C++ STL之deque的使用和模拟实现
目录
deque
核心本质与定位
与stack和queue的关系:
deque的使用
deque的底层实现
deque的原理介绍
deque的缺陷
总结:
deque
deque文档 : deque
翻译:
双端队列
- deque(通常发音类似“deck”)是“double-ended queue”(双端队列)的非常规缩写。双端队列是动态大小的序列容器,可在两端(前端或后端)进行扩展或收缩操作。
- 具体的库可能会以不同方式实现 deque,一般是某种形式的动态数组。但无论如何,它们允许通过随机访问迭代器直接访问单个元素,并且容器会根据需要自动扩展或收缩来管理存储。
- 因此,它们提供的功能与 vector 类似,但在序列的开头也能高效地插入和删除元素,而不仅仅是在末尾。但与 vector 不同的是,deque 不保证所有元素都存储在连续的内存位置:通过偏移一个元素的指针来访问 deque 中的其他元素会导致未定义行为。
- vector 和 deque 提供的接口非常相似,可用于类似的场景,但在内部工作方式上有很大不同:
- vector 使用需要偶尔重新分配的单个数组来实现增长,而 deque 的元素可以分散在不同的存储块中,容器在内部保存必要的信息,以常数时间直接访问任何元素,并通过迭代器提供统一的顺序接口。因此,deque 在内部比 vector 更复杂,但这使得它在某些情况下(尤其是超长序列,重新分配开销更大时)能更高效地增长。
- 对于需要频繁在开头或末尾之外的位置插入或删除元素的操作,deque 的表现比 list 和 forward_list 更差,且迭代器和引用的一致性也更弱。
在 C++ STL 中,deque(双端队列,Double-Ended Queue) 是核心的序列式容器之一,设计目标是平衡“两端高效操作”与“随机访问”能力,填补了 vector(尾部高效、头部低效)和 list(两端高效、无随机访问)的功能空白。虽然它名字里有队列,但是并不是队列,并不要求先进先出。
核心本质与定位
- 基础容器而非适配器:deque 是直接管理内存和元素的底层容器,与 vector、list 同级,不属于 stack/queue 这类“封装底层容器的适配器”,能独立提供完整的元素操作接口。
- 功能核心:以 O(1) 时间复杂度实现头部和尾部的插入/删除操作,同时支持 O(1) 随机访问(像 vector 一样用 [] 下标访问元素),是兼顾“两端灵活性”和“访问效率”的中间选择。
与stack和queue的关系:
在上篇文章中,在介绍stack和queue时就提到了deque,deque 是 stack 和 queue 的“默认底层实现”,在 C++ 中,stack、queue 与 deque 的核心关系是 “容器适配器”与“默认底层基础容器”的依赖关系,具体可拆解为两点:
1. deque 是 stack 和 queue 的“默认底层实现”
stack(栈)和 queue(队列)本身不存储元素,必须依赖一个基础容器来管理数据,而 deque 是 STL 为它们预设的默认底层容器。
- 当你直接定义 stack<int> s; 或 queue<int> q; 时,底层实际是用 deque 来存储元素的,相当于 stack<int, deque<int>> s; 和 queue<int, deque<int>> q; 。
- 选择 deque 作为默认的原因:deque 支持 O(1) 时间复杂度的两端操作(头部/尾部插入/删除),刚好匹配 stack(仅需栈顶,即 deque 尾部操作)和 queue(需队尾插入、队首删除)的功能需求,且比 vector(头部操作低效)、list(无随机访问)更适配。
2. 三者本质不同:适配器 vs 基础容器
- stack/queue:是“容器适配器”,作用是“封装底层容器的接口”,强制特定的数据访问规则(stack 先进后出、queue 先进先出),自身不具备元素存储和内存管理能力。
- deque:是“基础序列容器”,能独立管理元素存储和内存,提供完整的元素操作接口(如随机访问、两端/中间操作),是 stack/queue 实现功能的“底层支撑”。
下面我们就来详细学习deque的主要内容:
deque的使用
deque 、 vector 和 list 均作为 STL 基础序列容器,在成员函数上的共同点主要有以下几类:
- 元素增删(基础):都支持 push_back (尾部添加元素)和 pop_back (尾部删除元素)操作;也都提供 clear 函数用于清空容器内所有元素。
- 状态查询:均包含 empty 函数判断容器是否为空, size 函数获取容器内元素的个数。
- 迭代器遍历:都提供 begin 、 end 用于正向遍历元素, rbegin 、 rend 用于反向遍历元素。
- 元素访问(部分):都支持 front 获取容器头部元素的引用, back 获取容器尾部元素的引用。
- 赋值与交换:都实现了 operator= 用于容器间的赋值操作,也都有 swap 函数用于交换两个同类型容器的元素。
#include<deque>
#include<iostream>
using namespace std;void test_deque()
{deque<int> dp;//尾插dp.push_back(1);dp.push_back(2);dp.push_back(3);dp.push_back(4);//头插dp.push_front(10);dp.push_front(20);dp.push_front(30);dp.push_front(40);//尾删dp.pop_back();//头删dp.pop_front();//随机访问for (size_t i = 0; i < dp.size(); i++){cout << dp[i] <<" ";}cout << endl;
}
int main()
{test_deque();return 0;
}
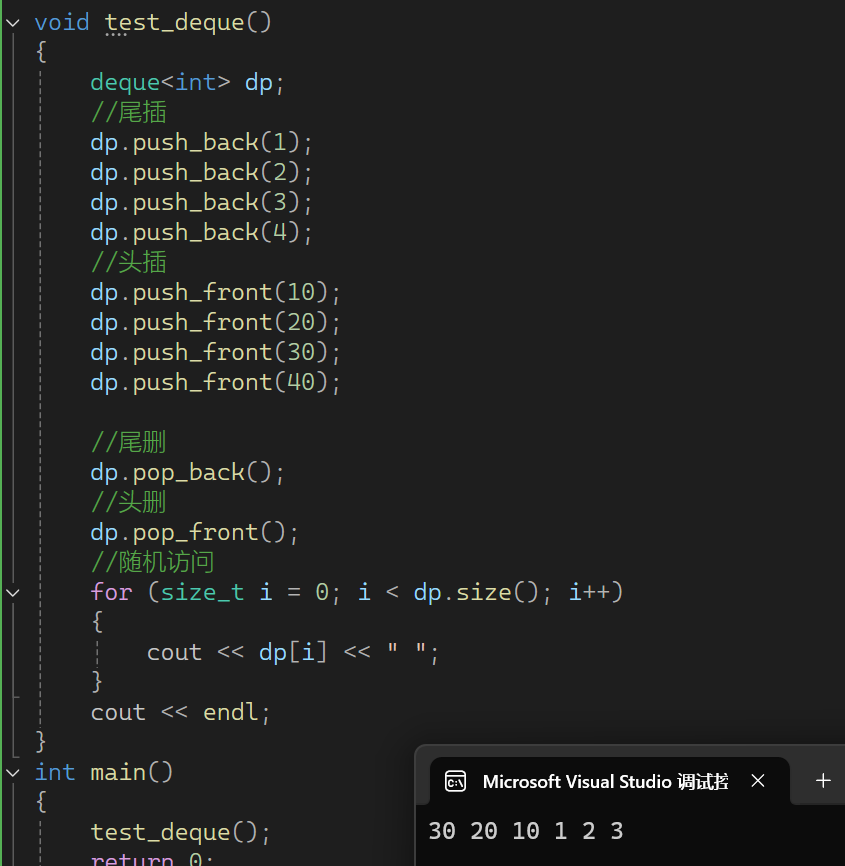
可以看到它既支持头插尾插,又支持头删尾删,还支持随机访问,它融合了vector和list的优点,从使用的角度,避开了它们各自的缺点:
- list的缺点:不支持随机访问
- vector的缺点:头部和中间插入删除效率低
deque的底层实现
deque 、 vector 和 list 均作为 STL 基础序列容器,它们之间究竟有什么区别呢 ? 首先我们来看一下vector和list的优缺点:
vector
核心特点:
- 基于连续内存空间存储,支持随机访问(通过下标 [] 或 at() 直接定位元素)。
- 元素在内存中紧密排列,尾部增删效率高,中间/头部增删效率低。
- 容量(capacity)会自动扩容(通常扩容为原容量的1.5-2倍),扩容时需拷贝旧元素到新内存,可能产生性能开销。
优点:
- 1. 随机访问速度快(时间复杂度 O(1)),适合需要频繁通过下标读取元素的场景(如数组遍历、索引访问)。
- 2. 内存缓存利用率高(连续内存易被CPU缓存命中),遍历元素时速度比 list 快。
- 3. 尾部 push_back / pop_back 操作高效(O(1),无内存移动)。
- 4. 接口简洁,支持 reserve() 预分配容量,避免频繁扩容,优化性能。
缺点:
- 1. 中间或头部插入/删除元素效率低(O(n)):需移动插入点后所有元素,内存移动开销大。
- 2. 扩容时可能浪费内存(扩容后的容量大于实际元素个数),且拷贝旧元素会产生额外性能消耗。
- 3. 不适合存储大量大型对象(扩容时拷贝大型对象开销高),也不适合频繁修改中间元素的场景。
list
核心特点:
- 基于非连续内存空间存储,元素通过前后指针连接,不支持随机访问。
- 元素在内存中分散存储,任意位置增删效率高,访问元素需从头/尾遍历。
- 无容量概念,元素增删时直接分配/释放单个节点内存,无需扩容和拷贝。
优点:
- 1. 任意位置(头部、中间、尾部)插入/删除元素效率高(时间复杂度 O(1)):只需修改对应节点的指针,无需移动其他元素。
- 2. 无扩容开销,内存分配灵活,不会浪费内存(每个元素按需分配节点)。
- 3. 适合频繁在中间位置增删元素的场景(如链表结构、频繁插入的队列)。
缺点:
- 1. 不支持随机访问(访问指定元素需遍历链表,时间复杂度 O(n)),无法通过下标快速定位元素。
- 2. 内存缓存利用率低(非连续内存难被CPU缓存命中),遍历元素时速度比 vector 慢。
- 3. 每个元素需额外存储前后指针,内存开销比 vector 大(存储相同数量元素时, list 占用更多内存)。
- 4. 不支持 reserve() 预分配内存,也无法通过下标访问,功能比 vector 受限。
结合上面deque的使用,我们可以看出deque既支持头插尾插,又支持头删尾删,还支持随机访问,它融合了vector和list的优点,从使用的角度,避开了它们各自的缺点,如果deque真的像上面说的那么优秀,那么vector和list可能就被淘汰了。
其实,deque还是有缺陷的,它的底层怎么实现的呢?
deque的原理介绍
deque(双端队列):是一种双开口的"连续"空间的数据结构,双开口的含义是:可以在头尾两端 进行插入和删除操作,且时间复杂度为O(1),与vector比较,头插效率高,不需要搬移元素;与 list比较,空间利用率比较高。
deque并不是真正连续的空间,而是由一段段连续的小空间拼接而成的,实际deque类似于一个 动态的二维数组,其底层结构如下图所示:
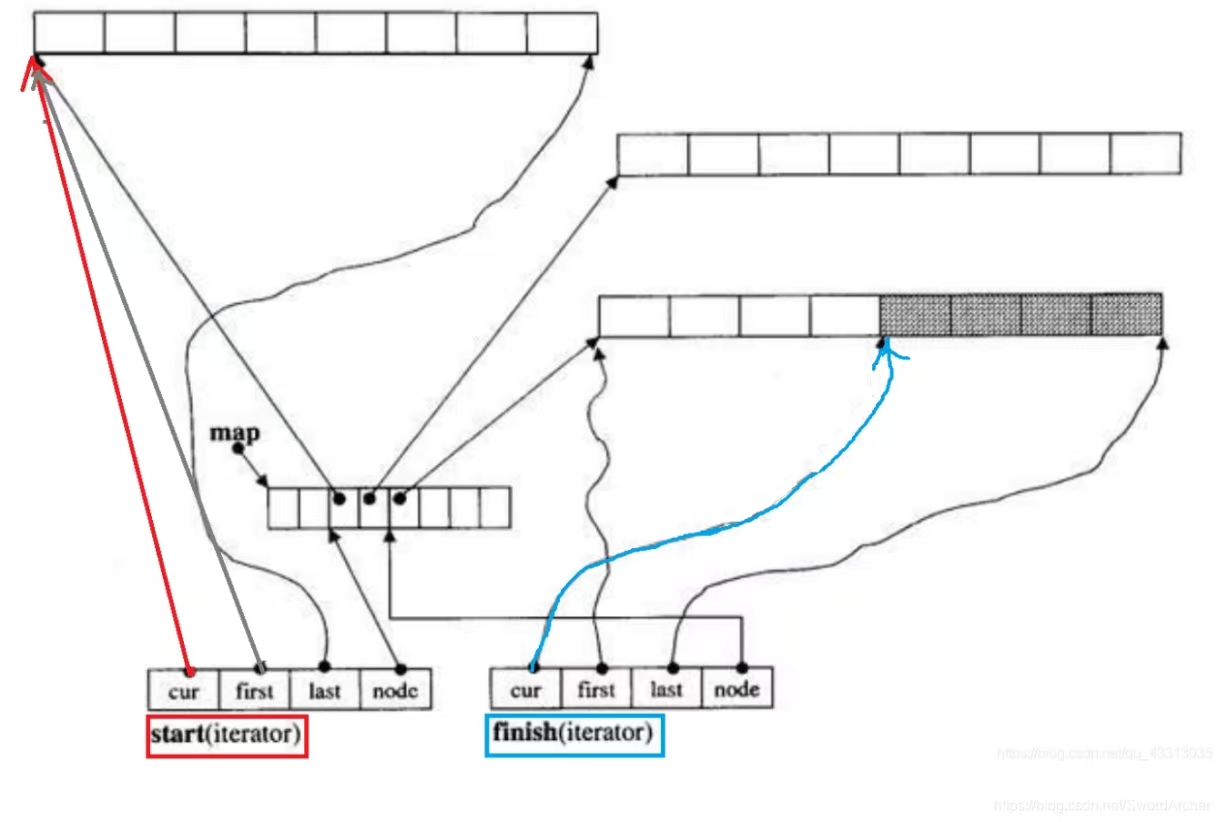
这张图准确展示了 deque(双端队列)的底层结构,核心由三部分组成:
- 中控器(map):是指针数组,每个指针指向一个缓冲区(buffer)(连续内存块),用于管理所有分段的内存。
- 缓冲区(buffer):多个分段的连续内存块,实际存储元素。图中不同缓冲区的填充状态体现了元素的分布(如中间缓冲区有部分元素已存储)。
- 迭代器(iterator):
- start(iterator) :标记 deque 的起始范围,由 cur (当前元素指针)、 first (起始缓冲区的起始指针)、 last (起始缓冲区的末尾指针)、 node (指向中控器对应节点的指针)组成。
- finish(iterator) :标记 deque 的末尾范围,结构与 start 一致,用于界定元素的结束位置。
这种结构的核心优势是:
- 双端操作高效:在起始缓冲区执行 push_front / pop_front ,在末尾缓冲区执行 push_back / pop_back ,均只需操作分段内存的两端,无需整体移动元素。
- 随机访问可行:通过中控器的指针数组快速定位目标元素所在的缓冲区,再结合迭代器的 cur 指针偏移,实现 O(1) 时间的随机访问。
双端队列底层是一段假象的连续空间,实际是分段连续的,为了维护其“整体连续”以及随机访问 的假象,落在了deque的迭代器身上,因此deque的迭代器设计就比较复杂,如下图所示:
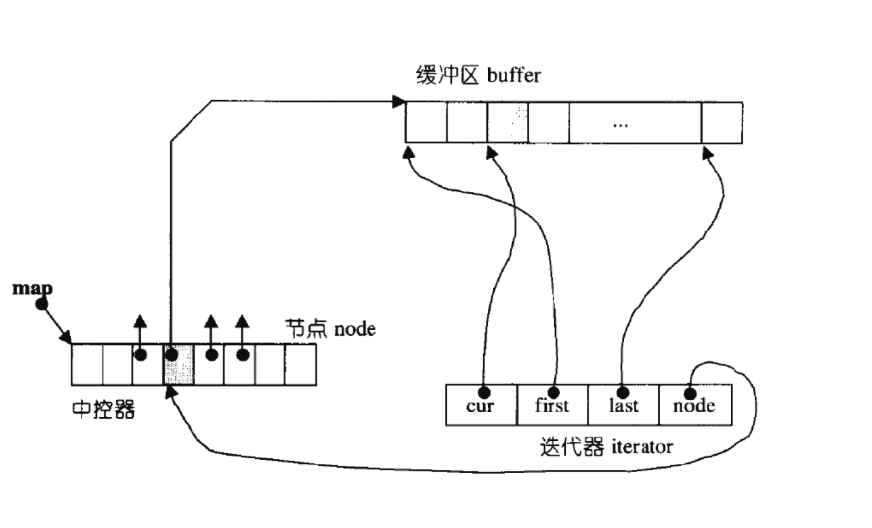
- 中控器(map):一个指针数组,每个指针指向一块连续的内存区域(称为“缓冲区 buffer”)。
- 缓冲区(buffer):分段的连续内存块,用于实际存储元素,解决了 vector 单一连续内存扩容时的拷贝开销问题。
- 迭代器(iterator):通过 cur (当前元素指针)、 first (缓冲区起始指针)、 last (缓冲区末尾指针)、 node (指向中控器对应节点的指针),实现跨分段的元素访问和迭代。
那deque是如何借助其迭代器维护其假想连续的结构呢?
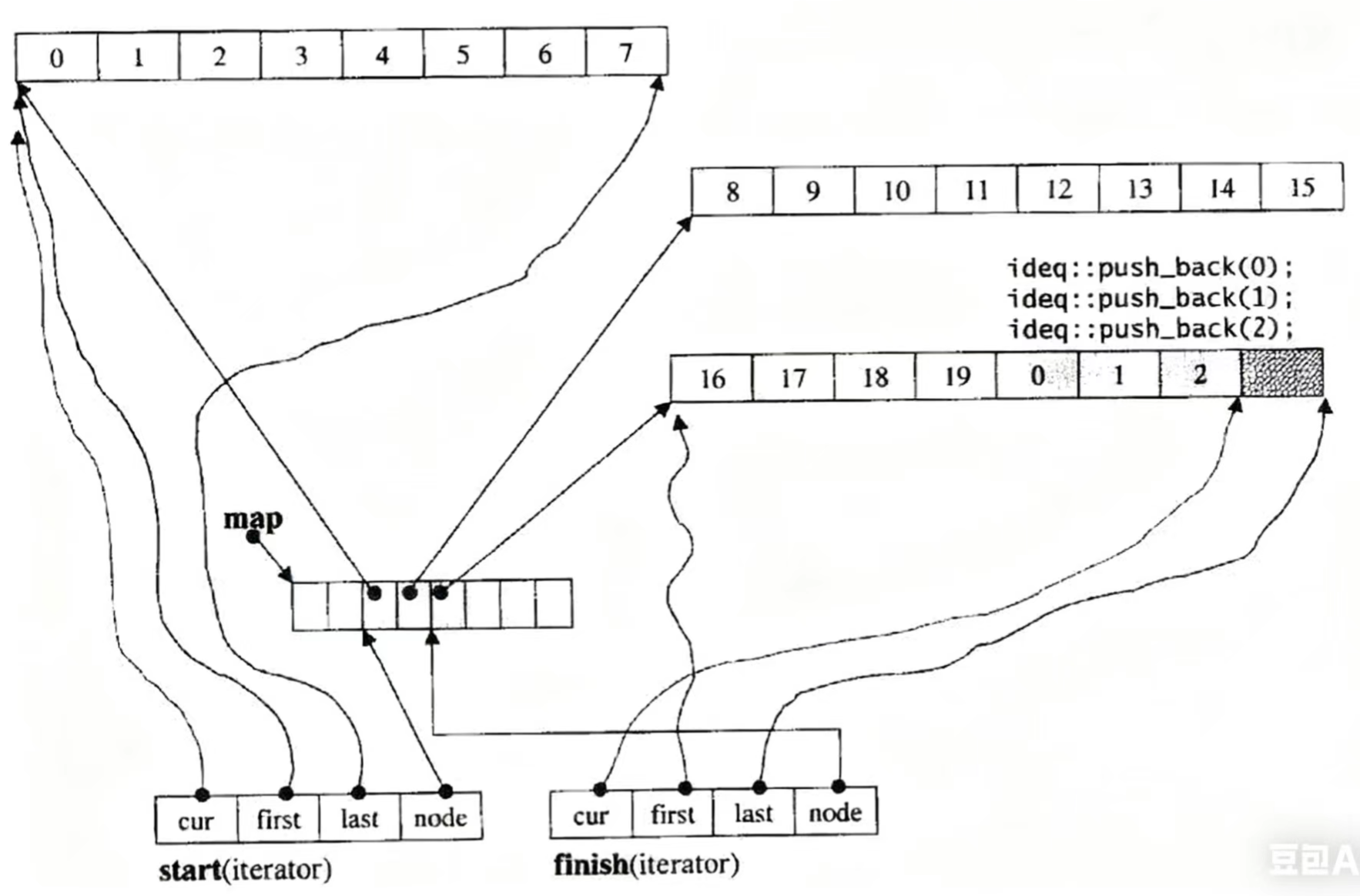
这张图通过可视化的方式,解释了 deque 执行 push_back (尾插)操作时的内部逻辑:
1. 缓冲区与中控器的配合:
deque 底层由多个缓冲区(buffer)(连续内存块)组成,这些缓冲区的地址由中控器(map,指针数组)管理。图中可以看到多个缓冲区(如存储 0-7、8-15、16-19 及后续元素的块),中控器的指针数组指向这些缓冲区的起始地址。
2. 尾插的执行流程:
当调用 push_back(0) 、 push_back(1) 、 push_back(2) 时:
- deque 会找到最末尾的缓冲区(图中存储 16-19 及后续元素的块)。
- 从该缓冲区的空闲位置开始依次插入元素 0、1、2。
- 若当前缓冲区已满,deque 会自动分配新的缓冲区,并通过中控器的指针数组维护新缓冲区的地址,保证后续尾插操作的连续性。
3. 迭代器的角色:
finish(iterator) 标记了 deque 的末尾范围,其内部的 cur 指针会随着尾插操作不断后移,始终指向“下一个可插入的位置”,从而维护了 deque“假想连续”的逻辑结构——尽管物理内存是分段的,但通过迭代器和中控器的配合,用户可以感知到元素是连续存储的。
简言之,这张图直观呈现了 deque 如何通过分段缓冲区 + 中控器管理 + 迭代器标记,实现高效的尾插操作,同时维持“逻辑连续”的抽象结构。
deque的缺陷
deque 虽然在双端操作和随机访问之间做了平衡,但也存在以下缺陷:
1. 中间操作效率低
在中间位置(非头部、非尾部)插入或删除元素时,需要移动该位置前后的元素,时间复杂度为 O(n),远不如 list(中间操作 O(1))高效。
2. 随机访问略逊于 vector
尽管支持随机访问,但由于内存是分段存储的,访问元素时需要先通过中控器定位到对应的缓冲区,再在缓冲区内偏移访问,实际速度比 vector(单一连续内存直接访问)稍慢。
3. 内存结构复杂
底层需要维护“中控器(map)+ 分段缓冲区”的结构,实现逻辑比 vector 和 list 更复杂,这也导致其迭代器的实现和维护成本较高。
4. 迭代器稳定性不足
当在 deque 的头部或尾部之外的位置进行插入/删除操作,或者因中控器扩容导致缓冲区地址变化时,迭代器可能会失效,稳定性不如 list(list 仅被删除节点的迭代器失效)。
5. 不适合大量中间操作场景
如果业务场景中需要频繁对中间元素进行增删,deque 的性能表现会明显不如 list;而如果需要频繁随机访问,又不如 vector 高效,存在一定的使用场景局限性。
与vector比较,deque的优势是:头部插入和删除时,不需要搬移元素,效率特别高,而且在扩 容时,也不需要搬移大量的元素,因此其效率是必vector高的。与list比较,其底层是连续空间,空间利用率比较高,不需要存储额外字段。但是,deque有一个致命缺陷:不适合遍历,因为在遍历时,deque的迭代器要频繁的去检测其 是否移动到某段小空间的边界,导致效率低下,而序列式场景中,可能需要经常遍历,因此在实 际中,需要线性结构时,大多数情况下优先考虑vector和list,deque的应用并不多,而目前能看 到的一个应用就是,STL用其作为stack和queue的底层数据结构。
stack是一种后进先出的特殊线性数据结构,因此只要具有push_back()和pop_back()操作的线性 结构,都可以作为stack的底层容器,比如vector和list都可以;queue是先进先出的特殊线性数据 结构,只要具有push_back和pop_front操作的线性结构,都可以作为queue的底层容器,比如 list。但是STL中对stack和queue默认选择deque作为其底层容器,主要是因为:
- 1. stack和queue不需要遍历(因此stack和queue没有迭代器),只需要在固定的一端或者两端进行操作。
- 2. 在stack中元素增长时,deque比vector的效率高(扩容时不需要搬移大量数据);queue中的 元素增长时,deque不仅效率高,而且内存使用率高。 结合了deque的优点,而完美的避开了其缺陷。
总结:
摘要: 双端队列deque是STL中的动态序列容器,支持两端高效插入/删除和随机访问,填补了vector和list的功能空白。其底层通过"中控器+分段缓冲区"实现,兼具vector的随机访问和list的双端操作优势,但中间操作效率较低。deque是stack和queue的默认底层容器,因其完美适配二者仅需单端或双端操作的特点。虽然deque平衡了功能与性能,但在实际应用中仍存在遍历效率低、中间操作慢等缺陷,通常在需要频繁随机访问时选择vector,频繁中间操作时选择list更为合适。
感谢大家的观看!