【动手学深度学习】3.2. 线性回归的从零开始实现
目录
- 3.2. 线性回归的从零开始实现
- 1)生成数据集
- 2)读取数据集
- 3)初始化模型参数
- 4)定义模型
- 5)定义损失函数
- 6)定义优化算法
- 7)模型训练
3.2. 线性回归的从零开始实现
这一节中,我们将从零开始实现整个线性回归方法, 包括数据流水线、模型、损失函数和小批量随机梯度下降优化器。
.
1)生成数据集
构造一个人造数据集,用于恢复线性模型参数,数据集包含从标准正态分布采样的 2 个特征的 1000 个样本。
(1)数据生成方法:
使用线性模型参数 w = [ 2 , − 3.4 ] ⊤ 、 b = 4.2 \mathbf{w} = [2, -3.4]^\top、b = 4.2 w=[2,−3.4]⊤、b=4.2 和噪声项 ϵ \epsilon ϵ 生成数据集及其标签:
y = X w + b + ϵ \mathbf{y} = \mathbf{X}\mathbf{w} + b + \epsilon y=Xw+b+ϵ
其中,噪声项 ϵ \epsilon ϵ 服从均值为 0、标准差为 0.01 的正态分布。
代码实现:
def synthetic_data(w, b, num_examples): #@save"""生成y=Xw+b+噪声"""# 生成形状为(num_examples, len(w))的张量X,元素从均值0、标准差1的正态分布采样X = torch.normal(0, 1, (num_examples, len(w))) # 计算真实标签y = Xw + b(无噪声)y = torch.matmul(X, w) + b # 添加均值0、标准差0.01的噪声到标签y上y += torch.normal(0, 0.01, y.shape) return X, y.reshape((-1, 1))true_w = torch.tensor([2, -3.4])
true_b = 4.2
features, labels = synthetic_data(true_w, true_b, 1000)print('features:', features[0],'\nlabel:', labels[0])
# 输出:
# features: tensor([1.4632, 0.5511]) # 二维数据样本矩阵。
# label: tensor([5.2498]) # 一维整数标签数组。
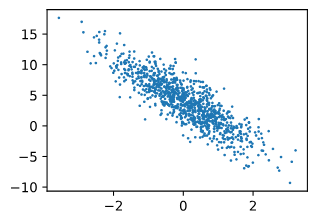
(2)数据集可视化:
通过生成第二个特征features[:, 1]和labels的散点图, 可以直观观察到两者之间的线性关系。
d2l.set_figsize()
d2l.plt.scatter(features[:, (1)].detach().numpy(), labels.detach().numpy(), 1);
.
2)读取数据集
(1)核心目标:
-
实现数据集遍历,按小批量(mini-batch)抽取样本,用于模型训练。
-
通过随机打乱数据顺序,避免模型学习到样本顺序的无关规律。
(2)数据迭代器data_iter:
定义一个 data_iter 函数,用于生成小批量数据:
-
输入 :批量大小
batch_size、特征矩阵features和标签向量labels。 -
输出 :生成多个小批量数据,每个小批量包含一组特征和标签。
def data_iter(batch_size, features, labels):num_examples = len(features) # 获取样本总数indices = list(range(num_examples)) # 创建索引列表 [0, 1, 2, ..., n-1]random.shuffle(indices) # 随机打乱样本顺序# 按批次生成数据for i in range(0, num_examples, batch_size):# 计算当前批次的结束位置(防止越界)end_idx = min(i + batch_size, num_examples) # 获取当前批次的索引batch_indices = torch.tensor(indices[i: end_idx])# 生成器:返回当前批次的特征和标签yield features[batch_indices], labels[batch_indices]
-
小批量运算可利用 GPU 并行计算优势,提高训练效率。
-
上述实现适合教学,但在实际应用中效率较低,深度学习框架内置的迭代器更高效,可处理存储在文件中的数据和数据流提供的数据。
.
3)初始化模型参数
在用小批量随机梯度下降优化模型参数前,需先初始化参数。
# 从均值为 0、标准差为 0.01 的正态分布中采样随机数初始化权重
w = torch.normal(0, 0.01, size=(2,1), requires_grad=True)
# 将偏置初始化为 0
b = torch.zeros(1, requires_grad=True)
初始化后,要更新这些参数以使其足够拟合数据。
每次更新需计算损失函数关于参数的梯度,手动计算易出错,所以使用自动微分来计算梯度。
.
4)定义模型
线性回归模型通过矩阵 - 向量乘法将输入特征 X 与权重 w 相乘,再加偏置 b 得到输出。广播机制会将标量 b 加到每个分量上。代码如下:
def linreg(X, w, b): """线性回归模型"""return torch.matmul(X, w) + b
.
5)定义损失函数
使用平方损失函数,同时,需将真实值 y 的形状转换为与预测值 y_hat 相同。代码如下:
def squared_loss(y_hat, y): """均方损失"""return (y_hat - y.reshape(y_hat.shape)) ** 2 / 2
.
6)定义优化算法
采用小批量随机梯度下降(SGD),每步用随机抽取的小批量计算损失梯度,朝减少损失方向更新参数。
更新大小由学习速率 lr 决定,用批量大小 batch_size 规范化步长。代码如下:
- 参数更新公式: θ ← θ − l r ⋅ ∇ L ( θ ) b a t c h _ s i z e \theta \leftarrow \theta - lr \cdot \frac{\nabla \mathcal{L}(\theta)}{batch\_size} θ←θ−lr⋅batch_size∇L(θ)
def sgd(params, lr, batch_size): """小批量随机梯度下降(SGD)"""with torch.no_grad(): # 创建无梯度计算上下文,确保参数更新操作不被加入计算图for param in params: # 遍历所有参数param -= lr * param.grad / batch_size # 参数更新param.grad.zero_() # 梯度清零
.
7)模型训练
模型训练主要过程如下:
-
初始化参数
-
重复训练直到完成
-
计算梯度: g ← ∂ ( w , b ) 1 ∣ B ∣ ∑ i ∈ B l ( x ( i ) , y ( i ) , w , b ) \mathbf{g} \leftarrow \partial_{(\mathbf{w},b)} \frac{1}{|\mathcal{B}|} \sum_{i \in \mathcal{B}} l(\mathbf{x}^{(i)}, y^{(i)}, \mathbf{w}, b) g←∂(w,b)∣B∣1∑i∈Bl(x(i),y(i),w,b)
-
更新参数: ( w , b ) ← ( w , b ) − η g (\mathbf{w}, b) \leftarrow (\mathbf{w}, b) - \eta \mathbf{g} (w,b)←(w,b)−ηg
-
在每个迭代周期(epoch)中,使用 data_iter 函数遍历整个数据集。这里设置迭代周期个数 num_epochs 为 3,学习率 lr 为 0.03。
lr = 0.03 # 学习率
num_epochs = 3 # 迭代周期数
net = linreg # 线性回归模型
loss = squared_loss # 均方损失函数for epoch in range(num_epochs):for X, y in data_iter(batch_size, features, labels): # 遍历小批量数据l = loss(net(X, w, b), y) # 前向传播:计算小批量损失l.sum().backward() # 反向传播:计算梯度(需先求和)sgd([w, b], lr, batch_size) # 参数更新:应用梯度下降# 评估当前模型with torch.no_grad():train_l = loss(net(features, w, b), labels)print(f'epoch {epoch + 1}, loss {float(train_l.mean()):f}')# 输出参数估计误差
print(f'w的估计误差: {true_w - w.reshape(true_w.shape)}')
print(f'b的估计误差: {true_b - b}')
输出:
# print(f'epoch {epoch + 1}, loss {float(train_l.mean()):f}')输出:
epoch 1, loss 0.042790
epoch 2, loss 0.000162
epoch 3, loss 0.000051# print(f'w的估计误差: {true_w - w.reshape(true_w.shape)}')
# print(f'b的估计误差: {true_b - b}')
# 的输出:
w的估计误差: tensor([-1.3804e-04, 5.7936e-05], grad_fn=<SubBackward0>)
b的估计误差: tensor([0.0006], grad_fn=<RsubBackward1>)
输出结果表明真实参数和训练学到的参数非常接近,说明训练成功。
注意:在机器学习中,我们更关注模型的预测能力而不是恢复真实参数。随机梯度下降通常能找到非常好的解。
.
声明:资源可能存在第三方来源,若有侵权请联系删除!