Python实现web请求与访问
一、 Web 请求与响应
Web 请求与响应是 Web 通信的基础。Web 请求由客户端发起,服务器处理后返回响应。
| 类别 | 组成部分 | 具体内容 |
|---|---|---|
| Web 请求 | 请求行 | 包括请求方法(如 GET、POST、PUT、DELETE )、URL 和 HTTP 协议版本(如 HTTP/1.1 ) |
| 请求头 | 包含关于客户端信息、请求体类型、浏览器类型等的元数据 | |
| 请求体 | 在 POST 请求中包含用户提交的数据,如表单数据或文件 | |
| Web 响应 | 响应行 | 包括 HTTP 协议版本、状态码和状态消息 |
| 响应头 | 包括关于响应的信息,如内容类型、服务器信息等 | |
| 响应体 | 包含实际返回的数据(如 HTML 页面、JSON 数据等 ) |
二、http协议
| 分类 | 详情 |
|---|---|
| HTTP 协议概述 | - GET:请求服务器获取资源,通常用于读取数据。 - POST:提交数据到服务器,通常用于表单提交、文件上传等。 - PUT:更新服务器上的资源。 - DELETE:删除服务器上的资源。 |
| 常见的 HTTP 状态码 | - 200 OK:请求成功,服务器返回所请求的数据。 - 301 Moved Permanently:资源已永久移动。 - 404 Not Found:请求的资源不存在。 - 500 Internal Server Error:服务器内部错误。 |
三、Python的requests 库
Python的 requests 库是发送 HTTP 请求和处理响应的最常用工具,它提供了简单、直观的 API使得Web 请求和响应的操作变得非常容易。通过requests,我们可以轻松地发送 GET、POST请求处理 JSON 响应,管理请求头等。
1、指定Python模块下载的源仓库
# 设置pip的全局镜像源为阿里云,加速国内下载速度
pip3 config set global.index-url http://mirrors.aliyun.com/pypi/simple# 添加阿里云镜像为可信主机,避免因HTTPS证书问题导致的警告或错误
pip3 config set install.trusted-host mirrors.aliyun.com# 使用更新后的配置升级pip到最新版本
pip3 install --upgrade pip2、安装requests 库
pip3 install requests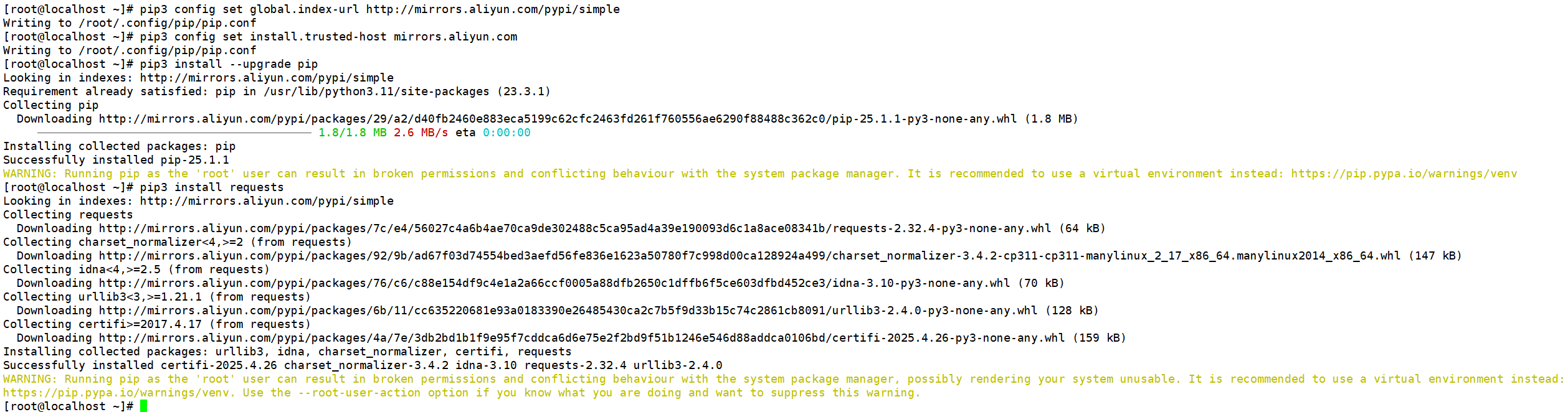
3、发送get请求
import requests#发送get请求
response=requests.get('https://www.httpbin.org/get')#查询返回的状态码
print(response.status_code)#查询响应内容
print(response.text)#查询响应头
print(response.headers)#查询响应内容长度
print(len(response.headers))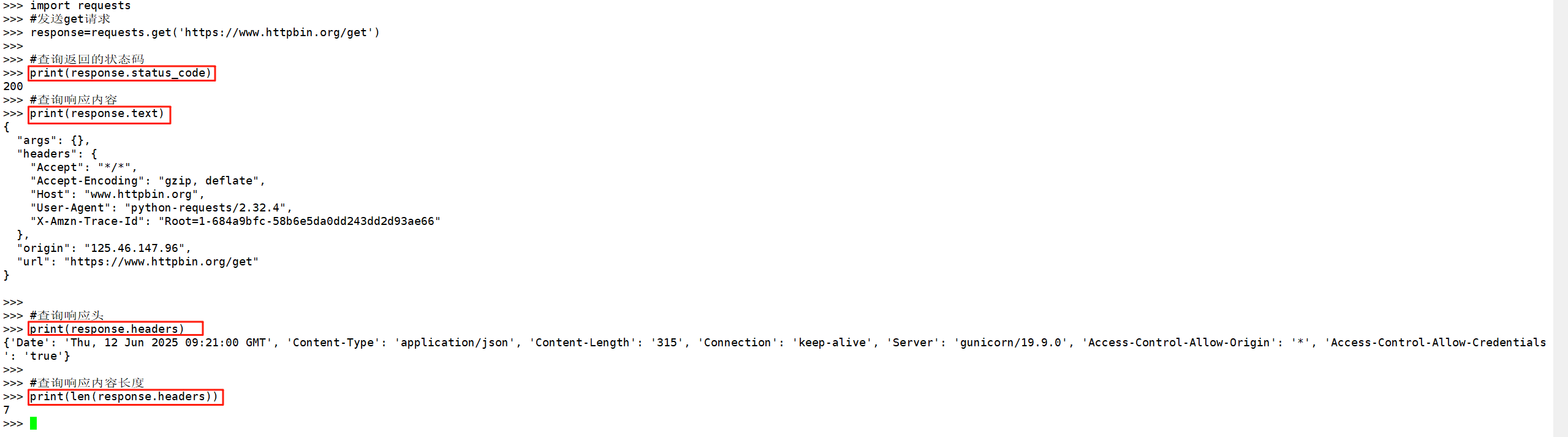
| 方法 / 属性 | 作用说明 |
|---|---|
requests.get() | 用于发送 GET 请求,获取指定 URL 的数据 |
response.status_code | 获取 HTTP 响应状态码,用于判断请求是否成功等(如 200 表示成功、404 表示资源未找到等 ) |
response.text | 获取响应的正文内容,通常是 HTML 或 JSON 数据,可用于进一步解析页面内容或接口返回数据 |
response.headers | 获取响应头,包含了服务器返回的元信息,如内容类型、缓存策略、Cookie 等相关信息 |
len(response.text) | 返回响应正文的长度,帮助我们了解返回内容的大小,可用于初步判断返回数据量多少等 |
4、发送post请求
url = 'https://www.httpbin.org/get'
data = {'id':1,'age':10}
response=requests.post(url,data=data)#查询返回的状态码
print(response.status_code)#查询相应内容
print(response.json())

| 语法 | 功能说明 |
|---|---|
response.json() | 将响应的内容解析为 Python 字典,方便我们处理 JSON 数据 |
四、文件操作
文件操作是 Python 编程中常见的任务。Python 提供了多种方法来读取、写入和管理文件,能够处理文本文件、二进制文件以及目录操作等。掌握文件操作的基础和技巧是高效编程的关键。
1、打开文件的模式
Python 使用内置的 open() 函数来打开文件。打开文件时,我们需要指定文件模式(即操作文件的方式)。
| 文件打开模式 | 模式说明 |
|---|---|
| r | 只读模式(默认模式)。文件必须存在。如果文件不存在,会抛出 FileNotFoundError 异常。 |
| w | 写入模式。如果文件存在,会覆盖文件内容。如果文件不存在,会创建新文件。 |
| a | 追加模式。如果文件存在,写入的数据会追加到文件末尾;如果文件不存在,会创建新文件。 |
| x | 独占创建模式。若文件已存在,操作会失败并抛出 FileExistsError 异常。此模式通常用于创建文件时防止覆盖现有文件。 |
| rb | 二进制读取模式,用于读取非文本文件(如图片、音频文件)。 |
| wb | 二进制写入模式,用于写入非文本文件。 |
| r+ | 读写模式。文件必须存在。既可以读取文件内容,也可以写入数据。 |
| w+ | 读写模式。如果文件存在,会覆盖文件内容;如果文件不存在,会创建新文件。 |
| a+ | 读写模式。文件存在时,数据会追加到文件末尾;如果文件不存在,会创建新文件。 |
| rb+ | 二进制读写模式。 |
1.1、只读
read
>>> with open('aaa.txt','r') as file:
... content=file.read()
... print(content)
...
dftgyuiahsvgsab

逐行读取readline()
# 使用 with 语句打开文件,'aaa.txt' 是文件名,'r' 表示以只读模式打开
# with 语句会在代码块结束后自动关闭文件,无需手动调用 close() 方法,很方便且能避免资源泄漏
with open('aaa.txt', 'r') as file: # 调用文件对象的 readline() 方法,读取文件的第一行内容,# 并将读取到的字符串(包含行末换行符等)赋值给变量 line line = file.readline() # 当 line 不为空字符串时,进入循环(因为文件末尾 readline() 会返回空字符串,用于判断是否读完文件)while line: # 对 line 字符串调用 strip() 方法,去除字符串首尾的空白字符(包括换行符、空格、制表符等)# 然后使用 print() 函数输出处理后的内容,这样打印的每行内容就不会带着行末换行符额外占行print(line.strip()) # strip()用来去除行末的换行符# 继续调用 readline() 方法,读取文件的下一行内容,更新 line 变量,# 为下一次循环判断和处理做准备,若已到文件末尾,此处会得到空字符串,循环后续就会结束line = file.readline()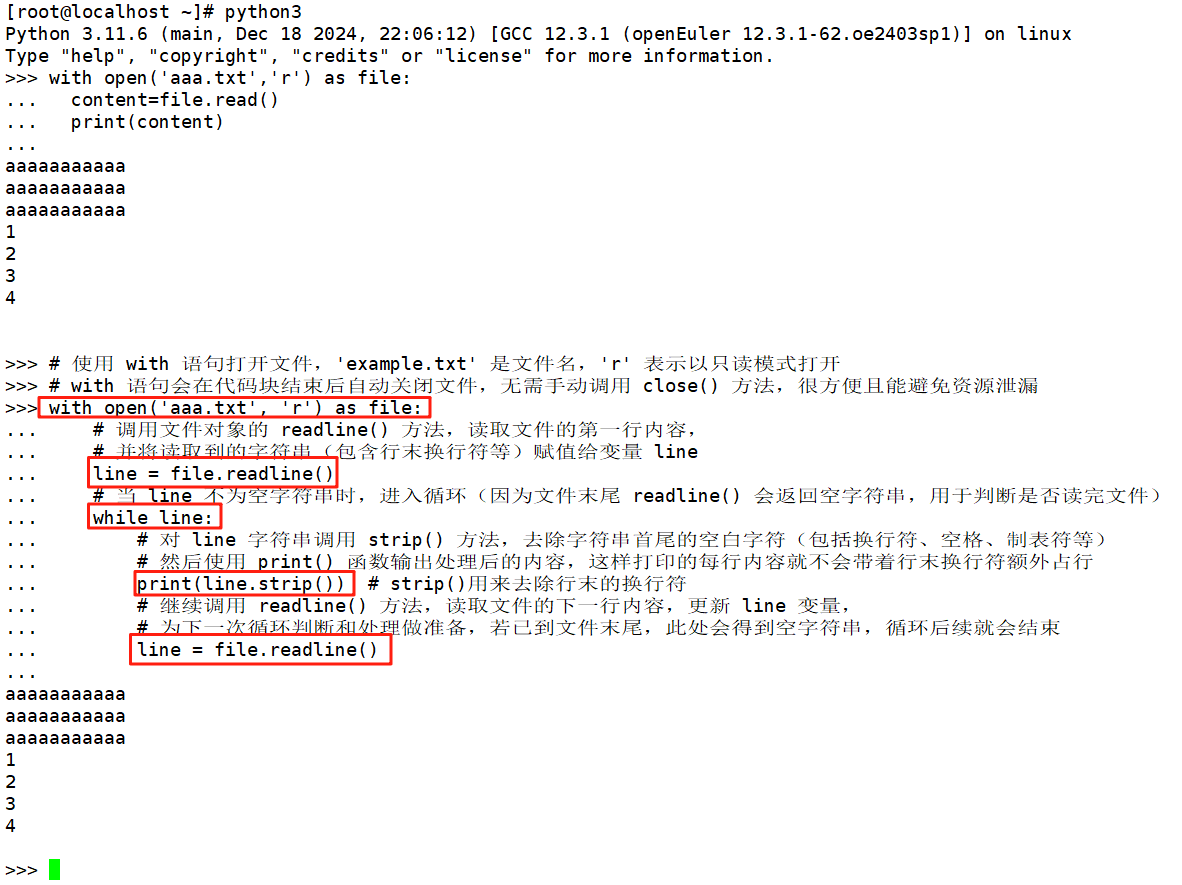
多行读取readlines()
# 使用 with 语句打开文件,'aaa.txt' 是要打开的文件名,'r' 表示以只读(read)模式打开
# with 语句的优势是,代码块结束后会自动关闭文件,无需手动调用 file.close(),避免资源泄漏问题
with open('aaa.txt', 'r') as file: # 调用文件对象的 readlines() 方法,一次性读取文件的所有行,# 每行内容作为列表中的一个元素(元素包含行末的换行符等空白字符),并将这个列表赋值给变量 lines lines = file.readlines() # 遍历 lines 列表,每次循环将列表中的一个元素(即文件的一行内容)赋值给变量 linefor line in lines: # 对 line 字符串调用 strip() 方法,去除字符串首尾的空白字符(像换行符 \n、空格 等都会被去掉)# 然后使用 print() 函数输出处理后的内容,让打印结果更整洁,不会因行末换行符出现多余空行print(line.strip()) 
1.2、写入(会覆盖原数据)
write
>>> with open('aaa.txt','w') as file:
... file.write("aaaaaaaaaaa\n")
...
12

多行写入writelines()
# 定义一个列表 lines,列表中的每个字符串元素代表一行数据,
# 注意元素里手动加了换行符 \n ,用于控制写入文件时的换行(writelines 不会自动添加换行,需手动处理)
#lines = ["第一行数据。\n", "第二行数据。\n", "第三行数据。\n"]
lines = ["11\n","22\n","33\n"]
# 使用 with 语句以写入模式('w')打开 aaa.txt 文件,
# with 语句会自动管理文件资源,代码块结束后自动关闭文件,避免资源泄漏
with open('aaa.txt', 'w') as file: # 调用文件对象的 writelines 方法,传入可迭代对象 lines,# 将 lines 中每个元素按顺序写入文件,实现多行数据写入file.writelines(lines) 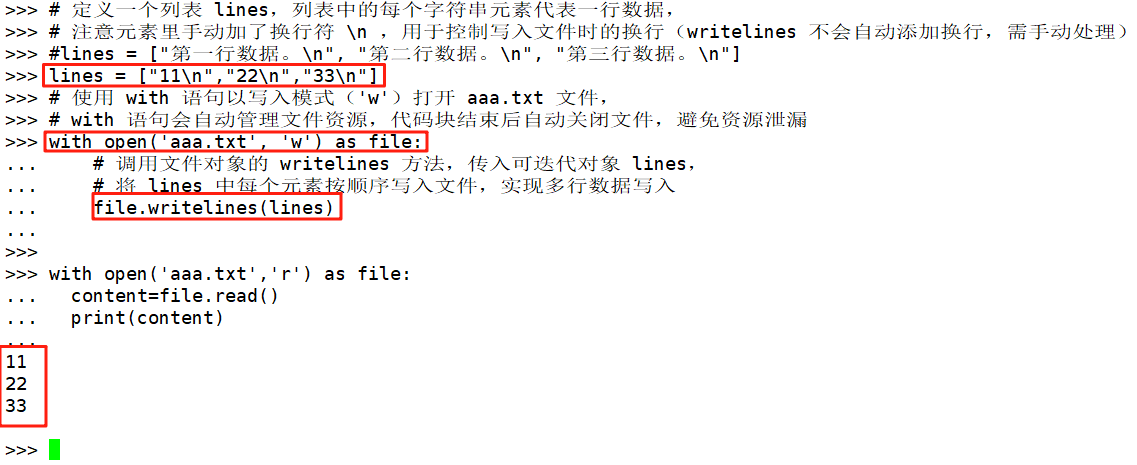
1.3、追加
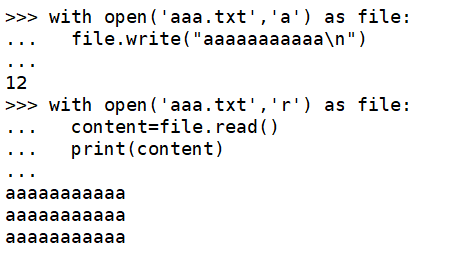
>>> with open('aaa.txt','a') as file:
... file.write("aaaaaaaaaaa\n")
...
12
>>> with open('aaa.txt','r') as file:
... content=file.read()
... print(content)
...
aaaaaaaaaaa
aaaaaaaaaaa
aaaaaaaaaaa
1.4、以二进制方式打开文件
# 以二进制模式打开文件(例如读取图片)
# 使用 with 语句,它会在代码块结束后自动关闭文件,避免资源泄漏问题
# 'image.jpg' 是要打开的文件路径及文件名,这里假设文件和代码在同一目录,若不在需写完整路径
# 'rb' 表示以二进制只读模式(read binary)打开文件,适用于读取图片、音频等二进制文件
with open('image.jpg', 'rb') as file: # 调用文件对象的 read 方法,一次性读取整个文件的二进制数据,并赋值给 binary_data 变量binary_data = file.read() # 打印读取到的二进制数据的前 20 个字节内容# 二进制数据直接打印可能会显示为类似 b'\x00\x01...' 这样的字节串形式,这里截取前 20 个字节展示print("读取到的二进制数据:", binary_data[:20]) 五、错误处理与异常捕获
在进行 Web 请求时,可能会发生各种错误,例如网络超时、服务器错误等。requests 库通过异常处理机制帮助我们捕获这些错误。Python 的 try 语句能够捕获和处理代码块中的异常,从而避免程序崩溃,并且提供了处理错误的机会
| 组成部分 | 说明 |
|---|---|
| try 块 | 包含可能会引发异常的代码。当代码运行过程中发生错误时,程序会跳到相应的 except 块进行处理 |
| except 块 | 当 try 块中的代码出现异常时,程序会跳转到 except 块执行。在 except 中可以指定要捕获的异常类型,如 Timeout、HTTPError 等 |
| else 块(可选) | 如果 try 块中的代码没有抛出异常,则会执行 else 块中的代码 |
| finally 块(可选) | 无论是否发生异常,finally 块中的代码都会执行,通常用于清理资源(如关闭文件、数据库连接等) |
import requests
from requests.exceptions import RequestException, Timeout, HTTPErrortry:# 发送 GET 请求到指定 URL,设置超时时间为 5 秒response = requests.get("https://www.baidu.com", timeout=5)# 检查响应状态码,若不是 200 主动抛出异常response.raise_for_status()# 请求成功时,打印响应体内容print('Response Body:', response.text)
except Timeout:# 捕获请求超时异常print('Request timed out')
except HTTPError as http_err:# 捕获 HTTP 错误异常print(f'HTTP error occurred: {http_err}')
except RequestException as req_err:# 捕获其他网络相关错误print(f'Request error occurred: {req_err}')
finally:# 无论请求成功/失败,都会执行此处代码print('Request attempt completed.')
| 分类 | 具体内容 |
|---|---|
| try 块 | 首先发起 HTTP 请求,设置超时时间为 5 秒,并使用 response.raise_for_status () 来检查响应的状态码。如果服务器返回了错误的状态码(如 404、500 ),raise_for_status () 会抛出 HTTPError 异常 |
| except 块 - Timeout | 如果请求超时(超过设置的 5 秒),程序会捕获到 Timeout 异常,并打印 “Request timed out” |
| except 块 - HTTPError | 如果响应的状态码表明出现 HTTP 错误(例如 404 表示未找到页面 ),程序会捕获到 HTTPError 异常,并打印相关错误信息 |
| except 块 - RequestException | 捕获其他类型的网络相关错误(如连接问题、DNS 解析失败等 )。RequestException 是所有 requests 库异常的基类,可以捕获任何 requests 库抛出的异常 |
| finally 块 | finally 中的代码无论是否发生异常都会被执行,通常用于释放资源或做一些收尾工作。这里我们仅打印 “Request attempt completed.” 表示请求的结束 |
| 异常处理总结 - 作用 | 异常处理让我们在程序运行中捕获到错误并做出相应处理,避免程序崩溃 |
| 异常处理总结 - 实现 | 通过 try...except 结构,可以精确捕获并处理不同类型的异常 |
| 异常处理总结 - finally 作用 | finally 块用于清理工作,在请求处理完成后可以释放资源(如关闭文件、数据库连接等 ) |