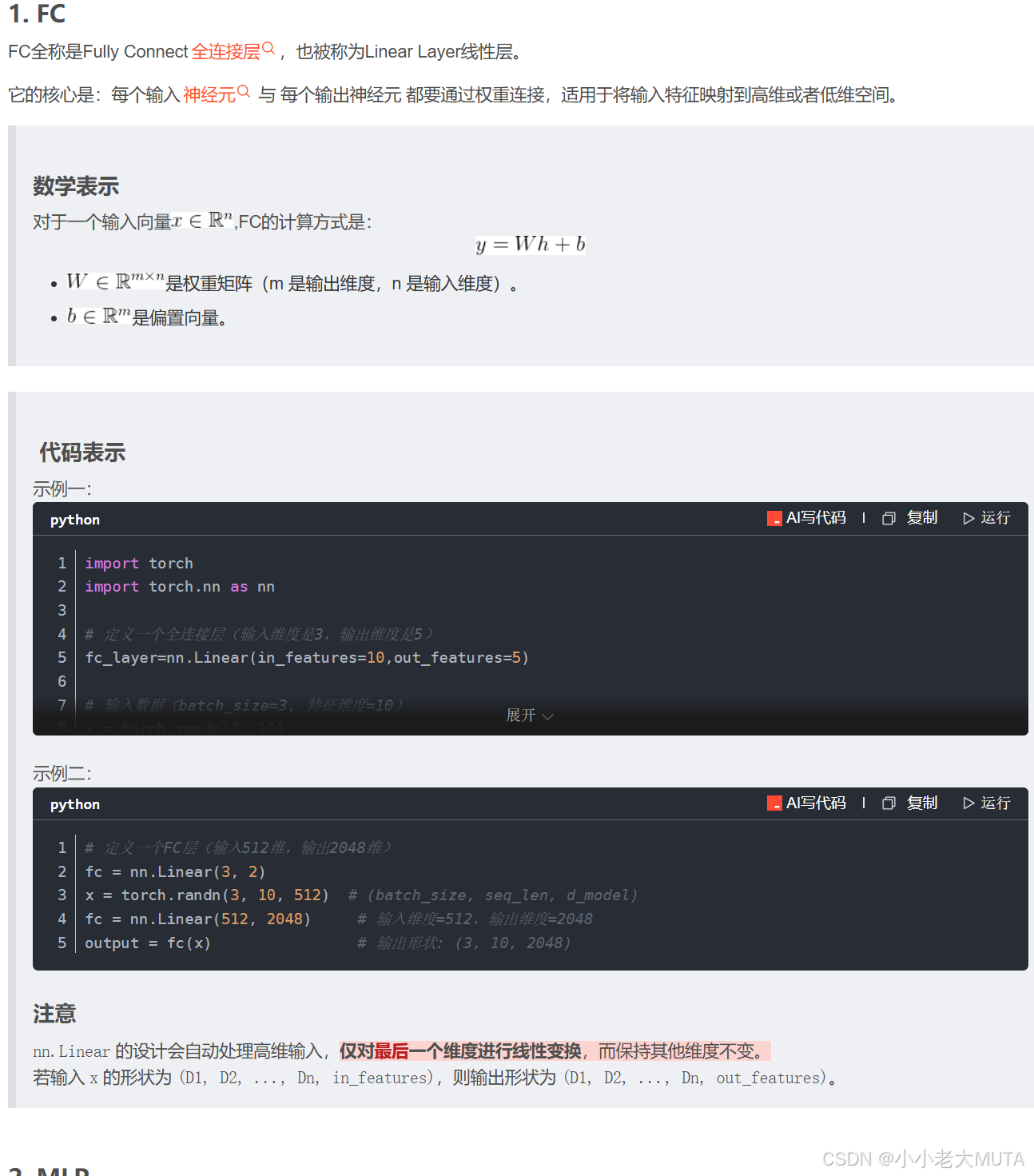
通道注意力机制
知识点:
通道注意力机制 Channel Attention Model CAM;
自适应池化层(Adaptive Pooling Layer);
全局平均池化(Global Average Pooling );
全局最大池化(Global Max Pooling);
nn.linear 全连接层操作;
参考博客: 通俗易懂理解通道注意力机制(CAM)与空间注意力机制(SAM)-CSDN博客
容易忽略的认知!!
不管是通道注意力机制还是空间注意力机制,他都是为了得到一个权重 然后和 原来特征图相乘。

自适应池化层
nn.AdaptiveAvgPool2d(1)和nn.AdaptiveMaxPool2d(1)都是 自适应池化层(Adaptive Pooling Layer),它们分别实现了 自适应平均池化 和 自适应最大池化。这两种池化方法的目标是将输入的特征图(tensor)调整为指定的输出大小(在这里是 1x1)。不过它们使用不同的池化方法:平均池化和最大池化。
平均池化和最大池化分别适用于什么场景呢?_平均池化和最大池化的特点和区别-CSDN博客
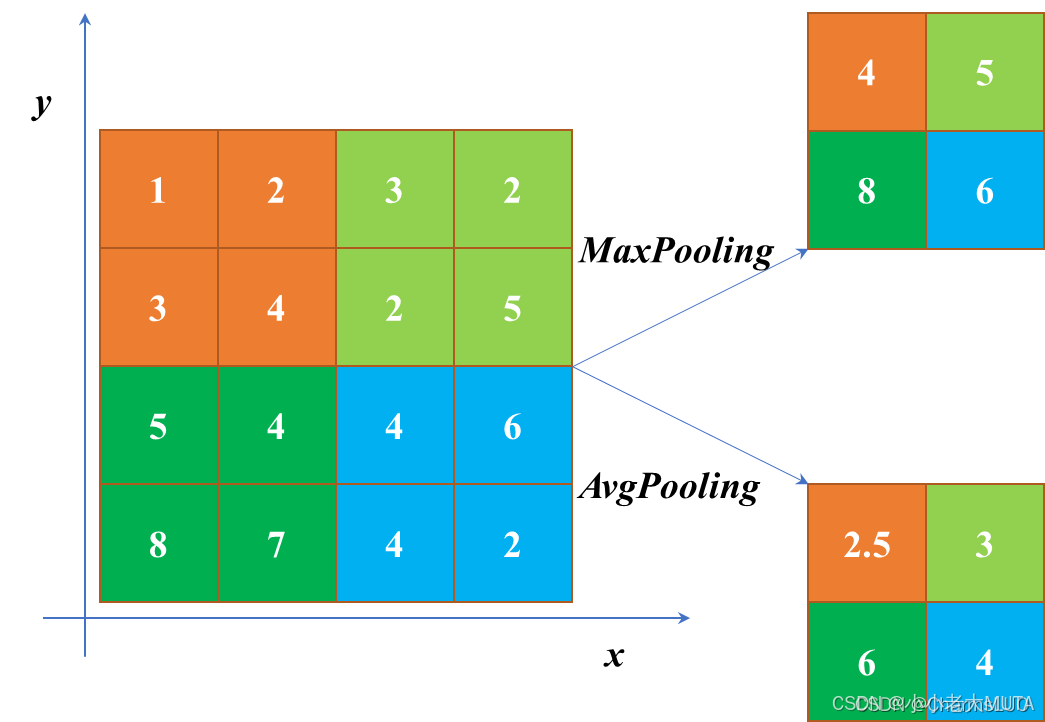
平均池化
使用场景:常用于 特征汇聚,如 全局特征提取,可以将图像的所有空间信息汇聚成一个标量。广泛用于分类任务中,通常在 CNN 的最后加一个全连接层前使用。
import torch import torch.nn as nn# 创建测试数据 x = torch.randn(2, 3, 32, 32) # [批次, 通道数, 高度, 宽度]# 不同输出尺寸的池化层 pool1 = nn.AdaptiveAvgPool2d(1) pool2 = nn.AdaptiveAvgPool2d((4, 4)) pool3 = nn.AdaptiveAvgPool2d((3, 5))# 查看输出形状 out1 = pool1(x) out2 = pool2(x) out3 = pool3(x)print(f"输入形状: {x.shape}") print(f"输出形状1: {out1.shape}") # [2, 3, 1, 1] print(f"输出形状2: {out2.shape}") # [2, 3, 4, 4] print(f"输出形状3: {out3.shape}") # [2, 3, 3, 5]

最大池化
常用于提取 最强的特征,例如在物体检测任务中可能希望选取最显著的特征。最大池化操作有时能够帮助模型捕捉到图像中的关键细节。

通道注意力机制代码
import torch
import torch.nn as nn
import torch.nn.functional as Fclass ChannelAttention(nn.Module):def __init__(self, in_channels, reduction_ratio=16):"""初始化通道注意力模块Args:in_channels (int): 输入特征图的通道数reduction_ratio (int): 降维比例,用于减少参数量"""super().__init__()# 确保降维后的通道数至少为1self.reduced_channels = max(in_channels // reduction_ratio, 1)# 全局平均池化 和 最大池化self.avg_pool = nn.AdaptiveAvgPool2d(1)self.max_pool = nn.AdaptiveMaxPool2d(1)# Sigmoid激活函数self.sigmoid = nn.Sigmoid()# 共享MLP网络# W0: in_channels -> reduced_channels# w1: reduced_channels -> in_channelsself.mlp = nn.Sequential(nn.Linear(in_channels,self.reduced_channels),nn.ReLU(inplace=True), # inplace=True 节省内存,直接在输入张量上修改,不会新建内存空间。默认是Falsenn.Linear(self.reduced_channels,in_channels))def forward(self, x):"""前向传播Args:x (torch.Tensor): 输入特征图 [B, C, H, W]Returns:torch.Tensor: 经过通道注意力加权后的特征图"""b,c,h,w = x.size()avg_pool = self.avg_pool(x).view(b, c) # [b,c,1,1]--> [b,c]max_pool = self.max_pool(x).view(b, c)avg_out=self.mlp(avg_pool) # w1(w0(F_avg^c))max_out=self.mlp(max_pool)# 融合两个分支并进行sigmoid激活channel_attention = self.sigmoid(max_out + avg_out)# 重塑维度用于乘法运算channel_attention = channel_attention.view(b, c, 1, 1)# 将注意力权重应用于乘法运算return x*channel_attentionif __name__ == '__main__':# 创建测试数据batch_size = 2channels = 3height = 64width = 64x=torch.randn(batch_size, channels, height, width)cam = ChannelAttention(in_channels=channels, reduction_ratio=16)outputs = cam(x)print(f"Input shape:{x.shape}")print(f"Output shape:{outputs.shape}")(1)深度学习基础知识(八股)——常用名词解释_深度学习八股-CSDN博客
nn.Linear()只对最后一维进行操作