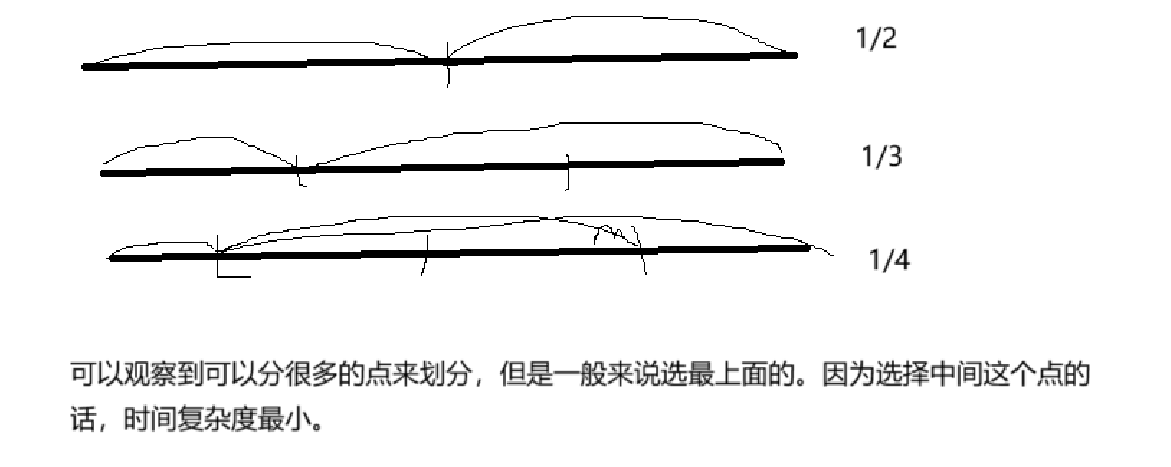
在介绍这道题目之前,先来介绍一下二分算法。
二分算法,可能刚开始使用,会觉得有点难。但是你要是洞悉了二分算法的原理,其实挺简单的。
且这个算法不管数组有序还是没序。你只要找到规律之后,都可以使用二分算法的。
19.1 题目解析:

这道题算是我从写博客以来最简单的。暴力可以解决,但今天咱们讲二分算法。
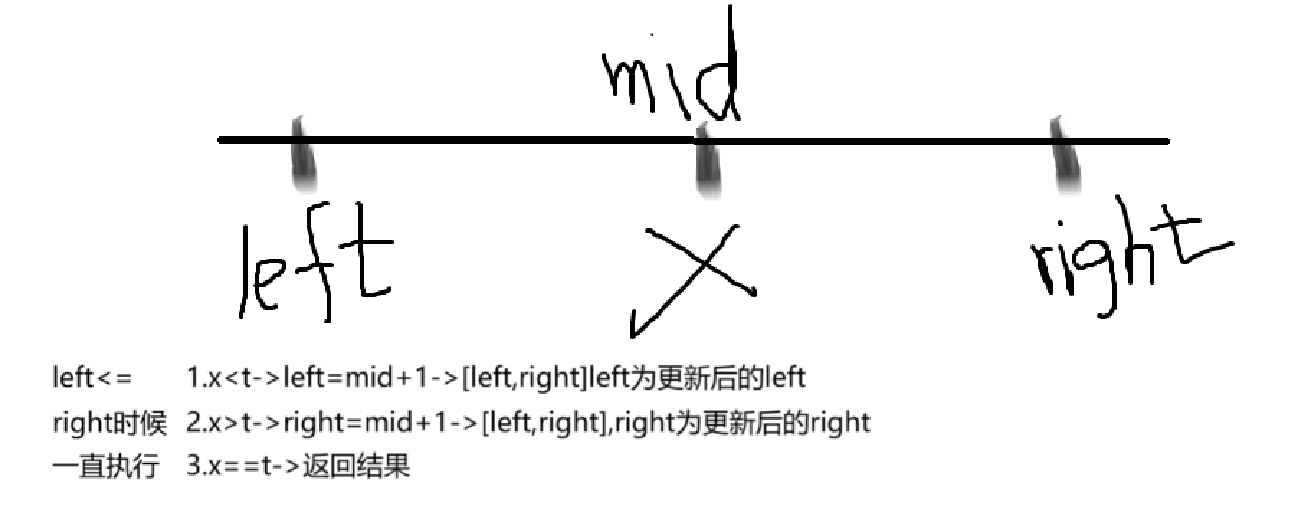
19.2 算法思路:
19.3 代码演示:
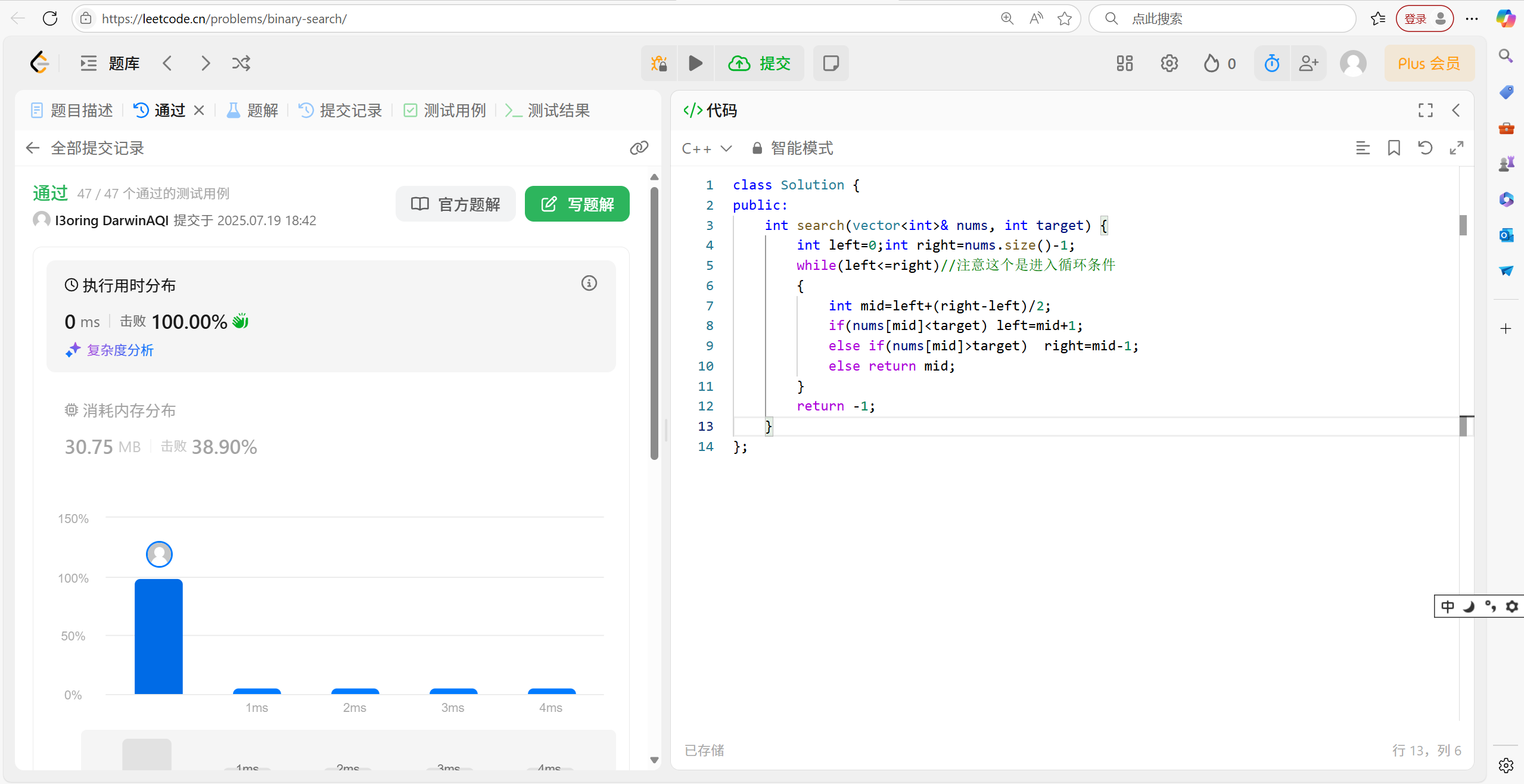
int search(vector<int>& nums, int target) {int left = 0; int right = nums.size() - 1;while (left <= right)//注意这个是进入循环条件{int mid = left + (right - left) / 2;if (nums[mid] < target) left = mid + 1;else if (nums[mid] > target) right = mid - 1;else return mid;}return -1;
}
int main()
{vector<int> nums = { -1,0,3,5,9,12 };int target = 9;cout << search(nums, target) << endl;return 0;
}这个求中间点一般是用到(right-left)/2+left。因为如果使用(left+right)/2,left+right会有溢出的风险。
19.4 总结反思:
这只是二分算法的一道开胃小菜。后面还有更大的礼物呢。