卷积神经网路--训练可视化
一、tensorboard
1.1简单介绍
TensorBoard 是一个强大的可视化工具,专为深度学习设计,用于监控和理解训练过程。
1.2运用步骤
(1)安装依赖
pip install tensorboard(2)导入模块并创建实例化对象
导入模块
from torch.utils.tensorboard import SummaryWriter实例化对象
writer = SummaryWriter(path) 也可以不填,不填就是默认路径runs(3)记录训练指标
在训练过程中记录
writer.add_scalar('loss/train',loss,epoch)
writer.add_saclar('accuracy/train',accuracy,epoch)也可以记录权重参数信息
for name,param in model.named_parameters():writer.add_histogram(name,param,epoch)训练结束后,关闭记录器
writer.close()(4)记录图像或模型结构
记录图像
writer.add_image('Images',img_tensor,global_step=0) 最后一个参数就是权重记录模型结构
writer.add_graph(model,input_tensor)(5)启动tensorboard服务器
tensorboard --logdir=runs如果用了 之后仍然没反应,就把runs改为绝对路径地址。
1.3保存网络结构
# 保存模型结构到tensorboard
writer.add_graph(net, input_to_model=torch.randn(1, 1, 28, 28))
writer.close()
1.4模型参数可视化
for name,param in model.named_parameters():
writer.add_histogram(name,param,epoch)
1.5记录训练数据
for i, data in enumerate(trainloader, 0):
inputs, labels = data
if i % 100 == 0:
img_grid = torchvision.utils.make_grid(inputs)
writer.add_image(f"r_m_{epoch}_{i * 100}", img_grid, epoch * len(trainloader) + i)
二、数据集训练可视化
对数据集进行可视化分析:包括记录标量值、模型参数、图像、模型结构
代码:
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as transforms
from torchvision.datasets import ImageFolder
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import os
from datetime import datetime# 数据预处理
transforms_train = transforms.Compose([transforms.Resize((32, 32)),transforms.RandomHorizontalFlip(),transforms.RandomVerticalFlip(),transforms.RandomRotation(10),transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),transforms.ToTensor()
])# 数据集路径
train_path = os.path.relpath(os.path.join(os.path.dirname(__file__), './dataset/train'))
train_dataset = ImageFolder(root=train_path, transform=transforms_train)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True, drop_last=True)# 定义模型
class MyNet(nn.Module):def __init__(self):super(MyNet, self).__init__()self.c1 = nn.Sequential(nn.Conv2d(in_channels=3, out_channels=6, kernel_size=5),nn.ReLU())self.s2 = nn.AdaptiveAvgPool2d(14)self.c3 = nn.Sequential(nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5),nn.ReLU())self.s4 = nn.AdaptiveAvgPool2d(5)self.l5 = nn.Sequential(nn.Linear(16 * 5 * 5, 120),nn.ReLU())self.l6 = nn.Sequential(nn.Linear(120, 84),nn.ReLU())self.l7 = nn.Linear(84, 3)def forward(self, x):x = self.c1(x)x = self.s2(x)x = self.c3(x)x = self.s4(x)x = x.view(x.size(0), -1)x = self.l5(x)x = self.l6(x)out = self.l7(x)return out# 设置设备和模型
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = MyNet()
model.to(device)# 训练参数
epochs = 20
lr = 0.001
criterion = nn.CrossEntropyLoss()
opt = optim.Adam(model.parameters(), lr=lr)
writer = SummaryWriter()# 模型保存路径
model_path = os.path.relpath(os.path.join(os.path.dirname(__file__), 'model.pth'))# 训练函数
def train():for epoch in range(epochs):model.train()loss_total = 0accuracy_total = 0for i, (data, label) in enumerate(train_loader):data = data.to(device)label = label.to(device)# 前向传播out = model(data)loss = criterion(out, label)# 反向传播opt.zero_grad()loss.backward()opt.step()# 统计损失和准确率loss_total += loss.item()_, predicted = torch.max(out, 1)accuracy_total += (predicted == label).sum().item()# 打印训练信息avg_loss = loss_total / len(train_loader)avg_accuracy = accuracy_total / len(train_dataset)print(f'Epoch {epoch+1}/{epochs}, Loss: {avg_loss:.4f}, Accuracy: {avg_accuracy:.4f}')# 保存模型torch.save(model.state_dict(), model_path)# 记录到TensorBoardwriter.add_scaler('loss/train', avg_loss, epoch, walltime=datetime.now().timestamp())writer.add_scaler('accuracy/train', avg_accuracy, epoch)# 记录模型参数for name, param in model.named_parameters():writer.add_histogram(name, param.clone().cpu().data.numpy(), epoch)# 记录模型结构(只在第一个epoch记录)if epoch == 0:writer.add_graph(model, data)# 记录训练图像if epoch % 5 == 0:writer.add_images('train_images', data.cpu(), epoch)writer.close()print('训练结束')# 执行训练
if __name__ == '__main__':train()结果:
标量值:
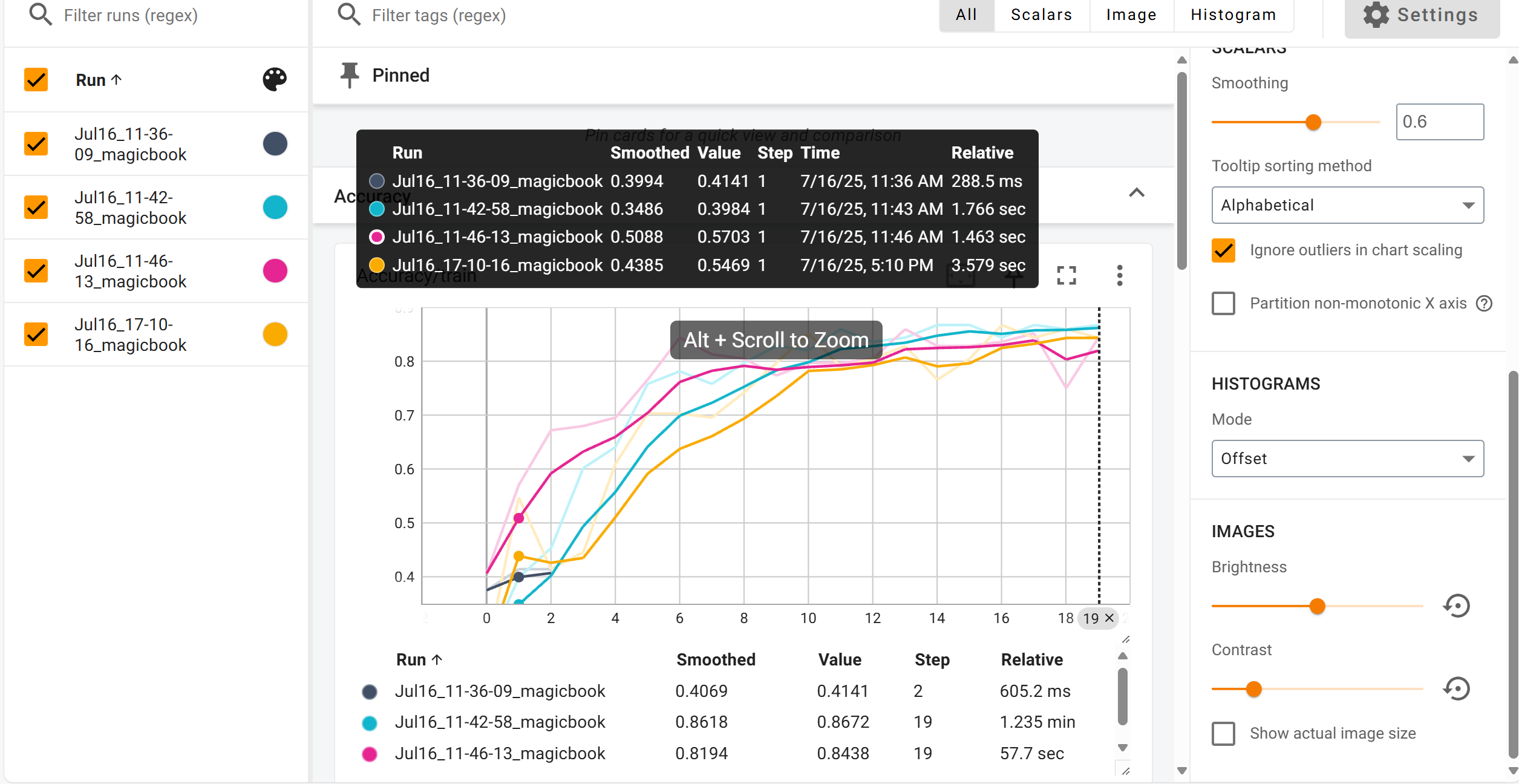
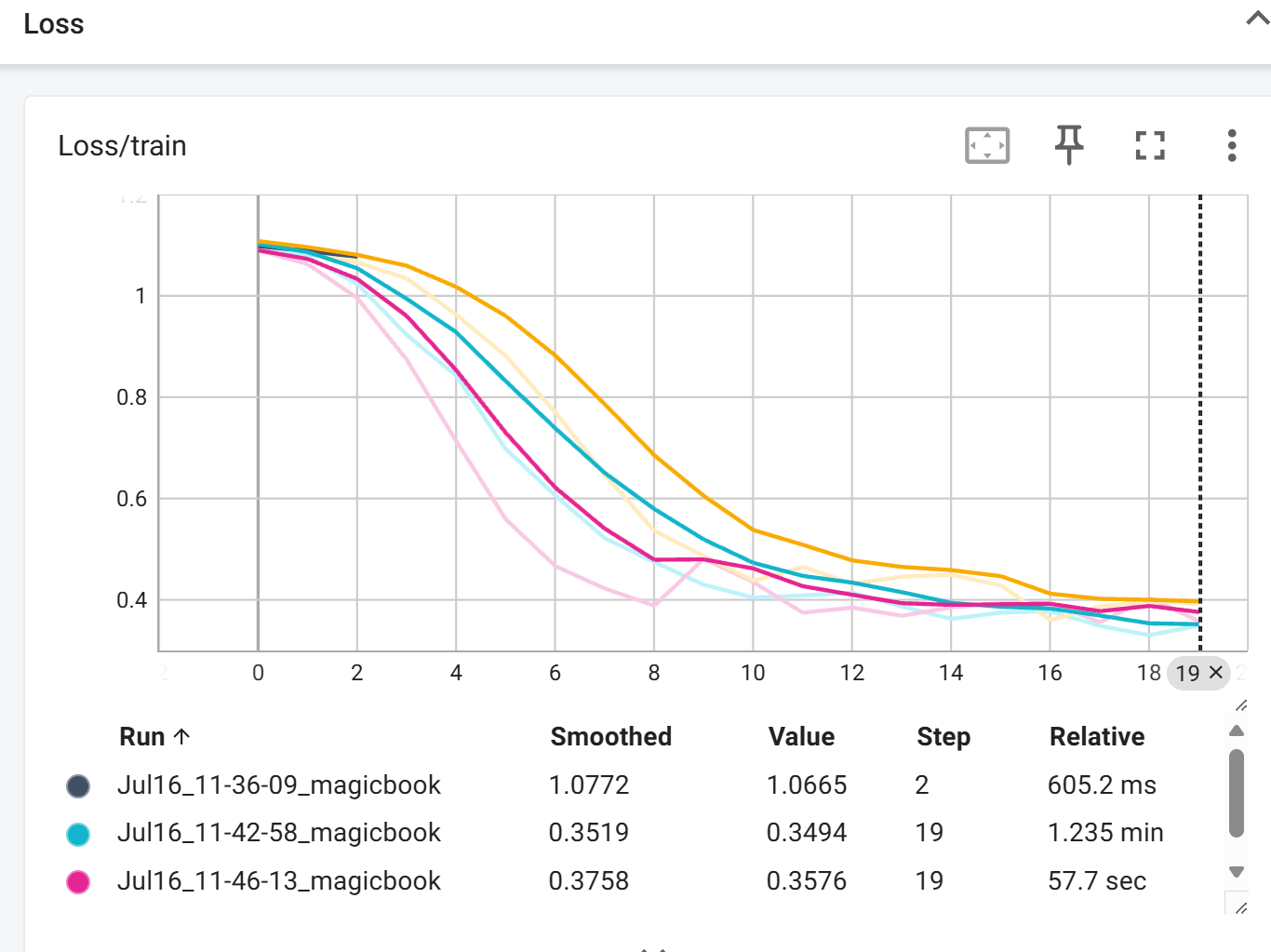 模型参数:
模型参数: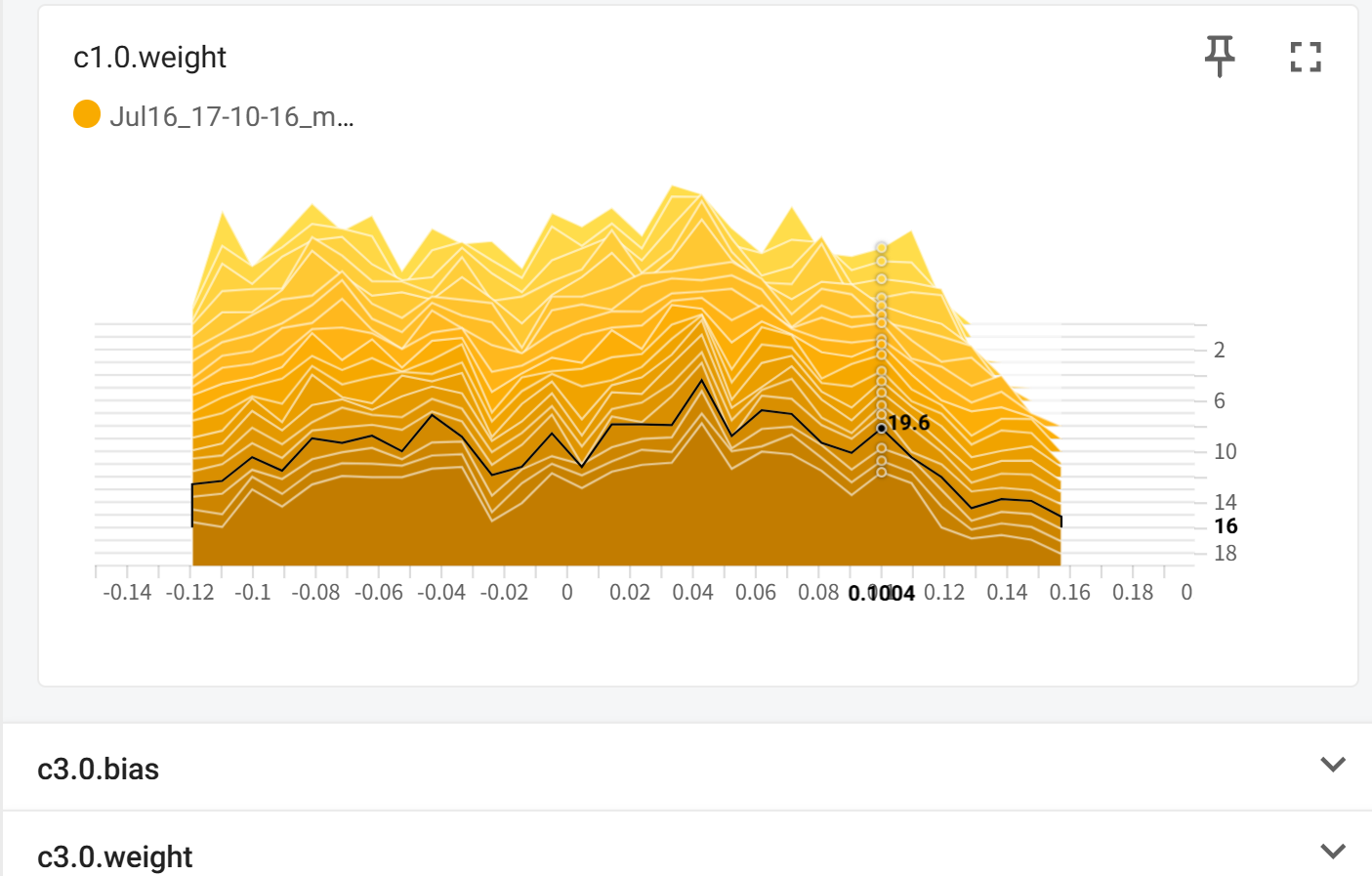
图像:

三、验证结果数据化
验证不需要打乱数据集,不需要下载数据集,也不需要进行梯度计算。
3.1数据转换csv
利用训练集的模型来验证测试集的结果,将训练过程的概率数据与训练的结果及原本的标签结果转换到一个Excel表中,这样有利于我们分析和查看模型情况。
主要步骤:
(1)导入相关库;
(2)加载验证数据;
(3)定义网络模型;
(4)加载训练好的模型;
(5)开始验证;
(6)利用pandas进行拼接;
(7)查看结果。
代码:
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from torchvision.datasets import MNIST
from torchvision import transforms
import os
import pandas as pd
import numpy as np
from torchvision import datasets# 数据集的地址
data_dir = os.path.relpath(os.path.join(os.path.dirname(__file__), 'Flower.v1i.folder/valid'))
# 模型保存的地址
model_dir = os.path.relpath(os.path.join(os.path.dirname(__file__), 'model', 'last.pth'))
tfs = transforms.Compose([transforms.ToTensor(),transforms.Resize(32),
])val_dataset = datasets.ImageFolder(root=data_dir,transform=tfs
)classNames = val_dataset.classesclass FlowerModel(nn.Module):def __init__(self):super(FlowerModel, self).__init__()self.c1 = nn.Sequential(nn.Conv2d(in_channels=3,out_channels=6,kernel_size=5,stride=1,),nn.ReLU(),)self.s2 = nn.AdaptiveAvgPool2d(14)self.c3 = nn.Sequential(nn.Conv2d(in_channels=6,out_channels=16,kernel_size=5,stride=1,),nn.ReLU(),)self.s4 = nn.AdaptiveAvgPool2d(5)self.l5 = nn.Sequential(nn.Linear(16*5*5,120),nn.ReLU(),)self.l6 = nn.Sequential(nn.Linear(120,84),nn.ReLU(),)self.l7 = nn.Linear(84,3)def forward(self, x):x = self.c1(x)x = self.s2(x)x = self.c3(x)x = self.s4(x)x = x.view(x.size(0), -1)x = self.l5(x)x = self.l6(x)out = self.l7(x)return out# 设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")model = FlowerModel()
model.to(device)
# 加载预训练好的权重参数
model.load_state_dict(torch.load(model_dir))model.eval()
acc_total = 0
val_dataloader = DataLoader(val_dataset, batch_size=32, shuffle=False)
total_data = np.empty((0,5)) #这是一个重要修改点
with torch.no_grad():# 每个批次for x, y in val_dataloader:x = x.to(device)y = y.to(device)out = model(x)pred = torch.detach(out).cpu().numpy()p1 = torch.argmax(out, dim=1) #获取最大值索引# 转化为numpyp2 = p1.unsqueeze(dim=1).detach().cpu().numpy() #将索引升维转成numpylabel = y.unsqueeze(dim=1).detach().cpu().numpy()batch_data = np.concatenate([pred, p2, label],axis=1) # 按列拼接,将pred,p2,label合并成一行total_data = np.concatenate([total_data, batch_data], axis=0) # 按行拼接,将每行数据合并# 构建csv文件的第一行(列名)
pd_columns = [*classNames, 'pred', 'label']csv_path = os.path.relpath(os.path.join(os.path.dirname(__file__), 'results', 'flower.csv'))pd.DataFrame(total_data, columns=pd_columns).to_csv(csv_path, index=False)
print(f"结果已保存到: {csv_path}") 结果:

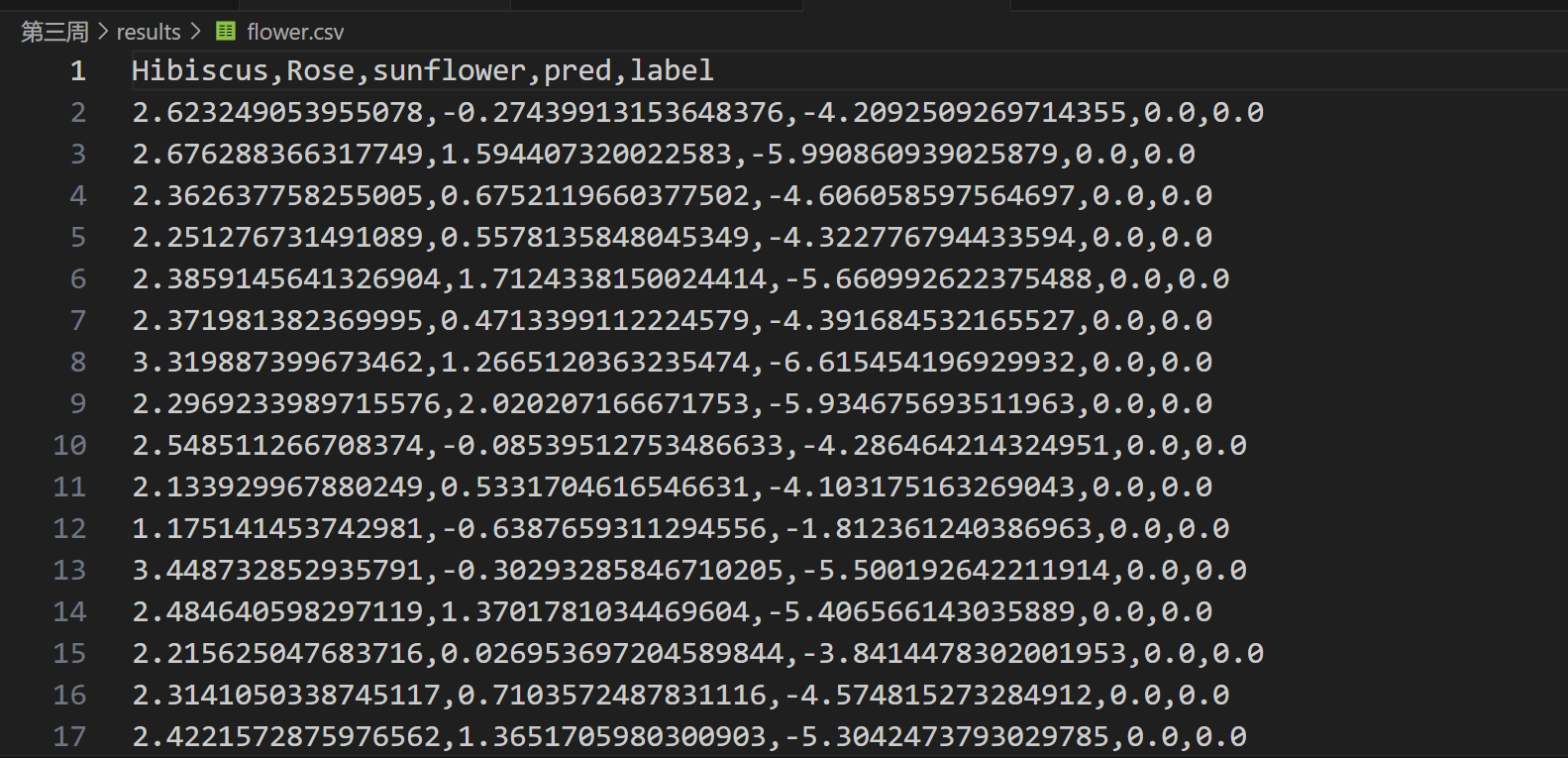
3.2模型的评判
3.2.1混淆矩阵
3.2.2准确度
3.2.3精确率
3.2.4召回率
3.2.5F1-socre
四、验证结果可视化(混淆矩阵)
五、继续训练
如果我们每一次训练发现训练结果不好,都从头开始训练的话会消耗很多时间和资源。因此继续训练在此就很有必要,它的操作方法也很简单。
只需要在之前保存的模型基础之上再次加载模型然后进行训练皆可以完成该操作。
代码使用:
model.load_state_dict(torch.load(model_path))完整代码:
#简单版本的继续训练,节省时间import torch
from torch import nn
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import torch.optim as optim
import os
from torch.utils.tensorboard import SummaryWriter# 定义训练数据的预处理步骤
transform_train = transforms.Compose([# transforms.Resize((32, 32)), # 确保所有图像调整为32x32# transforms.RandomHorizontalFlip(), # 随机水平翻转# transforms.RandomVerticalFlip(), # 随机垂直翻转# transforms.RandomRotation(10), # 随机旋转10度# transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1), # 色彩抖动transforms.ToTensor(), # 转换为张量
])# 数据集路径
DATA_PATH = os.path.relpath(os.path.join(os.path.dirname(__file__),'Flower.v1i.folder/train'))# 加载训练集
train_dataset = datasets.ImageFolder(root=DATA_PATH,transform=transform_train
)# 获取类别名称
# class_names = train_dataset.classes
# print(f"检测到 {len(class_names)} 个类别: {class_names}")# 创建数据加载器 (使用合理的batch_size)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True, drop_last=True)class MyNet(nn.Module):def __init__(self, num_classes):super(MyNet, self).__init__()# 修正输入通道为3 (RGB图像)self.c1 = nn.Sequential(nn.Conv2d(in_channels=3, out_channels=6, kernel_size=5), # 修正: 输入通道改为3nn.ReLU())self.s2 = nn.AdaptiveAvgPool2d(14)self.c3 = nn.Sequential(nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5),nn.ReLU())self.s4 = nn.AdaptiveAvgPool2d(5)self.l5 = nn.Sequential(nn.Linear(16*5*5, 120),nn.ReLU())self.l6 = nn.Sequential(nn.Linear(120, 84),nn.ReLU())# 输出层类别数改为实际类别数self.l7 = nn.Linear(84, num_classes) # 修正: 使用实际类别数def forward(self, x):x = self.c1(x)x = self.s2(x)x = self.c3(x)x = self.s4(x)x = x.view(x.size(0), -1) # 展平x = self.l5(x)x = self.l6(x)out = self.l7(x)return out# 设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 创建模型实例 (传入实际类别数)
model = MyNet(num_classes=3)
model.to(device)
# 训练参数
epochs = 20
lr = 0.001
opt = optim.Adam(model.parameters(), lr=lr)
# 损失函数 (使用mean更稳定)
criterion = nn.CrossEntropyLoss() # 修正: 使用默认mean reduction# 确保模型目录存在
model_dir = os.path.relpath(os.path.join(os.path.dirname(__file__), 'model'))
os.makedirs(model_dir, exist_ok=True)
model_path = os.path.join(model_dir, 'last.pth')model.load_state_dict(torch.load(model_path)) # 加载模型权重
# TensorBoard写入器
writer = SummaryWriter() # 默认log_dir='runs'# 训练循环
for epoch in range(epochs):model.train() # 设置为训练模式running_loss = 0.0correct = 0total = 0for i, (x, y) in enumerate(train_loader): # 使用train_loaderx = x.to(device)y = y.to(device)# 前向传播outputs = model(x)loss = criterion(outputs, y)# 反向传播和优化opt.zero_grad()loss.backward()opt.step()# 统计信息running_loss += loss.item() * x.size(0)_, predicted = torch.max(outputs.data, 1)total += y.size(0)correct += (predicted == y).sum().item()# 计算epoch指标epoch_loss = running_loss / totalepoch_acc = correct / total# 保存模型torch.save(model.state_dict(), model_path)print(f"Epoch [{epoch+1}/{epochs}], "f"Loss: {epoch_loss:.4f}, Accuracy: {epoch_acc:.4f}")# # 记录到TensorBoard
# writer.add_scalar("Loss/train", epoch_loss, epoch)
# writer.add_scalar("Accuracy/train", epoch_acc, epoch)
# # 记录模型参数的直方图
# for name, param in model.named_parameters():
# writer.add_histogram(name, param.clone().cpu().data.numpy(), epoch)# #保存网络结构
# writer.add_graph(model,x)# #保存训练图片
# for i, (x, _) in enumerate(train_loader):
# if i % 50 == 0:
# writer.add_images("train_images", x, epoch)# writer.close()
print("训练完成!")
结果:
第一次训练的结果大致为:
开头:
本次训练并没有像刚开始一样从20多开始,而是直接从80开始,这样说明我们想要的操作已经成功了。
Epoch [1/20], Loss: 0.4504, Accuracy: 0.8047
Epoch [2/20], Loss: 0.4164, Accuracy: 0.8438
Epoch [3/20], Loss: 0.4267, Accuracy: 0.8047
Epoch [4/20], Loss: 0.3386, Accuracy: 0.8672
Epoch [5/20], Loss: 0.3653, Accuracy: 0.8359
Epoch [6/20], Loss: 0.3431, Accuracy: 0.8750
Epoch [7/20], Loss: 0.3285, Accuracy: 0.8906
Epoch [8/20], Loss: 0.3243, Accuracy: 0.8906
Epoch [9/20], Loss: 0.3266, Accuracy: 0.8828
Epoch [10/20], Loss: 0.3189, Accuracy: 0.8906
Epoch [11/20], Loss: 0.3131, Accuracy: 0.8828
Epoch [12/20], Loss: 0.3147, Accuracy: 0.8828
Epoch [13/20], Loss: 0.3072, Accuracy: 0.8828
Epoch [14/20], Loss: 0.3091, Accuracy: 0.8906
Epoch [15/20], Loss: 0.3109, Accuracy: 0.8828
Epoch [16/20], Loss: 0.2734, Accuracy: 0.9141
Epoch [17/20], Loss: 0.2905, Accuracy: 0.8984
Epoch [18/20], Loss: 0.3060, Accuracy: 0.8750
Epoch [19/20], Loss: 0.3245, Accuracy: 0.8672
Epoch [20/20], Loss: 0.3065, Accuracy: 0.8984
训练完成!