MySQL 索引学习笔记
1.二叉树,红黑树,B 树,B+树
二叉树:就是每个节点最多只能有两个子节点的树;
红黑树:就是自平衡二叉搜索树,红黑树通过一下五个规则构建:
1.节点只能是红色或黑色;
2.根节点只能是黑色;
3.不能有连续的红色节点;
4.叶子节点为黑色;
5.从任意节点到其所有叶子节点的路径上,黑色节点数相同,黑稿平衡
B 树:多路平衡搜索树,所有节点都存储数据;
B+树:非叶子节点只存键,数据全部存在叶子节点;
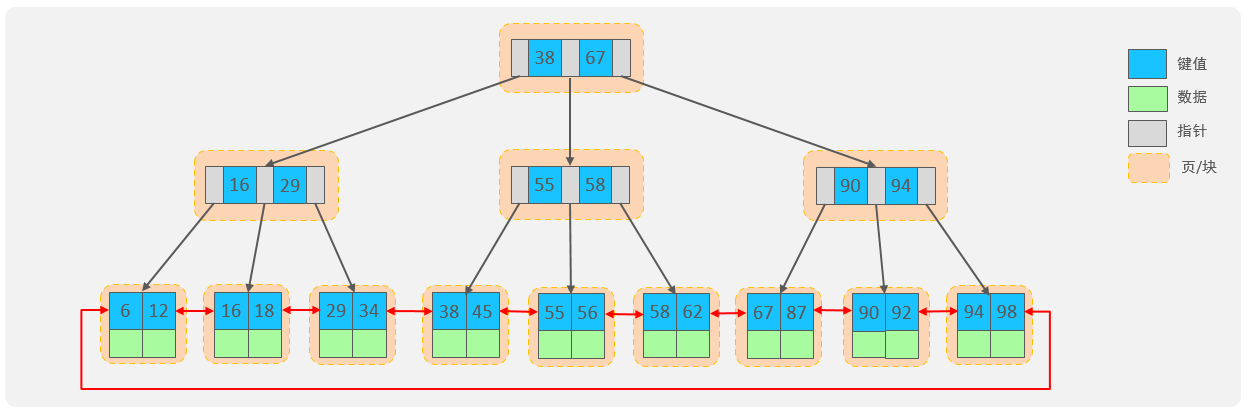
2.索引的底层数据结构了解过嘛 ?
索引的底层数据结构采用了 B+树加双向链表的形式实现,N 阶 B 树其实就是每个节点最多存储 N - 1 个键值对和 N 个指针,指向某个键值对的一边,而 N 阶 B+ 树其实就是每个节点最多存储 N - 1 个键和 N 个指针 ,只有叶子节点才存储键值,一旦一个节点存储的 Key 大于 N,中间元素会向上分裂;
而在索引中的 B+ 树就是在叶子节点之间构成一个双向链表,用于范围查询。
3.什么是聚簇索引什么是非聚簇索引 ?
聚簇索引:一个表只能有一个聚簇索引,聚簇索引的叶子节点直接存储行数据,主键默认是聚簇索引,如果没有主键则隐式构建 ROWID,优点是通过索引就可以获取到数据,避免了回表查询,缺点是插入速度依赖主键顺序;
非聚簇索引:就是索引的叶子节点只存主键值,而非完整的数据,一个表可以有多个非聚簇索引,通过索引找到主键后,需要回到聚簇索引获取完整数据。
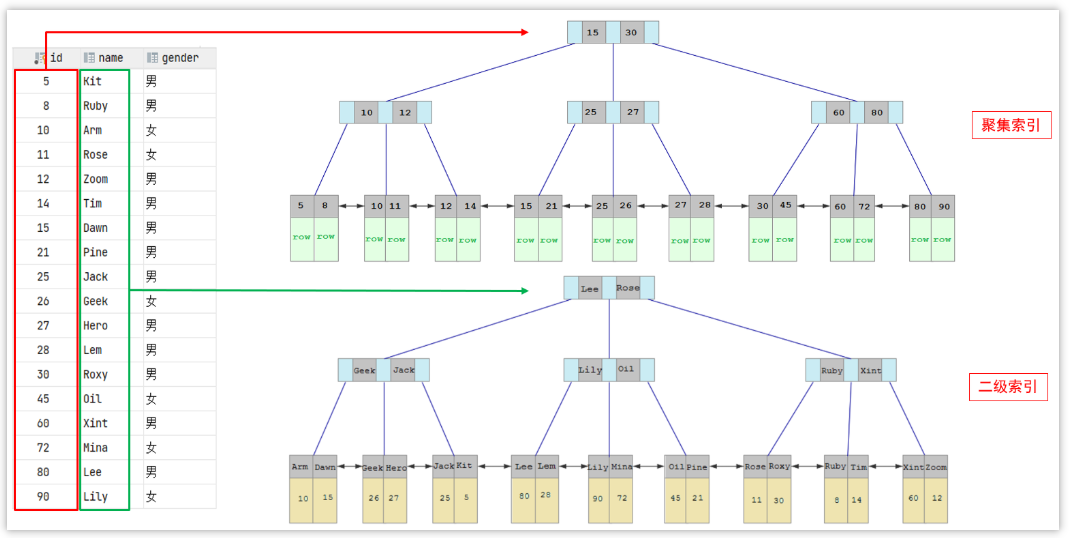
4.知道什么是回表查询嘛 ?
回表查询是查询数据时通过非聚簇索引进行查询,查询出来的只是数据的主键,还需要通过主键去查询聚簇索引,才能得到完整的数据。
5.索引创建原则有哪些?
1.高频查询字段:where,on,order by,group by 等高频使用的字段;
2.高区分度字段:使用由高区分度的字段,ID,身份证而不是性别;
3.短字段优先:使用整型而不是 VARCHAR;
4.覆盖索引优化:高频查询字段,可以建立联合索引覆盖查询字段,达到不用回表查询的目的;
5.范围查询字段放最后:将范围查询字段放最后,避免索引失效;
6.最左前缀匹配原则:只能最左前缀匹配,避免中间断开;
6.知道什么是左前缀原则嘛 ?
如果索引了多列(联合索引),要遵守最左前缀法则。最左前缀法则指的是查询
从索引的最左列开始,并且不跳过索引中的列。如果跳跃某一列,索引将会部分
失效(后面的字段索引失效)。
7.知道什么叫覆盖索引嘛 ?
覆盖索引是指查询使用了索引,并且需要返回的列,在该索引中已经全部能够找到 。
8.索引是越多越好嘛? 什么样的字段需要建索引, 什么样的字段不需要?
索引并不是多多益善,索引越多,维护索引结构的代价也就越大,会影响增删改的效率。针对于数据量较大,且查询比较频繁的表建立索引。
针对于常作为查询条件(where)、排序(order by)、分组(group by)操作的字段建立索引。
不适合创建索引的字段:
-
-
- 更新频繁字段不适合创建索引
- 若是不能有效区分数据的列不适合做索引列(如性别,男女未知,最多也就三种,区分度实在太低)
- 对于那些查询中很少涉及的列,重复值比较多的列不要建立索引。比如省会,城市、月份
- 对于定义为text、image和bit的数据类型的列不要建立索引
-