LatentSync V8版 - 音频驱动视频生成数字人说话视频 更新V1.6版模型 支持50系显卡 支持批量 一键整合包下载
LatentSync 是字节跳动开源的一款"AI口型同步神器",简单来说就是能让视频里的人物嘴巴动得和声音完美匹配的工具。比如你给一段配音,它能自动调整视频人物的嘴型,按照配音里的声音说出来,就像真人说话一样自然。简单说就是个让"假人说话像真人"的黑科技,拍视频、做直播的小伙伴用起来特别方便,也可广泛应用于数字人生成领域,自媒体必备神器。
今天分享的 LatentSync V8版,主要更新最新的1.6版模型(该版模型在 512 × 512 分辨率的视频上进行了训练,大幅度提升了生成嘴部的清晰度)
新增对50系显卡的支持
新增批量处理(根据网友反馈,更改批处理方式,支持一键拖拽多个文件)
新增人脸检测模型
同步官方最新源代码。
主要特点
低门槛:消费级的电脑就能运行,对普通用户很友好
操作简单:直接"声音控制嘴巴",不需要复杂操作
效果流畅:独有的"时间对齐"技术,避免视频卡顿或跳帧
高精度:采用类似Stable Diffusion的AI技术,嘴型同步非常精准
应用领域
影视配音:让外国电影的口型匹配中文配音
虚拟主播:让数字人说话更自然
短视频创作:轻松制作对口型视频
游戏开发:让游戏角色说话更真实
使用教程:(建议N卡,显存16G起。支持50系显卡,基于CUDA12.8)
因模型更新,模型从256x256提升到512x512,故对硬件支持也对应提升,显卡显存建议16G起。
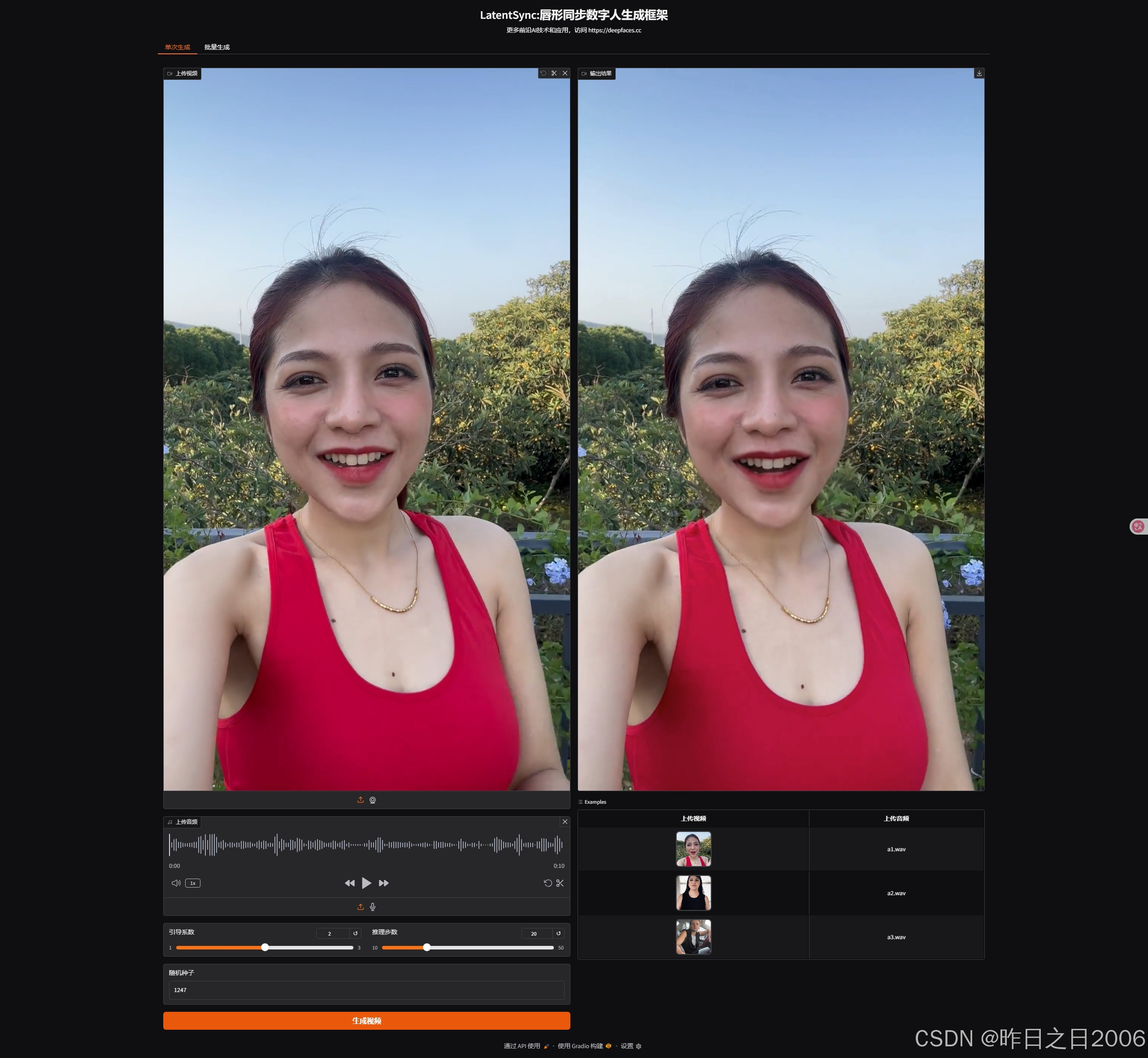
单次生成:上传一段音频和视频,设置参数,生成即可。
批量生成:批量上传视频和音频,视频和音频数量得一样,按照顺序一一对应。
注意事项:上传参考音频和视频时间长度最好一致,如果音频长度大于视频长度,则默认按照视频时长长度生成。如果视频长度大于音频长度,默认按照音频时长长度生成。
解压说明:一键包和模型包分开打包上传,分别下载一键包和模型包,先解压一键包,再下载模型包并复制到一键包目录下,右键->解压到当前文件夹,目录结构参考一键包内文档说明。
下载地址:https://deepfaces.cc/thread-699-1-1.html