【大模型应用开发】基于langchain的大模型调用及简单RAG应用构建
零、背景知识介绍
1.langchain
LangChain 为基于 LLM 开发自定义应用提供了高效的开发框架,便于开发者迅速地激发 LLM 的强大能力,搭建 LLM 应用。LangChain 也同样支持多种大模型,内置了 OpenAI、LLAMA 等大模型的调用接口。但是,LangChain 并没有内置所有大模型,它通过允许用户自定义 LLM 类型,来提供强大的可扩展性。
官方文档:https://python.langchain.com/docs/introduction/
2.主流大模型API介绍
ChatGPT:需要科学上网,无免费额度;
文心一言:当前无赠送新用户 tokens 的活动,推荐已有文心 tokens 额度用户和付费用户使用;
讯飞星火:新用户赠送 tokens,推荐免费用户使用;
智谱 GLM:新用户赠送 tokens,推荐免费用户使用。
3.RAG介绍
RAG(Retrieval-Augmented Generation,检索增强生成) 是一种结合了信息检索技术与语言生成模型的人工智能技术。该技术通过从外部知识库中检索相关信息,并将其作为提示(Prompt)输入给大型语言模型(LLMs),以增强模型处理知识密集型任务的能力,如问答、文本摘要、内容生成等。
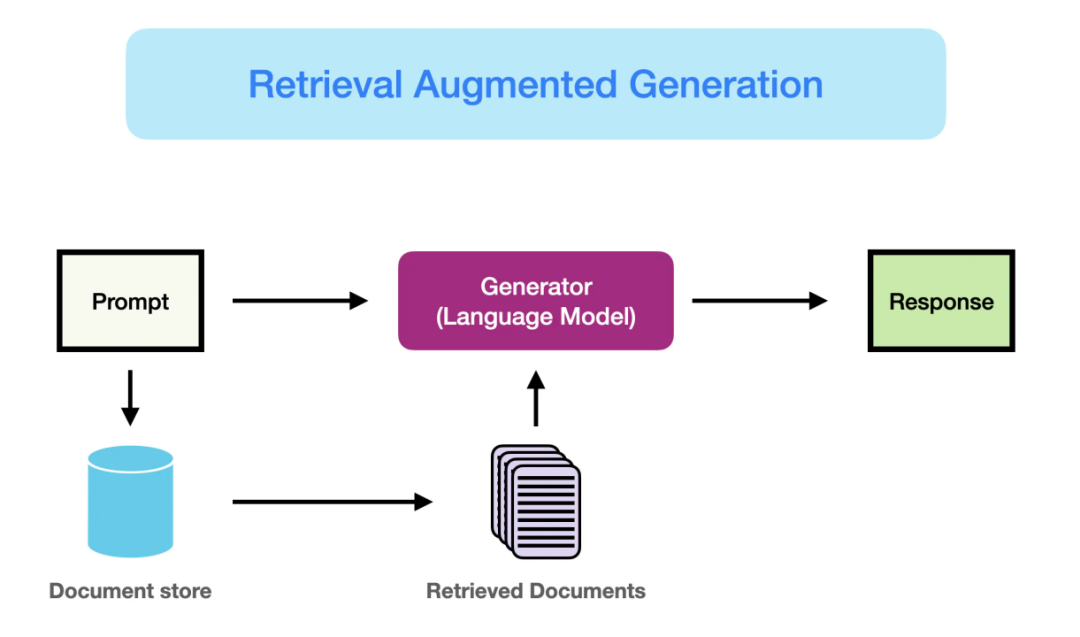
一、主流大模型API调用
1.调用 OpenAI API
from openai import OpenAIclient = OpenAI(# This is the default and can be omittedapi_key="your-apikey"
)# 导入所需库
# 注意,此处我们假设你已根据上文配置了 OpenAI API Key,如没有将访问失败
completion = client.chat.completions.create(# 调用模型:ChatGPT-4omodel="gpt-4o",# messages 是对话列表messages=[{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": "Hello!"}]
)
2.调用 智谱ChatGLM
from zhipuai import ZhipuAIclient = ZhipuAI(api_key="your-apikey"
)def gen_glm_params(prompt):'''构造 GLM 模型请求参数 messages请求参数:prompt: 对应的用户提示词'''messages = [{"role": "user", "content": prompt}]return messagesdef get_completion(prompt, model="glm-4-plus", temperature=0.95):'''获取 GLM 模型调用结果请求参数:prompt: 对应的提示词model: 调用的模型,默认为 glm-4,也可以按需选择 glm-3-turbo 等其他模型temperature: 模型输出的温度系数,控制输出的随机程度,取值范围是 0.0-1.0。温度系数越低,输出内容越一致。'''messages = gen_glm_params(prompt)response = client.chat.completions.create(model=model,messages=messages,temperature=temperature)if len(response.choices) > 0:return response.choices[0].message.contentreturn "generate answer error"
二、简单RAG应用构建
1.向量知识库库搭建
(1)词向量及向量数据库介绍
词向量:在机器学习和自然语言处理(NLP)中,词向量(word embedding)是一种以单词为单位将每个单词转化为实数向量的技术。这些实数向量可以被计算机更好地理解和处理。词向量背后的主要想理念是相似或相关的对象在向量空间中的距离应该很近。
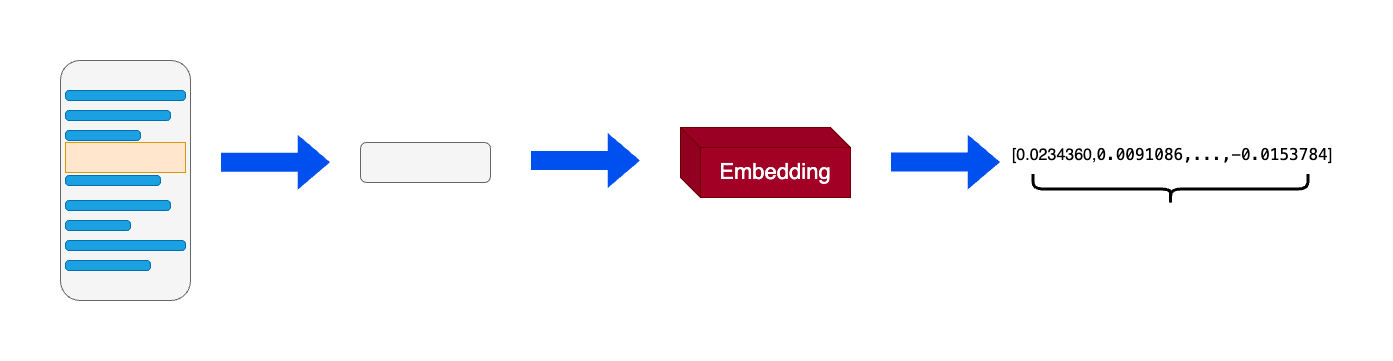
向量数据库:向量数据库是用于高效计算和管理大量向量数据的解决方案。向量数据库是一种专门用于存储和检索向量数据(embedding)的数据库系统。它与传统的基于关系模型的数据库不同,它主要关注的是向量数据的特性和相似性。在向量数据库中,数据被表示为向量形式,每个向量代表一个数据项。这些向量可以是数字、文本、图像或其他类型的数据。向量数据库使用高效的索引和查询算法来加速向量数据的存储和检索过程。
(2)数据处理
该部分需要针对不同的数据使用不同的数据处理方法,主要是去除无用数据,规范化有用数据
(3)数据向量化及搭建向量数据库
# 1.读取数据
import os
# 获取folder_path下所有文件路径,储存在file_paths里
file_paths = []
folder_path = 'data_base/knowledge_db'
for root, dirs, files in os.walk(folder_path):for file in files:file_path = os.path.join(root, file)file_paths.append(file_path)
print(file_paths[:5])from langchain_community.document_loaders import PyMuPDFLoader
from langchain_community.document_loaders import UnstructuredMarkdownLoader
from langchain_community.document_loaders import TextLoader# 遍历文件路径并把实例化的loader存放在loaders里
loaders = []for file_path in file_paths:file_type = file_path.split('.')[-1]if file_type == 'pdf':loaders.append(PyMuPDFLoader(file_path))elif file_type == 'md':loaders.append(UnstructuredMarkdownLoader(file_path))elif file_type == "txt":# 添加 encoding='utf-8',如果失败可以换成 'gbk'try:loaders.append(TextLoader(file_path, encoding='utf-8'))except UnicodeDecodeError:loaders.append(TextLoader(file_path, encoding='gbk'))# 下载文件并存储到text
texts = []
for loader in loaders: texts.extend(loader.load())
text = texts[1]
print(f"每一个元素的类型:{type(text)}.",f"该文档的描述性数据:{text.metadata}",f"查看该文档的内容:\n{text.page_content[0:]}",sep="\n------\n")from langchain_text_splitters import RecursiveCharacterTextSplitter# 切分文档
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
split_docs = text_splitter.split_documents(texts)# 2.使用智谱的embedding-3进行向量化操作
from zhipuai import ZhipuAI
from zhipu_embedding import ZhipuAIEmbeddings
def zhipu_embedding(text: str):api_key = "3cbdc9439e9543db9e7e0ea39871f9fb.LInKSkE8QGbU6k2K"client = ZhipuAI(api_key=api_key)response = client.embeddings.create(model="embedding-3",input=text,)return response
embedding = ZhipuAIEmbeddings()# 3.构建chroma向量库
from langchain_community.vectorstores import Chroma
# 定义持久化路径
persist_directory = 'data_base/vector_db/chroma'
vectordb = Chroma.from_documents(documents=split_docs,embedding=embedding,persist_directory=persist_directory # 允许我们将persist_directory目录保存到磁盘上
)
print(f"向量库中存储的数量:{vectordb._collection.count()}")
(4)向量数据库调用及结果显示

2.大模型API调用
#2.创建llm
# 智谱api调用
from langchain_community.chat_models import ChatZhipuAIchatglm = ChatZhipuAI(temperature=0.5,api_key="3cbdc9439e9543db9e7e0ea39871f9fb.LInKSkE8QGbU6k2K",model_name="glm-3-turbo",
)
# 测试
# print(chatglm.invoke("请介绍一下你自己").content)
3.构建检索问答链
# 3.创建检索链
from langchain_core.runnables import RunnableLambda
def combine_docs(docs):return "\n\n".join(doc.page_content for doc in docs)
combiner = RunnableLambda(combine_docs)
retriever = vectordb.as_retriever(search_kwargs={"k": 3})
retrieval_chain = retriever | combiner# 4.创建检索问答链
from langchain_core.prompts import PromptTemplate
from langchain_core.runnables import RunnablePassthrough, RunnableParallel
from langchain_core.output_parsers import StrOutputParser
template = """使用以下上下文来回答最后的问题。如果你不知道答案,就说你不知道,不要试图编造答
案。最多使用三句话。尽量使答案简明扼要。请你在回答的最后说“谢谢你的提问!”。
{context}
问题: {input}
"""
# 将template通过 PromptTemplate 转为可以在LCEL中使用的类型
prompt = PromptTemplate(template=template)
qa_chain = (RunnableParallel({"context": retrieval_chain, "input": RunnablePassthrough()})| prompt| chatglm| StrOutputParser()
)# 检索问答链效果测试
question_1="什么是南瓜书"
question_2="介绍一下天度公司"
result = qa_chain.invoke(question_1)
print("大模型+知识库后回答 question_1 的结果:")
print(result)
result = qa_chain.invoke(question_2)
print("大模型+知识库后回答 question_2 的结果:")
print(result)
print("**********************************")
print("大模型回答 question_1 的结果:"+chatglm.invoke(question_1).content)
print("大模型回答 question_2 的结果:"+chatglm.invoke(question_2).content)
4.生成结果对比
问题一测试结果:

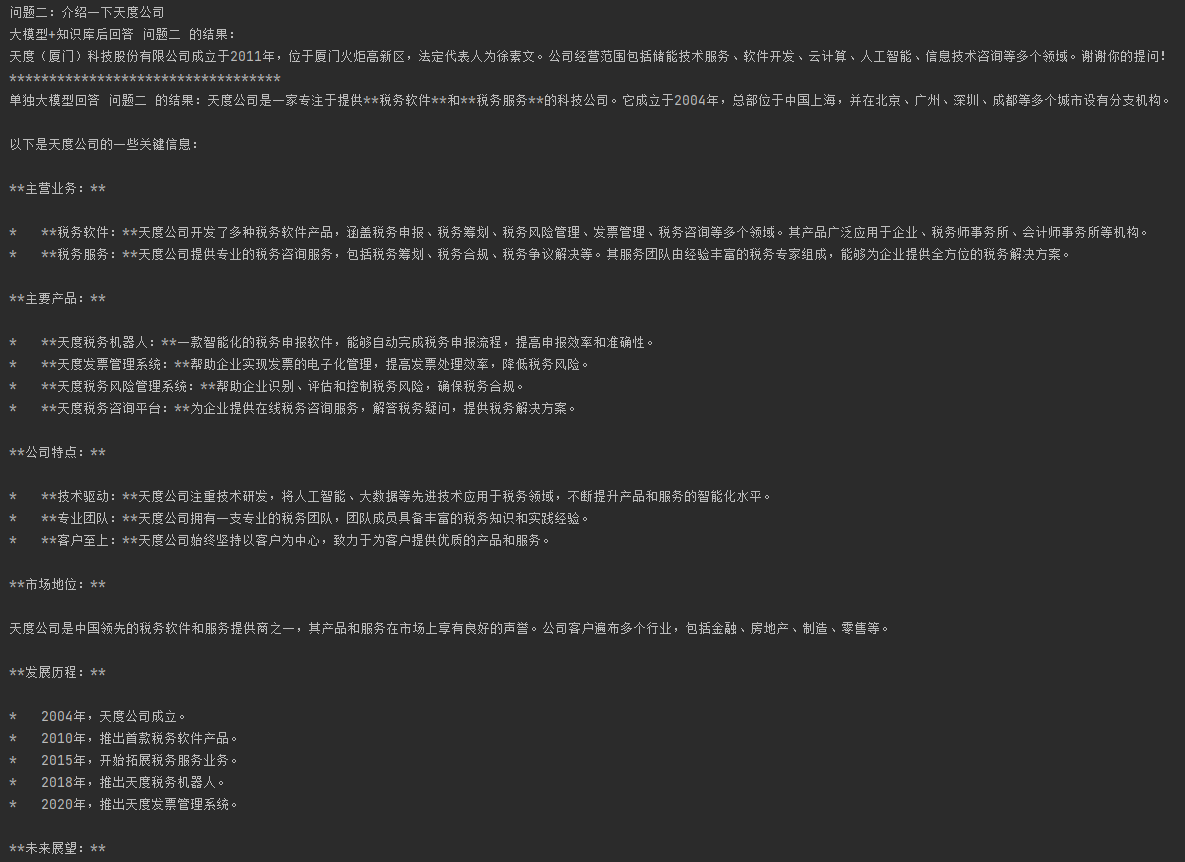
问题二测试结果:
5.RAG应用完整代码
# 1.加载先前构建的好的向量数据库
from zhipu_embedding import ZhipuAIEmbeddings
from langchain.vectorstores.chroma import Chroma# 定义 Embeddings
embedding = ZhipuAIEmbeddings()# 向量数据库持久化路径
persist_directory = 'data_base/vector_db/chroma'# 加载数据库
vectordb = Chroma(persist_directory=persist_directory, # 允许我们将persist_directory目录保存到磁盘上embedding_function=embedding
)
# 向量库测试
# print(f"向量库中存储的数量:{vectordb._collection.count()}")
# question = "什么是南瓜书?"
# retriever = vectordb.as_retriever(search_kwargs={"k": 3})
# docs = retriever.invoke(question)
# print(f"检索到的内容数:{len(docs)}")
# for i, doc in enumerate(docs):
# print(f"检索到的第{i}个内容: \n {doc.page_content}", end="\n-----------------------------------------------------\n")# 2.创建检索链
from langchain_core.runnables import RunnableLambdadef combine_docs(docs):return "\n\n".join(doc.page_content for doc in docs)
combiner = RunnableLambda(combine_docs)
retriever = vectordb.as_retriever(search_kwargs={"k": 3})
retrieval_chain = retriever | combiner#2.创建llm
# 智谱api调用
from langchain_community.chat_models import ChatZhipuAIchatglm = ChatZhipuAI(temperature=0.5,api_key="3cbdc9439e9543db9e7e0ea39871f9fb.LInKSkE8QGbU6k2K",model_name="glm-3-turbo",
)
# 测试
# print(chatglm.invoke("请介绍一下你自己").content)# 3.创建检索链
from langchain_core.runnables import RunnableLambda
def combine_docs(docs):return "\n\n".join(doc.page_content for doc in docs)
combiner = RunnableLambda(combine_docs)
retriever = vectordb.as_retriever(search_kwargs={"k": 3})
retrieval_chain = retriever | combiner# 4.创建检索问答链
from langchain_core.prompts import PromptTemplate
from langchain_core.runnables import RunnablePassthrough, RunnableParallel
from langchain_core.output_parsers import StrOutputParser
template = """使用以下上下文来回答最后的问题。如果你不知道答案,就说你不知道,不要试图编造答
案。最多使用三句话。尽量使答案简明扼要。请你在回答的最后说“谢谢你的提问!”。
{context}
问题: {input}
"""
# 将template通过 PromptTemplate 转为可以在LCEL中使用的类型
prompt = PromptTemplate(template=template)
qa_chain = (RunnableParallel({"context": retrieval_chain, "input": RunnablePassthrough()})| prompt| chatglm| StrOutputParser()
)# 检索问答链效果测试
question_1="什么是南瓜书"
question_2="介绍一下天度公司"
result = qa_chain.invoke(question_1)
print(f"问题一:{question_1}")
print("大模型+知识库后回答 问题一 的结果:")
print(result)
print("**********************************")
print("单独大模型回答 问题一 的结果:"+chatglm.invoke(question_1).content)
result = qa_chain.invoke(question_2)
print(f"问题二:{question_2}")
print("大模型+知识库后回答 问题二 的结果:")
print(result)
print("**********************************")
print("单独大模型回答 问题二 的结果:"+chatglm.invoke(question_2).content)