C++ std::thread线程类 相关问题、函数总结
问题:
1、std::thread构造函数,可以接收一个函数体吗?
std::thread构造函数可以接收一个函数体作为可调用对象。
在C++11标准中,std::thread支持通过:
构造函数直接传递(函数、lambda表达式、函数指针)等可调用对象,【创建】并【启动】新线程。
2、std::thread什么时候启动?
从C++11开始,当你创建一个std::thread对象并传入一个函数时(对象的实例化),
这个线程会自动开始执行该函数。
因此,通常你不需要显式调用start()方法!
std::thread t(threadFunction); // 创建并启动线程
3、在join\detach之后,哪些函数还能调用,哪些不能再调用?
t2.detach(); // 线程分离,不会等待t2的线程函数执行完毕,主线程可以继续执行
在join\detach之后,t2是不可连接状态。
但是仍然可以调用get_id()\joinable()\等方法。不可再调用join\detach等方法。
join之后就是不可连接状态,即使move到新线程对象之后,也不行,t2也不能join。
t1 线程失去所有权,t1中的线程函数也就结束了,所以t1不会执行线程函数。
t2获得了t1的所有权,去执行t1的线程函数。
std::thread t1([] {std::cout << "Hello, world!" << std::endl;});
t1.join();
thread t2(move(t1));4、线程数组中添加lambda表达式类型的线程元素,为何只能用emplace_back,而不用push_back()?

解释:
这个问题涉及C++中push_back和emplace_back 对lambda表达式 的不同处理方式。
以下是详细解释:
4.1 核心区别:
push_back:需要构造一个临时对象,然后进行【拷贝/移动】操作;
emplace_back:直接在容器内构造对象,避免了临时对象的创建;
4.2 具体原因分析:
1.lambda表达式的特性:
每个lambda表达式都有独特的匿名类型;
lambda不能直接赋值给另一个lambda变量(即使签名相同);
2.push_back失败的原因:
push_back需要先创建一个临时lambda对象;
然后尝试将这个临时对象【拷贝/移动】到容器中;
但lambda表达式的【拷贝构造函数被删除】,不能直接赋值(因为lambda本质上是匿名类对象);
3.emplace_back成功的原因:
emplace_back直接在容器内构造lambda对象;
避免了拷贝/移动操作;
emplace_back【接受lambda表达式】作为参数并就地构造;
5、C++ thread和 winAPI\linux中的API区别?
std::thread 提供了一个方便的方式来实现多线程编程,使得开发者能够充分利用现代多核处理器的能力。通过灵活的线程管理和同步机制,可以有效地实现并发计算。
5.1 在 Linux 和其他 Unix-like 系统上使用 std::thread 时,通常需要链接 pthread 库,因为 C++11 的 std::thread 是基于 POSIX 线程库(pthread)实现的。因此,当编译一个使用 std::thread 的 C++ 程序时,需要在编译命令中添加 -lpthread 选项,比如:
g++ -std=c++11 -o my_program my_program.cpp -lpthread在使用某些高级的编译器(例如 g++ 版本 5 及更高版本)时,如果使用了 -std=c++11 或者更高版本的选项,编译器可能会自动链接 pthread 库,因此即使没有明确指定 -lpthread,编译也能成功。
5.2 在 Windows 系统上,使用 std::thread 时不需要链接 pthread,因为 Windows 有自己实现的线程库,std::thread 使用的是 Windows API。
=》总之,std::thread 是跨平台的,在不同的平台,其实是调用了各自封装的API函数!
篇一、
std::thread 是 C++11 标准库中的一个类,用于支持多线程编程。它提供了一些成员函数来管理线程的生命周期和与线程进行交互。
std::thread 的一些主要成员函数:
joinable(): 检查线程是否可以被 join。
get_id(): 获取线程的 ID。
native_handle(): 获取与实现相关的本机句柄。
hardware_concurrency(): 返回实现的并发级别(硬件支持的最大并发线程数)。
join(): 阻塞调用线程,直到被调用线程完成。
detach(): 将线程与调用对象分离,允许线程在后台继续运行。
swap(): 交换两个 std::thread 对象的状态。展示一个例子
首先输出了硬件支持的最大并发线程数。然后创建了四个线程,并展示了如何获取它们的 ID、检查它们是否可以被 join、获取它们的 native handle 以及交换线程。最后,我们等待前两个线程结束并把后两个线程设置为脱离状态。
#include <iostream>
#include <thread>
#include <chrono>// 定义一个简单的函数,线程将执行该函数
void my_function(int id) {std::this_thread::sleep_for(std::chrono::seconds(2)); // 模拟耗时操作std::cout << "Thread " << id << " finished execution." << std::endl;
}int main() {// 获取硬件支持的最大并发线程数std::size_t max_threads = std::thread::hardware_concurrency();std::cout << "Maximum number of concurrent threads supported by hardware: "<< max_threads << std::endl;// 创建多个线程std::thread t1(my_function, 1);std::thread t2(my_function, 2);// 输出线程的 IDstd::cout << "Thread 1 ID: " << t1.get_id() << std::endl;std::cout << "Thread 2 ID: " << t2.get_id() << std::endl;// 检查线程是否可 joinif (t1.joinable()) {std::cout << "Thread 1 is joinable." << std::endl;} else {std::cout << "Thread 1 is not joinable." << std::endl;}// 输出底层线程句柄(具体实现依赖于平台)void* handle1 = t1.native_handle();void* handle2 = t2.native_handle();std::cout << "Native handle for thread 1: " << handle1 << std::endl;std::cout << "Native handle for thread 2: " << handle2 << std::endl;// 交换线程std::thread t3(my_function, 3);std::thread t4(my_function, 4);t3.swap(t4);std::cout << "Swapped thread 3 and 4." << std::endl;// 输出交换后的线程 IDstd::cout << "Thread 3 ID after swap: " << t3.get_id() << std::endl;std::cout << "Thread 4 ID after swap: " << t4.get_id() << std::endl;// 等待线程 t1 和 t2 结束std::cout << "Waiting for threads 1 and 2 to finish..." << std::endl;t1.join();t2.join();// 设置线程 t3 和 t4 为脱离状态std::cout << "Detaching threads 3 and 4..." << std::endl;t3.detach();t4.detach();std::cout << "Main function completed." << std::endl;return 0;
}输出
Maximum number of concurrent threads supported by hardware: 20
Thread 1 ID: 16628
Thread 2 ID: 9456
Thread 1 is joinable.
Native handle for thread 1: 00000000000000C4
Native handle for thread 2: 00000000000000C8
Swapped thread 3 and 4.
Thread 3 ID after swap: 10992
Thread 4 ID after swap: 22592
Waiting for threads 1 and 2 to finish...
Thread 1 finished execution.Thread 4Thread 2 finished execution.
Thread 3 finished execution. finished execution.Detaching threads 3 and 4...
Main function completed.
join() 说明
join() 方法用于等待线程完成其任务。当调用 join() 方法时,调用线程(通常是主线程)会被阻塞,直到被 join 的线程完成为止。
关于何时线程不可 join,有以下几种情况:
线程尚未启动:
如果线程对象尚未被启动,那么它是不可 join 的。例如,如果创建了一个 std::thread 对象但没有传递任何函数给它,或者还没有调用 start() 方法(注意:std::thread 没有 start() 方法,线程是在构造时立即启动的)。
线程已经结束:
如果线程已经完成了它的任务,并且线程对象已经被 join 或者 detach,那么它是不可 join 的。这是因为线程资源已经被释放。
线程已经被 detach:
如果线程被 detach() 方法分离,那么它将不会被 join。这意味着线程将在完成后自动清理资源,而不需要调用 join() 方法。一旦线程被 detach,它就不再与 std::thread 对象关联,因此也不可再 join。
线程对象已经销毁:
如果 std::thread 对象已经超出作用域并被销毁,那么它是不可 join 的。在这种情况下,线程会被自动 join 或 detach,具体取决于线程的状态。
输出
Thread 1 ID: 23612
Thread 2 ID: 2940
Thread 1 is joinable.
Waiting for threads 1 and 2 to finish...
Thread 2 finished execution.
Thread 1 finished execution.
Threads 1 and 2 have been joined.
Thread 3 is not joinable.
Thread 4 is not joinable.detach()说明
调用 detach 函数之后:1. *this 不再代表任何的线程执行实例。2. joinable() == false3. get_id() == std::thread::id()detach() 方法用于将线程设置为脱离状态。脱离状态的线程会在完成后自动清理资源,不需要其他线程调用 join() 方法。这在以下场景中是有用的:
后台任务:如果有一些后台任务,如日志记录、数据同步等,这些任务可以在主线程退出后继续运行,这时可以使用 detach() 方法。
非阻塞操作:如果希望主线程不等待子线程完成,而是继续执行其他任务,可以使用 detach()。
线程池:在实现线程池时,通常会将线程设置为脱离状态,以便线程可以自动回收资源。
动态调整线程分配
如何使用 std::thread::swap 方法来动态地重新分配任务到线程。swap 方法确保了线程对象的状态被正确交换,而不需要重新创建或销毁线程
初始化线程池:首先创建了一个包含 numThreads 个线程的向量,并为每个线程分配一个任务。
动态调整线程分配:循环遍历线程池中的每个线程,对于每个线程,等待它完成当前任务后,如果还有新的任务要执行,就创建一个新的线程对象,并使用 swap 方法将新任务移到原来的线程对象上。
确保所有线程完成任务:在完成所有任务调整后,再次循环遍历线程池,确保所有线程都已完成它们的任务。
输出所有任务完成的消息:最后输出一条消息,表示所有任务都已经完成。
#include <iostream>
#include <thread>
#include <vector>
#include <chrono>
#include <mutex>std::mutex mtx; // 用于输出的互斥量void taskFunction(int taskID) {std::this_thread::sleep_for(std::chrono::seconds(1));std::lock_guard<std::mutex> lock(mtx);std::cout << "Task " << taskID << " is complete." << std::endl;
}int main() {const int numThreads = 4;std::vector<std::thread> threadPool(numThreads);// 启动初始任务for (int i = 0; i < numThreads; ++i) {threadPool[i] = std::thread(taskFunction, i + 1);}// 动态调整线程分配for (int i = 0; i < numThreads; ++i) {if (threadPool[i].joinable()) {// 等待当前线程完成任务threadPool[i].join();// 如果还有新的任务,将任务移动到该线程上if (i + numThreads < 2 * numThreads) {std::thread newThread(taskFunction, i + numThreads + 1);// 确保新线程已经启动newThread.swap(threadPool[i]);}}}// 确保所有线程完成任务for (int i = 0; i < numThreads; ++i) {if (threadPool[i].joinable()) {threadPool[i].join();}}std::cout << "All tasks are complete." << std::endl;return 0;
}
输出
Task 1 is complete.
Task 2 is complete.
Task 3 is complete.
Task 4 is complete.
Task 7 is complete.
Task 8 is complete.
Task 6 is complete.
Task 5 is complete.
All tasks are complete.————————————————
原文链接:https://blog.csdn.net/flyfish1986/article/details/140792370
篇二、
C++11 的线程管理
C++11 引入了全面的多线程支持,使并发编程成为语言标准的一部分。核心组件包括线程管理(std::thread)、原子操作(std::atomic)和同步机制(互斥锁、条件变量)。
线程管理类 std::thread,用于创建和管理操作系统线程。它提供了跨平台的线程操作接口,消除了对平台特定 API(如 POSIX pthreads 或 Windows Threads)的依赖。
线程创建
我们可以通过传递可调用对象来构造 std::thread 线程实例,比如函数、Lambda、函数对象:
#include <thread>// 函数形式
void print(int num, const std::string& str) {std::cout << num << " " << str << "\n";
}// Lambda 形式
auto lambda = [](float f) { /*...*/ };int main() {// 创建线程并立即执行std::thread t1(print, 42, "Hello"); // 值传递std::string msg = "World";std::thread t2([&msg]() { // 引用捕获std::cout << msg << "\n";});t1.join();t2.join();
}
当我们构造 std::thread 实例时,可以使用以下几种数据传递机制:
- 默认行为:参数按值拷贝
- 传递引用:需使用
std::ref包装 - 移动语义:使用
std::move避免拷贝
void process_data(const BigData& data); // 大对象BigData data;
std::thread t1(process_data, data); // 拷贝data(可能昂贵)
std::thread t2(process_data, std::ref(data)); // 传递引用
std::thread t3(process_data, std::move(data)); // 移动语义
另外,我们需要注意的线程异常隔离问题,因为线程内异常不会传播到主线程,所以我们必须在每个线程内部处理异常:
std::thread t([] {try {// 可能抛出异常的代码} catch (...) {// 处理所有异常}
});
线程生命周期的管理
我们可以通过以下操作对线程的生命周期进行管理:
- 等待线程完成(join)
- 分离线程(detach)
- RAII 包装器(推荐模式)
在 std::thread 的生命周期管理中,"可连接"(joinable)和 "不可连接"(non-joinable)是核心概念,直接关系到线程的安全管理和资源回收。
1. 状态定义
- 可连接状态 表示线程对象关联着一个活跃的或已结束但未清理的执行线程。可连接状态的条件有:
1)通过构造函数创建了新线程
2)尚未调用join()或detach() - 不可连接状态 表示线程对象不再关联任何执行线程。不可连接状态的条件有:
1)已调用join()
2)已调用detach()
3)被移动(所有权转移)
4)默认构造(无关联线程)
2. 状态转换
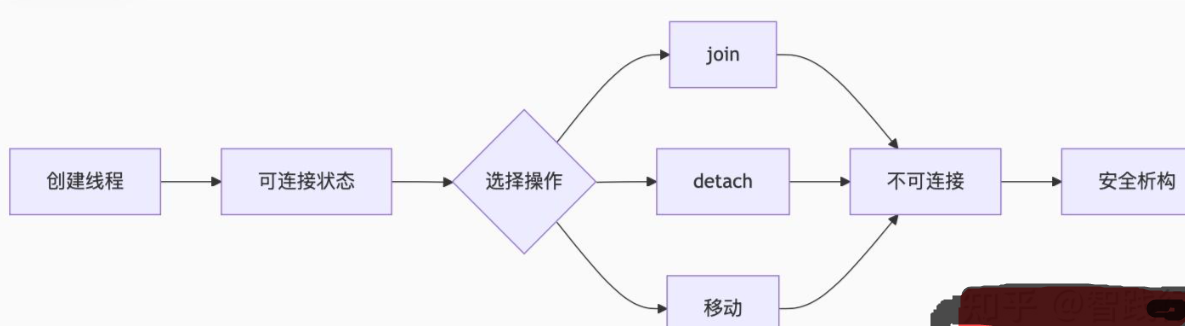
a. 进入可连接状态
// 创建线程对象 → 可连接状态
std::thread t([]{ /* 执行任务 */ }); // ✅ joinable() == true
b. 转为不可连接状态
// 方式1: 调用 join()
t.join(); // ❗ joinable() == false// 方式2: 调用 detach()
t.detach(); // ❗ joinable() == false// 方式3: 移动所有权
std::thread t2 = std::move(t); // t变为不可连接,t2变为可连接
3. 使用规则与后果
1)析构时必须不可连接
{std::thread t([]{ /*...*/ }); // 可连接状态// 未调用 join/detach → 析构时终止程序!
} // ❌ 此处调用 std::terminate() 终止程序!
2)禁止重复操作
std::thread t([]{ /*...*/ });t.join(); // ✅ 转为不可连接t.join(); // ❌ 抛出 std::system_error
// 错误信息:"Invalid argument"
3)移动后的状态
std::thread t1([]{ /*...*/ }); // t1 可连接
std::thread t2 = std::move(t1); // t1 不可连接,t2 可连接t1.joinable(); // false
t2.joinable(); // true
4. 状态检测:joinable()
joinable()主要用于安全判断当前状态,避免重复操作:
std::thread t;if (t.joinable()) { // 检查状态// 安全操作区域t.join(); // 或 t.detach()
}
典型使用场景:
void safe_thread_management() {std::thread t([]{ /*...*/ });try {// 可能抛出异常的代码} catch (...) {if (t.joinable()) t.join(); // 异常时安全清理throw;}// 正常流程if (t.joinable()) t.join();
}
5. 那么为什么需要这种设计?
首要原因是为了资源安全,操作系统线程是重要资源(通常占用 1-10 MB 内存),所以必须明确决定线程结束后的处理方式。
第二个原因是为了避免僵尸线程,join() 是为了确保线程资源被回收,而detach() 是为了明确的放弃所有权。
第三个原因是为了防止未定义行为,比如,未同步的线程访问已销毁的局部变量;再比如,未回收线程导致资源泄漏。
6. 正确用法示例
理解并正确管理线程的可连接状态,是避免多线程程序崩溃和资源泄漏的基础,也是编写健壮并发代码的关键所在。
下面列出几个正确使用的线程周期管理的场景:
场景1:等待线程完成(join)
void process_data() {std::vector<int> results;std::thread worker([&]{ results = calculate(); // 耗时计算});// 必须等待结果完成worker.join(); // 阻塞直到计算完成use_results(results); // 安全使用结果
}
场景2:分离后台线程(detach)
void start_background_task() {std::thread([]{while (true) {// 周期性后台任务std::this_thread::sleep_for(1h);cleanup();}}).detach(); // ✅ 立即分离
}
场景3:RAII 自动管理
RAII(Resource Acquisition Is Initialization) 是 C++ 的核心设计理念,中文译为"资源获取即初始化"。这是一种利用对象生命周期来管理资源(内存、文件句柄、网络连接、线程等)的技术,确保资源在任何执行路径下都能被正确释放。
class ThreadRAII {std::thread t;enum class Action { Join, Detach };Action action;
public:ThreadRAII(std::thread&& t, Action a) : t(std::move(t)), action(a) {}~ThreadRAII() {if (t.joinable()) {if (action == Action::Join) t.join();else t.detach();}}// ... 禁止拷贝 ...
};// 使用示例
{ThreadRAII tr(std::thread([]{ /* 关键任务 */ }),ThreadRAII::Action::Join // 退出作用域自动join);// 即使此处抛出异常,线程也会被正确清理
}
总结
| 特性 | 说明 |
|---|---|
| 构造即启动 | 线程在创建时立即开始执行 |
| 移动语义 | 线程所有权可转移,不可复制 |
| join/detach | 必须在线程析构前调用,否则程序终止 |
| 参数传递 | 默认值传递,引用需用std::ref,大对象用std::move |
| 异常隔离 | 线程内异常不会传播到主线程 |
| RAII模式 | 推荐使用包装类管理线程生命周期 |
正确使用std::thread需要注意:
- 始终管理线程生命周期(join/detach)
- 谨慎处理共享数据(使用同步原语)
- 避免线程间悬垂引用
- 考虑性能影响和线程创建开销
- 优先使用高级抽象(如
std::async)简化代码
篇三、std::this_thread
| 功能 | 含义 |
|---|---|
| get_id | 获取线程 ID(函数) |
| yield | 让出CPU |
| sleep_until | 睡眠到时间点(功能) |
| sleep_for | 睡眠时间跨度(功能) |