手搓transformer
思路是这样子的:从手搓代码的角度去学习transformer,代码会一个一个模块地从头到尾添加,以便学习者跟着敲,到最后再手搓一个基于tansformer的机器翻译实战项目。
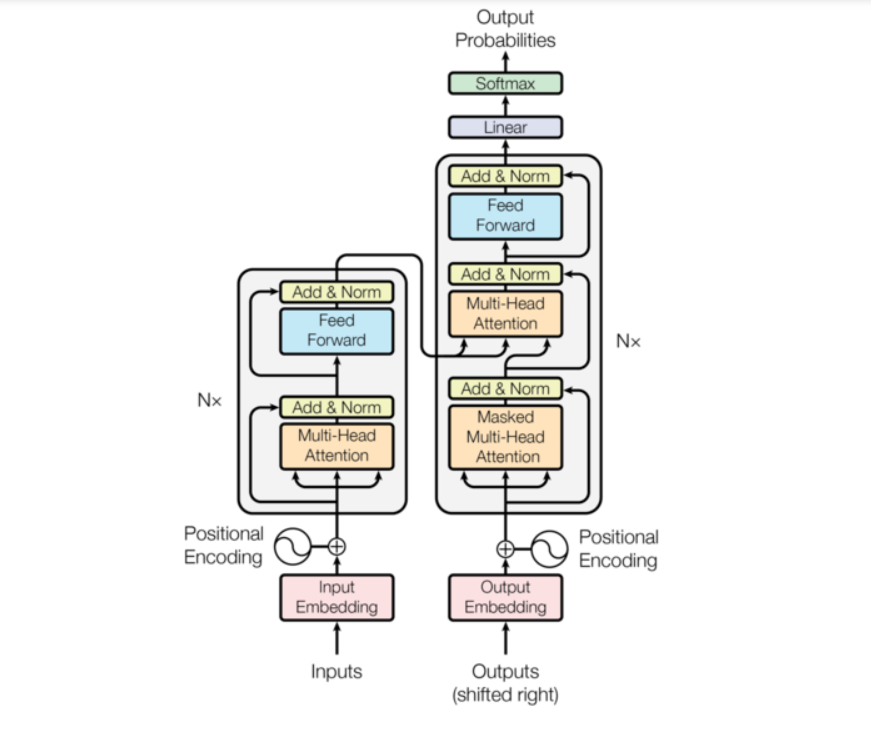
transformer整体架构
一、输入部分
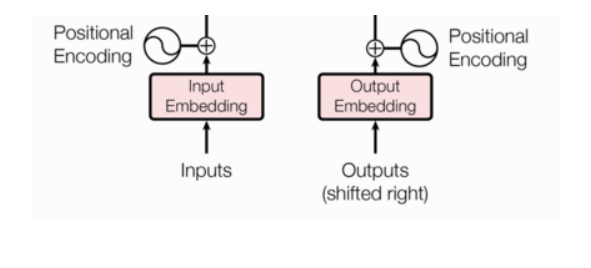
词向量
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
import math
import matplotlib.pyplot as plt
import numpy as np
import copyembedding = nn.Embedding(10, 3)
input = torch.LongTensor([[1, 2, 3, 4], [5, 6, 7, 8]])
print(embedding(input))"""
tensor([[[ 1.1585, -0.2142, 0.2379], #1[-0.0137, 0.4797, -1.0865], #2[ 0.7403, -1.1992, -0.0105], #3[-1.7339, -0.1899, -0.7764]], #4[[ 1.0883, -0.4474, -0.4151], #5[-0.8517, -0.2821, 1.3511], #6[-0.9131, -0.0999, -0.1846], #7[-3.0283, 2.6045, -1.3109]]], #8grad_fn=<EmbeddingBackward0>)
"""embedding = nn.Embedding(10, 3,padding_idx=0)
input = torch.LongTensor([[1, 2, 3, 4], [5, 6, 7, 8]])
print(embedding(input))
"""
tensor([[[-0.4958, -1.1462, 0.2109],[ 1.1422, -0.4182, 0.2201],[-0.7329, 1.1556, -0.0757],[ 1.3903, 0.3619, 0.5569]],[[ 0.0434, 2.1415, 0.2626],[ 0.3113, -0.2618, -1.6705],[ 0.8060, 0.1640, 1.4943],[-0.5313, 0.7362, 0.9071]]], grad_fn=<EmbeddingBackward0>)
"""⭐ 1.词嵌入层
变成高纬度的词向量,以便保存更多的词
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
import math
import matplotlib.pyplot as plt
import numpy as np
import copyclass Embeddings(nn.Module):def __init__(self, d_model, vocab):super(Embeddings, self).__init__()self.lut = nn.Embedding(vocab, d_model)self.d_model = d_modeldef forward(self, x):return self.lut(x) * math.sqrt(self.d_model)d_model=512
vocab=1000
x = Variable(torch.LongTensor([[100,2,421,508],[491,998,1,221]]))
emb = Embeddings(d_model, vocab)
embr = emb(x)
print("embr:", embr)
print("形状:", embr.shape)"""
embr: tensor([[[ 13.7968, -14.4595, 28.3401, ..., 1.9699, -16.2531, 0.4690],[ 20.9855, 10.0422, 0.5572, ..., 33.0242, 20.5869, 27.3373],[-25.8328, -20.8624, 15.1385, ..., -38.3399, -33.6920, -15.9326],[-19.9724, 17.2694, 22.7562, ..., -25.8548, -47.9648, 38.4995]],[[-49.9396, -43.8692, -24.5790, ..., 2.9931, -34.2201, 1.7027],[ -2.4900, 15.1773, -7.8220, ..., 19.9114, -24.9212, 11.0202],[ 21.6143, -0.7228, -11.8343, ..., -0.3574, -21.0696, 13.9079],[ 26.5733, 2.4455, -26.7212, ..., -38.3939, -1.6351, -32.0217]]],grad_fn=<MulBackward0>)
形状: torch.Size([2, 4, 512])
"""
nn.Dropout演示
torch.unsqueeze演示
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
import math
import matplotlib.pyplot as plt
import numpy as np
import copy# nn.Dropout演示
m = nn.Dropout(p=0.2)
input = torch.randn(4, 5)
output = m(input)
print(output)
"""
tensor([[ 0.5801, -0.8529, 0.2143, -0.5226, 0.0000],[ 0.2660, 0.8704, -1.8572, -0.0000, -2.0312],[-0.0000, -1.1344, -0.3601, -1.9231, -0.0159],[ 0.0000, 0.0000, 0.1374, -1.6314, -0.0000]])
"""# torch.unsqueeze演示
x = torch.tensor([1, 2, 3, 4])
print(torch.unsqueeze(x, 0))
print(torch.unsqueeze(x, 1))
"""
tensor([[1, 2, 3, 4]])
tensor([[1],[2],[3],[4]])
"""⭐ 2.位置编码器
词与词之间存在位置关系
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
import math
import matplotlib.pyplot as plt
import numpy as np
import copy# 1.文本嵌入层
class Embeddings(nn.Module):def __init__(self, d_model, vocab):super(Embeddings, self).__init__()self.lut = nn.Embedding(vocab, d_model)self.d_model = d_modeldef forward(self, x):return self.lut(x) * math.sqrt(self.d_model)# 2.位置编码器类
class PositionalEncoding(nn.Module):def __init__(self, d_model, dropout, max_len=5000):super(PositionalEncoding, self).__init__()self.dropout = nn.Dropout(p=dropout)pe = torch.zeros(max_len, d_model)position = torch.arange(0, max_len).unsqueeze(1)div_term = torch.exp(torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model))pe[:, 0::2] = torch.sin(position * div_term)pe[:, 1::2] = torch.cos(position * div_term)pe = pe.unsqueeze(0)self.register_buffer('pe', pe)def forward(self, x):x = x + Variable(self.pe[:, :x.size(1)], requires_grad=False)return self.dropout(x)d_model = 512
dropout = 0.1
max_len = 60vocab = 1000
x = Variable(torch.LongTensor([[100, 2, 421, 508], [491, 998, 1, 221]]))
emb = Embeddings(d_model, vocab)
embr = emb(x)x = embr
pe = PositionalEncoding(d_model, dropout, max_len)
pe_result = pe(x)
print("pe结果:", pe_result)
print(pe_result.shape)
"""
pe结果: tensor([[[ 26.0749, 1.7394, 18.1979, ..., 17.9599, 17.3468, 24.0999],[-26.7084, 29.3180, 41.9102, ..., -37.2804, -4.7909, 1.0968],[-41.5618, 1.7244, 2.7057, ..., -0.0000, 47.2770, -13.1729],[ 25.5094, 32.7570, 51.9276, ..., -12.3927, 5.0286, -28.2805]],[[ 16.1884, -7.0750, -18.7670, ..., -15.6387, 7.5007, 51.3489],[-32.2040, 36.8715, 11.7979, ..., -17.9770, 65.2743, 34.6677],[ 3.7295, -16.0210, -24.0060, ..., 25.5953, 13.9014, -0.0000],[-11.5124, -16.6056, -17.1153, ..., -21.1416, -28.6649, -24.2164]]],grad_fn=<MulBackward0>)
torch.Size([2, 4, 512])
"""
绘制词汇向量中特征的分布曲线
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
import math
import matplotlib.pyplot as plt
import numpy as np
import copy# 1.文本嵌入层
class Embeddings(nn.Module):def __init__(self, d_model, vocab):super(Embeddings, self).__init__()self.lut = nn.Embedding(vocab, d_model)self.d_model = d_modeldef forward(self, x):return self.lut(x) * math.sqrt(self.d_model)# 2.位置编码器类
class PositionalEncoding(nn.Module):def __init__(self, d_model, dropout, max_len=5000):super(PositionalEncoding, self).__init__()self.dropout = nn.Dropout(p=dropout)pe = torch.zeros(max_len, d_model)position = torch.arange(0, max_len).unsqueeze(1)div_term = torch.exp(torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model))pe[:, 0::2] = torch.sin(position * div_term)pe[:, 1::2] = torch.cos(position * div_term)pe = pe.unsqueeze(0)self.register_buffer('pe', pe)def forward(self, x):x = x + Variable(self.pe[:, :x.size(1)], requires_grad=False)return self.dropout(x)d_model = 512
dropout = 0.1
max_len = 60vocab = 1000
x = Variable(torch.LongTensor([[100, 2, 421, 508], [491, 998, 1, 221]]))
emb = Embeddings(d_model, vocab)
embr = emb(x)x = embr
pe = PositionalEncoding(d_model, dropout, max_len)
pe_result = pe(x)# 3.绘制词汇向量中特征的分布曲线
plt.figure(figsize=(15, 5)) # 创建一张15 x 5大小的画布
pe = PositionalEncoding(20, 0)
y = pe(Variable(torch.zeros(1, 100, 20)))
plt.plot(np.arange(100), y[0, :, 4:8].data.numpy())
plt.legend(["dim %d" % p for p in [4, 5, 6, 7]])
plt.show()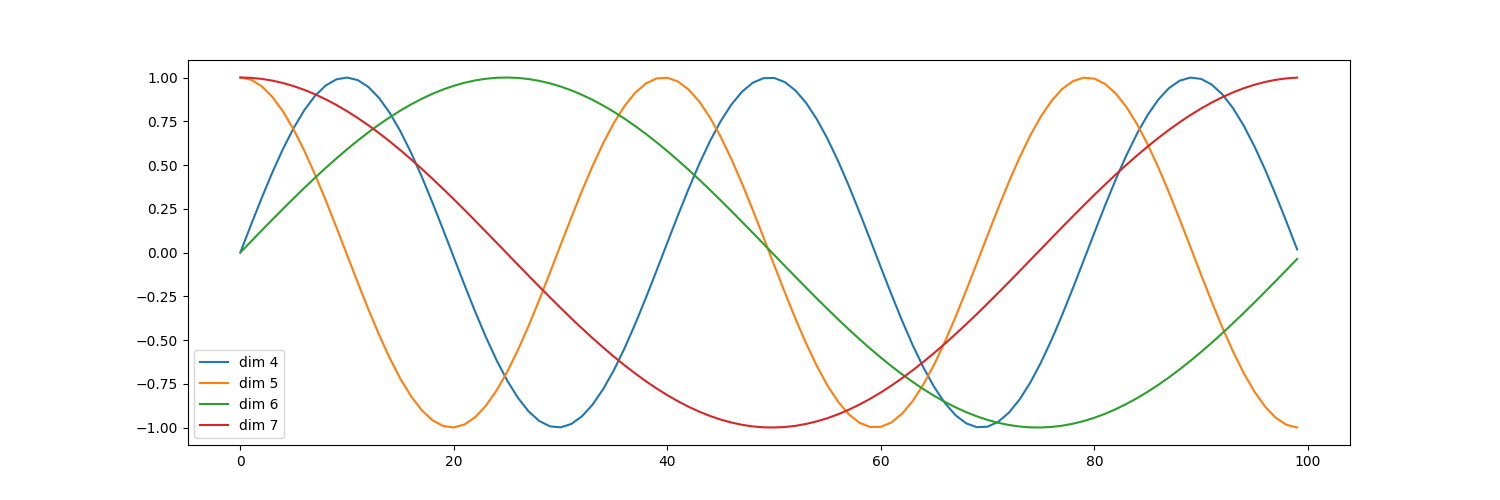
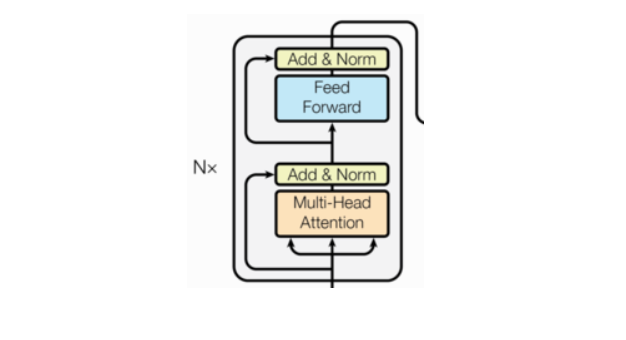
二、编码部分
- 由N个编码器层堆叠而成
- 每个编码器层由两个子层连接结构组成
- 第一个子层连接结构包括一个多头自注意力子层和规范化层以及一个残差连接
- 第二个子层连接结构包括一个前馈全连接子层和规范化层以及一个残差连接
掩码张量
np.triu演示
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
import math
import matplotlib.pyplot as plt
import numpy as np
import copy# np.triu演示
print(np.triu([[1, 2, 3], [4, 5, 6], [7, 8, 9], [10, 11, 12]], k=-1))
print(np.triu([[1, 2, 3], [4, 5, 6], [7, 8, 9], [10, 11, 12]], k=0))
print(np.triu([[1, 2, 3], [4, 5, 6], [7, 8, 9], [10, 11, 12]], k=1))
"""
[[ 1 2 3][ 4 5 6][ 0 8 9][ 0 0 12]]
[[1 2 3][0 5 6][0 0 9][0 0 0]]
[[0 2 3][0 0 6][0 0 0][0 0 0]]
"""⭐3.掩码张量函数
多次输入学习,最后学到最好。已经知道下文,所以要掩盖。
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
import math
import matplotlib.pyplot as plt
import numpy as np
import copy# 一、输入部分
# 1.文本嵌入层
class Embeddings(nn.Module):def __init__(self, d_model, vocab):super(Embeddings, self).__init__()self.lut = nn.Embedding(vocab, d_model)self.d_model = d_modeldef forward(self, x):return self.lut(x) * math.sqrt(self.d_model)# 2.位置编码器
class PositionalEncoding(nn.Module):def __init__(self, d_model, dropout, max_len=5000):super(PositionalEncoding, self).__init__()self.dropout = nn.Dropout(p=dropout)pe = torch.zeros(max_len, d_model)position = torch.arange(0, max_len).unsqueeze(1)div_term = torch.exp(torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model))pe[:, 0::2] = torch.sin(position * div_term)pe[:, 1::2] = torch.cos(position * div_term)pe = pe.unsqueeze(0)self.register_buffer('pe', pe)def forward(self, x):x = x + Variable(self.pe[:, :x.size(1)], requires_grad=False)return self.dropout(x)d_model = 512
dropout = 0.1
max_len = 60vocab = 1000
x = Variable(torch.LongTensor([[100, 2, 421, 508], [491, 998, 1, 221]]))
emb = Embeddings(d_model, vocab)
embr = emb(x)x = embr
pe = PositionalEncoding(d_model, dropout, max_len)
pe_result = pe(x)# 绘制词汇向量中特征的分布曲线
plt.figure(figsize=(15, 5)) # 创建一张15 x 5大小的画布
pe = PositionalEncoding(20, 0)
y = pe(Variable(torch.zeros(1, 100, 20)))
plt.plot(np.arange(100), y[0, :, 4:8].data.numpy())
plt.legend(["dim %d" % p for p in [4, 5, 6, 7]])
# plt.show()# 二、编码部分
# 1.掩码张量函数
def subsequent_mask(size):attn_shape = (1, size, size)subsequent_mask = np.triu(np.ones(attn_shape), k=1).astype('uint8')return torch.from_numpy(1 - subsequent_mask)
# 生成的掩码张量的最后两维的大小
size = 5
sm = subsequent_mask(size)
print("掩码张量:", sm)
"""
掩码张量: tensor([[[1, 0, 0, 0, 0],[1, 1, 0, 0, 0],[1, 1, 1, 0, 0],[1, 1, 1, 1, 0],[1, 1, 1, 1, 1]]], dtype=torch.uint8)
"""# 掩码张量的可视化
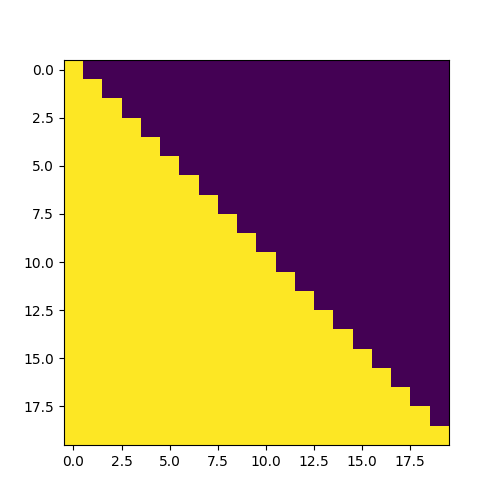
plt.figure(figsize=(5,5))
plt.imshow(subsequent_mask(20)[0])
plt.show()
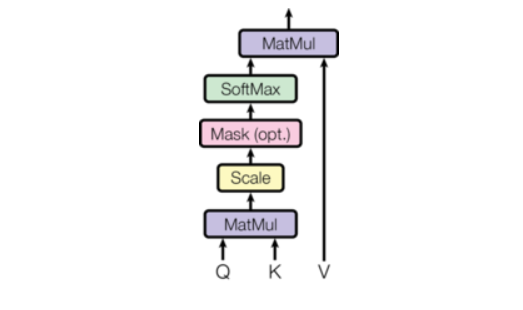
注意力机制
你在做一道题,key是提示,query是详细答案,value是你看完答案后你自己写的答案
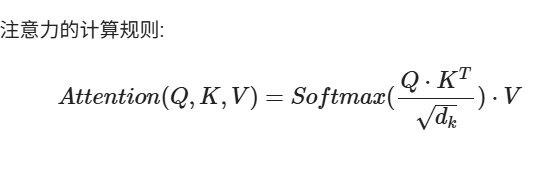
tensor.masked_fill演示
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
import math
import matplotlib.pyplot as plt
import numpy as np
import copyinput = Variable(torch.randn(5, 5))
print(input)mask = Variable(torch.zeros(5, 5))
print(mask)input.masked_fill(mask == 0, -1e9)
print(input)
"""
tensor([[-2.0163, -0.7226, -0.5435, 0.3623, 0.7278],[-0.8157, -0.6707, -1.4750, -0.4648, 0.4925],[ 0.7696, -0.9166, -0.2969, -0.0952, -0.0676],[ 0.6840, 0.4322, 1.5707, -0.2410, 0.9939],[ 0.2432, -0.8106, -0.8171, 2.3484, -0.3595]])
tensor([[0., 0., 0., 0., 0.],[0., 0., 0., 0., 0.],[0., 0., 0., 0., 0.],[0., 0., 0., 0., 0.],[0., 0., 0., 0., 0.]])
tensor([[-2.0163, -0.7226, -0.5435, 0.3623, 0.7278],[-0.8157, -0.6707, -1.4750, -0.4648, 0.4925],[ 0.7696, -0.9166, -0.2969, -0.0952, -0.0676],[ 0.6840, 0.4322, 1.5707, -0.2410, 0.9939],[ 0.2432, -0.8106, -0.8171, 2.3484, -0.3595]])
"""⭐4.注意力机制
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
import math
import matplotlib.pyplot as plt
import numpy as np
import copy# 一、输入部分
# 1.文本嵌入层
class Embeddings(nn.Module):def __init__(self, d_model, vocab):super(Embeddings, self).__init__()self.lut = nn.Embedding(vocab, d_model)self.d_model = d_modeldef forward(self, x):return self.lut(x) * math.sqrt(self.d_model)# 2.位置编码器
class PositionalEncoding(nn.Module):def __init__(self, d_model, dropout, max_len=5000):super(PositionalEncoding, self).__init__()self.dropout = nn.Dropout(p=dropout)pe = torch.zeros(max_len, d_model)position = torch.arange(0, max_len).unsqueeze(1)div_term = torch.exp(torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model))pe[:, 0::2] = torch.sin(position * div_term)pe[:, 1::2] = torch.cos(position * div_term)pe = pe.unsqueeze(0)self.register_buffer('pe', pe)def forward(self, x):x = x + Variable(self.pe[:, :x.size(1)], requires_grad=False)return self.dropout(x)d_model = 512
dropout = 0.1
max_len = 60vocab = 1000
x = Variable(torch.LongTensor([[100, 2, 421, 508], [491, 998, 1, 221]]))
emb = Embeddings(d_model, vocab)
embr = emb(x)x = embr
pe = PositionalEncoding(d_model, dropout, max_len)
pe_result = pe(x)# 绘制词汇向量中特征的分布曲线
plt.figure(figsize=(15, 5)) # 创建一张15 x 5大小的画布
pe = PositionalEncoding(20, 0)
y = pe(Variable(torch.zeros(1, 100, 20)))
plt.plot(np.arange(100), y[0, :, 4:8].data.numpy())
plt.legend(["dim %d" % p for p in [4, 5, 6, 7]])# plt.show()# 二、编码部分
# 1.掩码张量函数
def subsequent_mask(size):attn_shape = (1, size, size)subsequent_mask = np.triu(np.ones(attn_shape), k=1).astype('uint8')return torch.from_numpy(1 - subsequent_mask)# 掩码张量的可视化
plt.figure(figsize=(5, 5))
plt.imshow(subsequent_mask(20)[0])
# plt.show()# 2.注意力机制
def attention(query, key, value, mask=None, dropout=None):d_k = query.size(-1)scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)if mask is not None:scores = scores.masked_fill(mask == 0, -1e9)p_attn = F.softmax(scores, dim=-1)if dropout is not None:p_attn = dropout(p_attn)return torch.matmul(p_attn, value), p_attnquery = key = value = pe_result
attn, p_attn = attention(query, key, value)
print("query的注意力表示:", attn) # 2x4x512
print("注意力张量:", p_attn) # size 2x4x4print("*****************************************************************")
# 带有mask的输入参数
query = key = value = pe_result
mask = Variable(torch.zeros(2, 4, 4))
attn, p_attn = attention(query, key, value, mask=mask)
print("query的注意力表示:", attn) # size 2x4x512
print("注意力张量:", p_attn) # size 2x4x4"""
query的注意力表示: tensor([[[-1.0675e+01, -8.0456e+00, -2.2159e+01, ..., -1.7814e+01,3.0499e+01, 4.1339e+01],[ 3.2106e+01, 2.4037e+01, 1.3494e+01, ..., 2.4034e+01,1.8157e+00, -2.0683e+01],[ 6.6581e+00, 1.4371e+01, 1.6482e+01, ..., -9.3249e-01,1.4465e+01, -2.8638e+01],[-1.4626e+00, -8.2685e+00, 4.5742e+01, ..., 3.5178e+01,1.2451e+01, -5.7837e+00]],[[ 0.0000e+00, 1.4930e+01, 2.3648e+00, ..., -1.5506e+01,-3.2476e+01, -9.5132e+00],[ 0.0000e+00, 4.5180e-02, -3.4786e+01, ..., 9.0967e+00,-9.1057e+00, -2.0643e+01],[ 0.0000e+00, -6.6465e+00, -7.8801e+00, ..., 5.4841e+00,3.9251e+01, 2.5519e+01],[ 0.0000e+00, 2.9907e+01, -9.8955e+00, ..., -8.6210e+00,0.0000e+00, 0.0000e+00]]], grad_fn=<UnsafeViewBackward0>)
注意力张量: tensor([[[1., 0., 0., 0.],[0., 1., 0., 0.],[0., 0., 1., 0.],[0., 0., 0., 1.]],[[1., 0., 0., 0.],[0., 1., 0., 0.],[0., 0., 1., 0.],[0., 0., 0., 1.]]], grad_fn=<SoftmaxBackward0>)
*****************************************************************
query的注意力表示: tensor([[[ 6.6567, 5.5234, 13.3898, ..., 10.1163, 14.8077, -3.4414],[ 6.6567, 5.5234, 13.3898, ..., 10.1163, 14.8077, -3.4414],[ 6.6567, 5.5234, 13.3898, ..., 10.1163, 14.8077, -3.4414],[ 6.6567, 5.5234, 13.3898, ..., 10.1163, 14.8077, -3.4414]],[[ 0.0000, 9.5590, -12.5492, ..., -2.3865, -0.5825, -1.1594],[ 0.0000, 9.5590, -12.5492, ..., -2.3865, -0.5825, -1.1594],[ 0.0000, 9.5590, -12.5492, ..., -2.3865, -0.5825, -1.1594],[ 0.0000, 9.5590, -12.5492, ..., -2.3865, -0.5825, -1.1594]]],grad_fn=<UnsafeViewBackward0>)
注意力张量: tensor([[[0.2500, 0.2500, 0.2500, 0.2500],[0.2500, 0.2500, 0.2500, 0.2500],[0.2500, 0.2500, 0.2500, 0.2500],[0.2500, 0.2500, 0.2500, 0.2500]],[[0.2500, 0.2500, 0.2500, 0.2500],[0.2500, 0.2500, 0.2500, 0.2500],[0.2500, 0.2500, 0.2500, 0.2500],[0.2500, 0.2500, 0.2500, 0.2500]]], grad_fn=<SoftmaxBackward0>)
"""
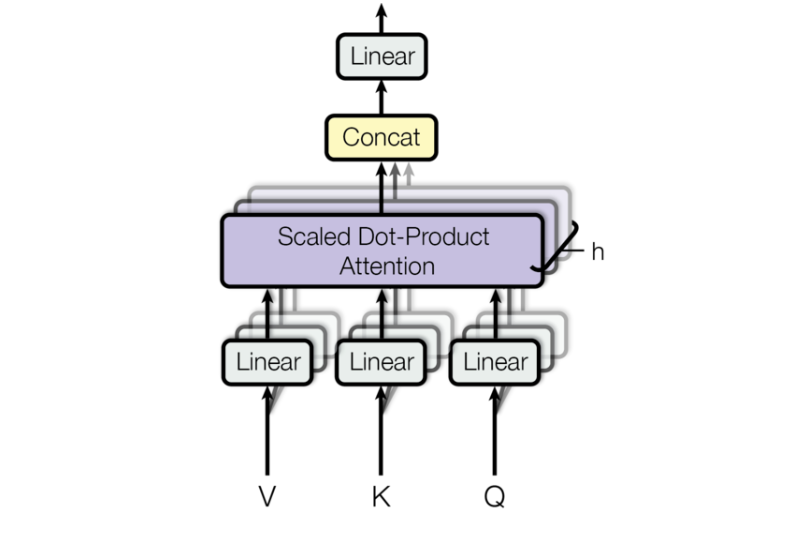
多头注意力机制
一千个哈姆雷特有《哈姆雷特》
tensor.view演示
torch.transpose演示
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
import math
import matplotlib.pyplot as plt
import numpy as np
import copy# tensor.view演示
x = torch.randn(4, 4)
print(x.size())# torch.Size([4, 4])y = x.view(16)
print(y.size())# torch.Size([16])z = x.view(-1, 8)
print(z.size())# torch.Size([2, 8])a = torch.randn(1, 2, 3, 4)
print(a.size())# torch.Size([1, 2, 3, 4])b = a.transpose(1, 2)# 序号为1的和序号为2的交换位置
print(b.size())# torch.Size([1, 3, 2, 4])c = a.view(1, 3, 2, 4)
print(c.size())# torch.Size([1, 3, 2, 4])
print(torch.equal(b, c))# False# torch.transpose演示
x = torch.randn(2, 3)
print(x)
# tensor([[-0.8869, 1.2497, 0.3226],
# [-0.6379, -1.4205, -1.2025]])
print(torch.transpose(x, 0, 1))
# tensor([[-0.8869, -0.6379],
# [ 1.2497, -1.4205],
# [ 0.3226, -1.2025]])⭐5.多头注意力机制
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
import math
import matplotlib.pyplot as plt
import numpy as np
import copy# 一、输入部分
# 1.文本嵌入层
class Embeddings(nn.Module):def __init__(self, d_model, vocab):super(Embeddings, self).__init__()self.lut = nn.Embedding(vocab, d_model)self.d_model = d_modeldef forward(self, x):return self.lut(x) * math.sqrt(self.d_model)# 2.位置编码器
class PositionalEncoding(nn.Module):def __init__(self, d_model, dropout, max_len=5000):super(PositionalEncoding, self).__init__()self.dropout = nn.Dropout(p=dropout)pe = torch.zeros(max_len, d_model)position = torch.arange(0, max_len).unsqueeze(1)div_term = torch.exp(torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model))pe[:, 0::2] = torch.sin(position * div_term)pe[:, 1::2] = torch.cos(position * div_term)pe = pe.unsqueeze(0)self.register_buffer('pe', pe)def forward(self, x):x = x + Variable(self.pe[:, :x.size(1)], requires_grad=False)return self.dropout(x)d_model = 512
dropout = 0.1
max_len = 60vocab = 1000
x = Variable(torch.LongTensor([[100, 2, 421, 508], [491, 998, 1, 221]]))
emb = Embeddings(d_model, vocab)
embr = emb(x)x = embr
pe = PositionalEncoding(d_model, dropout, max_len)
pe_result = pe(x)# 绘制词汇向量中特征的分布曲线
plt.figure(figsize=(15, 5)) # 创建一张15 x 5大小的画布
pe = PositionalEncoding(20, 0)
y = pe(Variable(torch.zeros(1, 100, 20)))
plt.plot(np.arange(100), y[0, :, 4:8].data.numpy())
plt.legend(["dim %d" % p for p in [4, 5, 6, 7]])# plt.show()# 二、编码部分
# 1.掩码张量函数
def subsequent_mask(size):attn_shape = (1, size, size)subsequent_mask = np.triu(np.ones(attn_shape), k=1).astype('uint8')return torch.from_numpy(1 - subsequent_mask)# 掩码张量的可视化
plt.figure(figsize=(5, 5))
plt.imshow(subsequent_mask(20)[0])# plt.show()# 2.注意力机制
def attention(query, key, value, mask=None, dropout=None):d_k = query.size(-1)scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)if mask is not None:scores = scores.masked_fill(mask == 0, -1e9)p_attn = F.softmax(scores, dim=-1)if dropout is not None:p_attn = dropout(p_attn)return torch.matmul(p_attn, value), p_attnquery = key = value = pe_result
attn, p_attn = attention(query, key, value)
# print("query的注意力表示:", attn) # 2x4x512
# print("注意力张量:", p_attn) # size 2x4x4
#
# print("*****************************************************************")
# 带有mask的输入参数
query = key = value = pe_result
mask = Variable(torch.zeros(2, 4, 4))
attn, p_attn = attention(query, key, value, mask=mask)# print("query的注意力表示:", attn) # size 2x4x512
# print("注意力张量:", p_attn) # size 2x4x4# 深拷贝
def clones(module, N):return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])# 多头注意力机制
class MultiHeadedAttention(nn.Module):def __init__(self, head, embedding_dim, dropout=0.1):super(MultiHeadedAttention, self).__init__()assert embedding_dim % head == 0self.d_k = embedding_dim // headself.head = head# 在多头注意力中,Q,K,V各需要一个,最后拼接的矩阵还需要一个,一共是4个self.linears = clones(nn.Linear(embedding_dim, embedding_dim), 4)self.attn = Noneself.dropout = nn.Dropout(p=dropout)def forward(self, query, key, value, mask=None):if mask is not None:mask = mask.unsqueeze(0)batch_size = query.size(0)query, key, value = [model(x).view(batch_size, -1, self.head, self.d_k).transpose(1, 2)for model, x in zip(self.linears, (query, key, value))]x, self.attn = attention(query, key, value, mask=mask, dropout=self.dropout)x = x.transpose(1, 2).contiguous().view(batch_size, -1, self.head * self.d_k)return self.linears[-1](x)head = 8
embedding_dim = 512
dropout = 0.2
query = value = key = pe_result
mask = Variable(torch.zeros(8, 4, 4))
mha = MultiHeadedAttention(head, embedding_dim, dropout)
mha_result = mha(query, key, value, mask)
print(mha_result)
"""
tensor([[[ 5.1117, 2.7441, -3.6746, ..., 5.4250, 2.4214, 0.8056],[ 6.1471, 2.2109, -3.5177, ..., 5.3436, 3.8831, 4.9805],[ 1.4831, 0.4307, -2.5829, ..., 2.0772, 0.9475, 3.2005],[ 3.5892, 2.9082, -1.7384, ..., 2.9132, 4.1973, 5.0990]],[[ -1.3965, -6.1177, -7.4958, ..., -0.5587, -6.4261, -3.2176],[ -1.2701, -4.3102, -6.2340, ..., -4.0173, -3.0431, -0.6736],[ 0.8762, -5.1155, -6.8253, ..., -4.9823, -1.4425, -2.7415],[ 0.3864, -8.2357, -11.1042, ..., 0.3552, -4.3414, -4.0765]]],grad_fn=<ViewBackward0>)
"""
⭐6.前馈全连接层
注意力机制可能对复杂过程的拟合程度不够, 通过增加两层网络来增强模型的能力
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
import math
import matplotlib.pyplot as plt
import numpy as np
import copy# 一、输入部分
# 1.文本嵌入层
class Embeddings(nn.Module):def __init__(self, d_model, vocab):super(Embeddings, self).__init__()self.lut = nn.Embedding(vocab, d_model)self.d_model = d_modeldef forward(self, x):return self.lut(x) * math.sqrt(self.d_model)# 2.位置编码器
class PositionalEncoding(nn.Module):def __init__(self, d_model, dropout, max_len=5000):super(PositionalEncoding, self).__init__()self.dropout = nn.Dropout(p=dropout)pe = torch.zeros(max_len, d_model)position = torch.arange(0, max_len).unsqueeze(1)div_term = torch.exp(torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model))pe[:, 0::2] = torch.sin(position * div_term)pe[:, 1::2] = torch.cos(position * div_term)pe = pe.unsqueeze(0)self.register_buffer('pe', pe)def forward(self, x):x = x + Variable(self.pe[:, :x.size(1)], requires_grad=False)return self.dropout(x)d_model = 512
dropout = 0.1
max_len = 60vocab = 1000
x = Variable(torch.LongTensor([[100, 2, 421, 508], [491, 998, 1, 221]]))
emb = Embeddings(d_model, vocab)
embr = emb(x)x = embr
pe = PositionalEncoding(d_model, dropout, max_len)
pe_result = pe(x)# 绘制词汇向量中特征的分布曲线
plt.figure(figsize=(15, 5)) # 创建一张15 x 5大小的画布
pe = PositionalEncoding(20, 0)
y = pe(Variable(torch.zeros(1, 100, 20)))
plt.plot(np.arange(100), y[0, :, 4:8].data.numpy())
plt.legend(["dim %d" % p for p in [4, 5, 6, 7]])# plt.show()# 二、编码部分
# 1.掩码张量函数
def subsequent_mask(size):attn_shape = (1, size, size)subsequent_mask = np.triu(np.ones(attn_shape), k=1).astype('uint8')return torch.from_numpy(1 - subsequent_mask)# 掩码张量的可视化
plt.figure(figsize=(5, 5))
plt.imshow(subsequent_mask(20)[0])# plt.show()# 2.注意力机制
def attention(query, key, value, mask=None, dropout=None):d_k = query.size(-1)scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)if mask is not None:scores = scores.masked_fill(mask == 0, -1e9)p_attn = F.softmax(scores, dim=-1)if dropout is not None:p_attn = dropout(p_attn)return torch.matmul(p_attn, value), p_attnquery = key = value = pe_result
attn, p_attn = attention(query, key, value)
# print("query的注意力表示:", attn) # 2x4x512
# print("注意力张量:", p_attn) # size 2x4x4
#
# print("*****************************************************************")
# 带有mask的输入参数
query = key = value = pe_result
mask = Variable(torch.zeros(2, 4, 4))
attn, p_attn = attention(query, key, value, mask=mask)
# print("query的注意力表示:", attn) # size 2x4x512
# print("注意力张量:", p_attn) # size 2x4x4# 3.多头注意力机制
# 深拷贝
def clones(module, N):return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])class MultiHeadedAttention(nn.Module):def __init__(self, head, embedding_dim, dropout=0.1):super(MultiHeadedAttention, self).__init__()assert embedding_dim % head == 0self.d_k = embedding_dim // headself.head = head# 在多头注意力中,Q,K,V各需要一个,最后拼接的矩阵还需要一个,一共是4个self.linears = clones(nn.Linear(embedding_dim, embedding_dim), 4)self.attn = Noneself.dropout = nn.Dropout(p=dropout)def forward(self, query, key, value, mask=None):if mask is not None:mask = mask.unsqueeze(0)batch_size = query.size(0)query, key, value = [model(x).view(batch_size, -1, self.head, self.d_k).transpose(1, 2)for model, x in zip(self.linears, (query, key, value))]x, self.attn = attention(query, key, value, mask=mask, dropout=self.dropout)x = x.transpose(1, 2).contiguous().view(batch_size, -1, self.head * self.d_k)return self.linears[-1](x)head = 8
embedding_dim = 512
dropout = 0.2
query = value = key = pe_result
mask = Variable(torch.zeros(8, 4, 4))
mha = MultiHeadedAttention(head, embedding_dim, dropout)
mha_result = mha(query, key, value, mask)
# print(mha_result)# 4.前馈全连接层
class PositionwiseFeedForward(nn.Module):def __init__(self, d_model, d_ff, dropout=0.1):super(PositionwiseFeedForward, self).__init__()self.w1 = nn.Linear(d_model, d_ff)self.w2 = nn.Linear(d_ff, d_model)self.dropout = nn.Dropout(dropout)def forward(self, x):return self.w2(self.dropout(F.relu(self.w1(x))))d_model = 512
d_ff = 64
dropout = 0.2
x = mha_result
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
ff_result = ff(x)
print(ff_result)
"""
tensor([[[ 1.3699, -0.0291, -0.3212, ..., -0.7105, 0.1728, -1.6720],[ 1.8951, 0.6111, -0.5830, ..., -1.4471, -0.2291, -2.0005],[ 1.1673, 0.0624, 0.8014, ..., 1.3812, -0.4503, -2.1730],[ 1.5105, 0.2297, 0.2027, ..., 1.0533, 0.9179, -0.9378]],[[-0.5993, 1.5654, -0.5952, ..., 0.9375, -0.1775, -2.4535],[ 0.1358, 1.8777, -0.6284, ..., 2.0970, 1.4326, -1.5991],[-0.4315, 0.3731, 0.6662, ..., 1.8709, 0.2463, -0.8921],[-0.6862, 1.1372, -0.1283, ..., 2.5608, 0.7814, -1.5519]]],grad_fn=<ViewBackward0>)
"""⭐7.规范化层
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
import math
import matplotlib.pyplot as plt
import numpy as np
import copy# 一、输入部分
# 1.文本嵌入层
class Embeddings(nn.Module):def __init__(self, d_model, vocab):super(Embeddings, self).__init__()self.lut = nn.Embedding(vocab, d_model)self.d_model = d_modeldef forward(self, x):return self.lut(x) * math.sqrt(self.d_model)# 2.位置编码器
class PositionalEncoding(nn.Module):def __init__(self, d_model, dropout, max_len=5000):super(PositionalEncoding, self).__init__()self.dropout = nn.Dropout(p=dropout)pe = torch.zeros(max_len, d_model)position = torch.arange(0, max_len).unsqueeze(1)div_term = torch.exp(torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model))pe[:, 0::2] = torch.sin(position * div_term)pe[:, 1::2] = torch.cos(position * div_term)pe = pe.unsqueeze(0)self.register_buffer('pe', pe)def forward(self, x):x = x + Variable(self.pe[:, :x.size(1)], requires_grad=False)return self.dropout(x)d_model = 512
dropout = 0.1
max_len = 60vocab = 1000
x = Variable(torch.LongTensor([[100, 2, 421, 508], [491, 998, 1, 221]]))
emb = Embeddings(d_model, vocab)
embr = emb(x)x = embr
pe = PositionalEncoding(d_model, dropout, max_len)
pe_result = pe(x)# 绘制词汇向量中特征的分布曲线
plt.figure(figsize=(15, 5)) # 创建一张15 x 5大小的画布
pe = PositionalEncoding(20, 0)
y = pe(Variable(torch.zeros(1, 100, 20)))
plt.plot(np.arange(100), y[0, :, 4:8].data.numpy())
plt.legend(["dim %d" % p for p in [4, 5, 6, 7]])# plt.show()# 二、编码部分
# 1.掩码张量函数
def subsequent_mask(size):attn_shape = (1, size, size)subsequent_mask = np.triu(np.ones(attn_shape), k=1).astype('uint8')return torch.from_numpy(1 - subsequent_mask)# 掩码张量的可视化
plt.figure(figsize=(5, 5))
plt.imshow(subsequent_mask(20)[0])# plt.show()# 2.注意力机制
def attention(query, key, value, mask=None, dropout=None):d_k = query.size(-1)scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)if mask is not None:scores = scores.masked_fill(mask == 0, -1e9)p_attn = F.softmax(scores, dim=-1)if dropout is not None:p_attn = dropout(p_attn)return torch.matmul(p_attn, value), p_attnquery = key = value = pe_result
attn, p_attn = attention(query, key, value)
# print("query的注意力表示:", attn) # 2x4x512
# print("注意力张量:", p_attn) # size 2x4x4
#
# print("*****************************************************************")
# 带有mask的输入参数
query = key = value = pe_result
mask = Variable(torch.zeros(2, 4, 4))
attn, p_attn = attention(query, key, value, mask=mask)
# print("query的注意力表示:", attn) # size 2x4x512
# print("注意力张量:", p_attn) # size 2x4x4# 3.多头注意力机制
# 深拷贝
def clones(module, N):return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])class MultiHeadedAttention(nn.Module):def __init__(self, head, embedding_dim, dropout=0.1):super(MultiHeadedAttention, self).__init__()assert embedding_dim % head == 0self.d_k = embedding_dim // headself.head = head# 在多头注意力中,Q,K,V各需要一个,最后拼接的矩阵还需要一个,一共是4个self.linears = clones(nn.Linear(embedding_dim, embedding_dim), 4)self.attn = Noneself.dropout = nn.Dropout(p=dropout)def forward(self, query, key, value, mask=None):if mask is not None:mask = mask.unsqueeze(0)batch_size = query.size(0)query, key, value = [model(x).view(batch_size, -1, self.head, self.d_k).transpose(1, 2)for model, x in zip(self.linears, (query, key, value))]x, self.attn = attention(query, key, value, mask=mask, dropout=self.dropout)x = x.transpose(1, 2).contiguous().view(batch_size, -1, self.head * self.d_k)return self.linears[-1](x)head = 8
embedding_dim = 512
dropout = 0.2
query = value = key = pe_result
mask = Variable(torch.zeros(8, 4, 4))
mha = MultiHeadedAttention(head, embedding_dim, dropout)
mha_result = mha(query, key, value, mask)
# print(mha_result)# 4.前馈全连接层
class PositionwiseFeedForward(nn.Module):def __init__(self, d_model, d_ff, dropout=0.1):super(PositionwiseFeedForward, self).__init__()self.w1 = nn.Linear(d_model, d_ff)self.w2 = nn.Linear(d_ff, d_model)self.dropout = nn.Dropout(dropout)def forward(self, x):return self.w2(self.dropout(F.relu(self.w1(x))))d_model = 512
d_ff = 64
dropout = 0.2
x = mha_result
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
ff_result = ff(x)# 5.规范化层
# 通过LayerNorm实现规范化层的类
class LayerNorm(nn.Module):def __init__(self, features, eps=1e-6):super(LayerNorm, self).__init__()self.a2 = nn.Parameter(torch.ones(features))self.b2 = nn.Parameter(torch.zeros(features))self.eps = epsdef forward(self, x):mean = x.mean(-1, keepdim=True)std = x.std(-1, keepdim=True)return self.a2 * (x - mean) / (std + self.eps) + self.b2features = d_model = 512
eps = 1e-6
x = ff_result
ln = LayerNorm(features, eps)
ln_result = ln(x)
print(ln_result)
"""
tensor([[[-8.3460e-01, -4.5519e-01, -4.8425e-01, ..., 4.5406e-01,9.2949e-01, 9.3043e-01],[-1.1315e+00, -9.1994e-01, -6.4669e-01, ..., 7.5945e-01,7.6214e-01, 8.0217e-01],[-6.3322e-01, 4.7747e-01, -5.0195e-01, ..., 4.6353e-04,3.2654e-01, -1.6072e-02],[-9.1272e-01, -3.7506e-01, -1.4400e+00, ..., -2.3055e-01,4.1403e-01, -1.4555e-01]],[[-1.1166e-01, -1.3829e+00, -5.9005e-01, ..., 1.5550e+00,9.5446e-01, 4.0732e-02],[ 6.8869e-01, -8.0725e-01, -1.4566e+00, ..., 1.2550e+00,6.6449e-01, -1.1773e+00],[-5.8408e-01, -1.1875e+00, -7.8642e-01, ..., 1.1239e+00,6.7882e-01, 5.9670e-01],[ 9.4805e-01, -1.3687e+00, 2.0909e-01, ..., 6.0416e-01,2.0030e+00, -5.7529e-02]]], grad_fn=<AddBackward0>)
"""⭐8.残差连接(子层连接、跳跃连接)
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
import math
import matplotlib.pyplot as plt
import numpy as np
import copy# 一、输入部分
# 1.文本嵌入层
class Embeddings(nn.Module):def __init__(self, d_model, vocab):super(Embeddings, self).__init__()self.lut = nn.Embedding(vocab, d_model)self.d_model = d_modeldef forward(self, x):return self.lut(x) * math.sqrt(self.d_model)# 2.位置编码器
class PositionalEncoding(nn.Module):def __init__(self, d_model, dropout, max_len=5000):super(PositionalEncoding, self).__init__()self.dropout = nn.Dropout(p=dropout)pe = torch.zeros(max_len, d_model)position = torch.arange(0, max_len).unsqueeze(1)div_term = torch.exp(torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model))pe[:, 0::2] = torch.sin(position * div_term)pe[:, 1::2] = torch.cos(position * div_term)pe = pe.unsqueeze(0)self.register_buffer('pe', pe)def forward(self, x):x = x + Variable(self.pe[:, :x.size(1)], requires_grad=False)return self.dropout(x)d_model = 512
dropout = 0.1
max_len = 60vocab = 1000
x = Variable(torch.LongTensor([[100, 2, 421, 508], [491, 998, 1, 221]]))
emb = Embeddings(d_model, vocab)
embr = emb(x)x = embr
pe = PositionalEncoding(d_model, dropout, max_len)
pe_result = pe(x)# 绘制词汇向量中特征的分布曲线
plt.figure(figsize=(15, 5)) # 创建一张15 x 5大小的画布
pe = PositionalEncoding(20, 0)
y = pe(Variable(torch.zeros(1, 100, 20)))
plt.plot(np.arange(100), y[0, :, 4:8].data.numpy())
plt.legend(["dim %d" % p for p in [4, 5, 6, 7]])# plt.show()# 二、编码部分
# 1.掩码张量函数
def subsequent_mask(size):attn_shape = (1, size, size)subsequent_mask = np.triu(np.ones(attn_shape), k=1).astype('uint8')return torch.from_numpy(1 - subsequent_mask)# 掩码张量的可视化
plt.figure(figsize=(5, 5))
plt.imshow(subsequent_mask(20)[0])# plt.show()# 2.注意力机制
def attention(query, key, value, mask=None, dropout=None):d_k = query.size(-1)scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)if mask is not None:scores = scores.masked_fill(mask == 0, -1e9)p_attn = F.softmax(scores, dim=-1)if dropout is not None:p_attn = dropout(p_attn)return torch.matmul(p_attn, value), p_attnquery = key = value = pe_result
attn, p_attn = attention(query, key, value)
# print("query的注意力表示:", attn) # 2x4x512
# print("注意力张量:", p_attn) # size 2x4x4
#
# print("*****************************************************************")
# 带有mask的输入参数
query = key = value = pe_result
mask = Variable(torch.zeros(2, 4, 4))
attn, p_attn = attention(query, key, value, mask=mask)
# print("query的注意力表示:", attn) # size 2x4x512
# print("注意力张量:", p_attn) # size 2x4x4# 3.多头注意力机制
# 深拷贝
def clones(module, N):return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])class MultiHeadedAttention(nn.Module):def __init__(self, head, embedding_dim, dropout=0.1):super(MultiHeadedAttention, self).__init__()assert embedding_dim % head == 0self.d_k = embedding_dim // headself.head = head# 在多头注意力中,Q,K,V各需要一个,最后拼接的矩阵还需要一个,一共是4个self.linears = clones(nn.Linear(embedding_dim, embedding_dim), 4)self.attn = Noneself.dropout = nn.Dropout(p=dropout)def forward(self, query, key, value, mask=None):if mask is not None:mask = mask.unsqueeze(0)batch_size = query.size(0)query, key, value = [model(x).view(batch_size, -1, self.head, self.d_k).transpose(1, 2)for model, x in zip(self.linears, (query, key, value))]x, self.attn = attention(query, key, value, mask=mask, dropout=self.dropout)x = x.transpose(1, 2).contiguous().view(batch_size, -1, self.head * self.d_k)return self.linears[-1](x)head = 8
embedding_dim = 512
dropout = 0.2
query = value = key = pe_result
mask = Variable(torch.zeros(8, 4, 4))
mha = MultiHeadedAttention(head, embedding_dim, dropout)
mha_result = mha(query, key, value, mask)
# print(mha_result)# 4.前馈全连接层
class PositionwiseFeedForward(nn.Module):def __init__(self, d_model, d_ff, dropout=0.1):super(PositionwiseFeedForward, self).__init__()self.w1 = nn.Linear(d_model, d_ff)self.w2 = nn.Linear(d_ff, d_model)self.dropout = nn.Dropout(dropout)def forward(self, x):return self.w2(self.dropout(F.relu(self.w1(x))))d_model = 512
d_ff = 64
dropout = 0.2
x = mha_result
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
ff_result = ff(x)# 5.规范化层
# 通过LayerNorm实现规范化层的类
class LayerNorm(nn.Module):def __init__(self, features, eps=1e-6):super(LayerNorm, self).__init__()self.a2 = nn.Parameter(torch.ones(features))self.b2 = nn.Parameter(torch.zeros(features))self.eps = epsdef forward(self, x):mean = x.mean(-1, keepdim=True)std = x.std(-1, keepdim=True)return self.a2 * (x - mean) / (std + self.eps) + self.b2features = d_model = 512
eps = 1e-6
x = ff_result
ln = LayerNorm(features, eps)
ln_result = ln(x)# 6.残差连接
class SublayerConnection(nn.Module):def __init__(self, size, dropout=0.1):super(SublayerConnection, self).__init__()self.norm = LayerNorm(size)self.dropout = nn.Dropout(p=dropout)def forward(self, x, sublayer):return x + self.dropout(sublayer(self.norm(x)))size = 512
dropout = 0.2
head = 8
d_model = 512
x = pe_result
mask = Variable(torch.zeros(8, 4, 4))
self_attn = MultiHeadedAttention(head, d_model)
sublayer = lambda x: self_attn(x, x, x, mask)
sc = SublayerConnection(size, dropout)
sc_result = sc(x, sublayer)
print(sc_result)
print(sc_result.shape)
"""
tensor([[[-8.1750e+00, 0.0000e+00, 7.1912e+00, ..., 1.4916e+01,-1.9816e+01, -1.5434e+01],[-1.0226e+01, 2.1595e+00, 6.9106e+00, ..., -1.8356e+01,-2.3092e+01, 1.7498e+00],[-2.8452e+01, -1.0691e-01, 1.9114e-01, ..., 6.0072e+00,2.7866e+01, -2.8865e+01],[ 2.7632e+01, 2.2874e+01, -5.3257e+00, ..., -2.7372e-01,-2.7839e+01, 3.2575e+01]],[[-7.4514e+00, 1.0837e+01, 1.2139e+01, ..., -4.2897e+01,4.9849e+00, -6.1880e+00],[-2.3347e+01, -2.6158e-02, 3.0347e+01, ..., -1.1466e+01,-2.5094e+01, 3.5434e+01],[ 1.8800e+01, -2.8887e+01, -5.4066e+00, ..., -1.9323e+01,3.9585e-01, -1.9223e+01],[-2.0564e+00, 1.3380e+01, 3.6210e+01, ..., -2.6659e+01,-9.5822e+00, 3.5938e+01]]], grad_fn=<AddBackward0>)
torch.Size([2, 4, 512])
"""
⭐9.编码器层
作为编码器的组成单元, 每个编码器层完成一次对输入的特征提取过程
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
import math
import matplotlib.pyplot as plt
import numpy as np
import copy# 一、输入部分
# 1.文本嵌入层
class Embeddings(nn.Module):def __init__(self, d_model, vocab):super(Embeddings, self).__init__()self.lut = nn.Embedding(vocab, d_model)self.d_model = d_modeldef forward(self, x):return self.lut(x) * math.sqrt(self.d_model)# 2.位置编码器
class PositionalEncoding(nn.Module):def __init__(self, d_model, dropout, max_len=5000):super(PositionalEncoding, self).__init__()self.dropout = nn.Dropout(p=dropout)pe = torch.zeros(max_len, d_model)position = torch.arange(0, max_len).unsqueeze(1)div_term = torch.exp(torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model))pe[:, 0::2] = torch.sin(position * div_term)pe[:, 1::2] = torch.cos(position * div_term)pe = pe.unsqueeze(0)self.register_buffer('pe', pe)def forward(self, x):x = x + Variable(self.pe[:, :x.size(1)], requires_grad=False)return self.dropout(x)d_model = 512
dropout = 0.1
max_len = 60vocab = 1000
x = Variable(torch.LongTensor([[100, 2, 421, 508], [491, 998, 1, 221]]))
emb = Embeddings(d_model, vocab)
embr = emb(x)x = embr
pe = PositionalEncoding(d_model, dropout, max_len)
pe_result = pe(x)# 绘制词汇向量中特征的分布曲线
plt.figure(figsize=(15, 5)) # 创建一张15 x 5大小的画布
pe = PositionalEncoding(20, 0)
y = pe(Variable(torch.zeros(1, 100, 20)))
plt.plot(np.arange(100), y[0, :, 4:8].data.numpy())
plt.legend(["dim %d" % p for p in [4, 5, 6, 7]])# plt.show()# 二、编码部分
# 1.掩码张量函数
def subsequent_mask(size):attn_shape = (1, size, size)subsequent_mask = np.triu(np.ones(attn_shape), k=1).astype('uint8')return torch.from_numpy(1 - subsequent_mask)# 掩码张量的可视化
plt.figure(figsize=(5, 5))
plt.imshow(subsequent_mask(20)[0])# plt.show()# 2.注意力机制
def attention(query, key, value, mask=None, dropout=None):d_k = query.size(-1)scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)if mask is not None:scores = scores.masked_fill(mask == 0, -1e9)p_attn = F.softmax(scores, dim=-1)if dropout is not None:p_attn = dropout(p_attn)return torch.matmul(p_attn, value), p_attnquery = key = value = pe_result
attn, p_attn = attention(query, key, value)
# print("query的注意力表示:", attn) # 2x4x512
# print("注意力张量:", p_attn) # size 2x4x4
#
# print("*****************************************************************")
# 带有mask的输入参数
query = key = value = pe_result
mask = Variable(torch.zeros(2, 4, 4))
attn, p_attn = attention(query, key, value, mask=mask)
# print("query的注意力表示:", attn) # size 2x4x512
# print("注意力张量:", p_attn) # size 2x4x4# 3.多头注意力机制
# 深拷贝
def clones(module, N):return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])class MultiHeadedAttention(nn.Module):def __init__(self, head, embedding_dim, dropout=0.1):super(MultiHeadedAttention, self).__init__()assert embedding_dim % head == 0self.d_k = embedding_dim // headself.head = head# 在多头注意力中,Q,K,V各需要一个,最后拼接的矩阵还需要一个,一共是4个self.linears = clones(nn.Linear(embedding_dim, embedding_dim), 4)self.attn = Noneself.dropout = nn.Dropout(p=dropout)def forward(self, query, key, value, mask=None):if mask is not None:mask = mask.unsqueeze(0)batch_size = query.size(0)query, key, value = [model(x).view(batch_size, -1, self.head, self.d_k).transpose(1, 2)for model, x in zip(self.linears, (query, key, value))]x, self.attn = attention(query, key, value, mask=mask, dropout=self.dropout)x = x.transpose(1, 2).contiguous().view(batch_size, -1, self.head * self.d_k)return self.linears[-1](x)head = 8
embedding_dim = 512
dropout = 0.2
query = value = key = pe_result
mask = Variable(torch.zeros(8, 4, 4))
mha = MultiHeadedAttention(head, embedding_dim, dropout)
mha_result = mha(query, key, value, mask)
# print(mha_result)# 4.前馈全连接层
class PositionwiseFeedForward(nn.Module):def __init__(self, d_model, d_ff, dropout=0.1):super(PositionwiseFeedForward, self).__init__()self.w1 = nn.Linear(d_model, d_ff)self.w2 = nn.Linear(d_ff, d_model)self.dropout = nn.Dropout(dropout)def forward(self, x):return self.w2(self.dropout(F.relu(self.w1(x))))d_model = 512
d_ff = 64
dropout = 0.2
x = mha_result
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
ff_result = ff(x)# 5.规范化层
# 通过LayerNorm实现规范化层的类
class LayerNorm(nn.Module):def __init__(self, features, eps=1e-6):super(LayerNorm, self).__init__()self.a2 = nn.Parameter(torch.ones(features))self.b2 = nn.Parameter(torch.zeros(features))self.eps = epsdef forward(self, x):mean = x.mean(-1, keepdim=True)std = x.std(-1, keepdim=True)return self.a2 * (x - mean) / (std + self.eps) + self.b2features = d_model = 512
eps = 1e-6
x = ff_result
ln = LayerNorm(features, eps)
ln_result = ln(x)# 6.残差连接
class SublayerConnection(nn.Module):def __init__(self, size, dropout=0.1):super(SublayerConnection, self).__init__()self.norm = LayerNorm(size)self.dropout = nn.Dropout(p=dropout)def forward(self, x, sublayer):return x + self.dropout(sublayer(self.norm(x)))size = 512
dropout = 0.2
head = 8
d_model = 512
x = pe_result
mask = Variable(torch.zeros(8, 4, 4))
self_attn = MultiHeadedAttention(head, d_model)
sublayer = lambda x: self_attn(x, x, x, mask)
sc = SublayerConnection(size, dropout)
sc_result = sc(x, sublayer)# 7.编码器层
class EncoderLayer(nn.Module):def __init__(self, size, self_attn, feed_forward, dropout):super(EncoderLayer, self).__init__()self.self_attn = self_attnself.feed_forward = feed_forwardself.sublayer = clones(SublayerConnection(size, dropout), 2)self.size = sizedef forward(self, x, mask):x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask))return self.sublayer[1](x, self.feed_forward)size = 512
head = 8
d_model = 512
d_ff = 64
x = pe_result
dropout = 0.2
self_attn = MultiHeadedAttention(head, d_model)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
mask = Variable(torch.zeros(8, 4, 4))
el = EncoderLayer(size, self_attn, ff, dropout)
el_result = el(x, mask)# 8.编码器
class Encoder(nn.Module):def __init__(self, layer, N):super(Encoder, self).__init__()self.layers = clones(layer, N)self.norm = LayerNorm(layer.size)def forward(self, x, mask):for layer in self.layers:x = layer(x, mask)return self.norm(x)size = 512
head = 8
d_model = 512
d_ff = 64
c = copy.deepcopy
attn = MultiHeadedAttention(head, d_model)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
dropout = 0.2
layer = EncoderLayer(size, c(attn), c(ff), dropout)
N = 8
mask = Variable(torch.zeros(8, 4, 4))
en = Encoder(layer, N)
en_result = en(x, mask)
print(en_result)
print(en_result.shape)
"""
tensor([[[-1.2431e-01, -2.3363e+00, 1.9084e-02, ..., -9.8174e-02,-2.0241e+00, -2.8970e-01],[-3.9608e-01, 5.2420e-02, 2.4076e-02, ..., -1.2182e-01,4.7777e-01, 4.0544e-01],[-6.3494e-01, -2.5631e-03, -1.7992e-01, ..., -5.5367e-02,-4.3454e-02, 1.0005e+00],[-8.5996e-01, 2.6673e+00, 9.2570e-01, ..., 6.2907e-01,3.7063e-01, 6.4456e-01]],[[ 3.3140e-01, 1.4327e+00, 4.1478e-02, ..., 4.5121e-01,-1.7026e+00, 8.7472e-01],[-2.5319e-01, 1.8512e+00, -3.0673e-02, ..., 7.9770e-02,1.1026e-01, -2.9194e-01],[ 1.3375e-01, -1.7779e-01, 2.6414e-03, ..., -5.6526e-01,6.5849e-01, 1.1001e+00],[ 1.5610e+00, -1.4482e+00, 2.5439e-01, ..., -5.4919e-01,-7.2307e-01, 1.4985e+00]]], grad_fn=<AddBackward0>)
torch.Size([2, 4, 512])
"""三、解码部分
- 由N个解码器层堆叠而成
- 每个解码器层由三个子层连接结构组成
- 第一个子层连接结构包括一个多头自注意力子层和规范化层以及一个残差连接
- 第二个子层连接结构包括一个多头注意力子层和规范化层以及一个残差连接
- 第三个子层连接结构包括一个前馈全连接子层和规范化层以及一个残差连接
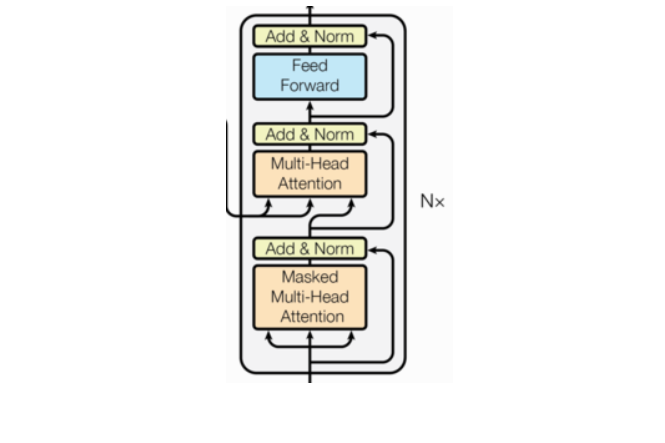
⭐10.编码器层
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
import math
import matplotlib.pyplot as plt
import numpy as np
import copy# 一、输入部分
# 1.文本嵌入层
class Embeddings(nn.Module):def __init__(self, d_model, vocab):super(Embeddings, self).__init__()self.lut = nn.Embedding(vocab, d_model)self.d_model = d_modeldef forward(self, x):return self.lut(x) * math.sqrt(self.d_model)# 2.位置编码器
class PositionalEncoding(nn.Module):def __init__(self, d_model, dropout, max_len=5000):super(PositionalEncoding, self).__init__()self.dropout = nn.Dropout(p=dropout)pe = torch.zeros(max_len, d_model)position = torch.arange(0, max_len).unsqueeze(1)div_term = torch.exp(torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model))pe[:, 0::2] = torch.sin(position * div_term)pe[:, 1::2] = torch.cos(position * div_term)pe = pe.unsqueeze(0)self.register_buffer('pe', pe)def forward(self, x):x = x + Variable(self.pe[:, :x.size(1)], requires_grad=False)return self.dropout(x)d_model = 512
dropout = 0.1
max_len = 60vocab = 1000
x = Variable(torch.LongTensor([[100, 2, 421, 508], [491, 998, 1, 221]]))
emb = Embeddings(d_model, vocab)
embr = emb(x)x = embr
pe = PositionalEncoding(d_model, dropout, max_len)
pe_result = pe(x)# 绘制词汇向量中特征的分布曲线
plt.figure(figsize=(15, 5)) # 创建一张15 x 5大小的画布
pe = PositionalEncoding(20, 0)
y = pe(Variable(torch.zeros(1, 100, 20)))
plt.plot(np.arange(100), y[0, :, 4:8].data.numpy())
plt.legend(["dim %d" % p for p in [4, 5, 6, 7]])# plt.show()# 二、编码器部分
# 1.掩码张量函数
def subsequent_mask(size):attn_shape = (1, size, size)subsequent_mask = np.triu(np.ones(attn_shape), k=1).astype('uint8')return torch.from_numpy(1 - subsequent_mask)# 掩码张量的可视化
plt.figure(figsize=(5, 5))
plt.imshow(subsequent_mask(20)[0])# plt.show()# 2.注意力机制
def attention(query, key, value, mask=None, dropout=None):d_k = query.size(-1)scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)if mask is not None:scores = scores.masked_fill(mask == 0, -1e9)p_attn = F.softmax(scores, dim=-1)if dropout is not None:p_attn = dropout(p_attn)return torch.matmul(p_attn, value), p_attnquery = key = value = pe_result
attn, p_attn = attention(query, key, value)
# print("query的注意力表示:", attn) # 2x4x512
# print("注意力张量:", p_attn) # size 2x4x4
#
# print("*****************************************************************")
# 带有mask的输入参数
query = key = value = pe_result
mask = Variable(torch.zeros(2, 4, 4))
attn, p_attn = attention(query, key, value, mask=mask)
# print("query的注意力表示:", attn) # size 2x4x512
# print("注意力张量:", p_attn) # size 2x4x4# 3.多头注意力机制
# 深拷贝
def clones(module, N):return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])class MultiHeadedAttention(nn.Module):def __init__(self, head, embedding_dim, dropout=0.1):super(MultiHeadedAttention, self).__init__()assert embedding_dim % head == 0self.d_k = embedding_dim // headself.head = head# 在多头注意力中,Q,K,V各需要一个,最后拼接的矩阵还需要一个,一共是4个self.linears = clones(nn.Linear(embedding_dim, embedding_dim), 4)self.attn = Noneself.dropout = nn.Dropout(p=dropout)def forward(self, query, key, value, mask=None):if mask is not None:mask = mask.unsqueeze(0)batch_size = query.size(0)query, key, value = [model(x).view(batch_size, -1, self.head, self.d_k).transpose(1, 2)for model, x in zip(self.linears, (query, key, value))]x, self.attn = attention(query, key, value, mask=mask, dropout=self.dropout)x = x.transpose(1, 2).contiguous().view(batch_size, -1, self.head * self.d_k)return self.linears[-1](x)head = 8
embedding_dim = 512
dropout = 0.2
query = value = key = pe_result
mask = Variable(torch.zeros(8, 4, 4))
mha = MultiHeadedAttention(head, embedding_dim, dropout)
mha_result = mha(query, key, value, mask)
# print(mha_result)# 4.前馈全连接层
class PositionwiseFeedForward(nn.Module):def __init__(self, d_model, d_ff, dropout=0.1):super(PositionwiseFeedForward, self).__init__()self.w1 = nn.Linear(d_model, d_ff)self.w2 = nn.Linear(d_ff, d_model)self.dropout = nn.Dropout(dropout)def forward(self, x):return self.w2(self.dropout(F.relu(self.w1(x))))d_model = 512
d_ff = 64
dropout = 0.2
x = mha_result
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
ff_result = ff(x)# 5.规范化层
# 通过LayerNorm实现规范化层的类
class LayerNorm(nn.Module):def __init__(self, features, eps=1e-6):super(LayerNorm, self).__init__()self.a2 = nn.Parameter(torch.ones(features))self.b2 = nn.Parameter(torch.zeros(features))self.eps = epsdef forward(self, x):mean = x.mean(-1, keepdim=True)std = x.std(-1, keepdim=True)return self.a2 * (x - mean) / (std + self.eps) + self.b2features = d_model = 512
eps = 1e-6
x = ff_result
ln = LayerNorm(features, eps)
ln_result = ln(x)# 6.残差连接
class SublayerConnection(nn.Module):def __init__(self, size, dropout=0.1):super(SublayerConnection, self).__init__()self.norm = LayerNorm(size)self.dropout = nn.Dropout(p=dropout)def forward(self, x, sublayer):return x + self.dropout(sublayer(self.norm(x)))size = 512
dropout = 0.2
head = 8
d_model = 512
x = pe_result
mask = Variable(torch.zeros(8, 4, 4))
self_attn = MultiHeadedAttention(head, d_model)
sublayer = lambda x: self_attn(x, x, x, mask)
sc = SublayerConnection(size, dropout)
sc_result = sc(x, sublayer)# 7.编码器层
class EncoderLayer(nn.Module):def __init__(self, size, self_attn, feed_forward, dropout):super(EncoderLayer, self).__init__()self.self_attn = self_attnself.feed_forward = feed_forwardself.sublayer = clones(SublayerConnection(size, dropout), 2)self.size = sizedef forward(self, x, mask):x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask))return self.sublayer[1](x, self.feed_forward)size = 512
head = 8
d_model = 512
d_ff = 64
x = pe_result
dropout = 0.2
self_attn = MultiHeadedAttention(head, d_model)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
mask = Variable(torch.zeros(8, 4, 4))
el = EncoderLayer(size, self_attn, ff, dropout)
el_result = el(x, mask)# 8.编码器
class Encoder(nn.Module):def __init__(self, layer, N):super(Encoder, self).__init__()self.layers = clones(layer, N)self.norm = LayerNorm(layer.size)def forward(self, x, mask):for layer in self.layers:x = layer(x, mask)return self.norm(x)size = 512
head = 8
d_model = 512
d_ff = 64
c = copy.deepcopy
attn = MultiHeadedAttention(head, d_model)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
dropout = 0.2
layer = EncoderLayer(size, c(attn), c(ff), dropout)
N = 8
mask = Variable(torch.zeros(8, 4, 4))
en = Encoder(layer, N)
en_result = en(x, mask)
print(en_result)
print(en_result.shape)
"""
tensor([[[-1.2431e-01, -2.3363e+00, 1.9084e-02, ..., -9.8174e-02,-2.0241e+00, -2.8970e-01],[-3.9608e-01, 5.2420e-02, 2.4076e-02, ..., -1.2182e-01,4.7777e-01, 4.0544e-01],[-6.3494e-01, -2.5631e-03, -1.7992e-01, ..., -5.5367e-02,-4.3454e-02, 1.0005e+00],[-8.5996e-01, 2.6673e+00, 9.2570e-01, ..., 6.2907e-01,3.7063e-01, 6.4456e-01]],[[ 3.3140e-01, 1.4327e+00, 4.1478e-02, ..., 4.5121e-01,-1.7026e+00, 8.7472e-01],[-2.5319e-01, 1.8512e+00, -3.0673e-02, ..., 7.9770e-02,1.1026e-01, -2.9194e-01],[ 1.3375e-01, -1.7779e-01, 2.6414e-03, ..., -5.6526e-01,6.5849e-01, 1.1001e+00],[ 1.5610e+00, -1.4482e+00, 2.5439e-01, ..., -5.4919e-01,-7.2307e-01, 1.4985e+00]]], grad_fn=<AddBackward0>)
torch.Size([2, 4, 512])
"""# 三、解码器部分
# 1.解码器层
class DecoderLayer(nn.Module):def __init__(self, size, self_attn, src_attn, feed_forward, dropout):super(DecoderLayer, self).__init__()self.size = sizeself.self_attn = self_attnself.src_attn = src_attnself.feed_forward = feed_forwardself.sublayer = clones(SublayerConnection(size, dropout), 3)def forward(self, x, memory, source_mask, target_mask):m = memoryx = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, target_mask))x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, source_mask))return self.sublayer[2](x, self.feed_forward)head = 8
size = 512
d_model = 512
d_ff = 64
dropout = 0.2
self_attn = src_attn = MultiHeadedAttention(head, d_model, dropout)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
x = pe_result
memory = en_result
mask = Variable(torch.zeros(8, 4, 4))
source_mask = target_mask = mask
dl = DecoderLayer(size, self_attn, src_attn, ff, dropout)
dl_result = dl(x, memory, source_mask, target_mask)
print(dl_result)
print(dl_result.shape)
"""
tensor([[[ 1.9604e+00, 3.9288e+01, -5.2422e+01, ..., 2.1041e-01,-5.5063e+01, 1.5233e-01],[ 1.0135e-01, -3.7779e-01, 6.5491e+01, ..., 2.8062e+01,-3.7780e+01, -3.9577e+01],[ 1.9526e+01, -2.5741e+01, 2.6926e-01, ..., -1.5316e+01,1.4543e+00, 2.7714e+00],[-2.1528e+01, 2.0141e+01, 2.1999e+01, ..., 2.2099e+00,-1.7267e+01, -1.6687e+01]],[[ 6.7259e+00, -2.6918e+01, 1.1807e+01, ..., -3.6453e+01,-2.9231e+01, 1.1288e+01],[ 7.7484e+01, -5.0572e-01, -1.3096e+01, ..., 3.6302e-01,1.9907e+01, -1.2160e+00],[ 2.6703e+01, 4.4737e+01, -3.1590e+01, ..., 4.1540e-03,5.2587e+00, 5.2382e+00],[ 4.7435e+01, -3.7599e-01, 5.0898e+01, ..., 5.6361e+00,3.5891e+01, 1.5697e+01]]], grad_fn=<AddBackward0>)
torch.Size([2, 4, 512])
"""⭐11.编码器
根据编码器的结果以及上一次预测的结果, 对下一次可能出现的'值'进行特征表示
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
import math
import matplotlib.pyplot as plt
import numpy as np
import copy# 一、输入部分
# 1.文本嵌入层
class Embeddings(nn.Module):def __init__(self, d_model, vocab):super(Embeddings, self).__init__()self.lut = nn.Embedding(vocab, d_model)self.d_model = d_modeldef forward(self, x):return self.lut(x) * math.sqrt(self.d_model)# 2.位置编码器
class PositionalEncoding(nn.Module):def __init__(self, d_model, dropout, max_len=5000):super(PositionalEncoding, self).__init__()self.dropout = nn.Dropout(p=dropout)pe = torch.zeros(max_len, d_model)position = torch.arange(0, max_len).unsqueeze(1)div_term = torch.exp(torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model))pe[:, 0::2] = torch.sin(position * div_term)pe[:, 1::2] = torch.cos(position * div_term)pe = pe.unsqueeze(0)self.register_buffer('pe', pe)def forward(self, x):x = x + Variable(self.pe[:, :x.size(1)], requires_grad=False)return self.dropout(x)d_model = 512
dropout = 0.1
max_len = 60vocab = 1000
x = Variable(torch.LongTensor([[100, 2, 421, 508], [491, 998, 1, 221]]))
emb = Embeddings(d_model, vocab)
embr = emb(x)x = embr
pe = PositionalEncoding(d_model, dropout, max_len)
pe_result = pe(x)# 绘制词汇向量中特征的分布曲线
plt.figure(figsize=(15, 5)) # 创建一张15 x 5大小的画布
pe = PositionalEncoding(20, 0)
y = pe(Variable(torch.zeros(1, 100, 20)))
plt.plot(np.arange(100), y[0, :, 4:8].data.numpy())
plt.legend(["dim %d" % p for p in [4, 5, 6, 7]])# plt.show()# 二、编码器部分
# 1.掩码张量函数
def subsequent_mask(size):attn_shape = (1, size, size)subsequent_mask = np.triu(np.ones(attn_shape), k=1).astype('uint8')return torch.from_numpy(1 - subsequent_mask)# 掩码张量的可视化
plt.figure(figsize=(5, 5))
plt.imshow(subsequent_mask(20)[0])# plt.show()# 2.注意力机制
def attention(query, key, value, mask=None, dropout=None):d_k = query.size(-1)scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)if mask is not None:scores = scores.masked_fill(mask == 0, -1e9)p_attn = F.softmax(scores, dim=-1)if dropout is not None:p_attn = dropout(p_attn)return torch.matmul(p_attn, value), p_attnquery = key = value = pe_result
attn, p_attn = attention(query, key, value)
# print("query的注意力表示:", attn) # 2x4x512
# print("注意力张量:", p_attn) # size 2x4x4
#
# print("*****************************************************************")
# 带有mask的输入参数
query = key = value = pe_result
mask = Variable(torch.zeros(2, 4, 4))
attn, p_attn = attention(query, key, value, mask=mask)
# print("query的注意力表示:", attn) # size 2x4x512
# print("注意力张量:", p_attn) # size 2x4x4# 3.多头注意力机制
# 深拷贝
def clones(module, N):return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])class MultiHeadedAttention(nn.Module):def __init__(self, head, embedding_dim, dropout=0.1):super(MultiHeadedAttention, self).__init__()assert embedding_dim % head == 0self.d_k = embedding_dim // headself.head = head# 在多头注意力中,Q,K,V各需要一个,最后拼接的矩阵还需要一个,一共是4个self.linears = clones(nn.Linear(embedding_dim, embedding_dim), 4)self.attn = Noneself.dropout = nn.Dropout(p=dropout)def forward(self, query, key, value, mask=None):if mask is not None:mask = mask.unsqueeze(0)batch_size = query.size(0)query, key, value = [model(x).view(batch_size, -1, self.head, self.d_k).transpose(1, 2)for model, x in zip(self.linears, (query, key, value))]x, self.attn = attention(query, key, value, mask=mask, dropout=self.dropout)x = x.transpose(1, 2).contiguous().view(batch_size, -1, self.head * self.d_k)return self.linears[-1](x)head = 8
embedding_dim = 512
dropout = 0.2
query = value = key = pe_result
mask = Variable(torch.zeros(8, 4, 4))
mha = MultiHeadedAttention(head, embedding_dim, dropout)
mha_result = mha(query, key, value, mask)
# print(mha_result)# 4.前馈全连接层
class PositionwiseFeedForward(nn.Module):def __init__(self, d_model, d_ff, dropout=0.1):super(PositionwiseFeedForward, self).__init__()self.w1 = nn.Linear(d_model, d_ff)self.w2 = nn.Linear(d_ff, d_model)self.dropout = nn.Dropout(dropout)def forward(self, x):return self.w2(self.dropout(F.relu(self.w1(x))))d_model = 512
d_ff = 64
dropout = 0.2
x = mha_result
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
ff_result = ff(x)# 5.规范化层
# 通过LayerNorm实现规范化层的类
class LayerNorm(nn.Module):def __init__(self, features, eps=1e-6):super(LayerNorm, self).__init__()self.a2 = nn.Parameter(torch.ones(features))self.b2 = nn.Parameter(torch.zeros(features))self.eps = epsdef forward(self, x):mean = x.mean(-1, keepdim=True)std = x.std(-1, keepdim=True)return self.a2 * (x - mean) / (std + self.eps) + self.b2features = d_model = 512
eps = 1e-6
x = ff_result
ln = LayerNorm(features, eps)
ln_result = ln(x)# 6.残差连接
class SublayerConnection(nn.Module):def __init__(self, size, dropout=0.1):super(SublayerConnection, self).__init__()self.norm = LayerNorm(size)self.dropout = nn.Dropout(p=dropout)def forward(self, x, sublayer):return x + self.dropout(sublayer(self.norm(x)))size = 512
dropout = 0.2
head = 8
d_model = 512
x = pe_result
mask = Variable(torch.zeros(8, 4, 4))
self_attn = MultiHeadedAttention(head, d_model)
sublayer = lambda x: self_attn(x, x, x, mask)
sc = SublayerConnection(size, dropout)
sc_result = sc(x, sublayer)# 7.编码器层
class EncoderLayer(nn.Module):def __init__(self, size, self_attn, feed_forward, dropout):super(EncoderLayer, self).__init__()self.self_attn = self_attnself.feed_forward = feed_forwardself.sublayer = clones(SublayerConnection(size, dropout), 2)self.size = sizedef forward(self, x, mask):x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask))return self.sublayer[1](x, self.feed_forward)size = 512
head = 8
d_model = 512
d_ff = 64
x = pe_result
dropout = 0.2
self_attn = MultiHeadedAttention(head, d_model)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
mask = Variable(torch.zeros(8, 4, 4))
el = EncoderLayer(size, self_attn, ff, dropout)
el_result = el(x, mask)# 8.编码器
class Encoder(nn.Module):def __init__(self, layer, N):super(Encoder, self).__init__()self.layers = clones(layer, N)self.norm = LayerNorm(layer.size)def forward(self, x, mask):for layer in self.layers:x = layer(x, mask)return self.norm(x)size = 512
head = 8
d_model = 512
d_ff = 64
c = copy.deepcopy
attn = MultiHeadedAttention(head, d_model)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
dropout = 0.2
layer = EncoderLayer(size, c(attn), c(ff), dropout)
N = 8
mask = Variable(torch.zeros(8, 4, 4))
en = Encoder(layer, N)
en_result = en(x, mask)
# print(en_result)
# print(en_result.shape)
"""
tensor([[[-1.2431e-01, -2.3363e+00, 1.9084e-02, ..., -9.8174e-02,-2.0241e+00, -2.8970e-01],[-3.9608e-01, 5.2420e-02, 2.4076e-02, ..., -1.2182e-01,4.7777e-01, 4.0544e-01],[-6.3494e-01, -2.5631e-03, -1.7992e-01, ..., -5.5367e-02,-4.3454e-02, 1.0005e+00],[-8.5996e-01, 2.6673e+00, 9.2570e-01, ..., 6.2907e-01,3.7063e-01, 6.4456e-01]],[[ 3.3140e-01, 1.4327e+00, 4.1478e-02, ..., 4.5121e-01,-1.7026e+00, 8.7472e-01],[-2.5319e-01, 1.8512e+00, -3.0673e-02, ..., 7.9770e-02,1.1026e-01, -2.9194e-01],[ 1.3375e-01, -1.7779e-01, 2.6414e-03, ..., -5.6526e-01,6.5849e-01, 1.1001e+00],[ 1.5610e+00, -1.4482e+00, 2.5439e-01, ..., -5.4919e-01,-7.2307e-01, 1.4985e+00]]], grad_fn=<AddBackward0>)
torch.Size([2, 4, 512])
"""# 三、解码器部分
# 1.解码器层
class DecoderLayer(nn.Module):def __init__(self, size, self_attn, src_attn, feed_forward, dropout):super(DecoderLayer, self).__init__()self.size = sizeself.self_attn = self_attnself.src_attn = src_attnself.feed_forward = feed_forwardself.sublayer = clones(SublayerConnection(size, dropout), 3)def forward(self, x, memory, source_mask, target_mask):m = memoryx = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, target_mask))x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, source_mask))return self.sublayer[2](x, self.feed_forward)head = 8
size = 512
d_model = 512
d_ff = 64
dropout = 0.2
self_attn = src_attn = MultiHeadedAttention(head, d_model, dropout)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
x = pe_result
memory = en_result
mask = Variable(torch.zeros(8, 4, 4))
source_mask = target_mask = mask
dl = DecoderLayer(size, self_attn, src_attn, ff, dropout)
dl_result = dl(x, memory, source_mask, target_mask)
# print(dl_result)
# print(dl_result.shape)
"""
tensor([[[ 1.9604e+00, 3.9288e+01, -5.2422e+01, ..., 2.1041e-01,-5.5063e+01, 1.5233e-01],[ 1.0135e-01, -3.7779e-01, 6.5491e+01, ..., 2.8062e+01,-3.7780e+01, -3.9577e+01],[ 1.9526e+01, -2.5741e+01, 2.6926e-01, ..., -1.5316e+01,1.4543e+00, 2.7714e+00],[-2.1528e+01, 2.0141e+01, 2.1999e+01, ..., 2.2099e+00,-1.7267e+01, -1.6687e+01]],[[ 6.7259e+00, -2.6918e+01, 1.1807e+01, ..., -3.6453e+01,-2.9231e+01, 1.1288e+01],[ 7.7484e+01, -5.0572e-01, -1.3096e+01, ..., 3.6302e-01,1.9907e+01, -1.2160e+00],[ 2.6703e+01, 4.4737e+01, -3.1590e+01, ..., 4.1540e-03,5.2587e+00, 5.2382e+00],[ 4.7435e+01, -3.7599e-01, 5.0898e+01, ..., 5.6361e+00,3.5891e+01, 1.5697e+01]]], grad_fn=<AddBackward0>)
torch.Size([2, 4, 512])
"""# 2.解码器
class Decoder(nn.Module):def __init__(self, layer, N):super(Decoder, self).__init__()self.layers = clones(layer, N)self.norm = LayerNorm(layer.size)def forward(self, x, memory, source_mask, target_mask):for layer in self.layers:x = layer(x, memory, source_mask, target_mask)return self.norm(x)size = 512
d_model = 512
head = 8
d_ff = 64
dropout = 0.2
c = copy.deepcopy
attn = MultiHeadedAttention(head, d_model)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
layer = DecoderLayer(d_model, c(attn), c(attn), c(ff), dropout)
N = 8
x = pe_result
memory = en_result
mask = Variable(torch.zeros(8, 4, 4))
source_mask = target_mask = mask
de = Decoder(layer, N)
de_result = de(x, memory, source_mask, target_mask)
print(de_result)
print(de_result.shape)
"""
tensor([[[ 0.2436, 0.8310, 1.1406, ..., 1.2474, 1.0660, -0.7125],[ 0.8292, -0.1330, -0.2391, ..., -1.0578, -0.8154, 1.4003],[ 0.8909, 0.1255, 0.9115, ..., 0.0775, 0.0753, 0.3909],[-1.9148, 0.2801, 1.7520, ..., -0.7988, -2.0647, -0.5999]],[[ 0.9265, 0.5207, -1.8971, ..., -2.2877, 0.1123, 0.2563],[ 0.8011, 1.0716, -0.0627, ..., -1.2644, 1.6997, 0.8083],[-0.6971, -1.6886, -0.7169, ..., 1.0697, -1.0679, 0.8851],[-0.9620, -0.2029, 1.2966, ..., -0.3927, 1.6059, 1.6047]]],grad_fn=<AddBackward0>)
torch.Size([2, 4, 512])
"""四、输出部分
- 线性层
- softmax层
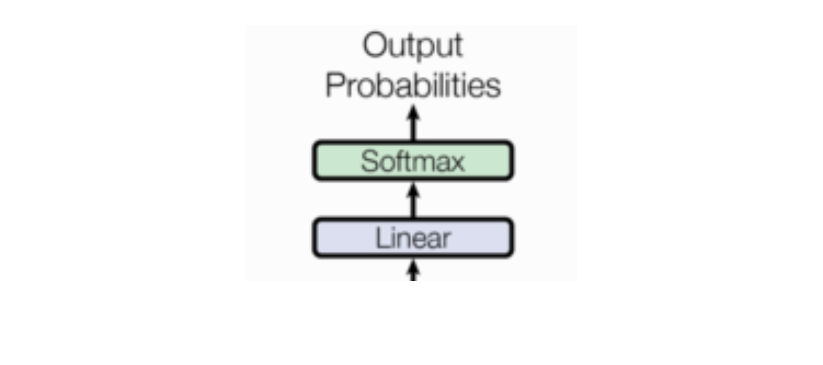
nn.Linear演示
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
import math
import matplotlib.pyplot as plt
import numpy as np
import copym = nn.Linear(20, 30)
input = torch.randn(128, 20)
output = m(input)
print(output.size())# torch.Size([128, 30])⭐12.线性层和softmax层
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
import math
import matplotlib.pyplot as plt
import numpy as np
import copy# 一、输入部分
# 1.文本嵌入层
class Embeddings(nn.Module):def __init__(self, d_model, vocab):super(Embeddings, self).__init__()self.lut = nn.Embedding(vocab, d_model)self.d_model = d_modeldef forward(self, x):return self.lut(x) * math.sqrt(self.d_model)# 2.位置编码器
class PositionalEncoding(nn.Module):def __init__(self, d_model, dropout, max_len=5000):super(PositionalEncoding, self).__init__()self.dropout = nn.Dropout(p=dropout)pe = torch.zeros(max_len, d_model)position = torch.arange(0, max_len).unsqueeze(1)div_term = torch.exp(torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model))pe[:, 0::2] = torch.sin(position * div_term)pe[:, 1::2] = torch.cos(position * div_term)pe = pe.unsqueeze(0)self.register_buffer('pe', pe)def forward(self, x):x = x + Variable(self.pe[:, :x.size(1)], requires_grad=False)return self.dropout(x)d_model = 512
dropout = 0.1
max_len = 60vocab = 1000
x = Variable(torch.LongTensor([[100, 2, 421, 508], [491, 998, 1, 221]]))
emb = Embeddings(d_model, vocab)
embr = emb(x)x = embr
pe = PositionalEncoding(d_model, dropout, max_len)
pe_result = pe(x)# 绘制词汇向量中特征的分布曲线
plt.figure(figsize=(15, 5)) # 创建一张15 x 5大小的画布
pe = PositionalEncoding(20, 0)
y = pe(Variable(torch.zeros(1, 100, 20)))
plt.plot(np.arange(100), y[0, :, 4:8].data.numpy())
plt.legend(["dim %d" % p for p in [4, 5, 6, 7]])# plt.show()# 二、编码器部分
# 1.掩码张量函数
def subsequent_mask(size):attn_shape = (1, size, size)subsequent_mask = np.triu(np.ones(attn_shape), k=1).astype('uint8')return torch.from_numpy(1 - subsequent_mask)# 掩码张量的可视化
plt.figure(figsize=(5, 5))
plt.imshow(subsequent_mask(20)[0])# plt.show()# 2.注意力机制
def attention(query, key, value, mask=None, dropout=None):d_k = query.size(-1)scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)if mask is not None:scores = scores.masked_fill(mask == 0, -1e9)p_attn = F.softmax(scores, dim=-1)if dropout is not None:p_attn = dropout(p_attn)return torch.matmul(p_attn, value), p_attnquery = key = value = pe_result
attn, p_attn = attention(query, key, value)
# print("query的注意力表示:", attn) # 2x4x512
# print("注意力张量:", p_attn) # size 2x4x4
#
# print("*****************************************************************")
# 带有mask的输入参数
query = key = value = pe_result
mask = Variable(torch.zeros(2, 4, 4))
attn, p_attn = attention(query, key, value, mask=mask)
# print("query的注意力表示:", attn) # size 2x4x512
# print("注意力张量:", p_attn) # size 2x4x4# 3.多头注意力机制
# 深拷贝
def clones(module, N):return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])class MultiHeadedAttention(nn.Module):def __init__(self, head, embedding_dim, dropout=0.1):super(MultiHeadedAttention, self).__init__()assert embedding_dim % head == 0self.d_k = embedding_dim // headself.head = head# 在多头注意力中,Q,K,V各需要一个,最后拼接的矩阵还需要一个,一共是4个self.linears = clones(nn.Linear(embedding_dim, embedding_dim), 4)self.attn = Noneself.dropout = nn.Dropout(p=dropout)def forward(self, query, key, value, mask=None):if mask is not None:mask = mask.unsqueeze(0)batch_size = query.size(0)query, key, value = [model(x).view(batch_size, -1, self.head, self.d_k).transpose(1, 2)for model, x in zip(self.linears, (query, key, value))]x, self.attn = attention(query, key, value, mask=mask, dropout=self.dropout)x = x.transpose(1, 2).contiguous().view(batch_size, -1, self.head * self.d_k)return self.linears[-1](x)head = 8
embedding_dim = 512
dropout = 0.2
query = value = key = pe_result
mask = Variable(torch.zeros(8, 4, 4))
mha = MultiHeadedAttention(head, embedding_dim, dropout)
mha_result = mha(query, key, value, mask)
# print(mha_result)# 4.前馈全连接层
class PositionwiseFeedForward(nn.Module):def __init__(self, d_model, d_ff, dropout=0.1):super(PositionwiseFeedForward, self).__init__()self.w1 = nn.Linear(d_model, d_ff)self.w2 = nn.Linear(d_ff, d_model)self.dropout = nn.Dropout(dropout)def forward(self, x):return self.w2(self.dropout(F.relu(self.w1(x))))d_model = 512
d_ff = 64
dropout = 0.2
x = mha_result
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
ff_result = ff(x)# 5.规范化层
# 通过LayerNorm实现规范化层的类
class LayerNorm(nn.Module):def __init__(self, features, eps=1e-6):super(LayerNorm, self).__init__()self.a2 = nn.Parameter(torch.ones(features))self.b2 = nn.Parameter(torch.zeros(features))self.eps = epsdef forward(self, x):mean = x.mean(-1, keepdim=True)std = x.std(-1, keepdim=True)return self.a2 * (x - mean) / (std + self.eps) + self.b2features = d_model = 512
eps = 1e-6
x = ff_result
ln = LayerNorm(features, eps)
ln_result = ln(x)# 6.残差连接
class SublayerConnection(nn.Module):def __init__(self, size, dropout=0.1):super(SublayerConnection, self).__init__()self.norm = LayerNorm(size)self.dropout = nn.Dropout(p=dropout)def forward(self, x, sublayer):return x + self.dropout(sublayer(self.norm(x)))size = 512
dropout = 0.2
head = 8
d_model = 512
x = pe_result
mask = Variable(torch.zeros(8, 4, 4))
self_attn = MultiHeadedAttention(head, d_model)
sublayer = lambda x: self_attn(x, x, x, mask)
sc = SublayerConnection(size, dropout)
sc_result = sc(x, sublayer)# 7.编码器层
class EncoderLayer(nn.Module):def __init__(self, size, self_attn, feed_forward, dropout):super(EncoderLayer, self).__init__()self.self_attn = self_attnself.feed_forward = feed_forwardself.sublayer = clones(SublayerConnection(size, dropout), 2)self.size = sizedef forward(self, x, mask):x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask))return self.sublayer[1](x, self.feed_forward)size = 512
head = 8
d_model = 512
d_ff = 64
x = pe_result
dropout = 0.2
self_attn = MultiHeadedAttention(head, d_model)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
mask = Variable(torch.zeros(8, 4, 4))
el = EncoderLayer(size, self_attn, ff, dropout)
el_result = el(x, mask)# 8.编码器
class Encoder(nn.Module):def __init__(self, layer, N):super(Encoder, self).__init__()self.layers = clones(layer, N)self.norm = LayerNorm(layer.size)def forward(self, x, mask):for layer in self.layers:x = layer(x, mask)return self.norm(x)size = 512
head = 8
d_model = 512
d_ff = 64
c = copy.deepcopy
attn = MultiHeadedAttention(head, d_model)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
dropout = 0.2
layer = EncoderLayer(size, c(attn), c(ff), dropout)
N = 8
mask = Variable(torch.zeros(8, 4, 4))
en = Encoder(layer, N)
en_result = en(x, mask)
# print(en_result)
# print(en_result.shape)
"""
tensor([[[-1.2431e-01, -2.3363e+00, 1.9084e-02, ..., -9.8174e-02,-2.0241e+00, -2.8970e-01],[-3.9608e-01, 5.2420e-02, 2.4076e-02, ..., -1.2182e-01,4.7777e-01, 4.0544e-01],[-6.3494e-01, -2.5631e-03, -1.7992e-01, ..., -5.5367e-02,-4.3454e-02, 1.0005e+00],[-8.5996e-01, 2.6673e+00, 9.2570e-01, ..., 6.2907e-01,3.7063e-01, 6.4456e-01]],[[ 3.3140e-01, 1.4327e+00, 4.1478e-02, ..., 4.5121e-01,-1.7026e+00, 8.7472e-01],[-2.5319e-01, 1.8512e+00, -3.0673e-02, ..., 7.9770e-02,1.1026e-01, -2.9194e-01],[ 1.3375e-01, -1.7779e-01, 2.6414e-03, ..., -5.6526e-01,6.5849e-01, 1.1001e+00],[ 1.5610e+00, -1.4482e+00, 2.5439e-01, ..., -5.4919e-01,-7.2307e-01, 1.4985e+00]]], grad_fn=<AddBackward0>)
torch.Size([2, 4, 512])
"""# 三、解码器部分
# 1.解码器层
class DecoderLayer(nn.Module):def __init__(self, size, self_attn, src_attn, feed_forward, dropout):super(DecoderLayer, self).__init__()self.size = sizeself.self_attn = self_attnself.src_attn = src_attnself.feed_forward = feed_forwardself.sublayer = clones(SublayerConnection(size, dropout), 3)def forward(self, x, memory, source_mask, target_mask):m = memoryx = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, target_mask))x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, source_mask))return self.sublayer[2](x, self.feed_forward)head = 8
size = 512
d_model = 512
d_ff = 64
dropout = 0.2
self_attn = src_attn = MultiHeadedAttention(head, d_model, dropout)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
x = pe_result
memory = en_result
mask = Variable(torch.zeros(8, 4, 4))
source_mask = target_mask = mask
dl = DecoderLayer(size, self_attn, src_attn, ff, dropout)
dl_result = dl(x, memory, source_mask, target_mask)
# print(dl_result)
# print(dl_result.shape)
"""
tensor([[[ 1.9604e+00, 3.9288e+01, -5.2422e+01, ..., 2.1041e-01,-5.5063e+01, 1.5233e-01],[ 1.0135e-01, -3.7779e-01, 6.5491e+01, ..., 2.8062e+01,-3.7780e+01, -3.9577e+01],[ 1.9526e+01, -2.5741e+01, 2.6926e-01, ..., -1.5316e+01,1.4543e+00, 2.7714e+00],[-2.1528e+01, 2.0141e+01, 2.1999e+01, ..., 2.2099e+00,-1.7267e+01, -1.6687e+01]],[[ 6.7259e+00, -2.6918e+01, 1.1807e+01, ..., -3.6453e+01,-2.9231e+01, 1.1288e+01],[ 7.7484e+01, -5.0572e-01, -1.3096e+01, ..., 3.6302e-01,1.9907e+01, -1.2160e+00],[ 2.6703e+01, 4.4737e+01, -3.1590e+01, ..., 4.1540e-03,5.2587e+00, 5.2382e+00],[ 4.7435e+01, -3.7599e-01, 5.0898e+01, ..., 5.6361e+00,3.5891e+01, 1.5697e+01]]], grad_fn=<AddBackward0>)
torch.Size([2, 4, 512])
"""# 2.解码器
class Decoder(nn.Module):def __init__(self, layer, N):super(Decoder, self).__init__()self.layers = clones(layer, N)self.norm = LayerNorm(layer.size)def forward(self, x, memory, source_mask, target_mask):for layer in self.layers:x = layer(x, memory, source_mask, target_mask)return self.norm(x)size = 512
d_model = 512
head = 8
d_ff = 64
dropout = 0.2
c = copy.deepcopy
attn = MultiHeadedAttention(head, d_model)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
layer = DecoderLayer(d_model, c(attn), c(attn), c(ff), dropout)
N = 8
x = pe_result
memory = en_result
mask = Variable(torch.zeros(8, 4, 4))
source_mask = target_mask = mask
de = Decoder(layer, N)
de_result = de(x, memory, source_mask, target_mask)
# print(de_result)
# print(de_result.shape)
"""
tensor([[[ 0.2436, 0.8310, 1.1406, ..., 1.2474, 1.0660, -0.7125],[ 0.8292, -0.1330, -0.2391, ..., -1.0578, -0.8154, 1.4003],[ 0.8909, 0.1255, 0.9115, ..., 0.0775, 0.0753, 0.3909],[-1.9148, 0.2801, 1.7520, ..., -0.7988, -2.0647, -0.5999]],[[ 0.9265, 0.5207, -1.8971, ..., -2.2877, 0.1123, 0.2563],[ 0.8011, 1.0716, -0.0627, ..., -1.2644, 1.6997, 0.8083],[-0.6971, -1.6886, -0.7169, ..., 1.0697, -1.0679, 0.8851],[-0.9620, -0.2029, 1.2966, ..., -0.3927, 1.6059, 1.6047]]],grad_fn=<AddBackward0>)
torch.Size([2, 4, 512])
"""# 四、输出部分
# 线性层和softmax层一起实现, 因为二者的共同目标是生成最后的结构
# 因此把类的名字叫做Generator
class Generator(nn.Module):def __init__(self, d_model, vocab_size):super(Generator, self).__init__()self.project = nn.Linear(d_model, vocab_size)def forward(self, x):return F.log_softmax(self.project(x), dim=-1)d_model = 512
vocab_size = 1000
x = de_result
gen = Generator(d_model, vocab_size)
gen_result = gen(x)
print(gen_result)
print(gen_result.shape)
"""
tensor([[[-7.0677, -6.3155, -6.8694, ..., -6.8623, -6.4482, -7.2010],[-7.8073, -7.6669, -6.3424, ..., -7.0006, -6.8322, -6.1138],[-9.0578, -7.1061, -6.2095, ..., -7.3074, -7.2882, -7.3483],[-8.1861, -7.2428, -6.7725, ..., -6.8366, -7.3286, -6.8935]],[[-7.3694, -6.7055, -6.8839, ..., -6.7879, -6.8398, -7.0582],[-6.5527, -6.8104, -7.6633, ..., -8.0519, -7.0640, -6.3101],[-8.4895, -7.9180, -6.4888, ..., -6.7811, -5.6739, -6.5447],[-6.2718, -7.3904, -7.8301, ..., -6.6355, -5.7487, -8.1378]]],grad_fn=<LogSoftmaxBackward0>)
torch.Size([2, 4, 1000])
"""五、完整代码
13.编码器-解码器
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
import math
import matplotlib.pyplot as plt
import numpy as np
import copy# 一、输入部分
# 1.文本嵌入层
class Embeddings(nn.Module):def __init__(self, d_model, vocab):super(Embeddings, self).__init__()self.lut = nn.Embedding(vocab, d_model)self.d_model = d_modeldef forward(self, x):return self.lut(x) * math.sqrt(self.d_model)# 2.位置编码器
class PositionalEncoding(nn.Module):def __init__(self, d_model, dropout, max_len=5000):super(PositionalEncoding, self).__init__()self.dropout = nn.Dropout(p=dropout)pe = torch.zeros(max_len, d_model)position = torch.arange(0, max_len).unsqueeze(1)div_term = torch.exp(torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model))pe[:, 0::2] = torch.sin(position * div_term)pe[:, 1::2] = torch.cos(position * div_term)pe = pe.unsqueeze(0)self.register_buffer('pe', pe)def forward(self, x):x = x + Variable(self.pe[:, :x.size(1)], requires_grad=False)return self.dropout(x)d_model = 512
dropout = 0.1
max_len = 60vocab = 1000
x = Variable(torch.LongTensor([[100, 2, 421, 508], [491, 998, 1, 221]]))
emb = Embeddings(d_model, vocab)
embr = emb(x)x = embr
pe = PositionalEncoding(d_model, dropout, max_len)
pe_result = pe(x)# 绘制词汇向量中特征的分布曲线
plt.figure(figsize=(15, 5)) # 创建一张15 x 5大小的画布
pe = PositionalEncoding(20, 0)
y = pe(Variable(torch.zeros(1, 100, 20)))
plt.plot(np.arange(100), y[0, :, 4:8].data.numpy())
plt.legend(["dim %d" % p for p in [4, 5, 6, 7]])# plt.show()# 二、编码器部分
# 1.掩码张量函数
def subsequent_mask(size):attn_shape = (1, size, size)subsequent_mask = np.triu(np.ones(attn_shape), k=1).astype('uint8')return torch.from_numpy(1 - subsequent_mask)# 掩码张量的可视化
plt.figure(figsize=(5, 5))
plt.imshow(subsequent_mask(20)[0])# plt.show()# 2.注意力机制
def attention(query, key, value, mask=None, dropout=None):d_k = query.size(-1)scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)if mask is not None:scores = scores.masked_fill(mask == 0, -1e9)p_attn = F.softmax(scores, dim=-1)if dropout is not None:p_attn = dropout(p_attn)return torch.matmul(p_attn, value), p_attnquery = key = value = pe_result
attn, p_attn = attention(query, key, value)
# print("query的注意力表示:", attn) # 2x4x512
# print("注意力张量:", p_attn) # size 2x4x4
#
# print("*****************************************************************")
# 带有mask的输入参数
query = key = value = pe_result
mask = Variable(torch.zeros(2, 4, 4))
attn, p_attn = attention(query, key, value, mask=mask)
# print("query的注意力表示:", attn) # size 2x4x512
# print("注意力张量:", p_attn) # size 2x4x4# 3.多头注意力机制
# 深拷贝
def clones(module, N):return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])class MultiHeadedAttention(nn.Module):def __init__(self, head, embedding_dim, dropout=0.1):super(MultiHeadedAttention, self).__init__()assert embedding_dim % head == 0self.d_k = embedding_dim // headself.head = head# 在多头注意力中,Q,K,V各需要一个,最后拼接的矩阵还需要一个,一共是4个self.linears = clones(nn.Linear(embedding_dim, embedding_dim), 4)self.attn = Noneself.dropout = nn.Dropout(p=dropout)def forward(self, query, key, value, mask=None):if mask is not None:mask = mask.unsqueeze(0)batch_size = query.size(0)query, key, value = [model(x).view(batch_size, -1, self.head, self.d_k).transpose(1, 2)for model, x in zip(self.linears, (query, key, value))]x, self.attn = attention(query, key, value, mask=mask, dropout=self.dropout)x = x.transpose(1, 2).contiguous().view(batch_size, -1, self.head * self.d_k)return self.linears[-1](x)head = 8
embedding_dim = 512
dropout = 0.2
query = value = key = pe_result
mask = Variable(torch.zeros(8, 4, 4))
mha = MultiHeadedAttention(head, embedding_dim, dropout)
mha_result = mha(query, key, value, mask)
# print(mha_result)# 4.前馈全连接层
class PositionwiseFeedForward(nn.Module):def __init__(self, d_model, d_ff, dropout=0.1):super(PositionwiseFeedForward, self).__init__()self.w1 = nn.Linear(d_model, d_ff)self.w2 = nn.Linear(d_ff, d_model)self.dropout = nn.Dropout(dropout)def forward(self, x):return self.w2(self.dropout(F.relu(self.w1(x))))d_model = 512
d_ff = 64
dropout = 0.2
x = mha_result
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
ff_result = ff(x)# 5.规范化层
# 通过LayerNorm实现规范化层的类
class LayerNorm(nn.Module):def __init__(self, features, eps=1e-6):super(LayerNorm, self).__init__()self.a2 = nn.Parameter(torch.ones(features))self.b2 = nn.Parameter(torch.zeros(features))self.eps = epsdef forward(self, x):mean = x.mean(-1, keepdim=True)std = x.std(-1, keepdim=True)return self.a2 * (x - mean) / (std + self.eps) + self.b2features = d_model = 512
eps = 1e-6
x = ff_result
ln = LayerNorm(features, eps)
ln_result = ln(x)# 6.残差连接
class SublayerConnection(nn.Module):def __init__(self, size, dropout=0.1):super(SublayerConnection, self).__init__()self.norm = LayerNorm(size)self.dropout = nn.Dropout(p=dropout)def forward(self, x, sublayer):return x + self.dropout(sublayer(self.norm(x)))size = 512
dropout = 0.2
head = 8
d_model = 512
x = pe_result
mask = Variable(torch.zeros(8, 4, 4))
self_attn = MultiHeadedAttention(head, d_model)
sublayer = lambda x: self_attn(x, x, x, mask)
sc = SublayerConnection(size, dropout)
sc_result = sc(x, sublayer)# 7.编码器层
class EncoderLayer(nn.Module):def __init__(self, size, self_attn, feed_forward, dropout):super(EncoderLayer, self).__init__()self.self_attn = self_attnself.feed_forward = feed_forwardself.sublayer = clones(SublayerConnection(size, dropout), 2)self.size = sizedef forward(self, x, mask):x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask))return self.sublayer[1](x, self.feed_forward)size = 512
head = 8
d_model = 512
d_ff = 64
x = pe_result
dropout = 0.2
self_attn = MultiHeadedAttention(head, d_model)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
mask = Variable(torch.zeros(8, 4, 4))
el = EncoderLayer(size, self_attn, ff, dropout)
el_result = el(x, mask)# 8.编码器
class Encoder(nn.Module):def __init__(self, layer, N):super(Encoder, self).__init__()self.layers = clones(layer, N)self.norm = LayerNorm(layer.size)def forward(self, x, mask):for layer in self.layers:x = layer(x, mask)return self.norm(x)size = 512
head = 8
d_model = 512
d_ff = 64
c = copy.deepcopy
attn = MultiHeadedAttention(head, d_model)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
dropout = 0.2
layer = EncoderLayer(size, c(attn), c(ff), dropout)
N = 8
mask = Variable(torch.zeros(8, 4, 4))
en = Encoder(layer, N)
en_result = en(x, mask)
# print(en_result)
# print(en_result.shape)
"""
tensor([[[-1.2431e-01, -2.3363e+00, 1.9084e-02, ..., -9.8174e-02,-2.0241e+00, -2.8970e-01],[-3.9608e-01, 5.2420e-02, 2.4076e-02, ..., -1.2182e-01,4.7777e-01, 4.0544e-01],[-6.3494e-01, -2.5631e-03, -1.7992e-01, ..., -5.5367e-02,-4.3454e-02, 1.0005e+00],[-8.5996e-01, 2.6673e+00, 9.2570e-01, ..., 6.2907e-01,3.7063e-01, 6.4456e-01]],[[ 3.3140e-01, 1.4327e+00, 4.1478e-02, ..., 4.5121e-01,-1.7026e+00, 8.7472e-01],[-2.5319e-01, 1.8512e+00, -3.0673e-02, ..., 7.9770e-02,1.1026e-01, -2.9194e-01],[ 1.3375e-01, -1.7779e-01, 2.6414e-03, ..., -5.6526e-01,6.5849e-01, 1.1001e+00],[ 1.5610e+00, -1.4482e+00, 2.5439e-01, ..., -5.4919e-01,-7.2307e-01, 1.4985e+00]]], grad_fn=<AddBackward0>)
torch.Size([2, 4, 512])
"""# 三、解码器部分
# 1.解码器层
class DecoderLayer(nn.Module):def __init__(self, size, self_attn, src_attn, feed_forward, dropout):super(DecoderLayer, self).__init__()self.size = sizeself.self_attn = self_attnself.src_attn = src_attnself.feed_forward = feed_forwardself.sublayer = clones(SublayerConnection(size, dropout), 3)def forward(self, x, memory, source_mask, target_mask):m = memoryx = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, target_mask))x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, source_mask))return self.sublayer[2](x, self.feed_forward)head = 8
size = 512
d_model = 512
d_ff = 64
dropout = 0.2
self_attn = src_attn = MultiHeadedAttention(head, d_model, dropout)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
x = pe_result
memory = en_result
mask = Variable(torch.zeros(8, 4, 4))
source_mask = target_mask = mask
dl = DecoderLayer(size, self_attn, src_attn, ff, dropout)
dl_result = dl(x, memory, source_mask, target_mask)
# print(dl_result)
# print(dl_result.shape)
"""
tensor([[[ 1.9604e+00, 3.9288e+01, -5.2422e+01, ..., 2.1041e-01,-5.5063e+01, 1.5233e-01],[ 1.0135e-01, -3.7779e-01, 6.5491e+01, ..., 2.8062e+01,-3.7780e+01, -3.9577e+01],[ 1.9526e+01, -2.5741e+01, 2.6926e-01, ..., -1.5316e+01,1.4543e+00, 2.7714e+00],[-2.1528e+01, 2.0141e+01, 2.1999e+01, ..., 2.2099e+00,-1.7267e+01, -1.6687e+01]],[[ 6.7259e+00, -2.6918e+01, 1.1807e+01, ..., -3.6453e+01,-2.9231e+01, 1.1288e+01],[ 7.7484e+01, -5.0572e-01, -1.3096e+01, ..., 3.6302e-01,1.9907e+01, -1.2160e+00],[ 2.6703e+01, 4.4737e+01, -3.1590e+01, ..., 4.1540e-03,5.2587e+00, 5.2382e+00],[ 4.7435e+01, -3.7599e-01, 5.0898e+01, ..., 5.6361e+00,3.5891e+01, 1.5697e+01]]], grad_fn=<AddBackward0>)
torch.Size([2, 4, 512])
"""# 2.解码器
class Decoder(nn.Module):def __init__(self, layer, N):super(Decoder, self).__init__()self.layers = clones(layer, N)self.norm = LayerNorm(layer.size)def forward(self, x, memory, source_mask, target_mask):for layer in self.layers:x = layer(x, memory, source_mask, target_mask)return self.norm(x)size = 512
d_model = 512
head = 8
d_ff = 64
dropout = 0.2
c = copy.deepcopy
attn = MultiHeadedAttention(head, d_model)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
layer = DecoderLayer(d_model, c(attn), c(attn), c(ff), dropout)
N = 8
x = pe_result
memory = en_result
mask = Variable(torch.zeros(8, 4, 4))
source_mask = target_mask = mask
de = Decoder(layer, N)
de_result = de(x, memory, source_mask, target_mask)
# print(de_result)
# print(de_result.shape)
"""
tensor([[[ 0.2436, 0.8310, 1.1406, ..., 1.2474, 1.0660, -0.7125],[ 0.8292, -0.1330, -0.2391, ..., -1.0578, -0.8154, 1.4003],[ 0.8909, 0.1255, 0.9115, ..., 0.0775, 0.0753, 0.3909],[-1.9148, 0.2801, 1.7520, ..., -0.7988, -2.0647, -0.5999]],[[ 0.9265, 0.5207, -1.8971, ..., -2.2877, 0.1123, 0.2563],[ 0.8011, 1.0716, -0.0627, ..., -1.2644, 1.6997, 0.8083],[-0.6971, -1.6886, -0.7169, ..., 1.0697, -1.0679, 0.8851],[-0.9620, -0.2029, 1.2966, ..., -0.3927, 1.6059, 1.6047]]],grad_fn=<AddBackward0>)
torch.Size([2, 4, 512])
"""# 四、输出部分
# 线性层和softmax层一起实现, 因为二者的共同目标是生成最后的结构
# 因此把类的名字叫做Generator
class Generator(nn.Module):def __init__(self, d_model, vocab_size):super(Generator, self).__init__()self.project = nn.Linear(d_model, vocab_size)def forward(self, x):return F.log_softmax(self.project(x), dim=-1)d_model = 512
vocab_size = 1000
x = de_result
gen = Generator(d_model, vocab_size)
gen_result = gen(x)
print(gen_result)
print(gen_result.shape)
"""
tensor([[[-7.0677, -6.3155, -6.8694, ..., -6.8623, -6.4482, -7.2010],[-7.8073, -7.6669, -6.3424, ..., -7.0006, -6.8322, -6.1138],[-9.0578, -7.1061, -6.2095, ..., -7.3074, -7.2882, -7.3483],[-8.1861, -7.2428, -6.7725, ..., -6.8366, -7.3286, -6.8935]],[[-7.3694, -6.7055, -6.8839, ..., -6.7879, -6.8398, -7.0582],[-6.5527, -6.8104, -7.6633, ..., -8.0519, -7.0640, -6.3101],[-8.4895, -7.9180, -6.4888, ..., -6.7811, -5.6739, -6.5447],[-6.2718, -7.3904, -7.8301, ..., -6.6355, -5.7487, -8.1378]]],grad_fn=<LogSoftmaxBackward0>)
torch.Size([2, 4, 1000])
"""# 编码器-解码器
class EncoderDecoder(nn.Module):def __init__(self, encoder, decoder, source_embed, target_embed, generator):super(EncoderDecoder, self).__init__()self.encoder = encoderself.decoder = decoderself.src_embed = source_embedself.tgt_embed = target_embedself.generator = generatordef forward(self, source, target, source_mask, target_mask):return self.decode(self.encode(source, source_mask), source_mask,target, target_mask)def encode(self, source, source_mask):return self.encoder(self.src_embed(source), source_mask)def decode(self, memory, source_mask, target, target_mask):return self.decoder(self.tgt_embed(target), memory, source_mask, target_mask)vocab_size = 1000
d_model = 512
encoder = en
decoder = de
source_embed = nn.Embedding(vocab_size, d_model)
target_embed = nn.Embedding(vocab_size, d_model)
generator = gen
source = target = Variable(torch.LongTensor([[100, 2, 421, 508], [491, 998, 1, 221]]))
source_mask = target_mask = Variable(torch.zeros(8, 4, 4))
ed = EncoderDecoder(encoder, decoder, source_embed, target_embed, generator)
ed_result = ed(source, target, source_mask, target_mask)
print(ed_result)
print(ed_result.shape)
"""
tensor([[[ 0.2102, -0.0826, -0.0550, ..., 1.5555, 1.3025, -0.6296],[ 0.8270, -0.5372, -0.9559, ..., 0.3665, 0.4338, -0.7505],[ 0.4956, -0.5133, -0.9323, ..., 1.0773, 1.1913, -0.6240],[ 0.5770, -0.6258, -0.4833, ..., 0.1171, 1.0069, -1.9030]],[[-0.4355, -1.7115, -1.5685, ..., -0.6941, -0.1878, -0.1137],[-0.8867, -1.2207, -1.4151, ..., -0.9618, 0.1722, -0.9562],[-0.0946, -0.9012, -1.6388, ..., -0.2604, -0.3357, -0.6436],[-1.1204, -1.4481, -1.5888, ..., -0.8816, -0.6497, 0.0606]]],grad_fn=<AddBackward0>)
torch.Size([2, 4, 512])
"""14.transformer模型
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
import math
import matplotlib.pyplot as plt
import numpy as np
import copy# 一、输入部分
# 1.文本嵌入层
class Embeddings(nn.Module):def __init__(self, d_model, vocab):super(Embeddings, self).__init__()self.lut = nn.Embedding(vocab, d_model)self.d_model = d_modeldef forward(self, x):return self.lut(x) * math.sqrt(self.d_model)# 2.位置编码器
class PositionalEncoding(nn.Module):def __init__(self, d_model, dropout, max_len=5000):super(PositionalEncoding, self).__init__()self.dropout = nn.Dropout(p=dropout)pe = torch.zeros(max_len, d_model)position = torch.arange(0, max_len).unsqueeze(1)div_term = torch.exp(torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model))pe[:, 0::2] = torch.sin(position * div_term)pe[:, 1::2] = torch.cos(position * div_term)pe = pe.unsqueeze(0)self.register_buffer('pe', pe)def forward(self, x):x = x + Variable(self.pe[:, :x.size(1)], requires_grad=False)return self.dropout(x)d_model = 512
dropout = 0.1
max_len = 60vocab = 1000
x = Variable(torch.LongTensor([[100, 2, 421, 508], [491, 998, 1, 221]]))
emb = Embeddings(d_model, vocab)
embr = emb(x)x = embr
pe = PositionalEncoding(d_model, dropout, max_len)
pe_result = pe(x)# 绘制词汇向量中特征的分布曲线
plt.figure(figsize=(15, 5)) # 创建一张15 x 5大小的画布
pe = PositionalEncoding(20, 0)
y = pe(Variable(torch.zeros(1, 100, 20)))
plt.plot(np.arange(100), y[0, :, 4:8].data.numpy())
plt.legend(["dim %d" % p for p in [4, 5, 6, 7]])# plt.show()# 二、编码器部分
# 1.掩码张量函数
def subsequent_mask(size):attn_shape = (1, size, size)subsequent_mask = np.triu(np.ones(attn_shape), k=1).astype('uint8')return torch.from_numpy(1 - subsequent_mask)# 掩码张量的可视化
plt.figure(figsize=(5, 5))
plt.imshow(subsequent_mask(20)[0])# plt.show()# 2.注意力机制
def attention(query, key, value, mask=None, dropout=None):d_k = query.size(-1)scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)if mask is not None:scores = scores.masked_fill(mask == 0, -1e9)p_attn = F.softmax(scores, dim=-1)if dropout is not None:p_attn = dropout(p_attn)return torch.matmul(p_attn, value), p_attnquery = key = value = pe_result
attn, p_attn = attention(query, key, value)
# print("query的注意力表示:", attn) # 2x4x512
# print("注意力张量:", p_attn) # size 2x4x4
#
# print("*****************************************************************")
# 带有mask的输入参数
query = key = value = pe_result
mask = Variable(torch.zeros(2, 4, 4))
attn, p_attn = attention(query, key, value, mask=mask)
# print("query的注意力表示:", attn) # size 2x4x512
# print("注意力张量:", p_attn) # size 2x4x4# 3.多头注意力机制
# 深拷贝
def clones(module, N):return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])class MultiHeadedAttention(nn.Module):def __init__(self, head, embedding_dim, dropout=0.1):super(MultiHeadedAttention, self).__init__()assert embedding_dim % head == 0self.d_k = embedding_dim // headself.head = head# 在多头注意力中,Q,K,V各需要一个,最后拼接的矩阵还需要一个,一共是4个self.linears = clones(nn.Linear(embedding_dim, embedding_dim), 4)self.attn = Noneself.dropout = nn.Dropout(p=dropout)def forward(self, query, key, value, mask=None):if mask is not None:mask = mask.unsqueeze(0)batch_size = query.size(0)query, key, value = [model(x).view(batch_size, -1, self.head, self.d_k).transpose(1, 2)for model, x in zip(self.linears, (query, key, value))]x, self.attn = attention(query, key, value, mask=mask, dropout=self.dropout)x = x.transpose(1, 2).contiguous().view(batch_size, -1, self.head * self.d_k)return self.linears[-1](x)head = 8
embedding_dim = 512
dropout = 0.2
query = value = key = pe_result
mask = Variable(torch.zeros(8, 4, 4))
mha = MultiHeadedAttention(head, embedding_dim, dropout)
mha_result = mha(query, key, value, mask)
# print(mha_result)# 4.前馈全连接层
class PositionwiseFeedForward(nn.Module):def __init__(self, d_model, d_ff, dropout=0.1):super(PositionwiseFeedForward, self).__init__()self.w1 = nn.Linear(d_model, d_ff)self.w2 = nn.Linear(d_ff, d_model)self.dropout = nn.Dropout(dropout)def forward(self, x):return self.w2(self.dropout(F.relu(self.w1(x))))d_model = 512
d_ff = 64
dropout = 0.2
x = mha_result
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
ff_result = ff(x)# 5.规范化层
# 通过LayerNorm实现规范化层的类
class LayerNorm(nn.Module):def __init__(self, features, eps=1e-6):super(LayerNorm, self).__init__()self.a2 = nn.Parameter(torch.ones(features))self.b2 = nn.Parameter(torch.zeros(features))self.eps = epsdef forward(self, x):mean = x.mean(-1, keepdim=True)std = x.std(-1, keepdim=True)return self.a2 * (x - mean) / (std + self.eps) + self.b2features = d_model = 512
eps = 1e-6
x = ff_result
ln = LayerNorm(features, eps)
ln_result = ln(x)# 6.残差连接
class SublayerConnection(nn.Module):def __init__(self, size, dropout=0.1):super(SublayerConnection, self).__init__()self.norm = LayerNorm(size)self.dropout = nn.Dropout(p=dropout)def forward(self, x, sublayer):return x + self.dropout(sublayer(self.norm(x)))size = 512
dropout = 0.2
head = 8
d_model = 512
x = pe_result
mask = Variable(torch.zeros(8, 4, 4))
self_attn = MultiHeadedAttention(head, d_model)
sublayer = lambda x: self_attn(x, x, x, mask)
sc = SublayerConnection(size, dropout)
sc_result = sc(x, sublayer)# 7.编码器层
class EncoderLayer(nn.Module):def __init__(self, size, self_attn, feed_forward, dropout):super(EncoderLayer, self).__init__()self.self_attn = self_attnself.feed_forward = feed_forwardself.sublayer = clones(SublayerConnection(size, dropout), 2)self.size = sizedef forward(self, x, mask):x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask))return self.sublayer[1](x, self.feed_forward)size = 512
head = 8
d_model = 512
d_ff = 64
x = pe_result
dropout = 0.2
self_attn = MultiHeadedAttention(head, d_model)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
mask = Variable(torch.zeros(8, 4, 4))
el = EncoderLayer(size, self_attn, ff, dropout)
el_result = el(x, mask)# 8.编码器
class Encoder(nn.Module):def __init__(self, layer, N):super(Encoder, self).__init__()self.layers = clones(layer, N)self.norm = LayerNorm(layer.size)def forward(self, x, mask):for layer in self.layers:x = layer(x, mask)return self.norm(x)size = 512
head = 8
d_model = 512
d_ff = 64
c = copy.deepcopy
attn = MultiHeadedAttention(head, d_model)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
dropout = 0.2
layer = EncoderLayer(size, c(attn), c(ff), dropout)
N = 8
mask = Variable(torch.zeros(8, 4, 4))
en = Encoder(layer, N)
en_result = en(x, mask)
# print(en_result)
# print(en_result.shape)
"""
tensor([[[-1.2431e-01, -2.3363e+00, 1.9084e-02, ..., -9.8174e-02,-2.0241e+00, -2.8970e-01],[-3.9608e-01, 5.2420e-02, 2.4076e-02, ..., -1.2182e-01,4.7777e-01, 4.0544e-01],[-6.3494e-01, -2.5631e-03, -1.7992e-01, ..., -5.5367e-02,-4.3454e-02, 1.0005e+00],[-8.5996e-01, 2.6673e+00, 9.2570e-01, ..., 6.2907e-01,3.7063e-01, 6.4456e-01]],[[ 3.3140e-01, 1.4327e+00, 4.1478e-02, ..., 4.5121e-01,-1.7026e+00, 8.7472e-01],[-2.5319e-01, 1.8512e+00, -3.0673e-02, ..., 7.9770e-02,1.1026e-01, -2.9194e-01],[ 1.3375e-01, -1.7779e-01, 2.6414e-03, ..., -5.6526e-01,6.5849e-01, 1.1001e+00],[ 1.5610e+00, -1.4482e+00, 2.5439e-01, ..., -5.4919e-01,-7.2307e-01, 1.4985e+00]]], grad_fn=<AddBackward0>)
torch.Size([2, 4, 512])
"""# 三、解码器部分
# 1.解码器层
class DecoderLayer(nn.Module):def __init__(self, size, self_attn, src_attn, feed_forward, dropout):super(DecoderLayer, self).__init__()self.size = sizeself.self_attn = self_attnself.src_attn = src_attnself.feed_forward = feed_forwardself.sublayer = clones(SublayerConnection(size, dropout), 3)def forward(self, x, memory, source_mask, target_mask):m = memoryx = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, target_mask))x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, source_mask))return self.sublayer[2](x, self.feed_forward)head = 8
size = 512
d_model = 512
d_ff = 64
dropout = 0.2
self_attn = src_attn = MultiHeadedAttention(head, d_model, dropout)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
x = pe_result
memory = en_result
mask = Variable(torch.zeros(8, 4, 4))
source_mask = target_mask = mask
dl = DecoderLayer(size, self_attn, src_attn, ff, dropout)
dl_result = dl(x, memory, source_mask, target_mask)
# print(dl_result)
# print(dl_result.shape)
"""
tensor([[[ 1.9604e+00, 3.9288e+01, -5.2422e+01, ..., 2.1041e-01,-5.5063e+01, 1.5233e-01],[ 1.0135e-01, -3.7779e-01, 6.5491e+01, ..., 2.8062e+01,-3.7780e+01, -3.9577e+01],[ 1.9526e+01, -2.5741e+01, 2.6926e-01, ..., -1.5316e+01,1.4543e+00, 2.7714e+00],[-2.1528e+01, 2.0141e+01, 2.1999e+01, ..., 2.2099e+00,-1.7267e+01, -1.6687e+01]],[[ 6.7259e+00, -2.6918e+01, 1.1807e+01, ..., -3.6453e+01,-2.9231e+01, 1.1288e+01],[ 7.7484e+01, -5.0572e-01, -1.3096e+01, ..., 3.6302e-01,1.9907e+01, -1.2160e+00],[ 2.6703e+01, 4.4737e+01, -3.1590e+01, ..., 4.1540e-03,5.2587e+00, 5.2382e+00],[ 4.7435e+01, -3.7599e-01, 5.0898e+01, ..., 5.6361e+00,3.5891e+01, 1.5697e+01]]], grad_fn=<AddBackward0>)
torch.Size([2, 4, 512])
"""# 2.解码器
class Decoder(nn.Module):def __init__(self, layer, N):super(Decoder, self).__init__()self.layers = clones(layer, N)self.norm = LayerNorm(layer.size)def forward(self, x, memory, source_mask, target_mask):for layer in self.layers:x = layer(x, memory, source_mask, target_mask)return self.norm(x)size = 512
d_model = 512
head = 8
d_ff = 64
dropout = 0.2
c = copy.deepcopy
attn = MultiHeadedAttention(head, d_model)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
layer = DecoderLayer(d_model, c(attn), c(attn), c(ff), dropout)
N = 8
x = pe_result
memory = en_result
mask = Variable(torch.zeros(8, 4, 4))
source_mask = target_mask = mask
de = Decoder(layer, N)
de_result = de(x, memory, source_mask, target_mask)
# print(de_result)
# print(de_result.shape)
"""
tensor([[[ 0.2436, 0.8310, 1.1406, ..., 1.2474, 1.0660, -0.7125],[ 0.8292, -0.1330, -0.2391, ..., -1.0578, -0.8154, 1.4003],[ 0.8909, 0.1255, 0.9115, ..., 0.0775, 0.0753, 0.3909],[-1.9148, 0.2801, 1.7520, ..., -0.7988, -2.0647, -0.5999]],[[ 0.9265, 0.5207, -1.8971, ..., -2.2877, 0.1123, 0.2563],[ 0.8011, 1.0716, -0.0627, ..., -1.2644, 1.6997, 0.8083],[-0.6971, -1.6886, -0.7169, ..., 1.0697, -1.0679, 0.8851],[-0.9620, -0.2029, 1.2966, ..., -0.3927, 1.6059, 1.6047]]],grad_fn=<AddBackward0>)
torch.Size([2, 4, 512])
"""# 四、输出部分
# 线性层和softmax层一起实现, 因为二者的共同目标是生成最后的结构
# 因此把类的名字叫做Generator
class Generator(nn.Module):def __init__(self, d_model, vocab_size):super(Generator, self).__init__()self.project = nn.Linear(d_model, vocab_size)def forward(self, x):return F.log_softmax(self.project(x), dim=-1)d_model = 512
vocab_size = 1000
x = de_result
gen = Generator(d_model, vocab_size)
gen_result = gen(x)
print(gen_result)
print(gen_result.shape)
"""
tensor([[[-7.0677, -6.3155, -6.8694, ..., -6.8623, -6.4482, -7.2010],[-7.8073, -7.6669, -6.3424, ..., -7.0006, -6.8322, -6.1138],[-9.0578, -7.1061, -6.2095, ..., -7.3074, -7.2882, -7.3483],[-8.1861, -7.2428, -6.7725, ..., -6.8366, -7.3286, -6.8935]],[[-7.3694, -6.7055, -6.8839, ..., -6.7879, -6.8398, -7.0582],[-6.5527, -6.8104, -7.6633, ..., -8.0519, -7.0640, -6.3101],[-8.4895, -7.9180, -6.4888, ..., -6.7811, -5.6739, -6.5447],[-6.2718, -7.3904, -7.8301, ..., -6.6355, -5.7487, -8.1378]]],grad_fn=<LogSoftmaxBackward0>)
torch.Size([2, 4, 1000])
"""# 编码器-解码器
class EncoderDecoder(nn.Module):def __init__(self, encoder, decoder, source_embed, target_embed, generator):super(EncoderDecoder, self).__init__()self.encoder = encoderself.decoder = decoderself.src_embed = source_embedself.tgt_embed = target_embedself.generator = generatordef forward(self, source, target, source_mask, target_mask):return self.decode(self.encode(source, source_mask), source_mask,target, target_mask)def encode(self, source, source_mask):return self.encoder(self.src_embed(source), source_mask)def decode(self, memory, source_mask, target, target_mask):return self.decoder(self.tgt_embed(target), memory, source_mask, target_mask)vocab_size = 1000
d_model = 512
encoder = en
decoder = de
source_embed = nn.Embedding(vocab_size, d_model)
target_embed = nn.Embedding(vocab_size, d_model)
generator = gen
source = target = Variable(torch.LongTensor([[100, 2, 421, 508], [491, 998, 1, 221]]))
source_mask = target_mask = Variable(torch.zeros(8, 4, 4))
ed = EncoderDecoder(encoder, decoder, source_embed, target_embed, generator)
ed_result = ed(source, target, source_mask, target_mask)
# print(ed_result)
# print(ed_result.shape)
"""
tensor([[[ 0.2102, -0.0826, -0.0550, ..., 1.5555, 1.3025, -0.6296],[ 0.8270, -0.5372, -0.9559, ..., 0.3665, 0.4338, -0.7505],[ 0.4956, -0.5133, -0.9323, ..., 1.0773, 1.1913, -0.6240],[ 0.5770, -0.6258, -0.4833, ..., 0.1171, 1.0069, -1.9030]],[[-0.4355, -1.7115, -1.5685, ..., -0.6941, -0.1878, -0.1137],[-0.8867, -1.2207, -1.4151, ..., -0.9618, 0.1722, -0.9562],[-0.0946, -0.9012, -1.6388, ..., -0.2604, -0.3357, -0.6436],[-1.1204, -1.4481, -1.5888, ..., -0.8816, -0.6497, 0.0606]]],grad_fn=<AddBackward0>)
torch.Size([2, 4, 512])
"""# Tansformer模型
def make_model(source_vocab, target_vocab, N=6,d_model=512, d_ff=2048, head=8, dropout=0.1):c = copy.deepcopyattn = MultiHeadedAttention(head, d_model)ff = PositionwiseFeedForward(d_model, d_ff, dropout)position = PositionalEncoding(d_model, dropout)model = EncoderDecoder(Encoder(EncoderLayer(d_model, c(attn), c(ff), dropout), N),Decoder(DecoderLayer(d_model, c(attn), c(attn),c(ff), dropout), N),nn.Sequential(Embeddings(d_model, source_vocab), c(position)),nn.Sequential(Embeddings(d_model, target_vocab), c(position)),Generator(d_model, target_vocab))for p in model.parameters():if p.dim() > 1:nn.init.xavier_uniform(p)return modelsource_vocab = 11
target_vocab = 11
N = 6
if __name__ == '__main__':res = make_model(source_vocab, target_vocab, N)print(res)
"""
EncoderDecoder((encoder): Encoder((layers): ModuleList((0): EncoderLayer((self_attn): MultiHeadedAttention((linears): ModuleList((0): Linear(in_features=512, out_features=512)(1): Linear(in_features=512, out_features=512)(2): Linear(in_features=512, out_features=512)(3): Linear(in_features=512, out_features=512))(dropout): Dropout(p=0.1))(feed_forward): PositionwiseFeedForward((w_1): Linear(in_features=512, out_features=2048)(w_2): Linear(in_features=2048, out_features=512)(dropout): Dropout(p=0.1))(sublayer): ModuleList((0): SublayerConnection((norm): LayerNorm()(dropout): Dropout(p=0.1))(1): SublayerConnection((norm): LayerNorm()(dropout): Dropout(p=0.1))))(1): EncoderLayer((self_attn): MultiHeadedAttention((linears): ModuleList((0): Linear(in_features=512, out_features=512)(1): Linear(in_features=512, out_features=512)(2): Linear(in_features=512, out_features=512)(3): Linear(in_features=512, out_features=512))(dropout): Dropout(p=0.1))(feed_forward): PositionwiseFeedForward((w_1): Linear(in_features=512, out_features=2048)(w_2): Linear(in_features=2048, out_features=512)(dropout): Dropout(p=0.1))(sublayer): ModuleList((0): SublayerConnection((norm): LayerNorm()(dropout): Dropout(p=0.1))(1): SublayerConnection((norm): LayerNorm()(dropout): Dropout(p=0.1)))))(norm): LayerNorm())(decoder): Decoder((layers): ModuleList((0): DecoderLayer((self_attn): MultiHeadedAttention((linears): ModuleList((0): Linear(in_features=512, out_features=512)(1): Linear(in_features=512, out_features=512)(2): Linear(in_features=512, out_features=512)(3): Linear(in_features=512, out_features=512))(dropout): Dropout(p=0.1))(src_attn): MultiHeadedAttention((linears): ModuleList((0): Linear(in_features=512, out_features=512)(1): Linear(in_features=512, out_features=512)(2): Linear(in_features=512, out_features=512)(3): Linear(in_features=512, out_features=512))(dropout): Dropout(p=0.1))(feed_forward): PositionwiseFeedForward((w_1): Linear(in_features=512, out_features=2048)(w_2): Linear(in_features=2048, out_features=512)(dropout): Dropout(p=0.1))(sublayer): ModuleList((0): SublayerConnection((norm): LayerNorm()(dropout): Dropout(p=0.1))(1): SublayerConnection((norm): LayerNorm()(dropout): Dropout(p=0.1))(2): SublayerConnection((norm): LayerNorm()(dropout): Dropout(p=0.1))))(1): DecoderLayer((self_attn): MultiHeadedAttention((linears): ModuleList((0): Linear(in_features=512, out_features=512)(1): Linear(in_features=512, out_features=512)(2): Linear(in_features=512, out_features=512)(3): Linear(in_features=512, out_features=512))(dropout): Dropout(p=0.1))(src_attn): MultiHeadedAttention((linears): ModuleList((0): Linear(in_features=512, out_features=512)(1): Linear(in_features=512, out_features=512)(2): Linear(in_features=512, out_features=512)(3): Linear(in_features=512, out_features=512))(dropout): Dropout(p=0.1))(feed_forward): PositionwiseFeedForward((w_1): Linear(in_features=512, out_features=2048)(w_2): Linear(in_features=2048, out_features=512)(dropout): Dropout(p=0.1))(sublayer): ModuleList((0): SublayerConnection((norm): LayerNorm()(dropout): Dropout(p=0.1))(1): SublayerConnection((norm): LayerNorm()(dropout): Dropout(p=0.1))(2): SublayerConnection((norm): LayerNorm()(dropout): Dropout(p=0.1)))))(norm): LayerNorm())(src_embed): Sequential((0): Embeddings((lut): Embedding(11, 512))(1): PositionalEncoding((dropout): Dropout(p=0.1)))(tgt_embed): Sequential((0): Embeddings((lut): Embedding(11, 512))(1): PositionalEncoding((dropout): Dropout(p=0.1)))(generator): Generator((proj): Linear(in_features=512, out_features=11))
)
"""