EINO框架解读:字节跳动开源的大模型应用开发框架
1 框架结构
1.1 基本组成
-
Eino(本文档所解读的仓库):包含类型定义、流处理机制、组件抽象、编排功能、切面机制等。
-
EinoExt:组件实现、回调处理程序实现、组件使用示例,以及各种工具,如评估器、提示优化器等。
-
Eino Devops:可视化开发、可视化调试等。
-
EinoExamples:是包含示例应用程序和最佳实践的代码仓库。
2 四种数据处理方式
2.1 非流式处理
-
适用于数据量较小、对响应时间要求不高、处理逻辑固定的场景,如批量数据处理、静态报表生成等。
-
在eino框架中,
Runnable接口定义了不同的流式范式,其中Invoke属于非流式处理,而Stream、Collect和Transform属于流式处理
2.2 流式处理
2.2.1 使用场景
-
适用于数据实时生成、对响应时间要求高、数据量较大的场景,如在线聊天、实时监控等
-
在eino框架中,流式处理可以在graph执行过程中自动进行拼接、转换、合并和复制等操作
-
比如:在聊天机器人场景中,ChatModel 会实时输出消息块,符合我们关注的场景,因此重点解读流式处理的相关实现
2.2.2 流式处理能力
-
转换(Boxing):在图执行过程中,当需要流时,Eino 会自动将非流式转换为流式。
-
拼接(Concatenate):主要用于将流数据拼接成非流数据,以满足只接受非流式输入的下游节点的需求。比如:对于只接受非流式输入的下游节点ToolsNode,Eino 会自动将流拼接起来。
-
合并(Merge):当多个流汇聚到一个下游节点时,Eino 会自动合并这些流。
-
复制(Copy):当流分散到不同的下游节点或传递给回调处理器时,Eino 会自动复制这些流
理解一下copy操作:
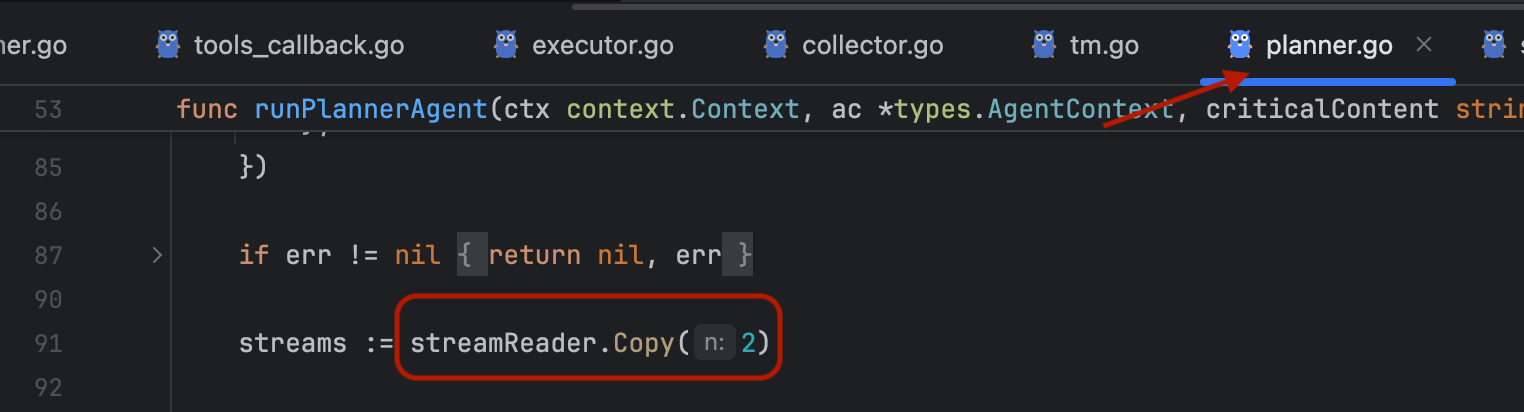
这里调用 Copy(2) 方法把 streamReader 代表的流式响应复制成两份。这两份流分别用于不同的处理任务:
-
第一份流(streams[0])通过
stream.Reply()用于实时把流式响应内容展示给用户 -
第二份流(streams[1])通过
CollectAgent()收集流式响应的最终结果,将流式响应合并成一个完整的字符串,便于传递给后续操作处理。
2.2.3 处理范式
| 处理范式 | 类型 | 解释 | 对应能力 |
| Invoke | 非流式 | 接收非流类型 I ,返回非流类型 O | 一次性处理完整数据 |
| Stream | 流式 | 接收非流类型 I , 返回流类型 StreamReader [O] | 转换(Boxing) |
| Collect | 流式 | 接收流类型 StreamReader [I] , 返回非流类型 O | 拼接(Concatenate) |
| Transform | 流式 | 接收流类型 StreamReader [I] , 返回流类型 StreamReader [O] | 合并(Merge) |
2.2.4 以stream范式为例串联整个实现链路
Stream 范式达成了从非流输入到流输出的处理过程,也是项目里主要使用的操作,因此以Stream 接口为例,讲解“从定义到借助 runnablePacker 实现、再到最终被调用”的整个链路
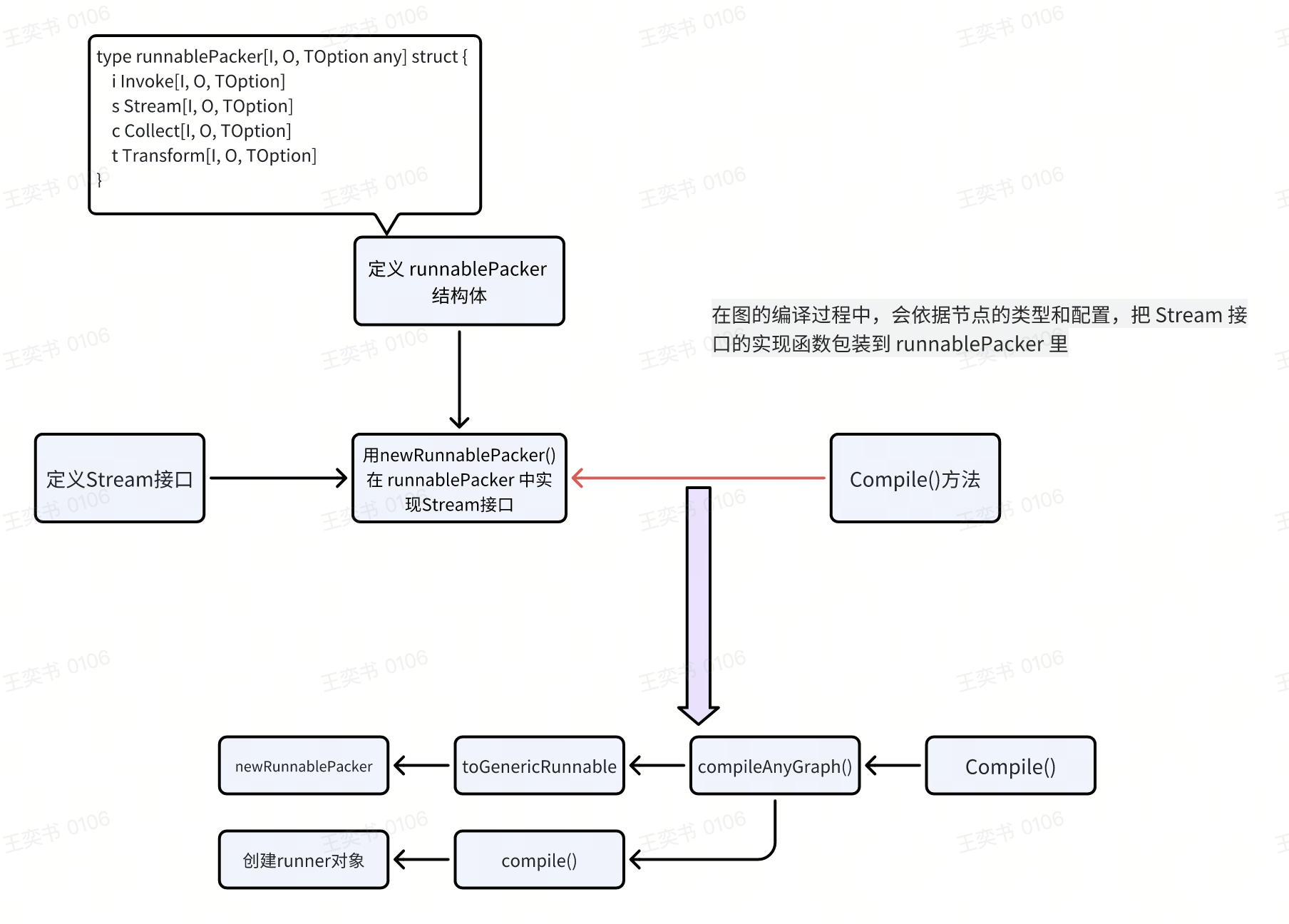
补充:newRunnablePacker中还对invoke、stream、collect、tranform添加了回调,在基础函数执行的前后分别插入 onStartXXX 和 onEndXXX 回调,在出错时插入 onError 回调
func streamWithCallbacks[I, O, TOption any](s Stream[I, O, TOption]) Stream[I, O, TOption] {return runWithCallbacks(s, onStart[I], onEndWithStreamOutput[O], onError)
}func collectWithCallbacks[I, O, TOption any](c Collect[I, O, TOption]) Collect[I, O, TOption] {return runWithCallbacks(c, onStartWithStreamInput[I], onEnd[O], onError)
}func transformWithCallbacks[I, O, TOption any](t Transform[I, O, TOption]) Transform[I, O, TOption] {return runWithCallbacks(t, onStartWithStreamInput[I], onEndWithStreamOutput[O], onError)
}3 三种结构
chain、graph、workflow这三个结构都可以通过 Compile 方法编译成可运行的对象,编译后的对象支持四种范式,即 Invoke、Stream、Collect 和 Transform
3.1 Chain
-
简单的链式有向图,只能向前推进
-
支持流式和非流式处理
-
通过 NewChain 函数创建一个 Chain,然后使用 AppendXXX 方法添加不同的节点,最后通过 Compile 方法编译成可运行的对象
3.2 Graph
-
一个循环或非循环的有向图
-
通过 NewGraph 函数创建一个 Graph,然后使用 AddXXXNode 方法添加节点,使用 AddEdge 或 AddBranch 方法添加边或分支
3.2.1 Node节点
-
结构
type graphNode struct {cr *composableRunnable // 包含节点的输入输出类型、调用和转换方法等信息g AnyGraph // 如果节点是子图,则存储子图信息nodeInfo *nodeInfoexecutorMeta *executorMeta // 执行器的元信息,包括组件类型、是否支持回调切面等instance anyopts []GraphAddNodeOpt
}节点类型有 ChatModel、ToolsNode、ChatTemplate
-
添加节点
通过graph的AddXXXNode方法将节点添加到图中,例如:
func (g *graph) AddChatModelNode(key string, node model.ChatModel, opts ...GraphAddNodeOpt) error {gNode, options := toChatModelNode(node, opts...) // 创建一个chatModel节点return g.addNode(key, gNode, options) // 把这个节点添加到图里 }底层实现:
graph结构体中,node是用map存储的
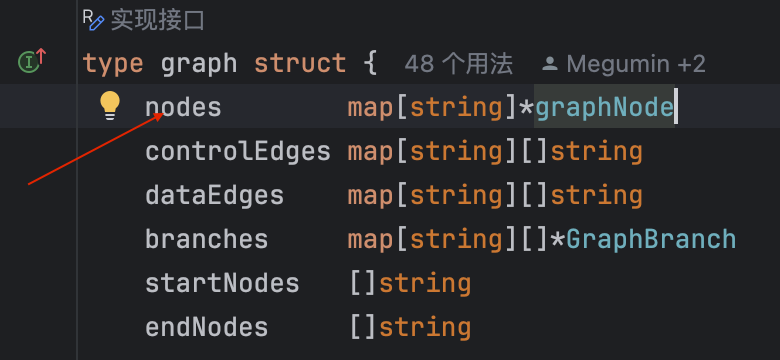
addNode()中先会检查确保要添加的节点合法,并且前置/后置处理器的类型与图和节点的类型匹配
最后g.nodes[key] = node把node写入map
-
编译节点
节点编译和图编译的关系:
-
如果节点是子图节点,会递归编译其内部的子图
-
计算节点之间的数据依赖和控制依赖关系,包括数据前驱节点和控制前驱节点
-
初始化运行器runner,并设置其相关属性,包括通道订阅信息、依赖关系、输入通道、运行类型、急切模式、通道构建器、输入输出类型等
-
节点编译是图编译的基础,是对图中每个独立节点进行处理在图的compile方法中,会遍历图中的所有节点并调用
node.compileIfNeeded(ctx)进行节点编译 -
图编译负责将所有节点编译的结果进行整合,构建出完整的图执行结构。在图编译过程中,会根据节点编译生成的可执行对象,生成通道调用信息(chanCall),确定节点之间的数据依赖和控制依赖关系,并初始化运行器runner
-
3.2.2 Edge边
图中存在两种类型的边:dataEdges 数据边和 controlEdges控制边,分别用于表示数据流动和控制依赖关系
注意⚠️eino为v0.3.14的旧版本,边不区分类型,只有一种默认的edge
-
添加边
g := NewGraph[string, string]() // 添加节点 A 和 B err := g.AddLambdaNode("A", InvokableLambda(func(ctx context.Context, input string) (output string, err error) { return "", nil })) err := g.AddLambdaNode("B", InvokableLambda(func(ctx context.Context, input string) (output string, err error) { return "", nil })) // 添加控制边 err = g.addEdgeWithMappings("A", "B", false, true) // 只添加控制边,不添加数据边// 添加节点 C 和 D err := g.AddLambdaNode("C", InvokableLambda(func(ctx context.Context, input string) (output string, err error) { return "output from C", nil })) err := g.AddLambdaNode("D", InvokableLambda(func(ctx context.Context, input string) (output string, err error) { return "", nil })) // 添加数据边 err = g.addEdgeWithMappings("C", "D", true, false) // 只添加数据边,不添加控制边 -
控制边(Control Edges)
控制边用于表示节点之间的控制依赖关系,它不涉及数据的传递,主要用于控制节点执行的顺序。当一个节点完成执行后,会通知依赖它的节点可以开始执行。
func (g *graph) addEdgeWithMappings(startNode, endNode string, noControl bool, noData bool, mappings ...*FieldMapping) (err error) {// ...if !noControl {for i := range g.controlEdges[startNode] {if g.controlEdges[startNode][i] == endNode {return fmt.Errorf("control edge[%s]-[%s] have been added yet", startNode, endNode)}}g.controlEdges[startNode] = append(g.controlEdges[startNode], endNode)if startNode == START {g.startNodes = append(g.startNodes, endNode)}if endNode == END {g.endNodes = append(g.endNodes, startNode)}}// ... }
举例:
假设我们有一个图,其中有两个节点 A 和 B,节点 B 需要在节点 A 执行完成后才能开始执行,可以通过添加控制边来实现该功能
-
数据边(Data Edges)
表示节点之间的数据传递关系,一个节点的输出数据会作为另一个节点的输入数据
func (g *graph) addEdgeWithMappings(startNode, endNode string, noControl bool, noData bool, mappings ...*FieldMapping) (err error) {// ...if !noData {for i := range g.dataEdges[startNode] {if g.dataEdges[startNode][i] == endNode {return fmt.Errorf("data edge[%s]-[%s] have been added yet", startNode, endNode)}}g.addToValidateMap(startNode, endNode, mappings)err = g.updateToValidateMap()if err != nil {return err}g.dataEdges[startNode] = append(g.dataEdges[startNode], endNode)}// ... }举例:
假设我们有一个图,其中有两个节点
C和D,节点C的输出数据需要作为节点D的输入数据,可以通过添加数据边
3.2.3 runner
-
结构
runner是整个图执行的核心控制器,负责管理图的运行状态、协调各个组件之间的交互,并处理任务的调度和执行
type runner struct {chanSubscribeTo map[string]*chanCallsuccessors map[string][]stringdataPredecessors map[string][]stringcontrolPredecessors map[string][]string// 其他字段... } -
实现
runner负责图的执行,在graph的compile()方法中创建runner对象
3.2.4 TaskManager
-
结构
type taskManager struct {runWrapper runnableCallWrapperopts []OptionneedAll boolmu sync.Mutexl *list.Listdone chan *tasknum uint32 } -
实现
runner 在执行图时,会初始化 taskManager 来管理任务的执行。runner 会根据图的状态和任务依赖关系,计算出下一批需要执行的任务,并将这些任务提交给 taskManager
3.2.5 数据的传输和存储
3.3 Workflow
-
Workflow 是 Graph 的包装器,通过声明节点之间的依赖关系和字段映射来替代添加边的操作(举例:先声明了2个node A和B,然后再声明node的依赖关系是B依赖于A,也就是说先执行完A再执行B)
-
有向无环图
4 关键问题的解释
4.1 eino的function call全流程

4.1.1 初始化与工具注册
-
初始化图
-
addNode
-
addEdge
-
Compile()
-
-
工具注册
eino提供了InferTool函数,可以把本地的自己写的function封装成tool
func InferTool[T, D any](toolName, toolDesc string, i InvokeFunc[T, D], opts ...Option) (tool.InvokableTool, error) {ti, err := goStruct2ToolInfo[T](toolName, toolDesc, opts...)if err != nil {return nil, err}return NewTool(ti, i, opts...), nil
}使用示例:

4.1.2 输入消息处理与模型推理
-
编译后的图调用r.Invoke(ctx, &types.AgentContext)来启动执行,传入req后节点会按照预先定义的顺序一次执行(req是用户输入的内容比如“帮我规划一个游乐场行程”)
-
创建agent (react.NewAgent)
-
项目中的exectueNode、plannerNode都是用react.NewAgent来创建agent的,但是只有executeNode注册了tool列表
-
调用NewAgent后发生的事:
-
NewAgent创建出的graph流程:(⚠️在4.1.2这个步骤里,其实只执行到图中的【1】步骤)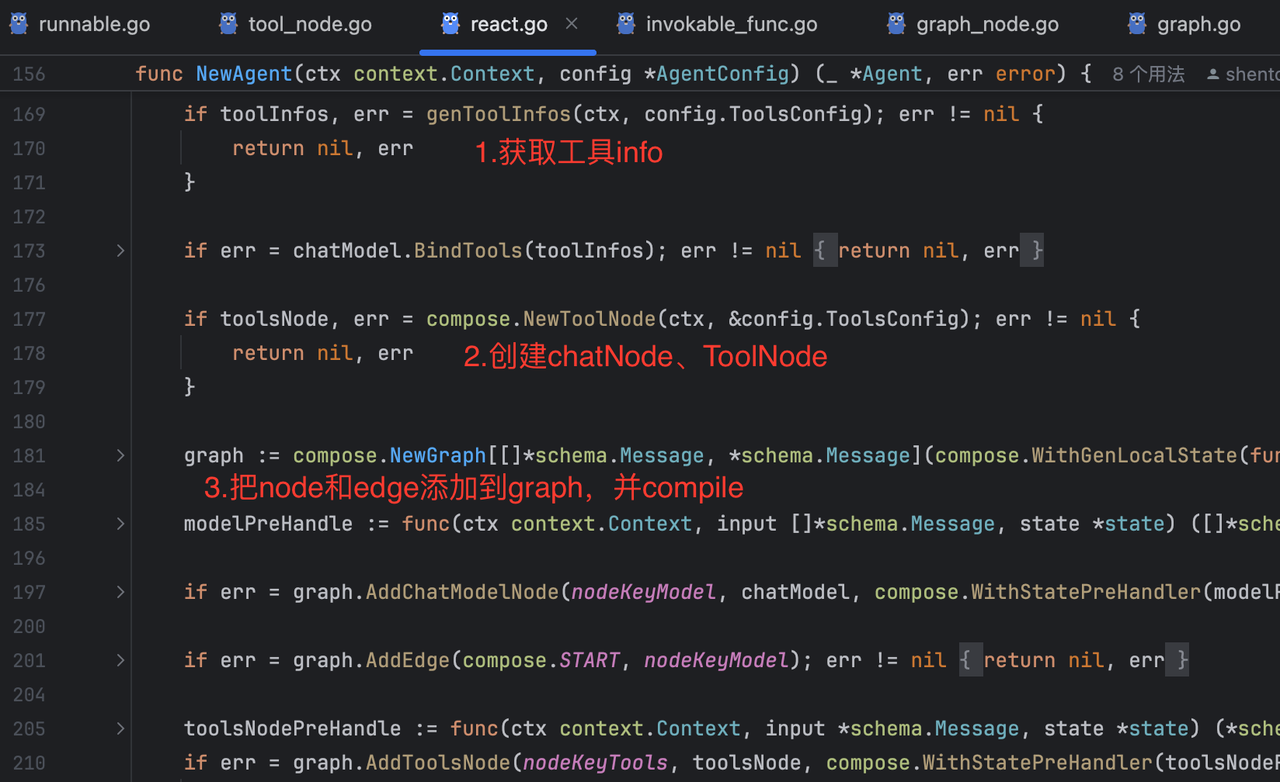
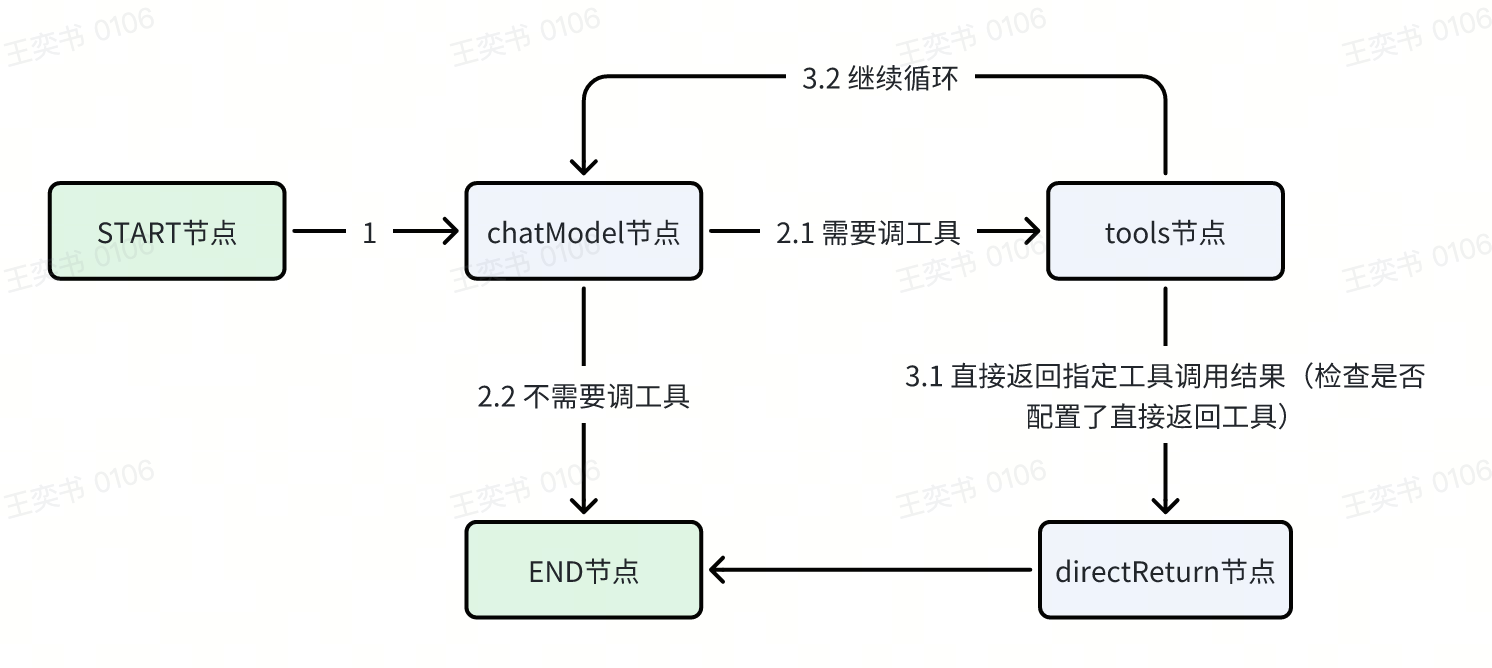
-
-
创建完agent后,构造并传递消息给agent
-
以项目的task_runner为例,调用Stream方法触发消息处理,把消息发给agent

-
通过CollectAgent函数收集模型输出
result, err := utils.CollectAgent(ctx, stream)
-
至此,已经拿到了模型推理的结果,下一步需要对结果进行分析,判断需不需要调用tool
4.1.3 工具调用决策与任务生成
-
决定调用哪个tool
-
“判断是否要调工具”这个操作是在modelPost这个branch实现的:
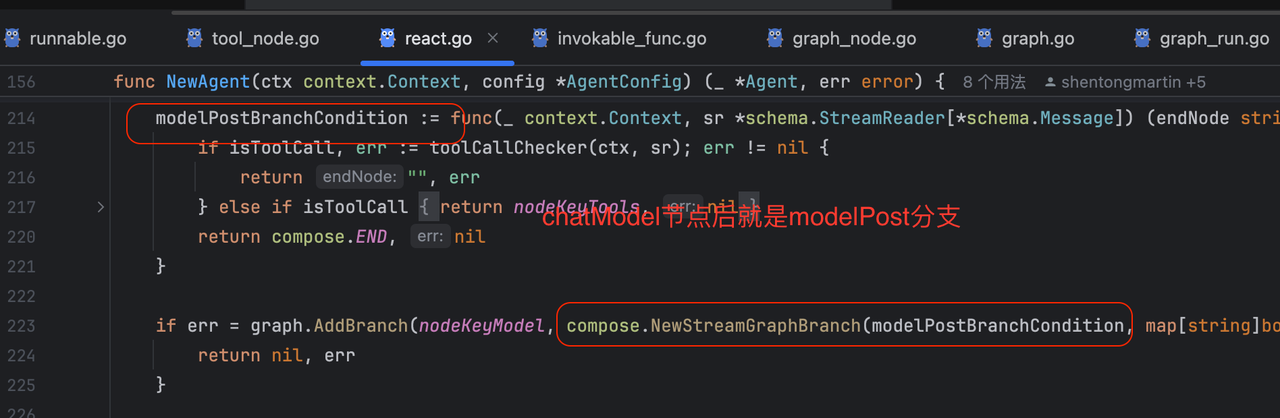
-
如果判断需要调用工具,就会进入tool节点处理(nodeKeyTools)
-
否则进入END节点
-
补充⚠️toolCallChecker是怎么判断是否要调工具的?
toolCallChecker 的判断逻辑主要分为默认和自定义两种情况,当用户没有配置自定义的StreamToolCallChecker时,默认的firstChunkStreamToolCallChecker就会生效。默认的firstChunkStreamToolCallChecker步骤:1.遍历流式输出的每个消息块2.遇到第一个包含 ToolCalls 的块 → 立即返回 true(需要调用工具)3.遇到第一个非空 Content 的块但没有工具调用 → 返回 false(不需要工具)
-
-
找到下一个要执行的task
-
在创建graph的时候,调用了compose.NewToolNode来创建工具节点
-
当模型生成包含ToolCalls的消息时,工具节点会遍历每个ToolCall,根据工具名称在注册的工具列表中查找对应的工具实例
-
(流程会通过分支判断进入工具节点,此时会触发 ToolsNode 的 Invoke 方法)Invoke里调用的genToolCallTasks这个方法,该方法主要功能就是生成[]toolCallTask
-
找到后,会调用该工具的InvokableRun方法,传入参数执行任务
所以对应的graph流转图里,其实tools节点具体是有2个大步骤的: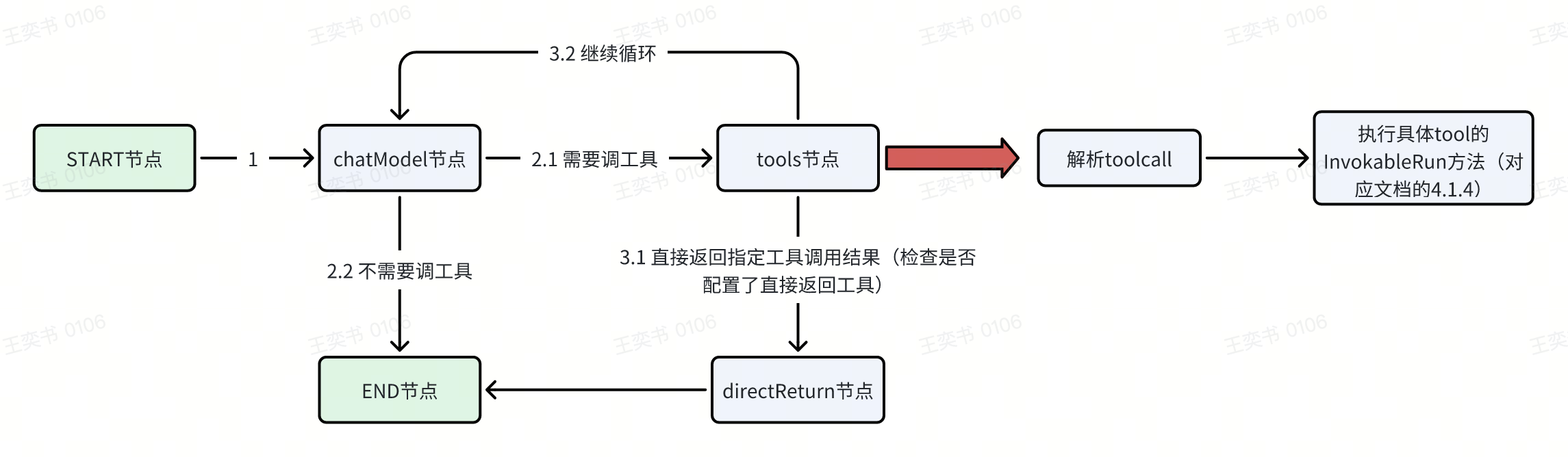
-
4.1.4 任务执行与回调处理
-
具体tool任务的执行
-
前面提到了,tool节点已经解析出了需要调的具体的[]toolCallTask
-
工具调用task是并行的,具体看实现细节:
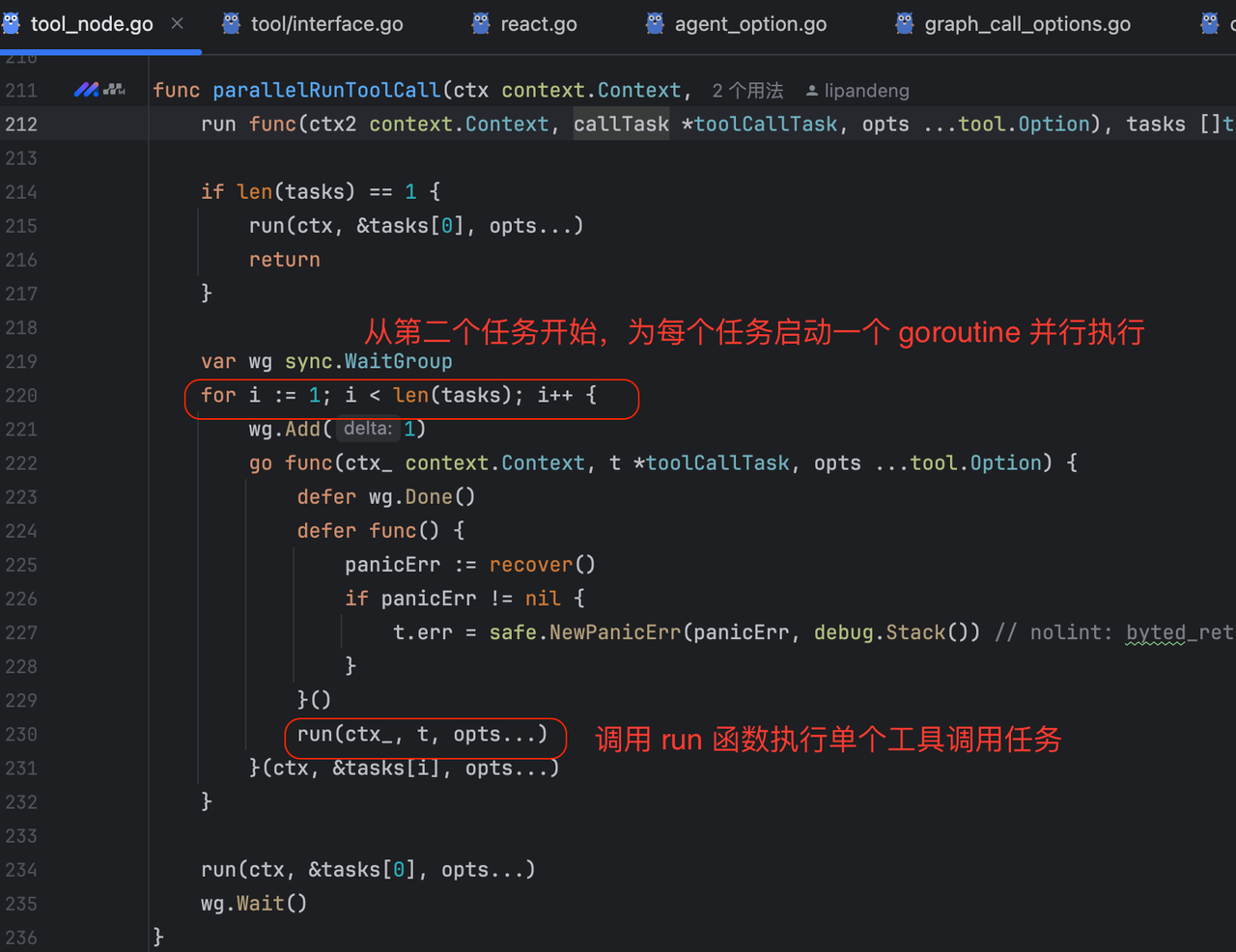
-
每个工具都要实现InvokableRun接口,这个接口里有具体调后端服务的操作
-
项目的3个tool节点可以作为具体的例子,比如浏览器工具、linkreader工具都在自己的InvokableRun接口实现了请求后端service的操作
-
-
在任务开始时分别调用相应回调函数
-
eino框架默认的toolsNodePreHandle的作用是把tool节点收到的消息添加到state的消息列表中,这一步是为了方便上下文管理,在4.2中会展示细节,这里就不多说了
-
编程时还可以自定义回调处理,比如项目里针对【浏览器tool节点】产生的图片结果,onEnd函数里会把图片转 URL
-
4.1.5 结果处理与反馈循环
-
若任务出错,toolCallTask 的 err 字段记录错误并返回。在流式调用中,错误会通过 schema.StreamReader 传递
-
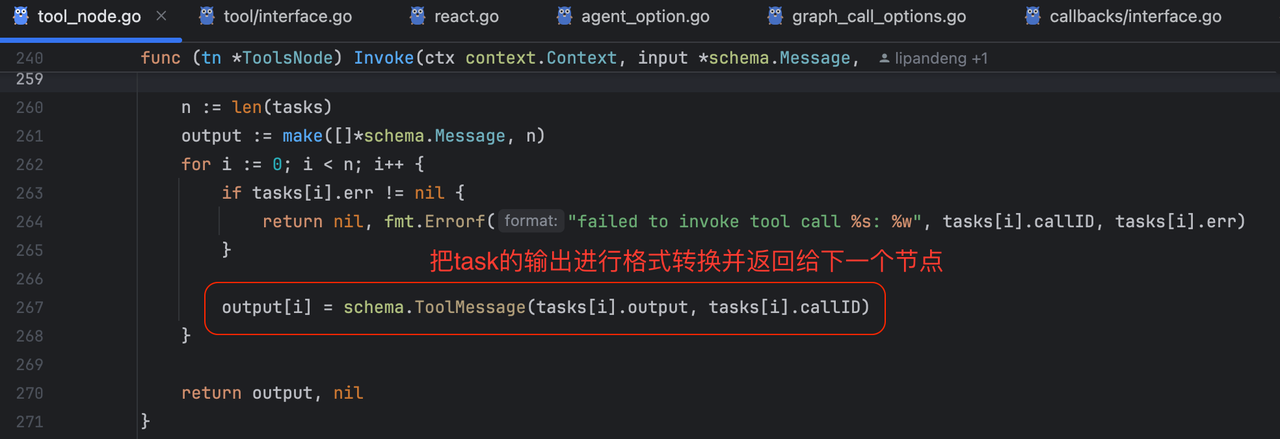
若成功,将结果封装成 schema.Message,反馈给 ChatModel 继续推理决策,循环直至任务完成
4.2 历史上下文的处理
整个eino框架分为了4个层级的结构来进行上下文传递和管理
4.2.1 message
每个处理节点自动将输入/输出追加到state.Messages,形成完整的对话历史链
type Message struct {Role RoleType // 消息角色(User/Assistant)Content string // 内容ToolCalls []*ToolCall // 历史工具调用链
}4.2.2 状态管理
主要功能是维护当前会话的状态
ttype state struct {Messages []*schema.Message // 存储完整对话历史ReturnDirectlyToolCallID string //
}4.2.3 添加prompt
创建ReAct Agent时配置了MessageModifier,能够接收上下文和输入消息,返回修改后的消息。具体来说,在消息传递给ChatModel之前,MessageModifier可以进行system prompt的添加,在这一步可以读fornax配置。

将当前的输入消息(即工具节点的输入)添加到状态的消息列表中。这一步的作用是记录整个代理的执行历史,确保每次工具调用的输入都被保存下来,供后续步骤使用,比如模型的下一次生成可能需要参考之前的交互历史