ViT架构所需的大型训练集
文章目录
- ViT架构所需的大型训练集
- 归纳偏置
- CNN 中的归纳偏置
- ViT中的归纳偏置
- 平移不变性和平移等变性
- 平移不变性
- 平移等变性
- ViT可以比CNN表现得更好
- ViT如何从训练数据中学习?
- ViT学到了什么?
- 总结
ViT架构所需的大型训练集
归纳偏置
归纳偏置(Inductive Bias)是指在机器学习模型中,为了使模型能够在有限的数据上进行有效学习而引入的先验假设或约束。它决定了模型在面对未知数据时的泛化能力。不同的模型具有不同的归纳偏置,例如卷积神经网络(CNN)通过局部感受野和权重共享引入了空间不变性,而ViT(Vision Transformer)则减少了这类归纳偏置,更依赖于大规模数据来学习有效的特征表示。
CNN 中的归纳偏置
以下是CNN中主要的归纳偏置,它们在很大程度上决定了CNN的工作方式:
-
局部连接:在CNN中,隐藏层的每个单元仅与前一层中的部分神经元相连。这一限制的合理性基于如下假设:邻近像素的关联性比相隔较远的像素更强。典型的例子是该假设应用于图像的边缘或轮廓识别场景。
-
权值共享:假设相同的滤波器对于检测图像不同部分的相同模式是有用的,那么通过卷积层,我们在整个图像中使用同一小组权重(卷积核或滤波器)。
-
分层处理:CNN由多个卷积层组成,用于从输入图像中提取特征。随着网络从输入层向输出层的逐步深入,低级特征逐渐整合形成更为复杂的特征,最终实现对复杂物体、形状的识别。此外,这些层中的卷积滤波器能学会在不同的抽象层次检测特定的模式和特征。
-
空间不变性:CNN具有空间不变这一数学特征,这意味着即使输入信号在空间域内移动不同的位置,模型的输出也保持一致。这一特点源于前文提到的局部连接、权值共享以及分层处理的结合。
ViT中的归纳偏置
与CNN相比,ViT(Vision Transformer)中的归纳偏置显著减少。ViT主要依赖自注意力机制来建模全局特征关系,缺乏CNN中的局部连接、权值共享和空间结构等先验假设。ViT的主要归纳偏置体现在以下几个方面:
- 位置编码:ViT通过显式的位置编码向模型注入位置信息,弥补自注意力机制对空间结构的感知能力不足。
- 分块输入:ViT将图像划分为固定大小的patch,每个patch作为一个“单词”输入Transformer,这种分块方式本身是一种归纳偏置。
- 层归一化与残差连接:这些结构有助于稳定训练和信息流动,但与CNN的空间归纳偏置不同。
由于ViT缺乏强归纳偏置,它更依赖于大规模数据集来学习有效的特征表达。这也是ViT在小数据集上表现不如CNN,但在大数据集上能够取得优异性能的原因之一。
平移不变性和平移等变性
平移不变性
平移不变性(Translation Invariance)是指:当输入数据发生平移(即整体移动)时,模型对输入的识别或输出结果不会发生变化。
举例说明:
- 在图像识别中,如果一只猫在图片左边还是右边,理想的模型都能识别出“猫”,这就是平移不变性。
- 卷积神经网络(CNN)通过卷积操作和池化层,天然具备一定的平移不变性。
原理简述:
平移不变性让模型关注“是什么”而不是“在哪里”,提升了模型对输入位置变化的鲁棒性。
注意:
ViT(Vision Transformer)等基于自注意力机制的模型,原生并不具备平移不变性,需要通过数据增强等方式提升这方面能力。
平移等变性
平移等变性(Translation Equivariance)是指:当输入数据发生平移时,模型的输出会以相同的方式发生平移。也就是说,输出会“跟着”输入的平移而平移。
举例说明:
- 假设有一张图片,图片中的物体从左边移动到右边。对于卷积神经网络(CNN)中的卷积层来说,卷积操作的结果(特征图)也会相应地向右移动。这说明卷积层对输入的平移是等变的。
- 例如,输入 x x x 向右平移 k k k 个像素,卷积操作 f f f 满足 f ( T k x ) = T k f ( x ) f(T_k x) = T_k f(x) f(Tkx)=Tkf(x),其中 T k T_k Tk 表示平移操作。
代码演示(PyTorch):
import numpy as np
import matplotlib.pyplot as plt
from scipy.ndimage import convolvedef translate_image(img, dx, dy):"""平移图像(不调用OpenCV)参数:img: 输入图像(2D数组)dx: X轴平移量(像素)dy: Y轴平移量(像素)返回:translated_img: 平移后的图像"""h, w = img.shape# 创建空矩阵存储结果translated_img = np.zeros_like(img)for y in range(h):for x in range(w):new_x, new_y = x - dx, y - dyif 0 <= new_x < w and 0 <= new_y < h:translated_img[y, x] = img[new_y, new_x]return translated_imgdef apply_convolution(img, kernel):"""应用简单卷积操作(验证等变性)"""return convolve(img, kernel, mode='constant')# 生成测试图像(中心带矩形)
image = np.zeros((100, 100))
image[40:60, 40:60] = 1 # 中心矩形# 定义卷积核(边缘检测)
kernel = np.array([[1, 0, -1],[1, 0, -1],[1, 0, -1]])# 实验1: 先卷积后平移
conv_result = apply_convolution(image, kernel)
translated_conv = translate_image(conv_result, 20, 20)# 实验2: 先平移后卷积
translated_img = translate_image(image, 20, 20)
conv_translated = apply_convolution(translated_img, kernel)# 可视化结果
fig, axes = plt.subplots(2, 2, figsize=(10, 10))
axes[0, 0].imshow(image, cmap='gray')
axes[0, 0].set_title("原始图像")
axes[0, 1].imshow(conv_result, cmap='gray')
axes[0, 1].set_title("卷积结果")
axes[1, 0].imshow(translated_conv, cmap='gray')
axes[1, 0].set_title("先卷积后平移")
axes[1, 1].imshow(conv_translated, cmap='gray')
axes[1, 1].set_title("先平移后卷积")plt.rcParams['font.sans-serif']=['Microsoft YaHei'] #用来正常显示中文标签
plt.show()
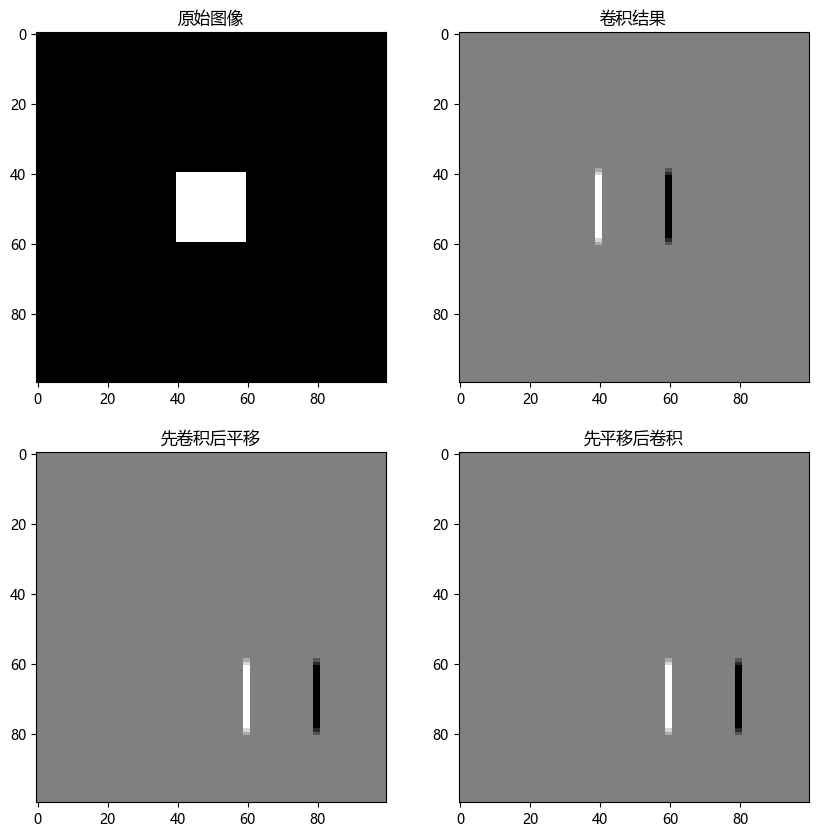
关键代码解析
-
平移函数 (translate_image)
- 通过循环逐像素移动图像,保留原始数据。
- 使用条件判断
0 <= new_x < w确保平移后不越界。
-
卷积操作 (apply_convolution)
- 使用
scipy.ndimage.convolve实现卷积,模拟CNN中的特征提取。 - 边缘检测核突出平移对特征位置的影响。
- 使用
-
等变性验证逻辑
- 路径1:原始图像 → 卷积 → 平移 → 结果A
- 路径2:原始图像 → 平移 → 卷积 → 结果B
- 等变性成立:结果A与结果B应完全一致(特征位置同步偏移)
注意:
- 卷积层天然具备平移等变性,这也是CNN能够有效处理图像等空间数据的关键原因之一。
- 池化层(如最大池化)会破坏等变性,但提升了平移不变性。
- ViT等自注意力模型不具备平移等变性,需要依赖数据增强等手段。
ViT可以比CNN表现得更好
通过前文讨论归纳偏置时所固化的那些假设,相比全连接层,CNN中的参数量大幅减少。另外,相比CNN,ViT往往具有更多参数,也就需要更多的训练数据。
在没有大规模预训练的情况下,ViT在性能上可能不如流行的CNN架构,但如果有足够大的预训练数据集,它可以表现得非常出色。语言Transformer模型中的首选方法是无监督预训练,而ViT通常使用大型的有标签数据集进行预训练,并采用常规的监督学习方式。
ViT如何从训练数据中学习?
ViT(Vision Transformer)通过端到端的监督学习,从大规模标注数据中自动学习图像的特征表示。其主要学习过程如下:
- 分块与嵌入:ViT首先将输入图像划分为固定大小的patch,并将每个patch展平后通过线性变换映射到高维特征空间,形成patch嵌入。
- 位置编码:为每个patch嵌入加上位置编码,使模型能够感知patch的空间位置信息。
- 自注意力机制:多个Transformer编码器层通过自注意力机制建模patch之间的全局依赖关系,捕捉图像中不同区域的长距离联系。
- 特征聚合与分类:最终通过分类token或全局池化等方式聚合特征,输出分类结果。
ViT学到了什么?
- 全局特征关系:ViT能够捕捉图像中不同区域之间的全局依赖,而不仅仅是局部特征。
- 空间结构信息:虽然ViT没有CNN那样的强空间归纳偏置,但通过大规模数据和位置编码,模型可以自动学习到一定的空间结构规律。
- 多层次抽象特征:Transformer层堆叠后,ViT能够逐步提取从低级到高级的图像语义特征。
- 适应性特征表达:ViT可以根据任务和数据自动调整其特征表达方式,不局限于固定的卷积核模式。
总之,ViT依赖大规模数据,通过自注意力机制和深层网络结构,学习到丰富且灵活的图像特征表达,从而在视觉任务中取得优异表现。
总结
本文主要介绍了ViT(Vision Transformer)与CNN在归纳偏置、平移不变性/等变性等方面的差异。CNN通过局部连接、权值共享等强归纳偏置,天然具备空间结构感知和一定的平移不变性/等变性,能在小数据集上表现良好。ViT则弱化了这些归纳偏置,依赖自注意力机制和大规模数据集,通过位置编码和分块输入等方式学习全局特征关系。虽然ViT在小数据集上不如CNN,但在大规模有标签数据集预训练下,能够学到丰富的特征表达,取得优异性能。整体来看,ViT的成功依赖于大数据和强大的模型容量,通过端到端学习实现了对视觉任务的高效建模。